



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合形态学与优化算法的XRF铁矿石品位定量分析检测方法研究
[王兰豪1  , 朱震宇
, 朱震宇2 , 钟宵3 , 王红艳3, * , 李朝朋4 ]
, 朱震宇, 李朝朋|
|


作者简介: 王兰豪, 1989年生, 中国矿业大学炼焦煤资源绿色开发全国重点实验室副教授 e-mail: wanglanhao@cumt.edu.cn
针对现有X射线荧光光谱(XRF)铁矿石在线品位检测技术受强本底干扰、 谱峰重叠解析困难及建模精度不足制约的问题, 提出覆盖“信号预处理—谱峰分解—品位建模”全流程的解决方案。 在本底扣除环节, 开发融合数学形态学与导数迭代多项式拟合(Mor+DIPF)方法, 在保障特征峰光谱保真度的同时显著提升基线平滑性与拟合精度, 解决传统形态学算法在特征峰区域平滑不足的缺陷。 针对复杂谱峰重叠, 提出自适应参数更新粒子群算法(APU-PSO)联合EM-GMM的分解框架, 通过增强全局寻优能力实现高精度解析, 为后续定量分析提供高精度谱峰参数。 为解决基体效应导致的非线性误差问题, 构建Transformer与双向长短期记忆网络(BiLSTM)融合模型, 利用Transformer捕捉工艺变量间的长距离依赖关系, BiLSTM增强时序动态特征学习, 通过多源数据融合深度提取品位波动关键影响因素, 解决基于XRF铁矿石品位高精度预测瓶颈。 实验结果表明, Mor+DIPF算法在四种不同基线(线性、 正弦、 高斯、 指数)下的均方根误差(RMSE)、 平均相对误差(MAE)和决定系数( R2)均优于传统方法, 其中 R2最高达到99.96%。 APU-PSO-EM-GMM算法在普通重叠峰、 肩部重叠峰和多重叠峰的拟合效果上均优于曲线拟合法、 高斯锐化法等对比算法。 Transformer-BiLSTM模型对钛铁矿品位的定量分析平均绝对误差为0.217 2, 均方根误差为0.280 7, 决定系数达99.716 1%, 性能优于SVM、 Transformer等模型。 该系统已在沈阳某选矿厂应用6个月以上, 在设定3%相对误差范围内的估计合格率均超90%, 展现出高精度、 强实时性与优异鲁棒性的综合优势, 该研究成果为复杂矿物在线分析提供了理论依据与技术范例, 推动XRF光谱分析在工业过程检测领域的智能化应用。
This study addresses the limitations of existing X-ray fluorescence spectroscopy (XRF) technology for the online detection of iron ore grade, including strong background interference, difficulty in resolving overlapping spectral peaks, and insufficient modeling accuracy. It proposes a comprehensive solution that covers the entire process, from signal pre-processing and spectral peak decomposition to grade modeling. In the background subtraction stage, a method combining mathematical morphology and derivative-iterative polynomial fitting (Mor+DIPF) has been developed. This method significantly improves baseline smoothness and fitting accuracy, while also ensuring spectral fidelity in the region of characteristic peaks. This addresses the deficiency of traditional morphological algorithms, which do not sufficiently smooth this region. To address complex peak overlap, a particle swarm optimization (PSO) approach with adaptive parameter updates (APU-PSO) is combined with an expectation-maximization (EM) Gaussian mixture model (GMM) decomposition framework. This enhances global optimization capabilities and enables high-precision analysis, providing accurate peak parameters for subsequent quantitative analysis. To address non-linear errors caused by matrix effects, a fusion model combining transformers and bidirectional long short-term memory networks (BiLSTM) is constructed. Transformers capture long-range dependencies among process variables, while BiLSTMs enhance the learning of temporal dynamics. By fusing multi-source data, key factors influencing grade fluctuations are thoroughly identified, overcoming the challenge of accurately predicting iron ore grades using XRF. Experimental results demonstrate that the Mor+DIPF algorithm outperforms traditional methods in terms of root mean square error (RMSE), mean absolute error (MAE), and coefficient of determination ( R2) across four different baselines (linear, sinusoidal, Gaussian, and exponential), with R2 achieving a maximum value of 99.96%. The APU-PSO-EM-GMM algorithm outperforms the comparison algorithm.
