{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于遗传算法优化的XGBoost煤质LIBS定量分析算法研究
[朱婷婷1  , 潘从元
, 潘从元1, 2, 3, * , 赵前进1 , 薛骅骎2, 3 , 申远2, 3 , 张兵2, 3 ]
, 潘从元, 赵前进|
|


作者简介: 朱婷婷,女, 1999年生,安徽理工大学数学与大数据学院硕士研究生 e-mail: 15655446560@163.com
针对燃煤铜冶炼厂对煤质成分在线检测的高精度需求, 提出了一种基于遗传算法(GA)优化的极端梯度提升决策树(XGBoost)集成模型GA-XGBoost, 提升了激光诱导击穿光谱(LIBS)技术在复杂煤质分析中的工业适用性。 针对传统XGBoost模型因超参数敏感性导致的过拟合及泛化能力不足问题, GA-XGBoost采用遗传算法全局搜索策略, 自适应优化关键超参数(学习率、 树深度、 正则化参数等), 并结合二进制编码实现特征子集的动态筛选, 从而有效降低高维LIBS光谱数据中的噪声干扰。 为验证模型的实用性与普适性, 选取山西大同(烟煤)及内蒙古鄂尔多斯(褐煤)两大典型产区的59个标准煤样作为实验对象。 通过自适应迭代基线校正(airPLS)与Savitzky-Golay滤波等预处理方法, 将原始光谱特征维度从14 328维压缩至500维, 并利用SHAP值筛选关键特征。 在此基础上, 分别采用GA-XGBoost、 XGBoost、 随机森林(RF)、 支持向量机(SVM)、 多元线性回归(MLR)与偏最小二乘(PLS)进行灰分与热值的预测对比实验。 实验结果表明, 相较于传统XGBoost、 随机森林等模型, GA-XGBoost在煤质灰分和热值预测任务中表现更优, 灰分预测的决定系数( R2)提升0.053, 均方根误差(RMSE)降低0.964, 平均绝对误差(MAE)降低0.324, RSD降低了1.494%; 热值预测的 R2提升0.003, RMSE降低0.021, MAE降低0.07, RSD降低了0.871%。 此外, 为验证模型在复杂工业环境下的鲁棒性, 该研究选取了20组未参与建模的煤炭现场数据进行外部验证, 结果表明GA-XGBoost在灰分和热值预测中的误差均保持在合理范围内, 验证了模型对不同煤种的适应能力。 该研究将GA优化与LIBS煤质光谱分析相结合, 有效应对光谱干扰和模型泛化问题, 为实时、 多参数煤质分析提供了统一框架。 现场测试结果表明, 该模型可集成至燃煤铜冶炼厂的LIBS在线检测系统, 灰分预测误差<1%、 热值误差<0.5 MJ·kg-1。 该研究将遗传算法与LIBS光谱分析深度融合, 提出了一个兼顾精度和鲁棒性的煤质多参数快速定量分析框架, 为煤炭清洁与高效利用提供了新的技术途径。
To address the high-precision demand for online coal quality detection in coal-fired copper smelters, this study proposes a genetic algorithm (GA)-optimized extreme gradient boosting decision tree (XGBoost) ensemble model (GA-XGBoost), enhancing the industrial applicability of laser-induced breakdown spectroscopy (LIBS) for complex coal analysis. To overcome overfitting and limited generalization in traditional XGBoost caused by hyperparameter sensitivity, GA-XGBoost implements a GA-based global search strategy to adaptively optimize key hyperparameters (e. g., learning rate, tree depth, regularization parameters) coupled with binary-encoded chromosome representation for dynamic spectral feature selection, effectively suppressing noise in 14 328-dimensional LIBS data. Validation employed 59 standard coal samples from Datong, Shanxi (bituminous coal) and Ordos, Inner Mongolia (lignite). Preprocessing via adaptive iteratively reweighted penalized least squares (airPLS) and Savitzky-Golay filtering reduced spectral dimensions to 500, with dominant features identified by SHapley Additive exPlanations (SHAP) values. Comparative experiments demonstrated GA-XGBoost's superiority over XGBoost, random forest (RF), support vector machine (SVM), multiple linear regression (MLR), and partial least squares (PLS) in predicting ash content and calorific value. For ash content, GA-XGBoost achieved a 0.053 increase in R2, 0.964% reduction in RMSE, 0.324% decrease in MAE, and 1.494-percentage-point lower RSD. For calorific value, it yielded a 0.003 R2 improvement, 0.021 MJ·kg-1 RMSE reduction, 0.07 MJ·kg-1 MAE decrease, and 0.871-percentage-point RSD reduction. External validation using 20 unmodeled on-site coal datasets confirmed robustness in industrial environments, with errors constrained within 1% (ash) and 0.5 MJ·kg-1 (calorific value). The GA-LIBS integration addresses spectral interference and generalization challenges, establishing a unified framework for real-time multi-parameter coal analysis. Field deployment in an operational copper smelter demonstrated seamless integration into LIBS online systems, providing a technically viable pathway toward clean and efficient coal utilization.
