




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于机器学习的手持式LIBS对黑粉的快速分类
[陈楠1, 2, *  , 邹招华
, 邹招华1 , 罗兹循1 , 沈新建1 , 刘燕德1, 2 ]
, 邹招华|
|


作者简介: 陈 楠, 1992年生, 华东交通大学讲师 e-mail: chennan@ecjtu.edu.cn
随着新能源汽车及储能装置的快速发展, 废弃锂电池数量激增。 黑粉作为电池回收过程中最关键的材料, 其成分复杂、 种类繁多, 若不能有效识别与分类, 极易造成资源浪费和环境污染。 传统检测方法存在耗时长、 成本高等局限性, 难以满足工业化场景对黑粉实时分类的需求。 激光诱导击穿光谱技术(LIBS)凭借多元素同步检测、 快速、 高效等优势, 为黑粉快速识别提供了新思路。 本研究将手持式LIBS光谱仪与机器学习算法相结合, 实现对废旧锂电池黑粉的精准识别与高效分类。 首先从赣州浩海新材料有限公司购买九种常见锂电池黑粉样品, 通过手持式LIBS仪对黑粉样品进行光谱采集; 为提升光谱数据的质量与后续建模的准确性, 采用最大最小归一化(MMN)、 Savitzky-Golay平滑滤波(SG)对LIBS光谱数据进行预处理优化; 将预处理后的光谱数据进行降维处理, 分别引入主成分分析(PCA)与线性判别分析(LDA)这两种数据降维方法; 最后, 基于降维后的光谱数据, 分别建立随机森林(RF)、 偏最小二乘判别分析(PLS-DA)和反向传播神经网络(BPNN)三类分类模型; 从测试集的分类准确率、 精确率、 召回率和F1得分四个方面进行比较, 选择最优黑粉分类模型。 实验结果显示, 采用线性判别分析(LDA)与反向传播神经网络(BPNN)相组合的方式所构建的分类模型, 展现出了最为优异的识别性能, 测试集的总体准确率高达99.70%。 验证了LIBS技术结合机器学习方法在锂电池黑粉识别中的可行性与有效性, 为废弃锂电池黑粉的高效分类与再利用提供了理论基础和实用价值。
With the rapid development of new energy vehicles and energy storage devices, the number of waste lithium batteries has surged. Black mass, as the most critical material in the battery recycling process, has a complex and diverse composition, which is very likely to cause resource waste and environmental pollution if it cannot be effectively identified and categorized. Traditional detection methods are time-consuming and costly, making it difficult to meet the demand for real-time classification of black mass in industrialized scenarios. Laser-induced breakdown spectroscopy (LIBS) offers a new approach for rapid identification of black mass, leveraging its advantages of simultaneous multi-element detection, rapidity, and high efficiency. In this study, a handheld LIBS spectrometer is combined with machine learning algorithms to achieve accurate identification and efficient classification of black mass from used lithium batteries. The experiment firstly purchased nine common lithium battery black mass samples from Ganzhou Haohai New Material Co., Ltd. and collected the spectra of the black mass samples by a handheld LIBS instrument; In order to improve the quality of spectral data and the accuracy of the subsequent modeling, maximum and minimum normalization (MMN) and Savutzky-Golay smoothing filter (SG) were used to optimize the preprocessing of LIBS spectral data; In the feature extraction stage, the pre-processed spectral data were subjected to dimensionality reduction by introducing two data dimensionality reduction methods, Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA), respectively; Finally, three types of classification models, namely, Random Forest (RF), Partial Least Squares Discriminant Analysis (PLS-DA) and Back Propagation Neural Network (BPNN), were established based on the dimensionality-reduced spectral data; The optimal black mass classification model is selected by comparing four aspects: classification accuracy, precision, recall and F1 score of the test set. The experimental results show that the classification model constructed using a combination of Linear Discriminant Analysis (LDA) and a Backpropagation Neural Network (BPNN) achieves the best recognition performance, with an overall accuracy of 99.70% on the test set. The results validate the feasibility and effectiveness of LIBS technology combined with machine learning methods for identifying lithium battery black mass, providing a theoretical basis and practical value for the efficient classification and reuse of waste lithium battery black mass.
