




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合特征空间注意力的卷积神经网络用于酒石酸近红外在线检测
[李志豪1, 2  , 肖金凤
, 肖金凤1, * , 张洪明2, * , 吕波2, 3, * , 尹相辉1 , 李晓星1, 2 , 赵明4 , 马飞5 ]
, 肖金凤, 张洪明, 吕波, 尹相辉|
|


作者简介: 李志豪, 2001年生, 南华大学电气工程学院硕士研究生 e-mail: 13461598948@163.com
酒石酸作为一种重要的有机酸, 广泛存在于葡萄酒、 果汁、 碳酸饮料及部分糖果等食品中, 其浓度直接影响产品的酸甜平衡、 口感稳定性。 在相关食品生产过程中, 酒石酸浓度会因原料差异及配方调整而波动, 因此建立能够实时在线监测酒石酸浓度的方法对保障产品质量与生产一致性至关重要。 然而, 现有检测方法(如滴定法、 HPLC)存在响应迟滞问题, 难以实现实时在线监测。 鉴于工业生产过程的多变量、 非线性和动态特性, 建立精确的浓度预测模型对方法学提出了更高要求。 为此, 融合一维卷积神经网络(1D-CNN)与特征空间注意力机制(FSA), 构建CNN-FSA混合模型, 采集近红外光谱以驱动酒石酸溶液浓度检测实验, 探索模型在提升检测速度与鲁棒性方面的潜力, 为溶液化学过程的浓度实时在线监测提供创新参考方法。 光谱数据先经主成分分析(PCA)结合马氏距离剔除异常, 采用标准正态变量变换(SNV)以消除散射与基线漂移, 再使用提出的CNN-FSA模型和 PLSR模型对数据集进行训练和评估。 模型性能通过决定系数( R2)、 均方根误差(RMSE)和平均绝对误差(MAE)进行综合评估。 设计了六轮实验, 每轮实验初始底料为 500 g(水、 酒精、 葡萄糖、 苹果酸, 柠檬酸)混合液体, 补料为500 g(475 g 水+25 g 酒石酸)。 前四轮实验数据按7∶3比例随机划分为训练集和测试集, 后两轮实验数据作为独立预测集以严格评估模型泛化能力。 在独立预测集上, CNN-FSA模型取得了优异的性能: R2=0.989 6, RMSE=0.000 702, MAE=0.000 580。 相比之下, PLSR模型的性能为: R2=0.968 8, RMSE=0.001 214, MAE=0.001 059。 相较于 PLSR, CNN-FSA在独立预测集上的RMSE显著降低了42.17%, MAE 降低了45.23%。 结果表明: CNN-FSA在酒石酸浓度预测建模中显著优于PLSR, 在预测集上展现出更强泛化性与稳健性。
, XIAO Jin-feng, ZHANG Hong-ming, LÜ Bo, YIN Xiang-huiTartaric acid, as an important organic acid, is widely present in wine, fruit juice, carbonated beverages, and certain confectionery products. Its concentration directly influences the balance between sweetness and acidity as well as the stability of flavor. During food production, the tartaric acid concentration may fluctuate due to variations in raw materials and formulation adjustments. Therefore, establishing a method for real-time online monitoring of tartaric acid concentration is crucial for ensuring product quality and production consistency. However, conventional