






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于KNN-SVM的混合气体检测方法研究
[孙超1  , 胡润泽
, 胡润泽1 , 吴中旭2 , 刘年松2 , 丁建军1, * ]
, 胡润泽, 吴中旭]
|
|


作者简介: 孙 超, 1984年生, 江汉大学智能制造学院副教授 e-mail: sycsc115@163.com
胡润泽, 2000年生, 江汉大学智能制造学院硕士研究生 e-mail: hrz453128789@163.com
孙 超, 胡润泽: 并列第一作者
当今混合气体检测的研究中, 针对多组分气体数据进行分类预测的数学算法百花齐放, 如何快速且准确的检测出气体的成分和浓度逐渐成为当今研究的热门。然而在一些研究中, 气体数据特征难以捕捉和判断, 泛化能力不足, 对气体数据进行分类预测的精度和效率表现较差。为此, 针对一些数据偏差和泛化误差无界的问题, 提出了一种K最近邻-支持向量机(KNN-SVM)算法, 对一些难以作出分类的模糊气体数据进行二次分类, 采用KNN和SVM两种算法共同抉择, 更加全面的捕捉数据特征, 根据实验确定各自算法的权重比从而提高判别气体类别的准确率, 两种算法的集成也能提高算法的效率, 对于不同种类的气体也能有良好的适应性的稳定性。该实验气体组分由12 mg·L-1的C2H2、 NO2、 SF6, 10 mg·L-1的NO2、 SF6和5 mg·L-1的C2H2(背景气体皆为N2)以及两瓶纯N2的气瓶组成; 通过互相混合和与N2配比制备出实验设定的气体浓度。实验过程通过单一气体的检测可分别对三种气体获得60组训练集, 并通过这60组数据可进行线性拟合得到每种气体的拟合线, 得到气体浓度与气体吸收峰值的关系, 通过实验检测得到的三种气体拟合线, 其中C2H2拟合线的调整后 R2为0.991, NO2拟合线的调整后 R2为0.981, SF6拟合线的调整后 R2为0.987, 可得气体检测的准确性。再通过互相混合进行检测可分别获得40组训练集, 采用KNN-SVM算法对混合气体进行分类和预测, 后通过拟合线即可反演出混合气体中每种气体的浓度。将该算法与传统SVM算法进行各种分类指标对比均可显示出该算法的有效性和优越性。实验结果表明, KNN-SVM算法在气体分类预测方面表现出卓越的性能, 准确率高达99.167%, AUC(area under curve)值达99.375%。这一算法不仅提高了气体检测的准确性, 还增强了泛化能力可适应多样化的气体组分, 为实时气体检测系统提供了有力支持。
SUN Chao and HU Run-ze: joint first authors
In the current research on mixed gas detection, various mathematical algorithms for classifying and predicting data of multiple gas components have emerged. Rapid and accurate gas composition and concentration detection has gradually become a hot topic. However, in some studies, the features of gas data are difficult to capture and judge, and the classification and prediction of gas data exhibit poor accuracy and efficiency due to data bias and unbounded generalization errors. In response to challenges like data bias and unbounded generalization errors, this paper proposes a KNN-SVM algorithm. This algorithm performs secondary classification on ambiguous gas data that is challenging to classify. It combines K-nearest neighbors and Support Vector Machine algorithms to make more comprehensive data feature assessments. The algorithm determines the weights of each algorithm based on experiments, thereby improving the accuracy of discriminating gas categories. The integration of the two algorithms also enhances the efficiency of the overall algorithm, providing stable adaptability to different types of gases. The experimental gas composition consists of cylinders containing C2H2, NO2, and SF6 at concentrations of 12 mg·L-1, NO2, SF6 at 10 mg·L-1, and C2H2 at 5 mg·L-1(all diluted with N2 as a background gas), as well as two bottles of pure N2. The experiment involves mixing these gases and adjusting their ratios to set the required gas concentrations for detection. By detecting individual gases,60 sets of training data are obtained for each of the three gases. Linear fitting of these 60 data sets yields fitted lines for each gas, establishing the relationship between gas concentration and absorption peak. The accuracy of gas detection is confirmed through the adjusted R-squared values for the fitted lines: 0.991 for C2H2,0.981 for NO2, and 0.987 for SF6. Subsequently, 40 sets of training data are obtained by detecting mixed gases. The KNN-SVM algorithm is then applied to classify and predict mixed gases, and the concentrations of each gas in the mixed gas are inferred from the fitted lines. Comparisons with traditional SVM algorithms using various classification metrics demonstrate the effectiveness and superiority of the proposed algorithm. Experimental results indicate that the KNN-SVM algorithm exhibits outstanding performance in gas classification and prediction,achieving an accuracy of 99.167% and an Area Under the Curve index of 99.375%. This algorithm enhances the accuracy of gas detection and improves generalization capabilities to adapt to diverse gas compositions,providing robust support for real-time gas detection systems.