钢铁制品作为国民经济和社会发展的重要基础材料产业, 在社会生产和人民生活中占据着不可或缺的地位[1]。 相关统计数据显示, 全球粗钢年产量已突破18亿吨, 其中中国粗钢产量约为9亿吨, 产量占比接近50%[2]。 尽管我国铁矿石储量较为丰富, 但主要以低品位矿石为主, 且矿石类型复杂多样, 导致开采难度大、 选矿成本高, 同时面临能耗高和生产效率低等技术难题, 这些因素制约了钢铁工业的高质量发展[3, 4]。
目前, 针对铁矿石品位的定量分析研究方案较为丰富, 多集中于传统化学分析方法, 包括ICP-AES法、 EDTA滴定法、 稳健统计法以及碘氟法等[5, 6, 7, 8]。 这些方法虽准确可靠, 但存在操作流程复杂、 分析成本高、 样品预处理繁琐、 分析效率低等问题。 近年来, 基于光谱的分析方法成为研究热点, 其中包括原子吸收光谱法、 原子荧光光谱法和X射线荧光光谱法等[9, 10]。 在这其中, X射线荧光光谱法(X-ray fluorescence, XRF)以其快速的检测速度、 较低的分析成本和广泛的适用元素范围等优点, 成为矿石元素分析的关键工具之一[11], 被广泛应用于环境科学、 化学以及生物学等多个学科领域, 并在一定程度上取代了传统的化学分析方法[12, 13, 14]。
在进行铁矿石元素XRF分析时, 工程师面临三个显著影响分析结果的问题: 背景信号造成的本底干扰、 邻近元素特征峰的重叠, 以及基体效应导致的元素定量分析中的非线性误差, 前两个问题会影响光谱数据的准确性和后续的定量分析结果, 第三个问题则降低定量检测结果精度。 针对上述问题, 本文开展基于XRF的铁矿石品位定量分析方法及系统研究。 首先从形态学方法和迭代多项式拟合算法进行深入研究, 提出了一种基于形态学与导数迭代多项式拟合的本底扣除方法。 其次是在谱线特征峰重叠问题上, 研究者常采用的方法包括曲线拟合法[15]、 导数法[16]、 小波变换法[17], 这些方法在处理谱线重叠问题上得到了广泛应用。 本文从元启发式算法[18]入手, 提出基于自适应参数更新策略的粒子群优化算法, 结合高斯混合模型, 采用EM算法对重叠峰进行解析。 最后在基体效应校正问题上, 选取Transformer融合双向长短时记忆网络实现钛铁矿品位的实时定量分析。
为解决XRF数据易受到外界干扰、 X射线与样品间相互作用等因素影响造成的本底干扰, 提出了一种基于形态学与导数迭代多项式拟合的本底扣除方法, 确保精确获取目标元素的光谱谱峰及其净峰面积。 形态学方法虽能够较好地保留光谱特征, 但在特征峰区域的本底信号平滑处理上仍有待提升; 相比之下, 四阶导数迭代多项式拟合方法在处理平缓变化的本底信号时, 能够更完整地分离特征峰信息, 从而显著提高本底拟合的精确度。
形态学的基本运算包括侵蚀、 膨胀、 开运算和闭运算, 这些运算构成了形态学算法的基础框架。 通过分析信号的局部结构, 这些操作可以有效提取和描述光谱信号中的形态特征。 此过程中, 结构元素Ys被定义为一个以通道地址点i为中心的可移动窗口, 窗口的半宽为Ls(全宽则为2Ls+1), 其中Si表示光谱信号S在第i个通道地址上的值。
侵蚀操作E(Si)定义为
膨胀操作D(Si)定义为
开运算O(Si)定义为
P运算P(Si)定义为
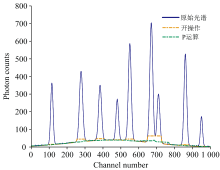
从图1可知, P运算在光谱特征保留方面具有一定优势, 但存在显著不足: 部分区间运算结果高于原始光谱信号; 在谱峰区域易出现强度突变, 导致提取的本底信号平滑性较差。
 | 图1 形态学P运算、 开操作与原始光谱对比示意图Fig.1 Diagram comparing morphological P operation, open operation and original spectrum |
为了提取适用于分析的背景光谱, 本文提出了一种4阶导数迭代多项式拟合方法, 采用多项式展开的方法, 对选定的背景光谱点进行拟合, 并将拟合结果从原始光谱中扣除, 可以获得较为纯净的光谱数据。 对M个点的光谱数据S进行4阶多项式拟合的表达式为
式(5)中, ap(p=0, 1, 2, 3, 4)为多项式的系数; i为光谱的通道地址; f为多项式拟合的光谱值。