锂离子电池具有自放电率低、 能量密度高、 循环性能好等优势, 已成为电动汽车、 新能源以及储能装置等领域的首选储能解决方案。 随着全球对可再生能源的需求不断增长以及电动汽车产业的快速发展, 各行业对锂电池的需求持续增长。 据国家数据统计局最新数据显示, 截至2024年12月锂离子电池产量达到294.57亿只, 同比增长8.4%。 然而锂离子电池属于易耗品, 动力锂离子电池的平均使用寿命为5至8年。 伴随着新能源产业的持续发展, 退役锂电池的数量也随之快速增加。 若不妥善处理这些废旧锂电池, 将造成严重的环境污染和资源损失。 废旧锂电池含有电解液、 重金属、 隔膜等污染物, 同时也含有锂(Li)、 镍(Ni)、 钴(Co)、 锰(Mn)等有价金属。 对废旧锂电池进行高效的回收再利用, 兼具稀有金属资源再利用和环境保护双重意义。 近年来, 物理回收和化学回收[1]等退役锂电池回收相关技术快速发展, 不同回收技术的原材料均为将废旧锂电池经过机械粉碎和筛分而获得的锂电池黑粉, 但废旧锂电池类型多样, 包括钴酸锂(LiCoO2)、 锰酸锂(LiMn2O4)、 磷酸铁锂(LiFePO4)、 三元锂(LiNi1-x-yCoxMnyO2)等, 不同类别锂电池黑粉粉末外观相似, 难以直接进行识别。 快速、 准确对退役锂电池黑粉进行识别分类, 可以为黑粉回收价格评估、 回收生产工艺选择、 二次资源综合利用提供有意义的参考。
当前广泛应用的元素分析技术主要包括电感耦合等离子体光谱法(ICP-OES)[2]、 X射线荧光法(XRF)[3]、 原子吸收光谱法(AAS)[4]等。 尽管上述方法在元素的定性分析具有较高的精度和可靠性, 但普遍存在检测效率低、 仪器系统笨重复杂等问题, 导致其在回收场景难以适配。 例如, 针对锂电池黑粉在回收现场进行快速成分解析, 往往要求检测设备兼具便携化与即时分析能力, 而上述方法均难以满足需求。 激光诱导击穿光谱技术(laser-induced breakdown spectroscopy, LIBS)具有检测速度快、 多元素同时分析, 无需对样品进行预处理等优势[5], 已广泛应用于金属冶炼[6]、 化学工业[7, 8, 9]、 食品安全[9, 10, 11]以及地质分析[12]等领域, 然而使用LIBS实现锂电池黑粉种类的鉴别还未见相关报道, 有待进一步探索。