detection methods (e. g., titration, HPLC) suffer from response delays and are unsuitable for real-time monitoring. Considering the multivariate, nonlinear, and dynamic characteristics of industrial processes, more accurate concentration prediction models are required. To address this, we integrate a one-dimensional convolutional neural network (1D-CNN) with a feature-space attention (FSA) mechanism, resulting in a CNN-FSA hybrid model. By conducting near-infrared (NIR) spectroscopy—driven experiments to detect tartaric acid concentration, this study explores the potential of CNN-FSA to improve prediction speed and model robustness, thereby providing an innovative approach for real-time online monitoring of solution-phase chemical processes. Spectral data were first processed using principal component analysis (PCA) combined with Mahalanobis distance to remove outliers, followed by standard normal variate (SNV) transformation to eliminate scattering and baseline drift. Subsequently, the proposed CNN-FSA model and the traditional partial least squares regression (PLSR) model were trained and evaluated. Model performance was comprehensively assessed using the coefficient of determination ( R2), root mean square error (RMSE), and mean absolute error (MAE). Six rounds of experiments were designed, with each round starting with 500 g of a mixed solution (water, ethanol, glucose, malic acid, and citric acid) as the initial substrate, supplemented with 500 g of a solution (475 g water+25 g tartaric acid). Data from the first four rounds were randomly split into training and test sets at a 7∶3 ratio. In comparison, data from the last two rounds were used as independent test sets to evaluate the model's generalization ability