计算原光谱数据点与拟合数据点之间的距离平方和
$S_{d}^{2}=\displaystyle\sum_{i=1}^{M}\left[S(i)-f\left(i, a_{0}, a_{1}, \cdots, a_{4}\right)\right]^{2}$(6)
式(6)中, S为原光谱数据, M为光谱的总通道地址数。
Mor+DIPF算法的实现步骤如下:
1) 输入原始光谱数据S, 设置窗口半宽为Ls, 基于形态学算法求侵蚀操作E(Si)、 膨胀操作D(Si)、 开运算O(Si)和P运算。
2) 通过P运算计算得出的光谱背景信号作为新的待拟合光谱信号y0。
3) 基于导数迭代多项式拟合算法对y0进行拟合, 得到最终的光谱背景yn。
4) 将yn从原始光谱数据S扣除即可得到本底信号校正后的纯净光谱信号。
1.2.1 基于EM算法的GMM参数初步解析
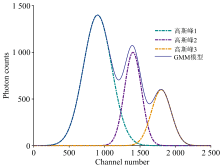
经过光谱数据本底扣除后, XRF光谱中的特征峰可视为一个高斯峰, 重叠峰相当于多个高斯峰叠加构成的高斯混合模型(GMM), 如图2所示。 因此, 重叠峰解析实质上是对GMM模型的解析。 只要能够准确估计GMM模型的参数, 便可完成重叠峰的解析。
 | 图2 GMM模型示意图Fig.2 Schematic diagram of the GMM model |
由于事先不知道XRF光谱重叠峰中的N个数据xN(每个通道数对应的特征X射线强度值)来自某一个高斯特征峰的概率, 而只能得到最终的观测数据, 所以重叠峰数据是含有隐变量的, 适合用EM算法来求解参数, 求解步骤如下:
1) GMM中初始参数θ 由三部分组成: 包括各个特征峰的峰位μ m, 方差
2) 引入隐变量Z
式(7)中, Zi=[Zi1, …Zim, …, Zik], Zim表示第i个光谱数据点属于第m个高斯特征峰的概率, 每一个数据点来源于k个高斯特征峰的概率总和为1, 即$\displaystyle\sum_{m=1}^{k} Z_{i m}=1$。
3) 隐变量Z可以指示重叠峰数据xN属于哪一个高斯特征峰, 这样就能将观测不完整数据转化为完整数据, 用Y表示完整数据[xN, Z], 则完整数据的似然函数可表示为
$P(Y \mid \theta)=\displaystyle\prod_{m=1}^{k} \displaystyle\prod_{i=1}^{N}\left[\pi_{m} N\left(x_{i} \mid \mu_{m}, \sigma_{m}^{2}\right)\right]^{z_{i m}}$(8)
完整数据的对数似然函数为
$\log P(Y \mid \theta)=\displaystyle\sum_{m=1}^{k} \displaystyle\sum_{i=1}^{N} z_{i m}\left(\log \pi_{m}+\log N\left(x_{i} \mid \mu_{m}, \sigma_{m}^{2}\right)\right.$(9)
4) 在E-step中, 目标代价函数可以表示为
$\begin{array}{c}Q\left(\theta, \theta^{t}\right)=\displaystyle\sum_{m=1}^{k} \sum_{i=1}^{N}\left(\log \pi_{m}+\right. \left.\log N\left(x_{i} \mid \mu_{m}, \sigma_{m}^{2}\right)\right) P\left(z_{i m} \mid x_{i}, \theta^{t}\right) \end{array}$(10)
式(10)中, θ t表示第t次迭代估计的参数集。 为了得到代价函数(10), 需要计算隐变量的后验概率P(zim|xi, θ t)。
5) 在上一次迭代参数下, 每个样本数据点xi属于第m个高斯特征峰的后验概率rim可以表示为