煤质成分在线检测不仅是铜冶金过程控制的“ 传感器” , 更是智能化升级的基石[1]。 通过将煤质数据与熔炼动力学模型、 专家系统深度融合, 可构建“ 检测— 分析— 决策— 执行” 的闭环智能冶金体系, 推动铜冶炼向高效、 低碳、 高精度方向跨越发展。 随着LIBS、 太赫兹等新型检测技术的工业应用, 煤质分析的实时性与精度将进一步提升, 为冶金4.0提供更强支撑[2]。 研究表明, 灰分每降低1%, 燃煤热效率可提升0.5%, 年碳排放减少约2.4万吨; 而热值每提高1 MJ· kg-1, 发电煤耗可降低约2.5 g· (kW· h)-1[3]。 开发灰分与热值的快速精准检测技术, 对铜冶炼厂的燃烧-还原协同优化、 冶炼能效提升及低碳清洁生产目标的实现具有关键作用。
目前, 常用的煤质快速分析技术包括双能γ 射线透射法(dual-energy gamma-ray transmission method, DETM)[4]、 中子瞬发γ 射线活化分析法(prompt γ -ray neutron activation analysis, PGNAA)[5]、 X射线荧光法(X-ray fluorescence spectrometer, XRF)[6]和近红外光谱法(near infrared spectroscopy, NIRS)[7]。 但是双能γ 射线与PGNAA需使用放射性源, 均存在核泄漏隐患与监管成本高的问题, 而XRF仅能检测原子序数≥ 11的元素(如Fe、 Ca), 无法分析煤中轻质灰分成分(如Al2O3、 SiO2), NIRS对无机矿物质的特征吸收峰响应微弱, 灰分预测误差常超过2%, 这无疑限制了上述四种技术在煤质现场应用的可行性。
激光诱导击穿光谱技术(laser-induced breakdown spectroscopy, LIBS)因其检测速度快、 原位分析能力强、 元素检测范围广, 以及煤质样品无需复杂预处理的特点, 已成为煤炭工业中灰分、 热值及元素成分快速检测的关键技术[8]。 在进行LIBS煤质分析时, 将高能激光束聚焦于煤样表面, 当脉冲能量密度超过煤的击穿阈值时, 煤质表层物质会被瞬间烧蚀并激发, 形成包含C、 H、 O、 Si、 Al、 Fe等元素特征谱线的等离子体。 通过光纤光谱仪采集煤中无机灰分组分及有机挥发分的特征谱线, 结合多元素特征谱线强度实现煤质多参数的快速定量分析。 然而, 煤中高碳基质对元素谱线产生的背景干扰[9], 针对煤质特性构建抗干扰光谱解析模型, 对提升LIBS在煤炭工业在线检测中的可靠性至关重要。 近些年来, 国内外学者在LIBS煤质定量分析领域取得进展。 Lu等[10]提出了一种基于小波阈值去噪(wavelet threshold denoising, WTD)和交叉验证递归特征消除法(recursive feature elimination with cross-validation, RFECV)的混合模型, 能够抑制LIBS煤质检测中的噪声干扰, 实现了灰分、 挥发分、 热值的准确定量分析。 上述研究虽减小了噪声对LIBS定量分析的干扰, 但是却忽略了煤质本身复杂的基质效应, Li等[11]采用预处理+定量分析的方法, 通过建立11点平滑结合二阶微分的定量分析模型, 有效降低了煤质样品中不同样品间基质效应差异, 将热值的预测均方根误差(root mean squared error of prediction, RMSEP)优化到0.276 MJ· kg-1。 然而伴随着机器学习技术的快速发展, 国内外学者开始探索更具泛化能力的非线性模型框架, 为突破现有技术瓶颈提供了新思路。 