






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于降采样的光谱基线校正方法
[胡颖惠1  , 曹政
, 曹政1 , 傅海军1, * , 戴继生2 ]
, 曹政, 戴继生|
|


作者简介: 胡颖惠,女, 2000年生,江苏大学电气信息工程学院硕士研究生 e-mail: 2222207007@stmail.ujs.edu.cn
基线漂移现象普遍存在于光谱数据的采集过程中, 基线校正是对抗基线漂移干扰的重要手段。 基于稀疏表示的基线校正方法能取得较好的光谱预处理目标, 但在应用于高维度光谱基线校正时, 计算复杂度极大, 实效性差; 且在纯光谱稀疏结构上的利用度不足, 性能有待进一步提升。 为充分利用稀疏结构并显著降低计算复杂度, 提出了一种基于降采样的光谱基线校正方法。 通过降采样策略构造一个多快拍并附加相关矩阵的稀疏恢复模型, 在降低光谱数据维度的同时, 确保各降采样快拍具有共同稀疏性和空间相关性。 随后, 在变分贝叶斯推理(VBI)框架中引入独立向量分解模式, 利用向量乘积的数学变换技巧, 自适应解耦多快拍间的空间相关性, 进而分别推断出各快拍对应的贝叶斯最优稀疏解。 此外, 采用网格细化技术处理离网间隙, 进一步提升了基线校正性能。 模拟和真实数据集上的实验结果验证了所提方法的优越性。
Baseline drift is a common phenomenon in the collection process of spectral data, and baseline correction is an important means to combat baseline drift interference. The baseline correction method based on sparse representation can achieve good spectral preprocessing goals. However, when applied to high-dimensional spectral baseline correction, the computational complexity is extremely high and the effectiveness is poor. Moreover, the utility of pure spectral sparse structure is insufficient, and the performance needs to be further improved. This paper proposes a spectral baseline correction method based on down-sampling to utilize sparse structures and fully