








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于BOA-FRNN光谱模型的彩绘颜料浓度预测研究
[刘振1  , 樊硕
, 樊硕2, * , 刘思鲁2 , 赵安然2 , 刘莉3 ]
, 樊硕, 刘思鲁|
|


作者简介: 刘 振, 1983年生,曲阜师范大学传媒学院副教授 e-mail: zhen@whu.edu.cn;樊 硕, 1999年生,曲阜师范大学工学院硕士研究生 e-mail: 13581064038@163.com;刘 振,樊 硕:并列第一作者
近年来, 加大文物和文化遗产保护力度, 加强历史文化保护传承已上升为国家战略。 彩绘文物在人类活动、 风沙侵蚀以及光照损伤等各种病害的影响下, 文物颜料普遍出现了不同程度褪色、 变色、 老化、 脱落丢失等病害, 以致现在很难看到彩绘壁画本来的面目, 数字化保护与修复成为传承彩绘文物的重要手段。 本研究以颜色指纹的光谱反射率为基础, 将颜料成分变化外在表现的光谱反射率作为切入点, 采用数字化手段对彩绘颜料进行浓度映射。 为了实现对彩绘中矿物颜料浓度快速、 精确的识别, 基于贝叶斯优化算法(BOA)寻找前馈回归神经网络(FRNN)的最佳超参数并构建BOA-FRNN光谱模型实现颜料成分及浓度分布图谱的预测。 首先, 以中国传统彩绘技法制备不同浓度梯尺的敦煌矿物颜料色卡, 并利用Ci64UV积分球式分光光度计获取色卡的可见光波段光谱反射率及色度信息; 其次, 基于测量数据, 构建颜料光谱反射率、 色度值、 浓度值、 颜料粒径、 颜料成分的关联数据库; 最后, 通过双常数Kubelka-Munk模型、 BP网络模型、 支持向量机(SVM)回归算法、 FRNN网络模型和BOA优化SVM对颜料浓度进行预测并比较预测结果, 为了提高颜料浓度的预测精度和模型稳定性, 提出利用BOA对FRNN的网络结构、 激活函数和正则化强度进行优化, 以均方根误差(RMSE)作为适应度函数, 通过迭代选择最优的回归参数训练模型。 实验数据表明本文提出的BOA-FRNN模型精度最高, 模型测试集的均方根误差RMSE为1.805%, 决定系数为99.55%。 结果表明: 基于敦煌颜料颜色数据库能够更加准确、 快捷地选取所需光谱反射率, 从而提高模型效率, 简化了算法复杂度; BOA寻找FRNN的最佳超参数, 通过迭代更新超参数最优位置, 可以快速得到全局最优解, 与K-M、 BP、 SVM、 FRNN和BOA-SVM等模型相比, 矿物颜料浓度的预测准确度和模型稳定性都得到了明显提高, 满足了对颜料映射的精确度要求, 是快速实现颜料映射的一个可行新方法。
In recent years, efforts to protect cultural relics and heritage have been intensified, and the strengthening of the preservation and inheritance of historical culture has risen to the level of a national strategy. Painted cultural relics under anthropogenic, sand erosion, and photodamage, the color of cultural relics generally appeared to varying degrees of fading, discoloration, aging, shedding, and loss of disease, so that it is now difficult to see the original face of the mural painting,digital protection and restoration has become an important means of protection and inheritance of painted cultural relics. Based on the spectral reflectance of color fingerprints, this study has taken the spectral reflectance of the external manifestation of pigment composition change as the entry point andused digital methods to map the concentration of painted pigments. To quickly and accurately identify mineral pigment concentration in color painting, the Bayesian Optimization Algorithm (BOA) was used to find the optimal hyperparameters of the Feed-forward Regression Neural Network (FRNN), and a BOA-FRNN spectral model was constructed topredict pigment composition and concentration distribution mapping. Firstly, the color chart of Dunhuang mineral pigments with different concentration gradients was drawn by traditional Chinese painting techniques, and the visible spectral reflectance and chromaticity information of the color chartwas obtained by Ci64UV integrating sphere spectrophotometer.Secondly, the correlation database of pigments' spectral reflectance, chromaticity values, concentration, pigment particle size, and ingredients was constructed based on the measured data. Finally, the pigment concentration was predicted. The results were compared using the two-constant Kubelka-Munk model, BP network model, support vector machine (SVM) regression algorithm, FRNN network model, and BOA-optimized SVM. To improve the accuracy of concentration prediction and model stability, BOA was proposed to optimize the network structure, activation function, and regularization strength of FRNN. Root Mean Squared Error (RMSE) was used as the fitness function, and the optimal regression parameters were selected through iteration to train the model.The results of pigment data prediction showed that the optimal combination model was BOA-FRNN. Experimental data show that the BOA-FRNN proposed in this paper has higher accuracy. The determination coefficient R2 of the model test set was 99.55%, theroot mean square error RMSE was 1.805%. The results show that the Dunhuang pigment color database can select the required spectral reflectance more accurately and quickly, thus improving the model's efficiency and simplifying the algorithm's complexity. BOA searches for the optimal hyperparameters of FRNN and can quickly obtain the global optimal solution by iteratively updating the optimal position of hyperparameters. Compared with K-M, BP, SVM, FRNN, and BOA-SVM, the prediction accuracy and model stability are significantly improved, which meets the accuracy requirements of pigment concentration detection and is a feasible new method for fast pigment mapping.
