{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于模式识别的X射线荧光光谱法用于土壤重金属快速检测
[倪晓芳1, 3  , 张长波
, 张长波1, 2, 3, * , 唐晓勇2, * ]
, 张长波, 唐晓勇]
|
|


作者简介: 倪晓芳,女, 1981年生,上海化工研究院有限公司高级工程师 e-mail: nxf@ghs.cn
土壤重金属的现场快速准确检测是实现土壤重金属污染防治的关键, 便携式X射线荧光光谱仪可实现土壤中典型重金属的现场无损快速检测, 且具有操作简单和无需消解处理的优势。 基于该设备的X射线荧光光谱重金属分析方法受土壤基体效应影响严重, 导致其检测准确度受限, 需通过基体相似的标准样品进行校正, 故将基于模式识别的基体成分分类方法和标准曲线法相结合, 实现对土壤中典型重金属的精准分析。 以我国砖红壤、 水稻土、 黑土、 潮土、 黄棕壤和黄红壤等6种典型土壤的X射线荧光光谱和重金属含量为数据集, 采用5点3次窗口平滑、 最大最小值归一化方法和主成分分析(PCA)对光谱数据进行处理, 以PCA降维后的前5个主成分作为输入特征变量, 土壤类别为标签, 建立基于径向基函数(RBF)的支持向量机(SVM)模式识别模型, 实现基体成分的相似性分类, 模型的超参数优化采用角蜥蜴优化算法, 优化后的核参数 g为0.0381, 惩罚因子 c为7.8529, 此时5折交叉验证正确率为100%。 定量方法为标准曲线法, 6类土壤中Cr的相关系数为0.994 7~0.999 3, Ni的相关系数为0.986 8~0.999 4, Cu的相关系数为0.992 9~0.999 9, Zn的相关系数为0.984 1~0.999 8, Pb的相关系数为0.987 7~0.999 6, As&Pb的相关系数为0.961 3~0.999 5, 在同一基体下, 重金属线性关系较佳。 采用建立RBF-SVM模式识别模型对预测集24个样品进行预测, 预测结果表明6类土壤的分类正确率为100%, 未出现错误分类。 根据分类结果, 选择对应的标准曲线进行定量分析。 结果表明Cr、 Ni、 Cu、 Zn、 Pb和As的预测平均相对误差分别为2.24%、 3.66%、 2.72%、 2.15%、 2.13%和5.55%, 均低于6%。 说明RBF-SVM模型结合标准曲线法对土壤中典型重金属的快速检测具有很好的适用性, 有望用于实际土壤典型重金属的快速定量分析与检测。
The rapid and precise detection of heavy metals in soil is the key to the efficacious prevention and remediation of soil contamination. Employing a portable X-ray fluorescence spectrometer facilitates the in-situ, non-destructive, and rapid detection of typical heavy metals. This advanced analytical technique also obviates the need for elaborate sample digestion procedures. However, the accuracy of the XRF-based heavy metal detection technique is significantly influenced by the soil matrix effects, which considerably limits the accuracy of such measurements. Calibration against standard soil with a similar matrix is imperative. As a result, this study combined pattern recognition and the standard curve method to achieve a precise analysis of typical heavy metals in various soils. The dataset comprises the X-ray fluorescence spectra and heavy metal contents across six characteristic soil types collected within China: humid-thermo ferritic, paddy soils, black soils, flavor-aquic soils, yellow-brown earth, and yellow-red earth. The spectral data is refined using a five-point, three-times window movement smoothing algorithm and a min-max normalization approach, followed by principal component analysis (PCA). Post-PCA dimensionality reduction's first five principal components are employed as input feature variables, with soil types serving as labels. A predictive model based on a Radial Basis Function (RBF) kernel for Support Vector Machine (SVM) is constructed to categorize soils by matrix similarity. The model's hyperparameters are optimized using the Horned lizard optimizer algorithm, yielding an optimized kernel function ( g) of 0.038 1 and a penalty factor ( c) of 7.852 9, with a correct classification rate of 100% under a five-fold cross-validation. The quantitative analysis utilizes the standard curve method. For the six soil types, the correlation coefficients for Chromium (Cr) ranged from 0.994 7 to 0.999 3, for Nickel (Ni) from 0.986 8 to 0.999 4, for Copper (Cu) from 0.992 9 to 0.999 9, for Zinc (Zn) from 0.984 1 to 0.999 8, and for Lead (Pb) from 0.987 7 to 0.999 6. Furthermore, the correlation coefficients of Arsenic and Lead (As & Pb) ranged from 0.961 3 to 0.999 5. The above results indicate a favorable linearity for heavy metals within the same matrix. Subsequently, the established RBF-SVM model and standard curves are applied to a prediction set of 24 samples. The predictive outcome corroborates a 100% classification accuracy for the six soil types. Upon classification, corresponding standard curves are utilized for quantitative analysis. The results show that the average relative prediction errors for Cr, Ni, Cu, Zn, Pb, and As are 2.24%, 3.66%, 2.72%, 2.15%, 2.13%, and 5.55%, respectively, below 6%. These findings prove the excellent applicability of the RBF-SVM model in combination with the standard curve method for the rapid detection of typical heavy metals in soil. This algorithm will facilitate the rapid quantitative detection of typical heavy metals in natural soil.