reduce computational complexity. Constructing a sparse recovery model with multiple snapshots and additional correlation matrices through a down-sampling strategy ensures that each down-sampling snapshot has common sparsity and spatial correlation while reducing the dimensionality of spectral data. Subsequently, in the variational Bayesian inference (VBI) framework, the independent vector decomposition mode is introduced, and the mathematical transformation technique of vector product is used to adaptively decouple the spatial correlation between multiple snapshots, thereby inferring the Bayesian optimal sparse solutions corresponding to each snapshot. In addition, using grid refinement technology to handle off-grid gaps further improves baseline correction performance. The experimental results on simulated and real datasets have verified the superiority of the proposed method.
红外、 拉曼等光谱技术在分析化学和无损检测领域具有广泛应用[1, 2]。 然而, 由于仪器测量的误差和光谱采集过程中可能出现的干扰, 纯光谱数据上易出现基线漂移, 从而影响原始光谱的特征提取[3]。 因此, 须在数据分析前对采集的光谱进行适当的基线校正, 提高光谱数据分析的可靠性和准确性。
相对于纯光谱而言, 基线的变化较为缓慢[3]。 充分利用这一特性, 国内外研究者提出了众多光谱基线校正方法。 惩罚最小二乘(penalized least squares, PLS)算法能有效地分离出光谱信号中的基线, 是最常用的基线校正方法之一[4]。 随后, 大量基于PLS的基线校正方法被提出[5, 6, 7, 8, 9], 尽管这些方法可自动更新权重, 但在低信噪比情况下难以获得令人满意的基线校正精度。
