

{kind=link}
{kind=link}
{kind=link}
一种近红外光谱数据预处理组合优化策略
[周宇坤 , 陈孝敬, 谢忠好, 石文
, 陈孝敬, 谢忠好, 石文* , 袁雷明, 陈熙, 黄光造]
, 陈孝敬, 谢忠好, 石文, 袁雷明, 陈熙, 黄光造]
|
|


作者简介: 周宇坤, 1999年生, 温州大学电气与电子工程学院硕士研究生 e-mail: yukun_zhou@163.com
预处理是构建近红外光谱检测模型的重要环节, 影响着近红外光谱检测的精度。目前已有的预处理方法种类众多, 不同方法用于解决不同类型的噪声和无关信息, 从而提高信噪比, 如何优化样品的光谱数据和预处理组合的选择对模型结果至关重要。为此, 提出一种用于近红外光谱模型校准的预处理组合优化策略, 包括挑选常用的八种预处理方法建立预处理方法库, 利用偏最小二乘方法(PLS)建立定量模型, 以建模交叉验证均方根误差(RMSECV)为迭代标准, 从库中简单高效地选出提高模型优良校准能力的预处理组合。基于该策略的结构设计, 选用优化领域中的贪婪算法作为寻优手段, 通过对每一步的预处理方法进行寻优完成全局优化, 简洁高效地完成光谱数据预处理组合的选择。提出的策略在小麦、 猪肉等公开数据集上进行了测试, 与同类的堆叠策略(Stacked)和多块数据顺序正交融合策略(SPORT)进行比较。结果显示, 在小麦数据集上, 提出的策略较Stacked和SPORT策略的校正均方根误差(RMSEC)分别降低了12%, 6%, 预测均方根误差(RMSEP)分别降低了32%, 17%; 在猪肉数据集上, 提出的策略较Stacked和SPORT策略的RMSEC分别降低了49%, 48%, RMSEP分别降低了46%、 41%, 显示出了较好的校准性能。最后, 分析了该策略所选出的预处理方法在模型校准中各自的贡献度, 讨论了该策略在模型可解释性、 防止过拟合方面的潜力。该策略为近红外光谱的预处理方法选择提供了一种新的思路。
Preprocessing is an important step in constructing a near-infrared (NIR) spectroscopy detection model, which significantly affects the accuracy of the detection process. Various preprocessing methods are available, each designed to address specific types of noise and irrelevant information, thereby improving the signal-to-noise ratio. Optimizing the preprocessing combination is essential for achieving the desired model results. This study proposes a strategy for the combinatorial optimization of pre-processing methods for the calibration of near-infrared spectroscopy models, which includes selecting eight commonly used preprocessing methods to establish a library of preprocessing methods, building a quantitative model using the partial least squares (PLS) method.Then selecting preprocessing combinations from the library that have an excellent calibration capability for the model simply and efficiently, using the root-mean-square-error-of-cross-verification of the model (RMSECV) as an iterative criterion.The strategy’s structural design employs the greedy algorithm for optimization and achieves global optimization by searching for the optimal preprocessing method at each step. This enables the selection of preprocessing combinations for spectral data to be completed simply and efficiently. Tests were conducted on publicly available datasets such as wheat and meat, and the proposed strategy was compared with a similar stacked strategy (Stacked) and sequential orthogonal fusion of multi-block data strategy (SPORT). The results show that on the wheat dataset, the proposed strategy reduced the root mean square error of calibration (RMSEC) by 12%, 6%, and the root mean square error of prediction (RMSEP) by 32%, 17% compared to the Stacked and SPORT strategies, respectively. On the meat dataset, the proposed strategy reduced the RMSEC compared to the Stacked and SPORT strategies by 49% and 48%, and RMSEP was reduced by 46% and 41%, respectively.These results demonstrate good calibration performance.Finally, this analysis examines the contribution of the preprocessing methods selected by the strategy in model calibration. It also discusses the strategy’s potential in terms of model interpretability and prevention of overfitting. The strategy presents a new approach to selecting preprocessing methods for NIR spectroscopy.