在现代环境监测和工业安全领域, 气体检测一直是至关重要的任务, 准确、 高效地检测和识别气体成分对于维护环境质量、 确保人员安全以及优化工业生产过程至关重要[1]。传统的气体检测方法主要依赖于化学传感器或光谱仪器[2], 然而, 这些方法通常需要复杂的校准过程, 容易受到外部干扰, 并且成本较高。在这一背景下, 光声光谱气体检测技术[3]引起了广泛的兴趣和研究, 结合了激光光谱学和声波检测的优势, 为气体检测带来了全新的可能性。与传统方法相比, 光声光谱气体检测技术具有多项优势, 包括高度灵敏、 实时性、 成本较低、 无需化学试剂, 并且可以同时检测多种微量气体成分。这一技术通过麦克风或者石英音叉[4, 5]检测声波信号并分析, 能够实现对气体成分的快速和准确检测。
为了提高气体检测的精确度, 过去通常依赖于工程上的改进, 如为了增强光声信号的强度设计出高灵敏度的气体传感器、 提高光谱仪器的分辨率或者是增加多个激光器以及传感系统等实验装置[6, 7], 这些方法在一定程度上取得了成功, 但也面临一些挑战, 如高成本、 复杂的仪器维护和校准等难题。此外, 传统方法对于同时检测多种气体成分的能力相对有限, 在一定的硬件条件下难以作出更好的改进。
然而, 随着数学方法和计算能力的不断提升, 现今的气体检测领域正在经历一场革命。借助计算机科学和数据分析技术的进步, 研究人员能够利用复杂的算法和数学模型来处理和分析气体检测数据, 从而实现更高级别的气体分类和识别。以下是一些引领这一领域发展的数学方法和算法: 马欲飞[8]等借助于无需数据预处理即可处理原始输入数据并自动提取所需特征的特性, 引入了强大的SNN拟合算法对传感器进行去噪处理。通过检测不同气体样本, 基于LITES的H2传感趋对H2浓度水平展现出了优秀的线性响应, 其最低检测限约为80 ppm。杜鸿飞[9]等通过使用遗传算法对BP神经网络的初始权重和阈值进行全局优化, 成功地应对了由NO2和NH3组成的混合气体的识别和预测。在他们优化后的GA-BP网络算法中, 混合气体的定性识别准确率达到了100%, 而在最差情况下, 定量预测的误差也不超过30%。钱新明[10]等提出了一种基于最小二乘法支持向量机(LS-SVM)的可燃气体分类预测模型, 使用多项式核函数和径向基核函数构建不同的分类模型。研究结果表明, 两种分类器的准确度相差不大。其中, 采用径向基核函数的分类模型达到了81%的测试准确度。这项研究表明, 最小二乘法支持向量机在可燃气体监测分类方面具有潜在的应用价值, 有助于提高燃气监测运维的准确性和效率。李鹏[11]等提出了一种新的气体泄漏故障诊断方法, 将鲸鱼算法与变分模态分解(WOA-VMD)和SVM相结合。这一方法能够自适应获取最优参数组, 具有抗模态混叠和抗噪声干扰的明显优点。通过优化后的VMD方法和其他时、 频域分析技术对压力容器气体泄漏声波信号进行特征提取, 然后选取最佳特征组合输入支持向量机进行判别, 结果显示泄漏与否的准确率高达99.18%。