

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
四种迁移学习架构在跨仪器绝缘纸聚合度评估中的效果对比
[李含 , 孙伟哲, 陈希源, 张冠军, 李元
, 孙伟哲, 陈希源, 张冠军, 李元* ]
, 孙伟哲, 陈希源, 张冠军, 李元]
|
|


作者简介: 李 含, 1998年生,西安交通大学电气工程学院博士研究生 e-mail: 2396023668@qq.com
近红外光谱(NIRS)分析技术已成为替代传统化学方法实现绝缘纸聚合度(DP)无损检测的重要手段。 作为一种典型的数据驱动型计量学方法, NIRS技术在不同仪器之间所采集的光谱数据常存在幅值偏移, 严重制约了其在工程应用中的通用性与规模化推广。 为此构建了一个涵盖四台典型光谱仪的模型传递场景, 分析了仪器间的光谱差异, 系统比较了四种主流深度神经网络结构在不同参数配置下的迁移学习微调表现, 探讨了网络冻结策略对模型迁移性能的影响, 并在既定超参数搜索空间中筛选出最优的微调网络结构和超参数组合。 结果表明, 不同仪器的光谱幅值存在显著差异, 导致源域模型在目标域上的预测性能急剧下降, 模型几乎失效。 冻结设置可以使神经网络模型微调效果更好, 通过冻结前端特征提取层、 微调高层决策层参数的策略可在保证稳定性的同时提高迁移适应能力。 在MLP、 1D-CNN、 EOT以及ResNet四种架构中, EOT的源域误差最小但目标域微调效果最差, 而ResNet的源域误差高于EOT, 但微调效果较好, 说明源域训练误差与迁移效果之间并无显著相关性。 在所有结构中, 基于多尺度Inception模块的三分支ResNet网络在目标域上获得最佳性能, 微调后RMSE为78.5, MAPE为8.6%, 显著优于其他模型。 研究结果为构建具备跨设备通用性的NIRS建模框架提供了科学依据。
Near-infrared spectroscopy (NIRS) has become an important nondestructive technique for assessing the degree of polymerization (DP) of insulating paper as an alternative to traditional chemical methods. As a typical data-driven chemometric approach, NIRS often suffers from amplitude shifts in spectral data collected across different instruments, which severely limit its generalizability and large-scale deployment in engineering applications. In this work, we construct a model transfer scenario involving four representative spectrometers to analyze inter-instrument spectral discrepancies. We systematically compare the transfer learning fine-tuning