近年来, 近红外光谱技术在农业、 食品、 制药、 化工等领域应用广泛[1, 2, 3]。这些近红外光谱技术发展的一个重要因素是采用化学计量学方法对光谱数据进行处理建模, 从而对不同形态的复杂混合物进行定性和定量分析[4, 5]。然而, 在实际实验过程中, 由于测量方式、 样品状态、 仪器背景等因素干扰, 复杂样品的光谱数据往往会含有大量无关信息和噪声, 从而影响最终的定量分析结果。因此, 为了建立预测能力强、 稳健性好的分析模型, 对光谱进行预处理至关重要[6, 7, 8]。
目前已有的光谱预处理方法有导数处理、 多元散射校正[9]、 标准正态变化[10]、 平滑处理、 标准化、 中心化等, 其中: 导数处理主要是消除仪器背景对数据采集的影响; 多元散射校正(multiplicative scatter correction, MSC)和标准正态变化(standard normalized variate, SNV)等方法用来消除由于样品形状分布和大小所产生的散射对光谱的影响; SG平滑(Savitsky-Golay smoothing)能够有效的提高谱图信噪比, 减少外界噪声的干扰; 中心化(Center)、 标准化(Standardization)等方法可以消除量纲不同带来的不良影响[11]。然而, 若分析体系相对复杂, 仅用一种光谱预处理方法往往不能得到较好的结果, 这时可将不同预处理取方法组合使用以获得预期的结果[12]。
对于优化光谱预处理组合, 研究人员也做出了一些尝试: Martyna等[13]提出一种基于网格搜索的方法, 该方法探索预处理方法的所有可能组合以确定最佳方法。但预处理方法排列组合结果众多, 尤其是对于数据规模较大的样品来说是一个较大的挑战; Xu等[14]提出了一种集成堆叠预处理方法(Stacked), 该方法通过蒙特卡罗交叉验证(Monte Carlo cross validation, MCCV)叠加回归将不同预处理数据建立的PLS模型组合在一起, 能够在模型校准上提供帮助。然而过程中有大量的模型需要训练和优化, 这可能会使计算费用变得昂贵[15]。Roger等[16]提出了一种基于序贯偏最小二乘(SO-PLS)的多块预处理数据的互补信息融合策略(sequential preprocessing through ORThogonalization, SPORT)建立模型。然而, SPORT策略作为一种顺序执行的方法, 存在一个关键问题: 在执行时, 要求用户定义要测试的不同预处理的方法和顺序[17]。这些策略在一定程度上改善了模型性能, 但在优化方法、 模型可解释性等方面仍有改善的空间。
对于一个复杂样品, 寻找合适的预处理方法组合可以看作一个优化问题。基于这种思路, 提出了一种简单有效的预处理组合优化策略, 通过设置预处理方法库, 设置收敛条件迭代寻优, 从库中选出优良的预处理组合, 旨在构建稳健的化学计量学模型。基于以上设计流程, 提出的策略选用优化领域的贪婪算法进行寻优。将该策略在小麦和猪肉两个近红外数据集上进行测试, 得到优化后的预处理组合, 最后通过PLS建立回归模型[18], 计算模型评价指标评估模型性能及泛化能力。分别将该策略与原始光谱、 经过单一预处理方法或简单组合的预处理策略、 及同类常用的优化策略进行比较, 旨在展示该策略的优良性能和预处理组合优化的潜力。
本方法在两组真实的公开数据集上进行了测试:
小麦数据(wheat data)[19]: 在光谱范围850~1 050 nm内均匀的取100个波长测量小麦种子的近红外透射光谱, 并用于校准蛋白质含量。数据集包含已划分好的415个样本的校准集和108个样本的测试集。
猪肉数据(meat data)[20]: 在光谱范围850~1 050 nm内均匀的取100个波长测量猪肉的近红外透射光谱, 用于标定脂肪含量。数据集包含已划分好的172个样本的校准集和43个样本的测试集。
小麦数据可在以下网站下载: www.models.life.ku.dk/datasets; 猪肉数据可在以下网站下载: http://lib.stat.cmu.edu/datasets/tecator。
对光谱数据进行预测, 通常采用如式(1)进行建模
式(1)中, X为光谱矩阵, y为响应变量。由于光谱矩阵具有典型的高维共线特点, 回归系数β 无法直接求解式(1)得到[21]。本研究采用PLS算法建模求解该系数。
为了去除光谱中的无关信息, 建模前通常要使用预处理方法。改写式(1)可以得到
光谱采集过程受到众多因素的干扰。单一的预处理方法往往难以取得理想的效果, 多种预处理方法组合使用已经成为预处理步骤的趋势。多种预处理方法按照一定的顺序处理原始光谱数据, 以此消除光谱中与建模无关的信息。令最大预处理方法数量为m, fi为第i个预处理方法, 多种预处理方法组合建模可以表示为
