

{kind=link}
{kind=link}
{kind=link}
{kind=link}
模糊双曲余弦判别分析的光谱分类研究
[武斌1, 2, *  , 刘富碑
, 刘富碑3 , 武小红3 ]
, 刘富碑|
|


作者简介: 武 斌, 1978年生, 滁州职业技术学院教授 e-mail: wubind2003@163.com
传统的线性判别分析(LDA)在直接处理高维的光谱数据时会出现小样本问题, 而双曲余弦判别分析方法(HCMDA)能够解决小样本问题。 为了进一步提高HCMDA的分类准确率和处理含噪声的光谱数据, 在HCMDA的基础上结合模糊集合理论和双曲余弦相似度计算提出了模糊双曲余弦判别分析算法(FHCMDA), 并建立了基于FHCMDA和K近邻(KNN)分类器的分类模型分别进行肉类中红外(MIR)光谱和苹果近红外(NIR)光谱的分类, 并与HCMDA作比较, 对比两者的分类准确率。 FHCMDA利用训练样本及其均值计算模糊隶属度, 然后计算模糊类内散射矩阵和模糊类间散射矩阵, 再计算模糊类内双曲余弦函数和模糊类间双曲余弦函数, 最后通过特征分解得到特征向量。 首先, 获取三种肉类(鸡肉、 火鸡和猪肉)样本的MIR光谱和四种苹果(红富士、 花牛、 黄蕉和加纳)样本的NIR光谱, 其中肉类每种有40个样本数据, 苹果每种有50个样本数据。 其次, 对苹果NIR光谱数据采用多元散射校正(MSC)预处理以消除由于散射水平不同带来的光谱差异, 增强其相关性。 然后确定肉类和苹果的初始聚类中心, 计算模糊隶属度。 根据计算的模糊双曲余弦函数, 分别用HCMDA和FHCMDA计算特征分解, 分别对光谱数据进行特征提取。 最后利用KNN进行分类, 得到HCMDA和FHCMDA的分类准确率并进行对比分析。 实验最终结果如下: HCMDA+KNN对肉类品种的分类准确率为90.48%, 对苹果品种的分类准确率为76.67%; FHCMDA+KNN对肉类品种的分类准确率为97.62%, 对苹果品种的分类准确率为91.67%。 以上实验结果表明, 采用模糊双曲余弦判别分析结合KNN是一种鉴别食品品种的有效方法, 且鉴别准确率明显高于HCMDA+KNN, 为食品品种的鉴别和筛选提供了一种新方法。
Traditional linear discriminant analysis (LDA) has a small sample problem when directly processing high-dimensional spectral data, while hyperbolic cosine discriminant analysis (HCMDA) can solve the small sample problem. To further improve the classification accuracy of HCMDA and process noisy spectral data, a fuzzy hyperbolic cosine discriminant analysis (FHCMDA) algorithm was proposed by combining fuzzy set theory with hyperbolic cosine similarity. Furthermore, a model based on FHCMDA and K-nearest neighbors (KNN) was built to classify meat mid-infrared (MIR) spectra and apple near-infrared (NIR) spectra, respectively, and was compared with HCMDA to contrast their classification accuracies. FHCMDA calculates the fuzzy membership values by using the training samples and their means, the fuzzy intra-class scatter matrix and the fuzzy inter-class scatter matrix, the fuzzy intra-class hyperbolic cosine function and the fuzzy inter-class hyperbolic cosine function, and the eigenvector through feature decomposition. At first, MIR spectra were obtained for three meat variaties (chicken, turkey, and pork) and NIR spectra for four apple varieties (Red Fuji, Huaniu, Huangjiao, and Jiana), with 40 samples for each meat type and 50 for each apple type. Secondly, multivariate scattering correction (MSC) was applied to preprocess the NIR spectral data of apples, eliminating spectral differences caused by varying scattering levels and enhancing their correlation. Thirdly, the initial clustering centers for meat and apple were determined, and the fuzzy membership degree of each sample was calculated. The feature decomposition was completed by HCMDA and FHCMDA, respectively, using the calculated fuzzy hyperbolic cosine function to extract features from spectral data. Finally, KNN was used for classification, and the classification accuracies of HCMDA and FHCMDA were obtained and compared. The final results of this experiment were as follows: HCMDA+KNN achieved classification accuracies of 90.48% for the meat variety and 76.67% for the apple variety. The classification accuracy of FHCMDA+KNN was 97.62% for the meat variety and 91.67% for the apple variety. The above experimental results show that fuzzy hyperbolic cosine discriminant analysis combined with KNN is an effective method for identifying food varieties, with identification accuracy significantly higher than that of HCMDA+KNN.
