








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向太空尘埃有机物的激光热解光谱探测与定性定量分析
[吴义健1, 4  , 徐卫明
, 徐卫明1, 2, 4, * , 许学森1, 4, * , 李鲁宁2, 4 , 吕文浩1, 4 , 鄢朋朋2 , 舒嵘1, 2, 3, 4 ]
, 徐卫明, 许学森, 李鲁宁|
|


作者简介: 吴义健, 2000年生, 国科大杭州高等研究院物理与光电工程学院硕士研究生 e-mail: wuyijian22@mails.ucas.ac.cn
太空微小星体中痕量有机物的探测对研究生命起源具有重要意义, 然而传统光谱技术难以一次性激发并释放样本中所有有机物进行全面检测。 特别是对于弥散分布的有机物, 往往难以有效捕捉其信号, 导致其在复杂基质中的检测受到限制。 针对这一问题, 提出一种激光热解-傅里叶变换红外光谱(LP-FTIR)结合机器学习的分析方法, 旨在为深空探测生命痕迹识别提供新的技术方案。 首先制备了含6种典型生命相关有机分子(甘氨酸、 硬脂酸、 胞嘧啶核苷、 核糖、 脱氧核糖以及大豆卵磷脂)的太空尘埃模拟样品。 利用小型化LP-FTIR探测平台, 获取热解气体的红外光谱数据。 在定性分析中, 开发了融合支持向量机(SVM)、 随机森林(RF)、 极限梯度提升(XGBoost)、 循环神经网络(RNN)和反向传播网络(BPNN)的多模型融合分类算法, 结合贝叶斯优化进行超参数调优, 最后通过多数投票机制集成预测结果。 定量分析方面, 创新性地设计了一维卷积神经网络(CNN)结合多头注意力机制的回归模型, 利用分段池化锁定关键波段以提升特征提取能力。 研究结果表明, 多模型融合分类方法在六类有机物识别中准确率达90%, 较最优单模型(BPNN 87%)提升显著。 改进的注意力CNN对甘氨酸的预测决定系数 R2达0.979, 均方根误差(RMSE)为0.21 mg, 较传统偏最小二乘回归(PLSR, R2=0.969)和基础CNN模型( R2=0.891)性能提升显著。
, XU Wei-ming, XU Xue-sen, LI Lu-ningDetecting trace organic compounds in deep-space minor celestial bodies is crucial for understanding the origins of life. However, conventional spectroscopic techniques often struggle to simultaneously excite and release all the organic compounds in the sample for comprehensive detection. This is particularly challenging for organic compounds that are diffusely distributed, as their signals are often difficult to capture effectively, leading to limitations in detection within complex matrices. To address this challenge, this study proposes a novel analytical approach that combines laser pyrolysis-Fourier transform infrared spectroscopy (LP-FTIR) with machine learning, establishing a high-precision method for both qualitative and quantitative detection of organic compounds in space dust. This work aims to provide a new technical solution for identifying potential biosignatures in deep-space exploration. First, simulated space dust samples containing six typical life-related organic molecules glycine, stearic acid, cytidine nucleoside, ribose, deoxyribose, and soybean lecithin were prepared. Infrared spectral data of pyrolysis gases were obtained using a miniaturized LP-FTIR detection platform. For qualitative analysis, a multi-model ensemble classification algorithm was developed, integrating SVM, RF, XGBoost, RNN, and BPNN, with hyper parameters tuned using Bayesian optimization. Predictions were integrated through a majority voting mechanism. For quantitative analysis, a novel regression model was crafted by integrating a one-dimensional CNN with a multi-head attention mechanism, employing segmented pooling to pinpoint critical spectral regions and improve feature extraction efficiency. The study results indicate that the multi-model ensemble classification method achieved a 90% accuracy rate in identifying six types of organic compounds, representing a significant improvement over the best single model (BPNN at 87%). The improved attention-based CNN achieved a coefficient of determination ( R2) of 0.979 and a root mean square error (RMSE) of 0.21 mg in predicting glycine content, showing significant performance enhancement over traditional PLSR ( R2=0.969) and the basic CNN model ( R2=0.891).