本研究采用手持式LIBS仪采集各类锂电池黑粉材料的光谱数据, 并分别采用主成分分析(principal component analysis, PCA)与线性判别分析(linear discriminant analysis, LDA)方法对光谱数据进行全谱降维, 在此基础上, 结合机器学习方法构建多个分类模型用于锂电池黑粉材料识别, 并通过分类评价指标对其分类精度和稳定性进行了比较分析。 结果表明, LIBS结合机器学习可高效识别不同类别的锂电池黑粉, 在锂电池黑粉回收领域展现出广阔的应用前景。
实验使用成都艾立本科技有限公司的手持式LIBS仪, 如图1所示。
 | 图1 实验仪器示意图Fig.1 Schematic diagram of experimental device |
该仪器采用带有图形用户界面的Android系统, 触摸屏控制面板用于控制光谱仪和采集设置。 数据点中的平均光谱数和采集门宽度可以根据实际情况进行更改。 由随仪器配送专用充电器充电, 也可在电池拆下后单独对电池充电。 所采用的激光器为1 535 nm铒玻璃脉冲激光器, 光谱仪的波长范围为185~680 nm, 光谱分辨率约为0.2 nm。 最高脉冲频率为10 Hz, 单脉冲能量为1 mJ。 为了获得最佳的光谱强度和信噪比, 采样延长设置为1 μ s, 积分时间为1 ms。
主要以锂电池回收过程中产生的黑粉为检测对象, 从赣州浩海新材料有限公司购买九种常见锂电池黑粉样品, 分别为镍钴铝酸锂(NCA)、 富锂锰基(LRMO)、 锰酸锂(LMO)、 磷酸锰铁锂(LMFP)、 钴酸锂(LCO)、 磷酸铁锂(LFP)、 以及高镍三元锂(NCM811)、 中镍三元锂(NCM622)、 常规镍钴锰三元锂(NCM523)。 由于样品为粉末状, 若直接对粉末样品进行烧蚀, 易产生严重的粉尘飞溅, 导致每个激光脉冲作用在样品表面的能量不一致, 进而影响光谱采集效率, 并可能污染采集光路[13]。 因此, 利用仪器配套的专用压片装置对黑粉粉末进行压片处理以提高测试的稳定性和准确性。 首先使用分析天平量取, 每个样品总质量为1 g, 误差控制在± 0.005 g以内, 再利用压片装置压成圆片状。 为评估样品制备过程的稳定性, 我们对典型元素谱线的光谱强度进行了多次重复测量, 并计算相对标准偏差(RSD)。 结果显示, 所有选定谱线的RSD均低于10%, 表明光谱信号具有良好的重复性, 压片工艺对实验结果的影响较小。
各类别黑粉分别压制25个样品, 共制备225个样品。 对样品随机取20个不同位置采集LIBS光谱, 使用LIBS仪对同一位点连续发射10次脉冲激光, 前2次激光脉冲用于对样品表面进行烧蚀清洗, 对后8次脉冲激光获得的光谱进行积分得到一张光谱, 共计获得4 500个光谱数据。 样品制备完成后取下手持式锂材料快速检测仪探头保护盖, 将压片样品置于压片样品磁吸限位器, 短按触发扳机按钮, 即开始分析样品。 最后利用type-c型USB接口接连外部存储设备将数据导出。 将4 500张光谱数据按样品的种类7∶ 3的比例进行分层抽样进行随机划分, 确保训练集与测试集中各类样本均匀分布。