土壤重金属污染是影响人类健康和食品安全的世界性难题[1]。 重金属的准确快速测定是明确污染分布、 水平和生态风险的基础。 近年来便携式X射线荧光光谱仪(portable X-ray fluorescence, PXRF)使用小型化X射线光电管为激发源, 激发待测样品中的元素, 产生特征X射线荧光, 由检测器获取荧光强度, 理论上荧光强度与含量成线性关系, 从而实现元素的定量分析。 PXRF具有无损、 分析速度快、 操作简单、 无需消解和现场检测能力强的优点, 被广泛应用于土壤重金属的现场快速检测, 特别是土壤异常样品的筛选[2, 3, 4]。 同时, 在“ 碳中和, 碳达峰” 目标之下, 发展绿色低碳的检测技术是大势所趋。 与实验室检测分析方法相比, PXRF检测方法电力消耗几乎可忽略, 分析全程无污染、 无需化学试剂, 待测样品无需交通运输, 是土壤重金属检测的绿色低碳发展方向。 由于不同类型土壤基体成分差异巨大, 在PXRF检测过程中, 待测元素特征峰会受到土壤基体成分的影响, 影响程度与土壤基体类型高度相关, 唐晓勇等[5, 6]研究发现土壤样品中同一浓度的砷、 铬元素在不同浓度的铁含量下呈现不同的特征峰强度, 样品基体成分将对不同类型土壤的重金属元素定量分析形成一定的困难, 只能依靠算法进行校正。 现有商业设备算法多采用基本参数法, 为半定量分析, 尚无法替代实验室大型仪器。 国外商业设备检测准确度较高, 但算法保密, 严重制约了我国土壤重金属绿色低碳快速检测的发展。 因此, 开发新的算法, 提升PXRF检测准确性, 对PXRF用于土壤重金属快速检测潜力释放至关重要。
为了克服土壤基体成分对PXRF检测准确度的影响, 补全PXRF土壤重金属检测短板, 主流方法是选择与待测样品基体相似的标准样品建立标准曲线或采用化学计量学模型方法进行非线性拟合校正。 黄秋鑫等[7]使用土壤加标样品制作XRF定量标准曲线, 实现典型重金属的检测, 检测结果与电感耦合等离子质谱(inductively coupled plasma mass spectrometry, ICP-MS)吻合度较高。 程惠珠等[8]采用经竞争性自适应重加权算法筛选后的光谱, 建立粒子群算法优化的支持向量机(support vector machine, SVM)定量分析模型, 实现土壤重金属元素的定量分析。 Zhang等[9]以59个土壤样品为基础, 设计了一种分层深度神经网络(HDNN)估计潜在有毒金属含量, 同时实现了多种元素的定量回归, Cr、 Mn和Cu的决定系数高于0.95。 李福生等[10]以55个国际土壤的X射线荧光光谱为数据集, 建立了一种结合灵敏度降维与贝叶斯优化算法支持向量回归(BOA-SVR)的定量分析模型, 其中铜和砷的预测结果与真实结果决定系数分别达到了0.991 8和0.999 6, 结果一致性较高。 杨桂兰等[11]以39个农田土壤为材料, 建立SVM模型, 实现砷元素的定量检测, 预测集平均预测误差低于5%。 