近年来, 随着压缩感知理论[10, 11]的迅速发展, 稀疏信号恢复(sparse signal recovery, SSR)已成功应用于光谱基线校正。 Han等对实测光谱进行稀疏表示, 提出了一种利用迭代收缩阈值对特征光谱和基线进行联合估计的方法(SSFBCSP)[12]。 然而, 所采用的l1范数近似不可避免地带来性能损失, 且在不同数据集上选择适当的正则项也存在较大挑战。 Li等人提出了一种基于稀疏贝叶斯学习(sparse Bayesian learning, SBL)的基线校正方法(SBL-BC)[13], 得益于贝叶斯框架固有的学习能力, 该方法无需手动选择任何正则项。 陈苏怡等提出了一种基于块稀疏学习的光谱基线校正方法(SBL-BC-block), 引入模式耦合分层模型[14], 自适应地学习稀疏向量的块稀疏结构, 改善了基于SBL的基线校正方法的性能。 然而, 光谱向量的维度一般较大, 导致基于SBL的基线校正方法在迭代计算矩阵逆时, 计算复杂度较高。
为充分利用稀疏结构并显著降低计算复杂度, 本文拟提出一种基于降采样的光谱基线校正方法。 该方法的主要创新点在于: 采用降采样策略构造一个多快拍且附加相关矩阵的稀疏恢复模型, 在降低光谱数据维度的同时, 确保各降采样快拍具有共同稀疏性和空间相关性。 随后, 在变分贝叶斯推理(variational Bayesian inference, VBI)框架中引入独立向量分解模式, 利用向量乘积的数学变换技巧, 自动解耦多个快拍间的空间相关性, 进而分别推断出各快拍对应的贝叶斯最优稀疏解。 此外, 进一步考虑将网格点作为可调参数, 采用网格细化技术来处理离网间隙。 模拟和真实数据集上的实验结果证实了该方法有效性和可靠性。
采集到的光谱数据y∈ RM的形式可表示为
式(1)中: x, b, n∈ RM分别表示纯谱向量、 基线向量和随机噪声。 由于纯谱x只包含少数几个谱峰, 因此可以用线型字典稀疏地表示[11]。 例如, 构造一个高斯线型矩阵AM∈ RM× M, 其第(i, j)个元素为: $\left.a( i, j\right)=\mathrm{e}^{\left(-\frac{1}{2 \sigma_{j}^{2}}(i-j)^{2}\right)}$, 式中
式(2)中: w∈ RM为纯谱的稀疏表示向量。 将式(2)代入式(1), 有
由于光谱数据通常包含多个波段, 每个波段都含有丰富的化学和物理信息, 如强度、 波长、 频率等, 导致光谱数据的维度较大。 为此, 可采用降采样策略降低原始频谱数据的维度[15]。 设T为整数因子, 令M=NT, 则可将y降采样为T个序列, 即
式(4)中, yt=[yt, yt+T, …, yt+(N-1)T]T, xt=[xt, xt+T, …, xt+(N-1)T]T, bt=[bt, bt+T, …, bt+(N-1)T]T, nt=[nt, nt+T, …, nt+(N-1)T]T。
将所有的yt项组合成一个矩阵, 有
