

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于ATR-FTIR光谱与机器学习的乳腺癌与卵巢癌差异性诊断研究
[宋澳1, 2  , 蔡以撒
, 蔡以撒1, 2 , 蔡李峥1, 4 , 杨万里1 , 庞楠1 , 于瑞华1 , 王士岩3, * , 杨超1, * , 姜峰1, * ]
, 蔡以撒, 杨超, 姜峰]
|
|


作者简介: 宋 澳, 1999年生, 淮阴工学院材料与化工学院硕士研究生 e-mail: songao719@qq.com
乳腺癌和卵巢癌是女性常见的恶性肿瘤, 其代谢活动和蛋白质结构的差异揭示了独特的病理机制。 然而, 由于二者在症状表现和分子特征上的部分重叠, 临床诊断与区分仍然存在挑战。 系统研究乳腺癌与卵巢癌在代谢过程和蛋白质构象上的变化, 可为疾病的诊断和个性化治疗提供科学依据与指导。 基于衰减全反射傅里叶变换红外(ATR-FTIR)光谱技术, 结合机器学习方法, 探索乳腺癌与卵巢癌的差异性光谱标志物, 并评估其诊断与区分的潜力。 研究共纳入157例女性受试者, 包括乳腺癌患者67例、 卵巢癌患者41例及健康对照49例, 采集血清样本进行光谱分析。 结果显示, 在1 450 cm-1波段, 乳腺癌组的吸光度显著高于卵巢癌组( p<0.05), 并伴随波数蓝移, 提示脂质代谢与细胞膜合成异常。 酰胺Ⅰ区域分峰拟合分析表明, 乳腺癌组的α-螺旋比例显著低于卵巢癌组(p<0.05), 而卵巢癌组的β-折叠比例显著高于乳腺癌组( p<0.05), 揭示了两种癌症在蛋白质构象变化上的特异性差异。 结合 A1 450/ A1 650相对吸光强度比和酰胺Ⅰ的光谱数据构建的线性判别分析(LDA)模型表现出一定的区分效能(AUC=0.851, 特异性=73.2%, 灵敏度=80.3%)。 研究结果表明, ATR-FTIR光谱技术结合光谱特征分析与分类模型可为乳腺癌与卵巢癌的诊断与鉴别提供有效支持, 并为未来癌症分型诊断研究奠定了基础。
, CAI Yi-sa, YANG Chao, JIANG Feng
Breast cancer and ovarian cancer are common malignant tumors in women, and the differences in their metabolic activity and protein structures reveal unique pathological mechanisms. However, due to the overlap in symptoms and molecular characteristics between the two, clinical diagnosis and differentiation remain challenging. A systematic study of the metabolic processes and protein conformational changes in breast cancer and ovarian cancer provides scientific evidence and guidance for disease diagnosis and personalized treatment. This study, based on attenuated total reflection Fourier transform infrared (ATR-FTIR) spectroscopy combined with machine learning methods, explores the differential spectral markers of breast cancer and ovarian cancer and evaluates their diagnostic and discriminative potential. A total of 157 female participants were included in the study, including 67 breast cancer patients, 41 ovarian cancer patients, and 49 healthy controls, with serum samples collected for spectral analysis. The results show that at the 1 450 cm-1 band, the absorbance of the breast cancer group was significantly higher than that of the ovarian cancer group ( p<0.05), accompanied by a blue shift in the wavenumber, suggesting lipid metabolism and cell membrane synthesis abnormalities. Peak fitting analysis of the Amide I region revealed that the α-helix proportion in the breast cancer group was significantly lower than that in the ovarian cancer group ( p<0.05). In comparisor the β-sheet proportion in the ovarian cancer group was significantly higher than that in the breast cancer group ( p<0.05), revealing specific differences in protein conformation changes between the two cancers. The Linear Discriminant Analysis (LDA) model constructed using the relative intensity ratio of 1 450/1 650 cm-1 and Amide Ⅰ spectral data showed a reasonable differentiation performance (AUC=0.851, Specificity=73.2%, Sensitivity=80.3%). The results of this study indicate that ATR-FTIR spectroscopy combined with spectral feature analysis and classification models can provide effective support for the diagnosis and differentiation of breast cancer and ovarian cancer, laying the foundation for future cancer subtype diagnostic research.