1.3.1 数据预处理
为降低仪器不稳定性及环境干扰等因素对LIBS光谱采集结果的影响, 采用三阶Savitzky-Golay平滑滤波器, 测试了不同窗口(11— 101)的Savitzky-Golay的平滑效果, 如图2。 结果显示较小窗口能更好保持峰形, 但较大窗口能显著提高整体SNR和数据稳定性, 综合考虑信噪比提升与后续分类性能最终选择使用窗口宽度为61对光谱进行平滑处理, 以提高其信噪比和平滑度。 随后采用最大最小归一化(maximum and minimum normalization, MMN)方法对光谱进行归一化处理, 以提高数据的稳定性和可比性; 再利用反归一化还原预测结果。 如式(1)和式(2)
$x^{\prime}=\frac{x-x_{\min }}{x_{\max }~-~x_{\min }~~} $(1)
$x=x^{\prime} \times\left(x_{\max }-x_{\min }\right)+x_{\min ~~}$(2)
式(1)和式(2)中, xmin和xmax分别表示光谱数据中的最小值和最大值, x是指原始数据。
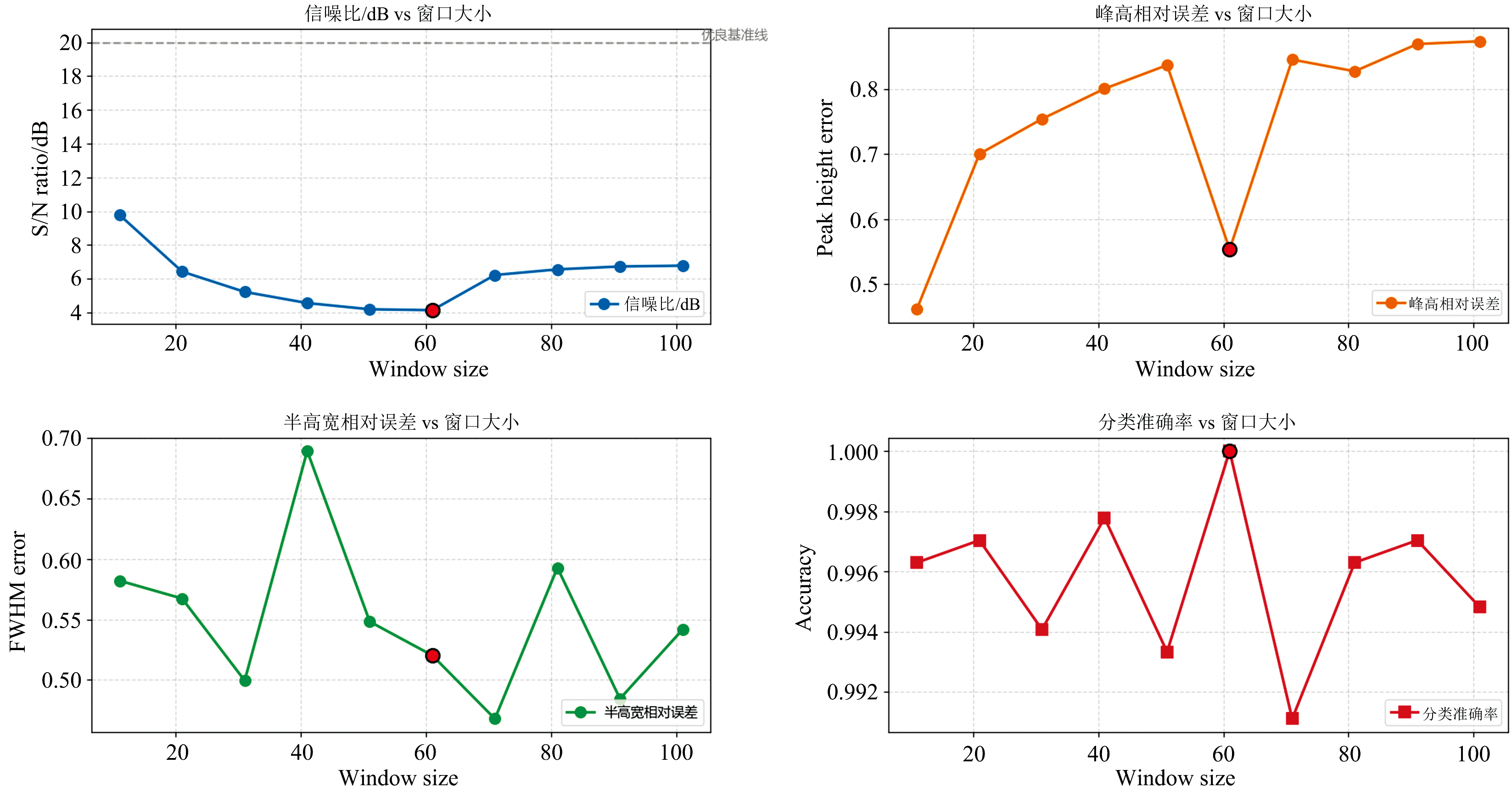 | 图2 SG平滑窗口大小对光谱信噪比、 特征参数稳定性及分类准确率的影响Fig.2 Effect of SG smoothing window size on spectral signal-to-noise ratio (S/N ratio), feature parameter stability, and classification accuracy |
1.3.2 反向传播神经网络
反向传播神经网络(back propagation neural network, BPNN)[14]是一种典型的多层前馈式人工神经网络模型, 能够自动提取复杂特征, 其模型结构如图3所示。 其核心思想在于结合前向传播和误差反向传播机制, 通过迭代优化权重参数, 使得网络能够通过误差反馈自主调整特征提取方式, 最终构建出符合预定精度要求的输入-输出映射关系。 该模型在结构上采用分层架构, 由相互连接的输入层、 隐含层和输出层构成, 各层神经元之间通过可调权值实现信号的前向传播。
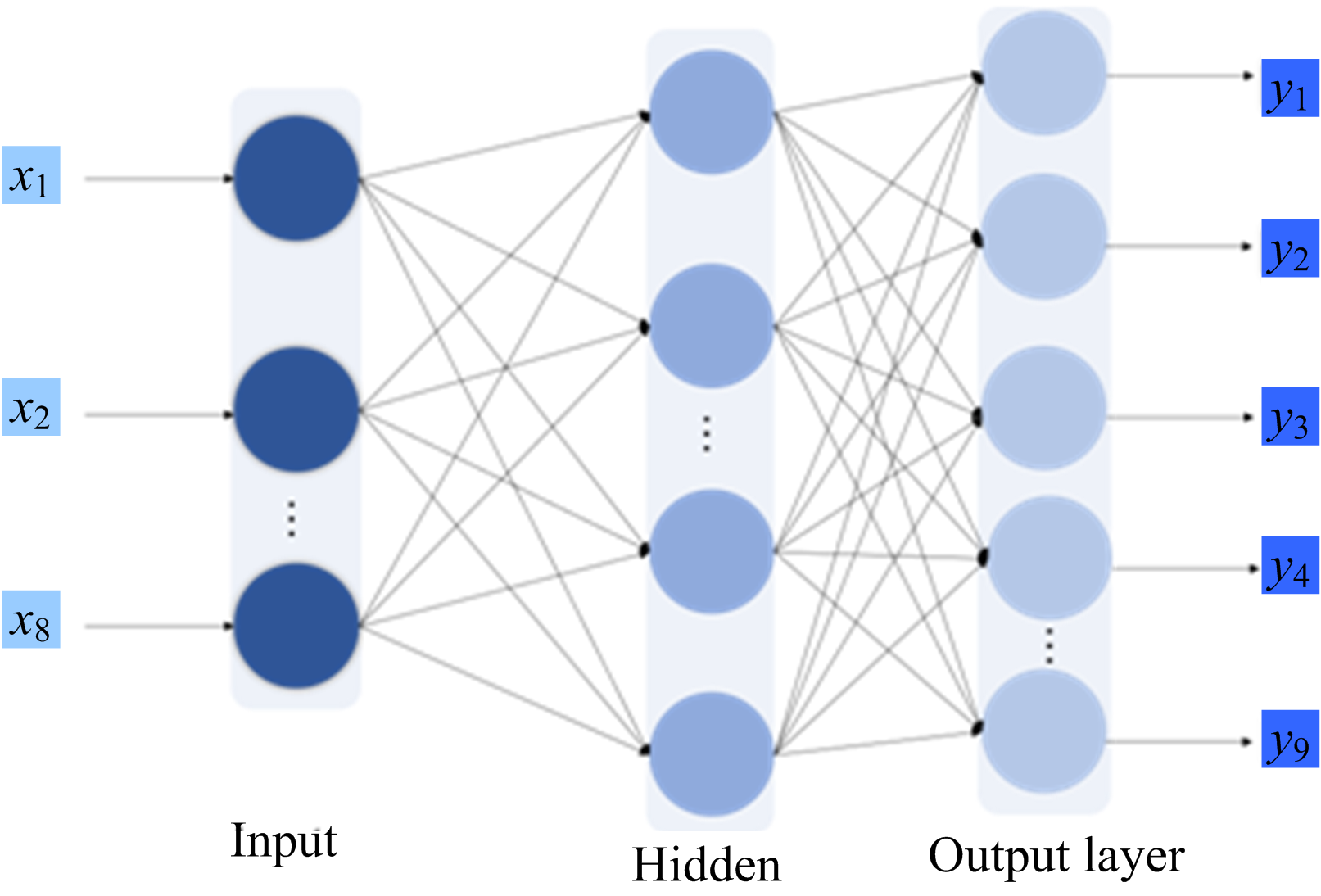 | 图3 BPNN模型结构图Fig.3 BPNN model structure diagram |