式(5)中: Y, W, B, N∈ RN× T, AN∈ RN× N。
一般而言, 降采样后的数据会丢失原始数据中的部分有用信息, 但若能保留所有遍历降采样的数据, 可避免信息丢失, 并获得额外的稀疏结构特性, 特别是以较低的速率对信号进行采样时, 降采样能产生非常好的序列近似值。 由此可得, 降采样后光谱的稀疏表示矩阵W具有行稀疏特性, 且其取值极为近似。 此外, 在基于降采样的稀疏表示模型中, 字典矩阵AN的维度远小于原字典矩阵AM的维度, 因此, 在后续稀疏信号恢复过程中, 有望能显著降低计算复杂度。
在本章中, 我们将阐述基于降采样的光谱基线校正方法, 讨论如何充分利用稀疏结构, 及如何实现相应的贝叶斯推断。 最后通过细化方差来处理离网间隙, 并给出所提方法对应参数的初始化。
为使降采样后稀疏表示矩阵同行的非零系数不仅存在, 并尽可能相等, 我们将模型(5)重新表述为
稀疏矩阵S≜[s1, s2, …, sK]∈ RN× K, 其每个列向量都服从具有精度向量为γ ≜[γ 1, γ 2, …, γ N]T的零均值、 独立同高斯分布[16]
γ 服从伽马分布
式(8)中, c, d分别取一个很小的正实数。
由上述讨论可知, 降采样后的信号恢复问题变成了多个快拍的形式, C∈ RK× T刻画了降采样后多快拍条件下稀疏频谱同行的非零系数之间的空间相关性。 适当选择C的大小并不断进行迭代更新, 当S与C相乘后, 即可使得降采样后光谱的稀疏表示矩阵W不仅具有行稀疏特性, 且其同行的取值极为近似。
假设噪声N符合零均值、 独立同分布的高斯过程, 即[13]
式(9)中, α 为噪声精度, 则有
相对于纯谱X, 基线B的变化非常平缓, 无法对其直接建模, 因此我们引入二阶差分矩阵D∈ R(T-2)× N, 构造一个趋向于零的矩阵DB, 间接对B建模。 若将DB建模均值为零, 精度为β 的独立高斯分布, 则B的模型为[15]
α 和β 均未知, 通常使它们服从伽马分布[13]
为方便贝叶斯推理, 我们将C视为一个参数矩阵, 而不是一个随机变量, 其更新规则将在之后讨论。 根据上述稀疏贝叶斯模型, 联合分布p(Y, Θ )可分解为
式(14)中, Θ ={S, B, γ , β , α }表示隐藏变量。
由于无法直接获得后验概率分布p(Θ |Y)的闭式解, 我们将采用VBI求得p(Θ |Y)的最优近似解。 然而, 式(6)中矩阵S和C是混合在一起的, 当更新q(S)或计算任何有关q(S)的期望时, 会遇到ANSC(ANSC)T项, 若通过vec(ANSC)=(CTAN)· vec(S)这一传统的向量化方法来提取S, 等式两边矩阵的维数会比原始矩阵大得多, 导致计算与贝叶斯推理相关的矩阵的逆颇为复杂。
为此, 我们通过联合恢复稀疏矩阵S和相关矩阵C来降低计算复杂度, 同时增强基线校正性能。 当采用VBI将S的每个列向量分离出来时, 可利用