癌症已成为全球范围内威胁人类健康的重大疾病, 其中乳腺癌和卵巢癌分别是女性最常见和最致命的两种恶性肿瘤[1]。 乳腺癌的发病率位居女性恶性肿瘤首位, 而卵巢癌则因其早期症状不明显、 诊断困难及预后较差, 被称为“ 沉默的杀手” [2]。 乳腺癌和卵巢癌的早期、 快速且准确的诊断对于提高治愈率和患者生存质量至关重要。 然而, 现有的传统诊断方法, 如影像学检查和病理活检, 通常操作复杂, 且要求检查者具备高度的专业技能, 同时可能导致较长的诊断时间和较大的心理压力。 此外, 这些方法涉及频繁的繁琐和侵入性操作, 增加了患者和医护人员的身体和心理负担, 进而影响了诊断效率和精度[3]。 因此, 开发一种高效、 无创且能够快速进行准确诊断的新型方法, 已成为肿瘤学领域的重要课题。
近年来, 傅里叶变换红外光谱(FTIR)技术, 特别是衰减全反射傅里叶变换红外光谱(ATR-FTIR), 因其非侵入性、 快速、 无损以及操作简便等显著优势, 逐渐成为医学界广泛关注的工具[4]。 ATR-FTIR能够通过分析生物样本(如血清、 组织等)中分子振动的特征, 提供丰富的化学和生物信息, 已广泛应用于癌症诊断、 疾病筛查以及生物标志物的发现[5]。 特别是在癌症诊断方面, ATR-FTIR已被广泛应用于不同癌种的研究, 能够为癌症的生物标志物发现和早期筛查提供支持。 一项研究表明, Butler等人使用ATR-FTIR光谱检测脑癌血液, 能够以93.2%和92.8%的灵敏度和特异性区分癌症患者与健康人群[6]。 另一项研究由Akin Geyak等进行, 表明ATR-FTIR光谱法能够确定癌症患者与健康个体的组织样本之间存在显著差异, 并进一步证明包括脂质/蛋白质浓度和核酸/蛋白质浓度在内的光谱参数可以作为癌症早期诊断的生物标志物[7]。 此外, 还有研究表明, 通过ATR-FTIR光谱结合多变量分类算法对唾液拭子进行分析, 可以区分良性唾液样本和潜在肺癌唾液样本[8]。 这些研究表明, ATR-FTIR能够有效地捕捉到与癌症相关的分子振动模式, 如蛋白质、 脂类和核酸等的变化, 这为癌症的精准诊断提供了有力的工具。
近年来, 机器学习方法与ATR-FTIR技术的结合, 为癌症分类和诊断带来了新机遇。 机器学习算法, 尤其是线性判别分析(linear discriminant analysis, LDA), 已广泛应用于ATR-FTIR光谱数据的分析中[19, 20]。 LDA是一种基于统计学原理的监督学习算法, 它通过计算各类别的均值并寻找最能区分不同类别的数据投影方向, 最大化类间散布矩阵与类内散布矩阵的比值, 进而实现不同类别数据的分类[21]。 LDA的优势在于其简单、 高效, 尤其适用于特征维度较高且样本数量较少的情况。 与其他常见的机器学习方法(如支持向量机和决策树)相比, LDA不仅计算效率较高, 而且模型的解释性较强, 有助于理解特征与类别之间的关系[21]。
尽管LDA在光谱数据分类中的应用已取得成功, 但乳腺癌与卵巢癌的区分依然面临较大的挑战。 现有的研究大多集中于使用单一的光谱特征来区分这两种癌症, 而在血清样本中, 乳腺癌与卵巢癌的光谱特征差异相对较小, 这使得分类任务变得更加复杂。 因此, 结合更多的光谱特征, 尤其是通过LDA模型进行优化, 是提高乳腺癌和卵巢癌区分准确性的关键。
基于ATR-FTIR光谱技术, 结合LDA算法, 提出了一种高效、 准确区分乳腺癌和卵巢癌的新型诊断方法。 通过系统分析不同癌症样本的光谱数据, 并构建LDA分类模型, 成功实现了乳腺癌与卵巢癌的有效区分。 主要创新点包括: 首次系统性地将ATR-FTIR光谱与LDA算法结合, 提出了有效的乳腺癌和卵巢癌区分方法; 开发了一种基于血清样本的非侵入性诊断技术, 为临床癌症诊断提供了新的工具; 验证了所提方法在癌症快速分类中的高效性与可靠性, 为光谱学与机器学习在癌症诊断中的跨领域应用提供了有益参考。 本研究的成果有助于推动乳腺癌和卵巢癌血清光谱诊断技术的临床应用, 并为肿瘤早期筛查和精准医疗提供了重要的科学依据与技术支持。
