


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种近红外光谱定量分析软件预测性能评价方法
[李蓉1, 2  , 郝璐
, 郝璐4 , 袁洪福4 , 何桂梅1, 2 , 邓天龙1 , 杜彪4, 5 , 龚丽4 , 岳欣2, 3, * ]
, 郝璐, 袁洪福]
|
|


作者简介: 李 蓉, 1999年生, 天津科技大学海洋与环境学院硕士研究生 e-mail: 2086972672@qq.com
郝 璐, 1992年生, 北京化工大学材料科学与工程学院硕士研究生 e-mail: haolu1@sinochem.com
李 蓉, 郝 璐: 并列第一作者
常用的多元分析模型评价指标尚缺乏评价近红外分析软件多项重要预测性能指标的能力, 成为近红外光谱仪预测性能以及实际近红外应用中模型适用性评价的痛点。为此, 旨在发展一种近红外定量分析软件预测性能的评价方法。以近红外测定汽油烯烃浓度为研究对象, 收集了192个国Ⅵ汽油样品, 包括92#、 95#和98#; 采集其近红外光谱; 按照GB/T 30519—2014测定其烯烃浓度作为参考值, 分别使用两种不同的多元分析软件(1种是偏最小二乘(PLS)建模软件, 另1种是非PLS的软件), 建立了两个校正模型。研究发现, 与参考值相比, PLS模型对低浓度样品预测值呈正偏差, 高浓度的呈负偏差, 即“均值化”现象。常用的模型预测性能评价指标尚不能评价模型预测值的均值化程度, 也不能评价: (1)预测值与参考值偏差大于参考方法再现性的样本占比, (2)模型泛化能力。本文针对上述问题, 提出了4项新评价指标包括均值化指数(AE)、 预测偏差超限值样本占比(Ratio)、 异常样本预测偏差(DAS)和孤立样品预测偏差(DIS)。综合常用的评价指标和新评价指标(共12项), 对仪器选型的近红外光谱定量分析软件预测性能的评价、 实际近红外分析应用中模型适用性的评价均具有实际意义, 对近红外分析学术研究也具参考意义。
, HAO Lu, YUAN Hong-fu
LI Rong and HAO Lu: joint first authors
The commonly used evaluation indexes of multivariate models lack the ability to evaluate many important predictive performance indicators of near-infrared quantitative analysis software. This has become a pain point in evaluating the predictive performance of near-infrared instrument selection and the applicability of models in practical near-infrared analysis applications. Therefore, this study aims to develop an evaluation method for the predictive performance of near-infrared quantitative analysis software. 192 national VI gasoline samples, including 92#, 95#, and 98#, were collected for determination of olefin concentration of gasoline using near-infrared spectroscopy; their near-infrared spectra collected and olefin concentrations were measured as a reference value according to GB/T 30519—2014, and two different multivariate software(one is partial least squares (PLS) modeling software, and the other is non-PLS software) were used to study. It has been found that compared to the reference value, the PLS model has a positive bias in predicting low-concentration samples and a negative bias in predicting high-concentration samples, which is known as the phenomenon of “averaging”. The commonly used performance evaluation indicators for model prediction cannot yet evaluate the degree of the averaging, nor can evaluate (1) the proportion of samples with deviation from the reference value greater than the limit value for the reproducibility of the reference method and (2) the model’s generalization ability. In this paper, four new evaluation indicators are proposed to address the above issues, including Averaging Index (AE), Ratio of samples with prediction bias exceeding the limit value (Ratio), Deviation of Abnormal Sample (DAS), and Deviation of Isolated Sample (DIS). The comprehensive use of commonly used evaluation indicators and new ones (12 items) has practical significance in evaluating the predictive performance of near-infrared quantitative analysis software for instrument selection and the applicability of models in practical near-infrared analysis applications. It also has reference significance for academic research in near-infrared analysis.