上述方法在一定程度上削弱了基体效应的影响, 提高了目标元素定量分析的准确度, 但标准曲线法在实际应用中由于待测样品的未知性, 难以确定基体成分类别, 无法选择合适的标准曲线, 实用性不足[12]。 化学计量学模型非线性校正方法对于数据集的数量及质量要求高, 并且对于数据集外样品的适用性较差, 当数据集数量和质量不够时, 模型会忽视不同土壤类型之间基体的差异, 以及相同土壤类型之间基体的相似性, 造成模型鲁棒性和泛化性较差, 影响部分未知样品的分析准确性[13]。 因此, 亟需采用新的策略构建化学计量学模型, 在训练样品数量有限的情况下, 保证检测准确性的同时提升模型的鲁棒性和泛化性。 使用模式识别方法确定相似土壤类型, 再结合标准曲线实现定量分析, 有望解决上述难题。
本工作提出了一种基于模式识别结合标准曲线法的PXRF重金属元素精准定量分析模型构建的新策略。 以我国砖红壤、 水稻土、 黑土、 潮土、 黄棕壤和黄红壤等6种典型土壤为基础, 采用人工染毒手段制备不同浓度梯度的砷、 铅、 铬、 铜、 锌、 镍重金属污染土壤作为供试材料, 通过PXRF分析仪器和ICP-MS分析方法获取供试样品的X射线荧光光谱信号和浓度参考值, 建立优化主成分数目后的径向基函数支持向量机聚类模型, 实现土壤相似基体智能识别, 根据模式识别结果选择对应土壤基体的目标重金属标准曲线, 从而实现未知样品的高精度定量分析, 旨在为PXRF实现土壤重金属快速检测提供更准确和简便的新方法。
X射线荧光光谱获取采用日本奥林巴斯公司的Innov-X Delta PXRF(DPO4000), 测试参数见表1。
| 表1 PXRF仪器测试参数 Table 1 PXRF instrument test parameters |
土壤样品参考浓度获取经消解处理后采用ICP-MS(ICAPRQ)进行分析, 仪器为美国赛默飞世尔科技公司生产, 测试参数见表2。
| 表2 ICP-MS仪器测试参数 Table 2 ICP-MS instrument test parameters |
压片机(YP-2), 上海精胜科学仪器有限公司。
微波消解仪(Mars6型, 美国CEM公司)。
采用砖红壤、 水稻土、 黑土、 潮土、 黄棕壤和黄红壤6种典型无污染土壤作为供试样品。 6种土壤样品采集于全国不同区域, 其中砖红壤采集自海南省海口市琼山区红旗镇; 水稻土采集自江苏省南京市江宁区汤山镇; 黄红壤采集自安徽省广德县杨滩镇; 黄棕壤采集自江苏省南京市江宁区淳化镇; 潮土采集自河南省封丘县潘店镇; 黑土采集自黑龙江省绥化市青冈县永丰镇。
