
{kind=link}
{kind=link}
面向气体光谱检测的机器学习技术研究进展
[张莹1, 2  , 张驰
, 张驰1, 2 , 石剑波1, 2 , 刘思思3, * ]
, 张驰]
|
|


作者简介: 张 莹, 1980年生,国家电网湖北省电力有限公司电力科学研究院高级工程师 e-mail: 171336973@qq.com
近年来, 人工智能技术在光谱检测领域受到广泛关注, 带来了数据驱动的科研新范式。 机器学习擅长从高维、 异构的光谱数据中探索关联性, 提高检测效率和准确度, 可以有效解决混合气体光谱检测难题。 介绍了机器学习的基本原理、 常见算法、 光谱数据建模的一般流程, 简要梳理了基于光谱学的各种气体检测技术及其典型应用, 并对机器学习在混合气体光谱检测技术的最新研究进展(2020年至今)进行了全面综述。 目前, 面向气体光谱检测的机器学习技术在工业过程控制、 癌症早期诊断、 环境监测、 地球观测系统等领域表现出巨大的潜力。 进一步, 重点探索了机器学习在混合气体定性识别、 定量分析以及高光谱成像中的具体应用, 最后讨论了基于机器学习的气体光谱检测技术在实际应用中面临的挑战与前景。 本文可为气体光谱检测及传感领域的相关研究者提供新思路和建议, 推动和扩展机器学习在该领域的应用。
Artificial intelligence (AI) technology has garnered significant attention in spectral detection recently, establishing a data-driven scientific research paradigm. Machine learning (ML) exhibits advantages in exploring correlations within high-dimensional and complex spectral data. It enhances detection efficiency and accuracy, thereby effectively addressing challenges in the spectral detection of gas mixtures. This paper introduces the fundamental principles of ML, common algorithms, and the general workflow for modeling of spectral data. It briefly reviews various spectroscopy-based gas detection techniques with typical applications, and provides an up-to-date overview (since 2020) of ML advancements in mixed-gas spectral detection. ML-driven spectroscopy technologies for gas show great potential across diverse fields, including industrial process control, early cancer diagnosis, environmental monitoring, and earth observation systems. Specifically, this work explores ML applications in qualitative identification and quantitative analysis of gas mixtures, as well as hyperspectral imaging. Finally, the paper discusses critical challenges and prospects for the practical implementation of ML-based gas spectral detection technologies. This review aims to provide novel insights and recommendations for researchers in gas spectroscopy detection and sensing, thereby advancing and expanding ML applications in this field.