文物和文化遗产承载着中华民族的基因和血脉, 是不可再生、 不可替代的中华优秀文明资源。 千百年来, 敦煌壁画在自然环境及人类活动的不断侵蚀下, 彩绘文物中的矿物颜料逐渐出现了粉化脱落、 颜色褪变、 起甲空鼓等病害, 导致壁画模糊或消失[1]。 彩绘文物传统修复主要通过修补、 再着色、 显现加固等物理方法, 但由于经验探索模式的局限性以及修复工作操作的不可逆性, 容易造成二次损伤[2]。 彩绘文物的数字化修复通过建立颜料颜色数据库对彩绘文物进行虚拟复原, 操作简单、 客观性强, 可将修复的风险性降至最低[3]。
颜料的浓度及颗粒度外显为彩绘文物的色彩外貌, 不同颜料呈现不同的阶调层次[4]。 因此, 彩绘文物表面颜料识别及浓度分析能够为褪变色彩绘文物的虚拟复原提供重要技术支撑, 对于彩绘文化遗产的数字化保护、 数字修复、 活化利用、 创新传承具有重要意义。 Kubelka-Munk模型基于颜料的光谱反射率获取浓度映射分布图谱, 已广泛应用于油画的色彩复原[5]。 美国孟塞尔颜色科学实验室Berns通过构建K-M光谱呈色模型, 建立“ 褪变色-原始色” 的色彩映射曲线, 对油画颜料的褪色部分进行色彩转换[6], 但是, K-M模型容易受到颜料首面反射的干扰, 需要Saunderson校正去除首面反射光[7], 适用于油画等颜料颗粒度较小的彩绘文物, 由于我国彩绘颜料的颗粒度普遍较大, Saunderson修正K-M模型的效果并不明显, 从而使得K-M模型难以精确地预测浓度映射分布图谱。
近年来, 深度学习因其多输入输出数据的并行处理能力及自学习能力, 在含量预测、 成分检测等领域展现出了巨大的发展潜力。 刘美辰等运用竞争性自适应加权算法筛选高光谱的特征波长, 提出了基于麻雀搜索算法优化支持向量机的方法, 实现了牛奶蛋白质含量的精确预测[8]。 深度学习中的前馈神经网络是目前技术较为成熟、 应用范围较为广泛的神经网络。 Zhao等通过缩放共轭梯度算法对前馈神经网络进行优化, 可根据水参数和关键控制参数对出水总氮进行精确预测[9]。 Sun等则通过遗传算法优化的BP神经网络建立了Phenol red溶液的定量分析模型, 通过寻找拉曼光谱强度与检测物质浓度之间的关系, 对不同浓度的Phenol red溶液进行检测[10]。 此外, 深度学习模型在多个应用领域展现出卓越的预测精度, 在矿物颜料浓度的预测方面, 现有的网络模型在基于光谱反射率预测颜料浓度时, 预测浓度精度不稳定, 容易出现局部最优, 鲁棒性有待提高。
综上, 针对颜料映射精度和模型稳定性不足的问题, 本文基于K-M模型建立浓度映射思想, 制备不同浓度的矿物颜料样本, 测量可见光400~700 nm波段的光谱反射率, 结合颜料浓度数据构建BOA-FRNN模型, 通过光谱反射率预测矿物颜料的浓度映射分布图谱。 并采用传统颜料分析中常用的双常数K-M模型、 具有任意复杂模式分类能力的BP网络模型、 具有强非线性拟合能力的支持向量机(SVM)回归算法、 具有优良多维函数映射能力的前馈回归神经网络(FRNN)模型以及基于贝叶斯优化算法(BOA)的BOA-SVM模型作为对比, 寻找出预测矿物颜料浓度的最优方法, 为彩绘中矿物颜料浓度的定量检验提供参考。