式(3)中i≤ m。
本文提出一种简单高效的预处理组合寻优方法, 并对预处理方法的个数和处理顺序进行优化。令经过该方法优化后的预处理组合为F, 本文所提方法的优化目标可以表示为
对于这个优化问题, 采用贪婪算法(greedy algorithm), 它是一个经典的寻优算法, 其基本思想是将一个问题的求解过程看作是一系列(多轮次)的选择, 每次选择一个当前状态下的最优选择, 而每做一次选择后, 所求的问题会简化为一个规模更小的子问题, 从而通过每一步的最优解逐步找到整个问题的最优解[22]。实际上, 对复杂的光谱数据而言, 寻找一个建模效果最好的预处理方法或组合本质上就是一个优化问题。贪婪算法的执行速度快, 易于实现, 在优化问题领域广泛使用。
本文提出的策略具体流程如下: 首先建立一个预处理方法库, 将样品的训练集分别经过库中的预处理方法处理, 然后利用PLS算法建模, 计算每一轮建模的RMSEC, 找到最低的RMSEC预处理方法, 最后利用十折交叉验证, 寻找最优的潜在变量数并建模, 计算其RMSECV, 以RMSECV为收敛标准, 优化整个数据集的预处理组合及其潜在变量数目, 完整策略描述见算法1。
算法1: 本研究提出的的预处理组合优化策略
输入: 光谱矩阵X, 响应变量y, 预处理方法库P, 最大候选方法数目m
输出: 最优预处理组合f={f1, …, fk}
1: 初始化f={⌀}、 第i轮的最优预处理方法fi、 参数j
2: i← 1
3: while优化过程未收敛do
4: j← 1
5: for j< m do
6: 应用第j个候选方法Pj对X进行预处理并建模, 计算RMSECj
7: j← j+1
8: end for
9: c← arg
10: fi← Pc
11: 对组合{f1, …, fi}建模进行十折交叉验证, 得到RMSECVi
12: if RMSECVi> RMSECVi-1 then
13: 退出并输出f
14: end if
15: f← {f1, …, fi}
16: i← i+1
17: endwhile
目前预处理方法数量众多, 有些方法需要设置内部参数, 想要顺利优化组合需要花费大量时间和计算资源。参考文献[14, 16]的预处理方法, 总结选取了在近红外光谱领域常用的8种预处理方法, 设置合适的参数, 构建预处理方法库见表1, 供算法迭代。
| 表1 预处理方法库 Table 1 Library of pre-processing methods |
选用光谱定量分析中的经典的PLS算法[23], 使用了Stacked策略和SPORT策略作为对比方法。Stacked策略是通过不同的预处理训练多个回归模型, 然后将它们与交叉验证或模型平均等方法相结合, 期望得到更稳定、 更精确的PLS模型[14]。SPORT策略是一种多块数据融合方法, 将多个预处理方法处理后的数据作为多块数据来处理, SPORT策略的核心思想是将解决预处理优化问题融入到PLS多元线性矫正步骤中[15], 得到一个增强过程。利用PLS算法建模符合控制变量法要求[24]。
表2展示了原始数据(未进行预处理)、 经过一些单一预处理(Single)或两种预处理方法组合使用(Double)后进行PLS建模后的结果。可以注意到, 原始数据建立的模型性能较差, 并且在小麦数据和猪肉数据的情况下都需要大量的潜在变量。当利用单个预处理方法时, 大多数预处理方法效果并不明显。对于小麦数据集, 较好的单一预处理方法是SNV。它使原始数据构建的模型的RMSEP从0.78降低到0.60, 预测均方根误差降低了23%。对于猪肉数据集, 多数单一预处理方法对模型校准效果并不显著, 相对较好的方法是SNV和SG平滑, 前者在校正集上相较原始数据建模均方根误差降低了约8%, 后者在测试集上降低约7%的均方根误差。观察两种预处理组合策略的应用情况, 文献[6]提出使用先进行平滑去除噪声再进行求导来突出特征信息的两种预处理方法组合(SG-O-P-Q)处理数据, 在两种数据集上相较于单一预处理方法建模结果有一定提升, 如在小麦数据集中Double策略表现最好的SG-15-2-2, RMSEC和RMSEP两项指标相较SNV都有一定程度的下降。从上面的结果显示, 两组数据集经过单个预处理方法或两种预处理方法组合后建模效果均有提升, 这表明合适的预处理方法组合对模型校正有更稳健的效果。
| 表2 单一预处理和两种预处理组合策略在小麦和猪肉数据上的评估结果 Table 2 Evaluation results of single preprocessing and two preprocessing combination strategies on wheat and meat data |
