


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高光谱技术的朱墨时序光谱差异特征分析及分类
[李昌盛 , 高树辉
, 高树辉* , 李开开]
, 高树辉, 李开开]
|
|


作者简介: 李昌盛, 1991年生, 中国人民公安大学侦查学院博士研究生 e-mail: chasonly@yeah.net
朱墨时序检验是法庭科学文件检验的核心内容, 通过鉴别印章与打印或书写字迹的先后顺序, 为文书真伪鉴定提供关键依据。 现有方法存在依赖检验人员经验及适用范围受限等问题, 难以满足无损、 自动化及高精度鉴别需求。 尽管光谱技术结合模式识别的化学计量学方法在无损检验中展现出潜力, 但在检验朱墨互溶情况的时序、 模型准确率等方面仍存在不足。 鉴于此, 本研究提出一种融合可见光-近红外高光谱成像(Vis-NIR HSI)与模式识别的无损自动鉴别方法, 实验基于多孔型激光打印机与3类印油的组合样本, 每组采集10 000个像素光谱数据构建光谱差异数据集。 首先通过系统性构建多角度光谱差异计算策略, 精准量化时序特征; 其次, 创新性结合标准正态变量(SNV)光谱预处理技术与智能降维的区间变量迭代空间收缩(iVISSA)特征波长选择算法, 通过噪声抑制及数据优化提升模型性能; 进一步对比逻辑回归(LR)、 支持向量机(SVM)、 随机森林(RF)等6种机器学习模型, 通过对比分析实现高精度分类。 实验表明: 对数比值方法能够有效增强光谱差异, SNV预处理和iVISSA特征波长筛选能够降低数据冗余并且显著增强了模型性能, 最优模型为SVM、 XGBoost和LightGBM, 能够有效实现互溶型印章印油与激光打印碳粉组合朱墨时序的判定, 经验证本文方法具有较好的泛化能力。 本研究突破传统局限, 展示了Vis-NIR HSI与模式识别方法深度融合检验互溶型朱墨时序的可能性, 能够作为传统检验方法的辅助, 对打击文书伪造犯罪具有重要的司法实践价值。
Determining line-crossing sequences between stamp inks and laser printing toner forms a core component of questioned document examination, offering critical evidence for authenticating questioned documents. Current methodologies are hindered by examiner dependency and limited applicability, failing to meet the demands for non-destructive, automated, and high-precision detection. While spectrochemical techniques combined with pattern recognition show promise in non-destructive analysis, they remain insufficient for investigating ink-toner interpenetration cases and model accuracy. This study proposes a novel approach that integrates visible-near-infrared hyperspectral imaging (Vis-NIR HSI) with machine learning, utilizing 10 000-pixel spectra per sample from three ink types and laser printers. Initially, a systematic multi-angle spectral difference calculation strategy was employed to quantify the temporal characteristics of material deposition sequences accurately. Following this, a new method that combines standard normal variate (SNV) spectral preprocessing with the interval variable iterative space shrinkage algorithm (iVISSA) was used to enhance model performance by minimizing noise and intelligently selecting wavelengths. In conclusion, a comprehensive comparative analysis of six machine learning models, including logistic regression (LR), support vector machines (SVM), and random forests (RF), was conducted to develop a high-accuracy classification system for questioned document examination. Experimental results demonstrate that the log ratio method effectively improves spectral differentiation. The combined application of SNV preprocessing and iVISSA-based characteristic wavelength selection successfully reduces data redundancy while significantly boosting model performance. Among the evaluated algorithms, SVM, XGBoost, and LightGBM emerged as the top models, showing robust capability in determining line-crossing sequences between compatible stamp inks and laser printing toners. Validation confirms the method's superior generalization ability for questioned document examination. This study addresses limitations by demonstrating the feasibility of integrating Vis-NIR HSI with pattern recognition to analyze line-crossing sequences of compatible stamp inks. This approach enhances conventional techniques, adding substantial judicial value in fighting document fraud.