这一方法有望在后续的泄漏源定位和实时监测系统开发中发挥重要作用。段小丽[12]等提出了一种改进型PSO-SVM算法, 用于解决CH4、 C2H6、 C3H8、 SO2和CO2这五种不同浓度范围的混合气体的光谱特征信息相互重叠的问题, 并采用了一种粒子变异约束的PSO算法, 优化模型的收敛路径。他们还通过粒子信息共享来提高模型的优化效率, 并引入了动态不敏感区, 相比传统的BP网络优化算法, 这种改进算法不仅速度更快, 而且模型的预测精度更高, 大大提高了建模的效率。杨朝[13]等提出了一种PCA-SVM模型, 用于分类不同浓度的CO、 CH4、 H2S以及C2H6O混合气体。通过对随机选择的气体数据集进行测试, 发现PCA-SVM模型在分类性能上表现出显著优势。特别是在包含13个特征的气体数据集中, PCA-SVM模型的准确度达到了98.974%。而在包含27个特征的数据集中, 准确度甚至达到了100%。这意味着PCA-SVM模型能够满足混合气体分类的实际需求, 提高了分类性能。Xia等[14]结合了PCA和KNN算法识别混合气体成分, 利用PCA提取气体的特征值, 使用KNN实现气体类型的识别。实验结果显示, 在降维后的特征空间中进行气体识别的准确率明显高于未降维前的情况, 此外, 他们还将所提出的方法与PCA和SVM算法进行了比较, 发现新方法对混合气体成分的识别准确率达到了96.88%。
尽管这些方法在提高气体检测的分类性能和准确度方面取得了显著的进展, 但仍存在一些不足之处。其中包括: 研究中可能需要更多的实验数据和更广泛的样本覆盖, 以确保算法在不同条件下的稳健性和适用性。某些方法可能需要更多的计算资源和时间来运行, 因此需要进一步优化以提高效率, 特别是在实时检测系统中的应用。因此本文提出一种K最近邻-支持向量机(K nearest neighbors-support vector machine, KNN-SVM)算法进行混合气体的定性分类, 相比于传统SVM算法, 此集成算法弥补各自算法的不足, 更全面地捕捉数据的特征, 可以进一步提高分类和识别的准确性, 具有较强的泛化能力, 可以适应不同混合气体和多样化的气体组分, 在实际应用中通常能够快速进行分类和识别, 这对于实时气体检测和监测系统非常重要。最后实验数据表明KNN-SVM集成算法可以有效地综合KNN和SVM的优势, 提高气体检测的准确性、 泛化能力和鲁棒性, 同时适应不同数据特性和应用场景, 为气体检测领域带来了更多的可能性。
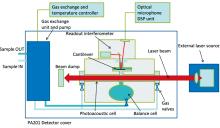