performance of four mainstream deep neural network architectures under different parameter configurations, investigate the effect of layer-freezing strategies on transfer performance, and identify the optimal network structure and hyperparameter combination within a predefined search space. The results show that significant spectral amplitude differences exist among instruments, leading to drastic degradation of predictive performance when a source-domain model is directly applied to the target domain, rendering the model nearly ineffective. Freezing strategies improve fine-tuning performance by stabilizing the network; specifically, freezing the front-end feature extraction layers while fine-tuning the higher-level decision layers enhances transferability without compromising stability. Among the four tested architectures—MLP, 1D-CNN, EOT, and ResNet—EOT achieved the lowest error in the source domain but performed worse after fine-tuning in the target domain, whereas ResNet exhibited higher source-domain error than EOT but achieved better fine-tuning performance. This indicates that source-domain training error is not strongly correlated with transfer effectiveness. Overall, a three-branch ResNet network incorporating multi-scale Inception modules achieved the best target-domain performance, with an RMSE of 78.5 and a MAPE of 8.6% after fine-tuning, significantly outperforming the other models. These findings provide theoretical support for constructing NIRS modeling frameworks with cross-instrument generalizability.
近红外光谱(near infrared spectrum, NIRS)技术在绝缘纸聚合度(degree of polymerization, DP)定量评估领域备受关注[1]。 通过建立NIRS与DP之间的关联模型, 可直接通过采集绝缘纸的光谱, 实现对DP的快速、 无损评估, 有效规避了传统化学方法的有损取样、 测试周期长等问题[2]。 然而, 在技术的进一步推广应用时, 发现不同型号或批次的光谱仪之间由于光源、 光路及探测器等硬件差异不可避免地在测量信号中引入系统性偏移。 这种偏移导致先前基于单一仪器建立的校准模型在应用于其他仪器时, 预测精度和可靠性显著下降[3]。
尽管为新生产的光谱仪建立独立的校正模型是最直接的方案, 但此过程需重建数据库, 如新构建样本集或对原有库样本进行光谱采集。 这会耗费大量人力和物力, 显著增加仪器开发成本。 因此, 实际应用通常摒弃重建数据库的策略, 转而采用模型传递技术, 实现从已建模(主机)光谱仪向新仪器(从机)的模型迁移[4]。
目前, 模型传递领域已发展出多种基于不同原理的策略, 主要包括光谱标准化、 稳健变量选择与模型更新等方法[5, 6, 7]。 其中, 光谱标准化方法被广泛采用, 其核心思想是通过构建主机与从机之间的光谱映射矩阵, 实现跨设备间的光谱校准, 以保证主机模型的可用性。 然而, 该类方法通常要求主机与从机在相同样本上进行光谱采集, 以保证配对数据的可比性[8]。 在实际应用场景下, 绝缘纸样本通常处于绝缘油浸渍状态。 由于绝缘油的含量不可控, 样本的光谱在不同采集位置处呈现显著分散性, 往往会严重干扰乃至掩盖仪器之间固有的系统光谱差异, 严重影响映射矩阵求解的鲁棒性与稳定性。 近年来, 以迁移学习为代表的模型更新方法在光谱模型传递任务中展现出显著优势, 逐步成为应对仪器间分布差异的关键解决方案[9], 能够在无需依赖主从机配对样本的前提下, 将源域模型的结构与知识迁移至目标域, 实现模型的快速适应与性能保持。
在现有的迁移学习研究中, 深度神经网络微调(fine-tuning)已成为广泛应用的核心策略之一[10]。 其基本思路是设计具备较强特征提取能力的深度网络, 在源域数据上充分提取与待测属性有关的域不变信息, 并在目标域通过网络参数微调实现源域知识的迁移, 最终使从机模型在仅有少量训练样本下达成较高的预测性能。 当前大多数研究在特征提取网络的选择上仍存在一定局限性, 通常仅基于单一架构(如卷积神经网络或Transformer)构建模型[11, 12, 13, 14]。 这种选择很大程度上依赖研究者的先验经验或当前流行趋势, 缺乏对各架构的系统性比较。 由于不同神经网络结构在建模局部模式、 多尺度信息和序列依赖方面存在天然差异, 结构选择本身对迁移学习效果具有重要影响。 因此, 系统比较不同网络架构的微调效果, 可为迁移机制的优化与网络设计提供更具普适性的理论依据。
针对上述问题, 构建了一个包含4台近红外光谱仪的多设备光谱模型传递数据库, 在此基础上, 基于四种典型网络架构定制了系统的超参数搜索组合, 全面分析不同网络架构在目标域微调时的性能表现, 探寻在现有所搜空间中最优的神经网络架构, 实现源域数据中DP关联信息充分提取与目标域的有效微调建模。