朱墨时序是指印章与笔迹(打印文字或书写字迹)的先后顺序, 朱墨时序检验是文书真伪鉴定常见的内容之一, 也常是某些案件争议的焦点。 在我国, 通常加盖了印章的正式文件才具有法律效力, 制作过程应该是先有文字, 通过审核后才能盖章, 称之为“ 先墨后朱” ; 而一些造假文件却是事先盖好印章, 需要时再添加上文字, 即“ 先朱后墨” 。 在有些案件中, 朱墨时序的检验结果是文书真伪性鉴定的重要参考。 因此, 朱墨时序检验具有重要意义。
朱墨时序检验的准确性需同时把握朱墨材料的多样性、 交叉部位随时间发生的物理化学变化以及现有检验技术的局限性, 这些复杂因素导致了判定过程的高难度和不确定性。 针对以上问题, 国内外学者进行了广泛的研究。 传统的朱墨时序检验方法主要有无损检验方法和有损检验方法[1, 2]两种。 其中, 有损检验方法包括切割法[3]、 胶带粘取法[4]、 成分分析法[5]、 脱色法[6]、 转印法[7]、 吸附法[8]等。 这些方法可以直接观察到朱墨交叉部位的微观物理变化, 提供更直观的证据, 然而, 检验过程会对原始证据文件造成不可逆的损伤, 从而影响物证的完整性及后续检验需求, 因此有损检验方法适用性受限。
相较而言, 无损检验方法则更具优势, 利用光学显微检验、 表面化学成分分析以及光谱检验技术等, 在不破坏检材的情况下检验朱墨时序。 显微镜检查通过分析交叉线区域的物理和化学特征差异来确定交叉线序列, 包括色料分布、 笔画连续特征和荧光特性等。 Wu等[9]利用激光荧光显微镜为检验印章印油和打印机碳粉组成的朱墨时序样品提供了一种可靠的方法, 该方法对检验非紧凑型碳粉特别有效, 在盲测中实现了较高的准确性和检出率。 2021年, Wu等[10]继续借助显微检验技术, 提出了一种基于碳粉熔融状态的新方法来检验朱墨时序, 通过观察交叉线部位碳粉的熔融状态实现朱墨时序的有效判断。 Kaur等[11]使用立体显微镜和LED显微镜成功地确定了激光打印碳粉和圆珠笔墨迹之间的交叉线时序。 Meneghetti等[12]使用高倍数码显微镜分析了激光打印碳粉与各种书写墨迹之间的交叉线时序。 虽然这些方法能够无损地判断交叉线时序, 但存在明显的局限性: 检验的结果在很大程度上取决于检验人员的经验和技能水平, 甚至可能导致不同的检验人员在同一检材中得出完全相反的结论[13]。
表面化学分析技术能够检测交叉线区域的化学成分或元素分布, 因此也被用来判定交叉线时序。 Morais等[14]提出使用简易环境声波喷雾电离(EASI)的质谱成像(MSI)可用于准确识别蓝色印章印油和钢笔墨迹的交叉线时序。 Barac等[15]通过对比光学技术和兆电子伏特二次离子质谱(MeV SIMS)在判定不同书写墨迹之间的交叉线时序方面的表现, 展示了MeV SIMS在处理光学不可区分的墨迹时的优势, 尤其是在结合多变量分析工具时能够成功区分并确定交叉线时序。 Mathayan等[16]通过卢瑟福背散射光谱法(RBS)和粒子诱导X射线(PIXE)离子束分析技术, 成功确定了不同书写墨迹和打印机碳粉的交叉线时序, 为文件检验提供了一种新的定量分析方法。 然而, 尽管这些表面化学分析方法能够在特定情况下确定交叉线时序, 但它们存在明显的局限性, 包括仪器操作复杂、 样品类型局限以及对专家经验的依赖等。
光谱技术也被用于检验朱墨时序, 通过分析朱墨时序样本交叉线区域的反射率、 透射率等光谱特征, 根据材料对光的吸收和反射特性确定交叉线时序。 Liu等[17]使用共焦拉曼光谱有效地确定了激光打印机碳粉和印章印油之间的交叉线顺序, 利用材料的拉曼光谱特征和微观形态确定朱墨顺序, 该技术对碳粉密集型激光打印机特别有效, 但对多孔和分散碳粉形式的激光打印机则难度较大。 Dirwono[18]成功地利用微衰减全反射傅里叶变换红外光谱(Micro-ATR-FTIR)对东亚地区红色印章印油进行了来源分析, 并实现了印章印油和圆珠笔墨迹的朱墨时序检验。 Wang[19]将傅里叶变换红外显微光谱(FTIR microspectroscopy)与扫描电子显微镜/能量色散(SEM/EDS)X射线元素映射相结合, 研究了激光打印碳粉和印章印油之间的朱墨时序。 尽管这些方法能够实现朱墨时序的检验, 但光谱检验方法在微观选择测量点时要求较高, 同样较依赖人工经验以及操作复杂等不足。