基于中国传统岩彩壁画绘制技法制备不同颗粒度及浓度的彩绘颜料色样, 构建敦煌彩绘矿物颜料样本集, 建立敦煌壁画颜料颜色色标数据库。 以白卡纸为基底模拟敦煌地仗, 以动物骨胶为连接料, 选取北京天雅岩彩画研究所提供的敦煌矿物颜料, 依照敦煌壁画绘制技法制作模拟样本。 混色颜料样本以0.1的比例间隔设置浓度梯尺, 如表1所示, 以钛白和铅黑两种混色颜料制作浓度梯尺色样, 共制作模拟样本430个。
| 表1 矿物颜料样本制备的浓度梯尺设置 Table 1 Concentration gradient setting for mineral pigment sample preparation |
实验依照中国传统岩彩绘画技法重绘了“ 释迦摩尼佛像” , 并将图像颜料分布区域及成分进行了映射, 如图1所示。 实验选取颜料样本中土红、 雌黄、 铅丹、 密陀僧、 群青和石绿等6类颜料, 具体包括纯色土红颜料、 土红与钛白7∶ 3混色颜料、 纯色雌黄颜料、 纯色铅丹颜料、 纯色密陀僧颜料、 纯色群青颜料、 群青与钛白5∶ 5混色颜料、 颗粒度9#的纯色石绿颜料、 颗粒度11#的纯色石绿颜料、 颗粒度13#的石绿与钛白7∶ 3混色颜料、 土红与雌黄5∶ 5混色颜料, 通过颜料颗粒度、 矿物颜料与钛白混合及矿物颜料两两混合呈现不同色调。
 | 图1 彩绘模拟图像中颜料的映射区域及对应色块 (a): 土红; (b): 土红∶ 钛白=7∶ 3; (c): 雌黄; (d): 铅丹; (e): 密陀僧; (f): 群青; (g): 群青∶ 钛白=5∶ 5; (h): 石绿(9#); (i): 石绿(11#); (j): 石绿(13#)∶ 钛白=7∶ 3; (k): 土红∶ 雌黄= 5∶ 5; (l): 模拟图像Fig.1 Mapping areas and their color blocks of pigments in an analog image (a): Earth red; (b): Earth red∶ titanium white=7∶ 3; (c): Orpiment; (d): Lead tetroxide; (e): Lithargyrum; (f): Ultramarine blue; (g): Ultramarine blue∶ titanium white=5∶ 5; (h): Mineral green(9#); (i): Mineral green(11#); (j): Mineral green(13#)∶ titanium white=7∶ 3; (k): Earth red∶ Orpiment= 5∶ 5; (l): The analog image |
本文采用X-Rite公司Ci64UV积分球式分光光度计测量430个色块可见光波段范围(400~700 nm)的光谱反射率。 设备采用d/8° 几何测量条件, 6 mm开孔直径, SCE测量模式, UV测量模式, 通过测量值三次求平均的方法消除测量随机误差, 将光谱反射率与色度值、 浓度值、 颜料粒径、 颜料成分等属性关联, 建立敦煌壁画颜料颜色色标数据库。