rigorously. On the independent prediction sets, the CNN-FSA model achieved outstanding performance: R2=0.989 6, RMSE=0.000 702, and MAE=0.000 580. In contrast, the PLSR model yielded R2=0.968 8, RMSE=0.001 214, and MAE=0.001 059. Compared with PLSR, CNN-FSA reduced RMSE by 42.17% and MAE by 45.23% on the independent prediction sets. The CNN-FSA model significantly outperforms PLSR in tartaric acid concentration prediction, demonstrating superior generalization and robustness on independent prediction datasets.
工业生产过程的物质成分演化构成多变量非线性动态系统, 相对于光谱检测, 传统化学分析方法在此场景下的应用具有一定的局限性。 目前, 常见的光谱技术包括拉曼光谱[1]、 激光诱导击穿光谱[2]、 近红外光谱(near-infrared spectroscopy, NIRS)[3, 4]和中红外光谱(mid-infrared spectroscopy, MIR)等。 基于近红外光谱(NIRS)的检测技术具备快速响应、 无损样本与操作简易的核心竞争力, 已被广泛应用于食品加工业[5]、 制药[6]、 能源[7]等领域。 NIRS与其他光谱技术的联合使用, 有助于解决食品复杂体系中的成分检测难题[8]。 它已然成为了工业领域生产过程参数预测和质量控制的重要工具。
酒石酸作为葡萄酒及柠檬汁等饮料的重要有机酸, 其浓度直接影响产品酸度与稳定性。 在酿酒过程中, 生产者通常需根据酸度需求人工添加酒石酸。 传统测量方式的酿酒更复杂且成本相对较高[9]。 贾玉荣[10]等建立高效液相色谱法(high performance liquid chromatography, HPLC)手性色谱法测定药用辅料L(+)-酒石酸中D(-)-酒石酸含量。 传统化学滴定法不仅耗时长、 操作繁琐且需破坏样品, 还难以满足工业生产中实时在线监测的需求。 NIRS技术则可在不破坏样品的前提下实现快速检测, 从而优化生产效率。
然而, NIRS数据往往具有高维性、 多重共线性和复杂非线性特征, 这对建模提出了挑战。 传统偏最小二乘回归(partial least squares regression, PLSR)虽可通过潜变量投影缓解多重共线性, 但其线性假设限制了对光谱-浓度非线性关系的刻画能力, 尤其在葡萄糖、 酒精、 柠檬酸、 苹果酸等混合液体(底料)与酒石酸(补料)协同变化的动态生产过程中, 模型的泛化性能受限。
卷积神经网络(convolutional neural network, CNN)凭借强大的层次化特征提取能力, 已成功从图像处理迁移至光谱分析领域, 为复杂光谱模式解析提供了新范式。 一维卷积神经网络(one-dimensional CNN, 1D-CNN)尤其适用于处理高维光谱数据。 在1D-CNN基础上引入特征空间注意力机制(feature space attention, FSA), 通过动态加权增强对关键化学特征的表达能力, 并结合特征压缩层优化高维光谱数据的处理[11]。 通过六轮近红外光谱驱动实验, 系统对比CNN-FSA模型与PLSR模型的性能, 验证其在非线性系统中的优势, 并基于注意力权重分析提升模型可解释性, 为深度学习在工业光谱在线检测中的应用提供理论与实验依据。