为保障模型泛化能力, 广泛收集了不同厂家、 主流类型的绝缘纸共6种, 如表1所示, 包括三种电缆纸(BZZ075、 BZZ125和GDL)、 两种皱纹纸(22HCC和JW50), 以及一种绝缘纸板(B31A)。 所有样本均在130 ℃恒温条件下进行加速热老化处理, 老化周期共计100 d, 并每隔2 d进行一次采样, 最终获得不同老化状态下的典型样本共计300个, 每类样品50个。 通过粘度法测试得到样品的DP标签值, 测试方法依据国家标准GB/T 29305执行。
| 表1 不同类型绝缘纸样本信息 Table 1 Information of different types of insulating paper |
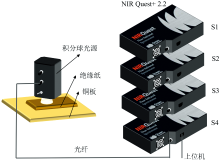
近红外光谱采集系统如图1所示, 主要由4台美国Ocean Insight公司生产的NIR Quest+ 2.2型近红外光谱仪, 以及美国Labsphere公司制造的ISP-REF型积分球光源组成。 光谱仪探测器波长范围为900~2 200 nm, 像元数为512。 光谱采集的积分时间设置为80 ms, 平均次数12次。 对于每个样品, 在不同位置进行3次光谱采集, 以尽可能采样到全面的绝缘油干扰信息。 最终, 每台光谱仪共采集得到900条光谱数据, 对应的数据集分别命名为S1、 S2、 S3和S4。
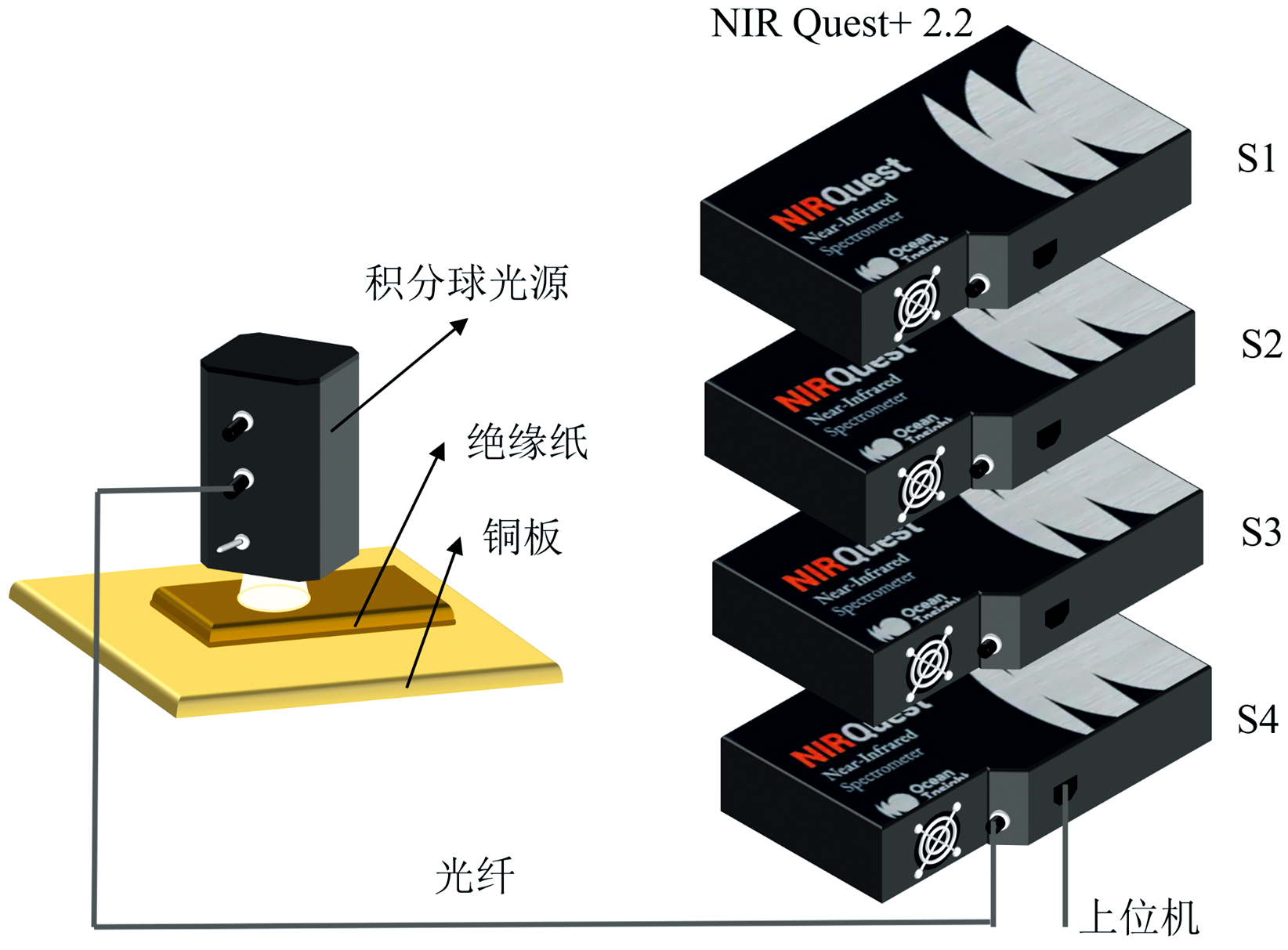 | 图1 绝缘纸近红外光谱采集系统Fig.1 Insulating paper NIR spectral acquisition system |
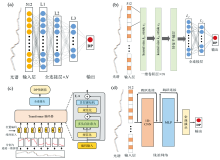
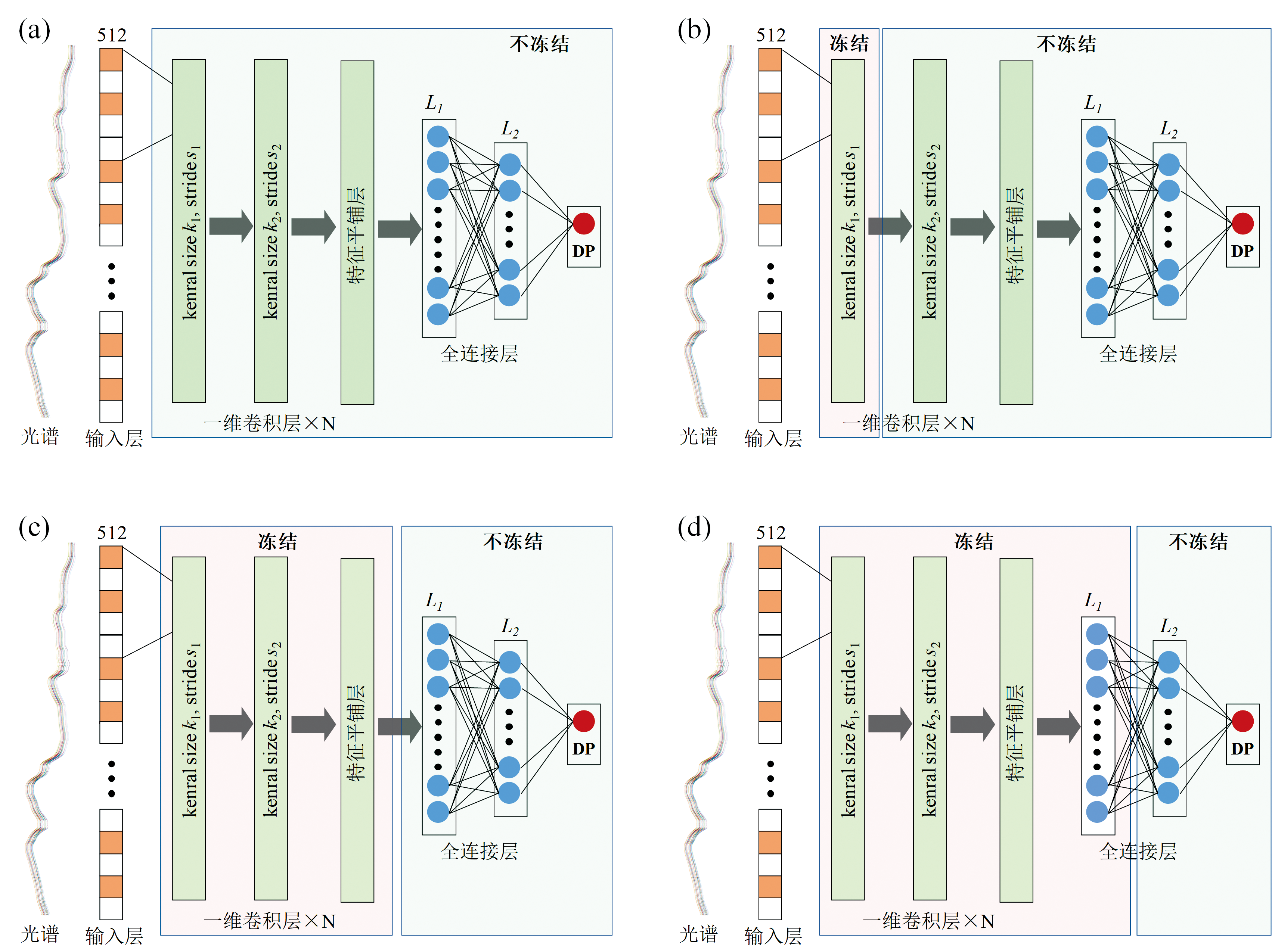
神经网络模型微调是一种基于参数的迁移学习方法, 旨在利用源域的预训练模型在目标域上继续训练, 调节网络参数以适应新任务。 模型的架构设计是影响微调效果的关键因素之一, 不同结构在特征提取能力、 参数效率及泛化能力方面存在显著差异。 参考现有文献, 设计了并对比了四种主流网络架构, 分别为多层感知机(multi-layer perception, MLP)、 一维卷积神经网络(one-dimensional convolutional neural network, 1D-CNN)、 Transformer编码器(encoder-only Transformer, EOT)以及残差网络(residual network, ResNet), 各网络结构如图2所示。
 | 图2 参与对比的四种神经网络架构 (a): MLP; (b): 1D-CNN; (c): EOT; (d): ResNetFig.2 Four neural network architectures involved for comparison (a): MLP; (b): 1D-CNN; (c): EOT; (d): ResNet |