为了实现混合气体的定性定量分析, 需搭建一套完整的气体检测系统, 主要由光源、 光声池、 光声信号检测以及配气系统组成, 其中光源采用红外激光器并配带有相应的滤光片。光声池采用PA201光声气体探测器模块, 红外激光器射出周期型光束进入到PA201光声池内发生光声效应, 配气系统由12 mg· L-1 C2H2、 NO2、 SF6, 10 mg· L-1 NO2、 SF6和5 mg· L-1 C2H2(背景气皆为N2)以及两瓶纯N2的气瓶和三个气阀组成, 通过互相混合配比得到实验所需检测的气体浓度, 最后由光声信号处理模块检测由光声效应产生的声信号。
PA201光声检测器是专为测量痕量气体而设计的一种设备, 如图1所示。当气体通过光声池时, 吸收激光能量, 但此时气体分子并不稳定, 会在极短的时间内从激发态通过非辐射跃迁返回基态并释放能量, 增加分子的动能, 宏观上表现为温度升高, 气体压力变大; 而当激光光源经过特定频率的调制后, 气体压力的这种变化也会呈现一定的周期性进而产生气体压力波也就是声波, 这个声波被光声池内麦克风等声传感器检测采集, 通过光声信号检测模块转化成直观的气体光声信号幅值。光声光谱气体检测系统如图2所示。
 | 图1 PA201光声检测器Fig.1 PA201 photoacoustic detector |
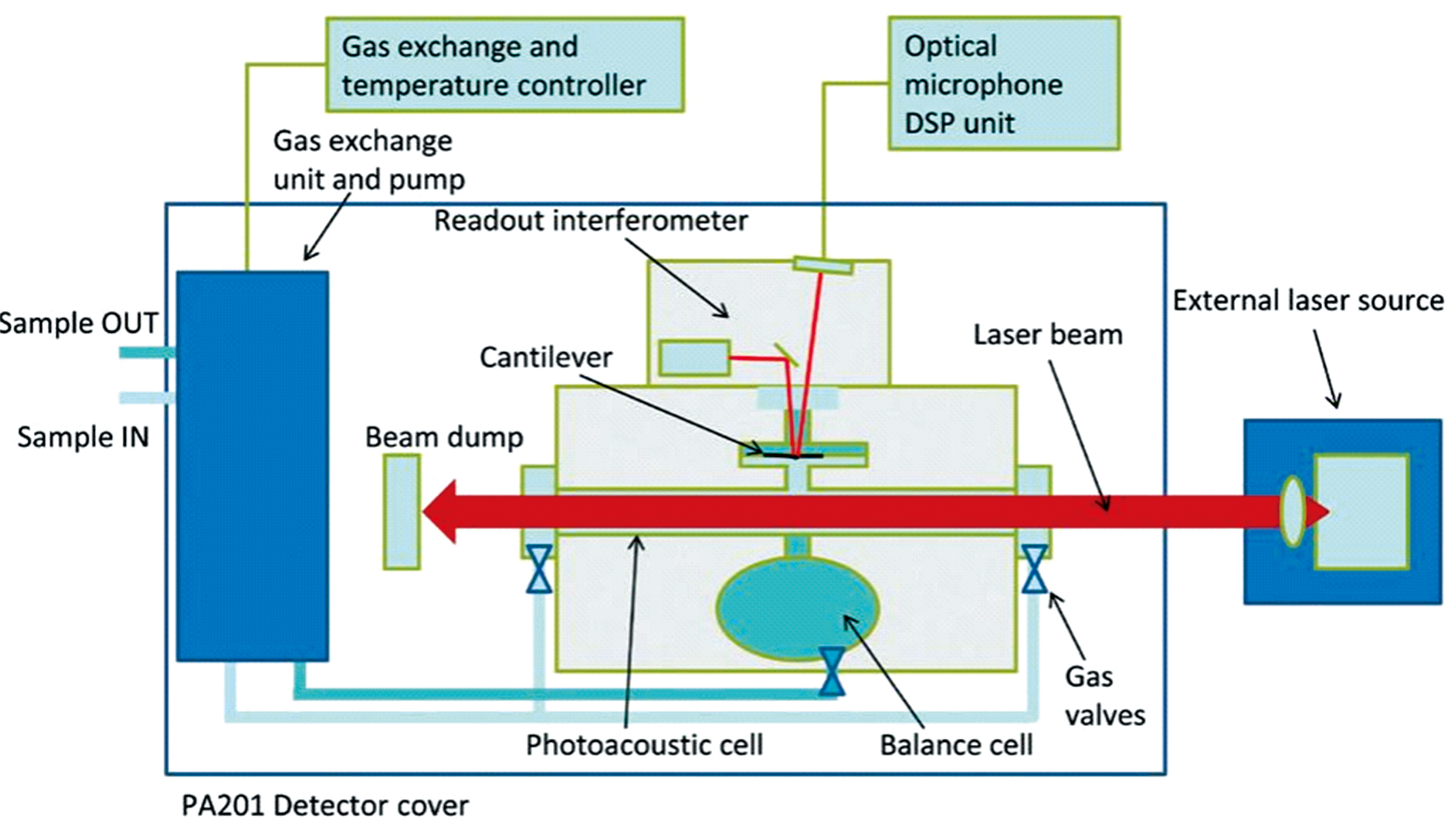 | 图2 光声光谱检测系统示意图Fig.2 Schematic diagram of photoacoustic spectroscopy detection system |
在光声池中的信号, 通常采用正弦波进行调制。而压力波悬臂式压力传感器检测, 由于周围气体压力的变化, 一个薄的悬臂来回移动, 微型镀金硅悬臂就像光声电池和更大的平衡电池之间的一扇门, 利用紧凑的激光干涉仪测量了悬臂梁的压力波弯曲和其自由端的位移, 通过悬臂梁的这微小振动来实现信号的检测, 如图3所示。
 | 图3 悬臂式压力传感器Fig.3 Cantilever pressure sensor |
系统利用悬臂梁的共振特性, 使其特定的自然频率, 与光声波的频率相匹配。当悬臂梁受到共振激励时, 其振动幅度显著增强, 从而使压力变化更为显著。这种结合光声池和悬臂梁式压力传感器的系统可在痕量气体测量中发挥作用, 实现对待测气体中痕量成分浓度的高效、 准确测量。悬臂梁的尺寸为: 厚度10 μ m, 宽1.2 mm, 长度5 mm, 悬臂与框架之间的间隙小于5 μ m。PA201光声池具有流动约束功能, 这一设计限制了通过PA单元的流量, 以保护敏感的悬臂梁结构不受损坏。
测量结果经过实时数字信号处理(DSP)单元处理, 该单元会生成与悬臂运动成比例的模拟和数字输出信号。模拟信号可以通过BNC输出连接器进行连接, 而数字信号则通过USB接口传输。最后通过LabView软件进行光声信号的采集。示例为测量前采用CO2气体进行光源校准以及系统标定时各种可采集信号示意图: 图4(a)为CO2的频谱图; (b)为CO2的光声信号幅值图; (c)为一定频率下的光声信号趋势图, 在LabVIEW可根据需求测量特定频率下的振幅, 并且可在任意时刻调整频率, 图中1~22 s为37.7 Hz, 23~42 s为14.6 Hz, 43~62 s为86.4 Hz。