为了克服上述缺点, 近年来出现了一些借助光谱成像技术与模式识别相结合的化学计量学方法研究, 为朱墨等交叉线时序的检验提供了新的思路。 Silva等[20]率先将近红外近红外高光谱成像(HSI-NIR)与多元曲线分辨率-交替最小二乘(MCR-ALS)和偏最小二乘判别分析(PLS-DA)相结合, 能够通过分析激光打印碳粉和黑色墨水笔迹的分布图识别交叉线条的时序, 识别率达到85%。 Borba[21]等开发了一种无损检验方法, 将共聚焦拉曼成像(confocal Raman imaging)与MCR-ALS相结合, 有效地解决了蓝色墨水笔迹的交叉线时序问题。 Brito等[22]利用HSI-NIR与主成分分析(PCA)、 MCR-ALS相结合, 探讨了分析黑色墨水笔迹交叉线顺序的潜力, 结果发现, 由于纸张对NIR辐射的强吸收以及墨水层的薄厚度, 导致难以区分墨水与纸张的光谱, 限制了该技术在实际案件中的应用。 随后他们[23]提出了一种基于拉曼高光谱成像(Raman HSI)的化学计量学方法, 分别使用K-均值聚类、 MCR-ALS和PLS-DA对蓝色与黑色墨水笔迹交叉线处的高光谱影像进行分析, 能够有效确定笔画的书写顺序, 准确率达到70%以上。 然而, 在朱墨时序检验的问题上, 这些研究仍存在一些不足: (1)缺乏对印章印油与打印机碳粉的朱墨时序组合的相关研究: 所选取的交叉线样本为书写墨水与打印机碳粉墨迹的交叉线组合, 如蓝色墨水笔迹、 黑色墨水笔迹与激光打印碳粉等; (2)并未考虑组成交叉线样本的碳粉和墨水互溶情况: 为了避免墨水之间发生互溶的情况, 这些研究在制作交叉线样本时, 间隔时间达到了两天[21]或一周[20]时间不等, 然而, 判定油墨发生互溶现象后的交叉线顺序则更具挑战性; (3)目前尚未有关可见光-近红外高光谱成像技术(visible-near infrared hyperspectral imaging, Vis-NIR HSI)用于朱墨时序检验的研究报道, 该方法的可行性有待探究。
鉴于此, 提出了Vis-NIR HSI技术与模式识别相结合的化学计量学方法, 采集朱墨时序样品的高光谱数据, 构建朱墨时序样本光谱差异数据集, 通过预处理、 特征选择、 构建机器学习分类模型等流程, 实现对互溶型朱墨时序样本进行高效、 准确的判定。 与传统的方法不同, 所提出的模型能够在朱墨材料发生互溶的复杂情况下, 完成印章印油与激光打印碳粉组合朱墨时序的判定, 减轻了人工经验的依赖, 实现朱墨时序的智能化检验。 上述研究成果能够为文件检验领域提供一种新的朱墨时序检验方法, 辅助其他常规检验方法, 进一步提高朱墨时序的检验准确率。
仪器设备与材料: 激光打印机、 推扫式可见光-近红外高光谱成像系统、 A4纸张(Deli No.7400, 70 g· m-2)、 光敏印章、 原子印章和印台印章等。 高光谱成像系统由卤素灯光源、 成像光谱仪、 铝型材支架、 样品台、 计算机及控制装置等组成, 型号为Pika XC2, 光谱范围为400~1 015 nm, 光谱分辨率为1.3 nm, 光谱通道数为462个。 光源为8个卤钨灯, 总功率为280 W。
实验样品: 激光打印碳粉选择多孔型打印碳粉(Porous-type toner), 印章印油按照印章类型的不同分别选取原子印油(Atomic ink)、 光敏印油(Photosensitive ink)和印台印油(Stamp-pad ink), 选取的激光打印机与印章印油类型信息如表1和表2所示。 在每种打印机碳粉与印油组合下, 制作“ 先墨后朱” 和“ 先朱后墨” 2种顺序的交叉线样品。 为确保实验结果的可靠性, 每种变量组合下重复制作3份样品, 共计制备120组交叉线样品。 样品制作时, 在A4纸张上打印相同的文字内容, 确保激光打印机碳粉分布一致; 在盖印印章时, 统一控制盖印力度、 角度和位置。 样品制备后置于温度25 ℃、 相对湿度50%的受控实验室环境中自然存放, 以保证样品的稳定性。
| 表1 用于制作朱墨交叉线样品的激光打印机类型 Table 1 Type of Laser printers used to print crossing line samples |
| 表2 用于制作朱墨交叉线样品的印章油墨类型 Table 2 Type of stamp inks used to print crossing line samples |
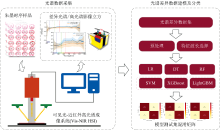
