




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱预处理方法与多模型在分类判别中的对比研究
[居雷1  , 于洁
, 于洁1 , 吴炎淼2 , 李丽2 , 卢天3 , 丁亚萍2 , 束茹欣1, * ]
, 于洁]
|
|


作者简介: 居 雷, 1988年生, 上海烟草集团有限责任公司技术中心硕士研究生 e-mail: jul@sh.tobacco.com.cn
高光谱技术能够快速、 无损地获取丰富的信息, 在植物研究和监测中已成为一种广泛应用的工具。茄科植物作为一种重要的经济农作物, 与高光谱技术结合进行研究具有巨大的应用潜力。本研究采用高光谱技术对茄科植物的初烤后不同部位叶片进行分类研究。采用Field Spec 3光谱辐射仪对293份不同部位的茄科植物粉末样本进行高光谱采样, 采用S-G平滑以及一阶导数和二阶导数的方法对数据进行预处理, 用于信息增强和去除噪声, 并通过偏最小二乘法对数据进行降维, 以减少冗余特征。基于降维数据, 采样支持向量机、 逻辑回归、 K近邻、 决策树、 随机森林和梯度提升决策树这六种机器学习算法建立分类模型。结果显示, 在分类任务中, 经过一阶导数处理后, 支持向量机模型最佳, 在训练集和测试集上分别实现了100.0%和84.7%的准确率。经网格参数优化后确定最优参数为:最大深度不限制, 最小样本分割数为4, 估计器数量为200。参数优化后五折交叉验证准确率为88.1%, 训练集准确率为100%, 测试集准确率为86.4%。研究结果表明, 预处理方法结合降维方法能够增强数据信息使得分类模型能够更好地捕捉茄科植物样本的特征。该研究对于快速、 准确、 无损地区分茄科植物的部位具有重要意义。
Identifying different parts of Solanaceae plants is crucial for their product formulation design and quality control. Hyperspectral technology, which can quickly and non-destructively acquire rich information, has become a widely used tool in plant research and monitoring. As important economic crops, Solanaceae plants have great research potential when combined with hyperspectral technology. This study employs hyperspectral technology to classify different parts of Solanaceae plant leaves after initial roasting. Firstly, hyperspectral sampling was conducted on 293 powder samples from different parts of Solanaceae plants using the Field Spec 3 spectroradiometer. Subsequently, data preprocessing was performed using S-G smoothing and first-order and second-order derivatives to enhance information and remove noise. To minimize redundant features, partial least squares (PLS) were then used for data dimensionality reduction. Finally, based on the dimensionality-reduced data, six machine learning classification models-support vector machine (SVM), logistic regression, K-nearest neighbors (KNN), decision tree, random forest, and gradient boosting decision tree—were used for modeling and analysis. The results showed that for the classification task, the SVM model performed best after first-order derivative processing, achieving an accuracy of 100.0% on the training set and 84.7% on the test set. After grid parameter optimization, the optimal parameters were determined: no restriction on maximum depth, a minimum sample split of 4, and 200 estimators. The accuracy of five-fold cross-validation after parameter optimization was 88.1%, with the training set accuracy at 100% and the test set accuracy at 86.4%. The study results indicate that preprocessing methods combined with dimensionality reduction can enhance data information, enabling classification models to capture the characteristics of Solanaceae plant samples better. This study is of great significance for the rapid, accurate, and non-destructive differentiation of parts of Solanaceae plants.