乳腺癌、 卵巢癌患者及正常健康对照组的血清样本均由上海健康医学院附属崇明医院检验科提供。 采用非抗凝采血管, 从乳腺癌患者(67例, 平均年龄61岁, 范围47— 78岁)、 卵巢癌患者(41例, 平均年龄62岁, 范围53— 75岁)及健康对照组(49例, 平均年龄62岁, 范围22— 83岁)中采集1 mL空腹外周静脉血。 血液样本在室温下静置30 min以促进自然凝血, 随后以3 000 rpm离心10 min分离血清。 血清样本在-80 ℃下保存直至使用。 所有患者均经手术或病理活检确诊为乳腺癌或卵巢癌, 且无其他恶性肿瘤病史。 健康对照组血液检查结果正常, 所有样本均经伦理委员会审批, 参与者签署了知情同意书。
使用位于中国合肥国家同步辐射实验室的ATR-FTIR光谱仪(Bruker IFS 66v), 在4000~900 cm-1波段测量血清样本的光谱。 将10 μ L血清样本均匀涂覆于氟化钡晶体(ATR晶体)上, 并置于相同的干燥箱中, 在25 ℃条件下自然干燥10 min, 以确保样本间一致性, 最大程度减少含水量差异对结果的干扰[23, 24, 25]。 由于本实验采用垂直(90° )入射的同步辐射光源, 氟化钡晶体具备良好的中红外透光性能, 能有效提高信噪比并减少反射损耗。 每个样本的光谱分辨率设置为4 cm-1, 成像点大小为100 μ m× 100 μ m, 进行128次累积扫描。 光谱数据使用OPUS软件处理并进行基本校正和标准化。
光谱预处理使用RStudio 4.4.0软件。 通过“ prospectr” 包中的Savitzky-Golay方法对原始光谱进行二阶微分, 以突出光谱带并分辨重叠区域[9, 10]。 在使用Savitzky-Golay平滑方法时, 我们优化了平滑窗口和多项式阶数(多项式阶数设置为2, 窗口大小为13), 有效减少了噪音且未对谱峰造成明显变形。 二阶导数处理有助于提高谱带的分辨率, 特别是在处理重叠区域时, 尽管该方法可能会放大某些干扰信号, 但通过优化参数设置, 确保了噪音和干扰的最小化。 值得注意的是, 由于二阶导数产生负峰(谷), 因此在分析过程中, 我们通过测量波数对应的谷值高度进行定量分析。
1.3.1 红外光谱分析
FTIR光谱图用Origin 2022软件处理分析, 获得红外光谱中各个谱带的峰位及对应的吸光度。 酰胺Ⅰ 区域(1 700~1 600 cm-1)的曲线拟合。 首先, 进行二次导数处理并平滑数据, 基线校正通过非对称最小二乘法完成。 拟合峰采用高斯函数, 初始峰位由二次导数谱确定。 拟合后, 计算各成分的面积并表示为百分比, 分析蛋白质两种二级结构的最大峰值位置, 并定量分析其波峰的面积。
1.3.2 ROC分析和分类模型
首先通过受试者工作特征(receiver operating characteristic, ROC)分析评估光谱数据的诊断性能[12], 并采用线性判别分析(LDA)算法[13]进行分类。 ROC分析用于评估不同诊断阈值下光谱特征的效能, 计算曲线下面积(AUC)以筛选光谱数据的分类潜力。
在分类任务中, 数据集按7∶ 3比例随机划分为训练集和测试集。 在LDA分类中, 训练集和测试集分别用于建模和验证。 LDA算法结合10重交叉验证(10-fold cross-validation)进行模型优化, 优化后的模型用于重新训练整个训练集并验证测试集。 分类性能的指标通过灵敏度(sensitivity)、 特异性(specificity)以及ROC曲线下的面积(AUC)进行评估[14]。 所有分析均使用R语言完成, 最终结果通过交叉验证和测试集的性能评估, 确保模型的稳健性和分类效果。
1.3.3 统计分析