表3展示了小麦和猪肉数据集用Stacked、 SPORT及本文提出策略的建模结果。据文献[14]解释, 对于小麦数据集, 堆叠模型的性能略优于最佳单块预处理, 而对于猪肉数据集, 堆叠模型的性能更好(RMSEP从2.26降低到1.82, 降低了约19%)。相比之下SPORT策略结果要优于堆叠模型, 小麦和猪肉数据集的RMSEP分别从0.57降低到0.47, 从1.82降低到1.65, 相应降低了18%和9%。而本研究提出的策略建模在两个数据集上都有最好的表现, 小麦数据集得到的RMSEP为0.39, 与原始模型相比, 误差减少了50%。猪肉数据集的RMSEP为0.98, 相较原始模型降低了57%。与堆叠模型相比, 小麦和猪肉数据集的RMSEP分别从0.57降低到0.39, 从1.82降低到0.98, 相应降低了32%和46%。与较为新颖的基于多块融合策略SPORT的模型相比, 小麦数据集的RMSEP从0.47降至0.39, 提出的策略在猪肉数据集上提升效果更为明显, RMSEP从1.65下降至0.98, 降低了41%。小麦和猪肉数据集的潜在变量个数相较于原始数据分别从10个降至7个, 从12个降至9个。结果显示, 本研究提出的策略在这两个数据集上都取得了最好的校正效果, 展现出其在预处理优化领域的潜力。
| 表3 三种优化策略对小麦和猪肉的评估结果 Table 3 Evaluation results of three optimization strategies on wheat and meat data |
对于这两个数据集, 提出的策略给出了不同的预处理组合。对于小麦数据集, 文献[4]提到此原始光谱有明显基线问题, 图1(a)中显示其分辨率和信噪比都很差。本文提出的策略先选择二阶导(SG-15-2-2)方法来处理数据, 二阶导是一个常用的基线校正的处理方法, 图1(b)展示了经过二阶导平滑处理后的光谱图, 对数据中一些峰值有明显的增强效果, 另外一定程度上改善了原始光谱严重的基线问题。表2中预处理策略的比较中, 二阶导数也是其中RMSEC最低的方法, 这样的选择也印证了该策略中步步寻优的思想; 第二个选择的预处理方法是SNV, SNV方法是在预处理中主要起散射校正的功能, 选择此方法似乎有些出乎意料, 在前面肉眼观察时该数据的散射问题似乎并不严重。实际上, 根据该策略的思想, SNV方法是第二轮中所有剩余的预处理方法中与二阶导组合建模效果最好的方法。正如图1(c)中展示的, 将二阶导与SNV方法组合对光谱预处理后不仅很大程度消除了基线漂移和噪声的问题, 同时很好的保留并突出了原光谱里潜在特征信息, 这也从侧面反映出选择SNV方法的合理性。
 | 图1 (a)、 (b)、 (c)和(d)、 (e)、 (f)分别展示了小麦和猪肉的原始光谱、 经过SG-15-2-2方法处理后的光谱及经过本研究提出的策略优化预处理组合处理后的光谱Fig.1 (a), (b), (c), and (d), (e), (f) show the original spectra, preprocessed spectra by SG-15-2-2 method, and the spectra further processed by the optimised preprocessing combination strategy proposed in this paper for wheat and meat datasets, respectively |
对猪肉数据集, 提出的策略选择的组合预处理数目达到3个, 依次是SG-15-2-2、 SNV和MSC。相比小麦数据集, 猪肉数据集在使用SNV处理后又引入了MSC方法, 可能的原因是在猪肉数据采集过程中引入了乘性散射信息, 导致猪肉数据集的干扰信息较多, 这也要求该策略引入了更多的预处理方法数目。从图1(e)中可以看到仅仅经过二阶导处理的光谱基线漂移情况依旧存在, 通过提出的三种方法组合处理策略后如图1(f)所示, 相较原始光谱, 显著的消除了基线问题、 突出了光谱波峰值信息, 很好的完成了光谱校正中预处理步骤消除无关信息, 突出潜在信息的目标。
图2展示了小麦和猪肉数据经过本研究提出的策略优化预处理组合处理后的建模效果散点图, 为了更清晰的展示该策略的优化能力, 选用原始光谱和Single和Double策略中校准效果较好的预处理方法(SG-15-2-2)处理后的光谱作为对照。另外, 表3的结果也很好的解释了猪肉数据集引入较多预处理方法的原因: 经过大量的预处理后, 不论是校准结果还是直观的线性拟合效果都得到大幅的提升, 其RMSEP相比原始建模下降了近60%。