高光谱技术通过主动采集待测样品反射的电磁光谱信号, 提取研究对象的特征。该技术能够从待测样品中快速、 无损地获取大量窄且连续的反射光谱数据, 采集的信息具有数据丰富和高分辨精度等优点, 在农业生产检测领域中发挥着重要作用[1]。茄科植物作为广泛种植的农作物之一, 其反射光谱数据信息也十分丰富, 成为了高光谱技术的重要潜在应用对象[2]。
高光谱技术在茄科植物研究中的应用主要涉及预测茄科植物化学成分, 如叶面积指数、 叶绿素和烟碱含量。付虎艳等采用Field Spec 3便携式地物光谱仪对烤烟叶片进行光谱采集, 测定其叶绿素含量。通过分析光谱特征变量和叶绿素含量之间的相关性, 建立了叶绿素含量估测模型, 相关系数达到0.705[3]。陈楠等采用高光谱数据结合神经网络算法预测茄科植物叶片中的镉含量。通过测量不同镉污染水平下茄科植物叶片高光谱反射率构建神经网络预测模型, 该模型在训练集和测试集中的决定系数分别达到了0.681和0.801[4]。刘红芸等采用高光谱图像结合偏最小二乘法建立判别分析模型, 对贵州省云烟87中部烟叶的成熟度进行判别, 模型的准确率达到了98%[5]。Guo等研究了叶片叶绿素与高光谱参数之间的定量关系, 发现叶片叶绿素与特定波长处的光谱反射率呈线性或指数关系, 相关系数达到了0.845和0.881[6]。Yu等采用高光谱和机器学习方法, 成功区分了受不同浓度重金属汞胁迫的茄科植物。通过偏最小二乘判别分析和支持向量机方法构建模型, 实现了100%的准确率[7]。研究展示了高光谱技术在茄科植物领域的潜力, 可以为茄科植物品质评估、 病害监测和环境污染检测提供有效的工具和方法。尽管上述研究在茄科植物领域取得了一些进展, 但目前仍缺乏采用的高光谱技术对茄科植物不同部位进行分类研究。不同生长部位的茄科植物叶片在化学成分、 物理特性和品质上可能存在显著差异[8]。这些差异不仅影响最终烟草产品的风味和质量, 还影响烟草栽培和加工的效率。了解各部位烟叶的特性可以帮助生产商优化种植和收获策略, 提高茄科植物的整体品质和经济效益[9]。本工作在填补这一研究空白, 通过高光谱技术结合机器学习方法, 实现茄科植物部位的准确、 快速分类。
采用高光谱分析技术, 对来自不同生长部位的茄科植物初烤后叶片粉末样本进行分类研究。采用Savitzky-Golay(S-G)平滑和导数预处理方法, 并结合偏最小二乘法进行降维, 得到降维后的光谱数据。采用六种分类算法并分别比较不同模型结果。对于茄科植物部位的分类任务, 随机森林模型结果最佳, 其训练集准确率为100%, 测试集准确率为86.4%, 五折交叉验证准确率为88%。研究结果强调了采用偏最小二乘法降维和S-G平滑、 导数预处理方法的有效性, 可以从高维数据中主动提取出关键特征并降低数据维度, 对于茄科植物品质评估和产地溯源具有重要意义。