在近红外光谱实验中, 数据质量是确保模型性能可靠性的基石。 异常光谱可能源于样品污染、 仪器瞬时噪声或实验操作误差等因素, 如果参与建模的数据中掺杂波动较大的无效光谱数据, 则会干扰模型的训练过程并且降低预测精度。 为确保数据的可靠性与一致性, 本研究采用主成分分析(principal component analysis, PCA)结合马氏距离的方法进行异常光谱检测与剔除。
主成分分析通过正交变换将高维、 强相关的原始光谱数据投影到由少数几个主成分构成的低维空间, 这些主成分能够最大程度地保留原始数据的主要变异信息。 此操做可以精准有效的降低数据维度和计算过程的复杂度。
相较于忽略维度相关性的欧氏距离, 马氏距离通过解析数据的协方差结构建立统计度量框架, 能更可靠地计算样本点与数据中心(均值向量)的概率分布距离。 在PCA降维后的主成分空间中, 计算每个样本点相对于主成分得分分布中心的马氏距离。
该方法结合了PCA的降维优势和马氏距离的统计特性, 是一种高效、 鲁棒的异常光谱检测手段。 其核心优势在于能够: 有效处理高维光谱数据; 充分考虑数据的内在分布特性(协方差结构); 适用于多种光谱分析场景。
光谱数据预处理是光谱分析流程中不可或缺的关键环节, 其核心目标是消除或减弱与目标化学信息无关的物理干扰(如光散射、 基线漂移), 规范化光谱基准得以构建, 为后续建模任务的可靠实施与结果可比性奠定基础[12, 13]。
标准正态变量变换(standard normal variate, SNV)的核心功能是消除近红外漫反射光谱中颗粒尺寸、 表面散射及光程变异引入的干扰。 对离群值剔除后的光谱数据实施SNV预处理。 其中SNV的数学本质是将每条光谱独立转化为均值为0、 标准差为1的标准正态分布空间, 其计算公式[14]
$X_{i, k}=\frac{x_{i, k}-\bar{x}}{\sqrt{\frac{\displaystyle\sum_{k=1}^{m}\left(x_{i, k}-\bar{x}\right)^{2}}{m-1}}}$(1)
式(1)中, ${\bar{x}}$为第i个样品光谱平均值; k=1, 2, …, m; m为波长点数。
采用标准正态变量变换(SNV)对于NIRS数据进行预处理。 该方法基于单样本独立校正机制(不依赖全局数据集), 可以有效消除由光程差异引起的散射效应, 提升光谱数据与目标变量(酒石酸浓度)之间的相关性。 与多元散射校正(multiplicative scatter correction, MSC)相比, SNV 不依赖参考光谱, 更加简便和稳健, 因此在定量分析中被广泛使用[15]。 该预处理流程输出的优化数据集, 为后续鲁棒建模提供了高质量数据支撑, 尤其适配在线监测中样品状态动态演化的实时需求。
用决定系数(coefficient of determination, R2)、 均方根误差(root mean square error, RMSE)和平均绝对误差(mean absolute error, MAE)评估模型的预测性能:
决定系数(R2): R2反映模型对数据的拟合程度[16], 计算公式为
$R^{2}=1-\frac{\displaystyle\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}}{\displaystyle\sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2}}$(2)
均方根误差(RMSE): RMSE衡量预测值与参考值之间的偏差, 是评价模型预测性能常用的重要指标[17]。 公式为
$\mathrm{RMSE}=\sqrt{\frac{1}{n} \displaystyle\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}}$(3)
平均绝对误差(MAE): MAE表示预测值与实际值的平均绝对偏差, 公式为
$\text { MAE }=\frac{1}{n} \displaystyle\sum_{i=1}^{n}\left|y_{i}-\hat{y}_{i}\right|$(4)