样品采集方式: 首先在取样区域内选取5个点位(4个分样点, 1个中心样点), 采样时先用铁铲切割一个大于取土量的20 cm深的土方, 再用木(竹)铲去掉铁铲接触面后装入样品袋, 尽可能做到采样量上下一致。 采样时挑出根系、 秸秆、 石块、 虫体等杂物。 每个分样点的采样部位、 深度及重量要求一致, 5个分样等量均匀混合组成1件样品。 采样深度一般为0~20 cm。 最后将样品混合均匀后, 使用“ 4分法” 采集所需样品量。 土壤样品采集至实验室后烘干研磨过2 mm筛备用, 同时分析基本信息, 结果列于表3。
| 表3 供试土壤信息 Table 3 Information on experimental soil samples |
为了获取不同类型不同重金属浓度梯度的土壤样品以供实验数据集获取, 以采集的6种类型无污染土壤样品作为基体, 首先通过“ 4分法” 采集每类土壤各17个样品。 然后采用杨桂兰等[14]土壤染毒手段, 制备不同浓度梯度的砷、 铬、 铅、 铜、 镍、 锌重金属污染土壤样品, 合计102个。
数据集以X射线荧光光谱为输入特征, 土壤样品基体标签和重金属元素ICP-MS分析值作为浓度参考值。 其中, X射线荧光光谱获取方法采用杨桂兰等[15]针对该便携式X射线荧光光谱设备前处理条件研究结果进行, 具体方法为: 样品晾干(含水量0.8%视为晾干样品), 研磨后过0.125 mm筛, 取4.0 g样品在3 MPa下压样, 设定仪器检测时间为120 s进行PXRF扫描测试, 每个样品平行测定3次, 计算平均光谱, 用于后续分析。
土壤样品浓度参考值的获取方法: (1)采用微波对土壤样品进行消解, 消解步骤为准确称量0.100 0~0.250 0 g样品于50 mL聚四氟乙烯消解罐中, 采用5 mL硝酸和盐酸的混合酸(4∶ 1), 在195 ℃下微波消解45 min, 将消解后的样品稀释定容至50 mL, 过滤后上机分析。 上机采用表2的ICP-MS参数。
1.4.1 模型构建研究思路
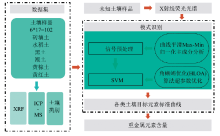
模型构建研究思路如图1。 以102个染毒土壤样品的PXRF荧光光谱和ICP-MS分析获取的浓度参考值为供试数据集, 首先采用5点3次窗口移动平滑算法对光谱信号进行平滑去噪, 并进行最大最小值归一化处理, 处理完成后采用主成分分析方法(principal component analysis, PCA)对光谱信号进行降维处理; 采用降维后的特征变量作为输入变量, 土壤类别为标签, 建立径向基函数(radial basis function, RBF)的SVM聚类模型, RBF-SVM模型超参数的优化以交叉验证的正确率为代价函数, 优化算法采用由Peraza-Vá zquez等[16]提出的角蜥蜴优化算法(horned lizard optimizer algorithm, HLOA)。 该算法是一种新型群智能优化算法, 在数学上模拟了角蜥蜴隐密, 皮肤变黑或变亮, 血液喷射和移动-逃跑等生物行为, 在隐蔽行为中, 蜥蜴通过变成半透明来改变自己的颜色, 以避免被捕食者发现。 具有进化能力强、 搜索速度快、 寻优能力强的特点, 该算法可以有效克服传统网格搜索法设备内存要求高、 计算量大和优化时间长等缺点。 基于建立的RBF-SVM模型实现土壤相似基体的智能分类, 基于分类结果进行定量分析。 定量分析采用标准曲线法, 即在每类土壤中建立重金属元素特征X射线荧光光谱和ICP-MS浓度参考值的线性回归曲线。
