






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于融合SENet通道注意力机制的残差网络和高光谱成像技术的血迹识别
[陈少阳 , 代雪晶
, 代雪晶* , 李云鹏, 汤澄清]
, 代雪晶, 李云鹏, 汤澄清]
|
|


作者简介: 陈少阳, 2003年生, 中国刑事警察学院硕士研究生 e-mail: 2740581484@qq.com
犯罪现场遗留血迹的提取与鉴定为案件侦破提供了重要依据, 但其快速、 无损显现与检验仍是法庭科学领域的研究热点。 为提高血迹的显现效率与检测精度, 高光谱技术逐渐被应用于血迹的无损识别。 然而, 现有高光谱成像技术在血迹及类血迹识别中, 尤其是针对复杂客体上的血迹时, 存在识别准确率低、 效率不足等问题。 为此, 通过将SENet通道注意力机制与一维残差网络(ResNet18-1D)融合, 提出了一种基于高光谱成像技术的血迹识别模型, 旨在提高血迹的高光谱成像技术识别准确率和效率。 SENet通道注意力机制通过学习自动获取每个特征通道的重要性权重, 进而增强有效特征并抑制无关特征。 针对承痕客体的复杂性, 改进传统SENet模块, 采用双分支瓶颈模型以提升模型的适用性。 为了应对公安实战中复杂多变的情况, 在包含多种承痕客体的公开数据集Blood Detection数据集上进行了两组实验。 (1)高光谱直推式分类实验场景: 训练集与测试集来自同一高光谱图像, 重点分析承痕客体对血迹特征的干扰。 实验表明, 该模型在包含复杂客体的模拟场景中总体精度(OA)与平均精度(AA)分别达96.8%和97.6%, 较当前最优的Hybrid CNN模型提升1.3%和1.9%; (2)高光谱归纳式分类实验场景: 在基础场景训练后直接迁移到另一幅图像中测试, 此实验侧重血迹及类血迹物质的预识别能力, 更具挑战性, 但更符合实际应用场景。 实验表明, 模型总体精度与平均精度分别为63.3%和65%, 较当前最优的RNN模型提升2.2%和1.6%, 并通过错误源分析发现, 番茄汁因其在470 nm附近的吸收峰与血液在415 nm的特征吸收峰相似, 成为主要干扰源。 除横向对比不同算法外, 还通过消融实验验证了SENet通道注意力机制模块对模型性能的影响。 结果显示, 改进后的SENet通道注意力机制模块相较于原始SENet通道注意力机制模块, 使模型在两种分类场景中的总体精度与平均精度都有提升。 同时, 效率测试显示虽然该模型参数量较大, 但残差结构与双分支SENet的协同设计显著降低计算成本, 训练耗时仅为45 ms·epoch-1, 满足实战的效率需求。
The extraction and identification of bloodstains left at crime scenes provide an important basis for case investigation, but their rapid and non-destructive development and examination remain a research hotspot in the field of forensic science. To enhance the development efficiency and detection accuracy of bloodstains, hyperspectral technology has gradually been applied to the non-destructive identification of bloodstains. However, existing hyperspectral imaging techniques have limitations, including low recognition accuracy and insufficient efficiency in identifying bloodstains and blood-like substances, particularly when dealing with bloodstains on complex objects. Therefore, a bloodstain identification model based on hyperspectral imaging technology by integrating the SENet channel attention mechanism with a one-dimensional residual network (ResNet18-1D) was proposed in this paper, aiming to improve the accuracy and efficiency of bloodstain recognition by hyperspectral imaging technology. The SENet channel attention mechanism automatically acquired the importance weight of each feature