近地轨道行星际尘埃粒子主要源自小天体(如行星、 彗星)的碰撞、 碎裂及挥发物蒸发, 并通过太阳风或流星活动迁移至地球近地轨道[1]。 降落至地球表面的陨石和彗星中携带了丰富的有机物, 大量有机碳可能通过陨石、 彗星或太空尘埃等途径传输至地球[2], 但穿越大气层时因高温氧化分解, 仅极少部分能够保存下来[3, 4]。 微陨石进入大气后经历加热、 蒸发和熔化, 导致其来源难以确定; 落到地表后, 还可能受天气和环境影响而风化或污染[5]。 因此, 通过原位探测直接获取未经大气侵蚀且保留原始挥发性有机化合物和矿物质成分的颗粒样品, 对于研究地球生命起源具有重要意义。
国际上已多次开展针对月球、 火星、 小行星等天体的遥感探测、 原位测量及采样返回任务[6, 7, 8, 9, 10]。 1969年默奇森陨石的发现揭示了地外氨基酸的存在[11], 为生命起源的外源假说提供了关键证据。 1999年NASA星尘号探测器成功采集Wild2彗星尘埃样本, 首次获得未受地球污染的地外有机物数据[12]; 日本隼鸟号探测器对小行星Itokawa的采样分析进一步证实了太空尘埃中矿物与微量有机物的共存[13, 14]。 此外, Tanpopo计划通过国际空间站暴露实验研究了微生物和有机分子在太空环境中的生存与迁移规律[15, 16]。 我国亦规划了主带彗星探测任务, 旨在通过尘埃分析仪实现原位成分检测[17]。 这些研究揭示了太空尘埃作为生命前体物质载体的重要意义, 但由于样品返回技术复杂, 原位探测技术仍存在较大挑战。
尽管实验室条件下的光谱仪分辨率与灵敏度均可做到较高水平, 但在深空探测环境中受到设备体积、 功耗及实时性等限制, 难以部署复杂的大型光谱系统。 传统方法在信噪比较低时也容易受背景干扰, 导致弱信号难以识别。 可见/红外成像光谱仪和激光诱导击穿光谱虽能分析表层成分, 但对包裹在矿物基质内部或深层裂隙中的有机物无法穿透检测, 如火星岩石中的蒙脱石夹层可能完全遮蔽内部有机物信号[18]。 拉曼光谱对浓度低于0.1%的有机分子敏感度不足[19], X射线荧光光谱对轻元素(C、 H、 O)的检测效率低。 有机物总量即使达ppm级, 若分布呈弥散而非富集状态, 也可能被背景噪声掩盖。 Greenwood等[20]首次将激光热解与气相色谱-质谱(GC-MS)结合, 实现了岩石样品中微量有机物的精准分析; Bodzay等[21]开发激光热解-傅里叶变换红外光谱(Fourier transform infrared spectrometer, FTIR)联用系统, 成功监测了聚合物热解气体的实时释放。 由此可见, 激光热解技术能够将矿物中包裹的有机物快速分解释放, 结合高灵敏度的气体光谱探测手段, 可实现低浓度有机物的高效检测, 且无需复杂样品预处理, 更适合空间环境应用。
本文将激光热解与FTIR联用, 并结合机器学习实现对原始样品中所含有机物的分类与定量回归分析。 基于此目标, 选用了与生命信息强相关的有机物成分制作含有机物的太空尘埃模拟样品。 然后开展太空尘埃模拟样品的热解探测实验, 采用机器学习算法通过所采集的光谱数据实现对原始样品中所含有机物的分类, 最后利用深度学习模型学习光谱数据特征, 以实现对原始样品中有机物含量的定量回归。
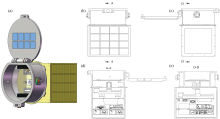
针对太空尘埃有机物原位探测问题, 设计了如图1所示的空间环境下原位探测装置。 装置包括热解舱与电子学箱, 前端盖板镶嵌二氧化硅气凝胶捕获尘埃, 后端通过透明窗连接电子学箱, 以传输热解产生的挥发性气体。 电子学箱内集成了微距放大相机、 红外激光单元、 红外测温相机以及双光梳光谱单元等关键检测元件, 并由主控单元进行统一调控。 进而可以实现: 通过气凝胶板在迎风面捕获漂浮在太空中的碳质微陨石或彗星尘埃; 利用红外激光单元对捕获样品进行精确加热让有机物受热分解; 采用高精度光谱探测技术对热解产物进行高精度光谱采集, 并通过内置反演模型实现有机物成分的定性与定量分析。
 | 图1 太空尘埃探测装置示意图 (a): 模型轴测图; (b): 主视图; (c): 右视图; (d): A-A剖面图; (e): D-D剖面图Fig.1 Schematic diagram of the space dust detection device (a): Isometric view of the model; (b): Front elevation; (c): Right side elevation; (d): Section A-A; (e): Section D-D |