以土红雌黄混色颜料为例。 首先, 将土红设为Ⅰ 号颜料, 雌黄设为Ⅱ 号颜料, 按照表1浓度比例混合, 制备出第1组11个浓度梯尺的混色样本; 其次, 重复以上步骤进行样本制作, 共制作出8组11个浓度梯尺的混色样本; 最后, 使用分光光度计对88个土红雌黄混色样本进行光谱测量。 土红雌黄混色颜料样本在不同浓度梯尺的光谱反射率如图2所示。
 | 图2 矿物颜料两两混合后在11个浓度梯尺下的8组光谱反射率Fig.2 Eight sets of spectral reflectance of mineral pigments mixed in pairs at 11 concentration gradients |
1.2.1 训练样本数据
数据集的增强与扩充能够增加训练数据的多样性, 缓解过拟合现象, 提高模型泛化能力, 进而提高模型性能。 一般来说, 训练样本越多, 可以使模型对输入数据的微小扰动具有更好的鲁棒性, 提高模型的稳定性, 预测结果更加精确。 基于此, 本文通过非线性插值将0.1浓度梯尺混色样本数据库, 扩充为0.05比例间隔的混色样本数据库, 即将原来的11个比例间隔为0.1的颜料浓度梯尺样本数据扩充为21个比例间隔为0.05的颜料浓度梯尺样本数据。 并由8组样本的光谱反射率数据中随机选取5组进行训练样本。 训练样本不同浓度梯尺的混色样本光谱反射率如图3所示。
 | 图3 采集到的21个浓度梯尺下训练样本的光谱反射率Fig.3 Spectral reflectance of the training samples collected at 21 concentration gradients |
1.2.2 测试样本数据
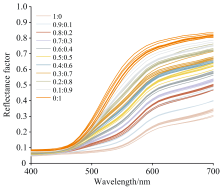
测试样本用于检验模型性能, 与训练样本类似, 测试样本数量过少同样会增加模型误差。 本文通过计算RMSE等评价指标来衡量真实值与预测值的一致程度。 同一个浓度梯度下的样本制备时难免会产生误差, 从而导致同一个浓度梯度下样本的光谱反射率不同, 当测试样本只有一组时, 通过光谱反射率计算出的预测值同样只有一组, 所得评价指标不足以证明模型精度, 因此本文通过三组测试样本对所建模型进行检验, 以此来减小误差。 实验选取8组样本数据中剩余的3组, 参照训练样本, 对其进行非线性插值扩充, 每组样本数据均具有21个浓度梯尺, 以保证训练集与测试集的一致性。 测试样本不同浓度梯尺的混色样本光谱反射率如图4所示。
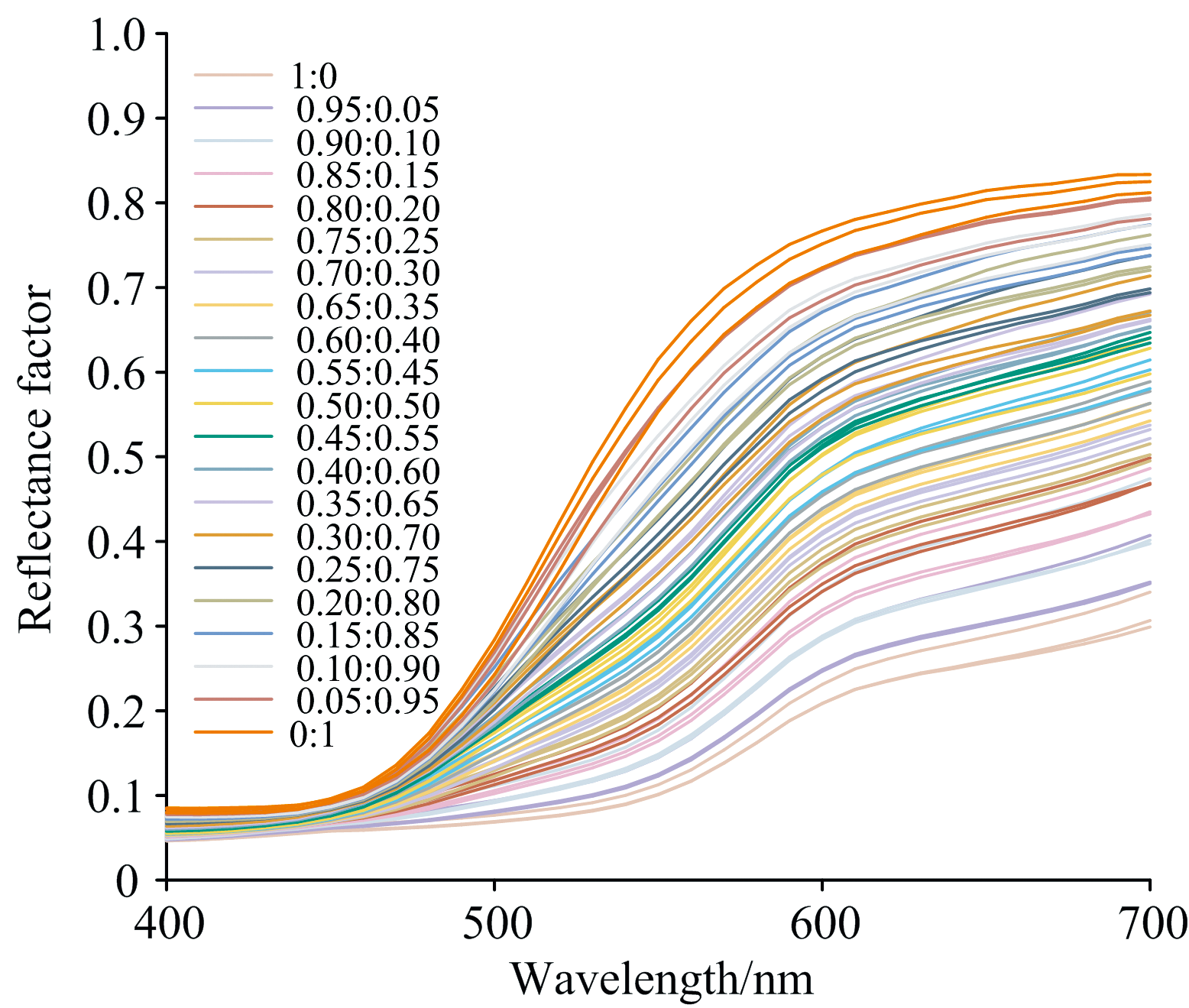 | 图4 采集到的21个浓度梯尺下测试样本的光谱反射率Fig.4 Spectral reflectance of the test samples collected at 21 concentration gradients |
K-M模型[11]通过光谱反射率计算吸收系数和散射系数之比, 对于不透明颜料, 可由式(1)表示
式(1)中, R为颜料的光谱反射率; K和S为颜料的吸收和散射系数。 混合颜料与各基色颜料之间的吸收散射比关系, 如式(2)所示