光谱数据经预处理后, 使用Microsoft Excel 2021和Rstudio 4.4.0进行统计分析。 首先进行正态性检验(Shapiro-Wilk检验), 对于不符合正态分布的数据, 使用Kruskal-Wallis秩和检验。 对于符合正态分布的数据, 进行方差齐性检验(F检验)或方差不齐检验(F’ 检验)。 当三组间有统计学差异时, 进行两两比较。 结果以均值± 标准误差(SD)表示, p< 0.05为显著性差异。 其显著性程度表示为* p< 0.05、 * * p< 0.01、 * * * p< 0.001。
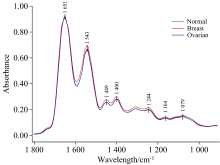
FTIR光谱可提供血清样本中生物分子的关键信息, 尤其是1 800~900 cm-1的“ 指纹区域” , 该区域包含用于表征蛋白质、 脂质、 碳水化合物和核酸等多种生物分子的谱带[4]。 图1展示了乳腺癌、 卵巢癌与健康对照组在该区域内的平均红外光谱, 可观察到多种生物成分的光谱差异。 乳腺癌和卵巢癌组在酰胺Ⅰ (1 651 cm-1)和酰胺Ⅱ (1 543 cm-1)处的吸收峰存在显著差异, 提示蛋白质二级结构发生了变化; 而在C— H弯曲振动区域(1 449和1 400 cm-1)和PO2-伸缩振动区域(1 244 cm-1)中谱峰强度的变化, 则揭示了脂质代谢和糖类相关生物分子的改变。 主要振动模式及其分子来源列于表1。
 | 图1 乳腺癌(红线)、 卵巢癌(蓝线)和正常对照组(黑线)血清样本在“ 指纹区域” 的FTIR平均光谱Fig.1 FTIR average spectra of serum samples from Breast Cancer (red line), Ovarian Cancer (blue line), and Normal Control Groups(black line) in the “ Fingerprint Region” |
| 表1 平均原始ATR-FTIR光谱中所示的主要波数分配[15, 16, 17, 22] Table 1 Distribution of major wavenumbers shown in the average raw ATR-FTIR spectrum[15, 16, 17, 22] |
特别需要指出的是, 1 460~1 450 cm-1区域段的谱峰不应简单归因于甲基(CH2)的变角振动。 已有研究表明, 亚甲基(CH2)在1 460 cm-1附近的变角振动亦会对1 455和1 450 cm-1处的谱峰产生显著贡献。 因此, 相关谱带更可能是CH2和CH3基团弯曲振动的复合峰, 反映了脂质和蛋白质中烷基侧链的综合结构特征[22]。
图2展示了三个研究组的二阶导数FTIR光谱特征。 在1 800~1 300 cm-1范围内识别出多个主要谱峰, 包括1 660、 1 640、 1 569、 1 548、 1 450、 1 400 和1 314 cm-1[图2(a)]; 在1 300~900 cm-1范围内识别出1 238、 1 167、 1 078、 1 031 和986 cm-1[图2(b)]。 这些谱峰的振动模式及其对应的分子来源见表2。
 | 图2 详细的平均二阶导数光谱和主要波数 乳腺癌(红线)、 卵巢癌(蓝线)和正常对照组(黑线)的平均光谱范围为(a)1 800~1 300 cm-1, (b)1 300~900 cm-1Fig.2 Detailed average second derivative spectra and key wavenumbers The average spectra of Breast Cancer (red line), Ovarian Cancer (blue line), and Normal Control Group (black line) in the range of (a) 1 800~1 300 cm-1 and (b) 1 300~900 cm-1 |
| 表2 傅里叶变换红外光谱二阶导数谱峰的分配 Table 2 Distribution of the Fourier transform infrared second derivative spectral peaks |