在鉴别食品品种及其组成成分方面, 传统的鉴别分类主要依靠人工经验和外部因素, 其可信度和准确度相对较低, 不利于对数量较大的食品进行快速、 准确的分类。 如肉类的新鲜程度和肉质组成, 有经验的人可以根据味道和口感来判断。 苹果的种类, 可以通过外观形状、 颜色、 色泽和口感等来进行判断, 但是主观性强, 效率低, 易受外部因素影响。
中红外光谱(mid-infrared spectroscopy, MIRS)是指在中红外波段(4 000~400 cm-1)内对样品进行光谱测量和分析的技术。 中红外光谱利用物质的分子振动引起的光的吸收特性, 可以提供关于样品的结构、 成分、 功能基团等信息。 中红外光谱技术可以通过监测食品中的化学成分变化, 如脂肪、 蛋白质、 糖类等, 来评估食品的新鲜程度。 通过建立针对不同食品的中红外光谱数据库和模型, 可以实现对食品新鲜度的快速、 准确的评估[1]。 例如Fattahi等[2]采用MIRS技术结合线性判别分析, 支持向量机和人工神经网络对不同品种小麦粉进行分类。 Wu等[3]通过主成分分析(principal component analysis, PCA)对白菜高维中红外光谱进行降维, 再分别利用非相关鉴别向量和模糊非相关鉴别向量对光谱数据进行特征提取。 实验结果表明, 模糊非相关鉴别向量联合MIRS是鉴定白菜上高效氯氰菊酯残留的有效方法。
近红外光谱(near-infrared spectroscopy, NIRS)是指在近红外波段(10 000~4 000 cm-1)内对样品进行光谱测量和分析的技术。 近红外光谱检测是利用物质在近红外范围内的分子振动、 组合振动和它们与近邻分子相互作用引起的光的吸收特性。 近红外光谱具有非破坏性、 快速、 多组分分析等优点, 可以通过检测食品中的化学成分和结构特征, 来实现对不同食品品种的分类和鉴别[4]。 通过构建近红外光谱数据和利用化学计量学方法, 可以实现对不同食品品种的快速、 准确的分类和鉴别。 例如刘雪松等[5]使用近红外光谱、 中红外光谱以及它们的组合和偏最小二乘回归建立定量标定分析模型, 快速测定黄芪中的主要活性成分(黄芪甲苷IV和总黄芪甲苷)。 Wang等[6]设计和开发了一个便携式可见光/近红外透射样机, 用于获取来自不同产地的苹果样品的可见光/近红外光谱, 并通过优化不同的光谱预处理和特征选择算法, 建立竞争适应加权偏最小二乘模型预测7个产地的苹果内部品质。
由于实验所用到的光谱为高维数据, 若使用线性判别分析(linear discriminant analysis, LDA)处理光谱会出现小样本问题[7], 即当样本数小于样本维数时, 样本类内散度矩阵Sw就会变得奇异, 导致LDA的执行过程中出现计算错误的问题。 为了解决小样本问题, 双曲余弦判别方法(hyperbolic cosine discriminant analysis, HCMDA)[8]引入双曲余弦函数[9], 通过将高维数据映射到低维空间, 以便更好地区分不同类别之间的差异, 具有非线性特征提取、 降维效果好、 适用范围广和稳健性强的优点。 因为光谱数据中包含有非线性特征, 所以, HCMDA适合处理光谱数据, 进行光谱数据的特征提取。 由于光谱数据中含有噪声数据, 光谱重叠等现象[10], 为了更好地处理这些问题, 本文提出模糊双曲余弦判别分析法(fuzzy hyperbolic cosine discriminant analysis, FHCMDA)。 FHCMDA是一种基于模糊隶属度和双曲余弦相似度的判别分析方法。 它在双曲余弦判别分析的基础上结合了模糊集合理论和双曲余弦相似度计算, 用于实现多类别样本的分类和判别。 FHCMDA方法为高维数据的分类和判别提供一种新的思路和方法, 而且在做红外光谱数据分析上的优越性尤为突出。 实验表明, FHCMDA+KNN方法对两类样本(肉类品种与苹果品种)均能实现快速、 准确的识别与分类, 验证了该算法在跨品类农产品光谱分析中的普适性。
本文利用傅里叶红外光谱分析仪分别采集三种肉类的中红外光谱和四种苹果的近红外光谱, 并利用多元散射校正(multiplicative scatter correction, MSC)对苹果的近红外光谱进行预处理, 然后分别用HCMDA和FHCMDA进行特征提取, 最后用KNN进行分类。 由分类结果可知, 采用模糊双曲余弦判别分析(FHCMDA)结合KNN可实现快速有效的食品品种鉴别和筛选。
