


{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于可见-近红外光谱和化学计量学的带壳香榧坏籽快速识别
[翁定康1  , 范郑欣
, 范郑欣1 , 孔令飞1 , 孙通1, * , 喻卫武2 ]
, 范郑欣, 喻卫武|
|


作者简介: 翁定康, 1999年生,浙江农林大学光机电工程学院硕士研究生 e-mail: 1098895154@qq.com
带壳香榧籽在后熟处理及炒制过程中会产生无法食用的香榧坏籽, 在不破坏外壳的情况下人工无法准确识别和消除, 将影响香榧籽整体品质。 利用两种近红外光谱仪采集带壳正常香榧籽和香榧坏籽的光谱数据, 研究比较8种光谱预处理方法, 采用单一波长选择方法(无信息变量消除算法、 竞争性自适应重加权采样算法、 连续投影算法和子窗口重排分析法)及联合波长选择方法对两个光谱仪的光谱数据进行特征波长筛选, 应用线性判别分析(LDA)和支持向量机方法(SVM)建立香榧坏籽的识别模型并比较模型性能的优劣, 以确定不同光谱仪下较优的特征波长选择方法。 研究结果表明, 对于光谱仪1, 预处理未能有效提高模型性能, 连续投影算法为最优的特征波长选择方法, 所建立的LDA和SVM模型的预测集敏感性、 特异性及准确率分别为97.10%、 95.00%、 96.00%和97.10%、 97.50%、 97.30%, 优于全波段模型, 建模波长变量数由661个缩减到9个, 仅占原波长变量数的1.36%。 对于光谱仪2, 基线校正为最优的预处理方法, 子窗口重排分析法为最优的特征波长选择方法, 所建立的LDA和SVM模型的预测集敏感性、 特异性及准确率分别为100.00%、 92.50%、 96.00%和100.00%、 95.00%、 97.30%, 与全波段模型性能一致, 建模波长变量数由155个缩减到55个, 占原波长变量数的35.48%。 近红外光谱技术可以较好地识别带壳香榧坏籽, 合适的特征波长选择方法可以有效筛选特征波长, 简化模型, 并提高模型的准确率和稳定性。 研究还发现1 000~1 300 nm光谱波段与香榧籽的淀粉、 脂肪和蛋白质含量有关, 较适合于带壳香榧坏籽的鉴别。 该研究为带壳香榧坏籽的快速无损识别提供一定参考。
Inedible shelled Torreya grandis bad seeds will be produced during post-ripening treatment and frying, which cannot be accurately recognized and rejected manually without destroying the shells, affecting the overall quality of shelled Torreya grandis seeds. This study used two near-infrared spectrometers to collect spectral data of shelled normal and bad Torreya grandis seeds and eight spectral pre-processing methods was studied and compared. Then, a single wavelength selection method (Uninformative Variables Elimination, Competitive Adaptive Reweighted Sampling, Successive Projections Algorithm, and Subwindow Permutation Analysis) and a joint wavelength selection method were adopted to select characteristic wavelength, and Linear Discriminant Analysis (LDA) and Support Vector Machine (SVM) methods were applied to establish the identification model of Torreya grandis bad seeds. Also, the model's performance was compared to determine the better wavelength selection method for different spectrometers. The results show that for spectrometer 1, preprocessing can not improve the model performance effectively. The Successive Projections Algorithm is the optimal wavelength selection method. The sensitivity, specificity, and accuracy of the LDA and SVM models in the prediction set are 97.10%, 95.00%, 96.00% and 97.10%, 97.50%, and 97.30%, respectively, superior to the full-wavelength model. The number of modeled wavelength variables was reduced from 661 to 9, only 1.36% of the original number of wavelength variables. For spectrometer 2, baseline correction is the optimal preprocessing method, and Subwindow Permutation Analysis is the optimal feature wavelength selection method. The sensitivity, specificity, and accuracy of the prediction sets of the developed LDA and SVM models are 100.00%, 92.50%, 96.00% and 100.00%, 95.00%, and 97.30%, which are consistent with full-band model performance. The number of modeled wavelength variables was reduced from 155 to 55, which is 35.48% of the original number of wavelength variables. It can be seen that near-infrared spectroscopy can better identify the shelled bad Torreya grandis seeds, and the appropriate wavelength selection method can effectively screen the characteristic wavelengths, simplify the model, and improve the accuracy and stability of the model. It is also found that the wavelength range of 1 000~1 300 nm is related to the starch, fat, and protein content of Torreya grandis seeds, making it more suitable for identifying bad Torreya grandis seeds. This study provides a reference for the rapid and nondestructive identification of shelled Torreya grandis bad seeds.