其中, MLP由多层全连接神经元构成, 适用于建模复杂的全局非线性关系, 但其缺乏对序列结构的建模能力, 易忽视波段间的顺序依赖[15]。 1D-CNN通过局部感受野与卷积共享机制, 能够有效捕捉光谱中的局部相关特征, 具有较强的参数效率, 但在处理长程依赖或细粒度结构时可能存在信息损失[16]。 EOT利用自注意力机制挖掘不同光谱波段之间的全局相关性, 具备强大的建模能力, 然而其模型参数量较大, 在小样本目标域中易导致过拟合[17]。 ResNet则通过引入残差连接, 有效缓解深层神经网络中的梯度消失与梯度爆炸问题, 适用于MLP或CNN模块的结构增强[18]。 上述四种网络架构分别代表当前主流的光谱特征提取方式, 对它们在目标域微调过程中的迁移表现进行系统比较, 有助于深入理解不同网络结构在特征提取能力与域迁移适应性方面的差异特征, 为后续网络设计与优化提供理论依据与实践参考。
考虑到近红外光谱数据的高维序列特征与本研究数据库的规模特点, 针对所选的四种神经网络架构(MLP、 1D-CNN、 EOT和ResNet), 设计了对应的超参数搜索空间, 具体配置如表2所示。 通过大量的建模对比实验, 系统评估不同超参数组合在目标域微调过程中的迁移性能, 并从中筛选出具有良好鲁棒性和迁移泛化能力的通用型网络结构与参数配置, 以构建适用于近红外光谱任务的最优迁移学习框架。
| 表2 不同网络架构的超参数搜索空间 Table 2 Hyperparameter search space for different network architectures |
模型训练与微调的详细流程如图3所示。 在数据准备阶段, 统一将S1、 S2、 S3作为源域数据集, S4作为目标域数据集。 在源域训练过程中, 将合并后的数据按80%:20%的比例划分为训练集和测试集; 在目标域微调中, 仅使用目标域数据中10%的样本用于训练, 其余90%用于测试, 以模拟实际应用中小样本迁移建模场景。 为增强实验结果的稳健性与可重复性, 源域与目标域训练均设置5组不同的随机种子, 分别进行随机划分与独立建模, 以减少因样本划分波动带来的偶然性影响。 模型训练严格遵循表3中定义的超参数组合, 训练完成后, 将源域模型的全部参数保存并加载至目标域模型初始化中, 随后在目标域上继续训练以完成微调过程。
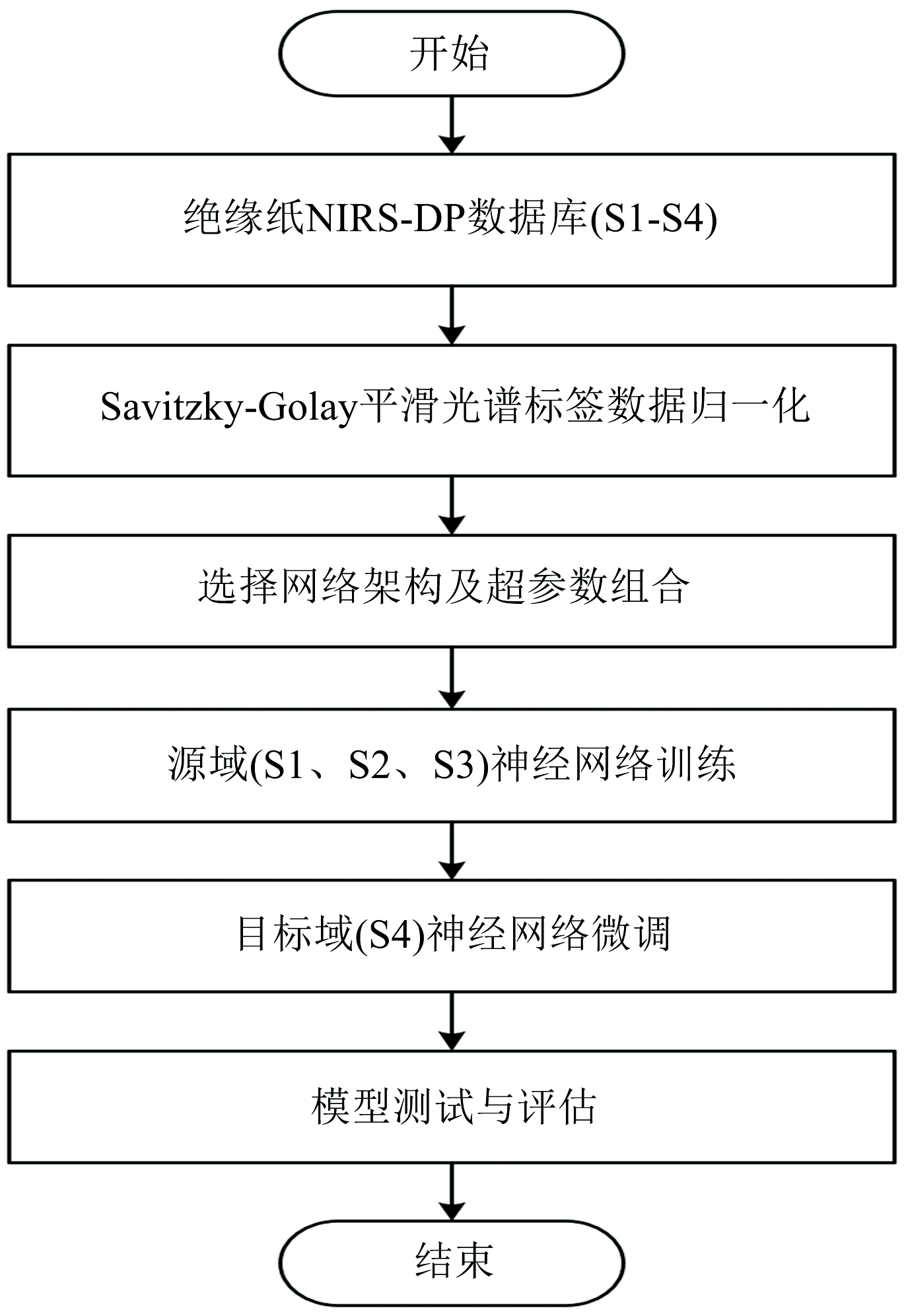 | 图3 模型训练与微调的过程Fig.3 Schematic diagram of the model training and fine-tuning process |
| 表3 不同网络架构的源域及目标域训练设置 Table 3 Training settings in source and target domains for different network architectures |
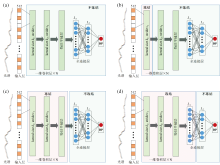
深度神经网络在训练过程中所学习到的低层特征通常有较强的通用性, 能够适应不同任务的初步特征提取需求[19]。 然而, 随着网络深度的增加, 高层特征表达更依赖于输入数据的具体分布。 现有研究普遍采用冻结模型前端特征提取层、 仅对后续高层模块进行微调的策略。 该策略一方面保留了预训练模型中对谱图低层特征的稳定提取能力, 另一方面通过对高层参数的局部优化增强模型对目标域(新光谱仪)数据的适应性。 基于上述思路, 以1D-CNN结构为例, 设计了四种不同的模型参数冻结方案, 如图4所示, 旨在评估不同层级参数冻结方式对迁移性能的影响。