在地面实验室中, 构建了一套去除尘埃捕获结构的简化激光热解— 光谱分析系统。 将激光热解平台、 FTIR光谱仪与氮气系统联用(图2), 搭建了所示的激光热解— 傅里叶变换红外光谱气体探测系统(laser pyrolysis-Fourier transform infrared spectrometer, LP-FTIR), 在惰性气氛下对含有机物的太空尘埃模拟样品进行激光照射加热, 并实时监测其释放的气相产物。
 | 图2 LP-FTIR探测系统示意图Fig.2 Laser pyrolysis-Fourier transform infrared spectrometer diagram |
实验系统核心模块包括FTIR光谱仪(气体成分检测)、 自制激光热解平台(可控热解)及高纯氮气供应系统(惰性氛围), 确保热解产物的无损传输与实时监测。 实验过程中, 氮气作为载气, 将热解过程产生的挥发性产物输送至光谱仪检测区, 最后由光谱仪排气口排出。
所选用的FTIR光谱仪为赛默飞公司的Antaris IGS Analyzer。 波数范围覆盖6 000~370 cm-1, 光谱分辨率0.5 cm-1, 最高扫描速度为2次· s-1, 检测限0.01 ppm。 本次实验中, 设置波数范围为4 000~600 cm-1, 光谱分辨率2 cm-1, 扫描速度2次· s-1。 自制激光热解平台如图3所示, 平台采用三维框架结构, 配备XY直线位移模组, 集成激光输出模块、 图像采集相机及反应舱等关键组件。 准直输出头通过光纤与1 064 nm激光器相连, 光纤准直器后输出功率1.6 W, 光斑直径约为4 mm, 功率稳定性优于97%, 并且支持外部TTL信号调制。
 | 图3 激光热解平台结构图 (a): 整体装配图; (b): 爆炸示意图Fig.3 Laser pyrolysis platform structural diagram (a): Overall assembly diagram; (b): Exploded view |
实验前, 使用高纯度氮气以恒定流速冲洗系统10 min, 保持系统内部处于惰性环境, 避免外界环境气体的干扰。 通过摄像头定位石英槽中的样品位置后, 开启激光器与测温相机, 使样品在1 min内升温至500 ℃并稳定维持3 min。 光谱测量阶段, 整个系统置于恒温22 ℃, 相对湿度40%~50%的实验环境下, 并全程保持激光热解反应舱在常压下运行。 热解过程中, 光谱仪以1 cm-1分辨率(4 000~600 cm-1范围)连续采集气体吸收光谱, 同步记录时间与温度数据。
为模拟太空尘埃的有机物-无机物相互作用, 选用甘氨酸、 大豆卵磷脂等6种典型有机分子(表1)与硅酸盐混合制备样品。 所选有机物均为太空尘埃中常见组分, 硅酸盐基质则复现了实际尘埃的热物理与化学特性。
| 表1 用于制备含有机物太空尘埃模拟样品的原材料 Table 1 Raw materials used to prepare space dust analogs containing organic compounds |
所选有机物(甘氨酸、 大豆卵磷脂等)及无机物(蒙脱石、 橄榄石)均具有太空环境代表性(表1)。 甘氨酸模拟原始行星有机化学过程[22]; 大豆卵磷脂可研究细胞膜形成[23]; 核酸相关分子(如D-核糖)适用于RNA世界假说验证[24]; 硬脂酸及其分解产物有助于探讨有机-无机界面作用[25]。 无机物中, 蒙脱石的层状结构利于催化[26], 橄榄石则常见于陨石[27]。
将上述有机物分别与硅酸盐(橄榄石∶ 蒙脱石=3∶ 2)混合, 制备不同浓度的模拟样品。 其中, 除甘氨酸外的其余样品设5%和10%两个浓度; 甘氨酸则按0.5%~24.5%梯度 (间隔1.5%)制备。 具体步骤: 有机物经行星球磨仪(100 rpm, 10 min)低温研磨; 按比例称量后振荡混匀, 详见表2。 LP-FTIR实验后, 经筛选获得有效光谱数据: 非甘氨酸样品(5%、 10%浓度)共210条/类; 甘氨酸样品(17个浓度梯度)185条/样品。
| 表2 制备出的含有机物太空尘埃模拟样品详情 Table 2 The details of the prepared space dust analog samples containing organic compounds |
1.3.1 多模型融合的分类方法
光谱分析中, 数据处理通常包含基线校正、 降噪、 归一化及降维等步骤, 以消除仪器漂移和环境干扰, 增强特征有效性。 传统基线校正法如多项式拟合等, 易产生拟合偏差, 特征选择依赖经验。 并且, 在定性分类方法中常使用的支持向量机(support vector machine, SVM)、 随机森林(random forest, RF)或循环神经网络(recurrent neural network, RNN)等机器学习模型, 由于光谱数据的高维和复杂性, 单一模型往往难以全面捕捉数据的全局与局部特征, 且易因参数调节不足而导致过拟合或泛化性能下降。