近红外光谱可从分子水平反映样品组成与结构信息[1], 使用多元分析方法将近红外光谱与样品性质进行关联, 建立近红外光谱预测样品性质的校正模型[2], 依据校正模型, 使用待测样品近红外光谱预测其性质。随着近红外光谱分析技术的广泛应用, 对近红外检测设备需求也呈逐年上升趋势。目前, 市场上近红外光谱分析仪器种类繁多, 其性能和价格参差不齐。在性能满足应用要求和价格合理的前提条件下, 选择性能更优的近红外光谱仪器是用户普遍关心的问题。
近红外光谱分析技术主要由近红外光谱仪, 近红外光谱定量分析软件和校正模型构成[3, 4]。其中, 近红外光谱仪和近红外光谱定量分析软件是技术基础, 其性能对模型预测性能均有重要影响。因此, 光谱仪和软件的预测性能的评价对其实际应用具有重要意义。通常近红外光谱仪器与预测性能有关的主要指标如光谱范围、 重复性、 信噪比等, 其性能评价方法是成熟的, 已制定相关标准[5]。但是, 近红外光谱定量分析软件的预测性能评价方法尚不多见。常用的多元分析模型评价指标尚缺乏评价近红外分析软件多项重要预测性能指标的能力[6], 已成为模型实际适用性评价及近红外分析仪器性能评价的痛点问题。因此, 发展近红外光谱定量分析软件预测性能的方法是近红外分析领域亟待解决的课题。
近红外光谱定量分析软件使用多元分析方法, 将样品光谱与性质进行关联建立校准模型[7]。常用的多元分析方法包括多元线性回归(MLR)和偏最小二乘回归(PLS)[8], 它们适合于建立线性校正模型; 还有一些方法如支持向量机(SVM)[9, 10], 卷积神经网络(CNN)等[11], 改善与光谱呈非线性指标校正模型的性能, 目前还停留在学术研究阶段, 少有用于商业软件。国内外商品近红外分析仪器配套的近红外定量分析软件大多使用PLS软件[12], 也有少数使用基于拓扑学软件, 对非线性指标建模表现出更优的性能。近年来, 国内也开发出了几款新型多元分析方法的近红外光谱定量分析软件[13]。采用的多元分析方法对软件预测性能具有主要影响, 另外, 软件拥有的光谱预处理能力也具有影响[14]。一般用户并不了解软件底层算法和功能设计逻辑, 仅凭软件提供的数据处理方法及功能名称, 不经实际样品建模验证, 难以评价软件预测性能优劣。无论软件算法公开与否, 通过实际建模效果评价软件预测性能则比较科学, 对用户和软件提供商都是公平的。常用的评价指标包括: 校正标准偏差(SEC)、 交互验证校正标准偏差(SECV)、 预测标准偏差(SEP)、 校正相关系数(Rc)、 预测相关系数(Rp)、 参考值和预测值标准偏差比值(RPD)、 配对t-test值等。但是, 这些指标为统计参数, 可计算整体模型预测值平均偏差, 但不能反映每个样品预测值偏离情况, 即使SEP小于参考方法再现性限值, 也不能判定建模型性能是否达到使用要求。另外, 也不能有效地评价模型的泛化能力。
为此, 通过建立近红外光谱检测汽油烯烃浓度校正模型, 剖析了常用的评价指标的局限性, 并提出了4项新的评价指标, 包括均值化效应(averaging effect, AE)、 预测偏差超限值样本占比(Ratio)、 异常样本预测偏差(deviation of abnormal sample, DAS) 、 和孤立样品预测偏差(deviation of isolated sample, DIS), 弥补了常用评价指标的不足, 完善了模型预测性能评价方法内容。综合使用常用的评价指标与新指标(共12项), 可以较为全面地评价近红外光谱定量分析软件预测性能, 为近红外分析实际应用中模型适用性评价提供技术支撑, 也为近红外分析学术研究提供参考。
1.1.1 SECV
SECV为通过交互验证(cross validation)获得的校正集预测值标准偏差, 用于估计校正集样品整体预测值偏离参考值的程度, 该值越小越好[15]。常用的交互验证方法为留一法, 即每次从校正集中取出一个样本, 用其余的校正集样本建立模型, 用所建模型预测被取出的样本, 计算该样本预测值与参考值的偏差, 然后, 将该样本放回校正集。重复上述过程, 直至校正集中每个样本都被取出过一次。还有留多法, 与留一法相似, 不同的是一次取出多个样品。依据式(1)计算SECV。