从而不再计算高维方差矩阵, 而是单独计算列向量的方差矩阵, 显著降低了计算复杂度。 式(15)有多种分解形式, 最优的一种是最小化p(Θ |Y)和q(Θ )的Kullback-Leibler (KL)散度, 即
KL散度越小, 其相似程度越高。 根据变分贝叶斯推导[15], 式(16)的解为
式(17)中, θ n表示Θ 第n个元素, q* /n表示$\prod_{i \neq n} q^{*}\left(\theta_{i}\right)$, $\propto$表示等于一个加性常数, $\langle\cdot\rangle_{q}$表示关于概率密度函数$q$的期望。
由于q* (θ n)由q* (θ i), i≠ n决定, 因此很难找到式(16)的封闭解。 然而, 我们可以通过式(17)迭代更新各个q(θ n)来找到一个稳态解。 例如, 在更新q(sk)时, 通过忽略与sk无关的部分, 可得
式(18)中,
式(19)中
类似可得
其中:
最后我们讨论如何更新相关矩阵C。 最优的C应最小化目标函数式(16), 其关于
$\begin{array}{c} \frac{\partial D_{K L}(q(\boldsymbol{\Theta}) \| p(\boldsymbol{\Theta} \mid \boldsymbol{Y}))}{\partial \boldsymbol{c}_{k}} \propto \\ \frac{\partial\left(\langle\ln p(\boldsymbol{Y} \mid \boldsymbol{S}, \boldsymbol{C}, \boldsymbol{B}, \alpha)\rangle_{q(\boldsymbol{S}) q(\boldsymbol{B}) q(\alpha)}\right)}{\partial \boldsymbol{c}_{k}} \propto \\ \hat{\alpha}\left[-\left(\boldsymbol{Q}_{-k}^{\mathrm{T}} \boldsymbol{A}_{N} \boldsymbol{\mu}_{k}\right)^{\mathrm{T}}-\boldsymbol{\mu}_{k}^{\mathrm{T}} \boldsymbol{A}_{N}^{\mathrm{T}} \boldsymbol{Q}_{-k}+2 \overrightarrow{\boldsymbol{c}}_{k} \boldsymbol{\mu}_{k}^{\mathrm{T}} \boldsymbol{A}_{N}^{\mathrm{T}} \boldsymbol{A}_{N} \boldsymbol{\mu}_{k}+\right. \\ \left.2 \overrightarrow{\boldsymbol{c}}_{k} \operatorname{tr}\left\{\boldsymbol{A}_{N} \boldsymbol{\Sigma}_{k} \boldsymbol{A}_{N}^{\mathrm{T}}\right\}\right] \end{array}$ (26)