 | 图2 展示了小麦和猪肉数据分别在未经预处理、 经过SG-15-2-2方法及经过提出的策略优化预处理组合处理后在预测集上的建模效果 (a)、 (b)、 (c)是小麦种子中蛋白质含量(%)的建模结果; (d)、 (e)、 (f)是猪肉中脂肪含量(%)的建模结果Fig.2 The modelling results of wheat and meat data of the prediction set without and with preprocessing using SG-15-2-2 method, and the proposed strategy-optimised preprocessing combination (a), (b) and (c) are the modelling results of protein content (%) in wheat seeds; (d), (e) and (f) are the modelling results of fat content (%) in meat |
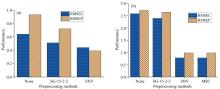
图3显示了本文提出的策略在优化过程中, 通过RMSEC和RMSEP指标来展示选出的预处理方法对建模的贡献情况。对于小麦种子数据集, 该策略选出了SG-15-2-2和SNV两个方法按顺序组合使用。从RMSEC和RMSEP指标来看, 这两种方法在上一步的基础上都做了一定程度的改进, 贡献度大致相同。而在猪肉数据集中, 提出的策略选出了SG-15-2-2、 SNV、 MSC三个方法组合使用。不论是在RMSEC还是RMSEP的上, SNV的贡献程度最大, SG-15-2-2次之, MSC方法的贡献程度最低。其中SNV方法贡献了超过80%的改进“ 因子” , 可能的原因是对于经过SG-15-2-2方法校正后的光谱虽然消除了部分基线, 此时的数据仍需解决大量的散射问题, SNV作为一种散射校正的经典方法能够很好的“ 清洗” 数据。相比之下MSC方法相比上一步SNV几乎没有改进, 注意到MSC和SNV同属于散射校正同一个功能方法族, 通过SNV的校正后, 猪肉光谱的散射问题已被基本消除, 这可能是MSC方法对建模贡献程度较低的原因。
 | 图3 小麦(a)和猪肉(b)数据按照提出的组合策略顺序处理时RMSEC和RMSEP的变化情况Fig.3 The variations of RMSEC and RMSEP when wheat (a) and meat (b) during the spectral data processed step by step using the proposed combination strategy for wheat and meat data |
根据选出的预处理方法对模型的贡献度不同, 在实际应用过程中, 通常舍弃对建模贡献度极低的预处理方法, 一方面可以降低模型过拟合的风险, 另一个可以减少组合内的预处理方法数量, 提高数据处理效率。虽然无法确保找到全局最优解, 但通过对优化组合的持续改进, 本研究提出的策略通常能够选择一个合适的预处理组合。最后值得注意的是, 由于实际数据总是有限的, 无论是对验证集还是测试集, 追求全局最优可能会带来过拟合的风险。因此, 在进行预处理方法的组合时, 需要谨慎平衡过拟合和欠拟合之间的关系[25]。如对猪肉数据集, 通常舍弃对模型贡献度极低的MSC方法后建模, 旨在降低过拟合的风险。总的来说, 对于复杂样品的近红外光谱数据, 本研究提出的策略不仅能够简洁的选出若干个预处理方法组合使用, 建立较为稳健的模型, 同时该策略的可解释性强, 过程中能够清晰的展示出每一个预处理方法对模型的贡献情况。
探索了一种新的策略来寻找最优的光谱的预处理方法组合, 将其用于校准真实的光谱模型中。针对目前复杂光谱样品预处理方法的选择问题, 设计了一种简单高效的预处理组合寻优策略, 这包括对同一组光谱应用不同的预处理, 然后通过贪婪算法步步迭代, 以建模结果反馈机制为迭代标准, 通过寻找每一轮的最优预处理方法继而得到整个问题的优化预处理组合。将该策略在小麦、 猪肉等数据集上测试, 结果显示: (1)对于现实中复杂光谱样品, 多种预处理方法组合使用往往比单一预处理方法建模效果更好; (2)提出的策略优化的预处理组合相比同类的堆叠方法(Stacked)和集成方法(SPORT)建立了更加稳健的模型, 具有较好的泛化能力; (3)提出的策略可以展现每一步选出的预处理方法对模型的贡献大小, 可解释性强。本研究展示了该策略所主张的简洁、 高效及可解释性在预处理方向的潜力, 为近红外光谱预处理方法选择提供了一种有效途径。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|