 | 图4 不同网络参数冻结设置 (a): 不冻结; (b): 冻结首层卷积层; (c): 冻结所有卷积层; (d): 冻结部分全连接层Fig.4 Different parameter freezing strategies for neural networks (a): No freezing; (b): Freezing the first convolutional layer; (c): Freezing all convolutional layers; (d): Freezing part of the fully connected layers |
源域与目标域的模型训练后采用均方根误差(root mean square error, RMSE)与平均相对误差(mean absolute percentage error, MAPE)进行性能评估
$\mathrm{RMSE}=\sqrt{\frac{\sum_{i=1}^{n}\left(y_{i}^{*}-y_{i}\right)^{2}}{n}}$(7)
式(7)和式(8)中: yi为标签值,
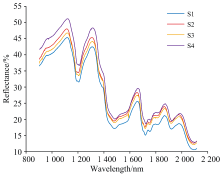
S1— S4的平均光谱对比如图5所示, 各仪器在整个波段范围内的光谱响应趋势具有良好的一致性, 反映出相似的谱形结构。 然而, 在光谱反射率的幅值上仍存在显著区别, 主要归因于各仪器在探测器灵敏度、 光源强度等方面的差异性。 为进一步分析不同光谱仪间的数据相关性及模型传递能力, 以偏最小二乘回归与1D-CNN为例, 研究了在无微调条件下将某一光谱仪上训练的模型直接应用于其他光谱仪数据的预测性能。 所得误差矩阵如图6所示。 结果表明, 各模型在本机测试集上表现较优, RMSE普遍维持在60左右, 但一旦迁移至其他光谱仪的数据上, 预测误差显著升高, RMSE均超过150, 甚至高达3126, 说明即便是细微的仪器差异也会导致模型性能大幅下降。 这一结果也印证了跨仪器建模的必要性, 即使不同仪器光谱形态高度一致, 幅值层面的微小差异也足以破坏模型的泛化能力, 因此需要结合迁移学习等策略来弥补分布差异带来的预测精度损失。
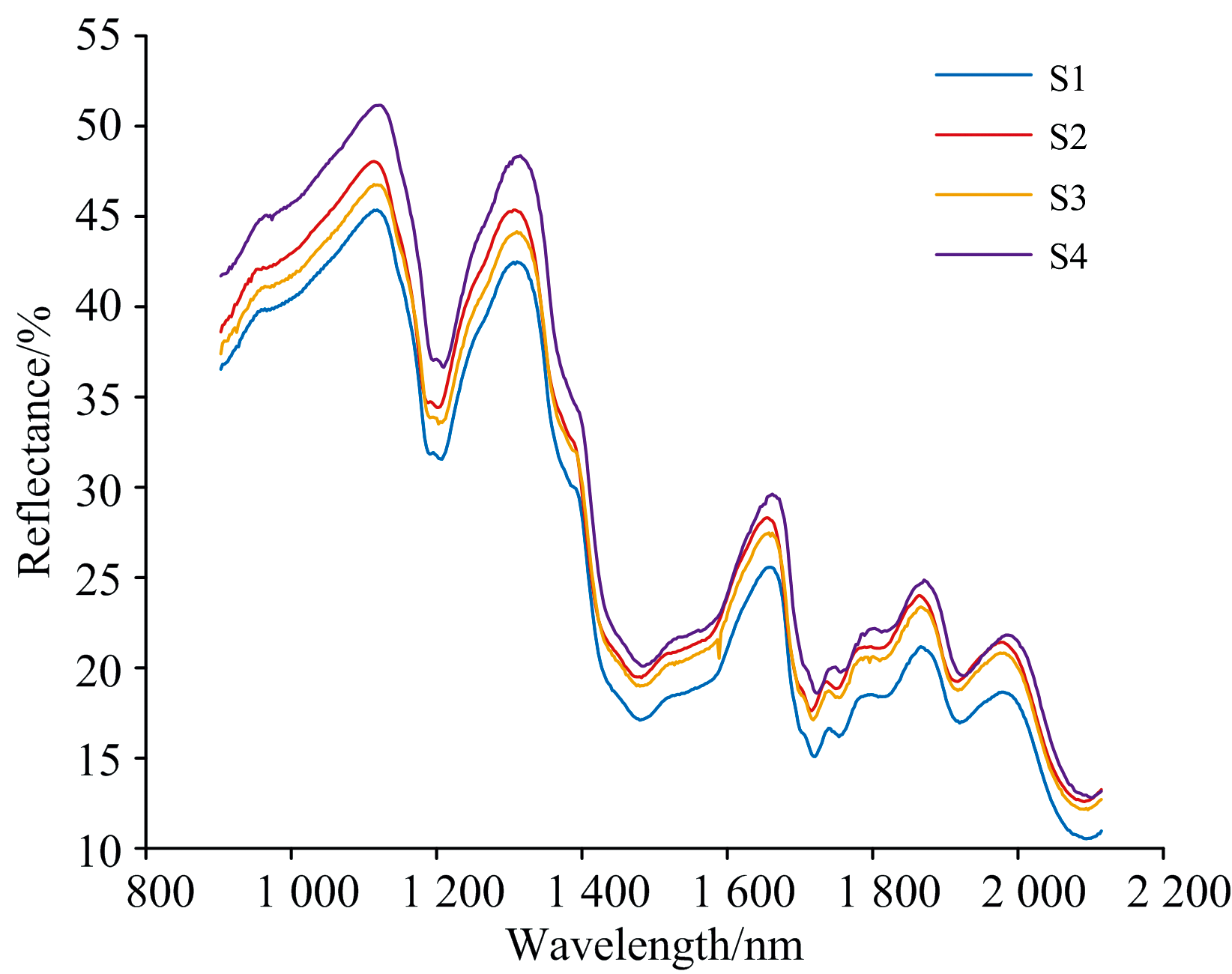 | 图5 四台光谱仪采集的绝缘纸漫反射近红外光谱的平均光谱对比Fig.5 Comparison of average diffuse reflectance NIR spectra of insulating paper acquired by four spectrometers |
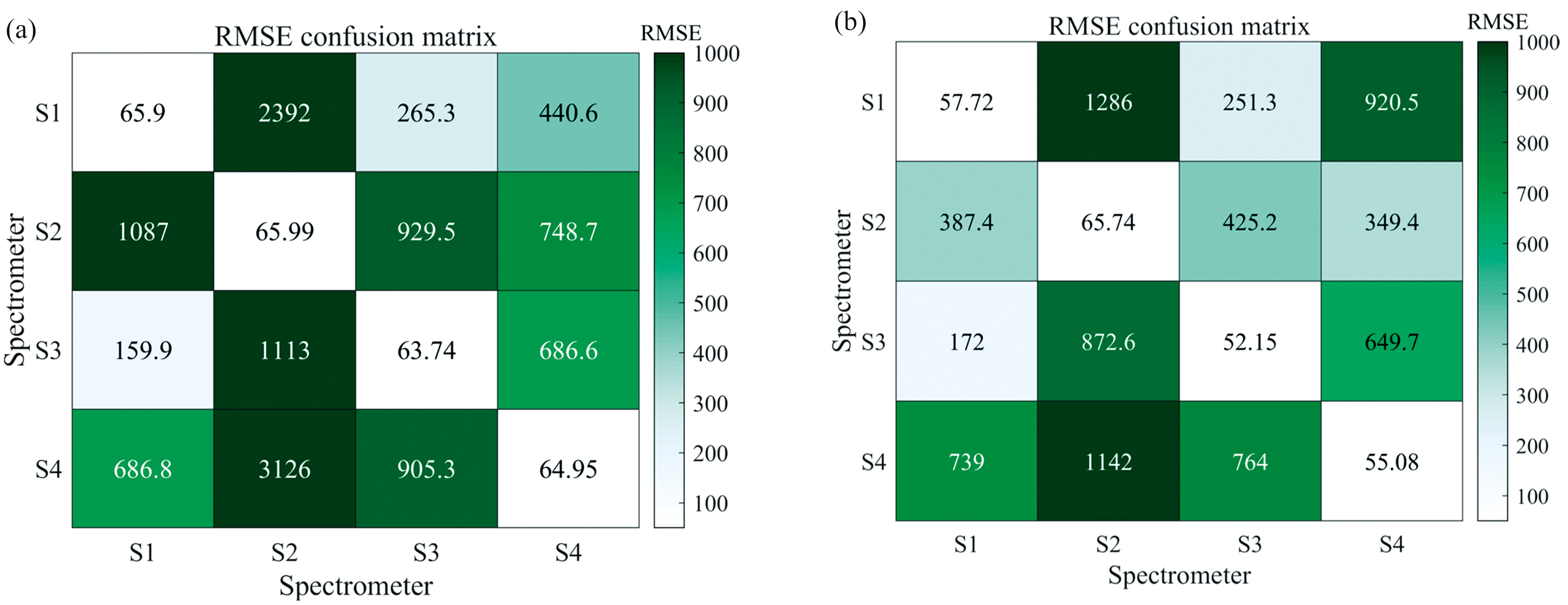 | 图6 源域模型直接应用于目标域时的误差 (a): PLS模型; (b): 1D-CNN模型Fig.6 Prediction errors when source domain models are directly applied to the target domain (a): PLS model; (b): 1D-CNN model |
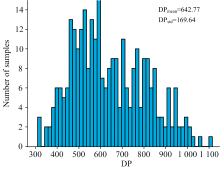
六种绝缘纸样本的DP测试结果如图7所示, DP分布范围为300~1 100, 整体呈近似正态分布。 其中, 大多数DP值集中于450~950区间, 表明所采集样本多数处于中度老化阶段。 DP的整体分布符合绝缘纸前期老化速率快、 后期逐渐减缓的指数衰减规律[20]。 这一规律性特征验证了所构建数据库在老化进程表征方面的有效性, 说明该数据库在支持老化建模、 特征提取与迁移学习研究方面具有良好的代表性与覆盖性。