鸡胸肉、 火鸡胸肉和猪排的蛋白质、 脂肪及水分含量存在显著差异, 这种差异会直接反映在近红外光谱的吸收峰位置和强度上, 如1 450 nm对应水分, 1 700 nm对应脂肪。 选择瘦肉(去骨去皮)是为了减少脂肪和结缔组织对光谱的干扰, 突出肌肉组织的主成分特征, 便于分类模型聚焦于关键波段。 这三种肉类是全球消费量最高的白肉和红肉代表, 其分类结果对食品溯源、 品质检测具有普适意义。
红富士(高糖)、 花牛(低酸)、 黄蕉(高酸)和加纳(中等糖酸比)的化学成分差异显著, 其近红外光谱在1 200 nm(糖类)和1 400 nm(有机酸)等波段存在可区分的特征峰。 四类苹果涵盖了常见口感类型(脆/绵、 甜/酸)。
从四家当地食品零售商购买了20块新鲜的鸡胸肉、 火鸡胸肉和猪排(每家店五块, 确保品牌和供应商多样性)。 所有样本(约100 g)切碎过程中去除骨头、 皮肤, 并尽量去除多余的脂肪, 只保留瘦肉[11]。 所选零售商涵盖大型连锁超市、 农贸市场及社区生鲜店, 以反映实际消费场景且统一切割方式和部位(如猪排取背最长肌), 减少个体差异对结果的影响。 而四种苹果(红富士、 花牛、 黄蕉和加纳)均从同一超市购买, 每种苹果品种有50个样本作为实验材料, 本次实验一次购买了200个苹果。 苹果样本的选择必须满足以下要求: 所选品种涵盖脆甜(红富士)、 绵软(花牛)、 酸甜(黄蕉)等不同口感类型, 代表主流消费偏好。 肉类和苹果的样本量及选取方法[12, 13]符合食品科学领域常见规范, 能够支持研究结论的普适性。 在进行近红外光谱采集之前, 实验人员擦拭了苹果表面的灰尘, 然后将苹果存放在温度为20~25 ℃、 相对湿度为50%~60%的环境中12 h[12]。
共采集并使用了两个光谱数据集, 第一个数据集是来自肉类样本的中红外光谱[13]。 肉类包含了60个独立样本的新鲜绞肉: 鸡肉、 猪肉和火鸡(每类20个), 使用衰减全反射采样的傅里叶变换红外光谱获取。 每个光谱包含了448个变量, 波数范围在1 000~1 900 cm-1。
第二个数据集是来自苹果样本[12], 包含了红富士、 花牛、 黄蕉和加纳四种类型, 是利用Antaris II NIR光谱仪获取200个苹果样本的近红外光谱。
具体的采集苹果近红外光谱的流程如下:
(1) 在采集相关数据近红外光谱数据前, 必须使光谱仪预热1 h, 使其达到稳定运行的状态;
(2) 每个品种50个样本, 波数范围在4 000~10 000 cm-1的近红外波段, 每个光谱是1 557维的数据;
(3) 保证灯光的稳定及苹果测量时放置高度的恒定;
(4) 每个苹果样品在赤道附近用光谱仪进行三次扫描, 最后的数据为三次测试结果的平均值, 最终得到检测的苹果近红外光谱数据。
检测苹果样本近红外光谱数据[12]时易受散射效应和颗粒大小差异因素影响, 发生基线漂移和幅度变化, 故采用光谱多元散射校正(MSC)对初始中红外光谱进行预处理, 经过散射校正后得到的光谱数据可以有效地消除由于散射水平不同带来的光谱差异[14], 从而增强光谱与数据之间的相关性。
步骤一, 初始化: 将光谱数据分为训练样本和测试样本。 定义双曲余弦矩阵函数
$f(A)=\cosh (A)=\frac{~\exp (A)+\exp (-A)~~~}{2}$(1)
式(1)中, A是一个方阵, f(A)是以方阵A为自变量的矩阵函数。
步骤二, 确定双曲余弦矩阵函数的特征向量[8]: 如果λ 是矩阵A的特征值, 则f(λ )是矩阵函数f(A)的特征值; 如果向量v是矩阵A属于特征值λ 的特征向量, 则向量v仍是矩阵函数f(A)属于特征值f(λ )的特征向量。
步骤三, 由双曲余弦函数f(A), 类间散度矩阵Sb, 类内散度矩阵Sw和特征值矩阵Λ w构建投影矩阵W
$J(W)=\underset{W}{\arg \max } \frac{\left|W^{\mathrm{T}} \cosh \left(\Lambda_{b}\right) W\right|~~}{\left|W^{\mathrm{T}} \cosh \left(\Lambda_{\omega}\right) W\right|~~}$(2)