式(2)中, (K/S)mixture为混合颜料的吸收和散射系数之比; (K/S)i为第i个基色颜料的吸收和散射系数之比; n为混合颜料总数; ci为第i个基色颜料的浓度。
贝叶斯优化算法(Bayesian optimization algorithm, BOA)属于迭代算法, 广泛应用于超参数优化问题[12]。 BOA通过构建代理模型来建立目标函数与超参数的关系, 并使用贝叶斯推断不断根据先验知识和已有数据进行模型优化[13], 从而最大程度上减少真实目标函数的评估次数, 贝叶斯推断如式(3)所示
式(3)中, p(y│D)为后验概率分布, 表示对超参数的估计; p(D|y)为似然函数, 表示给定观测数据下, 超参数的似然性; p(y)为先验概率分布, 表示在没有观测数据的情况下对超参数的初始估计; p(D)为边缘似然概率, 表示得出固定超参数的概率。
由于高斯过程模型的灵活性和可追踪性[14], 本文采用高斯过程作为目标函数建模的代理模型, 通过已经进行的评估结果来估计超参数的概率分布。 高斯过程是一组随机变量的无限集合, 其中任意有限个变量的联合分布服从多元高斯分布, 如式(4)所示
式(4)中, GP为高斯过程, 表示连续域上的无限多个服从高斯分布的随机超参数所组成的随机过程; f(x)为高斯过程中的随机函数; x为输入超参数; m(x)为均值函数, 表示超参数的整体趋势; k(x, x')为协方差函数, 表示不同输入超参数之间的相关性。
在优化超参数时, BOA能够在较少的评估次数内寻找到具有较高性能的超参数组合; 能够更加智能地选择下一个超参数组合进行评估, 以使目标函数的值更大可能地提升; 能够充分利用已有数据, 通过不断更新代理模型来进行全局优化, 从而更有效地找到最优解。
BOA的工作流程如图5所示。 具体步骤如下: (1)输入待优化的超参数空间; (2)选择初始的样本点集合; (3)使用已有的样本点集合, 建立高斯过程模型来评估超参数的概率分布; (4)使用熵搜索策略选择下一个样本点xi+1, 该方法旨在最大化对超参数不确定性的贡献, 以尽可能的减少搜索超参数时的不确定性; (5)根据选择的样本点, 在真实的目标超参数上进行函数评估, 并获取新的观测值yi+1; (6)将新的观测值纳入高斯过程模型, 使用贝叶斯推断来更新超参数的概率分布, 并获得新的观测集(xi+1, yi+1)∈ D; (7)迭代了n次之后, 输出历史最优配置组合及其评估指标值, 得出最佳超参数。
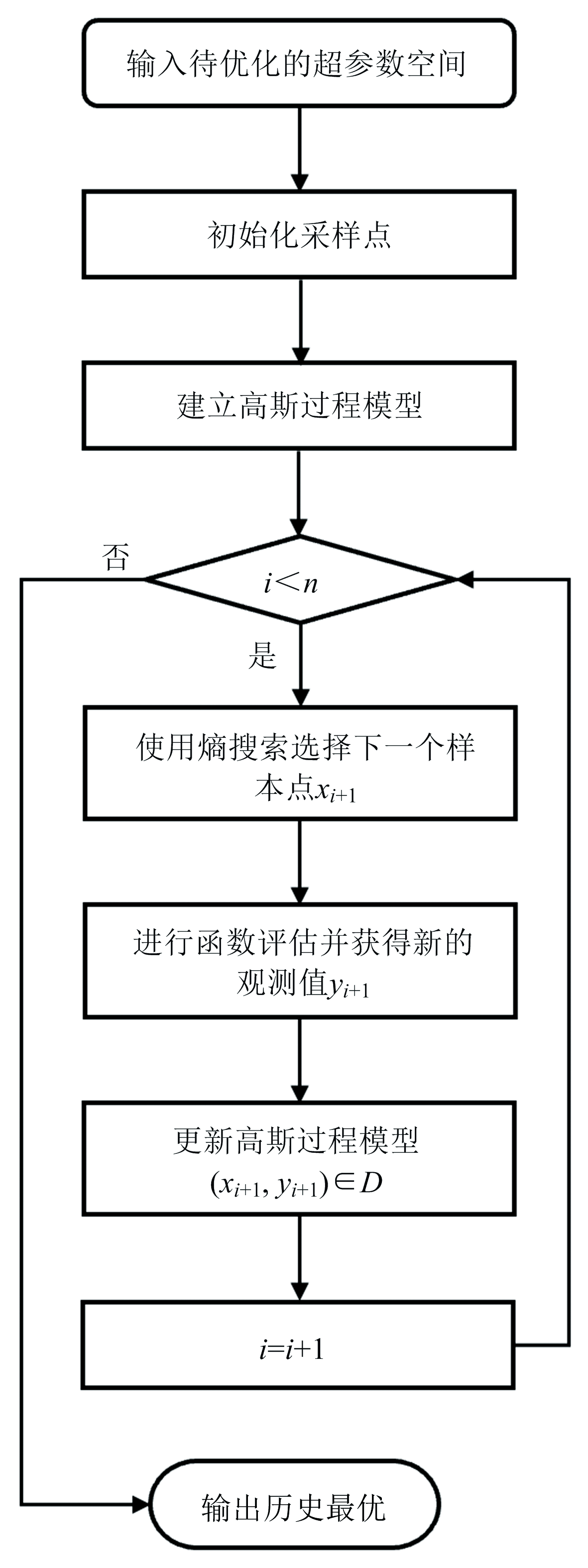 | 图5 贝叶斯优化算法流程图Fig.5 Workflow of the Bayesian optimization algorithm |
前馈回归神经网络(feedforward regression neural network, FRNN)的第一个全连接层与输入值相连, 随后的每一层与前一层相连, 即上下层之间实现全连接, 而同一层的神经元之间无连接, 如图6所示。 输入神经元与隐含层神经元之间是网络的权值, 其意义是两个神经元之间的连接强度。 隐含层或输出层任一神经元将前一层神经元传来的信息进行整合, 通常还会在整合过的信息中添加一个阈值, 模仿生物学中神经元必须达到一定的阈值才会触发的原理, 然后将整合过的信息作为该层神经元的输出。 FRNN在解决回归问题时具有较强的自学习和自适应能力, 但预测结果表明其对超参数选取的要求高, 若选取不当会导致性能降低。 故需要根据图5所示流程, 设置最大迭代次数为1 000, 利用BOA对FRNN的网络结构、 激活函数和正则化强度等超参数进行优化, 从而构建BOA-FRNN模型。