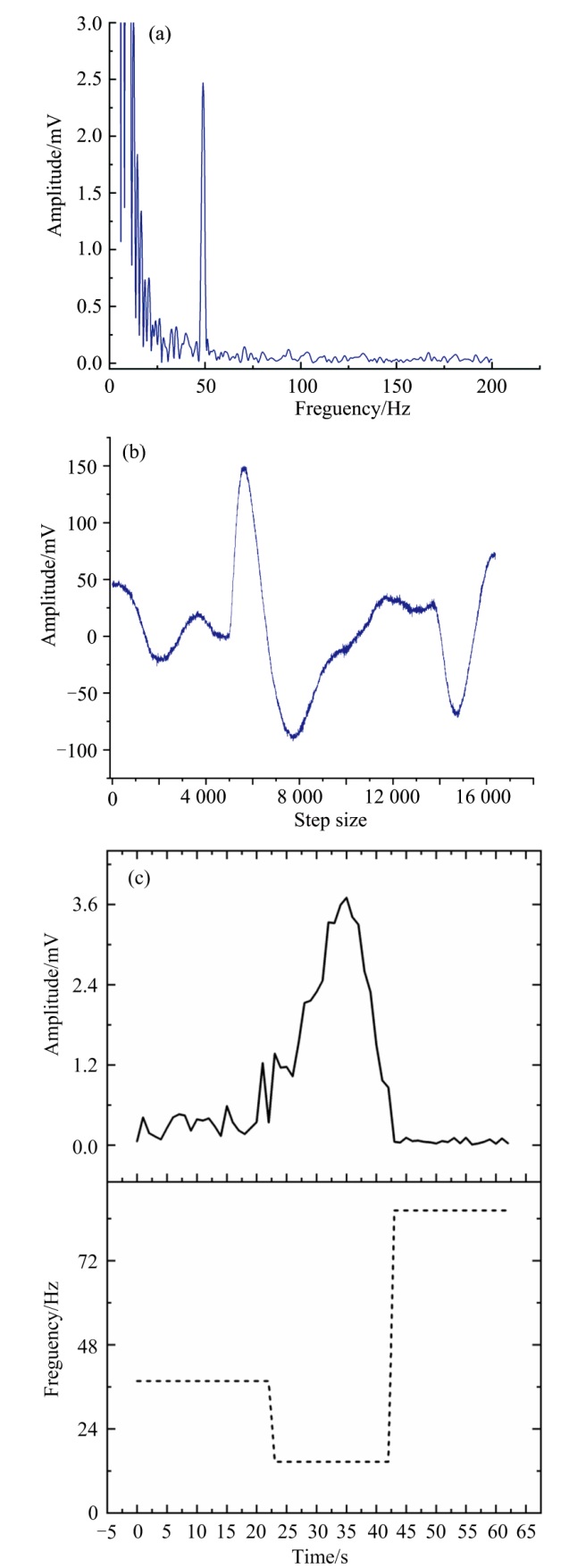 | 图4 (a) CO2频谱图; (b) CO2光声信号幅值图; (c) CO2一定频率下对应振幅图Fig.4 (a) Spectrum of CO2; (b) Photoacoustic signal amplitude of CO2; (c) Amplitude diagram of CO2 at a specific frequency |
SVM简单来说是就是支持或支撑平面上把两类类别划分开来的超平面的向量点[15], 用于解决分类、 回归和多分类等问题。其基本原理是在数据点之间找到一个最优的决策边界, 以将不同类别的数据分开, 并确保这个边界距离最近的数据点(支持向量)的距离最大化。其关键思想是通过最小化结构化风险来提高学习机的泛化能力。它在经验风险和置信范围之间取得平衡, 以确保在统计样本量较少的情况下仍能获得良好的统计规律, 这种方法能有效地将数据分隔开, 因此采用SVM方法处理气体分类问题。
SVM最初是一个二分类模型, 假设数据集为(xi, yi), 输入数据为xi, i=1, 2, …, n, 是一个n维向量, 而输出数据为yi, 且yi∈ [-1, 1], 表示的是两个不同的类别, 则需要在n维的数据空间中找到一个超平面, 则有式(1)
式(1)中, ω 为法向量, b为截距, x是数据点的特征向量。
对于一个数据点x, 令其垂直投影到超平面上的对应的为x0, 由于ω 是垂直于超平面的一个向量, γ 为数据点x到分类间隔的距离, 则有
又因f(x0)=0, 将式(1)代入得
为了求间隔则只需求其绝对值, 则有
而SVM的目标是找到一个最大间隔超平面来设计决策最优分类超平面, 也就是求max
式(5)中, C为惩罚因子, ξ 为松弛因子。
为了解决这个优化问题, 通常使用对偶问题, 引入拉格朗日乘子α i来构建拉格朗日函数
式(6)中, n为数据点的数量。
通过求拉格朗日函数的鞍点, 分别对ω 和b求偏导代入式(6), 则可将原问题转化为最优对偶问题
式(7)中, < xi, xj> 为非线性映射的内积核函数。
通过求解α 及能导出ω 和b的解从而求出分离超平面和分类决策函数。
在混合气体多样性的多分类任务中, SVM分类器支持两种类型的分类方法: 一对一和一对多。这两种方法在处理多类别问题时都存在一些问题, 如数据偏差和泛化误差无界, 而KNN算法是一种基于相似的数据点往往在数据空间中彼此靠近的分类方法, 这有助于识别数据特征和进行数据预处理, 从而可以改善SVM对数据的处理能力, 对判断数据的类别带来优势。