通过对血清FTIR光谱二阶导数的关键特征峰进行分析, 以揭示组间差异。 使用吸光度比减少了样本厚度差异、 水分波动和仪器漂移等对光谱结果的干扰, 提升了不同样本间的可比性和数据准确性。 我们选择了4个代表性吸收峰, 计算其吸光度与酰胺Ⅰ 带吸光度的比值, 统计分析结果见表3。
| 表3 傅里叶变换红外光谱平均二阶导数光谱波峰和吸光度比的统计分析 Table 3 Statistical analysis of peak positions and absorbance ratios in the average second derivative FTIR spectra |
检验结果表明, 所有数据均非正态分布, 使用非参数检验方法(Kruskal-Wallis秩和检验)对三组样本(正常组、 乳腺癌组、 卵巢癌组)进行峰位比较。 表3展示了三组样本FTIR二阶光谱吸收峰位及吸光度比的比较结果。 在1 450和1 167 cm-1波峰处的差异具有统计学意义; 在四个吸光度比值结果中, 仅1 450 cm-1处的差异具有统计学意义(H=18.354, p< 0.001)。 进一步的两两比较显示, 癌症组(乳腺癌和卵巢癌)与正常组在1 450 cm-1处的吸收峰差异具有统计学意义(H=16.714, p< 0.05)。
乳腺癌组在1 450 cm-1波段的吸光度和波数变化显著, 且波数发生蓝移, 这一现象可能与脂质代谢变化及细胞膜合成需求增加有关。 卵巢癌组在该波段未表现出显著波数变化, 但也显示了脂质代谢的改变。 这些变化表明ATR-FTIR技术能敏感地反映不同癌症类型(乳腺癌与卵巢癌)中的代谢活动差异, 特别是在脂质代谢领域。
为评估不同谱峰在癌症诊断中的潜力, 我们采用受试者工作特征(ROC)曲线分析, 对原始光谱和二阶导数光谱中的特征吸收峰进行系统评估。 所有FTIR振动模式的峰值高度统计分析结果见表S1。
| 表S1 二阶导数峰高度统计分析与ROC曲线分析结果 Table S1 Statistical analysis of second derivative peak heights and ROC curve analysis results |
值得注意的是, 1 450 cm-1处C— H变角振动谱峰在正常组、 乳腺癌组和卵巢癌组之间呈现出显著差异。 为控制因样品厚度、 水分含量等物理因素造成的强度偏差, 我们在分析中采用了相对强度法, 即将1 450 cm-1处的吸收强度归一化为其与酰胺Ⅰ 带(1 650 cm-1)吸收强度的比值, 作为诊断特征指标。
统计结果显示, 乳腺癌组的A1 450/A1 650比值显著高于正常组(p< 0.001)和卵巢癌组(p< 0.05); 卵巢癌组亦显著高于正常组(p< 0.05)。 这一差异表明乳腺癌和卵巢癌患者血清中CH2和CH3基团的生化特性发生了显著变化。
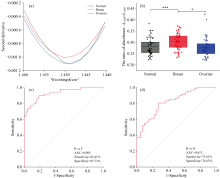
基于归一化的A1 450/A1 650强度比, 我们进一步构建ROC曲线并计算AUC值(见图3)。 结果显示, 该指标在区分正常人群与癌症患者中具有较高的诊断效能, AUC为0.905, 特异性为85.73%, 灵敏度为82.41%。 在乳腺癌与卵巢癌的区分中, AUC为0.813, 特异性为74.63%, 灵敏度为75.61%。 这些结果表明, 相对强度处理后的1 450 cm-1谱峰可作为可靠的光谱特征, 但在不同类型的癌症之间, 特异性和灵敏度有所降低。