channel through learning, thereby enhancing effective features and suppressing irrelevant ones. In view of the complexity of the trace-bearing object, this paper improved the traditional SENet module and adopts a dual-branch bottleneck module to enhance the applicability of the model. To address the complex and dynamic nature of forensic practice, this paper conducted two sets of experiments on the public blood detection dataset, which contains multiple traceable objects. (1) Hyperspectral Transductive Classification Scenario. Both training and test sets were derived from the same HSI image. This experiment focused on analyzing substrate interference with bloodstain spectral features. Results show the model achieved an overall accuracy (OA) of 96.8% and an average accuracy (AA) of 97.6% in the complex simulated scenario, representing improvements of 1.3% and 1.9%, respectively, compared to the state-of-the-art Hybrid CNN model. (2) Hyperspectral Inductive Classification Scenario. The model trained on the baseline scenario was directly transferred to test on a different image. This experiment focused on the pre-identification capability for bloodstains and blood-like substances, presenting greater challenges but better reflecting real-world application needs. Experiments showed that the overall accuracy and average accuracy of the model were 63.3% and 65% respectively, which were 2.2% and 1.6% higher than the current optimal RNN model. Through error source analysis, it was found that tomato juice, due to its absorption peak near 470 nm being similar to the characteristic absorption peak of blood at 415 nm, has become the main interference source. In addition to making horizontal comparisons of different algorithms, this paper also verified the impact of the SENet channel attention mechanism module on model performance through ablation experiments. The results showed that the improved SENet channel attention mechanism module, compared with the original SENet channel attention mechanism module, had enhanced the overall and average accuracy of the model in both classification scenarios. Meanwhile, the efficiency test showed that, despite having a large number of parameters, the collaborative design of the residual structure and the dual-branch SENet significantly reduced the computational cost. The training time is only 45 ms·epoch-1, meeting the efficiency requirements of practical combat.