研究中共采集了293个茄科植物初烤后叶片粉末样本的数据。目标是实现茄科植物的不同生长部位(上部、 中部和下部)的准确分类。实验使用了美国马尔文帕纳科(Malvern Panalytical)生产的ASD Field Spec 3光谱辐射仪。该仪器能够提供全范围太阳辐照光谱, 覆盖了350~2 500 nm的波长范围, 并具有高分辨率, 可以获取详细的光谱信息用于后续的分析和处理。在机器学习和数据处理方面, 研究使用了Python 3中一些流行的库和工具。其中包括Scikit-Learn用于机器学习模型的构建和评估, NumPy用于处理和操作数组数据, Pandas用于数据处理和分析, SciPy用于科学计算和统计分析。这些库提供了丰富的功能和工具, 可以方便地进行数据预处理、 特征提取、 模型训练和评估等任务[10]。
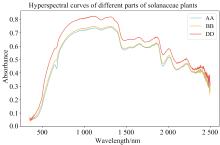
为了降低实验误差并确保实验结果的可重复性, 采取了以下措施: 首次使用预热30 min, 保持光源与样本采集的高度和角度的一致性, 采集高度为15 cm, 每隔3~5 min对设备进行一次校准。图1为不同部位的高光谱数据示意图。
 | 图1 茄科植物不同部位高光谱曲线 AA: 下部; BB: 中部; DD: 下部Fig.1 Hyperspectral curves of different parts of Solanaceae plants AA: The lower part; BB: The middle part; DD: The upper part |
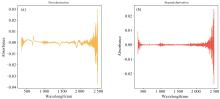
预处理方法包括一阶导数、 二阶导数和S-G(Savitzky-Golay)平滑。一阶导数可揭示光谱曲线的变化速率和趋势, 有助于定位特征点和边缘信息。二阶导数提供更详细的光谱特征, 突出峰值形状等信息[11]。S-G平滑是常用的数字信号处理技术, 用于平滑和光谱数据去噪, 通过滑动窗口上的多项式拟合来实现。S-G平滑在保留光谱特征的同时有效消除高频噪声和细微波动。通过调整滑动窗口大小和多项式阶数, 可以控制平滑的程度。综合应用这些方法能够提取关键特征、 减少冗余信息, 并揭示样本差异, 从而提高对光谱数据的分析和解释能力[12]。图2(a, b)分别为高光谱一阶导数和二阶导数图。
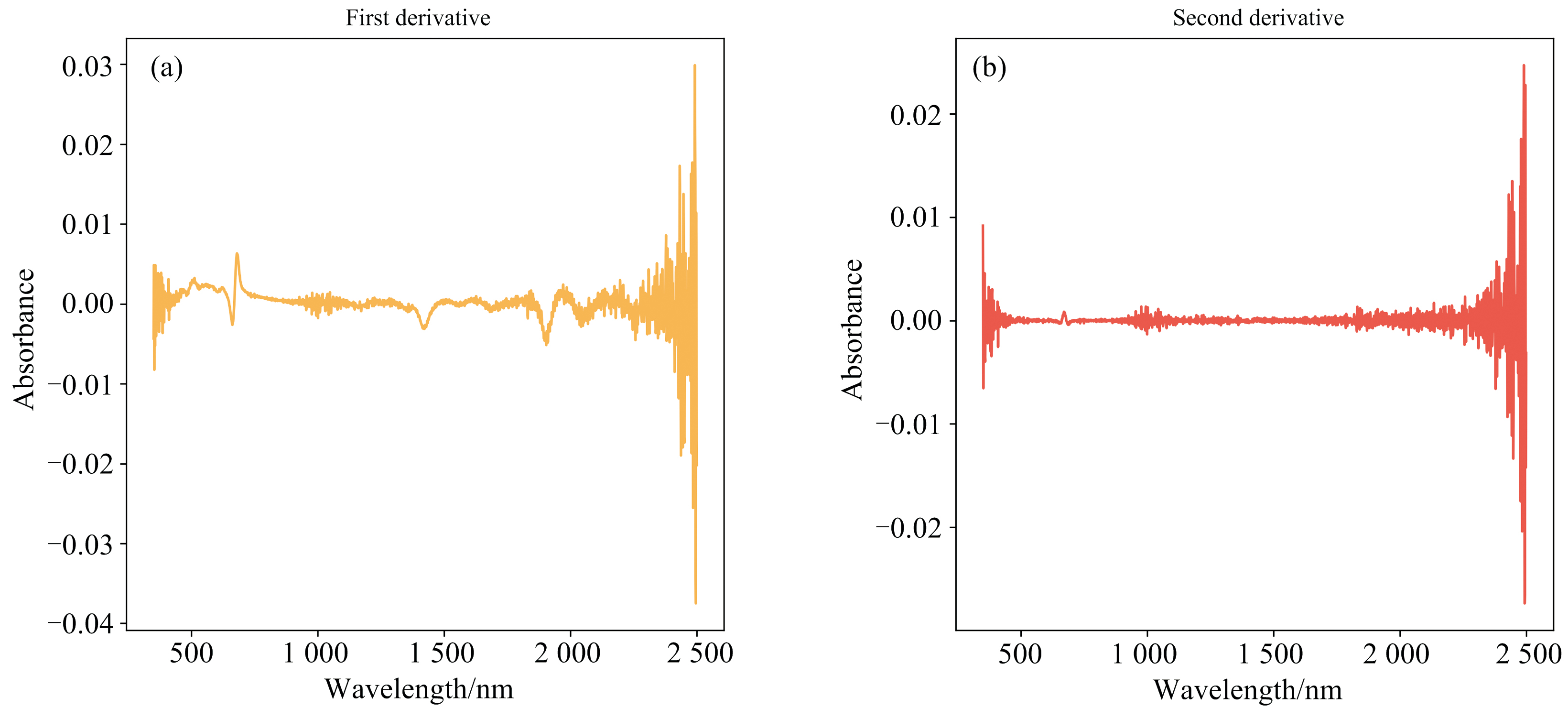 | 图2 一阶导数(a)和二阶导数(b)Fig.2 First Derivative (a) and Second Derivative (b) |