Zhang等[12]采用遗传算法(genetic algorithm, GA)优化的支持向量机(support vector machine, SVM)分类方法对煤样进行分类, 对每一类煤样建立偏最小二乘(partial least squares regression, PLSR)模型, 将挥发分的预测均方根误差降低至0.772。 Zhang等[13]建立人工神经网络(artificial neural network, ANN)模型对发电厂入炉煤指标进行预测, 灰分、 挥发分、 热值的平均绝对误差(average absolute error, MAE)优化至0.69、 0.87和0.56。 王安等[14]提出在小样本条件下使用核极限学习机(kernel extreme learning machine, K-ELM)等方法将固定碳、 灰分、 挥发分预测拟合系数分别提高了0.033、 0.102、 0.118。 上述方法在煤质分析中展现了潜力, 极端梯度提升决策树(extreme gradient boosting, XGBoost)作为近年来广受关注的高效集成算法, 其应用仍存在局限。 李晨阳等虽利用XGBoost对铜合金LIBS光谱实现了96.67%的分类准确率, 但其研究聚焦于金属材料, 未涉及煤质高维光谱的复杂干扰; 王铭萱等[15]将XGBoost与拉曼光谱结合用于血糖浓度预测, 尽管决定系数(R2)高达0.999 99, 但其模型依赖人工调参, 难以适应煤质在线检测的实时性需求。
基于此, 针对LIBS煤质定量分析中的背景干扰问题, 本研究提出将遗传算法(genetic algorithm, GA)与XGBoost深度融合, 通过GA的全局搜索策略自适应优化XGBoost超参数, 规避局部最优陷阱; 同时结合二进制编码动态筛选关键光谱特征, 降低数据维度与噪声干扰。 此方法提升了模型对煤质灰分与热值的预测精度, 并通过外部工业样本验证了其鲁棒性, 为LIBS技术在实际燃煤铜冶炼厂中的在线监测提供了可靠解决方案。
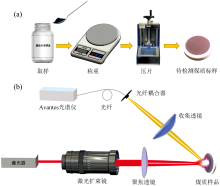
本论文选取我国两大煤炭产区— — 山西大同和内蒙古鄂尔多斯的共59个具有代表性的煤质标样作为研究对象。 所有煤样均依据GB/T 404— 2008《煤样的制备方法》进行制备和元素分析标定。 将5 g煤样破碎研磨至粒径< 0.2 mm, 使用YP-30T液压压片机在30 MPa压力下压制60 s, 制成直径30 mm、 厚度约3 mm的致密煤样压片, 具体的制样流程如图1(a)所示。 每个压片样品分别进行3次独立的LIBS光谱采集实验, 共获得177份煤样光谱数据, 表1给出了所测59个煤样的化学分析结果统计范围, 其中灰分含量范围为6.23%~40.95%, 热值范围为18.64~36.94 MJ· kg-1, 涵盖了烟煤到褐煤的主要品种。
 | 图1 (a)煤质样品制样图; (b)LIBS实验装置示意图Fig.1 (a) Sampling diagram of coal samples; (b) Schematic diagram of the LIBS experimental setup |
| 表1 煤质样本灰分、 热值含量分布表 Table 1 Distribution table of ash and calorific value content of coal quality samples |