$r_{i m}=P\left(z_{i m} \mid x_{i}, \theta^{t}\right)=\frac{\pi_{m}^{t} ~~~N\left(x_{i} \mid ~~\mu_{m}^{t}, \left(\sigma_{m}^{2}~~\right)^{t}\right)}{\displaystyle\sum_{j=1}^{k} ~~\pi_{j}^{t}~~ N\left(x_{i} \mid ~~\mu_{j}^{t}, \left(\sigma_{j}^{2}~~\right)^{t}\right)~~~}$(11)
6) 在M-step中, 最大化目标代价函数更新GMM参数, 这一过程可定义为
将代价函数对GMM参数求偏导, 并令导数为0, 可得到各个参数的新一轮迭代值, 从而完成M步。 每个高斯特征峰的峰位μ m, 方差
$\mu_{m}^{t+1}=\frac{\displaystyle\sum_{i=1}^{N} r_{i m} x_{i}}{\displaystyle\sum_{i=1}^{N} r_{i m}}, m=1, 2, \cdots, k$(13)
$\left(\sigma_{m}^{2}\right)^{t+1}=\frac{\displaystyle\sum_{i=1}^{N} r_{i m}\left(x_{i}-\mu_{m}\right)^{2}}{\displaystyle\sum_{i=1}^{N} r_{i m}}, m=1, 2, \cdots, k$(14)
$\pi_{m}=\frac{1}{N} \displaystyle\sum_{i=1}^{N} r_{i m}, m=1, 2, \cdots, k$(15)
在实际应用中, EM算法是估计高斯混合模型参数的常见方法, 但易受初始参数影响, 易陷入局部最优, 影响重叠峰解析准确性。 因此, 为了提高重叠峰解析的准确性, 还需在EM算法解析重叠峰的初始值参数θ 上做一定的优化。
1.2.2 基于自适应参数更新策略的粒子群优化算法
粒子群优化(PSO)算法因收敛快、 参数少, 适用于重叠峰参数的全局优化, 但传统PSO易早熟收敛, 影响优化效果。 为了提高PSO算法的局部搜索能力和全局搜索能力, 本文在惯性权重w、 个体学习因子c1和社会学习因子c2三个参数上提出自适应更新策略。 基于自适应参数更新策略的粒子群优化算法实现过程如下所示:
1) 设置算法相关参数。 初始化粒子的种群规模P=50; 粒子搜索空间的维度D=3k; 即高斯特征重叠峰的参数θ =[μ 1, μ 2, …, μ k,
2) 通过随机初始化生成粒子位置和粒子速度, 并且根据式(9)的对数似然目标函数计算出每个粒子的适应度值。 将初始化的粒子位置作为个体历史最优值pbest, 将每个粒子适应度值进行排序, 选择最大适应度值所对应的粒子位置作为初始全局最优位置gbest。
3) 自适应调整惯性权重w:
$w=\left\{\begin{array}{ll} w_{\min }-\frac{\left(w_{\max }-w_{\min }~~\right) \times\left(f-f_{\min }~\right)~~~}{\left(f_{\mathrm{avg}}-f_{\min }\right)}, & f \leqslant f_{\mathrm{avg}} \\ w_{\max }, & f> f_{\mathrm{avg}} \end{array}\right.$(16)
式(16)中, f表示当前粒子的适应度值, favg表示粒子群的平均适应度值, fmin表示粒子群的最小适应度值。
4) 个体学习因子c1和社会学习因子c2自适应更新
式中, iter为当前迭代的次数, Max_iter为初始化设置的最大迭代次数。
5) 更新粒子的位置和速度
式中,
6) 计算更新后粒子的适应度值, 并且更新个体最优位置pbest和全局最优位置gbest。
7) 当迭代次数达到设定的最大迭代次数时, 算法停止。 输出全局最优的粒子位置gbest, 即XRF光谱重叠峰中各个特征峰的峰位μ m、 方差
1.2.3 APU-PSO-EM-GMM算法描述
| 表1 APU-PSO-EM-GMM光谱重叠法分解算法伪代码 Table 1 Pseudocode for the APU-PSO-EM-GMM spectral overlap decomposition algorithm |