式(1)中: yi, reference为第i样品的参考值; yi, predicted为第i个样本预测值。
1.1.2 SEC和SEP
SEC和SEP分别为校正集和验证集的预测值标准偏差, 依据式(2)计算。用于描述预测值和参考值之间的离散程度及衡量预测值和参考值误差大小的尺度, 其数值越接近0, 表示模型预测的准确度越高[16]。
式(2)中: yi, reference表示校正集、 验证集中第i样品参考值; yi, predicted表示校正集、 验证集中第i样品的预测值; d表示校正模型的自由度。
1.1.3 Rc和Rp
Rp和Rc分别为校正集和验证集预测值与参考值的线性相关系数, 依据式(3)计算, 其值越接近于1, 表明模型预测值与实际值越接近[17]。
式(3)中:
1.1.4 RPD
RPD为验证集参考值标准偏差(SDV)与验证集预测值标准偏差(SEP)的比值, 依据式(4)计算。RPD值介于1.5~2, 模型的预测性能较差; RPD值为2~2.5, 模型的预测性能符合基本要求; RPD值大于2.5, 模型预测性能好[18]。
1.1.5 配对t检验
用于检验参考值与近红外预测值之间否有显著性差异, 依据式(5)计算[19]。
式(5)中:
1.2.1 AE
若在性质低端区域出现预测值呈正偏差趋势, 性质高端区域出现预测值呈负偏差趋势, 则模型预测值存在均值化效应。AE为均值化指数, 依据式(6)计算。
式(6)中: m表示性质低端区域内样品个数; n表示性质高端区域内样品个数,
1.2.2 Ratio
Ratio为预测值偏差超过参考方法再现性限值的样本数占所有样本数的比值。
式(7)中: x为预测偏差超限值样本数目; y为所有样本数目。Ratio值越小说明模型预测能力越好。
1.2.3 DAS
异常样本指在组成或形态上与建模样品有明显差的样品。将DAS与参考值再现性限值比较, 评价模型的泛化能力。
式(8)中: ya, reference表示异常样本的参考值, ya, predicted表示异常样本的预测值。
DAS绝对值越小说明模型泛化能力越强。
1.2.4 DIS
DIS为孤立样品预测值偏差。将DIS与参考方法再现性限值比较, 评价模型的泛化能力。
式(9)中: yii, reference表示孤立样本的参考值, yii, predicted表示孤立样本的预测值。
DIS绝对值越小说明模型泛化能力越强。
DIS又分为空心孤立DIS空心和边缘外孤立DIS边缘外。
中国计量科学研究院与北京易兴元石化科技有限公司共同研制的NIR-501A型便携式傅里叶变换近红外油品分析仪。波数范围: 10 000~4 000 cm-1, 信噪比优于10 000∶ 1, 配套比色管内径6 mm。
岛津公司(日本)制造的GC—2014C型气相色谱仪, 检测器为火焰离子化检测器(FID), 基线噪音: 1.0× 10-3 A; 基线漂移: 4.2× 10-12 A/30 min; 柱箱温度稳定性: 0.06%/10 min; 定性重复性: 0.03%; 定量重复性: 1.1%。
收集了192个国Ⅵ 汽油作为实验样品, 油样来源有中石化加油站、 顺义牛山油库, 地方抽检样品。其中92号车用汽油93个、 95号车用汽油76个、 98号车用汽油23个。为了避免组分挥发, 样品均密封保存在干燥阴凉的冷藏室。
将汽油样品从冷藏室中取出, 在室温(20± 5)℃下静置0.5 h。采集光谱前, 油品分析仪须预热60 min, 设置光谱采集参数: 扫描次数32。为减少比色管厚度不均匀对样品光谱的影响, 每次采集前旋转比色管1/3周, 一个样品依次重复3次采集, 取其平均光谱作为样品光谱。
按照标准方法《GB/T 30519—2014轻质石油馏分和产品中烃族组成和苯的测定(多维气相色谱法)》测定汽油样品烯烃浓度作为参考值。用微量注射器取50 μ L汽油样品进样, 经色谱仪气化室后进入极性分离柱将样品中烯烃与其他共存组分离, 通过FID检测, 使用分析软件处理色谱图, 计算样品烯烃浓度数值。