随着工业化的快速发展, 大量的工业气体被排放到空气中, 造成严重的生态环境问题, 如温室效应、 酸雨、 光化学烟雾等。 同时, 很多气体对人类的生产和生活产生重要影响。 因此, 对气体的种类和浓度进行检测具有非常重要的现实意义。 气体检测技术主要分为电化学传感、 光谱法和色谱法三类。 对于需要快速分析和实时监测的应用场景, 基于色谱法的气体检测方法的响应时间通常较长, 无法实时监测和迅速反应。 电化学传感器虽然响应迅速, 但电极材料易损耗且不抗干扰。 相比之下, 光学气体检测与传感技术具有检测快速(秒级)、 使用寿命长且易微型化等显著优势, 被广泛用于工业生产安全、 环境保护和临床医学等领域。 随着各种光谱技术的突破, 光学检测灵敏度已提升至ppb量级。 然而, 光谱数据具有高维度和重叠峰的特点, 在多组分气体同步检测时仍存在不少问题, 如低信噪比环境下特征峰辨识度不足、 多元气体吸收峰重叠效应引发的解谱困难, 以及环境参数漂移引起的系统误差等, 严重影响光谱检测技术的灵敏度和精度。 特别是针对半挥发性有机物(VOCs)、 肺癌早期呼气标志物等复杂混合气体的精准检测, 仍需在光谱解析算法和抗干扰传感系统设计方面实现突破。
近年来, 以深度学习(DL)为代表的人工智能(AI)技术正推动光谱检测领域进入数据驱动的时代。 随着各种机器学习技术的引入, 研究者开始探索其在光谱信号处理、 特征提取及浓度反演中的潜力, 为气体光谱检测技术带来了前所未有的机遇。 在实际检测环境中, 气体光谱信号较复杂, 通过机器学习模型快速对光谱数据中复杂旋转或振动指纹光谱特征进行识别, 减少人工干预, 提高分析效率。 这对于需要快速响应和实时监测的应用场景(如环境监测和疾病诊断)至关重要。 此外, 相比传统光谱数据分析方法, 机器学习中的各种DL方法能够通过多层神经网络处理高维特征, 有效解决多组分气体光谱检测低信噪比及光谱重叠、 模型精度低等难题, 提高检测准确度。 目前, 机器学习辅助的气体光谱检测技术在环境监测、 工业过程控制、 CH4泄漏监测、 癌症早期诊断、 高光谱成像(HSI)和地球观测系统等方面被广泛应用(图1)。 机器学习与气体光谱检测技术的深度融合已成为国外内研究的热点方向。
 | 图1 机器学习在气体光谱检测技术中的典型应用场景Fig.1 Typical applications of machine learning in spectroscopy detection techniques of gas |
因此, 本文的主要内容为: (1)介绍机器学习的基本原理、 常见算法以及光谱数据建模的一般流程; (2)总结各种气体光谱检测技术及其典型应用; (3)重点概述最近5年机器学习在气体光谱检测领域的研究进展和发展现状; (4)深入分析当前应用机器学习技术在气体光谱检测中面临的主要挑战, 并探讨解决这些挑战的潜在机遇。 本综述旨在帮助感兴趣的初学者快速了解该交叉领域的最新研究进展, 同时为该领域的研究人员和实践者提供创新的想法和思路, 以推动该交叉领域的持续改进。 需要指出的是, 本文侧重于机器学习在气体光谱检测中的应用场景介绍, 相关原理和公式推导详见有关文献[1, 2, 3]。 此外, 电化学气体传感器也不在本综述的范围之内。
机器学习是AI的核心分支, 其核心思想是通过数据训练模型, 使计算机能够自动发现规律并做出预测或决策。 其原理基于统计学和优化理论, 通过构建算法从数据中学习输入与输出的映射关系。 机器学习可分为监督学习、 无监督学习和强化学习三类。 监督学习利用带标签数据来训练模型, 又可分为分类和回归两类问题; 无监督学习用于数据探索, 挖掘无标签数据中的结构; 强化学习通过试错与奖励机制交互学习最优决策策略。 监督学习在气体光谱检测中使用最广。 例如, 从测量的吸收光谱中推断气体分子结构是一个分类问题。 反之, 从已知分子结构预测其光谱或相关属性则为回归问题。