高光谱成像技术是一种通过先进的光谱成像仪对样品进行拍摄, 直接获取检材特定频率和波长下的高光谱信息, 并对其数据进行计算和分析, 从而实现高效、 无损地识别与显现痕迹的技术[1]。 在公安学科领域, 随着公安技术信息化的快速发展, 高光谱成像技术在犯罪现场勘查与物证鉴定中的应用日益成熟, 尤其是在血迹检测和鉴定方面。 例如, 在犯罪现场勘查中, 高光谱成像技术可凭借对血迹独特光谱特征的捕捉, 精确定位血迹位置, 为案件侦破提供重要线索[2]。 在物证鉴定方面, 该技术能够识别各类涉案物质(如血迹[3]、 涂改笔迹、 指印等), 辅助判断物证来源及与案件的关联程度。 因此, 结合高光谱成像技术, 深入研究血迹及类血迹物质的识别算法, 对于提升公安部门案件侦破效率、 维护社会安全稳定具有重要的现实意义。 尽管高光谱图像识别技术在公安领域展现出巨大潜力, 但当前针对血迹及类血迹物质的识别算法仍存在诸多不足。 一方面, 识别准确率有待提高; 由于血迹的光谱特征易受承痕体背景干扰, 且各种类血迹物质的光谱特征可能存在相似性, 导致现有算法在复杂场景下难以准确区分血迹与类血迹物质。 另一方面, 算法效率较低; 高光谱图像具有高维度、 大数据量的特点, 同时面临共线性、 冗余性和“ 维数灾难” 等挑战, 使得模型构建成为挑战。 传统算法往往需要耗费大量计算资源, 难以满足公安实战中对快速检测的时效性需求。
近年来, 随着深度学习的快速发展, 基于高光谱成像技术的血迹识别算法成为一个研究热点。 2018年, Romaszewski[4]等构建了血迹及类血迹物质的高光谱数据集, 为利用高光谱成像技术研究血迹的识别算法提供了可选的训练数据集。 2019年, Zhao[5]等提出了一种血液波段不等式模型(blood band inequality model, BBIM), 用于血迹分类识别, 利用反射率之差建立不等式模型, 成功从8种类血迹痕迹中识别出血迹。 2020年, Kamil[6]等将用于遥感高光谱图像成像的神经网络模型迁移到血迹识别, 并比较了不同的深度学习网络框架。 2021年, Muhammad[7]等提出了一种混合卷积神经网络(Hybrid CNN)用于高光谱血迹分类。 该研究利用公开的高光谱血迹数据集[4]进行了实验; 数据集包含血迹、 番茄酱、 人造血液等多种物质, 其分类准确率达到了96%, 但未考虑更复杂的迁移场景(如不同承痕客体)。
为提高血迹及类血迹物质识别的准确率与效率, 本工作应用高光谱成像技术, 提出了一种适用于多客体、 多目标的血迹识别模型。 该模型融合SENet通道注意力机制与一维卷积残差网络(ResNet18-1D)。
SENet(squeeze and excitation networks)是由Momenta 团队提出的网络结构[8]。 该团队利用SENet, 一举取得ImageNet2017竞赛Image Classification 任务的冠军, 在ImageNet数据集上将top-5 error降低到2.251%(原最好成绩是2.991%)。 为了在不增加空间维度的情况下实现特征融合, 并有效建模通道间的依赖关系, Momenta 团队提出了SE模块(SENet中的瓶颈结构)。 具体而言, SE模块通过自主学习动态生成各特征通道的权重, 进而根据通道的重要性自适应地增强有用特征并抑制冗余特征。 SE模块的结构如图1所示。 SE模块主要包含Squeeze、 Excitation和Reweight三个阶段。
 | 图1 SENet网络的核心部分SE模块Fig.1 The core part of the SENet network: SE bottleneck module |
Squeeze是将各个通道大小为H× W的特征图通过全局平均池化压缩为一个标量值, 从而得到一个维度为C(通道数)相对应的通道描述向量的操作。 该向量表征了该层C个特征图的全局信息。 通过Squeeze操作, 原来的跨空间维度特征聚合到了通道维度上, 便于后续神经网络通过学习压缩后的一维向量来获取每个特征通道的重要程度。 Squeeze操作如式(1)所示
$z_{c}=F_{s q}=\frac{1}{H \times W} \displaystyle\sum_{i=1}^{H} \displaystyle\sum_{J=1}^{W} u_{c}(i, j)$(1)
式(1)中, uc表示第c个通道的特征图, zc表示经过压缩后全局信息。 Excitation是一个类似于循环神经网络中门的机制, 通过参数w来为每个特征通道生成权重。 为了限制模型复杂度和提高模型泛化能力, Excitation操作中通过采用两个全连接层的瓶颈结构来实现参数化门机制。 具体结构是由一个缩减比为r的全连接层, 一个ReLU层和一个返回输入维度C的全连接层的瓶颈结构。 Excitation操作如式(2)所示:
式(2)中, δ 表示ReLu函数, σ 表示sigmoid激活函数, W1和W2分别是两个全连接层的权重矩阵。 Excitation操作的输出s是一个C维向量, 表示对U中C个特征图的权重分配。 Reweight是将Excitation输出的权重向量s视为各特征通道的重要性, 通过乘法逐通道对原始特征图U加权, 进而在通道维度上对原始特征重标定的操作。 Reweight操作如式(3)所示
$\tilde{x}=F_{\text {scale }}\left(u_{c}, s_{c}\right)=s_{c} \cdot u_{c}$(3)
式(3)中, $\tilde{x}_{c}$是重标定后的维度为C的特征图。 SE模块核心是Excitation操作学习得到的通道权重s, 它是通过Excitation操作中全连接层和非线性层学习得到的。 由于其灵活的设计, 因此SE模块即可以嵌入到非残差网络的Inception结构当中, 如图2(a)所示, 也可以嵌入到含有跳跃连接的残差网络的残差结构中, 如图2(b)所示。
 | 图2 SE模块嵌入神经网络的两种结构 (a): SE模块嵌入非残差网络Inception结构; (b): SE模块嵌入残差网络的残差结构Fig.2 Two structures of embedding the SE bottleneck module into neural networks (a): SE bottleneck module embedded into the non-residual Inception architecture; (b): SE bottleneck module embedded into the residual structure of a residual network |
为更有效地聚焦波段特征对整体模型性能的影响, 将传统SENet通道注意力的Squeeze操作部分改进成为双分支结构, 如图3所示。 改进后的Squeeze部分在原有全局平均池化层(GAP)的基础上新增了全局最大池化层(GMP)的分支。 该结构能将原输入特征向量压缩为两组通道描述向量, 这两组向量的全局感受野具有不同的侧重点。 然后再对这两组向量分别进行Excitation操作得到两个权重向量s1、 s2, 将s1、 s2相加融合后再经过1D卷积层和Sigmoid层进行进一步提取通道相关性[9]。
 | 图3 改进后的SENet通道注意力机制模块Fig.3 Improved SENet bottleneck module |
He等[10]为克服传统卷积网络随层数增加引发的梯度消失或爆炸问题, 设计了残差网络(ResNet)。 传统模型中, 深层网络的梯度反向传播相关性会随着网络层数的增加逐渐减弱, 导致浅层梯度更新退化为无效扰动。 残差网络在训练过程中, 通过在残差块(Residual block)中引入“ 恒等短路连接(identity shortcut connections)” 实现恒等映射(identity mapping)。 通过跨越两个卷积层的跳跃连接(skip connection)将模块的输入与主路径的输出相加[11]。 这种设计构建了梯度传播的“ 捷径” , 使梯度无需经过多层非线性变换即可直达浅层, 显著缓解了梯度异常问题。 同时, 残差模块中的批量归一化层(batch normalization, BN)通过标准化与可学习的缩放平移变换, 将卷积输出特征调整至标准正态分布。 这迫使特征值落入激活函数的敏感区间, 微小输入变化即可引发损失函数的显著响应, 从而增大梯度幅值, 在抑制梯度消失的同时加速模型收敛。
由于原始的残差网络是为二维图像数据设计的, 而高光谱波段数据本质是序列数据, 本文进行了两项适配操作: 一是将原有的二维卷积替换为一维卷积(Conv1D); 二是将改进的SENet通道注意力机制模块嵌入残差结构。 基于ResNet18残差网络构建的融合模型如图4所示。
 | 图4 本文所构建的融合SENet通道注意力机制模块的残差网络模型Fig.4 Res18-1D model integrating SENet bottleneck module in this paper |
鉴于血迹高光谱检测的专业性及公开数据集的稀缺性, 采用文献[4]描述的Blood Detection公开数据集, 该公开数据集已经在文献[6, 7]中得到了论证, 可以迁移到卷积神经网络中进行训练。 Blood Detection数据集包含由已标注的血迹和六种类血迹物质(即人造血迹、 番茄汁、 番茄酱、 甜菜根汁、 海报颜料和亚克力漆)的高光谱图像。 该数据集的图像由SOC710高光谱成像仪采集, 工作波段范围为377~1 046 nm, 共128个波段。 根据文献[7]中的建议, 训练时去掉了[0~4]、 [48~50]和[122~128]的噪声波段, 保留剩余的113个波段作为模型输入。 由于其中的甜菜根汁在模拟场景E中没有图像及光谱数据, 所以在实验中去除了甜菜根汁, 对血迹及五种类血迹物质进行识别。
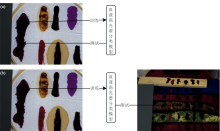