实验设计如图1所示。 首先采集朱墨时序样品的光谱数据, 然后创建光谱差异数据集, 最后在构建的朱墨交叉线顺序鉴别分类模型上实现朱墨交叉线顺序的识别。
 | 图1 本文的图形摘要Fig.1 Graphical abstract of this study |
1.3.1 样品准备
为模拟真实案件中朱墨发生的互溶现象, 在实验样品制作7 d后, 我们才采集其高光谱图像数据。 选取了不同朱墨时序样品的交叉部位及非交叉部位打印碳粉墨迹区域作为感兴趣区域(ROI)。 对于不同组别朱墨时序样品的两类ROI, 分别提取了5 000个像素点的高光谱数据, 共采集了30组样本数据集, 每组创建了一个包含10 000个样本的高光谱差异数据集, 以供分类任务训练使用。 为了提高模型的泛化能力, 训练和测试所用的光谱数据样品是随机抽取的。
每组高光谱差异数据集的组合按照50%、 20%、 30%划分为训练集、 验证集和测试集。 验证集和测试集完全独立于训练集, 用于模型调参和性能评估, 测试集用于最终评估模型泛化能力, 且统一设置随机种子42以确保数据划分和结果的可复现性。 为了验证模型在不同类型的朱墨组合样本之间的泛化能力, 数据集按照朱墨类型进行分组, 数据集的划分如表3所示。
| 表3 朱墨交叉线样品高光谱差异数据集的样本数 Table 3 The number of crossing line samples in the hyperspectral dataset |
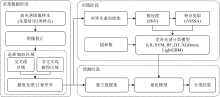
实验关键步骤流程详见图2。
 | 图2 实验过程关键步骤流程图Fig.2 Flowchart of the key steps in the experimental procedure |
1.3.2 光谱差异计算方法
在构建朱墨不同交叉线顺序样本的光谱数据集之前, 对样本的交叉部位与非交叉部位打印碳粉墨迹区域的光谱数据差异进行了计算, 并评估交叉部位和非交叉部位打印碳粉墨迹区域的光谱差异。 为了从不同角度量化两个区域的光谱差异, 以最大限度地揭示不同朱墨时序样本中的微小变化, 本文选取了三种经典的光谱差异计算方法: 直接差值(Direct Difference)[24]、 对数比值(Log Ratio)[25]和归一化差值(Normalized Difference)[24], 见式(1)、 式(2)和式(3)所示, 其中X1代表不同时序样品中交叉线部位光谱反射率值, X2表示非交叉部位打印碳粉墨迹区域反射率值。
1.3.3 光谱预处理与降维
在高光谱数据处理中, 光谱信号通常受到散射效应、 光照不均和背景噪声的影响, 使模型精度降低。 为解决这一问题, 采用标准正态变量(standard normal variate, SNV)算法[26]对光谱差异数据进行预处理。 SNV通过对每个光谱点的吸收值进行标准化处理, 使光谱数据的均值为零、 标准差为一, 可有效消除由散射和背景噪声引起的偏差。
由于高光谱数据的高维特性和波长之间可能存在的共线性及冗余信息, 直接使用全波进行建模不仅增加了计算复杂度, 还可能导致模型过拟合或预测性能下降。 因此, 对高光谱数据进行波长选择具有重要意义。 区间变量迭代空间收缩法(interval variable iterative space shrinkage approach, iVISSA)[27]是一种光谱间隔选择算法, 可结合全局和局部搜索智能优化光谱间隔的位置、 宽度和组合, 并通过局部搜索结合光谱数据的连续性来确定波长间隔的宽度。
1.3.4 分类算法
在高光谱数据的二分类任务中, 由于数据维度高、 特征复杂且类别边界可能模糊, 选择适当的机器学习模型对分类效果至关重要[28]。 基于线性的逻辑回归(logistic regression, LR)模型[29]因其实现简单、 计算效率高, 常被用于高光谱二分类的基线建模, 在特征分布接近线性可分的情况下, LR能够快速生成准确的分类结果。 基于边界的支持向量机模型(support vector machines, SVM)[30]在二分类任务中表现也很出色, 特别处另高维和非线性可分的高光谱数据时, SVM通过构建最大化分类边界的超平面, 能够在高维空间中精准区分类别, 其核函数的灵活性可以捕捉复杂模式, 并在高光谱二分类任务中有较高的准确率; 树模型以其鲁棒性和灵活性在高光谱二分类任务中表现同样优异, 如决策树(decision tree, DT)模型[31]通过基于规则的分裂方式, 快速生成简单且易于解释的分类结果, 但其单树结构可能导致过拟合。 在改进这一问题方面, 随机森林(random forest, RF)模型[32]集成了多棵决策树, 并采用投票机制提高了分类的准确性和稳定性。 此外, 作为增强树模型的XGBoost模型[33]和LightGBM模型[34]进一步优化了梯度提升方法, 在高光谱二分类任务中不仅能够提升分类精度, 还具备较高的计算效率, 适合在复杂特征空间中识别不同类别的光谱模式。