针对上述问题, 本文首先采用了一种自适应迭代加权惩罚最小二乘法(adaptive iteratively reweighted penalized least squares, airPLS)的去基线算法[28], 通过自适应权重调整, 精准去除基线干扰并保留真实信号。 而后利用Min-Max归一化处理基线校正后的光谱, 将光谱强度缩放到[0, 1]以消除量纲差异。 最终得到如图4所示的六类样品的光谱。 在此基础上, 采用主成分分析[29](principal component analysis, PCA)对数据进行降维, 选取累计贡献率达87%的前15个主成分。 实验采集FTIR数据波数范围为4 000~600 cm-1, 分辨率为2 cm-1, 共1 700个波数点。 经PCA降维后, 数据矩阵由(1 260, 1 700)降至(1 260, 15)。
 | 图4 六类样品经预处理的LP-FTIR光谱 (a): 含2-脱氧-D-核糖样品; (b): 含甘氨酸样品; (c): 含大豆卵磷脂样品; (d): 含胞嘧啶核苷样品; (e): 含D-核糖样品; (f): 含硬脂酸样品Fig.4 Preprocessed spectra obtained from LP-FTIR experiments for six types of samples (a): Sample containing 2-deoxy-D-ribose; (b): Sample containing glycine; (c): Sample containing soybean lecithin; (d): Sample containing cytidine nucleoside; (e): Sample containing D-ribose; (f): Sample containing stearic acid |
各样品热解产物的FTIR特征峰位相近, 但峰强比例差异显著。 所有样品均释放H2O(H— O— H弯曲振动~1 600 cm-1; O— H伸缩振动3 500~3 700 cm-1)、 CO2(非对称拉伸振动2 300~2 400 cm-1)及烷烃(C— H伸缩振动2 800~3 000 cm-1)。 甘氨酸与胞嘧啶核苷释放NH3(N— H伸缩振动3 300~3 500 cm-1), 表明含氮特性; 2-脱氧-D-核糖、 D-核糖与硬脂酸出现羰基化合物(C═O伸缩振动1 700~1 800 cm-1)。 甘氨酸独有CO(C≡ O伸缩振动2 100~2 200 cm-1)和羧酸(RCOOH 1 630~1 750 cm-1); 胞嘧啶核苷与硬脂酸含C— O伸缩振动(1 000~1 300 cm-1); D-核糖与硬脂酸特异性释放CH4(C— H伸缩振动2 800~3 000 cm-1)。
对于前述内容中经LP-FTIR实验测得的六类样品的光谱数据, 经预处理后, 构建了多模型融合判据的定性分类方法。 该框架集成了SVM、 RF、 极限梯度提升树(extreme gradient boosting, XGBoost)、 RNN和反向传播神经网络(backpropagation neural network, BPNN)五种分类模型。 传统机器学习模型(SVM、 RF、 XGBoost)适于刻画整体分布特征, 而深度学习模型(RNN、 BPNN)则擅长挖掘光谱数据中复杂的非线性模式。 融合这几类模型的优势, 采用多数投票机制集成各模型的预测结果, 可有效降低单一模型误判对整体的影响, 提升分类的稳健性和准确率。
为充分发挥各模型的性能, 本文采用贝叶斯优化策略对模型超参数进行调优。 基于Optuna框架[30]的贝叶斯优化算法对超参数空间进行全局搜索: 如调整SVM的正则化系数和核函数参数、 RF的决策树数量和深度、 XGBoost的学习率和树深度, 以及RNN和BPNN的隐层单元数、 层数、 学习率等。 最终, 在测试集上评估模型性能, 十折交叉验证测试模型稳定性。 整体流程如图5所示。
 | 图5 五种模型融合分类算法示意图Fig.5 Schematic diagram of five ensemble classification algorithms |
1.3.2 基于注意力机制的CNN定量分析方法
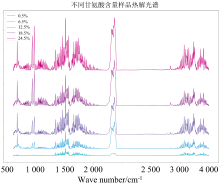
LP-FTIR实验获得了甘氨酸-硅酸盐样品, 从0.5%甘胺酸浓度到24.5%, 步长为1.5%的共计17个不同浓度的样品光谱, 每个浓度185个有效光谱。 图6所示五种甘氨酸浓度的LP-FTIR光谱, 随甘氨酸浓度的上升, 谱峰有着较为明显的强度增强。 在N— H弯曲振动的1 500~1 650 cm-1, 水分子弯曲振动的1 650~1 750 cm-1左右以及CO2伸缩振动的2 300~2 400 cm-1的这几个与甘氨酸热解成分强相关的波数区间, 随着甘氨酸含量的上升, 谱峰强度也近似同比例的增加。