偏最小二乘法(partial least squares, PLS)降维是一种基于统计建模的降维方法, 旨在保留原始数据中关键信息的同时降低数据维度。在机器学习建模方面, 使用了六种分类模型: 支持向量分类(support vector classification, SVC)[13]、 逻辑回归(logistic regression)[14]、 决策树(decision tree)[15]、 K-近邻(K-nearest neighbors)[16]、 随机森林(random forest)[15]和梯度提升决策树(gradient boosting decision tree)[17]。所使用的六种机器学习算法及介绍列于表1。
| 表1 机器学习算法及简介 Table 1 Machine learning algorithms and introduction |
评价参数指标: 分类准确率, 精准率, F1分数和混淆矩阵。分类准确率是用于评估分类模型性能的指标, 表示模型在测试数据集上正确分类的样本比例。其计算公式如式(1)
式(1)中, “ 正确分类的样本数” 指模型在测试数据集上正确预测的样本数量, “ 总样本数” 是测试数据集中的总样本数量。分类准确率的取值范围在0%到100%之间, 数值越接近100%表示模型的分类性能越好, 数值越接近0%则表示模型的分类性能较差。精确度衡量模型在预测为正例的样本中, 真正为正例的比例, 即预测为正例且确实为正例的样本数占所有预测为正例的样本数的比例。召回率衡量模型在所有实际为正例的样本中, 能够正确预测为正例的比例, 即预测为正例且确实为正例的样本数占所有实际为正例的样本数的比例。F1分数是精确度和召回率的调和平均值, 综合考虑了精确度和召回率, 为评估分类模型性能提供了单一指标。F1分数越高, 表示模型在精确度和召回率之间取得了更好的平衡。混淆矩阵(confusion matrix)是用于评估分类模型性能的工具, 是一个二维矩阵, “ 行” 表示实际类别, “ 列” 表示预测类别, 每个单元格中的值表示对应实际类别和预测类别的样本数量。在模型评估过程中, 混淆矩阵有助于了解模型在不同类别上的分类情况, 从而更好地理解模型的优缺点, 并进行针对性的改进[18]。验证方法采用5折交叉验证和测试集。5折交叉验证是一种常用的交叉验证方法, 用于评估机器学习模型的性能。在5折交叉验证中, 首先将数据集均匀分成5个子集, 其中4个子集作为训练集, 1个子集作为验证集。使用这4个训练集对模型进行训练, 并在相应的验证集上进行性能评估。这个过程重复5次, 每次使用不同的验证集。最终将5次验证结果进行平均, 得到模型的性能评估指标[19]。
在参数调优中, 采用网格搜索方法。首先确定参数的可能取值范围, 然后创建参数网格, 对每个参数组合采用交叉验证进行评估, 最后选择性能最佳的参数组合作为最终模型的参数。网格搜索的优点在于简单易用且能找到全局最优解[20]。