式(4)中, n为样本数量; yi为第i个样本的实际值; ${\hat{y}}$为第i个样本的预测值; ${\bar{y}}$为样本实际值yi的算数平均值。
在模型评价指标中, R2反映模型整体拟合能力, RMSE和MAE则从不同角度量化预测误差, 帮助比较模型性能。
通常, 回归方法可用于建立NIRS数据与分析物浓度之间的关系模型[18]。 神经网络可以用于回归任务以及统计模型[19]。 该实验中, 数据输入维度为376个特征, 对应950~1 700 nm 波长范围(2 nm分辨率)。
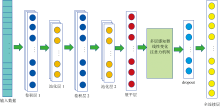
所有输入数据均通过预处理消除高频噪声、 散射效应与基线漂移。 CNN-FSA模型结构图如图1所示。 一维卷积神经网络模块采用两级串联结构:
 | 图1 CNN-FSA模型结构Fig.1 Structural configuration of the CNN-FSA model |
第一级: 使用16个尺寸为20的卷积核(步长6, 填充2), 卷积结果经整流线性单元激活函数(rectified linear unit, ReLU)处理后, 接入批归一化层, 最终通过尺寸为2、 步长为2的最大池化层降维。
第二级: 配置32个尺寸为10的卷积核(步长3, 填充2), 同样经过ReLU激活、 批归一化处理, 并以相同参数(池化核尺寸2, 步长2)进行最大池化操作。
批归一化层加速了模型收敛, 池化层有效消除了原始光谱中的噪声, 从而增强了光谱特征信息, 该模块可实现光谱特征的层次化提取[20]。 激活函数则是对卷积层的输出进行的非线性操作, 以此来提取更多的数据特征信息。 特征展平层: 将卷积模块输出的三维特征张量转换为一维特征向量, 为后续全连接层提供输入。 多层感知机模块: 单隐藏层结构; 输入维度; 输出维度。 采用带泄漏的整流线性单元(leaky rectified linear unit, LeakyReLU)激活函数(负斜率0.1)增强非线性表达能力。 通过批归一化稳定训练过程。 注意力机制受人类视觉系统启发, 模拟选择性聚焦重要区域的能力, 使模型能够对输入数据的关键特征赋予更高权重, 从而增强特征表达能力[21, 22]。 特征空间注意力模块: 采用多头自注意力机制(4个注意力头), 在8维特征空间对特征进行动态加权。 该模块能自适应地增强关键化学特征的贡献, 同时抑制噪声干扰。 输出层: 包含Dropout正则化(比率0.05)防止过拟合, 以及全连接层将8维特征映射为1维浓度预测值。
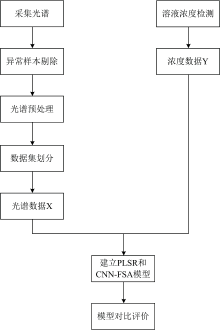
光谱分析流程如图2所示。
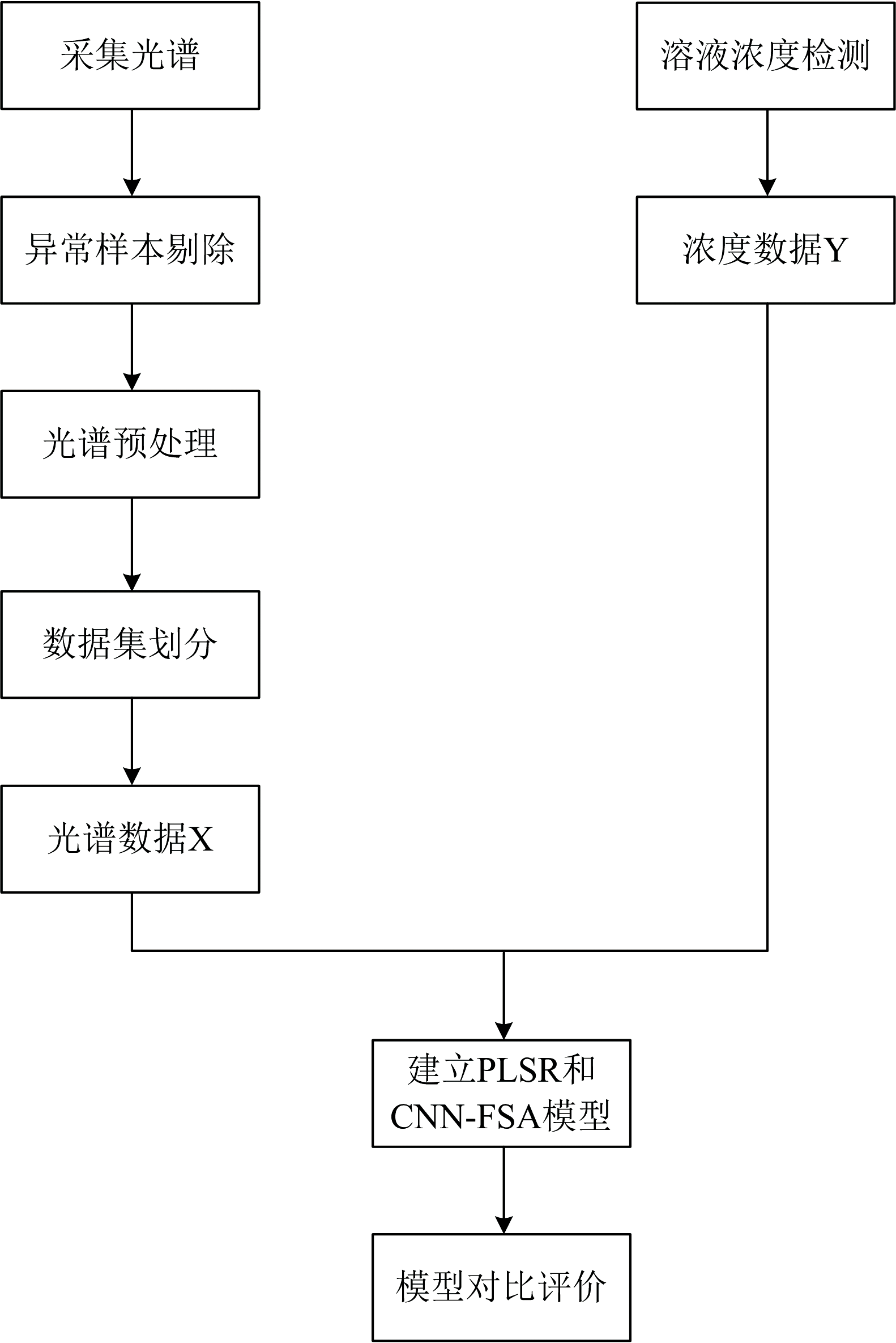 | 图2 实验光谱分析流程Fig.2 Experimental spectral analysis workflow |
图2展示了该研究实验光谱分析的基本流程, 开展了六轮重复实验, 每轮包含初始底料(453.9 g水+40 g无水乙醇(乙醇浓度99.7%)+5 g无水葡萄糖+1 g苹果酸+0.1 g柠檬酸)与补料(475 g水+25 g酒石酸)的标准化物料体系。 葡萄糖(C6H12O6)、 酒石酸(C4H6O6)与乙醇(C2H5OH)分子均含羟基(— OH)等极性基团, 用以模拟实际多组分体系中对酒石酸定量检测的干扰。 六轮实验同步采集光谱数据及对应理化值, 构建原始数据集。 对前四轮实验数据执行异常光谱剔除之后数据按7∶ 3比例随机划分为训练集(70%)与测试集(30%)。 基于划分后的数据集, 分别采用偏最小二乘回归(PLSR)与CNN-FSA神经网络模型进行训练。 训练完成后, 两模型分别对测试集进行预测, 并计算性能指标(R2, RMSE, MAE)。 对比测试集上的泛化差异和独立预测集上的鲁棒性表现。
所用试剂包括: 酒石酸(福晨(天津)化学试剂有限公司), 酒精(江苏花厅生物科技有限公司), 无水葡萄糖、 柠檬酸和苹果酸(天津聚恒达化工有限公司)。
酒石酸溶液浓度近红外在线检测系统框架如图3所示, 该装置包括反应釜、 计算机, 补料烧瓶、 电动搅拌机、 蠕动泵、 光谱仪、 流通池、 近红外光源、 短光纤。