令式(26)为0, 可得
此外, 为了快速计算Σ B和
如第1节“ 数据模型与方法回顾” 中所示, 高斯线型矩阵中方差
式(28)中, Re(· )代表实部,
其中, sign(· )表示符号函数, Δ 是步长且Δ > 0。 多次迭代后, 网格点将逐渐接近真实值, 从而使误差趋近于零, 减少了离网间隙带来的性能损失。
为了能顺利运行该算法, 我们需要对一些参数进行初始化:
所提出的基于降采样的光谱基线校正方法的具体步骤如表1所示。
| 表1 基于降采样的光谱基线校正方法步骤 Table 1 Steps of spectral baseline correction method based on down-sampling |
本文提出方法的主要计算复杂度为: 每次迭代更新$\left\{\mu_{k}\right\}_{k=1}^{K},\left\{\Sigma_{k}\right\}_{k=1}^{K}, \hat{\alpha}, \hat{\gamma}_{n}, \hat{\beta},\left\{\vec{c}_{k}\right\}_{k=1}^{K}$和ν j的计算复杂度分别为O(KN2), O(KN3), O(KN3), O(KN), O(KN3), O(KN2)和O(KN2)。 因此, 该方法每次迭代的总计算复杂度为O(KN3)。 而SBL-BC和SBL-BC-block每次迭代的计算复杂度为O(M3), 由于M≫N, 故本文所提方法有效降低了计算复杂度。
我们通过仿真实验来评估所提出方法的性能, 其中模拟数据集和真实数据集分别在3.1节和3.2节中使用。 实验运行环境为Windows 10操作系统, MATLAB版本为R2019a, CPU为Intel(R) Core(TM) i5-8265U, 内存为8GB。
在仿真1中, 针对指数基线构造的模拟数据集, 将本文方法与SBL-BC[13]和SBL-BC-block[14]进行比较。 假设模拟数据集中纯谱为:
图1为不同基线校正方法估计出的纯谱, 红色实线为真实光谱, 蓝色虚线为估计出的纯谱。 由图1可知, 当噪声方差较小(即σ 2=0.01)时, 所有方法的基线校正性能基本一致; 当噪声方差增大为σ 2=0.1时, SBC-BC部分性能下降, SBL-BC-block还能得到较为准确的纯谱估计结果; 当噪声方差继续增大为σ 2=0.5时, SBL-BC和SBL-BC-block性能明显下降, 无法估计正确的结果, 并且在背景区高估了一些未定义的额外峰, 这主要是因为噪声引起的一些波动被估计为光谱峰。 虽然本文提出的方法在背景区域会出现一些波动, 但其性能明显优于其他两种方法。 总之, 无论噪声方差如何变化, 本文方法都能表现出最优的估计性能。