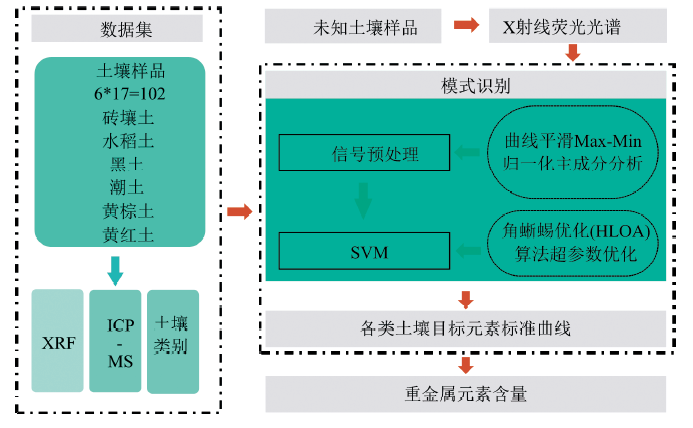 | 图1 研究思路Fig.1 Research thought |
1.4.2 评价指标
采用正确率对分类模型的预测效果进行评价, 采用预测相对误差对定量分析结果进行评价。 其中正确率越高, 模型的分类效果越佳, 准确率越接近100%和平均预测相对误差为相对误差的平均值, 该值越低, 定量分析效果越佳。 评价指标的计算公式如式(1)
(1)正确率(Classification Accuracy, CA)
式(1)中, TP是正确分类样品数量, FP是错误分类样品数量。
(2)相对误差(relative error, RE)
$R E=\frac{|\hat{y}-y|}{y} \times 100 \%$(2)
式(2)中,
对6类土壤分别通过浓度梯度法, 将102个土壤样品按3∶ 1的比例进行含量的划分, 得到78个训练样品和24个预测样品, 浓度参考值分布列于表4。
| 表4 训练及预测集样品分布 Table 4 Sample distribution in the training and testing datasets |
2.2.1 土壤X射线荧光光谱分析
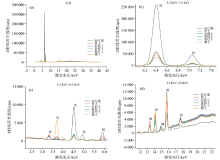
6种类型土壤的X射线荧光光谱如图2(a— d)所示。 不同类型土壤的成分具有较大的差别。 例如潮土中的钙含量较高, 而砖红壤中基本未见钙的谱峰, 主要是由于在长期的高温高湿的风化环境中, 砖红壤中的钙大量流失, 导致其含量远远低于潮土, 而潮土所在的环境排水条件较好, 温度较为适宜, 土壤中的钙含量较高。 与之相反, 砖红壤中的钛、 锰和铁等元素特征X射线荧光强度最大, 具有特异性, 其他类型土壤相对较为接近, 但仍具有一定的差异性。 不同类型的土壤中除铁、 钙、 钛、 锰等常量元素外, 其他元素含量也存在一定的不同。 XRF光谱明显反映了基体元素含量的差异, 有望作为土壤相似基体识别的判断依据。
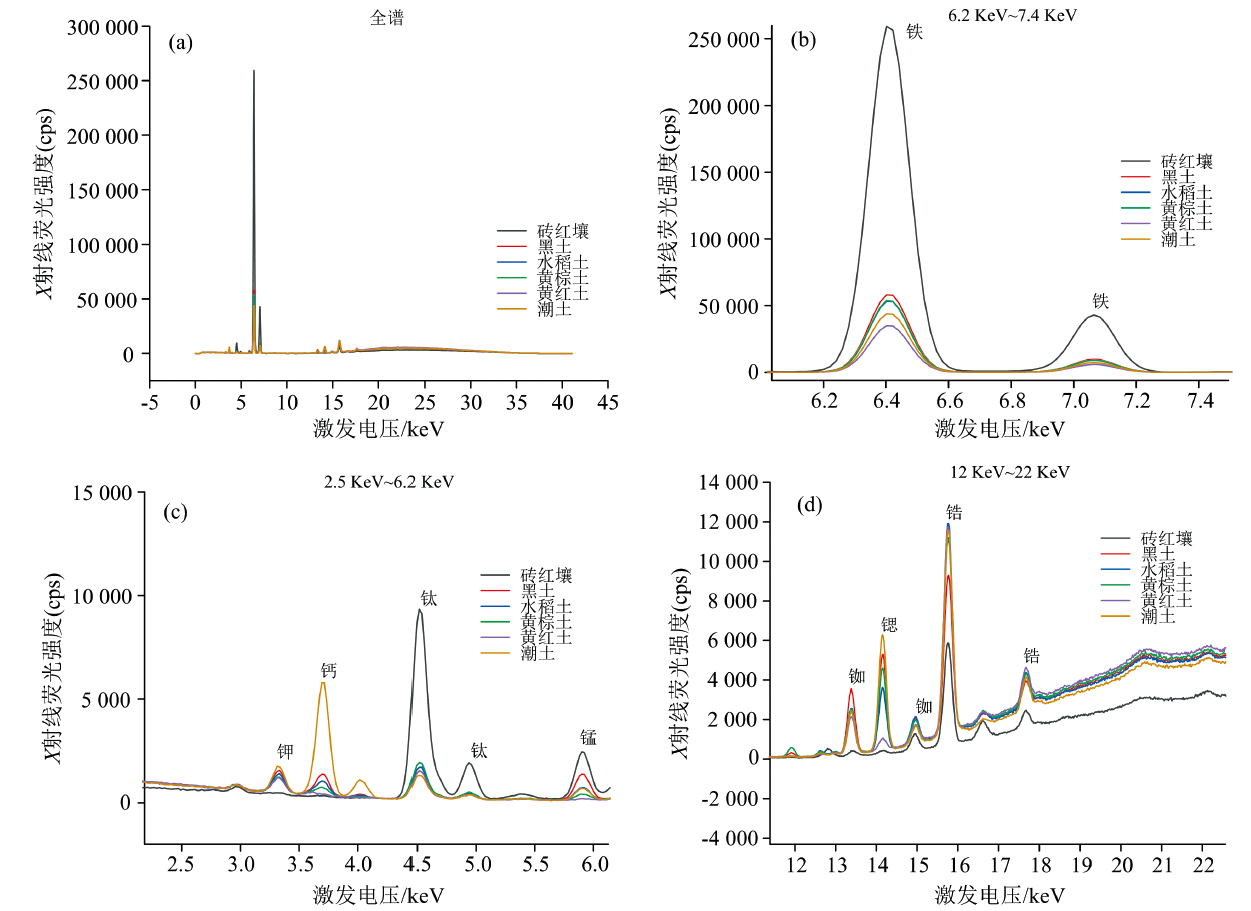 | 图2 六种土壤的土壤X射线荧光光谱谱图Fig.2 Spectroscopy spectra of soil X-ray fluorescence for six soil types |
2.2.2 主成分数的确定
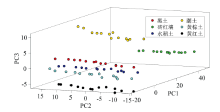