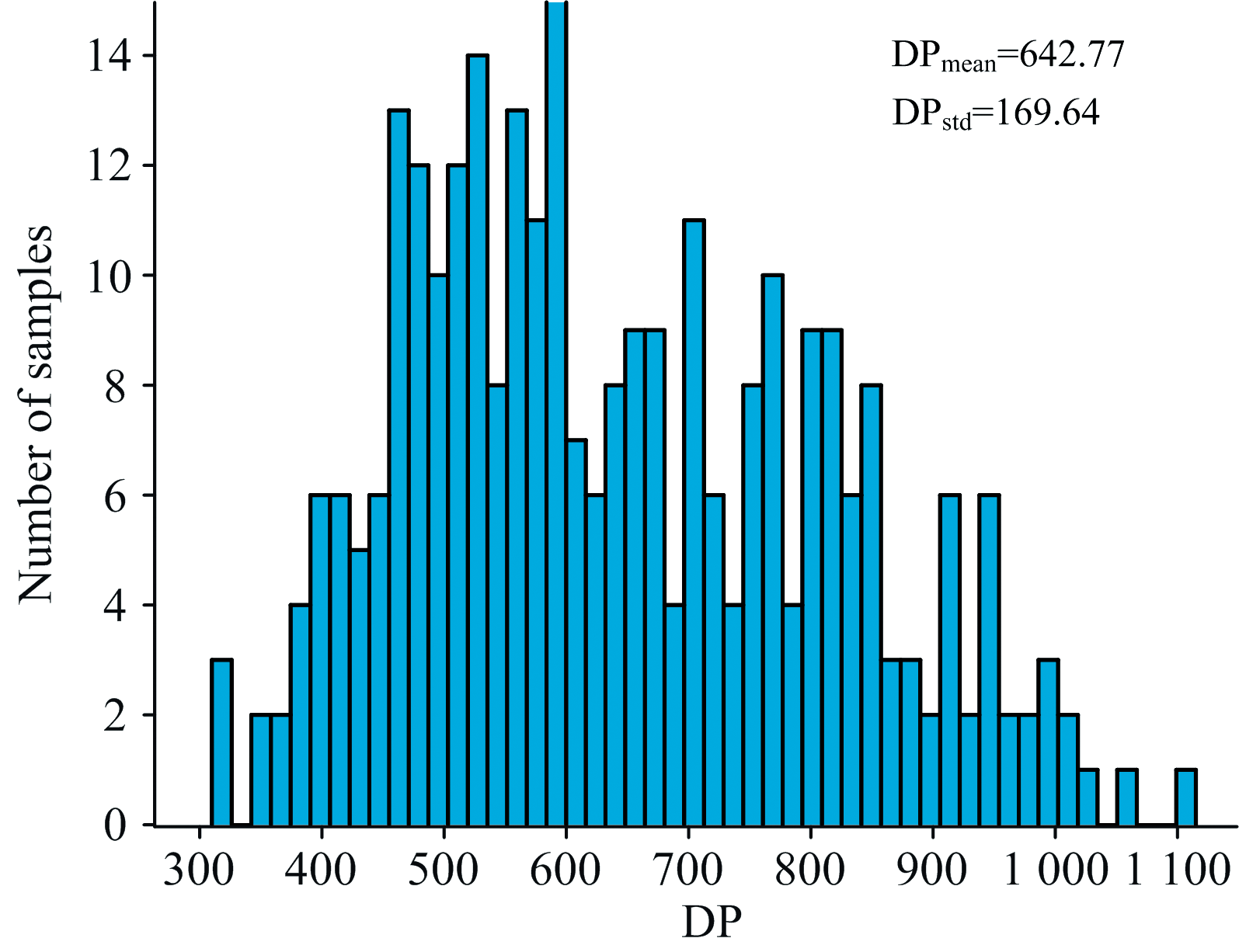 | 图7 样品的DP测试结果分布Fig.7 Distribution of DP test results of the samples |
不同冻结设置下模型在目标域(S4)微调后的测试集误差如图8所示, 对应图3中的不同冻结设置。 当仅冻结卷积层时, 模型具有最好的表现, 但与完全不冻结参数的设置相比差异较小, 而全连接层必须全部解冻以保证非线性拟合能力。 因此, 在后续进行模型微调时, 只对涉及CNN的首层卷积层以及EOT的首层编码器进行冻结。 可见, 冻结策略不仅影响最终精度, 还在一定程度上决定了训练的稳定性。 冻结低层特征提取层有助于保留源域已学习的与仪器无关的稳定特征, 避免在目标域小样本训练时发生过拟合; 而高层参数的解冻则允许模型快速适应目标域特有的分布特征, 从而在精度与泛化性之间取得平衡。
 | 图8 不同微调设置下模型的迁移学习表现对比 (a): 不冻结; (b): 冻结首层卷积层; (c): 冻结所有卷积层; (d): 冻结部分全连接层Fig.8 Comparison of model transfer performance with different fine-tuning Configurations (a): No freezing; (b): Freezing the first convolutional layer; (c): Freezing all convolutional layers; (d): Freezing part of the fully connected layers |
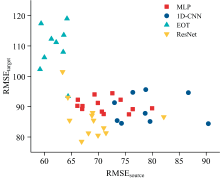
通过在多组超参数配置下对四类典型网络架构进行系统性微调测试, 得到了源域测试集误差RMSEsource与目标域微调后测试集误差RMSEtarget的分布散点图, 如图9所示。 从最终分布可以发现, RMSEsource与RMSEtarget并不具有显著相关性, 即源域性能较优的模型并不一定在目标域具有良好的迁移表现。 这表明, 模型迁移效果更依赖于其对与仪器无关、 但与DP高度相关的光谱特征的抽象与建模能力, 而非单纯依赖源域训练精度。 这一现象的根本原因在于, 源域精度主要反映模型在原始分布下的拟合能力, 而迁移性能则依赖模型能否提取出与DP高度相关且在不同仪器间保持稳定的域不变特征。 因此, 单纯依赖源域误差来判断网络的可迁移性是不充分的, 跨域任务更应关注特征提取的鲁棒性和域适应能力。
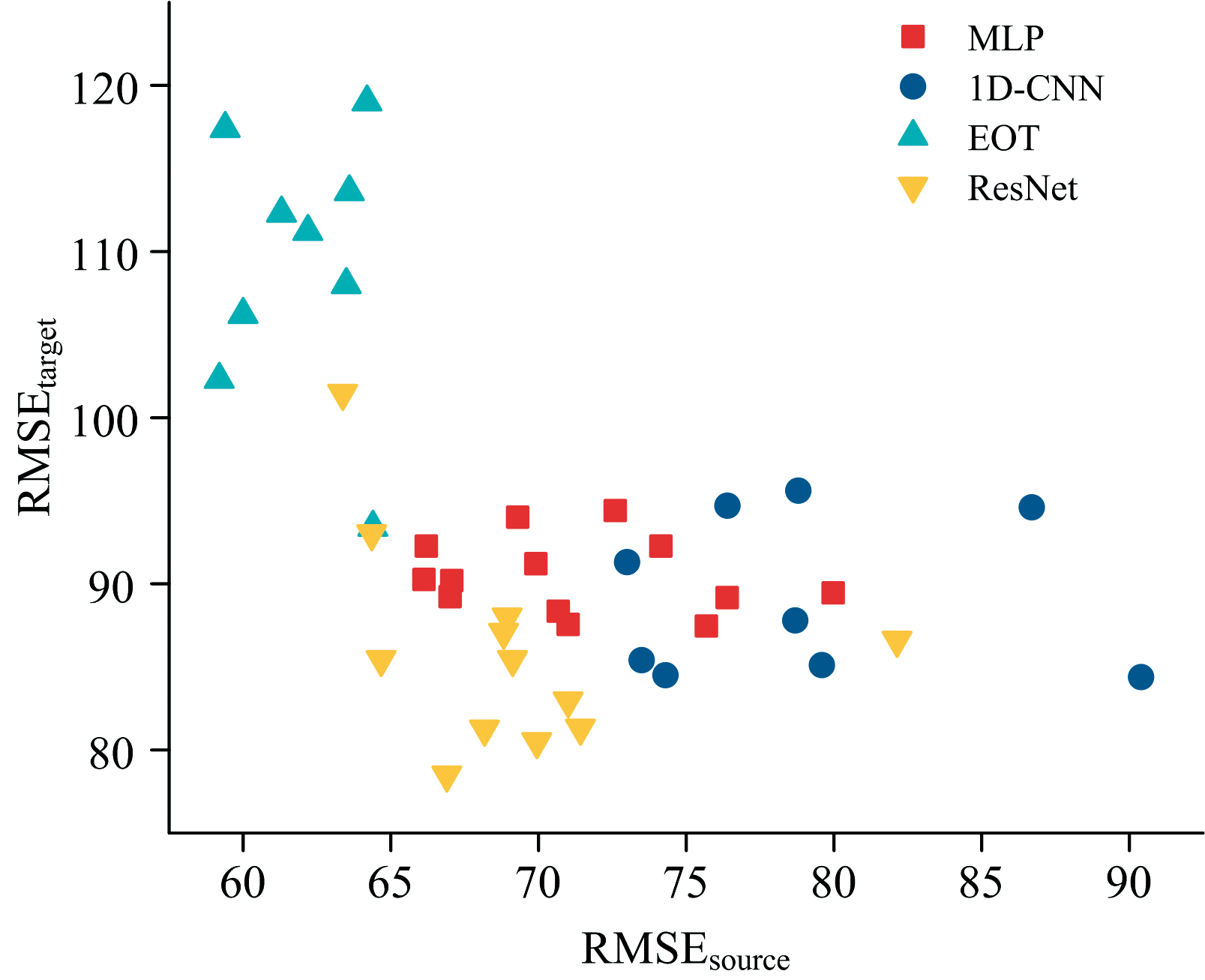 | 图9 四种架构的源域误差与目标域误差分布Fig.9 Distribution of errors on source and target domains across four network architectures |
从不同网络架构的表现来看, MLP与EOT在目标域的整体预测精度较低, 可能由于缺乏卷积层的特征提取机制, 难以有效捕捉具有位置不变性和局部相关性的光谱特征。 相比之下, 包含卷积模块的1D-CNN与ResNet尽管在源域上精度较差, 但由于其适当的参数规模和鲁棒的特征提取特性, 使模型更易捕捉到具有仪器不变性的DP关联特征。