不同类型机器学习所采用的算法各不相同。 监督学习的算法主要有: (1)线性回归/分类: 通过线性函数拟合数据, 适合简单预测任务(如偏最小二乘PLS); (2)决策树: 基于特征划分的树形结构来寻找最优决策规则, 可解释性强, 此类算法有随机森林(RF)、 梯度提升树(如XGBoost、 LightGBM); (3)支持向量机(SVM): 通过最大化分类间隔处理高维数据; (4)逻辑回归: 通过将线性回归模型的预测结果经过Sigmoid 函数(非线形)映射到(0, 1)之间, 用于解决分类问题; (5)朴素贝叶斯: 一种基于贝叶斯定理并假设特征之间相互独立的概率分类算法; (6)人工神经网络(ANN): 通过多层非线性结构学习复杂数据特征, 其中DL在气体光谱检测中广泛应用, 如多层感知机(MLP)和卷积神经网络(CNN)。 无监督算法有密度估计、 聚类(K-means、 层次聚类)和降维(PCA、 t-SNE和UMAP)等。 算法选择需权衡数据量、 特征维度及任务需求, 结合领域知识优化模型性能。
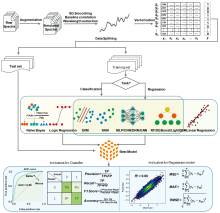
监督学习的建模通常包括以下步骤: 数据采集、 数据增强与预处理、 数据拆分、 算法选择及模型训练和模型性能评估(图2)。 机器学习建模往往对样本数据量有一定的要求。 有文献建议样本量与特征量的比值不低于20[4]。 当样本量不足时, 可以采用密度泛函理论(DFT)[5]或数据增强策略[6]生成模拟光谱。 HITRAN数据库广泛用于光谱的模拟与仿真[7, 8]。 例如, 有研究通过锁相放大技术从HITRAN数据库中获得的具有voigtfit曲线的光谱, 并引入了人工噪声以考虑噪声对模型性能的影响, 然后利用朗伯比尔定律将两种气体经过微分运算后的光谱按随机比例叠加, 通过组合得到混合气体的模拟光谱数据[9]。
 | 图2 光谱数据构建监督学习模型的一般流程Fig.2 A generic modelling flow of supervised learning for spectral data |
由于收集的原始光谱数据存在大量的毛刺噪声和基线漂移现象, 模型的精度并不是随着样本数的增加而越来越高。 相反, 随着训练样本的增加, 引入到模型中的干扰因素也会增加, 这些干扰因素的存在可能会掩盖光谱中的有用信息, 导致模型性能的下降。 因此, 有必要对采集到的原始光谱进行预处理, 包括噪声平滑、 基线校正、 特征提取等步骤。 多采用Savitzky-Golay卷积平滑算法降低光谱中的样本噪声, 采用airPLS方法消除基线漂移的影响[10]。 特征提取目的是降低数据维度和光谱信息的冗余量, 提高后期建模的效率和模型稳健性。 除从最初波段中直接选取有效的特征波段外, 也可通过对一个或若干个原始波段的属性关系进行组合变换, 得到新的特征属性。 实际应用中常结合多种降维方法进行特征提取[11, 12], 如PCA、 离散小波变换(DWT)、 变量重要性投影等。 最后, 将预处理后的每个光谱数据保存为高维向量。 此外, 多/高光谱数据还可表示为序列或者图像。
下一步, 加载预处理后的数据集, 并将其存储为标签对应的数据。 按照一定比例将数据集划分为训练集和测试集。 数据集划分比例直接影响建模效果, 如果预测集和校正集划分比例不合理, 模型预测性能必然不佳。 再次, 根据任务需求(分类/回归)选择合适算法并在训练集上训练模型。 此时需要避免数据泄露问题, 即测试集数据不可用于训练模型, 仅用于评估最佳模型的泛化能力[13]。 训练过程中, 可使用优化算法(如梯度下降、 随机网格搜索、 遗传算法)调整模型超参以最小化损失函数, 从而估计最优超参。 过拟合是模型训练过程中常见的问题之一, 一般可通过交叉验证来避免模型过拟合。 最后, 应用最佳模型在测试集数据进行预测。 采用多个评价指标来综合评价模型预测性能, 尤其是当数据标签不平衡时。 对于分类模型, 计算其预测精确率(Precision)、 准确率、 召回率(Recall)、 F1分数和特征工作曲线(ROC)下面积(AUC)等指标; 对于回归模型, 计算其均方误差(MSE)、 平均绝对误差(MAE)、 均方根误差(RMSE)、 决定系数(R2)。