本实验中采用波长为1 064 nm双脉冲激光器, 最大脉冲能量为200 mJ, 脉冲频率为5 Hz, 通过扩束再聚焦光学系统聚焦到样品表面, 激发煤质样品产生等离子体, 再利用旁轴收光系统收集等离子体光谱, 设备具体如图1(b)所示。 双脉冲激光器采用两路100 mJ脉冲激光合束而成, 第一个激光脉冲先作用于煤质样品表面, 使样品被激发产生等离子体, 在等离子体膨胀冷却后, 第二个激光脉冲再打到等离子体上对其再度激发。 这种二次激发过程能够使等离子体中更多的物质被持续加热、 电离, 增加了等离子体的温度和电子密度, 从而增强煤质样品LIBS光谱强度。 光谱仪采用低噪声CMOS探测器的制冷型Avantes光谱仪, 通过选择最优的光栅刻线数与狭缝尺寸, 分辨率能够达到0.09 nm。 光谱仪延迟时间设置为2 μ s, 积分时间设置为2 ms。 同时为了避免在同一位置检测时光谱信号减弱, 对整体实验结果的影响, 在数据采集过程中, 采用转盘对样品进行旋转运动, 实现样品多点位数据采集。
在传统的煤质灰分定量分析中, 特征选择通常依赖于专家经验, 通过预设规则对波长进行筛选。 尽管这一方法在实际应用中具有一定的实用性, 但其局限性亦不容忽视。 人工选线方法往往依赖于专家的直觉与经验, 容易忽略一些潜在的关键波长, 导致特征选择的过程受到人为偏差的影响, 从而影响模型的客观性和准确性。 而SHAP值(shapley additive explanations), 作为一种基于博弈论的解释方法, 旨在量化每个特征对模型输出的贡献。 通过计算每个波长的SHAP值, 能够自适应地评估各个波长对煤质灰分预测的影响, 从而实现更加科学和客观的特征筛选。 SHAP值能够为每个特征分配一个明确的贡献值, 体现其在模型预测中的重要性, 避免了传统人工选线方法中可能存在的主观偏差。 然而, SHAP值在处理特征共线性、 协同效应、 计算复杂度以及高维数据等方面仍然存在一定的局限性。 SHAP作为边际贡献度量工具, 难以有效反映特征之间的相互作用, 特别是在特征高度相关或存在强烈共线性时, 可能导致重要特征的贡献被低估或误删。 为了克服这些局限并提高特征选择的准确性, 本文在对光谱数据进行降维处理后, 再应用SHAP值进行特征筛选。 通过降维, 减少冗余特征的干扰, 可以有效地缓解特征共线性和协同效应问题, 确保最终筛选出的波长在煤质灰分和热值预测中的重要性被更加准确地评估, 从而提高模型的稳定性和泛化能力。
XGBoost是一种基于梯度提升决策树(gradient boosting decision tree, GBDT)的高效集成学习算法[16], 广泛应用于分类、 回归及排序任务。 其核心思想是通过加法模型(additive model)迭代优化多个弱学习器(决策树)的预测结果, 最终构建强学习器。 具体原理如下:
模型预测输出由K棵决策树的加权和构成:
式(1)中, F为决策树函数空间, fk为第k棵树的映射函数。 在第t次迭代时, 模型预测值为前t-1棵树的预测结果与新数ft的叠加
目标函数由损失函数L和正则化项Ω 共同构成, 旨在平衡预测精度和模型复杂度
式(3)中, L(yi,
式(4)中, ω j为叶子权重, γ 和λ 分别为叶子数量与权重的惩罚系数。 在第t次迭代中, 目标函数可简化为优化当前树ft
对损失函数进行二阶泰勒公式展开近似
式(6)中,
对ω j求导并令导数为零, 可得到最优叶子权重
将
在生成树结构时, 通过最大化分裂增益选择最优分割点
式(10)中,
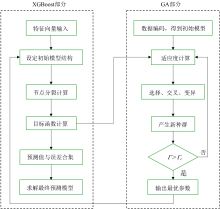