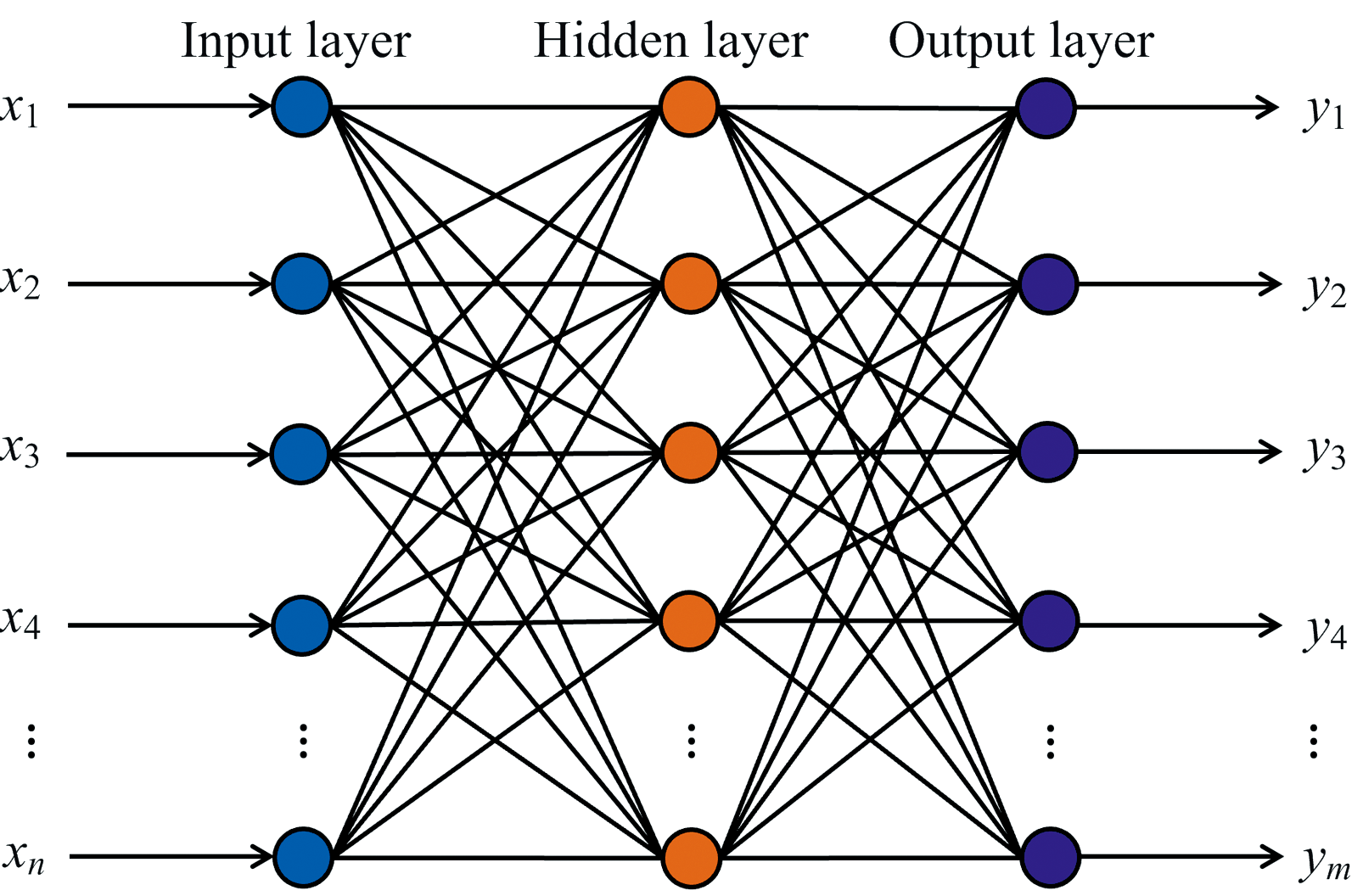 | 图6 FRNN模型的结构Fig.6 The structure of FRNN model |
2.3.1 网络结构优化
本文使用数据库中31维的光谱反射率预测1维的浓度映射分布图谱, 因此设置网络模型的输入层大小为31, 输出层大小为1。 对于隐含层, 按照图5所示步骤, 基于BOA寻找其大小从而使得网络结构最佳, 设置搜索范围为1~300, 最终优化出的隐含层大小为1, 从而构建出具有输入层、 隐含层和输出层的三层神经元网络。
2.3.2 激活函数优化
激活函数是神经网络的重要组成部分, 分为线性和非线性, 连续且可微。 神经网络的隐含层需要使用非线性激活函数, 目的是将非线性特性引入到神经网络中, 强化网络的学习能力。 若使用线性激活函数, 则具有隐含层的神经网络将成为一个巨大的线性回归模型, 这对于从光谱数据中学习复杂模式毫无用处。 输入层只保存输入数据, 不执行任何计算, 因此选取与隐含层相同的激活函数。 本文通过构建混合矿物颜料的浓度预测模型来解决回归问题, 输出层需要使用线性激活函数。
神经网络中使用的激活函数类型不同, 神经网络模型的性能便会存在较大差异, 因此需要选取适合于本文网络模型的激活函数以达到模型性能最大化。 本文基于BOA搜索最佳的激活函数, 设置搜索范围为ReLU、 LeakyReLU、 logsig、 dlogsig、 tansig和dtansig这6种回归问题中常用的非线性激活函数对输入层和隐含层的激活函数进行超参数优化, 搜索出的激活函数为tansig。 对于输出层, 本文使用线性激活函数purelin。 函数tansig的解析式为tanh(x)=
2.3.3 BOA-FRNN模型
本研究设置最大迭代次数为1 000, 根据图5所示流程, 基于BOA优化FRNN得出的网络输入层大小为31, 激活函数为tansig; 隐含层大小为1, 激活函数为tansig; 输出层大小为1, 激活函数为purelin; 正则化强度约为1.619× 10-5。 综上构建出BOA-FRNN模型如图7所示。
 | 图7 BOA-FRNN模型Fig.7 BOA-FRNN model |
本文定义BOA-FRNN模型将每个全连接层的输入乘以一个权重矩阵, 然后加上一个偏置向量。 权重矩阵决定了每个输入数据的特征对预测值的影响, 偏置向量避免了所有特征取值为0时得不出预测值的情况。 BOA-FRNN模型的权重调整如式(5)和式(6)所示, 偏置调整如式(7)式和(8)所示。