香榧(Torreya grandis ‘ Merrillii’ )是榧树中的优良变异类型, 是我国特有的珍贵经济树种[1]。 香榧籽因其含有单宁, 须经过后熟处理, 促使单宁转化, 在后熟过程中, 若温度过高香榧籽易变质为香榧坏籽。 香榧籽需进行炒制加工后, 方能食用, 香榧坏籽在此过程会进一步变质, 导致人们无法食用[2]。 带壳香榧坏籽与正常香榧籽相比, 只有部分外壳有焦班, 无法准确辨别, 但其果仁部分差异极大, 正常香榧籽果仁为亮黄色, 香榧坏籽果仁则为棕色, 部分位置甚至为黑色, 正常香榧籽和香榧坏籽对比如图1所示。 目前, 在不破坏外壳的情况下尚无有效方法可以识别香榧坏籽, 导致其混在正常香榧籽中无法剔除, 降低香榧籽的整体品质和售价, 影响香榧产业的健康发展。 因此, 对香榧坏籽的无损检测显得尤为重要。
 | 图1 正常香榧籽和坏籽对比 (上部分为正常香榧籽, 下部分为香榧坏籽)Fig.1 Comparison of normal and bad Torreya grandis seeds (The upper parts are normal Torreya grandis seeds and the lower parts are bad Torreya grandis seeds) |
近年来, 近红外光谱技术因其具备快速、 高效、 无损等特点在农产品识别检测中大量应用[3, 4]。 俞储泽等[5]利用两种近红外检测装置对带壳空苞山核桃进行检测, 经多元散射校正预处理所建立最佳分类模型的特异性、 敏感性和正确率均达到100%。 An等[6]建立一个基于近红外光谱技术的核桃霉变无损检测模型, 实现了100%的识别准确率, 并开发一个在线识别系统以实现自动光谱采集、 霉变识别和分类。 Rovira等[7]使用近红外光谱技术成功检测了腰果中巴西坚果、 山核桃、 澳洲坚果和花生四种掺假物。 Sammarco等[8]利用近红外光谱结合多元统计分析技术对意大利榛子原产地进行识别, 对新鲜和烤制的榛子, 其分类准确率分别为81%和91%。 Miaw等[9]提出了便携式近红外光谱结合多变量监督分类来检测腰果样品中的花生、 巴西坚果、 澳洲坚果和山核桃, 证明了便携式设备对不同类型过敏性坚果的欺诈和交叉污染进行快速和无损检测的适用性。 目前, 利用近红外光谱对香榧籽的研究主要集中在产地、 储藏时间[10]和内部水分[11]的变化, 尚未有香榧坏籽的近红外光谱无损识别研究的报道。
本研究利用两种不同波段的近红外光谱仪采集带壳的正常香榧籽和香榧坏籽的光谱数据, 采用8种不同的预处理方法进行光谱预处理, 利用无信息变量消除(uninformative variables elimination, UVE)、 竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)、 连续投影算法(successive projections algorithm, SPA)和子窗口重排分析(subwindow permutation analysis, SPA)四种特征波长筛选算法选取特征波长, 应用线性判别分析(linear discriminant analysis, LDA)和支持向量机(support vector machine, SVM)方法建立带壳正常香榧籽和香榧坏籽的分类模型, 为香榧坏籽的快速无损识别提供参考。 本研究中, 为方便叙述和区分, 后续将连续投影算法简称为SPA1, 子窗口重排分析法简称为SPA2。
带壳香榧籽样本采集自浙江省绍兴市嵊州市, 采购于2022年11月8日, 购买当天运至实验室保存于4~6 ℃冷库中。 为保证获得准确的香榧坏籽, 在榧农的指导下, 随机选择大小均匀、 外观正常的炒制后带壳正常香榧籽和香榧坏籽各120颗作为试验样本。
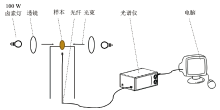