Blood Detection数据集提供了两种场景: (1)基本框架场景F, 如图5(a)所示。 该场景将血迹及类血迹物质均匀地涂抹在白色织物背景上, 最大程度上减少承痕客体对血迹及类似物光谱特征的干扰。 该场景中不同物质的光谱曲线如图5(a')所示; (2)模拟场景E, 如图5(b)所示。 该场景是将不同物质涂抹在不同承痕客体上。 由于不同承痕客体会干扰物体的光谱特征, 如图5(b')所示, 不同承痕客体上血迹的光谱曲线发生了不同程度的偏移。
 | 图5 Blood Detection数据集所提供的场景及光谱图 (a): Blood Detection数据集中的基本框架场景F; (a'): 基本框架场景F各物质的光谱曲线; (b): Blood Detection数据集中模拟场景E; (b'): 模拟场景E中不同承痕客体上血迹的光谱曲线Fig.5 The scene and the image in Blood Detection dataset (a): Basic framework scenario F in the Blood Detection dataset; (a'): Spectral curves of various substances in basic framework scenario F; (b): Simulated scenario E in the Blood Detection dataset; (b'): Spectral curves of blood on different substrates in simulated scenario E |
为了进一步提高模型的稳定性和泛化能力, 通过添加随机噪声和混合同类样本数据的方式对图像中像素点的高光谱波段数据进行了数据增强。
为了让模型能够处理多种情况, 设立了两组实验: (1)高光谱直推式分类场景, 如图6(a)所示。 模型在已知标签的高光谱图像上进行训练, 从图像中采样像素点, 利用其光谱特征进行分类。 由于高光谱图像中的血迹及类血迹区域已预先标定, 故分类任务的核心在于通过选取的少量像素点识别特定区域物质的种类。 该模型通过分析不同物质在多种承痕客体上的光谱特征, 提升了复杂背景下的识别能力。 实验旨在验证基于少量样本的多物质分类方法的可行性。 (2)高光谱归纳式分类场景, 如图6(b)所示。 该实验首先在Blood Detection数据集的基本场景F中训练分类模型, 随后将其迁移到包含不同承痕客体模拟场景E中进行测试。 该场景更具挑战性, 需克服光照角度、 承痕客体背景干扰等因素的影响。 然而, 这一实验场景更符合公安实战要求, 预训练模型可集成至系统中, 显著降低人工学习成本, 便于推广应用, 适用于复杂环境下的快速检测。
 | 图6 直推式和归纳式分类场景实验流程 (a): 高光谱直推式分类场景实验; (b): 高光谱归纳式分类场景Fig.6 Experimental process of transductive and inductive classification scenarios (a): Hyperspectral transductive classification scenario experiment; (b): Hyperspectral inductive classification scenario experiment |
实验平台的操作系统为Window10, CPU为Inter Core i5-10200H、 内存为16GB, GPU为Nvidia GeForce GTX 1650。 模型由Python 3.12.7编译, 训练框架为Pytorch GPU 2.5.1版本, CUDA版本为12.4。 优化器算法选择SGD, 学习率设定为0.01, 损失函数选择交叉熵损失函数, 如式(4)所示。
$L=-\displaystyle\sum_{i}\left[y_{i} \cdot \log \left(p_{i}\right)\right]$(4)
式(4)中, yi代表该真实标签中第i类的取值, 取值为0或1; pi表示模型预测第i类的概率。 训练集选取的像素点数量占高光谱图像中所有已标注像素点总数的5%并均分到各类物质中。 在基本场景F中, 训练集数量为2 478个像素点, 而在模拟场景E中, 训练集数量仅为为888个像素点。 其余部分为测试集, 每个训练轮次中再随机提取训练集中的5%用于验证, 训练轮次(epochs)设置为400。
在高光谱直推式分类场景中, 从总体精度(OA)、 平均精度(AA)和kappa系数(k)三个方面以评估其分类性能。 为了更直观展示模型性能, 表1统计了场景E、 F中各个物质的分类结果。 同时图7展示了基于测试样本数量的分类可视化结果及混淆矩阵。 在直推式分类场景中, 本算法在基本框架场景F、 模拟场景E中对不同承痕客体上的各种物质识别时, 总体精度和平均精度均高于95%, 并且Kappa系数分别达到了0.997、 0.958。 这表明该算法具有优异的分类性能和良好的泛化能力。
| 表1 本文提出的融合SENet通道注意力机制的Res18-1D网络的分类结果 Table 1 The results of the Res18-1D network with the SENet bottleneck module |