气体光谱检测技术主要包括被动式差分吸收光谱(DOAS)、 傅里叶红外光谱技术(FTIR)和可调谐激光吸收光谱(TDLAS)、 拉曼光谱、 激光诱导荧光光谱(LIF)等。 被动式DOAS技术采用自然光为光源, 主要用于对流层和平流层中的大气痕量气体浓度反演、 遥感成像和污染排放监测等[14, 15]。 基于车载或者机载的便携式DOAS系统还能为工业园区气体泄漏、 无组织排放等气态污染物的应急性及监督性监测和评估提供便捷、 有效的技术手段[16, 17]。 FTIR技术可以在城市、 自然及工业场景下大范围识别NH3、 N2O等大气污染物以及温室气体(如CO2、 CH4和SF6)并精准定位泄漏高发区[18, 19]。 TDLAS被广泛应用于气体流场检测、 燃烧诊断、 泄漏检测和定位等工业应用场景中[10, 20, 21, 22, 23, 24]。 拉曼光谱技术在气体能源质量监测[25]、 复杂气体混合物中高选择性和灵敏检测[26, 27]、 工业过程和环境监测中快速检测爆炸性/有毒有害气体[28, 29, 30, 31]、 VOCs检测[32]、 呼气代谢疾病早期诊断中检测气体生物标志物[33, 34, 35]等方面具有较高的研究和应用价值, 检测限低至亚ppb级别。 LIF主要用于检测生物体系中的各种气体信号分子, 在生物、 化学、 医学食品科学和环境科学等领域有广泛的应用前景[36, 37]。 LIF技术在复杂大气环境下的NOx高精度监测[38, 39]、 研究裂解氨燃烧火焰中NO的生成[40]以及检测碳氢化合物火焰中CO[41]亦有应用。
此外, 近年来新型气体光谱检测技术不断涌现, 如PAS、 光致热弹光谱(LITES)和激光诱导击穿光谱(LIBS)等。 PAS是一种基于光声效应检测气体吸收光辐射后产生的光声信号的新型光谱检测技术, 在大气CH4实时在线监测[42]、 天然气生产和燃气设备燃烧过程中短链烃类检测[43]、 电力设备故障诊断[44, 45]、 工业生产过程中的SF6及分解产物检测[46, 47]等方面开展了大量的研究。 LITES是一种基于石英音叉热弹效应的新型光谱检测技术, 由哈尔滨工业大学马欲飞于2018年首次提出[48]。 LIBS技术则利用超短脉冲激光直接作用于样品气流产生气态等离子体, 通过检测等离子体原子发射光谱确定样品的气体成分及含量。 目前, 国内外学者基于LIBS技术在检测氮气及稀有气体中的微量气体杂质、 温室气体和新能源氢气、 燃料/空气当量比以及燃烧诊断等方面开展了一些探索的工作[49]。
近年来, 机器学习技术的兴起为有效解决混合气体光谱检测难题提供了新思路。 在真实场景下, 很少存在单一气体, 往往多种气体混合共存。 低浓度下的背景噪声干扰是目前混合气体组分光谱定性识别技术所面临的主要挑战之一。 在光谱噪声干扰方面, Kistenev等[50]采用MLP与CNN模型提升宽线宽激光器(如光学参量振荡器)在气体吸收光谱中的分辨率。 结果发现, MLP在低噪声下优于CNN, 序列集成MLP模型在结合高斯或傅里叶滤波后, 可在中等噪声下实现更优重建, 但噪声超过4%时其精度下降3%~8%。
混合气体检测可以进一步分为针对单一气体选择性检测和多气体组分同时两类检测技术。 单一气体检测技术往往针对特殊的应用场景, 对检测特定目标物的抗干扰能力(即选择性)和精度的要求较高。 机器学习算法可以辅助对混合气体中特定目标物的精准识别。 例如, 在医学诊断中, Li等[51]开发了一种基于SERS技术的柔性纸膜传感器AgNWs@ZIF-8, 用于识别模拟呼气中结直肠癌标志物醛类气体。 结果表明, 集成ANN算法后, 传感器识别准确率高达94%。