遗传算法(GA)作为一种全局优化方法, 凭借其种群多样性机制和混合参数空间搜索能力, 在本研究中被用来同步优化XGBoost的超参数与特征子集[18]。 与贝叶斯优化和随机搜索相比, GA通过并行演化策略有效避免了局部最优解, 能够适应LIBS光谱分析中的高维离散-连续混合参数空间, 提供了更为高效且可靠的优化方法[19]。 相比之下, 贝叶斯优化虽然在低维连续空间具有较高的样本效率, 但其顺序迭代机制使得计算延迟敏感, 且高斯过程在建模高维离散参数时表现不佳。 随机搜索虽然可以进行全域采样, 但其盲目性导致收敛速度较慢, 且在局部最优解区域容易遗漏全局最优解。 相比之下, GA凭借其强大的全局搜索能力、 适应性强和并行计算优势, 能够更高效地在复杂的超参数空间中找到最优解。 在本研究中, GA用于优化XGBoost模型的超参数, 并结合二进制编码进行特征选择, 从而提升LIBS煤质分析模型的预测精度与鲁棒性。 遗传算法中的超参数优化模块主要用于调整和选择遗传算法的参数, 以便提升算法的性能并获得更好的解。 遗传算法的超参数包括种群大小、 交叉率、 变异率、 选择策略等, 这些参数对算法的收敛速度和最终解的质量有很大的影响, 具体流程如图2所示。
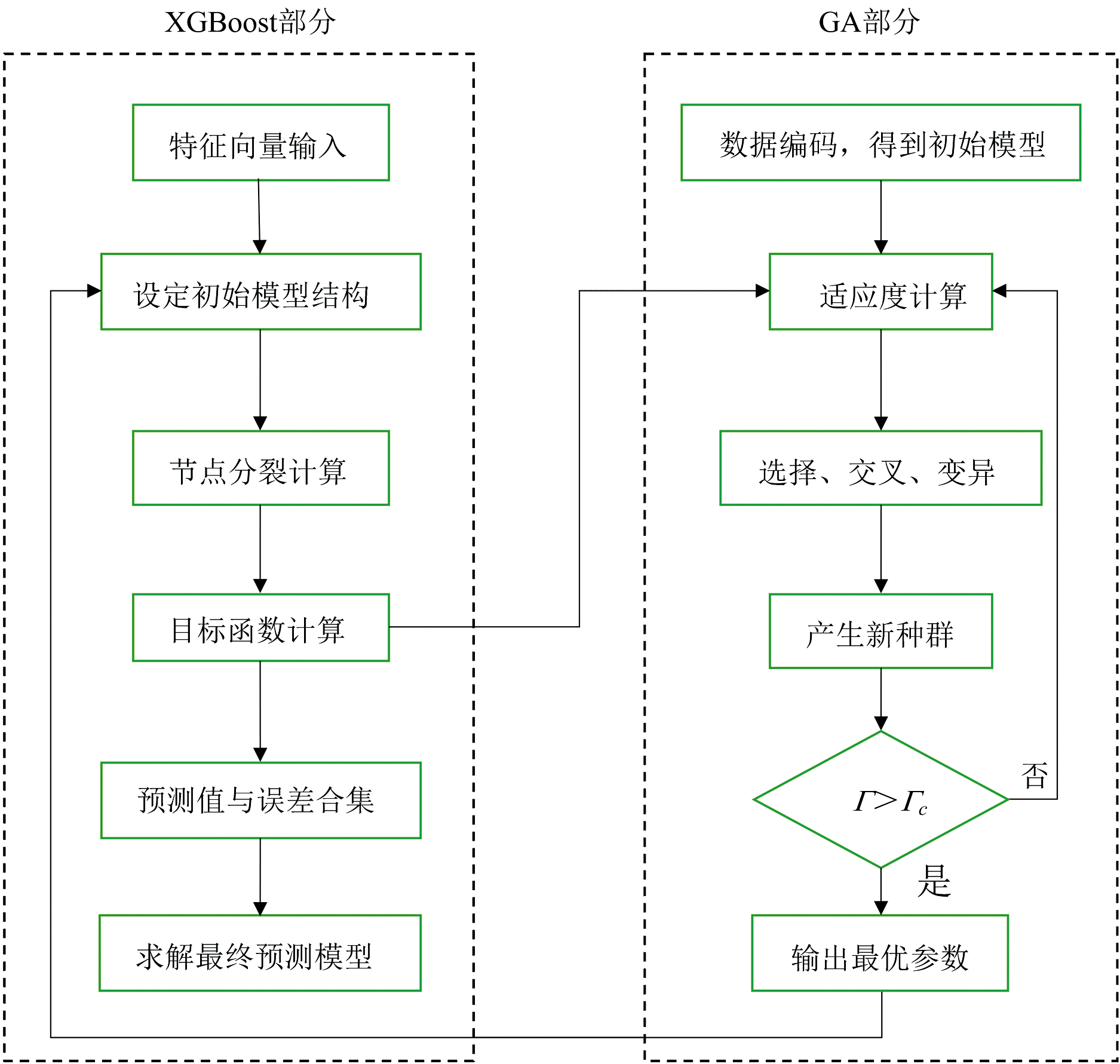 | 图2 GA-XGBoost模型流程图Fig.2 GA-XGBoost model flowchart |
步骤1: 对XGBoost模型的超参数进行二进制编码, 生成初始种群。
步骤2: 将二进制编码后的特征向量输入XGBoost模型进行训练, 同步记录每棵决策树的节点参数矩阵, 形成个体性能的量化依据。
步骤3: 计算各候选个体在训练集上的预测误差, 通过预设的适应度函数量化个体适应度值。 设定一个阈值Γ , 作为判断个体优劣的标准。
步骤4: 根据适应度值对种群执行选择、 交叉与变异操作, 生成新一代候选解集。 通过比较新一代群体的最高适应度Γ 与阈值Γ c, 决定是否终止迭代: 若Γ > Γ c, 则进入参数固化阶段; 否则重复步骤2— 步骤4直至满足条件。
XGBoost模型的性能往往受到超参数选择的影响。 传统的超参数选择方法通常依赖于人工调参或者网格搜索等方法, 这些方法可能会错过最优解, 且计算复杂度较高。 而遗传算法作为一种全局优化算法, 能够有效地在大规模超参数空间中进行搜索, 从而提高XGBoost模型的预测性能。 遗传算法优化的XGBoost模型通过对XGBoost的超参数进行优化, 通过适应度函数选择出最适合当前问题的超参数组合, 能够显著提升模型的准确性、 稳定性和泛化能力, 能够在较小的误差范围内做出更精准的预测, 并且减少了模型过拟合的风险, 具体参数范围如表2所示。
| 表2 GA-GXBoost超参数范围与遗传算法配置 Table 2 GA-XGBoost hyperparameter range and genetic algorithm parameters |
采用决定系数R2、 均方根误差RMSE、 平均绝对误差MAE、 相对标准偏差(relative standard deviation, RSD)、 来评价定量回归模型的预测性能, 相关的计算原理为
$\mathrm{RMSE}=\sqrt{\frac{\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}}{n}}$(12)
$\text { MAE }=\frac{\sum_{i=1}^{n}\left|y_{i}-\hat{y}_{i}\right|}{n}$(13)
$\mathrm{RSD}=\frac{\sqrt{\frac{\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2}}{n-1}}}{\bar{x}}$(14)