在模型参数设置上, 基础模型如决策树和逻辑回归采用默认配置, 而RF、 XGBoost和LightGBM集成学习模型通过优化基学习器数量、 树的最大深度和学习率等关键参数以提升性能, 特别是LightGBM模型, 调整了叶节点数与样本最小数量等参数, 模型参数如表4所示。 此外, 所有模型训练均使用5折交叉验证来提高模型验证的稳定性, 数据预处理则采用StandardScaler标准化方法, 确保输入特征在不同模型间的一致性。
| 表4 机器学习算法模型的参数配置 Table 4 Model parameter configurations for machine learning algorithms |
本节展示Vis-NIR HSI技术结合模式识别方法实现朱墨时序样本的分类效果, 受限于篇幅, 在光谱特征分析、 光谱差异特征分析及波长相关性分析部分选用具有代表性的两组高光谱差异数据集组合A1和B10进行对比展示, 模式识别方法部分输出的数据展示均为A1数据集。
为了深入探究不同朱墨时序样品的光谱反射差异, 本节利用高光谱成像技术对交叉部位和非交叉部位打印碳粉墨迹区域进行光谱反射率提取和差异分析, 旨在揭示朱墨时序样品的独特光谱特征, 为后续的分类识别提供依据。 高光谱成像技术有效分析可疑文书中印章印油与激光打印碳粉墨迹的时序差异, 关键在于比较两类特定区域的光谱反射差异: 一是交叉部位区域, 二是非交叉部位打印碳粉墨迹区域。 通过人工检视, 确定交叉部位和非交叉部位打印字墨迹区域为ROI区域, 并提取其光谱反射率曲线。 图3(a— c)和图3(d— f)分别展示了数据集A1和B10中不同朱墨时序样品两类ROI区域的光谱反射率曲线, 曲线中深色线条展示了样品的平均光谱反射率曲线。
 | 图3 不同朱墨时序样品交叉部位和非交叉部位打印碳粉墨迹ROI区域的光谱差异示意图 |
图3(a)和(d)比较了先墨后朱样品交叉部位和非交叉部位打印碳粉墨迹ROI的光谱反射率差异。 图3(a)中在可见光(Vis)范围内两个部位的反射率均较低, 而在近红外(NIR)区域内的反射率逐渐上升; 对于交叉部位而言, 在400~550 nm 波长的紫蓝绿光区域反射率较低, 表明对该波段光有较强吸收, 而在600 nm左右的红色区域至700~1 000 nm的NIR波长区域反射率逐渐上升, 并高于单纯打印碳粉墨迹区域, 表明对该区域的波段更敏感。 在朱墨重叠区域, 成分覆盖顺序会显著影响光谱特征[22], 红色印章印油的高反射率特性会部分弥补打印碳粉墨迹的低反射率, 尤其在红色和NIR波段, 印章印油覆盖打印机碳粉, 使交叉部位呈现的反光变强[35], 进一步凸显差异特征, 这与印油中的油机成分对近红外波段的敏感性有关。 而图3(d)和(e)中交叉部位反射率则在整个可见光至近红外波段范围内均高于打印碳粉墨迹部位, 光谱差异的不同体现出不同印油类型的物理和化学特性的不同。
图3(b)和(e)比较了先朱后墨样品交叉部位和非交叉部位打印碳粉墨迹区域ROI的反射率。 两者的总体趋势与图3(a)和(d)一致, 但图3(b)交叉部位的光谱反射率在所有的波段内均低于非交叉部位打印碳粉墨迹区域, 而图3(e)交叉部位的光谱反射率在所有的波段内均高于非交叉部位打印碳粉墨迹区域, 交叉部位打印机碳粉附着在渗有印油的纸张表面, 导致交叉部位表面粗糙度和光学干涉发生变化, 造成反射率的差异。
图3(c)和(f)直接对比了两种朱墨时序样品的交叉部位光谱反射率, 两图中先墨后朱样品在整个光谱范围内的反射率普遍高于先朱后墨样本, 特别是在图3(c)中红色至近红外波长区域。
综上所述, 不同组合的朱墨时序样品在交叉部位和非交叉部位打印碳粉墨迹ROI区域的光谱反射率曲线存在显著差异, 这些差异特征为朱墨时序的鉴别提供了重要的光谱依据。