选择了一种采用非PLS算法的多元分析软件, SunnyLib和一种采用PLS算法的软件(均为西派特(北京)科技有限公司产品软件), 用于近红外光谱定量分析软件预测性能的评价方法研究。这两种软件均具有光谱多元分析软件的基本功能, 包括样本集建立, 光谱预处理, 建模, 未知样品预测及各种可视化等。
使用同一套校正集和验证集数据, 分别使用上述两种软件建立模型, 计算上述的评价指标, 通过比较两种软件所建模型的评价指标, 多维度地评价这两种软件的预测能力。
通过分别对校正集和验证集样品的PLS模型预测值对参考值作图, 观测烯烃浓度范围两端区域内样品相对斜率为1实线的分布情况, 确定呈正偏差趋势和负偏差趋势的浓度范围, 计算AE; 通过对样品光谱进行PCA处理, 使用前3个主成分得分值, 取95%的置信区间, 计算异常样本, 结合参考方法再现性限值, 用于评价模型对异常样品的预测能力; 通过使用第一和第二主成分得分作图, 分别设计了两类孤立样品: 一类孤立样品位于建模样品分布的空心处, 称为空心分布型孤立样品, 另一类孤立样品在建模样品分布外边, 称为边缘外分布型孤立样品。结合参考方法再现性限值, 用于评价模型泛化能力。
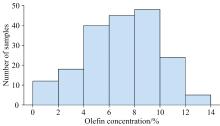
收集了192个来源于河北、 山西、 山东等不同地域的汽油样品, 按照气相色谱法测定其烯烃浓度结果分布如图1所示, 可以看出, 烯烃浓度变化范围0.9%~13.8%, 均满足国Ⅵ (B)烯烃浓度限值(不大于15%)。在整个浓度区域内样品数目分布并不均匀, 在低烯烃浓度区域和高浓度区域, 样品数目相对较少。实际中, 浓度两端的样品不易获得, 对建模具有不利影响。
 | 图1 样品数与烯烃浓度的关系图Fig.1 Number of samples vs olefin concentration |
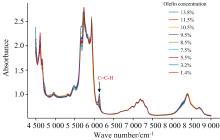
近红外光谱属于分子振动光谱的基频的倍频和组合频, 含氢基团(C—H, O—H, N—H, S—H)均在该区域有吸收峰[20]。而汽油是由大量的烃类化合物组成的, 所以烃类化合物中的甲基、 烯烃、 亚甲基和芳烃在近红外区域有丰富的特征吸收光谱[21]。烯烃分子的近红外光谱中, 最显著的特征峰是C—H伸缩振动峰和C=C伸缩振动峰, C—H伸缩振动和弯曲振动组合频的谱带吸收一般出现在5 000~4 545 cm-1波段范围; C—H振动的一级倍频出现在6 250~5 555 cm-1波数范围; C=C伸缩振动的谱带吸收频率出现在6 250~6 040和6 190~5 990 cm-1波段范围[22]。
图2为不同烯烃含量的汽油光谱, 在6 230~6 005 cm-1区间, 随着样本中烯烃含量的增加, 其光谱吸收曲线各峰随之变得陡峭即吸光度变强[23], 表明汽油烯烃特征峰吸光度与其含量呈正相关关系。在低于4 630 cm-1, 以及5 500~5 995 cm-1区间近红外光几乎完全被样品吸收, 其吸光度超出线性响应范围, 应不参与建模。
 | 图2 不同烯烃浓度汽油样品的近红外光谱Fig.2 Near-infrared spectra of gasoline samples with different olefin concentrations |
将192个汽油样品近红外光谱数据构成一个光谱矩阵, 进行PCA分析, 使用前3个主成分得分作图(如图3所示), 展示了不同汽油样本在主成分空间中的分布, 说明样品组成有很大变化, 而且分布不均匀, 有的区域中样品分布稀疏, 有的区域则密集。根据样品聚集程度, 设置置信区间为95%, 其中编号为10、 34、 128、 149、 175、 178、 180样品远离其他大多数样品, 位于置信区间外, 被视为异常离群样品, 不参加建模。
 | 图3 前3个主成分得分的作图Fig.3 Scores of the first three principal components |