在网络结构优化过程中, 利用五折交叉验证比较单层、 双层和三层隐藏层结构, 并对单层神经元数按5、 10、 15、 …、 40(共8种)进行逐一进行测试。 对每种结构与配置均进行五折交叉验证结果如表1。 单层结构最优精度与双层, 三层结构差别不大, 同时所需计算效率相对较高, 基于验证结果与模型简洁性原则, 最终选择单隐藏层且神经元数为10的配置作为最优结构。 其输入层为降维后的输入特征(8维), 隐含层包含十个具有tansig激活函数的神经元, 利用隐含层进行计算, 提取高层次特征; 输出层包含9个神经元, 使用softmax激活函数对类别概率进行建模, 训练时结合交叉熵损失函数进行优化。 再通过误差计算交叉熵损失(cross-entropy loss)并进行反向传播更新权重使得梯度下降, 最后通过不断地迭代训练直到收敛。 经过多次实验得出参数设置的最优选。 将最大训练轮数设置为6 000, 目标误差为0.000 001, 学习率设为0.001。
| 表1 网络结构优化 Table 1 Network structure optimization |
1.3.3 随机森林(RF)和偏最小二乘(PLS-DA)
为衡量BPNN分类模型的性能, 将其与随机森林(random forest, RF)和偏最小二乘判别分析(partial least squares discriminant analysis, PLS-DA)典型分类模型进行比较。 随机森林是一种集成学习方法, 通过投票地方式进行最终预测。 从原始数据集中随机有放回地抽取多个子集, 每个子集用于训练一棵决策树。 在每个决策树的分裂过程中, 仅从全部特征中随机选择部分特征, 以增强多样性, 避免树之间的相关性过高[15]。 将树的数量设置为40, 每个叶子节点的最小样本数为1, 树的深度由数据特征自适应决定。 偏最小二乘判别分析法(PLS-DA)是基于偏最小二乘回归的分类方法, 将高维输入数据降维从而提取与类别最相关的特征, 然后建立线性回归模型将输入变量映射到类别标签, 最后利用回归结果来进行分类[16]。 在模型训练过程中, 针对各分类模型的超参数进行优化, 以提升分类模型的性能。
为评价各分类模型对黑粉样本分类以及整体分类的性能, 采用混淆矩阵来计算准确率(Accuracy)、 精确率(Precision)、 召回率(Recall)和F1得分(F1-score)评估指标, 以衡量分类模型的整体性能[17]。 一般来说, 这些数值越高, 模型的性能越好。 各评价指标如式(3)— 式(6)所示