采用香榧籽近红外光谱检测装置示意图如图2所示, 采用透射模式进行光谱采集。 近红外光谱仪器为AvaSpec-HS光谱仪(Avantes公司, 荷兰)和NIR17S近红外光谱仪(上海复享光学公司, 中国)。 AvaSpec-HS光谱仪的探测器为热电制冷、 薄型背照式CCD, 信噪比为1 000∶ 1; 光谱范围为192.52~1 100.60 nm, 采样间隔为0.91 nm, 波长变量为1 000个。 NIR17S光谱仪的探测器为Hamamatsu 256 CCD, 信噪比为3 000∶ 1; 光谱范围为893.85~1 723.65 nm, 采样间隔为3.19 nm, 波长变量为256个。 光源为卤素灯, 每盏卤素灯功率为100 W, 光源总功率为200 W。 采用Avantes公司FC-UV600-2-ME型光纤, 芯径为600 μ m。 为方便叙述, 后续AvaSpec-HS光谱仪简称为光谱仪1, NIR17S光谱仪简称为光谱仪2。
 | 图2 香榧籽近红外光谱检测装置示意图Fig.2 Schematic diagram of the near-infrared spectral acquisition device for Torreya grandis seeds |
在近红外光谱采集前, 需提前打开光源30 min进行预热, 以达到光源稳定。 光谱采集时, 将带壳香榧籽水平放置于载物台上, 香榧籽顶端和底部与光源垂直放置(香榧顶端朝里), 采集1次光谱; 以香榧籽顶端和底部为轴顺时针旋转90° , 再采集1次光谱, 以获得更全面的香榧籽光谱信息, 取2次光谱平均值作为香榧籽样本的近红外光谱数据。 光谱采集参数设置: 光谱仪1积分时间为20 ms, 光谱仪2积分时间为100 ms, 平均扫描次数均为1次。 选择直径30 mm的聚四氟乙烯球作为参比, 以计算带壳香榧籽样本光谱的吸光度。
采用归一化(normalize)、 去趋势(detrend)、 基线校正(baseline)、 SG平滑(savitzky-golay smoothing)、 导数(derivative)、 标准正态变量变换(standard normal variate transformation, SNV)和多元散射校正(multiplicative scatter correction, MSC)方法对原始光谱进行预处理, 用于消除外部因素所带来的影响。
近红外光谱数据变量众多, 通常存在较多的冗余和无用信息变量, 非常有必要在建模前进行特征波长选择[12]。 本研究采用无信息变量消除算法[13]、 竞争性自适应重加权采样算法[14]、 连续投影算法[15]和子窗口重排分析法[16]四种特征波长筛选算法选取特征波长。
UVE变量选择, 蒙特卡罗抽样次数为1 000, 样本抽取比率为0.8。 CARS分析时, 设置蒙特卡罗迭代次数为50次。 SPA1选择含有最少冗余信息及最小共线性的波长组合, 设定所需提取的波长变量数目范围为1~50。 SPA2变量选择, 蒙特卡罗抽样次数为1 000, 样本抽取比率为0.8, 波长变量抽取数为50。 以上四种变量选择方法均通过MATLABR2020a软件完成。
LDA为常见的识别算法, 在特征空间中找到一个投影轴, 使得同类样本的投影点尽可能地接近, 不同类别之间的投影点尽可能地远离[17]。 SVM为用于识别和回归分析的监督学习模型[18]。 通过引入核函数将低维线性不可分问题转化为高维线性可分, 可有效解决小样本、 非线性及高维模式分类的问题。
本研究采用LDA和SVM两种判别分析方法建立香榧坏籽的识别模型, 以敏感性、 特异性和准确率对识别模型性能进行评价[19]。 模型性能评价指标定义如式(1)— 式(3)。
式(1)— 式(3)中: TP、 TN、 FP和FN分别表示真阳性、 真阴性、 假阳性和假阴性。
本研究中规定阳性为带壳香榧坏籽, 阴性为带壳正常香榧籽。 通常, 敏感性、 特异性以及准确率越高, 说明对样本的识别和分类能力越强。 本研究建模通过MATLAB R2020a软件中分类学习器完成。