 | 图6 不同甘氨酸含量样品的LP-FTIR光谱吸收峰对比Fig.6 Comparison of LP-FTIR spectral absorption peaks in samples with different glycine contents |
因此, 不同甘氨酸浓度的样品间, 以不同甘氨酸的含量与谱峰强度的比例关系来建立回归模型, 便可通过LP-FTIR光谱直接预测原始样品中含有多少甘氨酸成分。 每个原始样品中所含甘氨酸质量如表3所示, 在后续的定量模型的训练中, 样品中所含甘氨酸的质量将作为标签。
| 表3 不同甘氨酸含量样品的实验所用质量与所含甘氨酸质量 Table 3 The mass of the samples used in the experiment with different glycine contents and the corresponding mass of glycine included in each sample |
原始光谱数据采用airPLS基线校正, 消除基线偏移对定量建模的干扰。 并采用Z-score标准化处理光谱数据, 消除不同波数点的量纲差异和强度波动。 标准化后数据分布紧凑, 有利于梯度均匀更新, 避免模型对高幅值波段的过关注。 处理后数据集维度为3 145× 3 400, 对应3 145条4 000~ 600 cm-1范围的光谱(分辨率1 cm-1)。
在光谱定量分析建模方面, 常用方法包括偏最小二乘回归(partial least squares regression, PLSR)、 XGB以及卷积神经网络(convolutional neural network, CNN)等。 PLSR利用线性潜变量对光谱进行回归建模, 具有模型简单、 对小样本和噪声较为稳健的优点, 但因假设关系近似线性, 难以刻画光谱中复杂的非线性特征; XGBR通过集成多棵决策树来捕捉非线性关系, 通常能取得较高的预测精度, 但模型参数调节复杂, 且未针对连续光谱波段的相关性进行特殊设计; 基本一维CNN可从原始光谱中自动学习多层次特征表示, 对谱峰等局部结构较敏感, 但若无附加机制引导, CNN可能无法充分关注最具分析意义的波段, 并且在样本数量有限时容易出现过拟合。
针对上述不足, 设计了一种融合注意力机制的一维CNN定量分析模型。 通过设计一个可学习的注意力权重矩阵, 使得模型在处理整个光谱数据时能够自动分配各波段的重要性, 并在后续的卷积和分段池化中将这种关注进一步转化为局部特征。 其网络结构如图7所示。
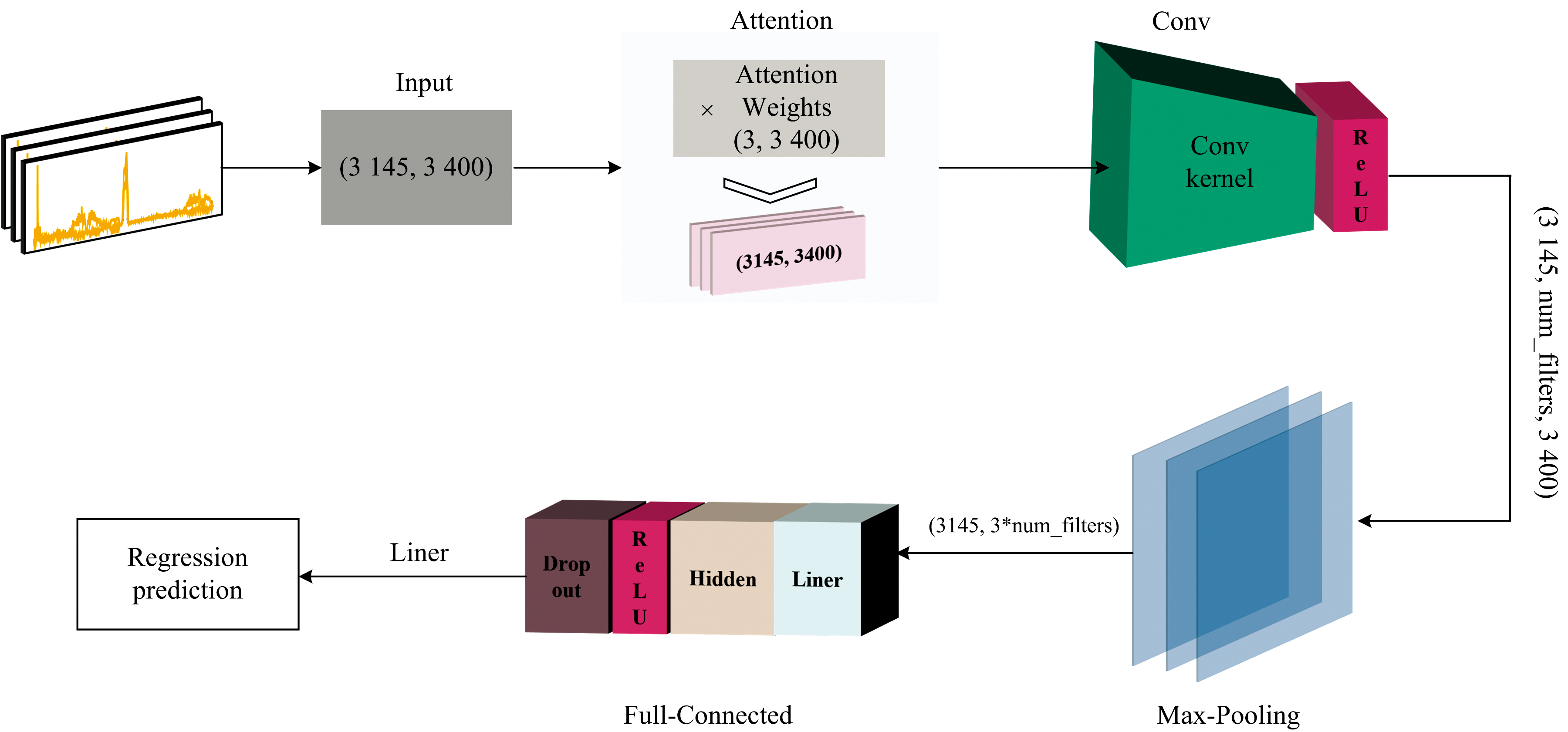 | 图7 引入注意力机制的CNN模型结构示意图Fig.7 Schematic diagram of CNN incorporating attention mechanism |
初始化阶段定义(3, 3 400)的注意力头矩阵。 每个注意力头通过softplus函数生成非负权重, 与输入光谱逐元素相乘以提取波段信息。 将这三个注意力头输出扩展维度并合并, 形成(3 145, 3, 3 400)的多通道光谱数据, 以刻画不同头对波段的关注模式。 随后, 将多通道数据输入一维卷积层。 卷积核参数(核数与大小)通过贝叶斯优化确定, 各卷积核通过局部滑动滤波提取光谱细节, 经ReLU激活后得到局部特征图, 形状为(3 145, num_filters, 3 400)。 卷积后, 通过分段最大池化操作进一步聚焦三个关键波数区间[1 500~1 650]、 [1 650~1 750]、 [2 300~2 400] cm-1, 对应甘氨酸的特征谱段。 每个波段执行最大池化, 提取该区间内最具代表性的响应, 形成三个维度为(3 145, num_filters)的特征向量, 并将其拼接为综合特征向量(3 145, 3× num_filters), 作为回归分析的输入。 随后, 通过全连接网络对综合特征向量进一步非线性映射与维度转换, 加入Dropout防止过拟合, 最终输出甘氨酸含量的回归预测值。 反向传播时, 计算预测与真实标签的MSE损失, 配合注意力权重的L1正则项优化模型参数。 误差经由全连接层、 分段池化层逐层回传至卷积层, 最后到达多头注意力模块。 分段池化的特征筛选机制确保梯度仅更新贡献显著的关键波段, 促使注意力模块自动聚焦于有效波段, 持续优化预测效果。