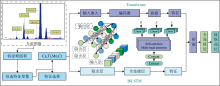
为应对传统基体效应校正方法在钛铁矿品位定量分析中存在的精度有限、 效率偏低等问题, 本文提出一种融合Transformer与双向长短期记忆网络(BiLSTM)的定量分析建模方法。 该模型利用Transformer架构强大的全局特征提取能力, 充分挖掘历史工况变量与实时监测数据间的长距离依赖关系; 同时引入BiLSTM网络结构, 有效增强模型对时间序列双向动态特征的学习能力。 通过对多源工艺变量的动态建模, 该模型能够深度提取影响品位波动的关键特征, 实现对钛铁矿品位的定量分析。 图3展示了XRF 品位检测系统结构框架。
 | 图3 XRF的钛铁矿品位检测方法结构图Fig.3 Structural diagram of XRF titanium iron ore grade detection method |
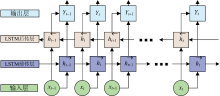
双向长短期记忆网络(BiLSTM)是一种改进型循环神经网络, 其核心原理在于通过同时学习时间序列的正向和反向特征, 提升对时序数据的建模能力。 BiLSTM由两个独立的LSTM层构成: 一个从前向后处理输入序列(前向LSTM), 另一个从后向前处理输入序列(后向LSTM)。 前向LSTM捕捉序列从过去到当前的动态特征, 而后向LSTM则捕捉从未来到当前的动态特征。 通过并行运行这两个LSTM层, BiLSTM 能够分别提取序列的前向和后向上下文信息, 将结果进行融合, 从而全面捕捉序列中的全局特征和依赖关系。 LSTM和BiLSTM的基本结构如图4和图5所示。
 | 图4 LSTM的基本机构Fig.4 Basic structure of LSTM |
 | 图5 BiLSTM的基本机构Fig.5 Basic structure of BiLSTM |
Transformer架构由多头自注意力机制与前馈神经网络构成, 是一种具备强全局建模能力的序列学习方法。 如图6所示, 输入特征首先通过线性变换映射为查询向量(Q)、 键向量(K)和值向量(V), 通过计算Q与K的点积得到位置间的相关性, 并以此为权重加权求和V, 实现对各输入位置间全局依赖关系的建模。 多头机制允许模型在不同子空间中并行建模注意力特征, 增强特征表达能力。 编码器每个子模块均采用残差连接与LayerNorm归一化操作以提高训练稳定性。
 | 图6 Transformer编码器层结构示意图Fig.6 Schematic diagram of a Transformer encoder layer |
为了验证本文所提出的Mor+DIPF算法在模拟高斯光谱中本底扣除的有效性, 分别与XRF中常用的两种本底扣除方法: 自适应迭代重加权惩罚最小二乘法(airPLS)、 自适应平滑约束最小二乘法(ASLS)以及多项式拟合法(PF)、 迭代多项式拟合法(IPF)、 形态学方法(Mor)进行对比实验。 为了评估六种不同算法对不同形状光谱的校正效果, 采用均方根误差(RMSE)、 平均相对误差(MAE)和决定系数(R2)三个性能指标来衡量校正后基线和模拟基线之间的误差和相关性, 三种评价指标的计算如式(21)— 式(23)所示, 结果如表2— 表4所示。
$\mathrm{RMSE}=\sqrt{\frac{\displaystyle\sum_{i=1}^{M}\left(z_{i}-t_{i}\right)^{2}}{M}}$(21)
$\mathrm{MAE}=\frac{1}{M} \displaystyle\sum_{i=1}^{M}\left|z_{i}-t_{i}\right|$(22)
$R^{2}=1-\frac{\displaystyle\sum_{i=1}^{M}\left(z_{i}-t_{i}\right)^{2}}{\displaystyle\sum_{i=1}^{M}\left(t_{i}-\bar{t}\right)^{2}}$(23)
$\mathrm{MAPE}=\frac{1}{M} \displaystyle\sum_{i=1}^{M}\left|\frac{z_{i}-t_{i}}{t_{i}}\right| \times 100 \% $(24)