因此, 提出了一种新的KNN-SVM方法, 即根据待测数据点到超平面的距离来进行判定, 如果一个数据点距离超平面足够远, 说明它明显地属于某个类别, 可以直接判定为该类别; 如果距离较近但没有足够明显的归属, 可以将其判定为模糊数据。对于确定在SVM区域内的数据, 可以直接使用SVM进行分类, 而对于模糊数据, 使用KNN和SVM共同投票进行二次分类。这个方法可以通过计算待测数据点到超平面的距离与最大间隔比值的大小来确定数据的模糊性。
KNN算法计算待分类数据和所有训练数据的距离可以表示为
式(9)中, xi为输入数据, xj为训练数据。
根据距离与数据点之间的相似性特性, 我们可以将距离转化为一种权重ω i, 这个权重表示了输入数据与训练数据之间的关联程度。通过计算每个类别的权重并将其标准化, 可以将这些权重视为各个类别的生成概率, 距离越近的训练数据对于确定输入数据的类别具有更高的影响力。
假设目标是二分类{-1, 1}, 则表达式
若P1≥ P-1, 则分类结果为1类。
一直重复分类过程, 则可得到回归值
式(11)中, y为输出结果, f(xi)为最近邻数据的值。
在对模糊数据进行类别判定时, 使用KNN和SVM共同投票分进行二次分类, 其中SVM的判决函数表示为
式(12)中, K(zi, z)为核函数。
KNN算法中的分类规则表示为
式(13)中, C代表类别。
双投票机制结合了KNN和SVM的结果, 以提高分类的准确性。在这种机制下, 两个分类器分别对样本进行分类, 然后根据权重将它们的结果结合在一起。
针对不同的实验数据可选择不同的权重比来提高此算法的准确性, 这种方法充分考虑了数据的模糊性, 避免了因为条件过于严格导致的误判问题。双投票机制充分利用了KNN和SVM的优势, 能够在多分类问题中提高分类性能。根据问题和数据特征的特点, 调整权重以达到最佳结果。
数据来自上述光声光谱气体检测系统, 为了对混合气体进行定量定性分析, 首先, 分别对C2H2(12和5 mg· L-1)、 NO2(12和10 mg· L-1)、 SF6(12和10 mg· L-1)三种气体进行不同浓度检测, 与氮气进行1∶ 1和1∶ 2配比后, 即可得到三种气体的六组不同浓度并进行检测, 每种气体每组浓度分别检测10组, 得到60组数据; 其次, 将12 mg· L-1的C2H2、 NO2、 SF6三种气体两两混合进行检测并与氮气1∶ 1∶ 1进行检测, 每种气体每组浓度分别检测10组, 即可分别得到40组数据; 将12 mg· L-1的C2H2、 NO2、 SF6三种气体直接混合检测, 每种气体检测10组即可得到30组数据作为验证数据, 最后将采集到的数据集综合, 以6∶ 4的概率随机分成训练集和测试集。以上每次检测均提取所采集的光声信号幅值线中的吸收峰值和波长作为所检测气体特征, 用于判断气体的种类, 并且在同一环境下进行检测实验。