式(5)— 式(8)中, E为网络输出与实际输出样本之间的误差平方和; η 为网络的学习速率, 即权重调整幅度; wij(t)为t时刻输入层第i个神经元与隐含层第j个神经元的连接权重; wij(t+1)为t+1时刻输入层第i个神经元与隐含层第j个神经元的连接权重; wjk(t)为t时刻隐含层第j个神经元与输出层第k个神经元的连接权重; wjk(t+1)为t+1时刻输入层第j个神经元与隐含层第k个神经元的连接权重。 b为神经元的偏置, 下标意义与权重相同。
实验采用均值(Mean)、 方差(Variance)、 标准差(standard deviation, SD)、 均方根误差(RMSE)和决定系数(R2)五个评价标准评估模型性能。 令ti为颜料浓度的真实值; pi为模型计算的预测值; xi=|ti-pi|。 五个评价标准的具体计算公式如式(9)— 式(13)所示
式(9)— 式(13)中, xi为浓度差;
实验对比分析了六种光谱预测模型的性能, 包括双常数K-M模型[11]、 BP网络模型[15]、 SVM分类器模型[16]、 FRNN网络模型[17]、 BOA-SVM模型[18]和本文构建的BOA-FRNN模型, 分析结果如表2所示。 通过分析数据可知, BOA-FRNN光谱模型对于训练集的均值、 方差和标准差最小, RMSE为0.330%, R2为99.99%, 较其他模型最优; 测试集的均值、 方差和标准差最小, RMSE为1.827%, R2为99.66%, 较其他模型最优。 图8为六种光谱模型对颜料浓度的预测准确率, 相较于其他模型, BOA-FRNN光谱模型对于训练集和测试集的预测结果更加收敛。 综上分析, 本文所构建的BOA-FRNN光谱模型更加适用于预测矿物颜料的浓度映射分布图谱。
| 表2 六种光谱模型的预测分析结果 Table 2 Predictive analysis results of six spectral models |
 | 图8 六种光谱模型对颜料浓度的预测准确率 (a): 双常数K-M模型; (b): BP模型; (c): SVM模型; (d): FRNN模型; (e): BOA-SVM模型; (f): BOA-FRNN模型Fig.8 Prediction accuracy of pigment concentration by six spectral models (a): Two-Constant K-M model; (b): BP model; (c): SVM model; (d): FRNN model; (e): BOA-SVM model; (f): BOA-FRNN model |
本文比较分析了双常数K-M模型、 BP模型、 SVM模型、 FRNN模型、 BOA-SVM模型和构建的BOA-FRNN模型获取矿物颜料浓度映射的精度。 由于纯色颜料只起到设置浓度梯尺的作用, 因此只保留混色颜料色样, 即只保留0.9∶ 0.1~0.1∶ 0.9的比例间隔为0.1的浓度梯尺数据。 以混合颜料中的土红浓度为例, 六种光谱模型预测出的浓度精度如表3所示, 预测结果与真实结果的对比图如图9所示, 六种光谱预测模型的精度排序为: BOA-FRNN> BOA-SVM> FRNN> SVM> K-M> BP。 其中BOA-FRNN模型的预测结果与真实结果之间的重合度更高, 更符合真实值。