为了从不同角度量化两个区域的光谱差异, 最大限度地揭示不同朱墨时序样本中的微小变化, 选取了三种经典的光谱差异计算方法(直接差值、 对数比值和归一化差值), 旨在比较和分析不同方法下光谱差异曲线的特征。 光谱差异数据集A1和B10的朱墨时序样本的反射率光谱差异曲线如图4所示。 图4(a— c)和图4(d— f)分别为数据集A1和B10基于三种差异计算方法所计算的反射率光谱差异曲线, 两类曲线显示出了不同时序样品光谱数据的差异特征。
 | 图4 数据集A1 (a— c)和B10 (d— f)在不同差值计算方法下交叉部位和非交叉部位打印碳粉墨迹ROI区域的光谱差异曲线 |
由图4可见, 图4(a)和(d)直接差值方法清晰地表现了两种朱墨时序样品的反射率差异, 特别是图4(a)中红色至近红外区域的显著差异, 而图4(b)两种朱墨时序样品的反射率在可见光至近红外波段均存在显著差异, 这与图3中展示的反射率曲线差异能够进行对应; 图4(b)和(e)采用对数比值计算差异, 以反映样本反射率之间的非线性差异, 图4(b)对数比值方法有效地增强了红色至近红外区域的对比特性, 图4(e)在可见光至近红外波段上都增强了差异对比; 图4(c)和(f)显示了两种朱墨时序样本的归一化差值, 归一化差值方法突出显示了光谱差异的动态特性, 特别是在图4(c)的红色至近红外波段和图4(f)的可见光至近红外波段中。
这是由于不同的差值计算方法对光谱数据的处理方式不同, 能够从多个角度揭示光谱差异。 直接差值方法直接反映了两个区域的反射率差异; 对数比值方法能够反映样本反射率之间的非线性差异, 对相对变化更敏感; 归一化差值方法则通过归一化处理, 突出了差异的相对大小。
综上所述, 三种差值计算方法均能有效揭示不同朱墨时序样品的光谱差异, 但对数比值方法在增强光谱差异方面表现更优, 为后续的分类识别提供了更丰富的特征信息。
为了挖掘光谱差异数据集的内在结构和特性, 为后续的数据处理、 特征选择及模型建立提供依据, 计算了光谱差异数据集的相关矩阵热力图, 如图5所示。 图5展示了光谱差异数据的相关矩阵热力分布情况, 有效地揭示了A1和B10光谱差异数据集中不同波长间的线性关系强度和模式。 颜色越红, 表示正相关性越强。 图中大面积的红色区域表明光谱差异数据中存在显著的冗余, 许多波长提供了相似的信息, 不同波段内的信号表现出高度的内部相关性, 特别是近红外波段区域。 因此, 需要借助降维技术来减少特征数量, 在保留大部分重要信息的同时, 能够降低模型的计算成本, 提高模型效率。
 | 图5 相关性矩阵热力图 |
为了降低高光谱数据的维度, 提高模型的计算效率和分类性能, 本节采用iVISSA算法进行特征波长选择, 旨在识别出具有最大类间差异性的波长区域, 同时最小化冗余光谱信息。 iVISSA算法参数设置如下: 最大主成分数设为15, 交叉验证次数设为15。 同时, 选择“ 集中式” (center)数据处理方法, 二元矩阵样本数设置为500。 iVISSA算法在机器学习分类任务的波长选择中表现出优异的性能, 将光谱维度从462个波段有效降低至112个, 同时保持了99.75%的分类准确率。 在保持完美分类性能的同时大幅降低了维度, 在识别信息丰富的光谱特征方面非常有效。 图6为A1数据集在iVISSA算法迭代过程中分类准确率的演变和特征波长的选择结果。
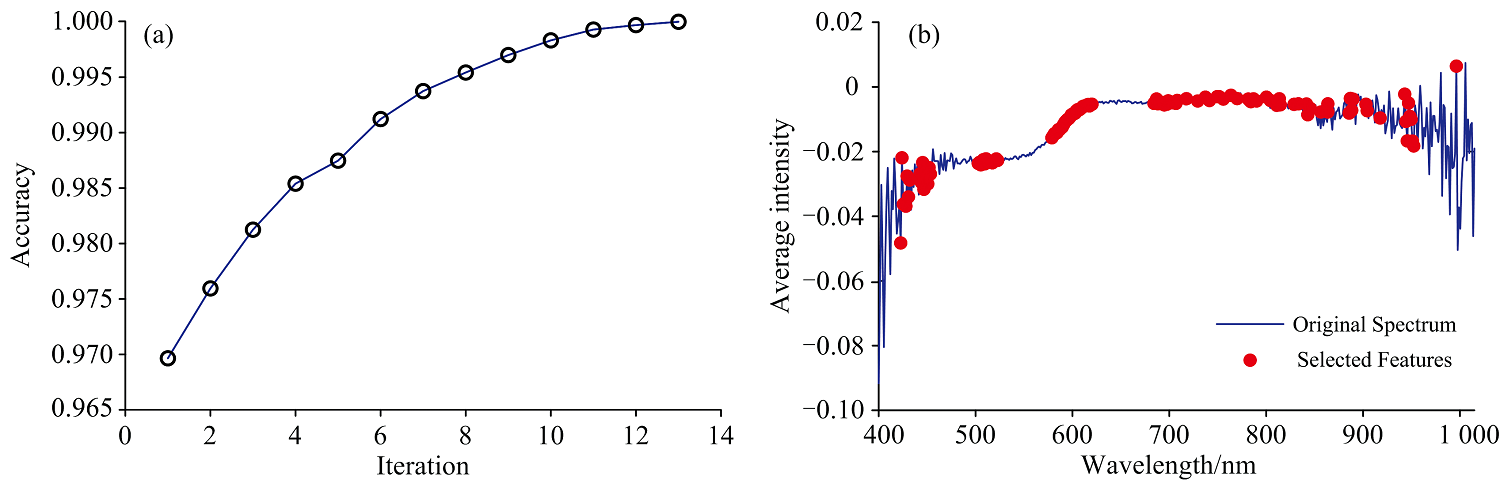 | 图6 iVISSA 特征波长选择算法的迭代过程图 |
由图6(a)可见, 分类准确率随迭代次数变化, 起始准确率约为0.97, 随迭代次数增加, 准确率持续提升, 在第13次迭代时达到最高; 图6(b)为波长选择结果分布, 可以看到特征波长倾向于在光谱曲线变化明显的区域集中分布, 特别是红光到近红外区域, 选择的特征波长覆盖了整个光谱波段, 这种选择模式表明算法有效识别出具有最大类间差异性的波长区域, 同时最小化了冗余光谱信息。
2.5.1 波段选择
为了实现对不同朱墨时序样本的准确分类, 本节利用多种机器学习模型对A1光谱差异数据集进行分类识别, 旨在比较不同模型在全波段、 可见光、 近红外和特征波长等范围的性能差异, 探究不同波段对模型性能的影响。 在全波段(All bands)、 可见光(Vis)和近红外(NIR)光谱波段对分类结果进行评估, 直接差值计算方法构建的光谱差异数据集分类结果见表5。