两种光谱仪所测量的香榧籽原始光谱分别如图3(a, b)所示。 由图3(a)可知, 带壳正常香榧籽与香榧坏籽在500~1 100 nm波长范围内光谱变化趋势相似, 吸收峰和波谷所在的波长位置基本相同, 且两类光谱相互重叠, 很难直接从形态上加以区分, 需要进行后续处理分析。 由于香榧籽的近红外光谱在200~500 nm波段范围的噪声比较大, 因此最终选用500~1 100 nm波段范围, 661个波长的带壳香榧籽近红外光谱用于后续分析。 图3(b)为光谱仪2采集的香榧籽原始光谱。 由图3(b)可以看出, 带壳香榧坏籽的吸光度普遍高于正常香榧籽, 且带壳香榧籽光谱在1 170和1 220 nm处均有明显的吸收峰, 在1 040 nm处略有波峰。 1 170和1 220 nm附近为甲基和亚甲基中C— H键二级倍频的特征吸收谱带, 1 040 nm附近为水的O— H键二级倍频的特征吸收谱带。 图3(b)根据经验综合考虑选用900~1 400 nm波段范围, 155个波长的带壳香榧籽近红外光谱用于后续分析。
 | 图3 两种光谱仪采集的带壳香榧籽原始近红外光谱 (a): 光谱仪1; (b): 光谱仪2Fig.3 Raw near-infrared spectra of shelled Torreya grandis seeds collected by two spectrometers (a): Spectrometer 1; (b): Spectrometer |
由于受到环境因素、 样本自身以及近红外光谱仪等客观因素的影响, 会不可避免地出现一些异常样本。 因此, 在建模前需将异常样本剔除。 本研究使用主成分分析-马氏距离法(principal component analysis-Mahalanobis distance, PCA-MD)进行异常样本的剔除, 光谱仪1剔除7个异常样本, 光谱仪2剔除样本10个, 总计剔除17个异常样本。
主成分分析(principal component analysis, PCA)不仅可以进行数据降维, 也能对两类样本间的差异进行初步分析, 被广泛应用于特征提取和数据可视化等方面[20]。 因此, 对两种光谱仪采集的香榧籽光谱进行主成分分析, 前4个主成分的方差贡献率和累计贡献率如表1所示。 两种光谱仪采集带壳香榧籽光谱的前4个主成分的累计贡献率分别为99.97%和99.91%, 可以有效地代表原有光谱信息。
| 表1 带壳香榧籽光谱的主成分贡献率 Table 1 Principal component contribution of shelled Torreya grandis spectra |
由于两个光谱仪的第1主成分和第2主成分的累计方差贡献率达到99.00%和99.91%, 远大于其他主成分。 采用PC1与PC2主成分为变量绘制散点分布图, 以探究带壳正常香榧籽和香榧坏籽的光谱差异, 其结果如图4所示。 由图4(a)可以看出, 光谱仪1所测的带壳正常香榧籽和香榧坏籽的PC1与PC2主成分散点分布相互交错, 没有明显的簇拥现象; 图4(b)显示光谱仪2所测正常香榧籽的PC1与PC2主成分散点有明显的簇拥现象, 香榧坏籽主成分散点分布更广更加散, 说明两者之间的主成分散点分布有明显的差异。
 | 图4 第1和第2主成分散点分布图 (a): 光谱仪1; (b): 光谱仪2Fig.4 Distribution of the first and second principal components (a): Spectrometer 1; (b): Spectrometer 2 |
2.3.1 全波段识别模型