这种设计既利用了注意力机制对全局信息的自适应加权, 又通过分段池化将模型的注意力锁定在预先确定的最关键的波数段上, 二者在训练过程中协同作用, 共同推动模型在反向传播时调整各个注意力头的权重, 最终实现对目标变量预测精度的提升。 采用决定系数(R2)、 均方根误差(RMSE)与平均绝对误差(MAE)来评估模型的性能, 如式(1)— 式(3)所示
$R^{2}=1-\frac{\displaystyle\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}}{\displaystyle\sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2}}=1-\frac{\mathrm{SS}_{\mathrm{res}}}{\mathrm{SS}_{\mathrm{tot}}}$(1)
$\mathrm{MSE}=\frac{1}{n} \displaystyle\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}, \mathrm{RMSE}=\sqrt{\mathrm{MSE}}$(2)
$\mathrm{MAE}=\frac{1}{n} \displaystyle\sum_{i=1}^{n}\left|y_{i}-\hat{y}_{i}\right|$(3)
完成各模型基于贝叶斯优化算法的超参数搜索后, 在测试集上评估模型在各样品光谱上的分类性能, 采用精确率、 召回率、 F1值和准确率这四个指标, 如表4所示, 混淆矩阵如图8。
| 表4 各模型经超参数优化后在测试集上的评估结果 Table 4 Evaluation results of each model on test set after hyperparameter optimization |
 | 图8 各模型的混淆矩阵 (a): SVM; (b): RF; (c): XGBoost; (d): RNN; (e): BPNN; (f): 多模型融合Fig.8 Confusion matrices for each model (a): SVM; (b): RF; (c): XGBoost; (d): RNN; (e): BPNN; (f): Multiple models |
SVM准确率0.85, 其中D-核糖召回率最高(0.93), 但胞嘧啶核苷最低(0.74)。 混淆集中在2-脱氧-D核糖与胞嘧啶核苷, 甘氨酸与卵磷脂识别效果较差。 RF准确率0.86, 改善了胞嘧啶核苷识别问题, 但甘氨酸与胞嘧啶核苷仍有混淆。 XGBoost在测试集上准确率为0.85, 在含D-核糖样品的识别率最高, 召回率达0.93, 但在含2-脱氧-D-核糖样品与含胞嘧啶核苷的样品上略有不足。 混淆矩阵可见含D-核糖样品与含胞嘧啶核苷样品间有少量误判。 RNN测试集准确率为0.87, 虽略低于RF与XGBoost, 但其在含2-脱氧-D-核糖样品和含D-核糖样品上表现较好, 召回率高。 从混淆矩阵可见, 仍然存在部分含胞嘧啶核苷样品被误判到了含甘氨酸样品一类。 训练/验证损失曲线平稳收敛, 准确率曲线趋势一致, 训练略高于验证, 表明dropout和早停有效抑制了过拟合。
BPNN在测试集上准确率为0.87, 对于各类别具有较为均衡的识别能力。 与RNN类似, 在含胞嘧啶核苷样品的分类上仍易混淆。 其混淆矩阵也反映出在含卵磷脂、 甘氨酸和胞嘧啶核苷的样品间有少量错分。 BPNN在训练与验证阶段的损失曲线和准确率曲线显示出了平滑收敛的过程。 训练准确率略高于验证准确率, 但整体差距较小, 说明在超参数优化后得到了合理的网络结构与超参数。 随着训练轮次的增多, 模型过拟合风险虽有所上升, 但因及时引入早停机制, 整体性能依然保持稳定。
SVM模型虽对高维小样本数据表现优异, 但其分类性能受核函数与正则参数影响显著, 且对噪声敏感。 RF模型泛化能力强、 参数调优简单, 对光谱预处理要求低, 但在处理不平衡数据时表现不佳, 分类边界不够精细, 模型解释性较弱。 XGBoost模型非线性拟合能力强, 内置正则化有效防止过拟合, 计算效率高, 但同样对噪声和异常值敏感, 模型可解释性低。 RNN模型善于捕捉光谱数据的局部特征和顺序信息, 输入长度灵活, 在识别D-核糖和2-脱氧-D-核糖等样品时表现突出, 但存在单次迭代耗时较长, 深层模型训练困难, 容易产生过拟合的情况。 BPNN模型参数共享程度高, 能较好地学习全局特征, 对各类适应性相对均衡, 但其性能依赖于网络结构与初始参数, 易出现过拟合, 并存在模型黑箱的问题。