由于多种气体组分同时检测更能满足用户的需求, 越来越多的研究聚焦于如何同时精准检测混合气体中的多种组分。 采用光谱检测技术进行混合气体测量时, 吸收谱线重叠较为严重且相互交叉吸收干扰的现象会造成测量误差大、 分析精度低。 待测组分本征光谱重叠(如CH4与乙烷的红外吸收峰)难解析是目前多气体组分光谱解析技术存在的主要难题之一。 Enders等[52]利用CNN对FTIR图像进行机器学习建模, 通过NIST数据库中8 728个气相有机分子光谱数据训练出15种常见官能团的识别模型, 实现了无需人工干预的自动化光谱解析。 在环境污染监测方面, Zhao等[53]提出基于FTIR与反向传播神经网络(BP-ANN)的融合方法, 通过优化学习率、 动量因子等网络参数, 有效解决了中红外波段汽车尾气中CO、 NO、 NO2与SO2吸收光谱重叠的检测难题。 在生物标志物健康监测方面, Liu等[54]报道了一种基于AI的中红外芯片波导“ 光子鼻” 传感器, 通过亚波长光栅波导设计和CNN算法, 成功解决了VOCs光谱重叠难题, 二分类精度达到93%, 体积分数的浓度预测误差降低至2.4%。 Lee等[55]采用PCA降维对不同VOCs等离子体增强的红外吸收光谱进行分类识别, 用于辅助早期医疗诊断。 Yang等[56]对比了传统的PLS和RBFNN方法对测井气体的红外光谱识别能力, 发现使用CNN模型对元素气体识别准确率达到100%, 混合气体的识别准确率为98%。 Chowdhury等[8]提出了一种基于一维CNN的红外吸收光谱分类模型, 针对含10种大气相关小分子的多组分混合气体, 在用户自定义频段内实现82%~97%的准确识别。 目前, 由于红外光谱数据较多且易获取, 多数相关研究利用红外吸收光谱数据构建机器学习模型。 不难发现基于ANN的算法在众多算法中表现出色。
机器学习在其他气体光谱检测技术中亦有应用, 但研究十分有限。 Chen等[12]报道了一种SERS气体传感器。 该传感器结合PCA与DWT降维对拉曼信号进行预处理, 在闭集识别中采用SVM算法对四种挥发性芳香化合物及其混合蒸气的分类准确率高达99%; 开集识别中利用CNN特征提取与类锚聚类(CAC)模型, 在开放度0.087 1时AUC达0.846、 已知样本分类准确率94.5%。 Chowdhury等[57]利用8种机器学习方法对太赫兹波段12种VOCs和卤代烃旋转吸收光谱进行分类, 模拟数据分类准确率达88%~99%, 实验噪声数据中SVM和MLP的“ 一对多” 模型准确率可达87%~94%。 该方法可推广至其他频段和化合物。 Mansouri等[11]利用大气压射频氦等离子体的光学发射光谱结合偏最小二乘判别分析(PLS-DA)检测痕量CH4气体, 检出限低至1 ppm, 并在0~100 ppm范围内建立九分类模型。 通过变量重要性投影、 波长压缩等算法优化, 将高维共线光谱数据变量数显著缩减, 多轮训练测试中波长压缩法准确率超97%。
在利用光谱技术定量分析混合气体组分时, 不同气体成分的光谱信号相互重叠。 并且, 气体分子之间的相互作用导致它们的振动方式与纯物质相比有所不同。 另一方面, 对于光谱定量分析, 测量气体浓度的准确性取决于压力稳定性和光谱拟合精度。 在实际环境下, 光谱信号很容易受到实验现场的温度、 压强和入射光源波长漂移的影响, 导致正比关系偏移[63, 64]。 这些因素给混合气体定量分析带来了很大困难。 传统方法必须对压力和温度定期校准, 再采用单变量和多变量方法以及高斯拟合、 多项式拟合、 线性拟合等简单模型处理低信噪比的多组分复杂光谱数据。 例如, 檀兵等[65]利用Voigt函数对原始光谱进行拟合以解决多元素共存条件下的谱峰重叠问题; 在此基础上, 利用拟合谱峰的中心波长、 光强、 半峰全宽和谱峰质心构建特征参数向量, 从而提升小信号拉曼谱峰的判别能力。 传统方法的测量精度往往与模型的建立好坏有直接联系, 要取得较高的精度则需要大量的已知样本进行训练。 此外, 不同气体组分构成的混合物模型也存在着差异, 一旦测量环境和测量对象的组成发生改变, 则需要重新收集样本建立定量模型。 因此传统光谱多组分定量分析方法难以满足实际应用需要。
构建机器学习回归模型为解决传统光谱定量模型面临的挑战提供了可行的思路。 针对光谱训练样本稀缺、 激光波长漂移的问题, Xiong等[66]提出了一种基于ANN的混叠光谱智能抗扰的方法, 并应用于中红外波长调制光谱(WMS)气体检测系统, 实现了CH4、 H2O、 C2H6的三组分气体的同步测量。 作者利用迁移学习的训练策略在受控的实验室条件下模拟了大量的混叠光谱进行训练, 以提高模型的泛化能力, 同时采集了少量的实验光谱数据进行模型的校准。 此外, 为解决由激光工作波长漂移引起的信号平移的问题, 作者采用了2f/1f归一化来减少信号强度变化带来的影响, 并通过对光谱信号平移的方法来扩充数据集用以对模型进行增强训练。 