步骤四, 计算最优鉴别矢量, 即矩阵
步骤五, 通过一个非线性映射, 将非线性的散度矩阵映射到一个新的特征空间, 并在新的特征空间内提取特征。
步骤一, 初始化: 将肉类和苹果的光谱数据均分为训练样本和测试样本。 模糊权重指数m和类别数c, 其中m> 1;
步骤二, 计算训练样本xk隶属于第i(1≤ i≤ c)类的初始模糊隶属度uik
$u_{i k}=\left[\displaystyle\sum_{j=1}^{c}\left(\frac{\left\|x_{k}-\bar{x}_{i}\right\|}{\left\|x_{k}-\bar{x}_{j}\right\|}\right)^{\frac{2}{m_{1}-1}}\right]^{-1}, \forall i, k$(3)
式(3)中, c为类别数; m1为权重指数; ${{\bar{x}}_{i}}$为训练样本第i类的均值, ${{\bar{x}}_{j}}$为训练样本第j类的均值;
步骤三, 计算训练样本模糊类间离散矩阵SfB, 模糊类内离散度矩阵SfW
$S_{f B}=\displaystyle\sum_{i=1}^{c} \displaystyle\sum_{k=1}^{n} u_{i k}^{m}\left(\bar{x}_{i}-\bar{x}\right)\left(\bar{x}_{i}-\bar{x}\right)^{\mathrm{T}}$(4)
$S_{f W}=\displaystyle\sum_{i=1}^{c} \displaystyle\sum_{k=1}^{n} u_{i k}^{m}\left(x_{k}-\bar{x}_{i}\right)\left(x_{k}-\bar{x}_{i}\right)^{\mathrm{T}}$(5)
式(4)和式(5)中,
步骤四, 计算模糊类内双曲余弦函数$H_{f W}=\frac{\exp \left(S_{f W}~\right)+\exp \left(-S_{f W}~\right)~~}{2}$, 模糊类间双曲余弦函数$H_{f W}=\frac{\exp \left(S_{f B}~\right)+\exp \left(-S_{f B}~\right)~~}{2}$。
步骤五, 计算特征分解:
K-最近邻法(K-nearest neighbor, KNN)是一种有监督的分类方法[15]。 从测试样本点x开始不断扩大区域直到包含进k个训练样本点为止, 并且把测试样本点x的类别归为这最近的k个训练样本点中出现频率最多的类别。 根据前面两种双曲余弦判别分析方法提取出来的特征参数, 进行判别分类, 设置K值, 分别得出双曲余弦判别和模糊双曲余弦判别的分类准确率。
主成分分析(PCA)作为模式识别领域的经典特征提取方法, PCA通过线性变换将高维光谱数据投影至低维空间, 在保留原始数据最大方差的同时, 能有效消除光谱中的冗余特征。 但是, PCA在降维过程中也会丢失分类信息。 将肉类样本和苹果样本的光谱数据分别用PCA降维到2维, 最后用最近邻分类器进行分类, 分类准确率分别为85%和90.48%。
每类肉类样本中, 训练样本数为26, 测试样本数为14; 每类苹果样本中, 训练样本数为35, 测试样本数为15。 用MSC对苹果样本的近红外光谱数据进行预处理。 接着用HCMDA和FHCMDA分别计算肉类和苹果训练样本的特征向量, 实现肉类和苹果训练样本和测试样本的特征转换。 然后用KNN法进一步判别分类, 通过设置不同的K值、 模糊权重指数值m和初始模糊权重指数m1值优化分类性能, 得到各自的分类准确率如表1和表2所示。 实验结果表明, FHCMDA在大多数情况下具有更高的分类准确率, 这是由于FHCMDA在特征提取过程中更好地处理了数据的模糊性和复杂性。 无论是肉类还是苹果的数据集, FHCMDA的准确率都比HCMDA的准确率要高, 对于肉类分类, 最佳的分类准确率在K=3, m=1, m1=2时达到, 此时FHCMDA的准确率为97.62%, 而HCMDA的准确率为85.71%。 对于苹果分类, 最佳的分类准确率在K=3, m=2, m1=2时达到, FHCMDA的准确率为91.67%, 而HCMDA的准确率为75.00%。