$\text { Accuracy }=\frac{\displaystyle\sum_{i=1}^{n} T_{i}}{\displaystyle\sum_{i=1}^{n} T_{i}+\displaystyle\sum_{i=1}^{n} F_{i}} \times 100 \% $(3)
$\text { Precision }=\frac{T P}{T P+F P~~}$(4)
$\text { Recall }=\frac{T P}{T P+F N~~}$(5)
$\text { F1-score }=\frac{2 \times \text { Recall } \text { × Precision }~~~}{\text { Recall }+ \text { Precision }}$(6)
式(3)— 式(6)中, Ti是正确分类到第i类的样本数量, Fi是错误分类到第i类的样本数量。 TP是模型正确预测为正例的数量。 TN是模型正确预测为负例的数量。 FP是模型错误预测为正例的数量。 FN是模型错误预测为负例的数量。 本研究所有算法都是在MatlabR2022b环境下运行的。 计算机的配置为Intel(R) Core(TM) i7-1065G7 CPU @1.30 GHz 1.50 GHz。
实验中所采集的9种不同类型锂电池黑粉样品的LIBS光谱图如图4所示。 根据美国国家标准与技术研究院(NIST)数据库, 可以确定样品光谱中具有代表性物质元素的发射谱线波长, 其中主要包含Fe Ⅱ (238.20、 261.19和373.71 nm)、 Al Ⅱ (266.00、 281.62和466.30 nm)、 Co Ⅱ (228.62、 238.89和258.03 nm)、 Mn Ⅱ (257.61、 259.37和260.57 nm)、 Ni Ⅱ (222.29、 231.60和241.94 nm)、 Li Ⅱ (323.26和610.36 nm)、 O Ⅱ (372.60和373.59nm)、 Mg Ⅱ (280.272 7 nm)、 Ca Ⅱ (393.37和396.85 nm)等元素特征谱线。 黑粉样品的不同元素谱线之间存在重叠现象, 即谱线干扰现象。 这主要是由于光谱仪分辨率不足, 导致的相近波长谱线无法有效分离。 同时, 由于黑粉的光谱特征复杂且包含大量的噪声和冗余信息, 也会极大影响分类精度。 光谱降维能够有效消除光谱中不相关的信息, 提高分析性能。 线性降维方法因其计算过程相对稳定、 结果具有较强可解释性等优势, 被广泛用于光谱数据处理等领域, 主要包括主成分分析(PCA)和线性判别分析(LDA)。 基于此, 选择PCA与LDA对原始光谱数据进行降维, 旨在保留主要信息的同时, 简化模型结构, 提升分类效果。