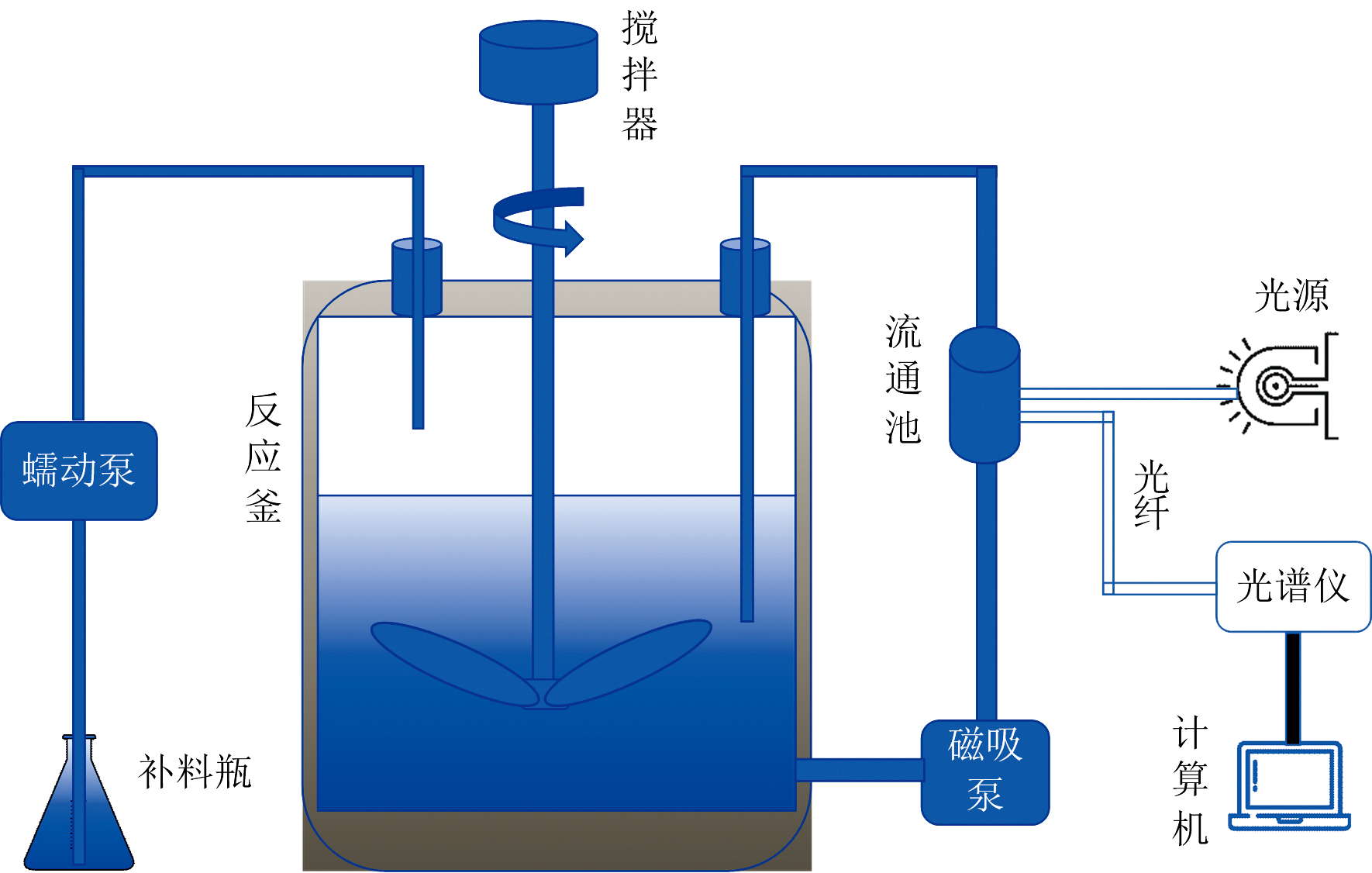 | 图3 酒石酸溶液浓度近红外在线检测系统Fig.3 Online NIR detection system for tartaric acid concentration in solutions |
采用台湾超微光学光谱仪开展实验。 该光谱仪波长范围为900~1 700 nm(实验选择实际的波段范围为950~1 700 nm), 专用于检测近红外光谱, 光谱仪分辨率设置为2 nm, 蠕动泵则是经由RS485工业总线实施闭环控制, 该设备可实现转向切换与速度的无级调节, 转速控制分辨率达± 0.1 RPM。
反应釜是双层设计, 里层盛装料液, 外层是冷却循环水, 利用制冷装置将循环冷却水降温, 保持反应釜内部液体温度在25 ℃左右。 温度检测设备使用的是BT6系列温控仪表, 分辨率0.1 C° , 测量精度± 0.5%FS。 实验时, 称取453.9 g水、 40 g无水乙醇(浓度 99.7%)、 5 g无水葡萄糖、 1 g苹果酸和 0.1 g柠檬酸, 加入烧杯中, 使用玻璃棒进行充分搅拌, 确保完全溶解, 然后倒入反应釜中。 以同样的方式称25 g酒石酸, 另取补料瓶, 加入475 g的水, 将25 g酒石酸加入补料瓶, 同时使用玻璃棒进行充分搅拌, 确保酒石酸充分溶解, 配制出质量分数为5%的酒石酸溶液。 计算机经由RS485串行总线发送指令信号, 驱动蠕动泵执行精确流量调节。 通过称量蠕动泵50次加料的总质量, 平均之后确定单次加料质量。 计算机据此即时计算并记录每次加料后反应釜中的酒石酸浓度, 并将这些数据集保存在Excel文档。
实验开始前, 反应釜里倒入料液, 打开搅拌机, 然后打开循环料液的磁吸泵保证流通池与反应釜的料液循环流通。 使用光纤将光源的出光端口与流通池的一端连接, 流通池的另一端则使用光纤连接至光谱仪, 蠕动泵上的硅胶管伸入反应釜中。 光谱波长范围选择950~1 700 nm, 2 nm分辨率共计376个波长。
为消除滴定终点蠕动泵管道内可能会掺杂空气的影响, 每轮实验数据实际结束浓度是到2.44%, 剩余数据因可能受管道内残留空气影响而舍弃。 单轮实验时长约40 min, 采样间隔约4 s, 平均每轮可获得约562条吸光度光谱(不同实验轮次略有差异)。 前四轮实验共得到2 248条数据, 剔除10%(225条)异常数据后, 保留2 023条; 后两轮实验共获得1 120条数据。
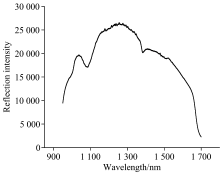
图4展示了实验过程中的背景光谱变化图, 波长范围950~1 700 nm。 背景光谱强度在950~1 100 nm保持较高水平(约25 000~30 000), 1 100 nm附近出现明显凹陷, 这一特征与光纤传输特性相关, 光纤的材料折射率或弯曲损耗在该波段引起信号衰减。 背景光谱作为参考, 用于校正样品光谱中的仪器噪声和环境干扰, 确保后续透射和吸光度计算的准确性。
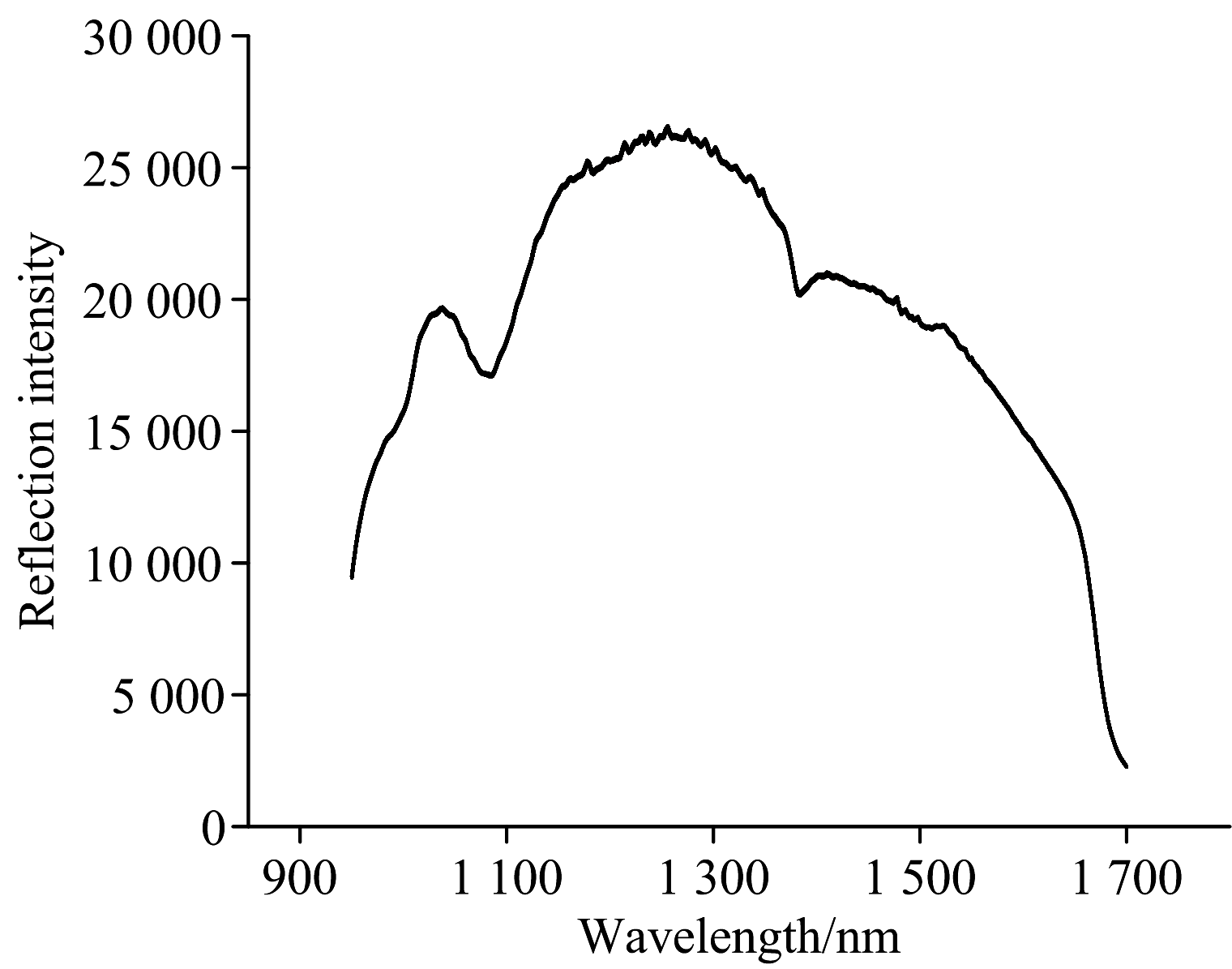 | 图4 背景光谱Fig.4 Background spectrum |
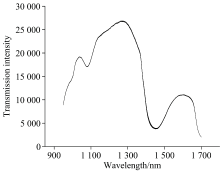
图5展示了六轮实验采集的近红外透射光谱(950~1 700 nm)叠加图。 图6展示了对应的吸光度光谱。 1 400~1 500 nm区域显示出较明显的吸收谷(对应吸光度峰)。 这些特征反映了乙醇、 葡萄糖(C— H), 水(O— H)和微量有机酸的吸收贡献。 补料(5%酒石酸)泵入40 min导致酒石酸浓度渐增至约2.5%, 但水(> 90%)的强吸收(1 450 nm)主导光谱, 不同浓度下的光谱叠加后在整个波长范围内的变化幅度相对有限。 这一现象在近红外透射光谱分析水溶液体系时较为常见, 主要归因于水分子在1 450 nm附近的强吸收主导了光谱信号, 从而导致其他成分的贡献被部分掩盖。 然而, 吸光度的细微变化模式与溶液中酒石酸浓度的增加存在关联。 背景光谱(图5)的1 100 nm凹陷在透射图中被校正, 避免仪器误差。