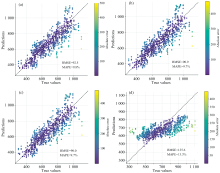
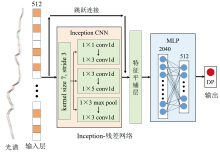
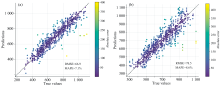
在本研究设定的模型搜索空间中, 图10所示的Inception-ResNet架构表现最优, 该网络主体由两层一维卷积构成, 其中第二层引入了三分支的Inception结构。 多尺度卷积能够同时覆盖近红外光谱中宽波段趋势性特征和窄波段局部吸收峰特征, 从而兼顾全局与局部信息的捕捉能力。 残差连接的引入则在加深网络深度的同时缓解了梯度消失, 使得网络能够稳定训练并保留浅层的稳定特征表达。 这种结构对仪器差异引起的幅值偏移具有一定的容错能力, 因此在跨仪器迁移场景下表现更优。 Inception-ResNet在源域和目标域样本误差分布如图11所示, 源域中的Inception-ResNet对于大多数样本具有较好的预测效果, 而在目标域微调后的测试集上误差为RMSEtarget=78.5, MAPE=8.6%, 已满足工业应用中对聚合度分析的准确性要求(预测误差10%以内)。 部分预测误差较大的样本可能是由于未进行异常样品剔除而存在的异常点。 综上所述, Inception-ResNet将残差连接与多尺度卷积相结合, 既保留了浅层特征的稳定性, 又提升了深层特征的抽象能力, 是近红外光谱迁移学习任务中的优选网络架构。
 | 图10 微调表现最优的Inception-Resnet架构Fig.10 The Inception-ResNet architecture exhibiting the best fine-tuning performance |
 | 图11 Inception-Resnet架构在源域和目标域中的表现 (a): 源域表现; (b): 目标域表现Fig.11 Performance of the Inception-ResNet architecture in the source and target domains (a): Source domain performance; (b): Target domain performance |
针对NIRS技术在绝缘纸DP定量评估中的跨仪器迁移问题, 设计了四种具有代表性的深度神经网络架构, 并结合系统化的超参数优化与多次随机划分实验, 全面评估各模型在源域训练后于目标域上微调的迁移性能。 结果表明:
(1)尽管四台光谱仪所采集的平均光谱形态整体一致, 但在光谱幅值上存在显著差异, 导致源域训练模型在直接应用于目标域时预测性能显著下降。 进一步分析发现, 预训练模型中前端低层卷积层提取的特征具有较强的通用性, 冻结前端权重并仅微调高层参数, 有助于在提升拟合能力的同时保持模型稳定性。
(2)低误差的源域模型不一定具有优异的迁移表现, 关键在于是否能够提取出与DP高度相关且对仪器差异具有鲁棒性的特征。 综合评估结果显示, 基于Inception模块的三分支ResNet结构在跨仪器迁移任务中表现最优, 其在目标域微调后的预测精度达到RMSE=78.5, MAPE=8.6%。 该结构通过多尺度并行卷积有效增强了对DP相关特征的提取能力, 并在一定程度上缓解了光谱特征中的共线性问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|