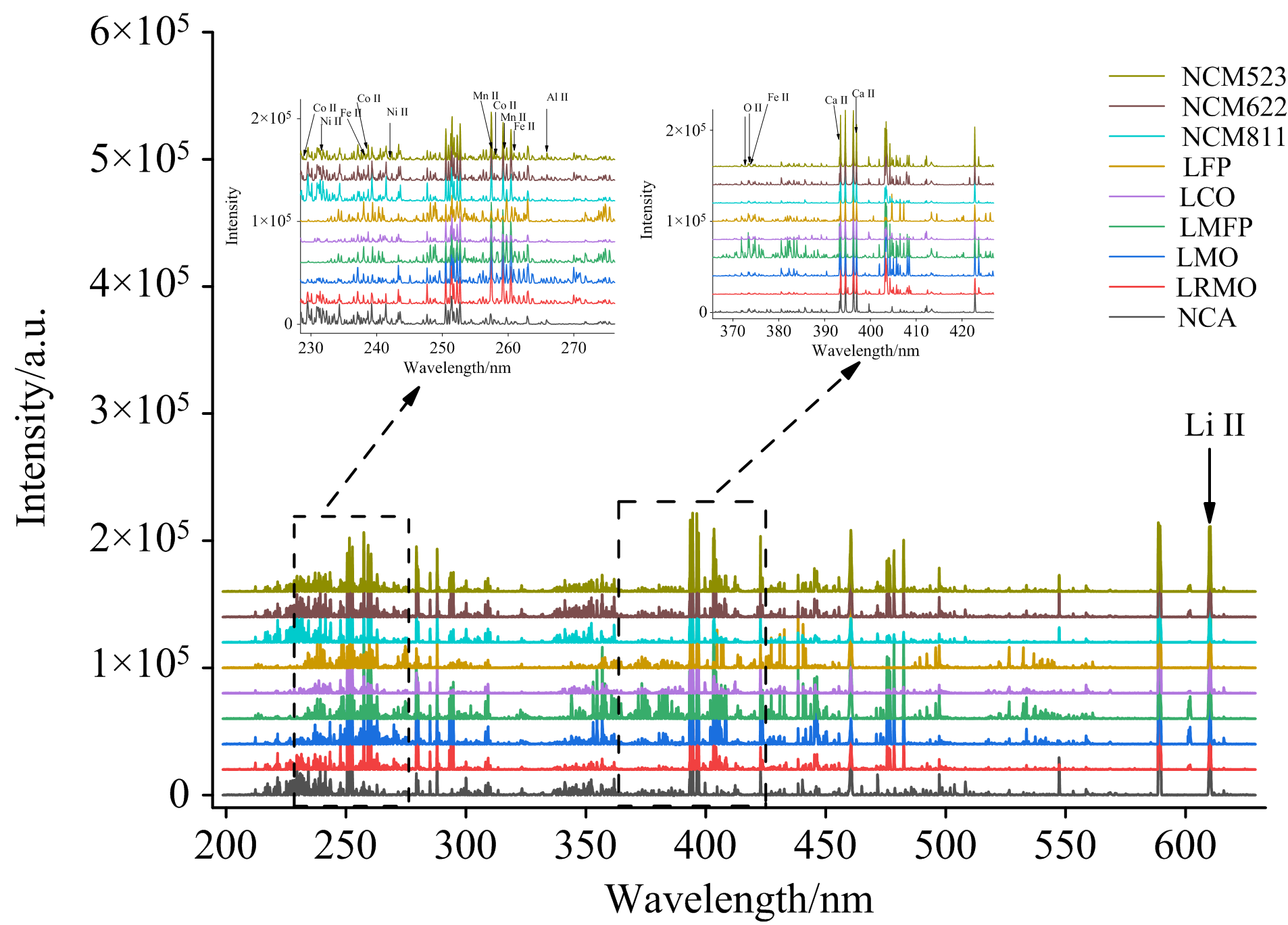 | 图4 九种样品的典型LIBS光谱图Fig.4 LIBS spectra of nine samples |
PCA通过线性变换将原始高维她据投影到低维空间, 同时尽可能保留数据的方差信息[18]。 样品分类的精度取决于主成分选取的个数, 通过计算特征向量与主成分得分实现高维数据的低秩近似, 再利用累计方差解释率(cumulative_variance)评估主成分贡献度, 选取大于等于90%~95%方差贡献率前k维特征实现降维, 经过反复实验, 维数为10的时候效果最好。 LDA作为一种监督降维方法, 其核心目标是寻找最优投影方向, 使得不同类别的样本在低维空间中最大化分离, 同时使同一类别的样本尽可能紧密聚集[19]。 该方法通过优化类间散度矩阵与类内散度矩阵的比值来实现这一目标。 值得注意的是, LDA的降维能力受限于数据类别数量, 若数据包含C个类别, 则最大可降维至C-1维, 最大可降维至8维。
基于黑粉样品的光谱数据, 分别采用PCA和LDA降维方法进行数据降维, 进而构建了PCA_RF、 LDA_RF、 PCA_PLS-DA、 LDA_PLS-DA、 PCA_BPNN和LDA_BPNN分类模型, 分类结果如表1及表2所示。 由表可知, 相较于PCA降维方法, LDA在黑粉光谱数据降维方面表现出更好的性能。 其原因在于, LDA能够有效利用类别标签, 进而更好优化类间分离度和类内紧密度, 使得降维后的数据更具判别力, 进而提升分类性能。 相比之下, LDA_BPNN的分类模型对样品的识别性能最佳更好, 达到99.70%, 其次是LDA_RF分类模型达到98.89%, 这表明BPNN分类模型在黑粉样品识别上具有优越的性能。 而PCA_PLS模型的分类结果最差, 准确率为89.56%。 其原因在于, PCA结合PLS-DA的组合存在信息冗余或丢失。 此外, 它更容易受到异常值、 分布变化的影响。 当变量维度较高或变量间存在较强相关性时, 容易产生过拟合或信息不足的情况, 尤其当提取的主成分维数不恰当时, 更容易丢失关键信息。 而LDA结合RF可以提取出高度判别性的特征, 它属于一种“ 非线性提取+线性判别” 的协作结构, 在实际分类中优于传统线性组合且更能处理高维小样本数据。 同时随机森林对异常值不敏感, 可以自动减弱噪声对模型的影响, 泛化能力更强。
| 表2 九种样品预测结果 Table 2 Prediction results of nine samples |