该模型在不增加任何额外的硬件设备的情况下, 有效解决了吸收谱线交叉干扰的问题, 极大提高了系统在复杂环境下稳定性。 Cai等[67]开发了一个基于近同心腔增强拉曼光谱系统, 结合一维卷积神经网络-长短时记忆网络(CNN-LSTM)与注意力机制模型在线检测泥浆录井中10种烃类/非烃类气体。 新方法有效克服了激光波动、 振动干扰及谱峰重叠问题, 检测限低至0.004%~0.022%, 平均误差0.9%~3.5%, 最大误差低于12%。 Wang等[68]针对太赫兹气体定量检测中光谱参数获取难、 宽带数据降维复杂的问题, 构建了基于高斯过程回归(GPR)的时域-频域双机器学习模型, 通过抗噪声干扰的端到端算法处理CO的太赫兹时域光谱数据。 该定量模型在模拟和实测中均实现均方根误差低于0.6%, 其中频域模型抗色散畸变, 时域模型消除时序噪声更优。 闪霁芳等[59]构建了一个SVM模型用于解决光纤激光气体传感中NH3与CO2吸收谱线交叉干扰导致的测量误差问题。 该模型采用自适应变异粒子群算法优化超参, 对0.5%~2% NH3与2%~5% CO2混合气体的体积分数预测均方误差低至0.000 088和0.000 170, R2值均达0.99, 在精度与效率上均比传统优化方法更优。
在极端复杂场景的气体监测(如CH4泄露)过程中, 环境条件波动较大, 传统方法需要频繁校准。 DNN模型可以在经过足够样本训练后直接从吸收光谱中学习特征, 实现不需要压力校准和轮廓拟合的气体浓度直接识别。 Wang等[69]报道了一个基于DFB激光二极管的CH4检测气体传感器系统, 并采用DNN算法构建了一个激光吸收光谱回归模型直接定量CH4浓度, 预测的浓度与校准值吻合较好, 标准偏差仅5.95 ppm。 此外, GPR算法亦有较多应用。 Mhanna等[9]针对天然气发动机CH4逃逸监测中传统方法校准频繁、 计算复杂的问题, 提出一种基于机器学习增强的WMS传感器, 通过GPR模型反演信号。 结果表明, 该传感器在船舶尾气实测中平均绝对误差仅为4%, 计算效率与精度显著提升。 Andrews等[70]开发了一种基于GPR算法的CH4实时监测系统, 通过云端平台连接分布式传感器网络, 可在全天气条件下以1 ppm精度、 0.6 kg· h-1泄漏率阈值检测石油天然气设施中无规律分布的CH4泄漏, 其小参数模型有效整合环境干扰因素。
高光谱遥感技术可以获取海量的高分辨图像数据。 一张高光谱图像(HSI)不仅包含丰富的光谱域信息, 还包含高分辨率的空间域信息。 光谱信息可以充分反映气体的物理结构、 化学成分的差异, 而空间域信息则反映样本的大小、 形状、 缺陷等外部品质特征。 中国发射的风云四号B星上搭载的GIIRS是世界首个业务化运行的静止轨道干涉红外探测器, 其以2 h的时间分辨率对东亚进行昼夜持续扫描, 可反演获得大气温湿度廓线及多种反应性痕量气体。 广泛的探测区域以及时空密集扫描带来的海量数据为其大气参数的实时反演带来挑战。 相比于常规物理反演方法, 基于机器学习的高光谱反演技术更高效、 优势更明显, 尤其是基于DNN的计算机视觉算法。
目前, 机器学习技术在利用高光谱监测CH4泄漏中应用最为广泛。 Wang等[71]开发了基于3D-CNN的DL模型(VideoGasNet), 将红外光学成像技术从泄漏检测拓展至自动化分类, 二分类(泄漏/非泄漏)准确率近100%, 三分类(小/中/大泄漏量)达78%, 但八分类精度降至39%。 R
此外, 有研究者尝试采用高光谱遥感结合机器学习技术分析渗漏区附近植被的光谱特征, 从而间接获取CH4渗漏信息。 Du等[74]提出了一种基于植被响应机制的知识引导DL框架, 通过融合图像与近红外-红边-红波段光谱的多分支网络(Img-Spec-PGE模型)可以精准估算天然气胁迫下小麦叶面积指数(R2=0.867), 结合改进的SAFY-NG物理模型同化反演应力因子Ka, 实现了地下天然气微泄漏的早期检测及泄漏量区分。 Ma等[75]利用植被作为生物传感器, 基于高光谱影像分析植被指数及DNN开展地下天然气泄漏的早期检测。 通过优化土壤调节植被指数(OSAVI)在泄漏21 d后可有效识别植被胁迫, 而DNN在CH4暴露3周后检测准确率达98%, 并发现CH4导致植被光谱可见光增强、 近红外减弱。