在2 000~3 000 cm-1的光谱区间, 六类典型有机物的谱峰存在明显重叠, 主要来自烷烃类C— H伸缩振动(2 800~3 000 cm-1), 部分羧酸类分子的倍频吸收也位于该区间。 这种重叠降低了单一特征峰的区分度, 例如硬脂酸与D-核糖在此区间信号高度相似, 而胞嘧啶核苷的弱峰则容易被掩盖, 导致分类模型在这几类样品间产生一定混淆。 为降低该干扰对后续分析的影响, 本研究在光谱预处理与模型构建中采取了若干措施: 一方面, 利用PCA降维时并非单独依赖单个波段, 而是结合多主成分来综合反映不同分子在多个波段的差异性; 另一方面, 在机器学习分类模型中, 通过融合SVM、 RF、 XGBoost、 RNN和BPNN的多模型投票机制, 能够有效抵消由于单一波段混淆带来的分类偏差。 综合分析上述模型的处理结果可见, 采用多模型投票融合后, 测试集分类准确率提高至0.89, 高于单一模型表现; 特别是在D-核糖、 大豆卵磷脂和硬脂酸样品分类中效果更为明显, 也弥补了单一模型对胞嘧啶核苷样品分类的不足。 这说明, 多数投票策略有效地避免了单个模型由于过拟合或训练不足所导致的极端与偏差预测情况, 显著降低了预测错误率, 从而提升了模型整体分类的稳健性和可靠性。
最后, 将经贝叶斯优化搜索出的超参数, 带入各新模型中, 重新在完整数据集上进行十折交叉验证。 各折的准确率如下: 0.920 6、 0.912 7、 0.899 2、 0.904 8、 0.888 9、 0.881 0、 0.936 8、 0.857 1、 0.857 1和0.911 0, 十折平均准确率0.896 9。 可见该方法可以在不同的样本划分下, 可保持较高的一致性与稳定性, 为模型在实际应用的可靠性提供了有力支撑。
还需注意的是, 多模型投票集成虽然提升了分类准确率, 但也引入了一些潜在挑战。 集成五个独立模型会显著增加计算资源需求, 训练时间约为单一模型的4-5倍, 推理阶段的延迟也有增加, 这在计算能力有限的深空探测设备中可能成为瓶颈。 且模型复杂度上升可能降低整体解释性, 使追踪决策过程更困难。 实际工作中可通过模型剪枝或蒸馏等方法减少参数量, 平衡准确率与效率。 但这些局限性并不削弱方法的整体优势, 但在太空尘埃探测等实时应用中需要着重关注。
 | 图9 (a) RNN训练与验证损失曲线; (b) RNN训练与验证曲线Fig.9 (a) RNN training and validation loss curves; (b) RNN training and validation accuracy curves |
 | 图10 (a) BPNN训练与验证损失曲线; (b) BPNN训练与验证曲线Fig.10 (a) BPNN training and validation loss curves; (b) BPNN training and validation accuracy curves |
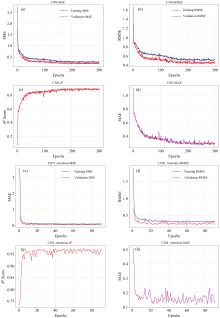
图11(a)— (h)展示了CNN和CNN-Attention的训练和验证曲线, 包括MSE、 RMSE、 MAE和R2。
 | 图11 CNN与CNN-Attention模型训练效果对比 (a): CNN MSE曲线; (b): CNN RMSE曲线; (c): CNN R2曲线; (d): CNN MAE曲线; (e): CNN-Attention MSE曲线; (f): CNN-Attention RMSE曲线; (g): CNN-Attention R2曲线; (h): CNN-Attention MAE曲线Fig.11 Comparison of training performance between CNN and CNN-Attention (a): CNN MSE curves; (b): CNN RMSE curves; (c): CNN R2 curve; (d): CNN MAE curve; (e): CNN-Attention MSE curves; (f): CNN-Attention RMSE curves; (g): CNN-Attention R2 curve; (h): CNN-Attention MAE curve |
对比CNN模型, 在引入注意力模块后, CNN-Attention模型在训练的初始阶段即可快速降低训练和验证误差, 比原始CNN更早地进入稳定收敛区间。 CNN-Attention在验证集的R2显著高于CNN, 且RMSE和MAE更低, 残差分布更集中。 两种模型在后期的训练损失与验证损失之间的差异较小, 表明Dropout、 权重衰减以及适当的注意力正则化, 有效避免了网络出现过拟合。 在最终的测试集上, 对五种模型在训练完成后进行了一次独立的预测, 如图12所示为五个模型的真实值对比预测值图以及残差分布图。 其中CNN-Attention 模型的散点分布最贴近真实值的直线, 表明其整体预测精度最高; 其余模型都不可避免地在部分区域出现偏离。 在残差图中, CNN-Attention的残差集中在± 1.0范围内, 拟合效果明显优于CNN和XGBR。