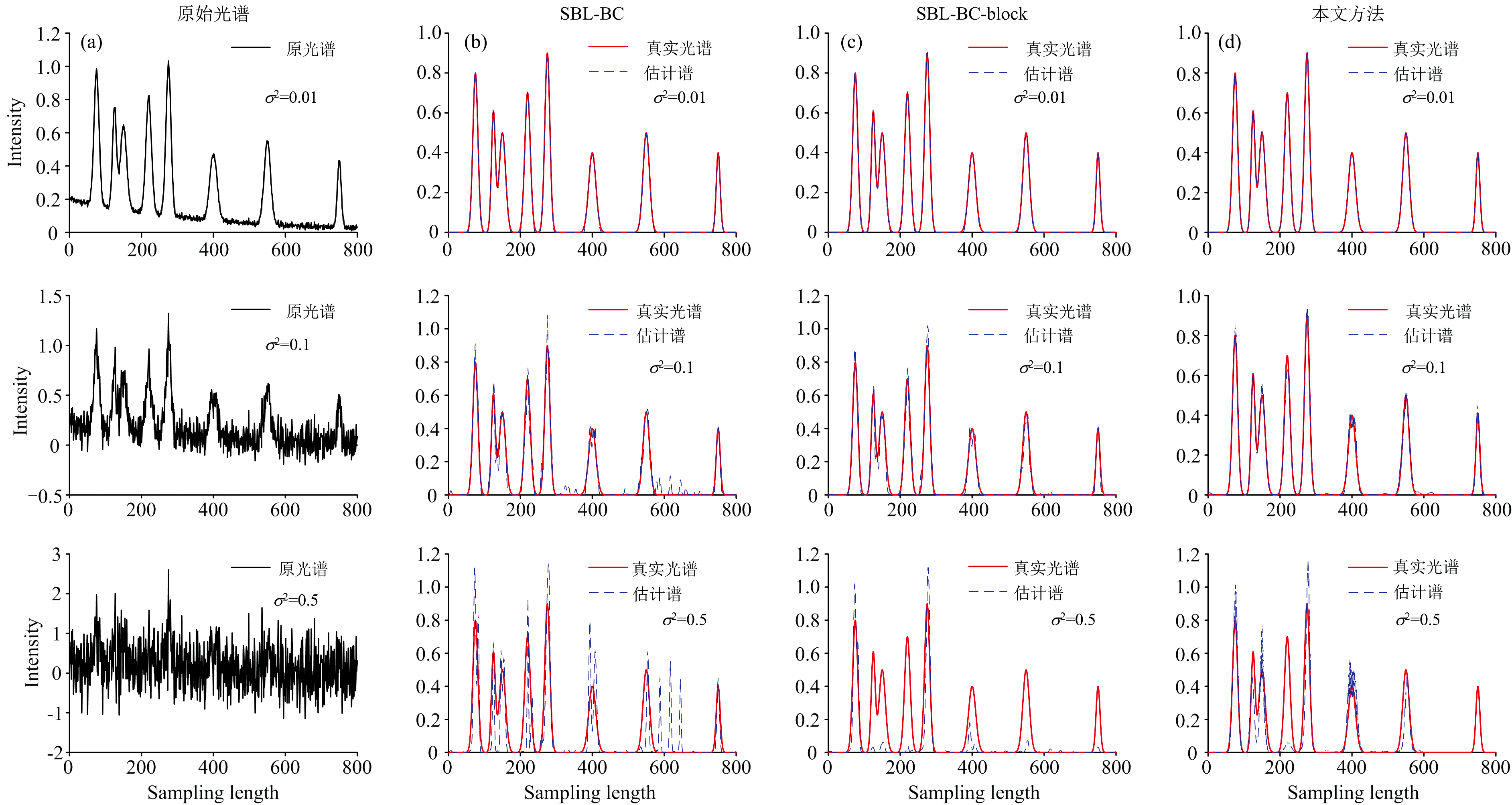 | 图1 模拟指数基线下不同基线校正方法估计的纯谱对比图Fig.1 Estimated spectrum comparison among different baseline correction strategies for simulated exponential baseline |
在仿真2中, 通过蒙特卡罗实验研究了信噪比与纯谱拟合的归一化均方误差(normalized mean square error, NMSE)的关系, 其中NMSE的定义为
式(30)中, 蒙特卡罗实验次数M=200,
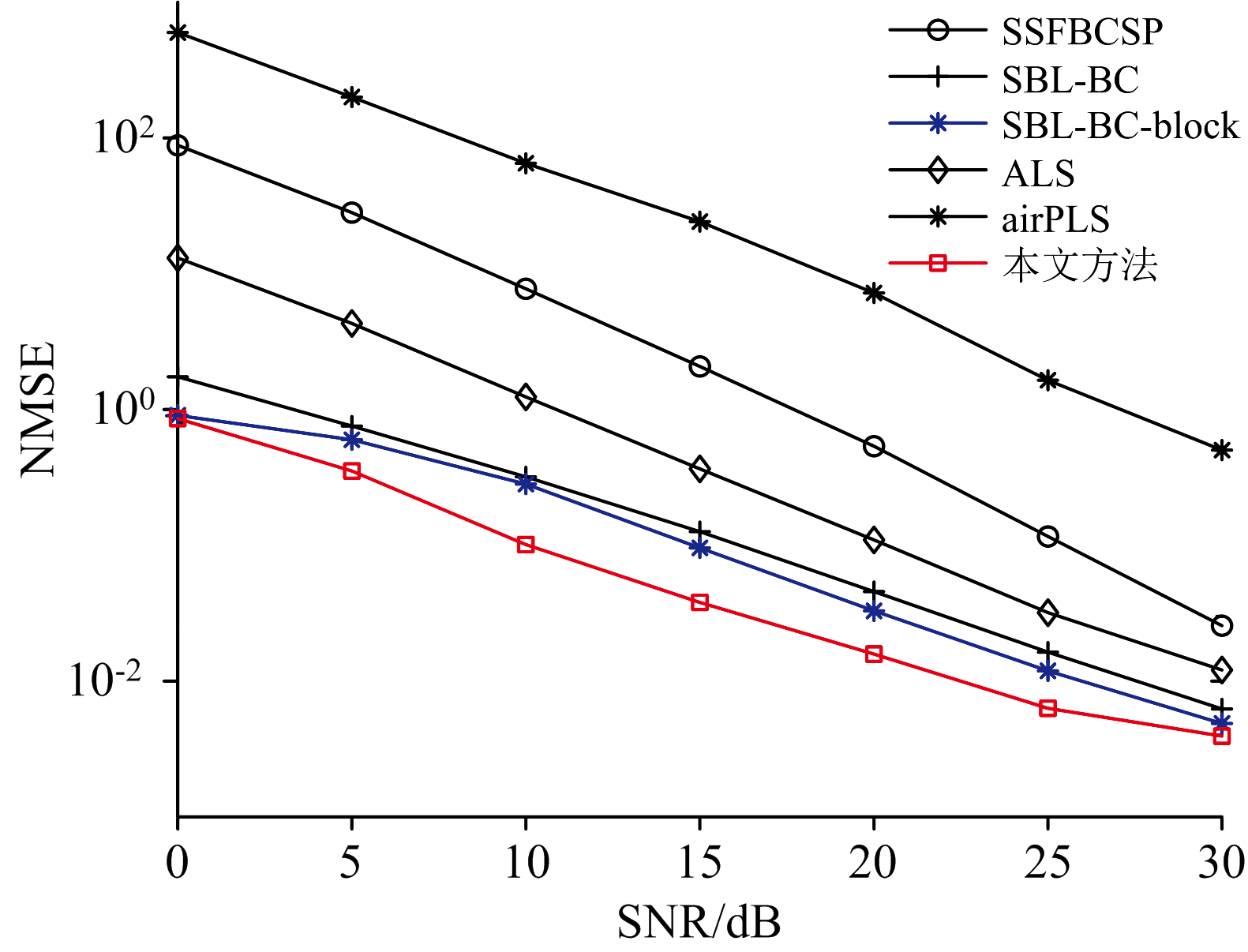 | 图2 模拟指数基线下随信噪比变化的纯谱拟合NMSE性能对比图Fig.2 NMSE performance comparison of spectrum fitting versus SNR for simulated exponential baseline |
表2列出了不同数据长度下单次蒙特卡罗仿真实验所需的时间。 易见, 随着数据长度的增加, 所有方法仿真时间都随之增加, 但不论数据长度为多少, 本文方法所用时间均少于基于贝叶斯方法的SBL-BC和SBL-BC-block, 说明本文方法可有效降低计算复杂度。
| 表2 不同数据长度下单次蒙特卡罗仿真实验运行时间对比 Table 2 Comparison of running time of single Monte Carlo simulation experiments under different data lengths |
为研究该方法在真实数据集中的基线校正性能, 本文选择三种不同矿物(锑华石、 绿帘石和准蒙脱石)的拉曼光谱数据集和玉米样品的近红外光谱数据集来进行实验[14]。 将本文方法与和SBL-BC和SBL-BC-block进行比较, 原光谱用黑色线表示, 估计出的纯谱用红色线表示, 估计出的基线用蓝色线表示。 图3至图5为三种矿物的拉曼光谱数据集估计出的纯谱与基线, 横坐标为拉曼位移; 图6为基于玉米样品的近红外光谱数据集估计出的纯谱与基线, 横坐标为波长(其数据集可在http://eigenvector.com获得)。 由实验结果可见, 本文方法估计出的纯谱信号更平滑, 能够过滤较多的噪声, 并且获得了更好的光谱信号重构性能。 总而言之, 对比四种数据集, 本文方法均表现出了最优的基线校正性能。
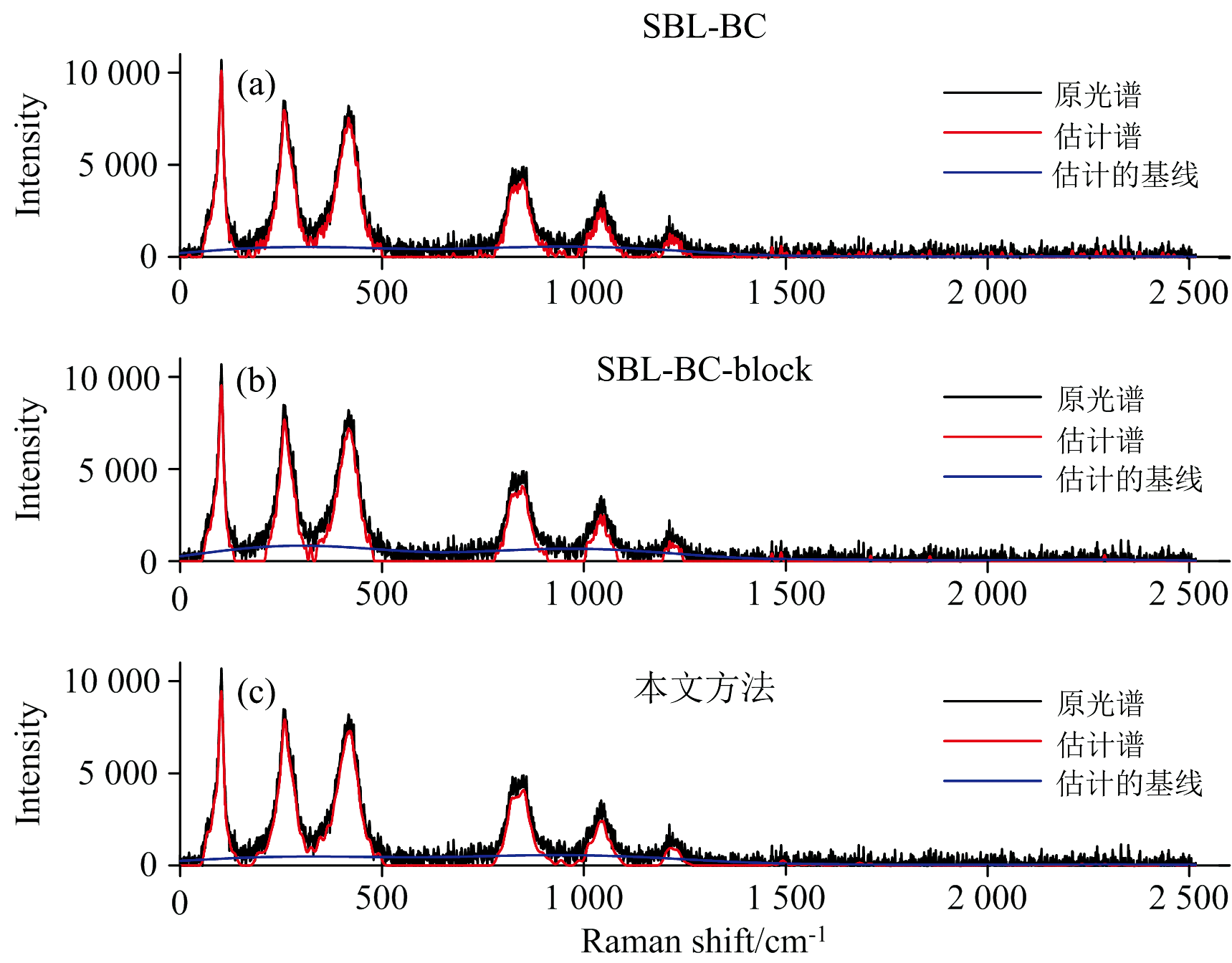 | 图3 锑华石数据集的基线校正对比图Fig.3 Comparison of baseline correction for Valentinite dataset |