 | 图3 三组研究对象在1 450 cm-1处统计显著的相对吸光强度分析 (a): 1 460~1 440 cm-1区间的平均二阶导数光谱图, 其中乳腺癌组(红色)、 卵巢癌组(蓝色)与正常对照组(黑色)在1 450 cm-1处的谱带差异明显; (b): A1 450/A1 650相对吸光强度的散点图, 展示乳腺癌(红色)、 卵巢癌(蓝色)和正常对照组(黑色)之间的显著差异。 水平实线表示各组的均值; (c): 正常对照组(N)与癌症组(C: 包括乳腺癌与卵巢癌)之间的ROC曲线; (d): 乳腺癌(B)与卵巢癌(O)之间的ROC曲线, 基于A1 450/A1 650相对吸光度绘制; 曲线下面积(AUC)、 灵敏度和特异性等关键指标展示于图中相应位置; 统计学显著性用* 表示: * p< 0.05, * * * p< 0.001Fig.3 Comparative analysis of statistically significant relative absorbance at 1 450 cm-1 among the three study groups (a): Averaged second derivative spectra in the range of 1 460~1 440 cm-1, showing the spectral differences at 1 450 cm-1 among breast cancer (red line), ovarian cancer (blue line), and normal control (black line) groups; (b): Scatter plots of the relative absorbance ratio A1 450/A1 650, comparing breast cancer (red), ovarian cancer (blue), and normal control (black) groups; The horizontal solid lines represent the group means; (c): ROC curve differentiating normal controls (N) from the cancer group C (breast and ovarian cancers); (d): ROC curve distinguishing breast cancer (B) from ovarian cancer (O), based on the relative absorbance ratio A1 450/A1 650; The area under the curve (AUC), sensitivity, and specificity values are indicated near the respective curves; Statistical significance is denoted by asterisks: * p< 0.05; * * * p< 0.001 |
为了深入探讨乳腺癌、 卵巢癌及健康对照组血清中蛋白质二级结构的差异, 我们对三组的平均FTIR光谱在酰胺Ⅰ 带区域(1 700~1 600 cm-1)进行了高斯拟合分析。 分析前, 光谱数据经平滑处理与基线校正, 以最大程度减少背景干扰, 尤其是水的H— O— H弯曲振动可能对该区域(约1 645 cm-1)的影响。
在分峰过程中, 我们参考二阶导数谱以确定拟合峰位, 并基于文献报道[18, 26, 27, 28], 各构象对应峰位为: 1 651 cm-1对应α -螺旋, 1 631 cm-1为随机卷曲, 1 670和1 680 cm-1为β -转角, 1 617和1 690 cm-1代表β -折叠与反平行β -折叠。 虽然酰胺Ⅰ 带通常包含多个子峰, 我们本研究中仅选取其中两种代表性结构(α -螺旋和β -折叠)进行研究讨论, 因其在三组间差异最为显著, 便于突出诊断特征。 图4展示了三组酰胺Ⅰ 带的高斯拟合结果。
 | 图4 酰胺Ⅰ 带(1 700~1 600 cm-1)蛋白质二级结构的高斯拟合结果Fig.4 Gaussian fitting results of the Amide Ⅰ band (1 700~1 600 cm-1) protein secondary structure |