R2衡量的是模型对数据的解释能力, 表示特征能够解释目标值的方差比例。 R2的值范围从0到1, 越接近1表示模型的拟合效果越好, R2> 0.7通常认为模型拟合效果较好, 而R2< 0.5则提示模型可能未充分捕捉数据规律, 需优化特征或算法。 MSE是预测值与实际值差异的平方的平均值的平方根, 它给出了误差的标准单位, 反映了模型预测的误差大小。 当模型的RMSE值接近0时, 表示模型的预测误差很小, 表现较好。 但如果RMSE值显著较高, 则说明模型的预测误差较大, 可能需要调整模型或使用其他方法来优化性能。 MAE是预测值与实际值之间差异的绝对值的平均值。 它反映了预测值与实际值之间平均偏差的大小。 若MAE接近0, 说明模型的预测误差较小。 将RMSE和MAE一起评估, 可以提供更全面的模型性能反馈, RMSE强调了大误差, 而MAE则更关注整体的平均误差。 RSD是衡量数据相对波动性的一个指标, 通常用于描述数据集的离散程度。 RSD< 10%通常表明数据精度较高, RSD> 10%则可能提示需要改进实验设计或模型。
在本次实验中, 共使用了177组煤样数据, 所有样品通过随机抽样方法被划分为141个训练样品和36个测试样品。 为了进一步提高模型的稳定性并减少数据划分带来的偏差, 采用了5折交叉验证(5-fold cross-validation)方法对训练集进行进一步划分。 交叉验证是一种常用的机器学习模型验证方法, 其核心思想是通过将数据集划分为多个子集, 在每一轮验证中使用其中的部分子集进行训练, 剩余的子集用于验证, 从而评估模型的泛化能力。 在5折交叉验证中, 数据集被均匀划分为5个互不重叠的子集, 每次验证时, 模型使用4个子集进行训练, 剩余的1个子集用于验证。 该过程重复5次, 最终结果通过对5次验证的性能结果进行平均, 得到模型的整体评估指标。 这一方法不仅提高了模型的可靠性, 还有效减少了训练集划分所可能带来的偶然性误差。
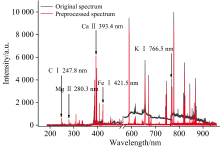
为了进一步提升定量分析的准确性, 并防止模型出现过拟合, 本文对原始光谱数据进行了多项预处理操作。 首先, 在光谱数据的背底校正方面, 采用了自适应迭代重加权惩罚最小二乘法(adaptive Iteratively reweighted penalized least squares, airPLS)。 通过最小化背景信号的平方误差, 准确估算并去除光谱中的背底, 其中窗口大小设置成5, 惩罚系数为0.1, 最大迭代次数为200。 该算法的优势在于其能够根据光谱的局部特征自适应地调整背底形状, 无需对背底进行先验假设。 通过这种方法, 可以有效去除光谱中的背底漂移, 并保留光谱中元素的特征信息, 从而确保后续分析的精度。 经过背底校正后, 对光谱数据进一步进行了S-G平滑去噪, 以减少高频噪声的干扰, 其中窗口大小设置为5, 多项式阶数设置成3, 并对数据进行了光谱识别及谱峰的提取。 基线校正与去噪前后的平均光谱如图3所示。
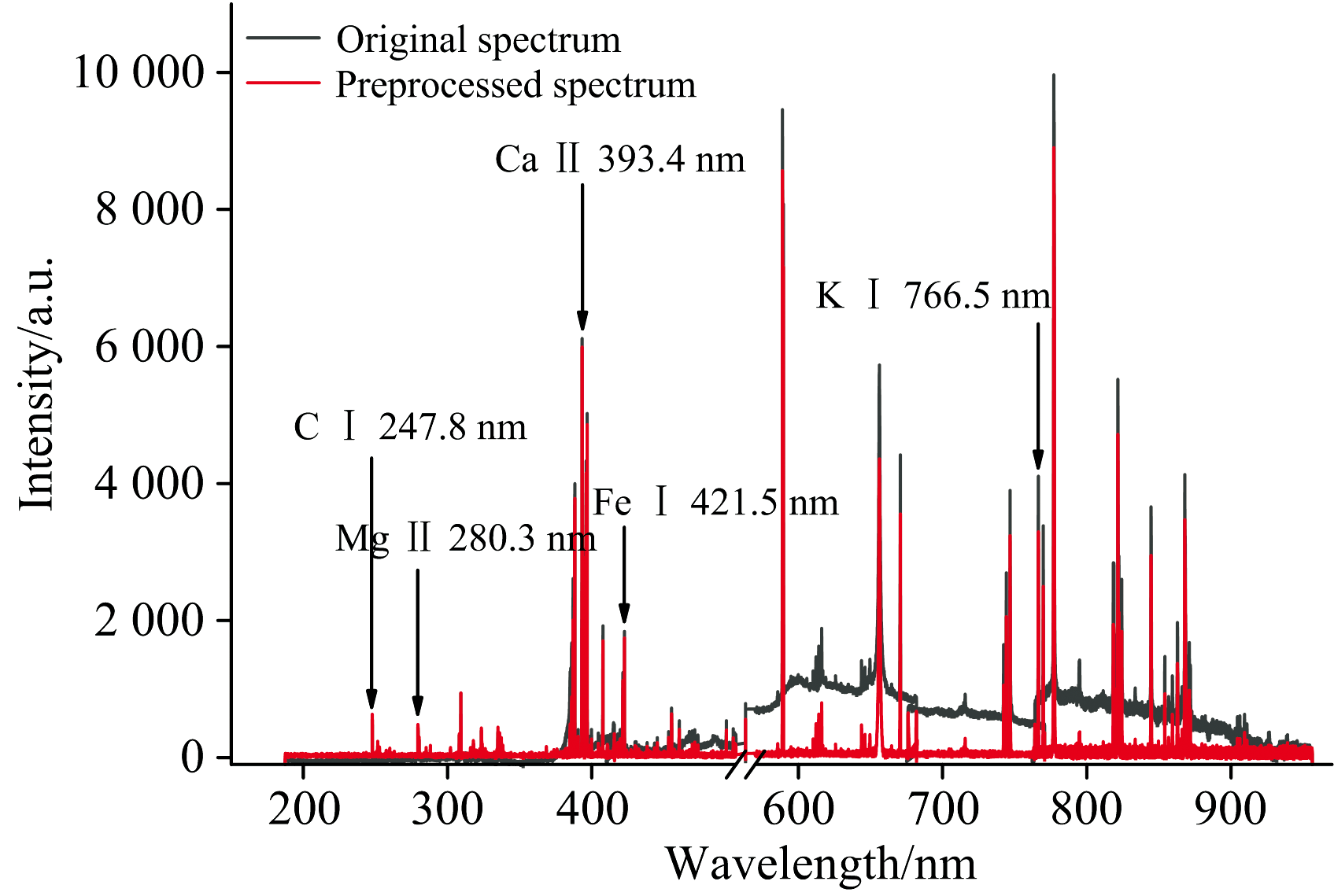 | 图3 预处理前后平均光谱对比Fig.3 Comparison of average spectra before and after preprocessing |
在谱峰识别与量化过程中, 首先识别出光谱中的500个强度最高的极大值位置, 这些极大值被认为是谱峰的中心波长[14]。 随后, 通过寻找每个谱峰中心附近的两个极小值, 构建每个谱峰的基线。 最后, 通过计算基线与光谱曲线之间的面积, 量化每个谱峰的强度信息。 通过这一系列的预处理操作, 原始光谱数据的维度由14 328维降至500维, 有效减少了数据的复杂性, 同时保留了与样品特征相关的关键信息。
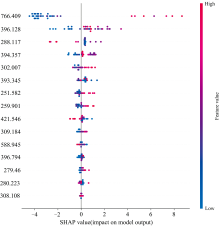