 | 图12 各模型真实值对比预测值图以及残差分布图 (a), (b): CNN-Attention; (c), (d): CNN; (e), (f): XGBR; (g), (h): PLSRFig.12 Comparison between the actual and predicted values for each model, along with the residual distribution plots (a), (b): CNN-Attention; (c), (d): CNN; (e), (f): XGBR; (g), (h): PLSR |
此外, 还计算了五个模型在测试集上RMSE指标, 分别为: CNN-Attention为0.21、 CNN为0.47、 PLSR为0.24、 XGBR为0.38。 可见CNN-Attention的RMSE指标最低, 并且相对于CNN有了大幅提升, 再一次证明引入了注意力机制的深度学习模型在光谱预测上的优势。
最后, 为衡量模型在不同数据集划分下的表现一致性与泛化能力, 进行了十折交叉验证, 记录每一折的R2与MAE(保留三位小数), 如表5所示: 从表中数据可见, CNN-Attention取得了最高的R2与最低的MAE, 且有9个折次都达到了0.97以上的拟合度。 PLSR与XGBR则维持在0.94~0.97的水平。 CNN的效果为四个模型最差。 可见引入了注意力模块并结合分段池化方法的CNN模型, 不仅拟合度和预测精度高于传统模型, 其稳定性和泛化能力一样具有优势。
| 表5 各模型十折交叉验证的R2与MAE结果 Table 5 R2 and MAE results from 10-fold cross-validation for each model |
综合上述分析, 五个模型在样品甘氨酸含量预测任务中均表现出一定的学习能力, 但在捕捉光谱复杂特征、 抑制噪声影响及保持泛化性方面存在明显差异。 PLSR模型结构简单稳健, 在有限数据下表现突出, 但受限于线性结构, 难以捕捉光谱中的非线性规律。 XGBR具有自带特征选择和抗噪防过拟合机制, 对适度非线性数据预测表现较好, 但在处理高维稀疏光谱数据时存在不足。 传统CNN模型能够自动提取复杂非线性特征, 但难以准确聚焦关键波段, 泛化能力存在局限。 相比之下, 注意力CNN通过多头注意力机制显著提升了对关键波段的关注度, 能更有效地捕捉光谱数据的内在特征, 仅需较少的训练迭代即可达到较高的预测精度, 其泛化能力也明显强于其他模型。 在验证集、 测试集及十折交叉验证中, 注意力CNN取得最高或接近最高的R2, 并且RMSE与MAE指标显著优于其他模型, 模型结构的复杂性与调参成本虽较高, 但通过充分的正则化防止过拟合, 明显提升了预测性能。 综上所述, 注意力CNN模型综合性能最为突出, 充分体现了注意力机制在复杂光谱定量任务中的优势。
为检验LP-FTIR技术在太空尘埃中典型有机物的探测性能及定性定量分析能力, 本文制备了包含甘氨酸、 硬脂酸、 胞嘧啶核苷、 核糖、 脱氧核糖和大豆卵磷脂六种典型生命相关有机分子的太空尘埃模拟样品, 通过LP-FTIR系统获取不同样品的热解气体红外光谱数据, 并构建了多模型融合分类算法和基于注意力机制的一维CNN回归模型, 分别实现对样品中有机成分的定性识别与甘氨酸含量的定量预测。 研究结果表明: (1)基于SVM、 RF、 XGBoost、 RNN和BPNN的多模型融合投票分类方法, 实现了六类典型有机物的高精度识别, 分类准确率达90%, 较最优单模型(BPNN, 87%)有显著提升, 十折交叉验证平均准确率达到89.69%。 (2)引入多头注意力机制与分段池化策略的一维CNN回归模型, 有效提取了光谱数据中与甘氨酸热解产物密切相关的关键波段特征, 实现对样品甘氨酸含量的高精度定量分析。 该模型在甘氨酸含量的回归预测中R2达到0.979, RMSE低至0.21 mg, 其性能高于传统的PLSR和基础CNN模型。 基于注意力机制的CNN模型表现出良好的稳定性与泛化能力, 各折R2均在0.967以上。
将LP-FTIR与机器学习相结合的方法, 在复杂基质条件下不仅可以有效区分不同种类的有机成分, 还能精确预测特定成分的含量。 本研究结果为深空探测任务中痕量有机物及生命痕迹的光谱探测提供了新的分析方法, 也为未来类似空间原位探测设备的研制提供了可靠的实验依据和方法指导。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|