 | 图7 本文提出算法的直推式分类场景分类效果图及混淆矩阵图 (a): 基本场景F分类可视化结果; (b): 模拟场景E分类可视化结果; (c): 基本场景F分类混淆矩阵; (d): 模拟场景E分类混淆矩阵Fig.7 Classification and confusion matrix diagram of the Res18-1D (a): Classification visualization results for basic framework scenario F; (b): Classification visualization results for simulated scenario E; (c): Confusion matrix of classification results in basic framework scenario F; (d): Confusion matrix of classification results in simulated scenario E |
为了深入验证所提算法在高光谱直推式分类场景的有效性, 针对更复杂的场景E, 进一步将该模型与三种经典的卷积神经网络结构模型(1DCNN[12]、 2DCNN[13]、 3DCNN[14])、 RNN循环神经网络[15]、 Hybrid CNN进行对比, 对比结果如表2所示, 各个算法的可视化结果如图8所示。
| 表2 直推式分类场景本文算法与其他算法的对比 Table 2 Comparison of the algorithm proposed in this paper with other algorithms in transductive classification scene |
 | 图8 直推式分类场景下各算法的分类效果图 (a): 本算法; (b): 1DCNN; (c): 2DCNN; (d): 3DCNN; (e): RNN; (f): Hybrid CNNFig.8 Classification diagrams of each algorithm in the transductive classification scenario (a): Our algorithm; (b): 1DCNN; (c): 2DCNN; (d): 3DCNN; (e): RNN; (f): Hybrid CNN |
由此可见, 本文提出的融合SENet通道注意力机制的Res18-1D网络展现出最优的识别性能: 其总体精度、 平均精度和Kappa系数分别为96.8%、 97.6%和0.958, 均显著领先于其他算法。 相较于当前最优方法(Hybrid CNN[7]), 本算法在总体精度、 平均精度和Kappa系数上分别提升了1.2%、 2.9%和0.013。 此外, 实验结果表明, 该算法仅需利用5%的像素点即可实现对血迹及类血迹物质的精准识别, 显著降低了对样本数量的依赖。
在高光谱归纳式分类任务中, 首先基于Blood Detection数据集的基本框架场景F学习血迹及类血迹物质的特征, 随后将提取的特征迁移至模拟场景E进行分类验证。 本文所提算法与其他对比方法的性能评估结果如表3所示, 分类效果的可视化展示如图9所示。
| 表3 归纳式分类场景中本算法与其他算法的对比 Table 3 Comparison of the algorithm proposed in this paper with other algorithms in inductive classification scene |
 | 图9 归纳式分类场景各算法的分类效果图 (a): 本算法; (b): 1DCNN; (c): 2DCNN; (d): 3DCNN; (e): RNNFig.9 Classification diagrams of each algorithm in the inductive classification scenario (a): Our algorithm; (b): 1DCNN; (c): 2DCNN; (d): 3DCNN; (e): RNN |
实验结果表明, 在归纳式分类场景下, 本算法在总体精度(63.3%)、 平均精度(65.0%)和Kappa系数(0.564)上均优于其他方法, 保持了最优性能。 相较于当前最优方法(RNN[15]), 本算法在总体精度、 平均精度和Kappa系数上分别提升了2.2个百分点、 1.6个百分点和0.026。 此外, 实验验证了基于场景F进行预训练的有效性: 即使在复杂承痕客体的干扰下, 本算法仍能准确检测血迹并实现类血迹物质的分类区分。 为了进一步分析归纳式实验场景中的错误来源, 本统计并分析了归纳式场景下本算法在模拟场景E中各物质的分类结果, 如表4所示。
| 表4 归纳式分类场景中本算法识别精度分析 Table 4 Analysis of the prediction accuracy of the algorithm proposed in this paper in inductive classification scene |