在每单种气体的检测中, 因检测6种不同的浓度气体幅值变化, 则可对这6种已知浓度的吸收峰作出线性拟合, 从而在混合气体检测中反演出气体的浓度。每种浓度检测10组, 以10组吸收峰值的平均值作为所需特征值, 具体数据见表1, 并将以上采集的数据进行线性拟合, 可得三种气体的拟合线如图5、 图6和图7所示。
| 表1 单一气体浓度检测 Table 1 Single gas concentration detection |
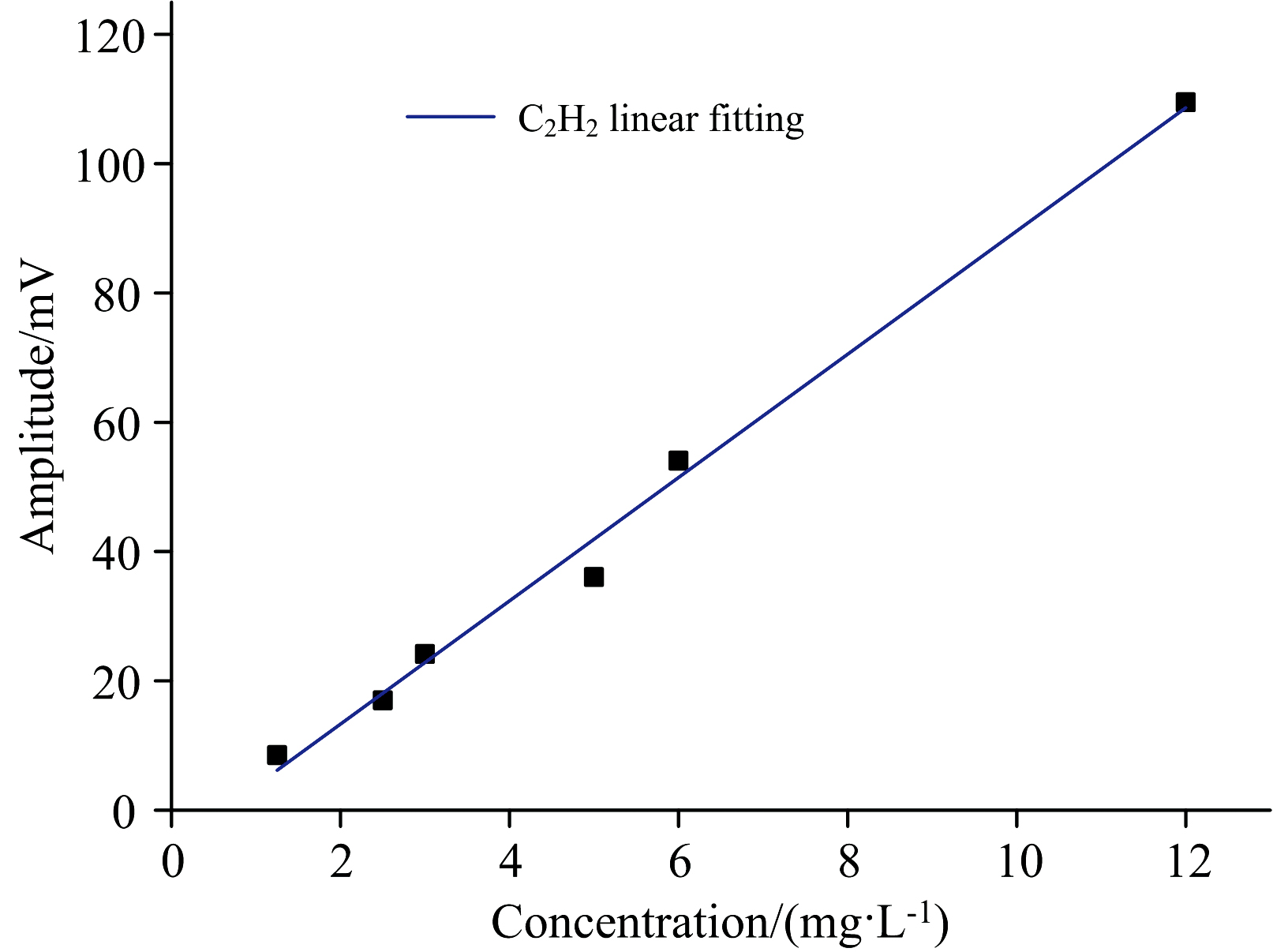 | 图5 C2H2的线性拟合Fig.5 Linear fitting of C2H2 |
 | 图6 NO2的线性拟合Fig.6 Linear fitting of NO2 |
 | 图7 SF6的线性拟合Fig.7 Linear fitting of SF6 |
其中, C2H2的线性拟合公式为
C2H2的线性拟合线的R2达到了0.990 77。
NO2的线性拟合公式为
NO2的线性拟合线的R2达到了0.981 15。
SF6的线性拟合公式为
SF6的线性拟合线的R2达到了0.986 64。
光声光谱气体检测技术中, 单一气体的检测精度是实现混合气体分析的基础, 单一气体的精确测量, 可以为混合气体分析提供关键的参考数据。而以上三种气体的拟合线调整后R2均在0.98以上, 可以认为该光声光谱气体检测系统的准确性足以能够根据混合气体的检测结果反演出该种气体的浓度, 完成对混合气体的定量分析。根据实验数据得到的混合气体种单一气体的浓度如表2所示。
| 表2 混合气体中单一气体的浓度 Table 2 Concentrations of individual gases in the mixed gas |
SVM的性能表现很大程度上依赖于所选的核函数以及这些核函数的相关参数。通过参数寻优, 对比不同类型的核函数的各种参数, 选择准确率最高的核函数及其参数。这种方法可以让我们从多个核函数中挑选出最适合特定问题的内核函数, 充分利用它们各自的优势, 从而提高SVM的性能。其中ROC曲线是一个图形化的评估分类器性能的工具, 横轴表示假正率(false positive rate, FPR), 纵轴表示真正率(true positive rate, TPR)。假正率是错误被分类为正类的负类样本占所有负类样本的比例, 真正率是正确被分类为正类的正类样本占所有正类样本的比例。ROC曲线通过在不同的阈值下计算FPR和TPR, 绘制出来的曲线展示了分类器在所有阈值下的性能。AUC通常指的是ROC曲线下的面积, 是评估分类模型性能的一个重要指标。AUC用于衡量分类器对于正负样本分类能力的一个综合指标, 值的范围从0到1, AUC越接近1, 分类器的性能越好。不同核函数的具体分类指标如表3所示。
| 表3 不同核函数下SVM分类性能比较 Table 3 Classification performance comparison of SVM with different Kernel Functions |