本研究利用主成分分析(principal component analysis, PCA)进行二次降维, 保留95%的累积方差贡献率后, 利用XGBoost模型计算每个波长对应的SHAP(shapley additive explanations)值。 通过求取各特征在所有样本上的平均绝对SHAP值, 筛选出前15个权重最高的波长, 如图4所示。 其中红色代表高特征值, 蓝色代表低特征值, 颜色越深, 表示该特征值对当前样本的SHAP值影响越显著。 最顶部的特征对模型预测影响最大, 其SHAP值的分布范围较广, 说明该特征在不同样本中的影响差异显著。
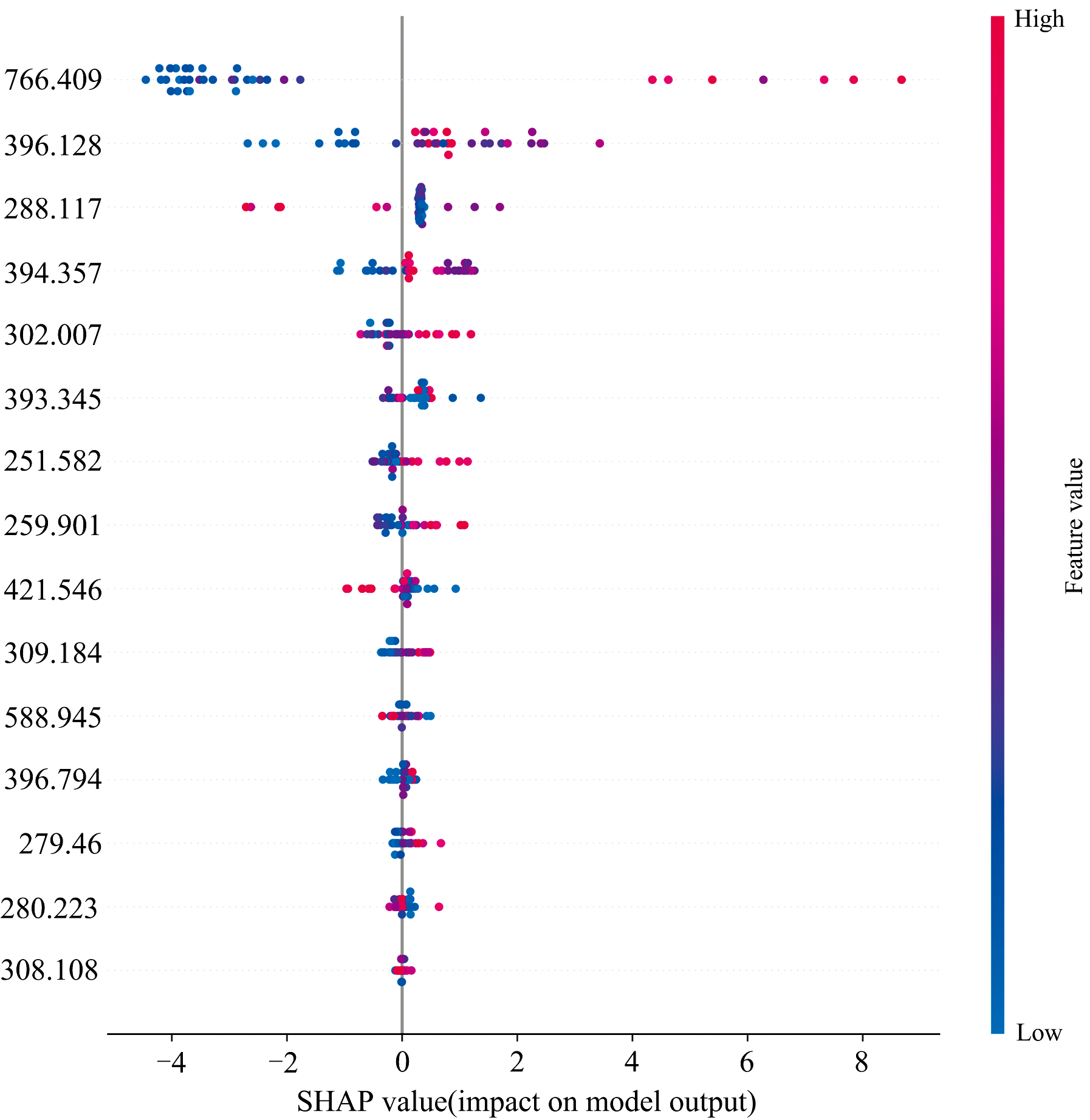 | 图4 前15特征SHAP值Fig.4 SHAP values of the top 15 features |
为评估所提模型的有效性, 本研究将GA-XGBoost模型与多种常用的回归方法进行了对比, 包括标准XGBoost、 多元线性回归(multiple linear regression, MLR)、 偏最小二乘回归(partial least squares, PLS)随机森林(random forest, RF)和支持向量机回归(SVM)模型。
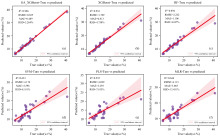
在灰分预测任务中, GA-XGBoost模型展现出显著优势。 如表3所示, GA-XGBoost的R2值达到0.986, 相较于传统XGBoost模型提升了0.053, 且显著高于其他对比模型。 其预测误差为所有模型中最低, RMSE为0.825, 较XGBoost降低0.964; MAE为0.489, 较XGBoost降低0.324; RSD为3.264%, 较XGBoost模型降低了1.494%。 整体模型效果较11点平滑-二阶微分模型[10]与WTD-RFECV混合模型[11]有较好的提升。 这一结果表明, GA-XGBoost在灰分预测中不仅具有更高的拟合精度, 还能有效抑制噪声干扰, 提升模型稳定性。
| 表3 模型预测结果比较 Table 3 Comparison of model prediction results |
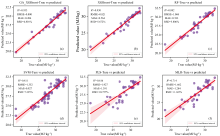
在热值预测任务中, GA-XGBoost同样表现卓越, 其R2值为0.933, 较传统XGBoost提升0.003, 优于随机森林和支持向量机等模型。 模型RMSE为0.800 MJ· kg-1, 较XGBoost降低0.021; MAE为0.494 MJ· kg-1, 较XGBoost降低0.070; RSD为4.801%, 较XGBoost模型降低了0.871%。 此外, 图5与图6展示了灰分与热值各模型预测值与真实值的对比, 其中GA-XGBoost的预测点紧密分布于对角线附近, 表明其预测值与真实值高度一致; 而其他模型的预测点则呈现明显离散趋势。
 | 图5 不同模型在煤质灰分上的预测效果(a)— (f)Fig.5 Predictive effects of different models on coal ash (a)— (f) |
 | 图6 不同模型在热值上的预测效果(a)— (f)Fig.6 Predictive effects of different models on coal calorific value (a)— (f) |
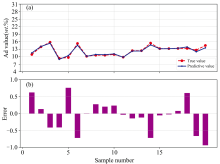
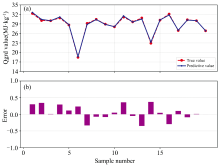