| 表5 基于直接差值方法, 不同波段和预处理对分类模型准确率的影响(单位: %) Table 5 Effect of different wavebands and preprocessing methods on classification accuracy (in %) for different models, based on the Direct Difference method |
全波段分类模型中, XGBoost模型的准确率最高。 然而, 使用SNV预处理方法时, SVM和LR模型的表现优于其他模型。 与Vis波段相比, 人眼无法观测的NIR波段的分类准确率更高。 这表明, NIR波段能提供更多关于差异特征的信息。 各个模型在选择特征波长后的表现介于全波段和NIR波段之间, 使用SNV预处理后, 模型的分类性能有所提升。
由表5可见, 除DT模型外, 其余模型在所有评估指标上表现均衡, SVM和LR表现较好, 测试集准确率均超过98%, 表明全波段光谱信息能够全面表征样本特征, 支持分类模型的高效学习。 在Vis波段, 模型性能出现一定下降, 尤其是DT, 测试集准确率仅为72.90%。 然而, SVM和LR的表现相对稳定, 测试集准确率分别为86.67%和87.63%。 这说明在较少波段特征下模型依然具有一定的适应能力。 NIR波段对分类任务的贡献显著提高, 特别是SVM的测试集准确率由98.03%提高到了98.73%, 表明NIR波段包含了关键的分类特征。 XGBoost和LightGBM的测试集准确率相较于全波段分别提高至97.20%和96.77%; SVM的测试集准确率为98.73%, 与NIR波段表现一致, 是最优模型; LR紧随其后, 测试集准确率为98.63%。
综上所述, 特征波长选择方法的分类效果接近全波段, 甚至在部分模型中能够获得更高的测试集准确率, 说明波长选择能够提高模型性能, 同时减少计算复杂度。
2.5.2 差异计算方法
为了进一步探究不同差异计算方法对模型性能的影响, 对比了三种差异计算方法得到A1数据集的光谱差异数据对模型性能的影响, 以确定最佳差异计算方法。 重点关注模型针对正类样本即伪造文书样本的预测准确性, 即模型的精准度(Precision), 以尽量减少假阳性误报, 从而提高系统在实际应用中的可靠性和效率。 此外, 特异性(Specificity)同样重要, 因为高特异性意味着模型能够有效区分负类样本即真实文书样本, 进一步提升整体分类的准确性[36]。 因此, 本文基于三种光谱差值计算方法, 对多种模型的精准度和特异性进行了全面比较, 模型在波长选择后的性能结果如表6所示。
| 表6 不同光谱差异计算方法对模型分类准确率的影响(单位: %) Table 6 Effect of different methods of spectral difference calculation on classification accuracy (in %) for different models |
由表6可见, SVM在三种光谱差值方法下均表现最佳, 精准度分别达到99.26%、 99.33%和99.47%, 特异性分别为99.27%、 99.33%和99.39%。 相比之下, 集成模型XGBoost和LightGBM尽管略逊于SVM, 但在所有指标上仍然表现出高度稳定性。 在对数比值差值方法下, XGBoost的精准度为97.57%, 特异性为97.87%; 而LightGBM的精准度和特异性分别达到97.35%和97.67%。 DT和RF模型的表现相对较差, DT模型在直接差值方法下的精准度和特异性仅为83.69%和83.00%, 在其他差值方法下的性能提升也较为有限。
综上所述, 在基于对数比值的差异数据集上, SVM模型在特征波长下表现出最佳的分类性能, 此外集成模型XGBoost和LightGBM也表现出高度的稳定性。
2.5.3 泛化能力评估
为了进一步验证所提方法的泛化能力, 在涵盖激光打印碳粉与3种印章类型的印油组合的光谱差异数据集进行了验证。 通过对上述最优模型进行了跨数据集的性能评估, 测试本方法的泛化能力。 在其他各组的数据集中, 采用相同的对数比值方法计算光谱差异, 随后依次对光谱差异数据采用SNV预处理和iVISSA特征波长选择策略, 最后通过SVM、 XGBoost和LightGBM等最优模型对本方法进行评估。 不同最优模型在不同数据集上的识别准确率及性能如表7和图7所示。