在其他强反应性气体泄漏监测方面(如CO2、 CO、 N2O、 HCHO和NO2), 机器学习技术也有应用。 Ma等[76]通过改进常规红外成像技术并结合机器学习模型识别CO2泄漏, 准确率达到95%以上。 Jiang等[77]通过构建机器学习模型结合地面污染物浓度、 不同高度的气象参量等特征变量预测了HCHO和NO2在对流层底层的垂直廓线, 预测结果与MAX-DOAS观测结果高度一致(r=0.98)。 Fan等[78]利用长时序、 高分辨率的卫星影像获取与N2O相关的珠江口水环境参数, 结合机器学习算法筛选最优输入特征集, 开发N2O浓度估算模型和扩散通量核算方法, 分析2003年— 2022年珠江口N2O浓度与排放的时空动态, 量化了年度和季节性的排放特征, 识别了排放的热点区域, 并揭示了输入特征对模型估算过程的影响。 Liang等[61]利用卫星数据开发了一种基于辐射传输模型和机器学习的快速反演方法, 成功实现了东亚地区CO浓度的高精度监测(陆地和海洋反演方差解释率超98%)。 该方法无需传统迭代计算即可获得与最优估计、 地基观测一致的CO时空分布结果。
机器学习技术还可以帮助解决长波红外高光谱气体检测技术背景干扰问题。 Yu等[79]针对FTIR系统检测气体烟云时干扰特征难以去除的问题, 采用多类SVM分类算法, 通过训练阶段同时学习目标气体光谱与残留干扰特征构建分类超平面, 在测试阶段有效抵抗未消除干扰的影响。 该方法能鲁棒识别有害气体云, 提升FTIR的抗干扰能力。 Ö zdemir等[80]针对长波红外高光谱气体检测中传统方法忽略背景与气体辐射混合的问题, 提出一种结合解混与分类的DL框架: 通过亮度-温度数据转换, 采用3D-CNN与自编码器网络提取端元光谱及丰度, 再经全连接网络分类, 在CH4和SO2检测中性能优于传统光谱角匹配及自适应余弦估计法, 消融实验证实解混模块对提升检测精度具有关键作用。 Jarman等[81]则基于图像分割的局部白化方法, 通过结合全局协方差与局部均值优化背景建模, 并利用分水岭分割集成生成像素级背景估计, 来解决长波红外高光谱气体检测中背景光谱估计难题。 该方法在洛杉矶盆地的机载数据中显著提升了模型分类置信度, 有望用于复杂场景下气体羽流识别。
机器学习擅长快速识别高维光谱数据中的复杂模式, 从而构建光谱-分子结构映射关系, 在混合气体定性识别、 定量分析和HSI等方面具有广泛的应用潜力。 然而, 面向气体光谱检测的机器学习研究目前仍面临着数据质量、 稀缺性和模型可解释性差等挑战。
机器学习本质上是数据驱动的。 数据质量和样本大小直接决定模型性能。 高维和异构是光谱数据的两大特点。 一条分辨率为4 cm-1、 波长范围为4 000~400 cm-1的FTIR光谱包含约900个数据点, TDLAS在特定波段扫描也可能产生数百至上千个数据点, 远高于传统传感器, 给数据处理和模型训练带来维度灾难。 异构是指不同来源或条件下获取的气体光谱数据在格式、 质量、 尺度、 甚至包含的信息上存在显著差异。 仪器差异、 测量条件变化、 样本复杂性和数据来源多样性都可能产生数据异构。 光谱数据建模往往需要整合实验室标准气谱、 现场在线监测数据、 开放数据库(如HITRAN模拟谱)、 不同文献报道的数据等。 这些数据在采集协议、 噪声水平、 预处理方式上往往不一致。 文献中的光谱数据质量参差不齐。 原始光谱数据多存在噪声、 基线漂移等问题, 导致光谱分辨率和强度不一致。 并且不同研究中测量方法和环境条件存在较大的差异性, 同一气体成分的光谱信息并不完善且准确性难以保证。 在模型数据量方面, 气体光谱检测中使用最广的DL模型严重依赖海量标注数据, 模型性能会随样本量增加而提升; 而高质量、 带注释的气体光谱数据集稀缺且不平衡。 在燃烧场异常诊断、 泥浆录井气体监测等一些特殊应用场景中光谱分析模型的样本量明显不足(表1), 限制了模型的泛化能力并增加了过拟合风险。 目前, 仅有用于部分CH4泄漏高光谱数据集开源(如AVIRIS-NG[58]和GasVid[75]), 而商业光谱库(如Wiley、 NIST)主要收录矿物晶体、 金属材料等无机物质的光谱数据, 非反应性、 研究较少的有机气体(如大多数VOCs)光谱数据较少, 且存在访问限制, 在机器学习研究中使用不多。