 | 图4 绿帘石数据集的基线校正对比图Fig.4 Comparison of baseline correction for Epidote dataset |
 | 图5 准蒙脱石数据集的基线校正对比图Fig.5 Comparison of baseline correction for Paramontroseite dataset |
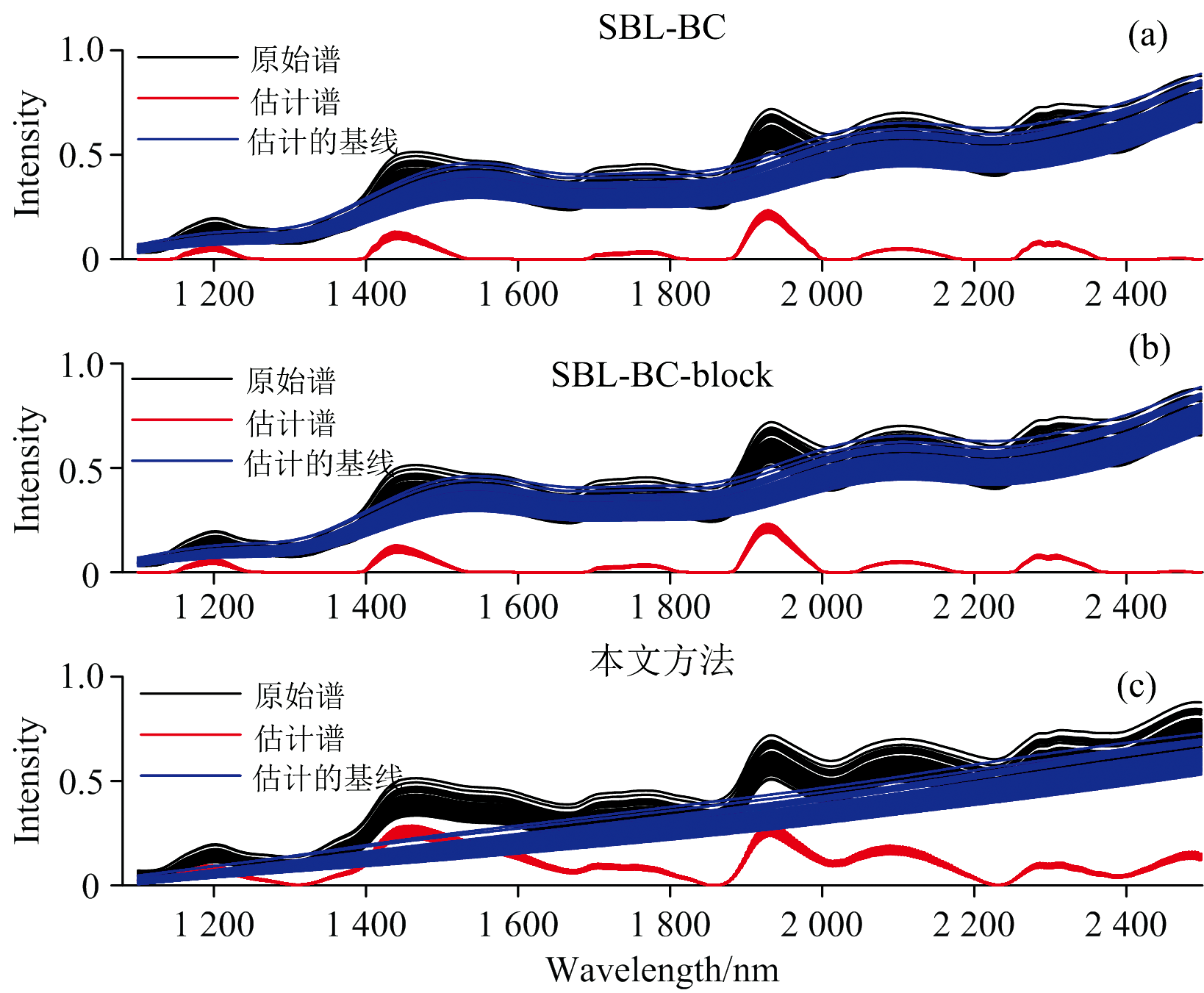 | 图6 玉米样品近红外光谱数据集的基线校正对比图Fig.6 Comparison of baseline correction for corn NIR dataset |
表3列出了每个真实数据集的程序运行时间。 不论是哪种数据集, 本文方法所用时间均最少, 由此可以验证本文方法有效降低了计算复杂度。
| 表3 真实数据集下不同基线校正方法的运行时间对比 Table 3 Comparison of the running time of different baseline correction methods on real datasets |
为了验证各种方法对抗噪声的性能, 我们将处理真实数据后的估计光谱作为参照信号; 然后, 在真实数据上施加一定大小的随机噪声, 并再次用各种方法处理获得新的估计光谱; 最后, 计算参照信号与新估计光谱的相似度。 相似度越大, 说明方法抗噪声能力越好。
具体实验步骤和结果如下: 本文通过蒙特卡罗实验验证不同程度的噪声对参照信号与新估计光谱相似度的影响。 所加的随机噪声遵循正态分布, 其强度由噪声系数ζ 所决定。 蒙特卡罗实验次数为100, 图7为四种不同的真实数据集实验得到的相似度与噪声的关系, 横坐标为噪声系数, 纵坐标为对应的相似度。 实验结果表明, 随着噪声的增加, 相似度整体呈下降趋势, 然而在所有数据集上, 本文提出的方法始终保持最高的相似度, 这凸显了其在噪声对抗上的优越性。
 | 图7 真实数据集的参照信号与新估计光谱相似度随噪声变化对比图Fig.7 Comparison of reference signals and newly estimated spectral similarity with noise changes for real datasets |
提出了一种改进的基于降采样的光谱基线校正方法。 为更好地利用纯谱的稀疏结构, 构造了一个多快拍且附加相关矩阵的稀疏恢复模型, 以确保各降采样快拍具有共同稀疏性和空间相关性。 为降低计算复杂度, 采用降采样策略减少字典矩阵的维数, 并在VBI框架中引入独立向量分解模式, 分别计算每个列向量的方差矩阵, 自适应解耦多个快照间的空间相关性。 此外, 将方差作为可调参数, 采用一步梯度法来处理离网间隙, 有效地提升了基线校正方法性能。 模拟和真实数据集上的实验结果验证了所提方法的优越性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|