鲁棒性反映了检测系统在复杂工况下持续输出高精度结果的能力, 其核心体现在对未参与建模样本的参数预测准确性及长期稳定性方面。 工业场景中, 检测仪器需克服环境扰动与操作变量引入的系统误差, 而高性能软硬件协同架构可有效抑制系统漂移, 提升对异常工况的容忍阈值。 为验证本设备的工业鲁棒性, 采用20组未参与建模的煤炭样本进行外部验证。 这20组样品来自某燃煤铜冶炼厂, 通过现场实际生产过程中皮带物料进行跨带式在线检测, 通过化验室送检得到灰分与热值浓度后进行比对, 能够代表实际使用场景。 将GA-XGBoost模型应用于这20个样品的光谱数据, 比较预测灰分、 热值与标准值之间的偏差如图7(a)与图8(a)所示, 灰分与热值的预测值与真实值高度吻合, 最大绝对偏差分别小于1%和0.5 MJ· kg-1; 图7(b)与图8(b)进一步展示了各样本的误差分布, 灰分预测误差集中在± 0.9%范围内, 热值误差波动幅度低于± 0.35 MJ· kg-1, 且无明显系统性偏移。 实验结果表明, GA-XGBoost模型在复杂工业场景下仍能保持高精度与稳定性, 其误差水平能够满足燃煤铜冶炼厂在线监测的实时性需求[20]。 该模型的可靠性能为燃料配比优化、 燃烧效率提升及环保调控提供精准数据支撑, 从而降低设备损耗并减少碳排放。
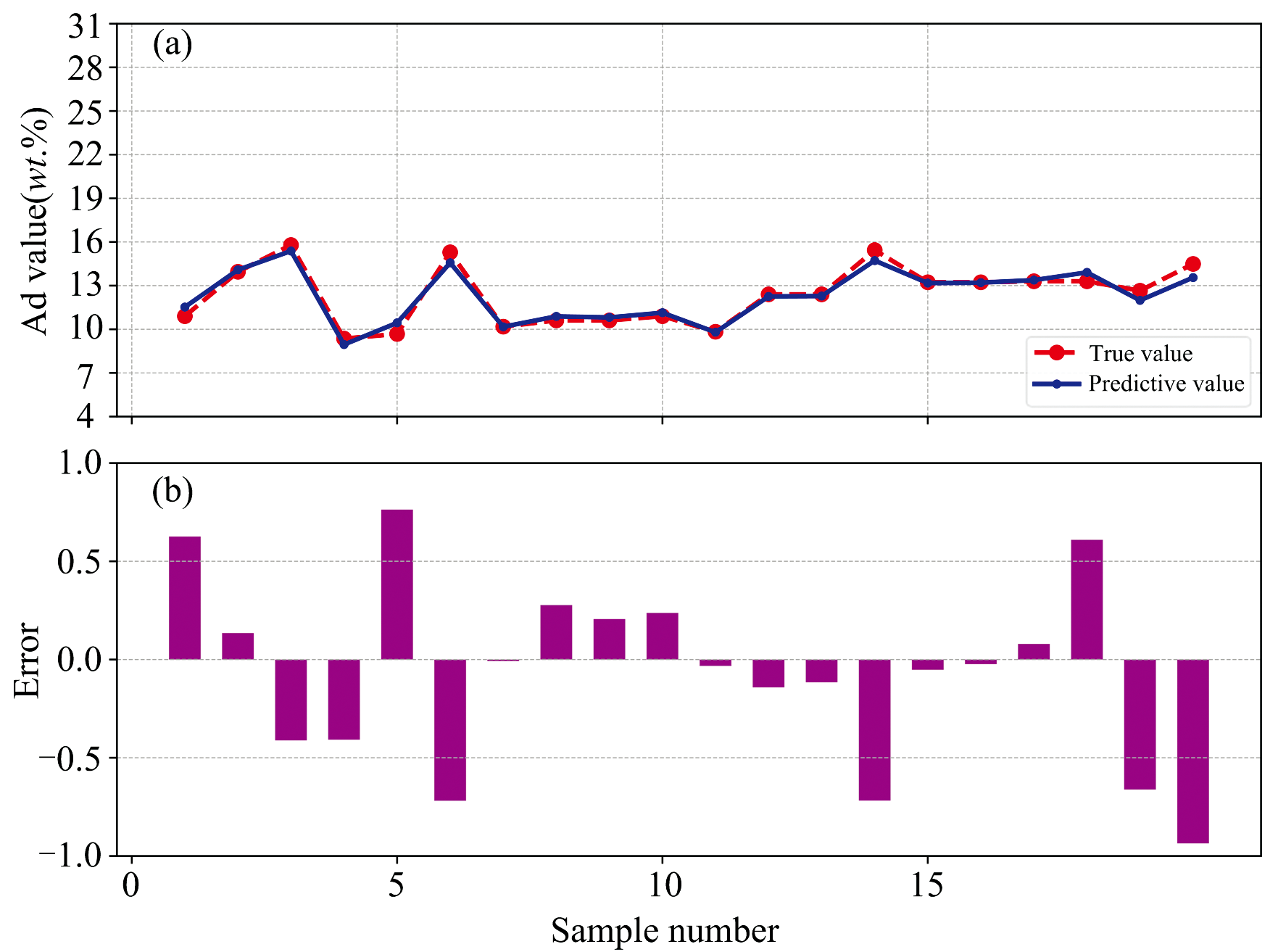 | 图7 灰分定量分析设备模型验证结果(a)— (b)Fig.7 Results of model validation of equipment for quantitative analysis of ash (a)— (b) |
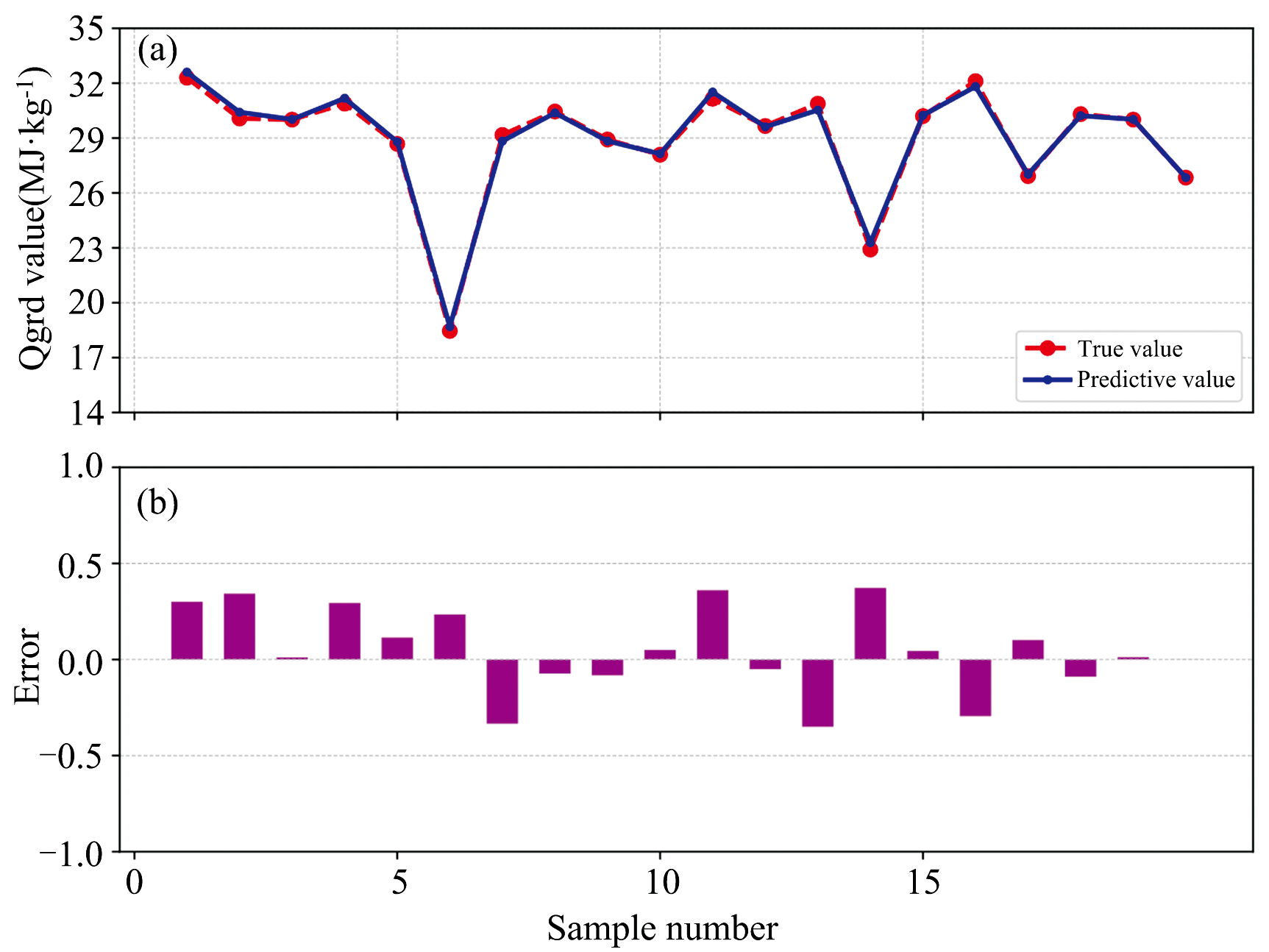 | 图8 热值定量分析设备模型验证结果(a)— (b)Fig.8 Results of model validation of equipment for quantitative analysis of calorific value (a)— (b) |
提出了一种基于遗传算法与XGBoost集成的煤质光谱定量分析方法, 并验证了其煤质在线分析中的应用潜力。 通过遗传算法对XGBoost模型的超参数和光谱特征子集进行全局优化, 所构建的GA-XGBoost模型在煤炭灰分和热值的预测中展现出优异的性能。 与传统的线性回归、 偏最小二乘法以及其他非线性模型相比, GA-XGBoost模型不仅在准确度和稳定性上表现卓越, 而且显著克服了光谱数据维度高以及模型参数敏感性强等问题。 在特征选择方面, 遗传算法采用二进制编码进行全局寻优, 有效降低了冗余特征导致的过拟合风险, 提高了模型泛化能力; 在超参数优化方面, 遗传算法能够以全局优化的方式自动探索更广阔的参数空间, 不受网格粒度的限制, 相比网格搜索和随机搜索在高维或连续参数空间中的计算效率和搜索能力更强, 从而更有可能获得更优的模型配置, 进一步提升预测精度和鲁棒性。 该模型不仅能为煤质分析提供可靠的数据支持, 还能够直接集成到煤质在线监测设备中, 实现对煤质参数的实时监控。 其应用前景广泛, 能够为铜冶金优化燃烧工艺提供科学依据, 帮助提高燃烧效率、 降低能源消耗和减少排放。 本研究为LIBS煤质定量分析提供了新的思路, 通过本文的研究, 证明了GA-XGBoost方法在煤质灰分与热值预测中的有效性。 虽存在一定的计算挑战和模型的局限性, 通过未来的技术创新和方法优化, GA-XGBoost有望成为解决更多高维、 大规模数据问题的重要工具。 随着计算技术的不断发展, GA-XGBoost将在各类实际应用中展现更大的前景, 推动智能预测领域的发展。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|