原始X射线荧光光谱数据中包含了众多信息, 每个荧光信息在不同程度上与土壤类别的识别有关。 然而, 单个样品的XRF光谱信号含有2 048个数据点, 一方面这2 048个数据点对于土壤相似基体识别的贡献存在一定的重叠, 即存在信息冗余。 另一方面, 若把2 048个数据点均作为输入变量, 对于数据数量的需求将变大, 若训练数量较小, 将存在信息的维度爆炸, 造成模型失去应用能力。 因此, 需使用主成分分析方法对光谱信号进行降维, 提取数据的主要特征分量作为后续模式识别模型的输入特征变量。 XRF光谱信号PCA降维后, 前三个主成分可视化结果如图3所示。 经PCA处理后, 各类别土壤存在明显的边界, 有助于分类模型的构建。
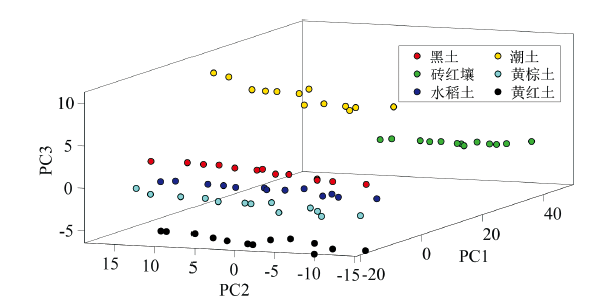 | 图3 XRF光谱PCA降维数据三维可视化Fig.3 Three-dimensional visualization of PCA-reduced XRF spectroscopy data |
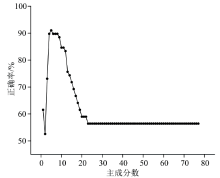
在PCA分析中, 主成分数的确定至关重要, 当主成分数过多时, 将引入噪声信息, 而主成分数过少时, 将导致有用信息缺失。 因此, 采用控制变量法, 通过控制验证模型, 以分类正确率为指标, 确定最佳主成分数。 其中验证模型为SVM模型, 核函数为RBF, 超参数采用默认参数分别为惩罚因子c=1、 核参数g=0.1。 对于验证方式, 由于训练集样品相对较少, 不适合采用留出法, 故采用5折交叉验证, 以全面评估模型性能。 主成分数目对模型验证正确率的影响如图4所示。 随着主成分的增加, 验证准确率先升高, 后降低。 当主成分数为5时, 此时验证准确率最高, 达到了91.02%, PC1— PC5的方差贡献率分别为77.02%、 10.54%、 3.83%、 1.85%和0.95%, 累计为94.19%。 将主成分数确定为5。
 | 图4 主成分数对交叉验证准确率的影响Fig.4 The impact of the number of principal components on cross-validation accuracy |
2.2.3 基于HLOA算法的最优SVM模的建立
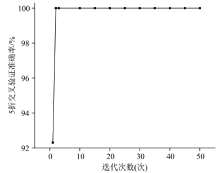
确定最佳主成分数目后, 需对SVM模型超参数进行优化, 提升模型预测能力。 选择PCA处理后的前5个主成分数作为输入特征变量, RBF-SVM作为目标模型, RBF-SVM模型的5折交叉验证分类正确率为目标函数, 采用HLOA优化算法对核参数g和惩罚因子c在[0, 10]范围内进行优化, HLOA算法参数为推荐默认设置为群落数为30, 最大迭代次数为50。 从图5可知, 在第二次迭代时, 模型的交叉验证准确率即达到100%, 未出现错误分类情况, 此时超参数分别为c=7.852 9, g=0.038 1。 将该值作为RBF-SVM模式识别模型的最佳超参数, 并进行模型的训练, 得到PCA-RBF-SVM分类模型。 同时, 由于该算法收敛迅速, 在实际应用时可缩小迭代次数和群落数, 以减少寻优时间。