由此可知, 在归纳式分类场景中, 番茄汁对血迹、 番茄酱、 人造血液及海报颜料的分类结果影响显著。 例如, 在血迹识别任务中, 包含番茄汁样本时的整体识别精度仅为58.9%; 剔除番茄汁样本后, 血迹识别精度则提升至86.3%。 分类精度较低的番茄酱和人造血液也呈现类似规律, 而其余三类物质的分类正确率相对较高。 造成此现象的主要原因是番茄汁富含番茄红素, 其光谱特征与血液较为相似: 文献[16]指出, 番茄红素在470 nm波段附近存在强吸收峰, 与血红蛋白在415 nm的吸收峰位置相近。 叠加多种背景干扰后, 易导致番茄汁在血迹和人造血液样本中被误判。 同时, 番茄酱成分与番茄汁接近, 故番茄酱样本中番茄汁的误分类率也较高。 上述因素共同作用, 显著降低了归纳式分类场景的总体精度和平均精度。 由此可见, 在实际应用中需特别关注番茄汁对血迹识别的干扰。
为了评估SENet通道注意力机制模块对Res18-1D网络模型性能, 并验证改进后的双分支SENet模块的有效性, 设计了消融实验。 在保持训练参数一致的前提下, 对比了以下三种Res18-1D模型变体: 无SENet模块、 集成基础SENet模块、 集成改进型SENet模块。 在直推式分类的模拟场景E和归纳式分类场景中进行了测试。 实验结果如表5所示。
| 表5 不同SENet通道注意力机制对实验结果的影响 Table 5 Ablation experimental results of SENet bottleneck module |
从表5中可以看出, 在模拟场景E的分类任务中, 引入SENet通道注意力机制提升了Res18-1D模型的性能。 尤其是在归纳式分类场景, 相较于无注意力模块的基准模型, 集成基础SENet模块显著提高了分类性能: 总体精度、 平均精度和Kappa系数分别提升了3.4%、 4.1%和0.041。 同时, 相较于基础SENet模块, 改进后的双分支SENet模块在归纳式场景(F→ E)中进一步提升了模型性能, 总体精度、 平均精度和Kappa系数分别提升了1.0%、 0.6%和0.011。 消融实验结果表明, 改进后的双分支SENet通道注意力机制模块通过多分支结构优化了高光谱数据的特征表达, 全局最值池化(GAP)和全局平均池化(GMP)能够让模型从不同统计视角提取高光谱特征。 该改进模块与残差结构“ 短路连接” 方式相互结合, 实现了高光谱多尺度特征的互补增强, 从而提升了模型在复杂迁移场景下的泛化能力。
采用的深层残差结构和SENet通道注意力机制在一定程度上增加了神经网络的参数量。 为了进一步探究这两种结构对模型性能的影响, 对不同算法的参数量、 浮点运算数(FLOPs)以及直推式分类场景下的训练和识别时长进行了统计, 如表6所示。
| 表6 不同算法参数量、 浮点运算数(FLOPs)及特定场景下训练和测试时长 Table 6 The number of parameters, FLOPs, and the training and testing duration in specific scenarios of different algorithms |
由于采用了18层的深层神经网络结构, 本模型的参数量显著高于其他算法。 例如, 基础的Res18-1D残差网络的参数量(3 847 k)是3层2DCNN[13](34 k)的113倍, 其FLOPs(21.6MLOPs)是3层1DCNN[12](0.1 MLOPs)的216倍。 然而, 得益于残差块的恒等映射(短路连接), 梯度在残差块中的传播效率得到提升, 从而优化了模型性能。 因此, 基础的Res18-1D网络平均每轮训练时长(32 ms)仅为1DCNN[12](10 ms)的3.2倍, 且两者均处于毫秒级。 改进型双分支SENet模块使原始Res18-1D网络的参数量增加59%(达到6 116 k), 但训练复杂度并未显著提高, 平均每轮训练时长仅从32 ms增加到45 ms(增量13 ms), 处于可接受范围内。 基于数据对比分析可知, 在深层神经网络中, 残差结构相较于全连接神经网络能显著降低计算开销并提升模型性能。
提出了一种基于高光谱成像和融合SENet通道注意力机制残差网络的血迹识别模型。 为应对承痕客体的复杂性, 将传统SENet通道注意力机制模块重构为双分支瓶颈模型。 为验证模型在公安实战复杂多变环境下的适用性, 在包含多种承痕客体的公开数据集Blood Detection数据集上进行了两组实验。 实验结果表明: 在直推式分类场景的模拟场景E中, 总体精度(OA)、 平均精度(AA)和Kappa系数分别到达96.8%、 97.6%和0.958; 在归纳式分类场景中, 总体精度(OA)、 平均精度(AA)和Kappa系数分别达到63.3%、 65%和0.564。 上述结果均超越了当前基于高光谱成像的血迹识别领域的最先进方法。 然而, 在无标签标注的归纳式分类场景中, 受限于所采用公开数据集的多样性和规模, 模型在更复杂、 多样化的承痕客体上泛化能力面临挑战。 因此, 未来工作需在更多样化的承痕客体上扩充实验数据, 并持续优化算法, 旨在提升无标注归纳式场景下的识别精度、 降低训练成本, 从而进一步提高血迹识别的泛化性能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|