定量分析结果见表4, 在1 617和1 690 cm-1(β -折叠)波段, 三组间存在显著差异(H=7.032, p=0.02)。 乳腺癌组的β -折叠比例显著低于卵巢癌组(p< 0.05), 而与正常组无统计学差异(p> 0.05)。 在1 651 cm-1(α -螺旋)波段, 组间差异更显著(H=13.104, p=0.002), 其中乳腺癌组显著低于正常组与卵巢癌组(p< 0.05), 正常组与卵巢癌组之间亦存在显著性差异(p< 0.05)。
| 表4 乳腺癌、 卵巢癌和正常对照组FTIR光谱中酰胺Ⅰ 区域的蛋白质二级结构比较 Table 4 Comparison of protein secondary structures in Amide Ⅰ region of FTIR spectra for Breast Cancer, Ovarian Cancer, and Normal Control Groups |
已有研究指出, β -折叠结构比例的变化与癌症相关蛋白聚集及纤维化趋势密切相关[11]; 而α -螺旋减少则可能与癌症患者中功能性蛋白流失、 酶活性异常等生理变化有关。 这些发现表明, 乳腺癌和卵巢癌在蛋白质二级结构方面存在显著差异, 可能反映其在代谢状态、 蛋白折叠及细胞功能方面的不同机制。
在前述基础上, 我们进一步结合1 450 cm-1波段的相对强度与酰胺Ⅰ 带高斯拟合分析结果, 利用LDA方法对不同组别进行分类评估, 以探索其联合在癌症诊断中的潜力。
结果显示, 整合A1 450/A1 650相对强度和酰胺Ⅰ 带中α -螺旋与β -折叠比例作为联合特征变量, 显著提升了LDA模型的分类性能。 在区分正常组与癌症组(乳腺癌与卵巢癌合并)时, 模型的AUC值达到0.952, 敏感性为90.3%, 特异性为92.2%。 这些结果表明, 联合分析能够提供更全面的分子信息, 显著提高了正常组织与癌症组织之间的区分能力, 有效地识别癌变组织。
尽管在乳腺癌与卵巢癌的区分中LDA模型也表现出了性能的提升, 但相较于正常组与癌症组的分类, 提升幅度较为有限。 结合后的LDA模型在乳腺癌与卵巢癌的分类中, AUC值为0.851, 灵敏度为80.3%, 特异性为73.2%。 虽然这种方式提供了有益的信息, 但乳腺癌与卵巢癌之间的光谱差异相对较小, 因此该模型在区分这两种癌症时的性能仍有进一步提升的空间。 未来研究可能需要引入更多的光谱特征或通过多维度信息的融合, 进一步优化分类模型的性能。
通过FTIR技术对乳腺癌、 卵巢癌及健康对照组血清样本的详细分析, 揭示了血清成分的代谢差异。 通过二阶导数光谱分析, 我们发现不同类型癌症组在酰胺Ⅰ 和酰胺Ⅱ 带的吸收峰、 脂质和糖类代谢区域的特征明显不同, 这表明FTIR 技术能敏感地识别癌症相关的生物分子变化。 特别是在1 450 cm-1波段, 乳腺癌与卵巢癌组与正常组之间的吸收峰差异具有显著统计学意义, 为诊断提供了有力支持。 ROC分析表明, A1 450/A1 650相对强度在区分正常组织和癌症组织方面具有较高的诊断性能(AUC=0.905), 但在区分乳腺癌与卵巢癌时, 灵敏度和特异性有所下降。 进一步的高斯拟合分析揭示了乳腺癌和卵巢癌在蛋白质二级结构(如α -螺旋和β -折叠结构)的差异, 这些变化可能反映了癌症相关蛋白质的折叠机制和代谢活动的差异。 结合LDA分类分析后, 联合使用A1 450/A1 650相对强度和酰胺Ⅰ 带的光谱特征大幅提高了癌症组与正常组的区分能力, AUC值达到0.952, 但在乳腺癌与卵巢癌的区分中仍存在一定挑战。 总体而言, FTIR光谱技术结合机器学习方法, 作为一种高效、 非侵入性的方法, 具有广泛的临床应用前景。 未来, 结合多维度光谱信息和优化的算法, FTIR光谱数据有望在癌症筛查、 分期、 分型诊断及治疗监测中发挥重要作用, 为精准医学提供科学的数据支持。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|