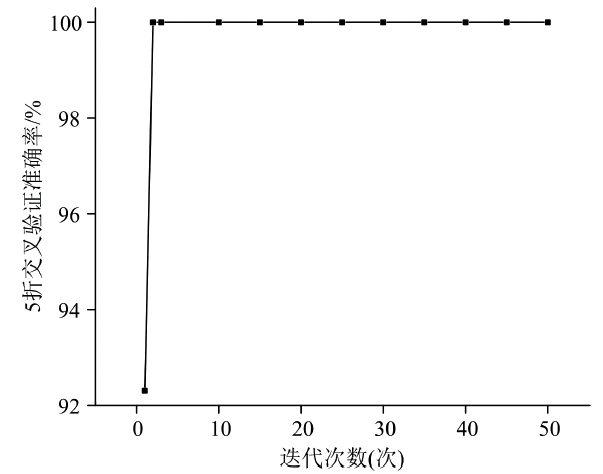 | 图5 RBF-SVM超参数HLOA算法优化结果Fig.5 Optimization results of the RBF-SVM hyperparameters using the HLOA algorithm |
2.3.1 元素特征峰的选取
6种典型重金属的特征X射线能量列于表5, 砷与铅的Kα 激发谱线存在重叠, 且砷的Kβ 能量较低, 不利于定量分析。 因此, 铅的分析采用Kβ 处荧光强度进行标准曲线绘制, 而砷的分析采用10.50 keV处激发能量进行线性回归后, 扣除铅的含量进行间接计算。 其余元素均采用Kα 处荧光强度进行标准曲线的绘制。
| 表5 典型重金属元素特征X射线能量表/keV Table 5 Characteristic X-ray energy for typical heavy metal elements/keV |
2.3.2 不同土壤中典型重金属的标准曲线
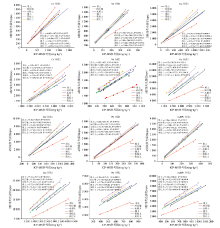
采用标准曲线法进行典型重金属元素定量分析时, 为了消除高浓度样品对低浓度样品的干扰, 将标准曲线按照浓度分为两段, 6类土壤中6种典型重金属不同浓度分段的标准曲线如图6所示。 根据回归结果显示6类土壤中Cr的相关系数为0.994 7~0.993 93, Ni的相关系数为0.986 8~0.999 4, Cu的相关系数为0.992 9~0.999 9, Zn的相关系数为0.984 1~0.999 8, Pb的相关系数为0.987 7~0.999 6, As& Pb的相关系数为0.961 3~0.999 5。 由此可知, 在同类土壤中由于土壤基体差异变化不大, 重金属元素的特征X射线荧光强度与浓度之间的线性关系较佳。
 | 图6 六类土壤中6种典型重金属不同浓度分段的标准曲线Fig.6 Standard curves for different concentration ranges of 6 typical heavy metals in 6 types of soil |
2.4.1 模式识别准确率评价
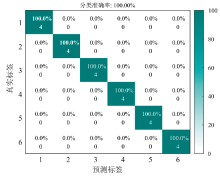
为了验证建立的RBF-SVM聚类模型对于未知样品分类的正确性, 采用经参数优化后的PCA-RBF-SVM聚类模型对提前留出的测试集样品进行预测, 其混淆矩阵如图7所示。 预测集共有6类土壤, 每类土壤各4个样品, 合计24个样品。 预测分类正确率为100%, 未出现错误分类情况, 所建立的PCA-RBF-SVM聚类模型具有优异的预测效果, 可基于X射线荧光光谱谱图实现土壤相似基体的智能分类, 为后续定量分析所需的标准曲线选择提供智能决策。