采用归一化、 去趋势、 基线校正、 SG平滑、 一阶导数(first derivative, FD)、 二阶导数(second derivative, SD)、 标准正态变量变换、 多元散射校正方法对两种光谱仪采集的带壳香榧籽原始光谱进行预处理, 然后应用LDA和SVM方法建立带壳坏籽和正常香榧籽的识别模型, 并利用预测集样本对识别模型精度进行验证, 其结果如表2和表3所示。
| 表2 不同预处理和建模方法下带壳香榧坏籽的识别模型结果(光谱仪1) Table 2 Identification model results of shelled bad Torreya grandis seeds under different pretreatment and modeling methods (Spectrometer 1) |
| 表3 不同预处理和建模方法下带壳香榧坏籽的识别模型结果(光谱仪2) Table 3 Identification model results of shelled bad Torreya grandis seeds under different pretreatment and modeling methods (Spectrometer 2) |
由表2可知, 对于光谱仪1, 光谱预处理均未能有效提升模型的识别性能。 综合考虑, 选择原始光谱建立的识别模型为最优模型, 其LDA和SVM模型预测集的敏感性、 特异性及准确率均为97.10%、 92.50%及94.70%。 由表3可知, 选择基线校正为光谱仪2光谱数据的最佳预处理方法, 其LDA和SVM模型预测集的敏感性、 特异性及准确率均为100.00%、 95.00%和97.30%。
2.3.2 基于特征波长的识别模型
针对最佳预处理方法, 对光谱仪1及光谱仪2的光谱数据进行特征波长筛选。 采用单一波长选择方法(UVE、 SPA1、 SPA2、 CARS)及联合波长选择方法(UVE-SPA1、 UVE-SPA2、 UVE-CARS)对两个光谱仪的光谱数据进行特征波长筛选, 然后应用LDA和SVM方法建立带壳香榧坏籽的识别模型, 并比较模型性能的优劣, 以确定较优的特征波长选择方法。
表4为光谱仪1中基于特征波长的带壳香榧坏籽的识别模型结果。 由表4可知, 与全波段模型相比, 经过UVE、 UVE-SPA1及UVE-SPA2特征波长筛选后所建的模型性能略下降, 经过CARS、 SPA2及UVE-CARS特征波长筛选后所建的模型性能持平, 而经SPA1特征波长筛选后模型的校正集和预测集的识别准确率均有所上升, 其模型性能优于全波段模型, 且所用的建模波长数为9个, 仅占原波长变量的1.36%, 表明SPA1方法可以最大程度地剔除无用变量和共线性变量, 筛选有用的特征波长变量。 综上分析, 对于光谱仪1, SPA1为最优的波长选择方法。 SPA1-LDA和SPA1-SVM模型的预测集敏感性、 特异性及准确率分别为97.10%、 95.00%、 96.00%和97.10%、 97.50%、 97.30%。
| 表4 基于特征波长的带壳香榧坏籽的识别模型结果(光谱仪1) Table 4 Results of the identification model of shelled bad Torreya grandis seeds based on characteristic wavelengths (Spectrometer 1) |
表5为光谱仪2中基于特征波长的带壳香榧坏籽的识别模型结果。 由表5可知, 在LDA模型中, 与全波段LDA模型相比, 经特征波长筛选后模型性能均有不同程度的下降。 其中经SPA2特征波长筛选后模型校正集的各指标一致, 预测集的特异性由95.00%下降到92.5%, 准确率由97.30%下降到96.00%, 模型性能略有下降, 但其建模波长数由原来的155个缩减到55个, 占原波长变量数的35.48%, 表明该方法能较有效地筛选香榧坏籽的特征波长。 而在SVM模型中, 与全波段SVM模型相比, 经SPA2、 CARS、 UVE-CARS及UVE-SPA2特征波长筛选后模型性能与全波段模型基本一致, 而经UVE、 SPA1及UVE-SPA1特征波长筛选后模型性能则有不同程度地下降。 综合分析, 对于光谱仪2的光谱数据, SPA2为最优的波长选择方法。 SPA2-LDA和SPA2-SVM模型的预测集敏感性、 特异性及准确率分别为100.00%、 92.50%、 96.00%和100.00%、 95.00%、 97.30%。