总样本数为293条, 部位数据集共有3个类别。为了便于后续处理, 将目标值转换为数字形式, 如表2数据集信息。重新构建数据集后, 按照4∶ 1随机将数据集划分为训练集和测试集, 其中训练集包含234条数据, 测试集包含59条数据。为了筛选最优方法, 对数据集进行5种不同预处理方式的对比: 原始数据、 一阶导、 一阶导结合S-G平滑、 二阶导、 二阶导结合S-G平滑。原始光谱数据中光谱范围为350~2 500共2 150维数据, 采用PLS降维方式, 将5种不同处理方式的谱图降维至2~24维, 每种预处理方式下共23种维度组合。
| 表2 数据集信息 Table 2 Information of the dataset |
将降维后的数据用六种机器学习分类算法进行训练和评估, 由23× 6× 5=690(23个维度, 6种机器学习模型, 5种预处理方式)种组合中选择出训测试集准确率最高的分类模型。
2.2.1 直接建模
图3为PLS降维后和六种机器学习模型的建模结果。在图中可以观察到, 在原始数据集上直接进行降维后建模, 相对于其他模型, 树模型(如决策树、 随机森林和梯度提升决策树)在训练集上的结果几乎均为100%, 说明树模型的拟合能力较强, 但也容易出现过拟合情况。相比于树模型, 其他模型在训练集和测试集上则体现出先升高而后逐渐趋于稳定的状态, 说明维度过低会使得原始数据丧失过多的有用信息。各模型在维度为约15后趋于稳定, 说明降维后的有用信息主要集中在前15个维度, 更多维度的增加并不会带来模型性能上的提升反而可能因为冗余信息的增加使得模型性能下降。
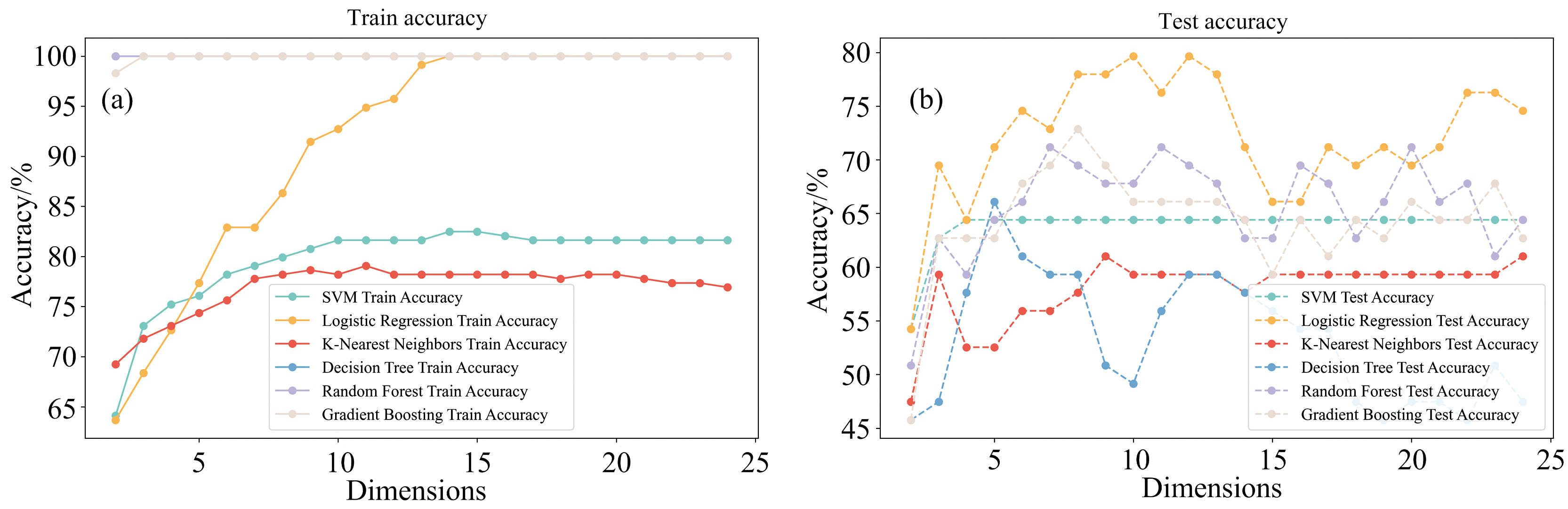 | 图3 六种机器学习模型直接建模训练集(a)、 测试集(b)准确率变化趋势 SVM: 支持向量分类; Logistic Regression: 逻辑回归; Decision Tree: 决策树; K-Nearest Neighbors: K-近邻; Random Forest: 随机森林; Gradient Boosting Decision Tree: 梯度提升决策树, 下同Fig.3 The trend of accuracy changes for six machine learning models trained and tested directly on the training set (a) and testing set (b) |
2.2.2 求导后建模
图4为对原始数据集进行一阶导数处理后的建模结果。相较于未进行一阶导处理的数据集, 所有模型在测试集上的准确率均有所提升。测试集准确率总体上提高了约10%。当数据维度降至23维时, 随机森林模型的准确率提升至84.7%。这表明, 一阶导数处理能够增强原始数据中的某些信息, 使得模型能够更好地捕捉数据的规律, 从而提高了预测性能。图5(a, b)为原始数据集在二阶导数后的建模情况, 虽然数据在训练集的准确率有所提升, 但是相对没有导数处理的数据, 二阶导数处理后的数据在测试集上的准确率普遍有所下降, 整体下降约20%。说明虽然二阶导在增强数据信息的同时, 也为数据带来了很多噪声的干扰, 导致模型的泛化能力下降。