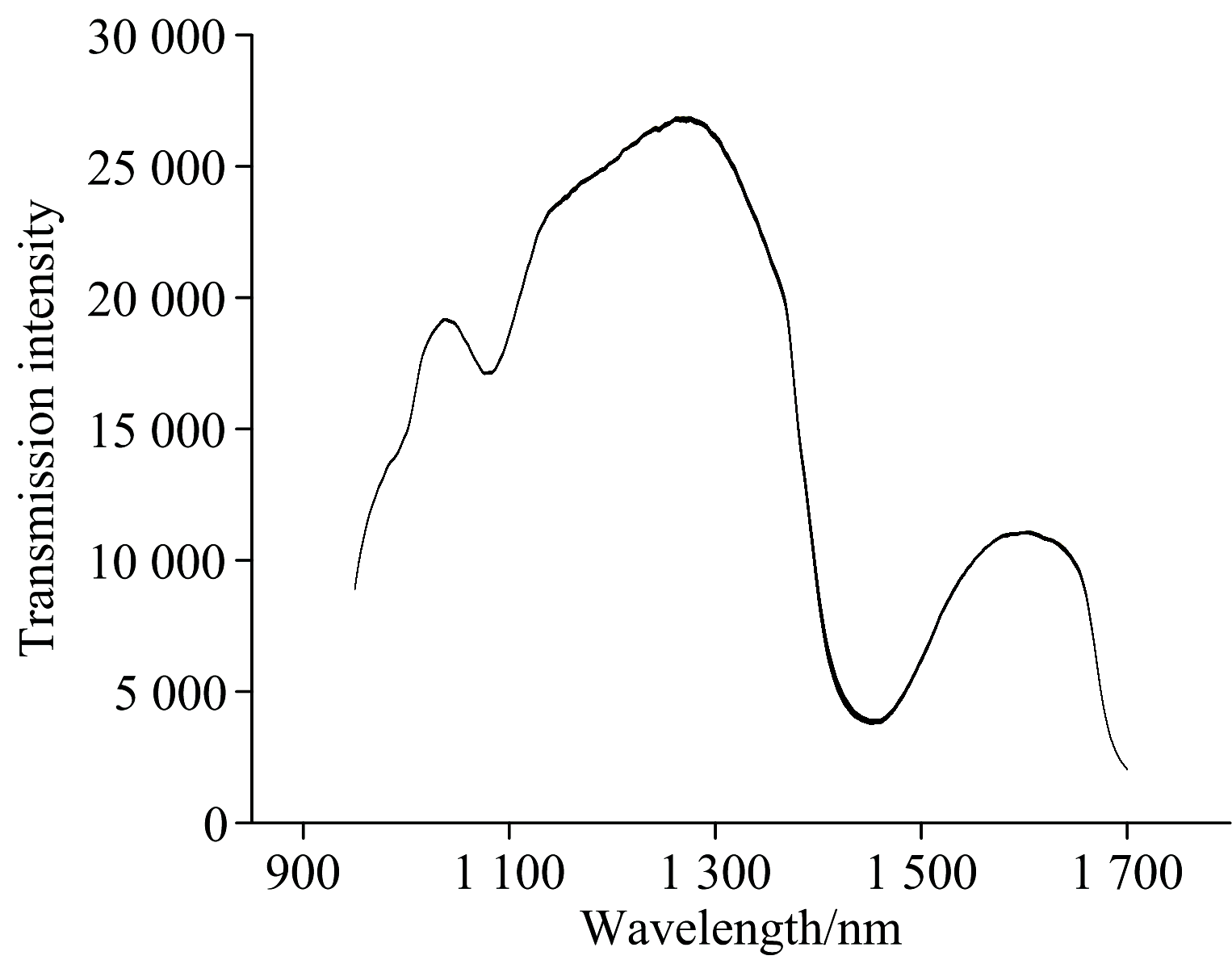 | 图5 反应釜溶液透射光谱Fig.5 Transmission spectrum of the solution in the reactor |
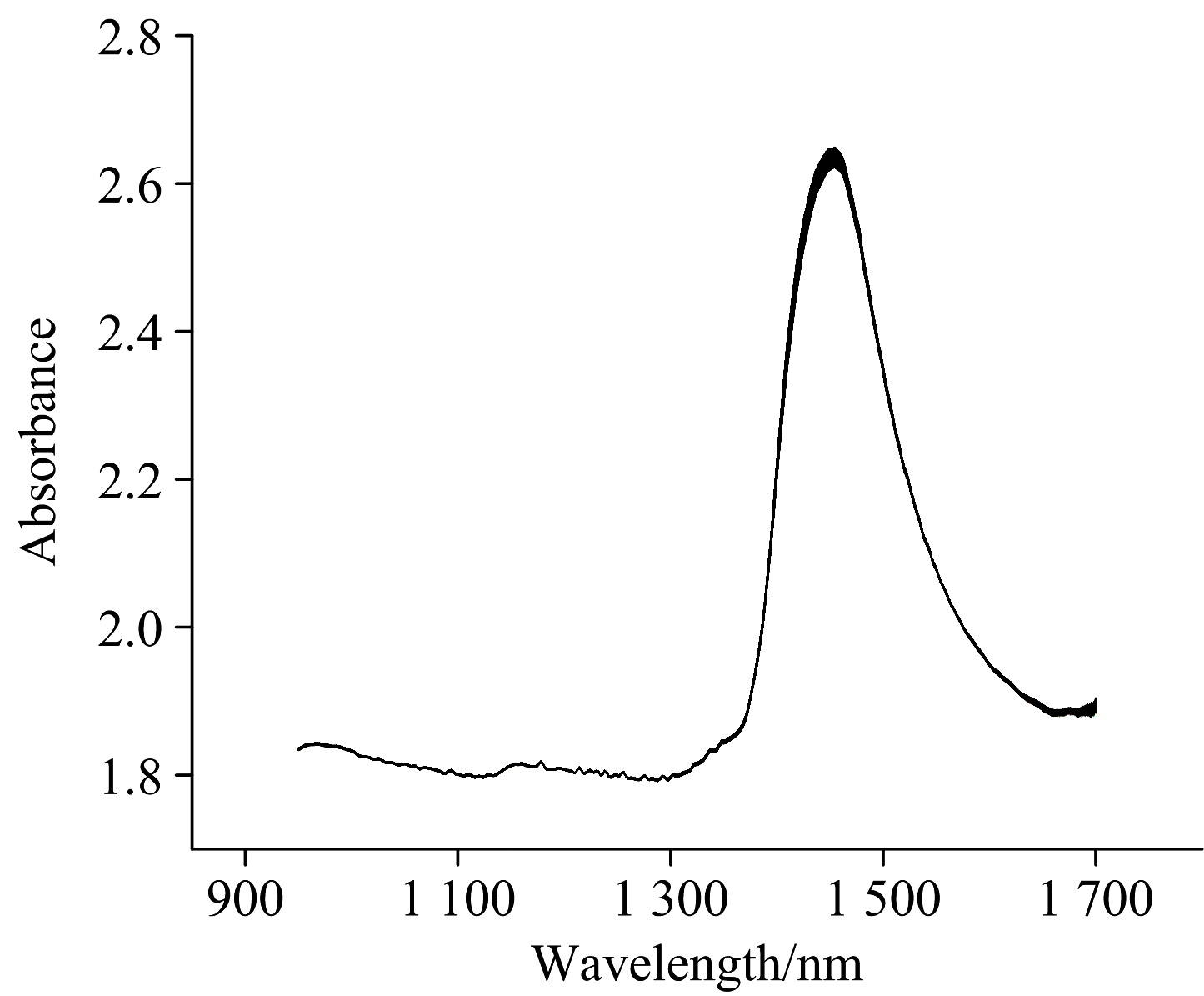 | 图6 反应釜溶液吸光度Fig.6 Absorbance spectrum of the solution in the reactor |
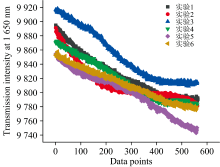
图7展示了六轮实验在1 650 nm波长点处的透射光谱强度随实验变化的趋势图。 近红外光谱技术准确性来自于此技术对样品内部物理及化学信息的感知[23]。 近红外光的散射和吸收与介质中存在的分子的化学键的分子振动有关。 图中清晰显示, 透射强度从初始强度约9 920逐渐下降至约9 760, 变化幅度约1.6%, 表明样品对该波段的吸收增强。 透射光谱总体呈下降趋势, 局部存在轻微波动, 表明实验过程中样品对该波长近红外光的吸收持续增强。 虽然水分子在此波段也有贡献, 但1 650 nm处透射强度呈现独立的下降趋势(对应吸光度上升, 图8)。 补料泵入导致浓度增加, 透射下降趋势与酒石酸累积相关, 不同轮次间分化反映实验操作细节的影响。 乙醇和葡萄糖的干扰在此波段较弱, 强化了酒石酸检测的特异性。 结合酒石酸分子中含有的羧基和羟基基团, 可以认为酒石酸浓度的增加是导致该波段吸收增强的重要因素之一。 不同轮次间的透射强度分布存在重叠但有分化, 反映了实验操作细节(如补料添加的微小时间差异)对光谱特征的微弱影响。
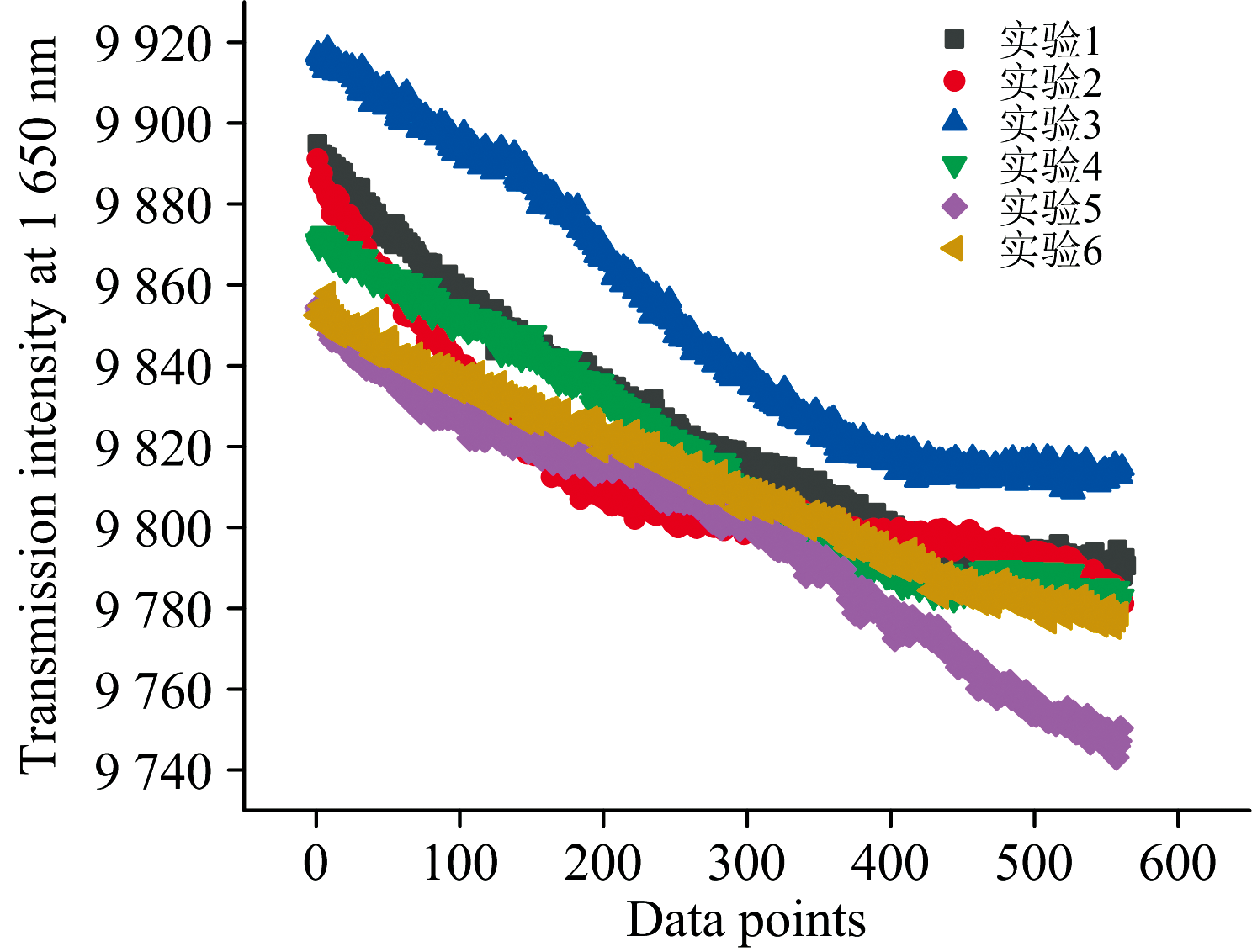 | 图7 1 650 nm波长点光透射谱强度变化Fig.7 Transmission spectral intensity variation at 1 650 nm |
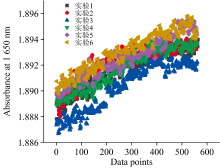
 | 图8 1 650 nm波长点吸光度变化Fig.8 Absorbance variation at 1 650 nm in the reactor solution |
图8展示了1 650 nm处吸光度(基于图8透射强度和背景光谱计算)随实验的变化, 可以看到, 吸光度随实验进行而逐渐增加, 与酒石酸浓度增加一致。
在训练该神经网络模型时, 采用带权重衰减的自适应矩估计(adaptive moment estimation with weight decay, AdamW)作为优化器, 学习率初始值设置为0.001。 损失函数选用均方误差作为优化目标, 批量大小固定为32。 最大训练轮数设置为500轮, 同时实施双重早停机制。 学习率调度策略采用平台自适应学习率调整(reduce learning rate on plateau, ReduceLROnPlateau), 当验证损失连续200轮无改善时, 学习率衰减为原来的50%(衰减因子0.5)。
图9分别展示了利用前四轮实验吸光度数据(训练集∶ 测试集=7∶ 3)构建的偏最小二乘回归(PLSR)模型和CNN-FSA在训练集和测试集上的回归性能散点图。
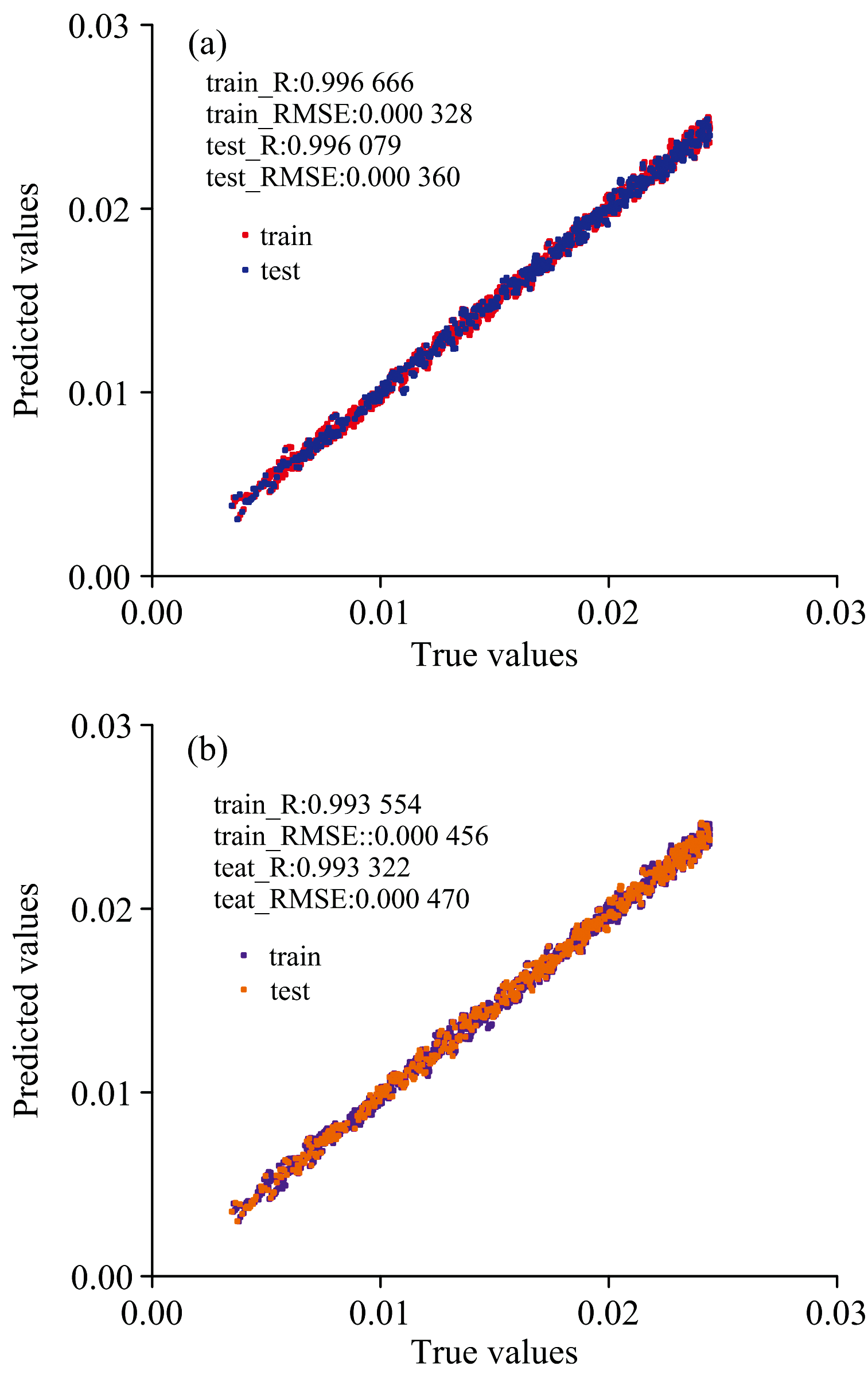 | 图9 (a) PLSR模型拟合回归曲线; (b) CNN-FSA模型拟合回归曲线Fig.9 (a) Fitted regression curves of the PLSR model; (b) Fitted regression curves of the CNN-FSA model |
表1的模型性能对比表明两模型的预测值与实际观测值均高度相关, 散点紧密分布在理想拟合线附近。 无论是训练集还是测试集, R2值均较高, RMSE和MAE值较低, 表明两种模型对训练数据均具有极强的拟合能力, 在内部测试集上也表现出优异的预测精度, 且两者性能接近。