$\mathrm{MSE}=\frac{1}{M} \displaystyle\sum_{i=1}^{M}\left(z_{i}-t_{i}\right)^{2}$(25)
| 表2 六种本底扣除算法在四种不同基线下的RMSE Table 2 RMSE of six background subtraction algorithms under four different baselines |
| 表3 六种本底扣除算法在四种不同基线下的MAE Table 3 MAE of six background subtraction algorithms under four different baselines |
| 表4 六种本底扣除算法在四种不同基线下的R2(%) Table 4 R2 of six background subtraction algorithms under four different baselines (%) |
对表2、 表3和表4数据分析, 六种算法在处理四种不同的光谱时表现出不同的性能特征。 本研究提出的Mor+DIPF算法在性能上优于IPF、 DIPF、 airPLS、 ASLS和Mor算法。
为了验证本文所提出的APU-PSO-EM-GMM算法在重叠峰解析上的有效性, 分别与XRF中常用的三种重叠峰分解算法: 曲线拟合法、 高斯锐化法、 离散小波变换法(DWT)以及三种优化算法: 基于和声搜索优化EM算法(HS-EM-GMM)、 基于蝙蝠行为优化EM算法(BA-EM-GMM)和基于麻雀搜索优化EM算法(SSA-EM-GMM)进行对比实验。 图7为七种对比算法在普通重叠峰、 肩部重叠峰和多重叠峰上的拟合结果。 从图中可以看出, 曲线拟合、 高斯锐化法和DWT算法在拟合的整体趋势上表现较差, 尤其在峰值位置上存在较大的偏差。 相比之下, SSA-EM-GMM、 BA-EM-GMM和HS-EM-GMM这三种基于EM-GMM的优化算法在捕捉峰值和细节方面表现较为出色。 而本文提出的APU-PSO-EM-GMM算法在整体拟合效果上最为接近模拟重叠峰, 显示出其在处理重叠峰时具有显著的优势。
 | 图7 七种对比算法在普通重叠峰, 肩部重叠峰和多重叠峰下的拟合结果Fig.7 Fitting results of seven comparison algorithms under ordinary overlapping peaks, shoulder overlapping and multiple overlapping peaks |
在本文中, 采用实际工业现场采集的钛铁矿样本数据开展实验。 通过在光谱分析软件中加载不同品位的钛铁矿光谱, 对特征峰的变化趋势进行观察, 并分析影响铁元素光子计数变化的关键特征变量。 实验结果显示, 钛铁矿与铁矿石之间的光谱信号存在显著干涉现象。 具体而言, Mn与Fe之间存在光谱线重叠, 而Cr元素则对Fe、 Ca和Ti的特征X射线表现出明显吸收效应。 作为高原子序数元素, Cr 具备更强的 X 射线吸收能力, 尤其对Fe-Kα (约 6.40 keV)具有明显的吸收作用, 进而导致目标元素Fe的光子计数显著减少。 综合光谱分析结果可见, 样品中存在四种主要共存元素: Ca、 Ti、 Mn和Cr, 它们均对Fe元素的荧光强度产生干扰影响。 数据集共有41组数据, 按照训练集与测试集=8∶ 2进行划分。 为避免特征间量纲不一致带来的影响, 本文采用最大-最小归一化方法对数据进行处理, 将各特征值线性映射至[0, 1]区间。 令X=[ICa, ITi, IMn, ICr, IFe], X为41× 5阶矩阵, 其中I(· )表示各元素的X射线荧光强度值, 通过式(26) 进行数据处理
$X^{*}=\frac{X-\min (X)}{\max (X)-\min (X)~~~~}$(26)