| 表7 最优模型在不同数据集上的识别准确率(单位: %) Table 7 Classification accuracy (in %) of the optimal models across different datasets |
 | 图7 最优模型在不同数据集中的性能表现 |
实验发现, 30组不同类型的印油与同种激光打印碳粉形成的朱墨时序组合在模型分类性能方面具有相似性, 因此在每类组合中各选取了两组具有代表性的数据集进行展示。 表7中列出的数据集A1与B3、 A8与B10、 A11与B15为激光打印机碳粉分别与原子印油、 光敏印油和印台印油组合的代表。 由表7可见, SVM在所有数据集上的验证集和测试集准确率都相对较高, 尤其是在原子印油组合的数据集上表现最佳, XGBoost和LightGBM在不同数据集上的表现相对接近, 但总体上略低于SVM。 对于不同的数据集而言, 原子印油组合的数据集上, 所有模型的准确率都较高, 尤其是SVM模型; 光敏印油组合的数据集上, SVM模型的表现也优于其他模型, 但XGBoost和LightGBM的表现也较为接近; 而印台印油组合的数据集上, XGBoost体现出较SVM更佳的性能。
图7选取了具有代表性的B3、 B10和A11数据集展示了最优模型的性能表现。 SVM模型体现出较好的分类性能, 在B3和B10数据集中表现最佳, 但在A11数据集中性能有所下降; XGBoost的鲁棒性和泛化能力较强, 在所有三个数据集中均表现出色; LightGBM表现也较为稳定, 性能仅次于XGBoost。 造成模型性能差异的原因可能是不同类型朱墨组合的物理和化学特性的差异, 导致不同数据集中特征分布的复杂度存在差异导致。 此外, 不同模型对于不同数据结构的适应性不同, 因此, 模型在这些不同类型数据集上的表现也会不同。
综上所述, SVM、 XGBoost和LightGBM这三个机器学习模型作为最优的模式识别方法, 能够实现光谱差异数据的有效分类, 该方法在不同数据集中均能够表现出较好的分类效果,
实验结果可见, 不同朱墨时序样品在交叉部位与非交叉部位打印碳粉墨迹的ROI区域中, 其光谱反射率曲线表现出显著差异, 这些差异特征为朱墨时序的鉴别提供了坚实的光谱依据。 进一步分析表明, 3种差值计算方法均能有效揭示样品间的光谱差异, 其中对数比值方法对于光谱差异增强效果尤为突出, 为后续分类模型提供了更丰富且具有判别力的特征信息。 SNV预处理显著增强模型性能, 特别是在关键特征波段。 iVISSA特征波长选择策略能够有效识别出类间差异最大的关键波长区域, 同时最大限度地减少了冗余信息的干扰, 该方法不仅降低了计算复杂度, 还提升了模型的整体性能。 差异计算方法对模型性能有显著影响, 对数比值差值法通过放大光谱相对变化, 增强了模型的分类能力。 模型对比显示, SVM在对数比值法下对小差异特征尤为敏感, 而XGBoost和LightGBM在复杂数据中展现了出色的鲁棒性。 上述结果进一步支持了Vis-NIR HSI结合模式识别的化学计量学方法在检验互溶型朱墨时序样品中的应用潜力及泛化能力。
证明了Vis-NIR HSI技术与模式识别相结合的化学计量学方法检验互溶型印章印油与激光打印碳粉组合朱墨时序的可行性。 通过采集30组不同类型印章印油与激光打印碳粉组合的朱墨时序样品高光谱数据, 采用3种差异计算方法构建朱墨时序样本光谱差异数据集, 分别对差异数据进行预处理、 特征提取及模式识别建模分类。 实验结果表明, 对数比值方法能够最大化增强光谱差异, 经过SNV预处理和iVISSA特征波长筛选能够降低数据冗余并且显著增强模型性能, 通过对比6种机器学习方法, 发现SVM、 XGBoost和LightGBM三个机器学习模型最优, 并通过不同数据集验证了该方法的有效性和泛化能力, 实现了朱墨时序样本的高效、 准确判定。 这些结果表明, 结合Vis-NIR HSI技术和模式识别方法, 能够实现对朱墨时序样本的高精度、 高效分类识别, 该方法能够在在朱墨材料发生互溶的复杂情况下, 完成印章印油与激光打印碳粉组合朱墨时序的判定, 为法庭科学中的文书检验提供了新的思路和方法。 当前研究在激光打印机碳粉类型、 印油种类选择上仍存在不足, 导致数据集存在限制, 下一步将继续扩展数据集, 同时将通过引入领域自适应或迁移学习技术, 进一步提升模型在异构样本间的稳定性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|