3.4.1 建模及常用评价参数
剔除离群样品后剩余185个样品, 采用K-S分类法, 按照4∶ 1将其分为校正集和验证集。分别使用原始光谱、 SNV光谱、 MSC光谱、 平滑光谱、 一阶微分和二阶微分光谱以及它们的组合, 采用PLS和留一法交互验证, 建立了9 个烯烃含量校正模型, 其常用模型评价参数如表1所示。使用相同的样品集及预处理方法, 采用SunnyLib建模, 其常用模型评价参数如表2所示。可以看出, 两种软件都是采用一阶微分处理建立的模型性能最优, 计算的所有t值均小于查表值1.645。与PLS最优模型相比, SunnyLib将SEC从0.861%降低至0.803%, SECV从0.972%降低至0.910%, SEP从0.870%降至0.811%, Rc从0.959提升至0.974, Rp从0.950升至0.967, RPD从4.598升至4.932。《GB/T 30519—2014轻质石油馏分和产品中烃族组成和苯的测定(多维气相色谱法)》中规定不同烯烃含量对应着不同的再现性, 在满足国VIB汽油(烯烃含量不大于15%)的要求下, 国标方法再现性范围为0.8%~1.4%, 可见两个模型的SECV、 SEC、 SEP均满足国标方法再现性要求。配对t-test结果表明使用两种软件建立的模型其预测值与参考值之间均无显著性差异。两款软件计算结果得到的RPD均大于4.5, 表明均有很好的预测能力, SunnyLib软件的RPD大于4.9, 具有更好的预测能力。
| 表1 PLS模型评价指标 Table 1 Evaluation indicators of PLS models |
| 表2 SunnyLib模型评价指标 Table 2 Evaluation indicators of SunnyLib Models |
3.4.2 AE评价
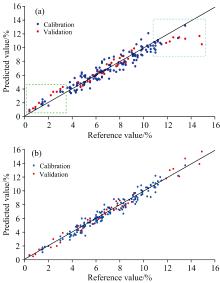
对上述校正集样品(148个)和验证集样品(37个)。分别使用PLS软件和SunnyLib建模, 并对验证集样品进行预测。将所有样品预测值对其参考值作图, 如图4所示。所有样品烯烃浓度均值为7.0%, 其中, 在4%~10%之间样本占比为60%, 剩余40%样本分布在小于4%和大于10%的两端区域。
 | 图4 (a) PLS软件建模预测值对参考值作图; (b) SunnyLib建模预测值对参考值作图Fig.4 (a) Predicted values obtained by PLS software vs reference values; (b) Predicted values obtained by SunyLib software vs reference values |
使用PLS软件建模, 用所建模型对所有样本进行预测, 将其预测值对参考值作图[如图4(a)所示]。可以看出, 在4%~10%区间, 无论校正样本(红色)还是验证样本(蓝色)参考值与预测值线性关系均较好, 其预测偏差较小, 均低于国标再现性限值。但在浓度值低于4%区间(绿色框内), 除1个校正样本位于实线下方外, 其他校正样本和验证样本分布在实线上方, 其预测值呈正偏差; 在大于10%区间(蓝色框内), 所有样品都分布在实线下方, 其预测值呈负偏差。表明低浓度样本预测值偏高, 高浓度样本预测值偏低, 是典型的均值化现象。使用式(6)计算, AE=0.87%, 表明PLS软件建模存在着明显的均值化效应。
使用SunnyLib建模, 再用所建模型对所有样本进行预测, 将其预测值对参考值作图[如图4(b)所示]。可以看出, 在整个浓度区间, 无论校正样本还是验证样本在以斜率为1实线为中心线较窄范围内呈均匀分布, 其预测偏差较小, 均满足国标再现性。对小于4%和大于10%两端区间内的样本, 使用式(6)计算, AE=0.007 6%, 接近于0, 表明SunnyLib软件建模基本不存在均值化效应。
3.4.3 Ratio评价
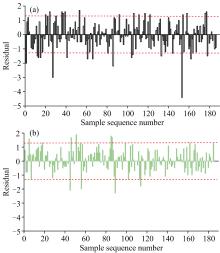