| 表5 基于特征波长的带壳香榧坏籽的识别模型结果(光谱仪2) Table 5 Results of the identification model of shelled bad Torreya grandis seeds based on characteristic wavelengths (Spectrometer 2) |
在不破坏外壳的情况下准确识别和剔除缺陷香榧籽能显著提高香榧籽整体品质。 目前, 尚未有带壳香榧坏籽方面的近红外光谱无损识别研究的报道。 分析原因可能是香榧籽外壳较厚, 难以获取其果仁的近红外光谱信息。 本研究所搭建的带壳香榧籽近红外光谱检测装置采用漫透射检测方式, 利用两盏光源经过透镜后照射被测样本, 能有效穿透香榧籽外壳, 获取香榧籽果仁的光谱信息。
本研究推进近红外光谱技术在带壳香榧坏籽识别, 采用两种不同波段的近红外光谱仪采集正常带壳香榧籽和香榧坏籽的光谱数据, 对比发现光谱仪2采集的近红外光谱1 000~1 300 nm区域内, 带壳正常香榧籽与香榧坏籽差异较大, 其中1 170和1 220 nm区域为甲基和亚甲基中C— H键二级倍频的特征吸收谱带, 主要与香榧籽果仁的脂肪含量有关, 与Guan等[10]在研究香榧籽果仁储藏时间所采集的光谱所对应。 在PCA分析中, 采用PC1与PC2主成分为变量绘制散点分布图也同样发现光谱仪2所测正常香榧籽与香榧坏籽的主成分散点分布有明显差异。 因此, 1 000~1 300 nm光谱波段更适合于带壳香榧坏籽的鉴别。
不同品种香榧籽果实特性不同, 在炒制加工后香气物质不同[21]。 本研究所选用的带壳香榧籽源于浙江绍兴嵊州市的细榧, 其他品种若要使用本研究所建模型, 则需在此模型中加入不同品种的香榧籽样本, 从而提高模型的精确度。 本研究只对香榧坏籽进行识别, 后续可进一步扩展香榧籽缺陷样本种类, 并开展带壳香榧籽内部品质指标检测, 如香榧籽油酸价和过氧化值等, 建立近红外定量模型。
利用近红外光谱技术对带壳香榧坏籽进行快速无损识别。 研究比较了8种不同预处理方法和7种特征波长选择算法, 并应用LDA和SVM方法建立识别模型, 以获得较优的带壳香榧坏籽识别模型。 研究结果表明: 对于光谱仪1, 光谱预处理未能有效提高模型性能, SPA1为最优的特征波长选择方法, SPA1-LDA和SPA1-SVM模型的预测集敏感性、 特异性及准确率分别为97.10%、 95.00%、 96.00%和97.10%、 97.50%、 97.30%, 优于全波段模型。 经SPA1筛选后, 建模波长变量数由661个缩减到9个, 仅占原波长变量数的1.36%, 可以有效简化模型和提高模型的稳定性。 对于光谱仪2, 基线校正为最优的预处理方法, SPA2为最优的特征波长选择方法, SPA2-LDA和SPA2-SVM模型的预测集敏感性、 特异性及准确率分别为100.00%、 92.50%、 96.00%和100.00%、 95.00%、 97.30%, 与全波段模型性能相近。 经SPA2筛选后, 建模波长变量数由155个缩减到55个, 占原波长变量数的35.48%。 1 000~1 300 nm光谱波段与香榧籽的淀粉、 脂肪和蛋白质含量有关, 较适合于带壳香榧坏籽的鉴别。 近红外光谱技术可以较好地识别带壳香榧坏籽, 合适的特征波长选择方法可以有效筛选特征波长, 简化模型, 并提高模型的准确率和稳定性。 为带壳香榧坏籽的快速无损识别提供一定的参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|