| 表1 HCMDA和FHCMDA对肉类的分类准确率 Table 1 The identification accuracy of HCMDA and FHCMDA on meat |
| 表2 HCMDA和FHCMDA对苹果的分类准确率 Table 2 The identification accuracy of HCMDA and FHCMDA on apple |
肉类样本和苹果样本的训练样本数和测试样本数和2.2节相同, 分别用HCMDA和FHCMDA对肉类样本和苹果样本进行特征提取, 然后再用朴素贝叶斯分类器进行分类。 苹果样本的分类准确率: HCMDA为25%, FHCMDA(m=2, m1=2)为96.67%; 肉类样本的分类准确率: HCMDA为88.10%, FHCMDA为90.48%(m=1.2, m1=2.5)。 可见, FHCMDA在2个数据集上的分类准确率均高于HCMDA。
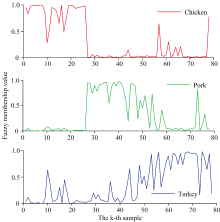
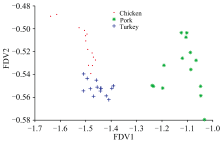
在FHCMDA算法中, 已经计算出了每个训练样本的初始模糊隶属度, 且通过实验发现FHCMDA的判别准确率较高, 所以主要利用FHCMDA和KNN对肉类和苹果进行判别分类。 模糊隶属度图展示了每个样本属于不同类别的程度, 有助于理解数据的分布情况。 图1展示了三种肉类的模糊隶属度图, 本实验有三个不同品种的肉类, 所以有三个不同的小图, 包括Chicken鸡肉, Pork猪肉, Turkey火鸡肉。 横坐标代表样本集(k-th sample代表第k个样本集), 纵坐标表示模糊隶属值。 当纵坐标值超过0.5时, 说明样本属于某类型的肉类。 在3个小图中都存在误分的样本, 比如在Chicken图中在第60和第78样本附近有大于0.5的尖峰值存在属于误分的样本。 图2展示了经过FHCMDA处理后的结果图。 其中FDV表示模糊判别向量。 从图中可以看出, FHCMDA算法能够有效地区分不同类型的肉类。 图3和图4分别展示了四种苹果的模糊隶属度图和处理后的结果图。 从图4可看出红富士和花牛存在少量样本重叠。 由经FHCMDA处理数据后的结果图可以看到, 不同类别的数据区分度比较好, 有利于后续KNN的分类。
 | 图1 肉类样本的模糊隶属度图Fig.1 Fuzzy membership values of meat |
 | 图2 FHCMDA处理后的肉类数据分布图Fig.2 Data distribution of meat processed by FHCMDA |
 | 图3 苹果样本的模糊隶属度图Fig.3 Fuzzy membership values of apple samples |
 | 图4 FHCMDA处理后的苹果数据分布图Fig.4 Data distribution of apple processed by FHCMDA |
为了快速、 无损、 有效地定性分析肉类以及苹果种类, 将HCMDA和模糊集理论相结合提出了FHCMDA算法。 实验中收集肉类中红外光谱以及苹果的近红外光谱。 随后, 实验使用MSC的预处理方法对苹果近红外光谱进行预处理。 然后, 采用传统的判别分析方法HCMDA和本文提出的FHCMDA判别分析方法来提取肉类中红外光谱和苹果近红外光谱的鉴别信息。 最后, 采用KNN分类器和朴素贝叶斯分类器对肉类以及苹果的光谱数据进行分类。 最终根据实验结果, 比较两种算法的准确率, 发现无论是肉类还是苹果的数据集, FHCMDA的准确率都比HCMDA的准确率要高。 当K=1时, 肉类使用FHCMDA+KNN法判别分析的准确率达到了97.62%, 高于HCMDA+KNN法的准确率(90.48%)。 苹果使用FHCMDA+KNN法判别分析的准确率达到了91.67%, 远高于HCMDA+KNN的准确率(76.67%)。 综上所述, 模糊双曲余弦判别分析法(FHCMDA)+KNN能够对肉类和苹果的光谱数据进行准确的鉴别分析, 并建立光谱分类模型, 为其他食品的分级与筛选提供了新的研究方向, 同时也为其他的食品鉴别分类提供了不同的思路以及切实可行的技术路线。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|