| 表1 两种模型在训练集和测试集上的拟合效果对比 Table 1 Comparative fitting performance of PLSR and CNN-FSA models on training/test sets |
图10展示了基于两轮独立预测数据的偏最小二乘回归(PLSR)和卷积神经网络模型的预测性能。 真实值和预测值随时间呈一致上升趋势, 值域为0.000~0.025, 反映了实验过程中酒石酸浓度的动态变化。 表2列出了PLSR和CNN-FSA两种模型对独立预测数据的评价指标。 PLSR模型的决定系数(R2)为0.968 750, 均方根误差(RMSE)为0.001 214, 平均绝对误差(MAE)为0.001 059; CNN-FSA模型的R2为0.989 558, RMSE为0.000 702, MAE为0.000 580。 相比之下, CNN-FSA模型通过卷积结构和注意力机制有效捕捉光谱中的非线性特征, 预测精度显著优于PLSR模型(RMSE降低42.17%, MAE降低45.23%)。
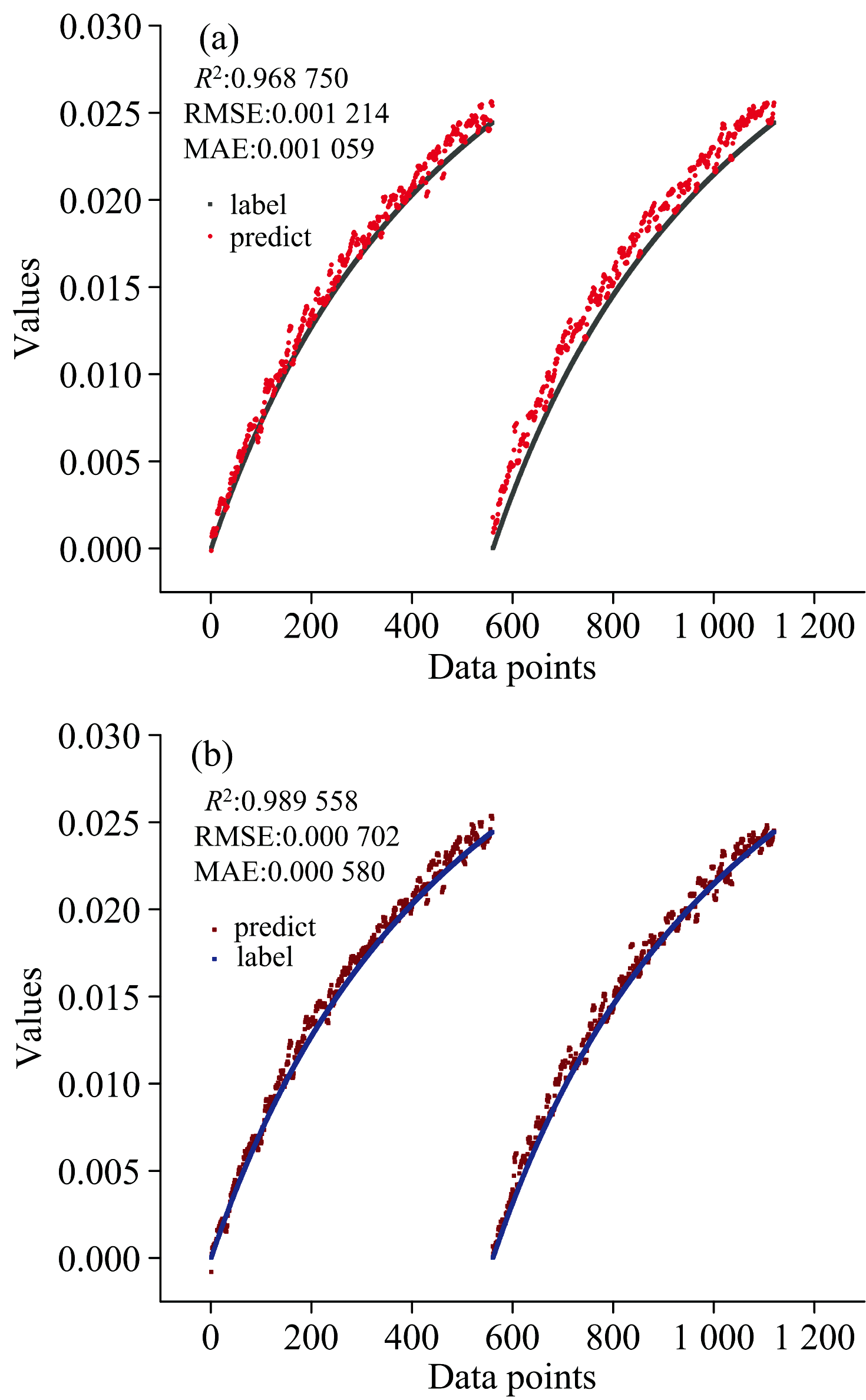 | 图10 (a) PLSR模型预测结果; (b)CNN-FSA模型预测结果Fig.10 (a) Predicted results of the PLSR model; (b) Predicted results of the CNN-FSA model |
| 表2 PLSR和CNN-FSA两种模型在预测样本上的预测效果对比 Table 2 Comparative prediction performance of PLSR and CNN-FSA models on the prediction set |
图11展示了PLSR和CNN-FSA模型在独立预测数据集各样本的绝对误差及其平均绝对误差(MAE)。 结果表明, CNN-FSA模型的MAE为0.000 580, 最大误差为0.002 363; PLSR模型的MAE为0.001 059, 最大误差为0.003 594。 CNN-FSA模型的误差波动总体小于PLSR模型, 表明CNN-FSA在独立预测数据上的精度上优于传统的PLSR。
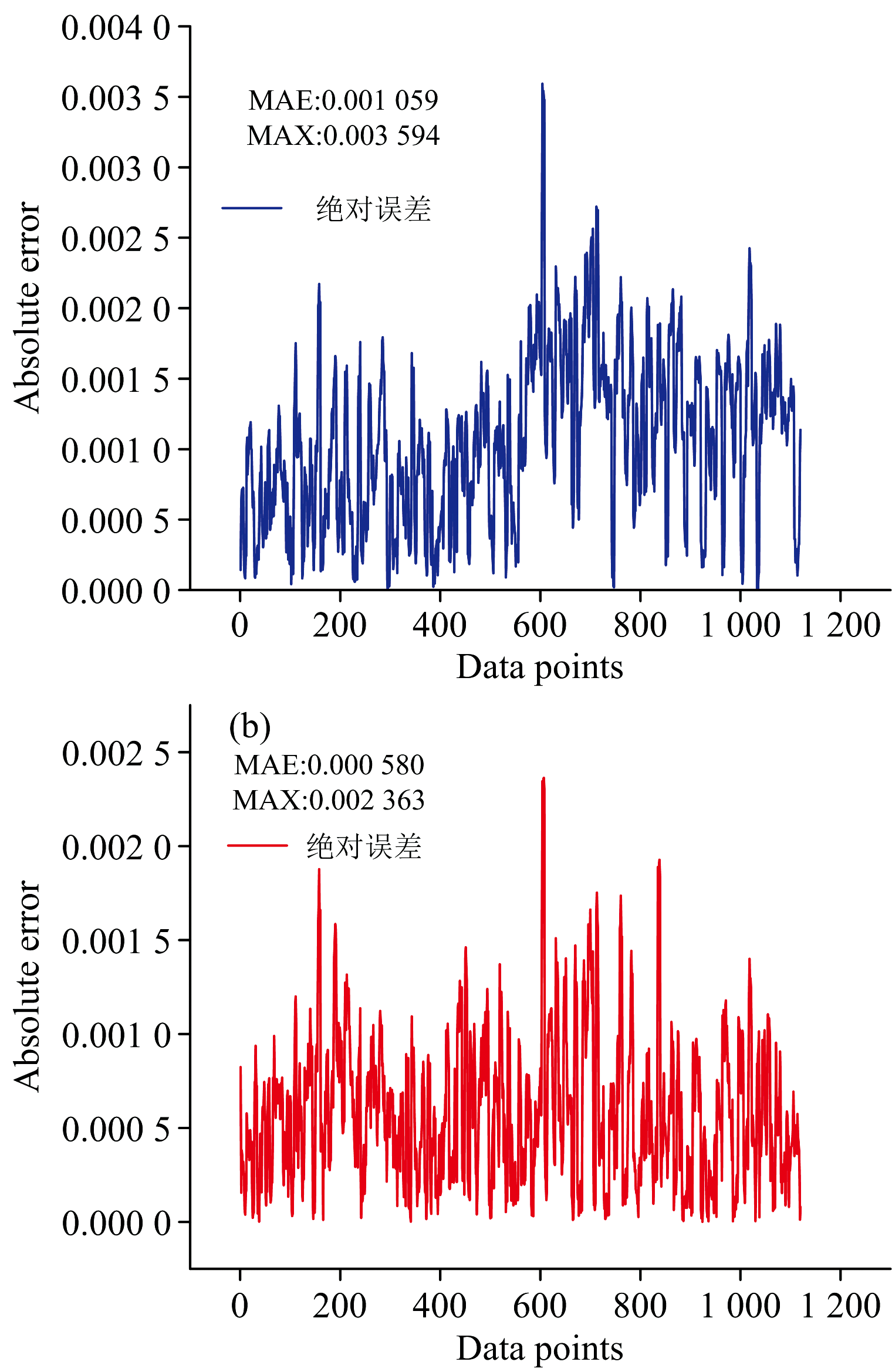 | 图11 (a) PLSR模型预测样本绝对误差; (b) CNN-FSA模型预测样本绝对误差Fig.11 (a) Absolute prediction errors of the PLSR model samples; (b) Absolute prediction errors of the CNN-FSA model samples |
针对近红外光谱分析在溶液体系关键参数监测中的非线性建模挑战, 提出了一种融合一维卷积神经网络(1D-CNN)与特征空间注意力机制(FSA)的CNN-FSA卷积神经网络模型。 通过六轮酒石酸浓度在线检测实验的系统验证, 在完全独立的预测集上, CNN-FSA模型取得R2=0.989 6、 RMSE=0.000 702、 MAE=0.000 580的优异性能。 与经典PLSR模型(R2=0.968 8, RMSE=0.001 214, MAE=0.001 059)相比, 其预测绝对误差降低幅度超过45%。 结果表明, CNN-FSA模型在捕捉近红外光谱与酒石酸浓度之间复杂非线性关系上具有优势。 该优势主要源于: CNN-FSA对光谱局部特征的强大提取能力; 特征空间压缩层在降维的同时保留了关键信息; 特征空间注意力机制能够动态聚焦于关键化学特征。 该研究结合SNV预处理有效提升了模型对高维 NIRS数据的适应性。 本研究为基于近红外光谱的酒石酸浓度检测精准在线快速监测提供了一种有效的参考方法, 并初步验证了特征空间注意力机制在复杂光谱定量分析中的应用潜力。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|