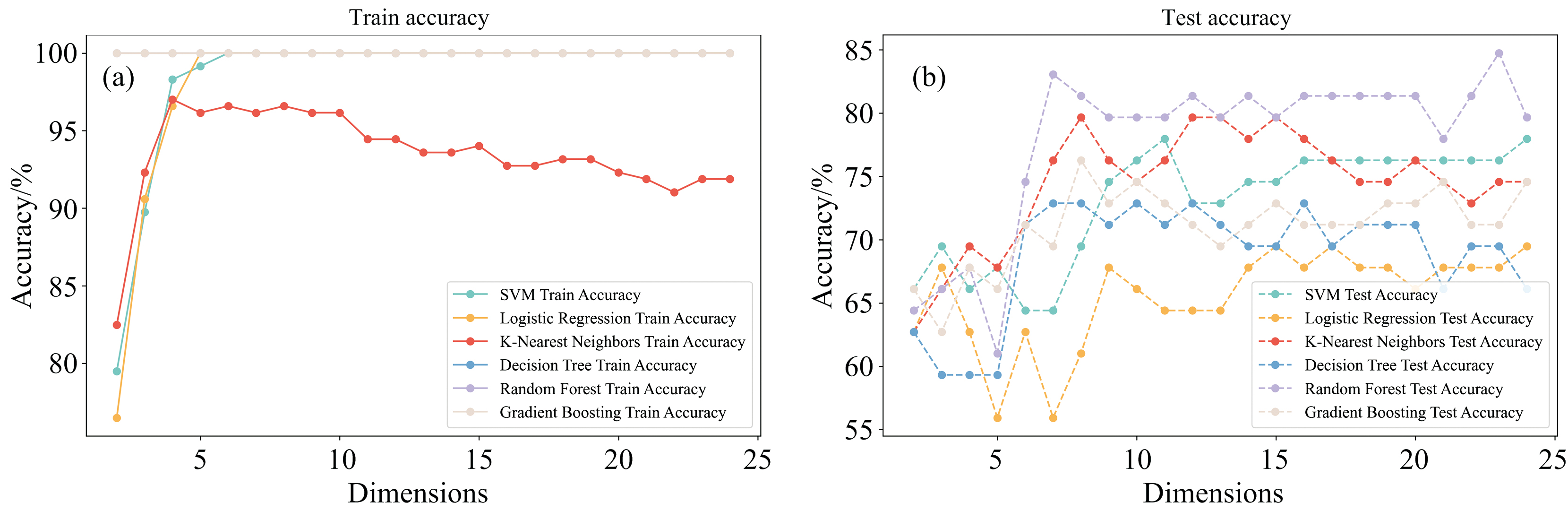 | 图4 六种机器学习模型一阶导数训练集(a)、 测试集(b)准确率变化趋势Fig.4 The first derivative modeling of accuracy changes for six machine learning models trained and tested directly on the training set (a) and testing set (b) |
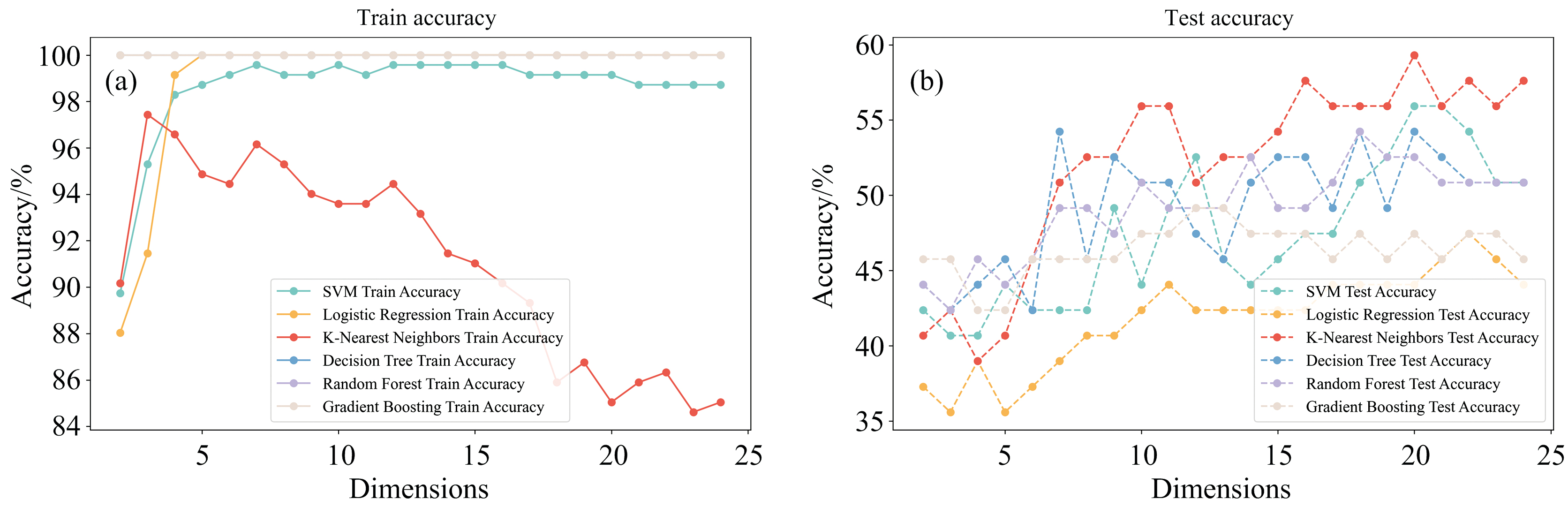 | 图5 六种机器学习模型二阶导数训练集(a)、 测试集(b)准确率变化趋势Fig.5 Modeling the second derivative of accuracy changes for six machine learning models trained and tested directly on the training set (a) and testing set (b) |
当在原始数据集进行一阶导数处理时, 可能会改变数据的特征表示, 有时会提高模型性能。这种改变可能会突出数据中的某些重要特征或减少不必要的噪声, 从而使模型更好地捕捉数据中的模式, 提高预测性能。当进行二阶导数处理时, 可能会引入更多的噪声或不必要的变化, 从而降低模型的性能, 并且会进一步放大数据中的细微变化, 可能会引入过多的细节, 导致模型过度拟合训练数据, 从而在测试数据上表现不佳。二阶导数处理还可能导致数据中出现异常值, 这些异常值可能会干扰模型的学习过程, 并导致性能下降。二阶导数可能会导致数据的特征表示过于复杂, 使模型难以泛化到新数据, 从而影响了模型的性能。因此, 尽管一阶导数处理有助于改善模型性能, 但二阶导数处理可能会产生副作用, 导致模型性能下降。
2.2.3 导数结合平滑预处理后模型
图6(a, b), 图7(a, b)分别展示了对原始数据进行一阶导结合S-G平滑处理、 二阶导数结合S-G平滑处理后的建模结果, 在尝试S-G平滑不同参数组合后, 平滑窗口大小设置为7多项式参数设置为2的平滑效果最佳。对比一阶导函数处理但未平滑的数据集在训练集上的表现, 如图4(a, b), 可见K-近邻在训练集上的准确率更加平稳, 平滑后测试集上模型准确率呈现出逐渐升高的趋势, 表明平滑后的数据集在一定程度上缓解了模型的过拟合现象, 并且可以推测随着维度的继续增加模型的测试集准确率会有继续提升的趋势。从各模型总体上看一阶导平滑后的数据集相较于未平滑的一阶导数据集并没有很大的提升, 测试集上最佳正确率不及未平滑的数据集。对比图5(a, b)可以看出, 平滑后的二阶导数数据集训练集整体准确率有所提升, 测试集相较于未平滑的二阶导数据集有了小幅度的升高。说明S-G平滑过滤了数据集中的部分噪声, 但因为二阶导数处理后数据集信息丧失了过多的有用信息, 因此模型性能并不会有本质上的提升, 测试集准确率依然小于60%。