| 表3 六种模型分类结果 Table 3 Classification results of six models |
| 表4 三元锂电池主要元素含量 Table 4 Major element content in ternary lithium batteries |
为了更好分析BPNN模型的分类性能, 图5展示了LDA_RF和LDA_BPNN两种分类模型测试集的混淆矩阵。 由图5(a)可知, LDA_RF模型的分类错误主要集中在样品7、 样品8和样品9, 分别对应于NCM811、 NCM622与NCM523三种三元锂电池黑粉样品。 其原因在于, 这三类黑粉材料元素成分和含量较为相似, 且手持式LIBS仪本身性能有限, 易导致错误识别。 由图5(b)可知, LDA_BPNN分类模型在处理元素成分相近的三元锂材料分类任务中表现出更强的判别能力。 相比于LDA_RF分类模型, LDA_BPNN模型通过其多层非线性映射结构, 能够更有效地捕捉样本间的深层特征差异, 尤其是在面对高维且复杂的数据分布时展现出更优的学习能力。 此外, BPNN在模型训练过程中可通过反向传播机制持续优化网络权重, 从而提升模型对细微特征差异的敏感性。
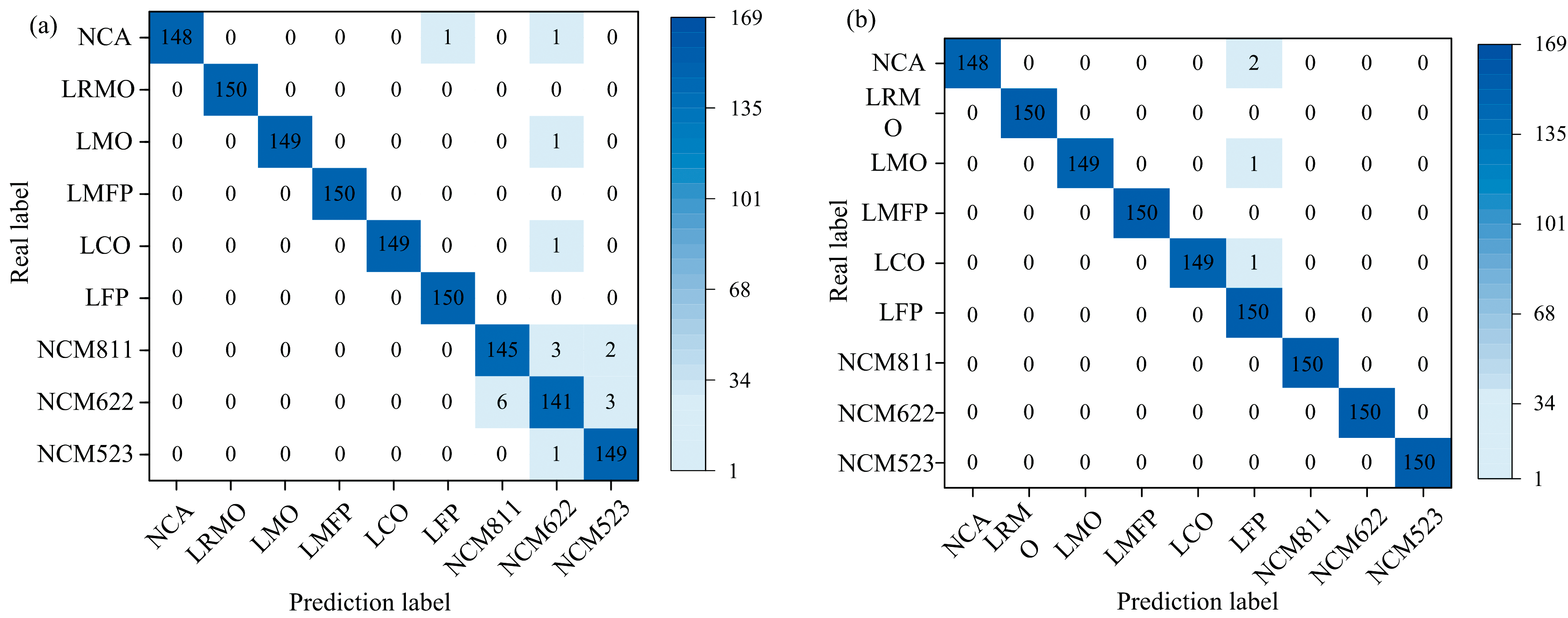 | 图5 不同方法的混淆矩阵对比图 (a): LDA_RF混淆矩阵图; (b): LDA_BPNN混淆矩阵图Fig.5 Comparison of confusion matrices for different methods (a): LDA_RF; (b): LDA_BPNN |
采用便携式激光诱导击穿光谱(LIBS)装置对来源于不同锂电池类型的黑粉样品进行光谱采集与分析, 并结合三阶Savitzky-Golay平滑与最大-最小值归一化方法对原始光谱数据进行预处理, 以提高信号质量和数据稳定性。 基于处理后的光谱数据, 构建了包括PCA_RF、 LDA_RF、 PCA_PLS-DA、 LDA_PLS-DA、 PCA_BPNN和LDA_BPNN在内的六种分类模型, 对不同类别的黑粉样品进行识别分析。 结果表明, LDA_BPNN模型在分类准确率和稳定性方面均优于其他模型, 整体识别准确率达到99.70%。 这表明将LIBS技术结合机器学习方法应用于锂电池中黑粉类别的判定具有良好的可行性, 同时更加高效、 准确、 低成本, 为锂电池中黑粉的分类回收提供了一种新的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|