为了验证本文所提出的Transformer-BiLSTM算法在钛铁矿品位定量分析的性能, 与常用的四种算法: 支持向量机(SVM), Transformer, Transformer融合LSTM进行对比实验。 本文采用了MAE、 RMSE和R2作为模型评价指标。 表5 给出四种算法对钛铁矿品位定量分析的评价量化指标, 可以看出本文所提出的Transformer-BiLSTM的平均绝对误差为0.217 2、 均方根误差为0.280 7, 为四种算法当中最小。 决定系数为99.716 1%, 更逼近理想值1。
| 表5 模型检测结果评价 Table 5 Evaluation of model detection results |
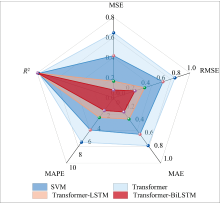
图8展示了四种模型(SVM、 Transformer、 Transformer-LSTM、 Transformer-BiLSTM)在五个关键性能指标(MSE、 RMSE、 MAE、 MAPE、 R2)上的对比结果。 其中, MSE与RMSE最低, 说明其在拟合能力上最为精准; MAE与MAPE最小, 表明模型在不同样本下的泛化误差波动最小; R2为0.997 1, 接近于理想值1, 反映了该模型对真实数据的拟合度极高。 Transformer-BiLSTM模型在定量分析的精度、 稳定性与泛化能力方面均达到最优状态。
 | 图8 四种估计模型的评估指标雷达图Fig.8 Radar chart of evaluation indicators for four estimation models |
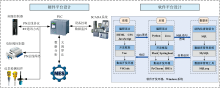
本系统软硬件平台如图9所示, 其中硬件平台采用汇川SV660F伺服控制器与西门子PLC通过PN总线及RT通讯实现高精度控制; 气控系统通过PN总线阀岛减少布线、 提高通讯实时性; 现场仪表采用继电器输出, 增强抗干扰能力。 MES系统通过OPC-UA协议与PLC通讯, 实现XRF分析数据的实时传输与管理优化; SCADA系统采用WINCC 7.5 SP2, 通过S7协议与PLC通信, 实现设备监控与数据采集。 软件平台如图9所示, 基于Windows系统, 前端采用Vue框架, 后端采用Spring Boot与Flask, 数据库使用MySQL, 整体架构灵活高效。 该系统已在沈阳某选矿厂应用6个月以上, 图10展示了钛铁矿品位实时检测模块, 可动态显示检测与人工化验结果。 表6数据显示, 系统在设定3%相对误差范围内的估计合格率均超90%, 验证了系统在工业现场的实用性与准确性。
 | 图9 软硬件平台设计Fig.9 Hardwareand software platform design |
 | 图10 钛铁矿品位实时与历史检测模块Fig.10 Real-timeand historical detection module for titaniferous iron ore grade |
| 表6 投运六个月余的钛铁矿品位估计误差分析 Table 6 Error analysis of titanium iron ore grade estimation after more than six months of operation |
针对XRF光谱分析中普遍存在的本底干扰与谱峰重叠问题, 提出了两种算法优化方式。 首先, 在EDXRF光谱仪获取数据的过程中, 由于外界干扰、 X射线与样品之间的相互作用等因素造成噪声和背景信号的产生, 提出一种基于形态学与导数迭代多项式拟合的本底扣除方法, 确保精确获取目标元素XRF光谱谱峰及其净峰面积; 进一步将获得的净荧光光谱数据输入到EM算法中进行重叠峰参数的初步解析, 以得到各个特征峰的峰位、 方差和权重。 其次, 针对EM算法对初始参数的选择较为敏感, 易陷入局部最优的缺点以及标准粒子群优化算法存在早熟收敛问题, 提出一种基于自适应参数更新策略的粒子群优化算法, 从惯性权重w、 个体学习因子c1和社会学习因子c2三个参数上进行改进, 从而获得更为精确的解析结果。 最后, 在此基础上构建了Transformer-BiLSTM的钛铁矿品位检测方法, 实现了高精度、 轻量化的在线检测建模, 为传统化学分析方法提供了高效可行的替代方案。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|