 | 图6 六种机器学习模型一阶导平滑后训练集(a)、 测试集(b)的准确率Fig.6 Smoothed first-order derivatives of accuracy for six machine learning models on training set (a) and testing set (b) |
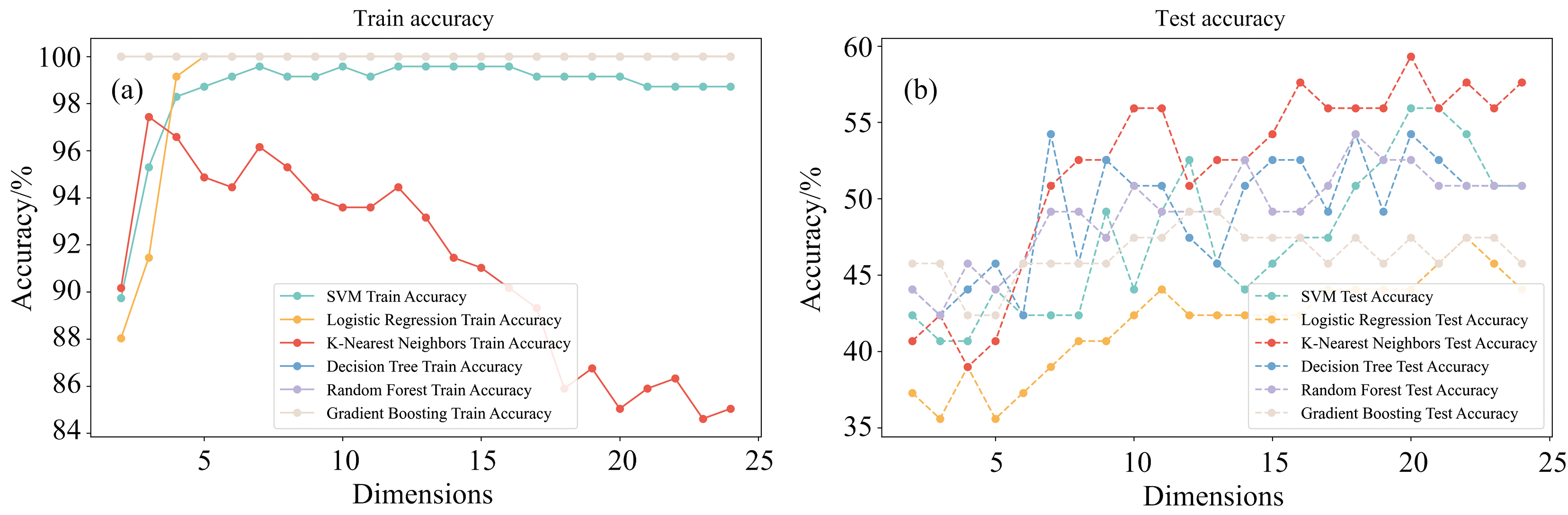 | 图7 六种机器学习模型二阶导平滑后训练集(a)、 测试集(b)的准确率Fig.7 The accuracy of training set (a) and testing set (b) after smoothing the second-order derivatives for six machine learning models |
表3为不同情况下的最佳训练和测试准确率结果。相对于原始数据直接建模, 一阶导数处理后的数据集模型性能有较为明显的提升。S-G平滑后可以使得某些模型上的效果得到小幅度的提升, 但提升主要相对于未平滑前数据集的基本情况。对比五种数据集上的准确率结果, 一阶导数处理后的数据在23维的情况下随机森林模型具有最佳的测试集准确率, 测试集准确率为84.7%, 五折交叉准确率为86%。
| 表3 茄科植物部位分类各数据集对应的最优情况 Table 3 Optimal scenarios for classification of parts of Solanaceae plants for each dataset |
采用网格搜索方法对随机森林模型进行参数优化。“ 决策树个数” 参数影响森林中树的数量, 其选择直接影响到模型的复杂度和泛化能力。较多的树可能提高模型的准确性, 但也增加了计算成本。“ 决策树个数” 尝试了从100到250(包括250), 步长为10。测试的决策树个数分别是: 100、 110、 120、 130、 140、 150、 160、 170、 180、 190、 200、 210、 220、 230、 240和250。“ 最大深度” 参数控制每棵树的最大深度, 它直接影响到模型的复杂度。较深的树能够捕获更多的数据细节, 但也容易导致过拟合。测试了None、 2、 4和6这几个取值。“ 最小样本分裂数” 参数设置了成为叶节点所需的最小样本数, 其影响到叶节点的数量和深度。增加这个值可以使模型更加平滑, 减少过拟合。考察了2、 3、 4和5这几个选项。“ 最小叶节点样本数” 参数设置了成为叶节点所需的最小样本数, 尝试了1、 2和3这三个值。以训练集五折交叉验证的准确率作为评价标准。经过参数优化后, 选择出最佳参数组合为: 最大深度=None、 最小样本分裂数=4、 树的数量=200, 其余参数保持默认设置。经过参数优化后, 五折交叉验证准确率提升至为88.1%, 训练集准确率为100%, 测试集准确率提升至为86.4%, 精确度为88.2%, 召回率为86.4%, F1分数为86.2%。