使用两种模型预测值和参考值, 计算各样品预测残差值。图5(a)为PLS软件获得的样品残差值图, 可以看出, 即使SEP满足国标方法再现性限值, 但仍有35个样品预测偏差大于国标方法再现性限值。最大预测偏差为4.4%, Ratio为19%。SunnyLib软件获得的样品残差值图如图5(b)所示。与图5(a)比较可以看出, 整体上残差绝对值明显降低, 仅有9个样品预测偏差大于国标再现性限值, 最大预测值偏差为2.3%; Ratio为5%。
 | 图5 (a) 使用PLS软件获得的样品残差值图(虚线为国标再现性限值); (b)使用SunnyLib软件获得的样品残差值图3.4.4 DAS评价Fig.5 (a) Residual vs sample sequence number for PLS software (dashed line stands for the reproducibility limitation of national standard); (b) Residual vs sample sequence number for SunnyLib software |
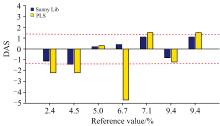
模型泛化能力是指模型对离群样本或不被模型适用范围所覆盖的样品的预测能力。离群样本一般是指那些性质分布在总体样本之外的样本, 且经核实其光谱采集精度和参考值精度没有问题。如图3, 通过主成分分析, 位于置信区间外的7个样品为离群样品, 不参加建模。使用两种软件建立的模型对该类样本进行预测。使用式(8)计算DAS, DAS对参考值作图(如图6所示)。可以看出, SunnyLib软件获得的平均DAS为0.83%, 最大DAS为1.5%, 所有样本预测偏差值均小于国标方法再现性限值; 而PLS软件获得的平均DAS为1.94%, 最大DAS为4.7%。表明SunnyLib软件对离群样本预测具有很好的泛化能力。
 | 图6 两种软件DAS对比Fig.6 DAS comparison between two softwares |
3.4.5 DIS评价
生产过程中物料来源常常发生变化, 导致近红外光谱分析在建模或后续应用过程中出现孤立样本, 这些样本超出了所建模型适用边界, 它们与模型总体样本无法一起建模, 这种情况也是基于回归算法的多元分析方法迄今尚未解决技术难题之一。目前也没有近红外光谱定量分析软件对孤立样本预测能力的评价方法与指标, 为此, 这里提出了一种孤立样本预测能力评价新方法。通常在组成上, 孤立样本与总体建模样本之间不具有连续性。在空间分布上, 孤立样本可以是被总体样本包围, 称为空心分布型; 也可以是总体样本边缘之外, 称之为边缘外分布型。本节设计了这两类与样品建模校正集空间分布差异较大的孤立样本, 通过建模与预测结果, 对两种不同软件对孤立样本的预测泛化能力进行了评价。
3.4.5.1 空心分布型孤立样本
使用3.4.1所述185个建模样本作为试验样本。对其光谱进行PCA分析, 使用第一主成分得分与第二主成分得分作图[如图7(a)所示], 其中每个点代表一个样本。然后将位于图7(a)中红圈内的样品剔除, 使用剩余样本构造了一个空心分布的校正集[如图7(b)所示]。从剔除样本中选择与空心分布校正集不连续的5个样品, 如图7(c)红圈中心区域的5个样品, 构造了空心分布型孤立样品, 作为外部验证集。
 | 图7 (a)基于主成分分析的185个样本分布图; (b)空心分布型校正样本分布图; (c)空心分布型孤立样品(红圈内)分布图Fig.7 (a) Distribution map of 185 samples based on spectral PCA; (b) Distribution map of hollow-distribution type calibration samples; (c) Distribution map of hollow-distribution-type isolated samples (within red circle) |