| 表1 机器学习在气体光谱检测技术中的应用举例 Table 1 Application examples of machine learning technology in spectral analysis of gas |
针对这些方面的挑战, 未来可结合迁移学习与主动学习、 自编码器、 Transformer、 构建轻量模型等小样本学习方法[82], 突破DL模型对海量标注数据的依赖, 缓解小样本训练难题。 气体分子的吸收光谱特征(谱线位置、 强度、 形状)由量子力学决定, 具有内在一致性。 这为知识迁移提供了物理基础。 大量仿真光谱数据、 实验室标准气数据以及不同场景下积累的历史数据或公开数据集可以作为迁移学习的源域。 例如, Zhu等[62]通过变分模态分解提取光谱特征, 然后用14 801个仿真光谱(源域数据)预训练模型, 再用63组CS2-SO2混合气体的DOAS实测光谱(目标域数据)进行微调。 模型通过预训练-微调后能更准确高效学习光谱特征, 从而解决混合气体小样本检测难题, 实现了CS2和SO2的ppb级高精度检测, 模型平均绝对误差分别为0.51和1.12 ppb, 其性能达到国际最优水平。 在HIS分类应用中, 主要通过标准方法验证或专家判读获得标记的训练样本。 这些过程通常很困难、 昂贵且耗时。 主动学习技术可以通过选择性的标记较少数据而训练出表现较好的模型来降低样本标注成本。 其中, 主动深度学习(ADL)利用神经网络模型对图像数据进行自动分层特征提取, 以筛选出更加丰富的特征进行人工标注, 因而具有更强的图像分类能力[83]。 此外, 还可以结合AIGC(AI生成内容)等数据增强技术自动生成模拟光谱数据并解决化学“ 逆问题” , 显著提升分析效率与准确性[84]。 同时, 鼓励研究者积极开源建模数据和代码以持续推动交叉研究, 建立开源的气体光谱数据库, 作为机器学习模型评估的基准数据集。
此外, 未来应推动人机协同创新, 探索生成式AI大模型在光谱解析中的新范式, 为气体光谱检测与传感提供更智能的研究工具。 目前, 在气体光谱检测智能化方面已有一些有益探索。 Tian等[85]提出了一种基于端到端DNN的直接吸收光谱气体传感系统, 利用CNN及MLP模型精准检测CH4和乙炔浓度, 相较传统WMS在精度、 抗噪声及抗硬件老化方面表现更优。 但该方法仍然面临低浓度信号信噪比不足及模型可解释性挑战, 未来可结合生成模型增强数据并优化低信噪比场景下的鲁棒性。 Wei等[86]创新性地将AI诊断与红外测温技术结合开发油气生产运输中泄漏检测专用小模型, 并运用检索增强生成(RAG)技术构建知识库提升大语言模型的推理能力, 最终设计出基于开源大模型的智能检测代理系统。 新方法在检测准确率(提升15%)、 中文复杂推理正确率(提高约70%)和系统稳定性(检索中断率趋近零)等方面均有显著提升, 初步实现了泄漏检测与处置方案的智能化生成。 Akewar等[87]探讨了自然语言处理(NLP)与HSI的融合, 提出通过结合自然语言的抽象特征(如序列建模、 语义信息)与HSI的光谱空间特性, 提升图像分类、 特征提取及语义分割等任务的性能。 最近, Wang等[88]发布了首个专为HSI设计的基础大模型(> 10亿参数)— HyperSIGMA, 具备泛化能力强、 任务迁移性强等特点。
AI和机器学习在化学领域广泛应用, 但在气体光谱检测与传感中的应用相对不足。 光谱技术产生大量高维、 异构数据, 传统分析方法难以处理。 最新研究表明, 机器学习尤其是DL方法可以有效解决混合气体光谱数据中的噪声干扰、 待测组分本征光谱重叠以及波长漂移等问题, 提高检测效率和准确度。 当前, 机器学习与气体光谱检测技术在环境监测、 工业过程控制、 CH4泄漏监测、 癌症早期诊断、 HSI和地球观测系统等领域正在不断融合。 面向气体光谱检测的机器学习研究未来仍面临着数据质量、 稀缺性和多模态集成等诸多挑战, 以及AI大模型带来的机遇。 需要指出的是, 和传统研究手段一样, 机器学习仅仅是种新的研究工具, 并不是所有问题的最优解, 不宜为了追求热点而乱用/滥用机器学习。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|