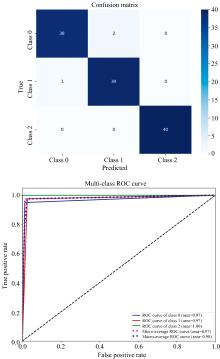
为了增强SVM对光声光谱系统采集气体特征数据的适应能力和性能, 通过param_grid函数确定参数取值范围, grid_search函数进行网格搜索, 并通过计算最高准确率来输出最优的SVM参数, 从而可寻找到适配本数据集的最佳参数如下: C=10, degree=2, gamma=‘ scale’ , kernel=‘ linear’ 。为了验证本算法的有效性和优越性, 将KNN-SVM算法与传统SVM算法对比, 对检测的混合气体进行分类预测。实验中, KNN-SVM算法和传统SVM算法都被用于同一数据集, 并且选择SVM的权重和KNN的权重比值为2∶ 1, 以提高算法判别类别的准确性, 具体参数对比结果如图8和图9所示。
 | 图8 传统SVM算法进行气体分类的混淆矩阵和ROC曲线Fig.8 Confusion matrix and ROC curve for gas classification using traditional SVM algorithm |
 | 图9 KNN-SVM算法进行气体分类的混淆矩阵和ROC曲线Fig.9 Confusion matrix and ROC curve for gas classification using KNN-SVM algorithm |
根据表3和表4的数据比较可知, 经过参数调优后本文所提出KNN-SVM算法相比传统SVM算法对于气体分类预测的正确率均有明显的提升, 可达到99.167%, AUC指标达99.375%, 对混合气体的定性预测有更好的分析能力, 可以更加准确的对混合气体进行分类, 经过线性拟合和KNN-SVM算法可以反演出混合气体的浓度和种类。KNN-SVM算法可以有效地综合KNN和SVM的优势, 提高气体检测的准确性、 泛化能力和鲁棒性, 为气体检测领域带来了更多的可能性。
| 表4 KNN-SVM与传统SVM性能对比 Table 4 Performance comparison between KNN-SVM and traditional SVM |
针对一些气体数据偏差和泛化误差无界的问题, 提出一种KNN-SVM算法用于混合气体的分类预测, 该算法能够更加全面的捕捉数据特征, 且结合两种算法的优势, 相比于传统的SVM算法在各项分类指标均有提升, 准确率达99.167%, AUC指标达99.375%, 精度和效率均更高, 在混合气体的定性预测方面表现出更好的分析能力。通过线性拟合和KNN-SVM算法对气体数据做出分析, 能够有效地反演出混合气体中单一气体的浓度和种类。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|