分别使用上述两种软件建立烯烃浓度校正模型, 对这类孤立样本烯烃浓度进行了预测。SunnyLib软件获得的平均DIS为0.56%, 小于PLS软件的为0.82%。这5个样本的预测结果列于表3, 可以看出, 尽管两种软件孤立样本预测偏差DIS均满足国标再现性限值, 但Sunnylib依然表现出更优秀的预测能力, 即其建模对于空心孤立样本具有更好的泛化能力。
| 表3 空心分布型孤立样品预测结果 Table 3 Predicted results for hollow-distribution-type isolated samples |
3.4.5.2 边缘外分布型孤立样本
对185个样本集光谱进行PCA分析后重新划分区域[如图8(a)所示]。然后将位于图8(a)中绿色矩形框内样品剔除, 使用左侧黄色圈区域剩余的98个样本构造了一个校正集, 使用位于右侧蓝色圈区域14个样品构造一批边缘外分布型孤立样品[如图8(b)所示], 作为外部验证集。
 | 图8 (a)基于主成分分析的185个样本分布图; (b)校正集样本和边缘外分布型孤立样本分布图Fig.8 (a) 185 samples distribution map based on PCA; (b) distribution maps of calibration set samples and edge-out-distribution type isolated samples (within blue circle) |
分别使用上述两种软件建立了烯烃含量校正模型, 对14个孤立样本进行预测, 结果列于表4。可以看出, 使用SunnyLib软件建立的模型预测, 其中13个样品预测偏差不大于国标再现性限值, 预测正确率为92.8%, 平均DIS为0.55%, 最大DIS为2%; 使用PLS软件建立的模型预测, 其中9个样品预测偏差不大于国标再现性限值, 预测正确率为64.3%, 平均DIS为1.06%, 最大DIS为3.3%。对每个孤立样本, 根据 Sunnylib软件预测值计算的DIS值, 比PLS软件的明显更低, 表明Sunnylib软件建模对于该类孤立样品表现出更优秀的泛化能力。
| 表4 边缘外分布型孤立样品预测结果 Table 4 Predicted results for edge-out-distribution type isolated samples |
以汽油烯烃浓度检测为例, 分别使用两种近红外光谱定量分析软件建模与预测, 其模型预测性能参数如表5所示。可以看出, SunnyLib软件获得的12项模型性能指标, 均明显优于PLS 软件。常的用模型评价指标仅从统计上反映模型性能, 而新增指标则分别从预测偏差超限值样本占比、 模型预测值均值化程度、 模型对异常样本和孤立样本的预测泛化能力方面评价模型预测性能。常用的评价指标结合新增指标, 可更直观地深入评价近红外光谱定量分析软件预测性能。
| 表5 使用两种软件评价的结果 Table 5 Results of two software evaluations |
(1)使用PLS软件建立的汽油烯烃浓度近红外分析模型预测, 模型预测具有明显的均值化效应; 软件对异常样品和离群孤立样品预测能力较弱。常用的评价指标不能评价上述问题, 也不能给出预测值偏差大于参考方法再现性限值的样本占比。
(2)提出了4项模型预测性能评价新指标(AE、 Ratio、 DAS和DIS), 弥补了模型性能常用评价指标的不足。使用常用的评价指标结合新评价指标(共12项), 可定量和直观地评价多元分析软件的预测性能, 可为近红外光谱定量分析软件选型以及对模型在实际应用中的适应性判断提供更科学的评价依据, 对近红外分析学术研究也具参考意义。
(3)以近红外检测汽油烯烃浓度为例, 对两款不同的近红外光谱定量分析软件预测性能进行了评价, 结果表明, 根据常用评价指标和新指标共12项指标的表现, SunnyLib软件明显优于PLS 软件。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|