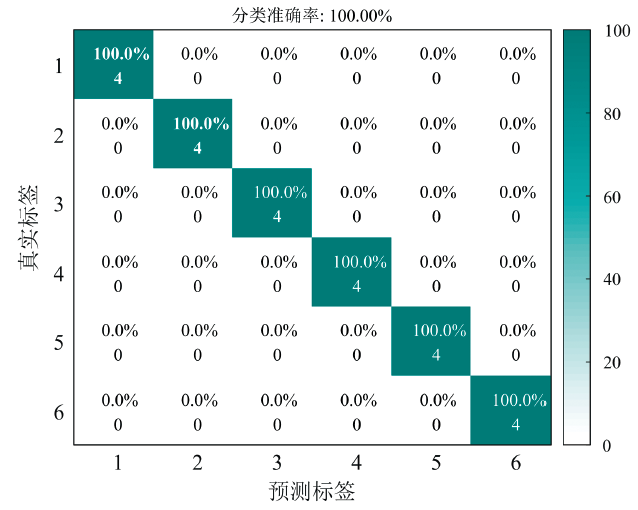 | 图7 预测集分类结果混淆矩阵Fig.7 Confusion matrix of the classification results for the prediction set |
2.4.2 定量分析准确度评价
根据预测集样品的分类预测结果, 选择对应的标准曲线, 标准曲线的分段选择根据其荧光强度大小确定。 预测集6种土壤样品的6种典型重金属含量经标准曲线法计算结果如表6所示。 从预测集结果来看, Cr预测相对误差范围在0.01%~6.27%, Ni的预测相对误差范围在0.17%~11.31%, Cu的预测相对误差范围在0.25%~9.65%, Zn的预测相对误差范围在0.17%~6.27%, Pb的预测相对误差 范围在0.06%~6.30%, As的预测相对误差范围在0.15%~33.84%。 Cr、 Ni、 Cu、 Zn、 Pb和As的平均预测相对误差分别为2.24%、 3.66%、 2.72%、 2.15%、 2.13%和5.55%, 均低于6%。 其中As预测相对误差最高达到了33.84%, 主要原因其浓度参考值较低为7.21 mg· kg-1, 而预测值为9.65 mg· kg-1, 偏差为2.44 mg· kg-1, 剩余土壤样品相对误差低于10.50%, 故其预测结果与参考值基本一致。 而其余5种重金属的预测相对误差均低于7%, 预测准确度高。 说明本方法对土壤中典型重金属的快速检测具有很好的适用性, 能够用于实际土壤典型重金属的快速定量分析与检测。
| 表6 预测集典型重金属元素含量预测结果 Table 6 Prediction results of the typical heavy metal element content in the prediction set |
采用PCA-RBF-SVM的土壤类别智能分析模型结合标准曲线法用于土壤典型重金属快速定量分析, 为土壤重金属快速检测提供新的思路。 建立的PCA-RBF-SVM模型对预测集土壤样品的分类正确率达100%, 根据PCA-RBF-SVM模 型分类结果, 选择建立的标准曲线进行定量分析, Cr、 Ni、 Cu、 Zn、 Pb和As的预测平均相对误差分别为2.24%、 3.66%、 2.72%、 2.15%、 2.13%和5.55%, 均低于6%。 但本方法目前采用的6种土壤基体, 还不足以涵盖土壤所有类型, 后续将进一步扩大土壤类型, 增加土壤样品数据库, 以提升方法的泛化能力。 对于同一区域内采集的土壤样品也可通过无监督聚类方法进行聚类分析, 再建立定量模型以提升预测准确度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|