为验证最佳模型的稳定性, 对包含23个特征的一阶导数数据集进行了100次随机划分。每次划分后, 采用优化后的随机森林模型进行训练。经过100次随机划分, 训练集准确率的平均值为100%, 测试集的平均准确率为85.8%, 平均精确度为85.8%, 平均召回率为84.8%, 平均F1分数为84.2%。表明所提出的模型在不同的数据子集上具有稳健的性能, 展现出良好的泛化能力。
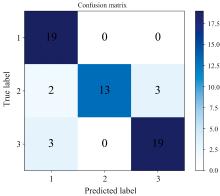
图8为最佳模型在测试集上的分类混淆矩阵。在混淆矩阵中, 纵坐标代表真实标签, 横坐标代表预测标签。在所有类别中, 中部样本的数量最少, 但预测错误的次数却最多。在本研究中, 下部、 中部和上部样本分别对应茄科植物生长状态下的相邻部位, 即下部与中部相邻, 中部与下部和上部相邻, 上部与中部相邻。在实际采集分类状态下, 对相邻部位的分类存在一定的人为主观性。此外相邻叶片的化学成分差别较小, 因此它们往往更难以分类。这导致了对于中部样本, 部分被错误地归类为下部, 而另一部分则被错误地归类为上部的情况。后续研究可以考虑增加中部样本的数量以提升模型的整体性能。
 | 图8 随机森林测试集混淆矩阵Fig.8 Confusion matrix of the Random Forest model on the test set |
通过应用高光谱技术和机器学习方法, 对初烤后茄科植物的不同部位叶片进行了分类研究。通过预处理方法(如Savitzky-Golay平滑和导数处理)和偏最小二乘法进行降维, 从高光谱数据中提取了关键特征并减少了冗余信息和噪声的影响。在分类任务中, 随机森林模型处理了一阶导数后的23维数据, 该模型五折交叉验证准确率为88.1%, 训练准确率为100%, 测试集准确率为86.4%。结果表明, 高光谱技术结合机器学习模型在茄科植物部位分类中具有高的分类准确率和可行性。预处理方法的改进和分类模型的优化还可以进一步提高分类准确率, 并增强模型的鲁棒性和泛化能力。未来的研究方向可以包括扩大样本数量和数据集的范围, 增加更多茄科植物部位的数据, 以更全面地了解茄科植物的特征和变化规律。可以进一步探索其他的预处理方法和机器学习模型, 以寻求更好的特征提取和分类效果。同时, 结合实际应用需求, 将高光谱技术与其他传感器和数据源相结合, 开展更深入的研究和应用。本研究的成果为茄科植物行业的质量控制和市场监管提供了准确、 快速、 无损的工具和方法, 对于优化茄科植物生产和推动行业发展具有重要意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|