| 表3 六种光谱模型预测出的浓度映射分布 Table 3 Concentration mapping distribution predicted by the six spectral models |
 | 图9 预测结果与真实结果之间的对比图 (a): 双常数K-M模型; (b): BP模型; (c): SVM模型; (d): FRNN模型(e): BOA-SVM模型; (f): BOA-FRNN模型Fig.9 Comparison between predicted and ground truth (a): Two-Constant K-M model; (b): BP model; (c): SVM model; (d): FRNN model; (e): BOA-SVM model; (f): BOA-FRNN model |
六种模型真实值与预测值浓度差统计曲线如图10所示, 数据表明, 本文提出的BOA-FRNN模型预测的27个浓度差整体小于物理模型(双常数K-M模型)和网络模型(BP、 SVM、 FRNN和BOA-SVM), 且误差数据波动小, 结果更加稳定。 综上分析, 本文提出的BOA-FRNN模型在根据光谱反射率预测矿物颜料的浓度映射分布时性能更加稳定, 不容易陷入局部最优, 有效的提高了矿物颜料浓度的预测准确率。
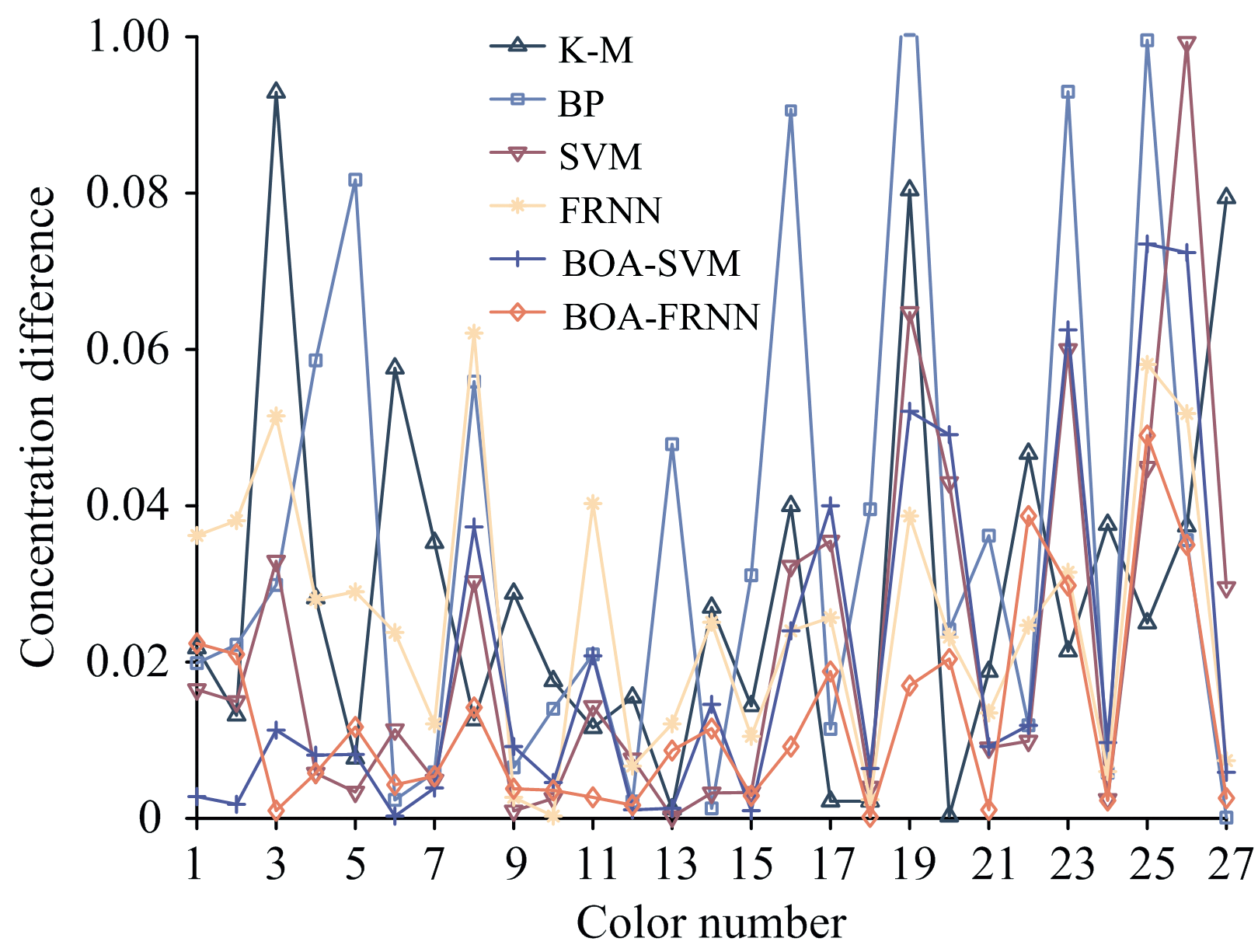 | 图10 六种光谱模型的浓度差曲线Fig.10 Concentration difference curves for the six spectral models |
本文以中国传统彩绘技法制备不同浓度梯尺的敦煌矿物颜料色卡, 构建了颜料光谱反射率、 色度值、 浓度值、 颜料粒径、 颜料成分的关联数据库, 提出了BOA-FRNN模型, 并与双常数K-M模型、 BP模型、 SVM模型、 FRNN模型、 BOA-SVM模型等光谱预测模型进行性能比较, 实现了基于可见光谱反射率的矿物颜料浓度预测, 结论如下:
(1)参照中国传统岩彩画绘制技艺, 建立了敦煌彩绘颜料色样集, 并与矿物颜料色度值、 吸收系数、 散射系数、 颜料粒径、 浓度等信息关联, 构建了敦煌矿物颜料数据库, 有效降低了颜料浓度预测模型的误差, 提高了准确率。
(2)评估分析了双常数K-M、 BP、 SVM、 FRNN、 BOA-SVM和BOA-FRNN六种预测模型。 其中本文提出的BOA-FRNN模型具有较高的精度。 在可见光谱反射率作为输入变量时, 训练集RMSE=0.330%, R2=99.99%; 测试集RMSE=1.827%, R2=99.66%, 相较于另外五种模型, 鲁棒性和精确性得到明显提高, 满足了预测需求, 为获取彩绘颜料的浓度映射分布图谱提供了有效依据。
(3)BOA-FRNN矿物颜料浓度分析模型精度高、 实验过程简便, 为彩绘中颜料浓度的定量检测提供了有效参考, 是彩绘中颜料浓度预测的可行新方法, 对实现古代彩绘的色彩复原具有重要意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|