


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
紫苏中紫苏醛含量的高光谱预测方法
[孙佳琪 , 殷勇
, 殷勇* , 于慧春, 袁云霞, 郭林鸽]
, 殷勇, 于慧春, 袁云霞, 郭林鸽]
|
|


作者简介: 孙佳琪,女, 1999年生,河南科技大学食品与生物工程学院硕士研究生 e-mail: 13017632329@163.com
为了实现高光谱成像技术快速检测紫苏中的紫苏醛(PAE)含量, 采集了4种产地的紫苏高光谱图像, 在获取紫苏有效波长图像的基础上, 将其纹理特征和经小波变换后获得的能量值与光谱值采用不同方式融合, 构建出了不同的表征向量, 建立了相应的PAE含量快速检测模型。 经对比分析确定了PAE含量最优预测策略, 具体方法如下。 (1)采用4种方法对光谱值进行预处理, 对比所构建模型的预测能力, 可得较优预处理方法为局部加权回归散点平滑(LOWESS)。 (2)运用竞争自适应重加权采样法(CARS)和连续投影算法(SPA)提取预处理后光谱信息的特征波长, 计算对应的光谱值, 以便与其他特征进行组合。 (3)对高光谱图像进行主成分分析(PCA)获得有效波长图像, 利用其灰度共生矩阵(GLCM)提取能量(ASM)、 对比度(CON)、 相关性(COR)和熵(ENT)等4种纹理特征; 同时, 采用Daubechies小波对有效波长图像进行三层分解, 将分解出的低频分量能量也作为有效波长图像的1种表征特征。 (4)将上述提取的特征波长光谱值、 小波能量值、 纹理特征值以不同组合方式构造特征输入向量, 在此前提下分别构建偏最小二乘回归 (PLSR)、 BP神经网络、 随机森林(RF)、 极限梯度提升树(XGBoost)四种检测模型, 经对比分析后获得最优输入向量和预测模型。 结果表明, 基于单类特征输入向量的4种预测模型的预测能力均不如多类特征融合的输入向量; 最佳输入向量是经LOWESS预处理后由CARS优选的特征波长所对应的光谱值与有效波长图像的纹理特征值和小波能量值三者的融合向量, 且XGBoost模型预测能力最强, 其训练集
To rapidly detect Perilla aldehyde (PAE) content in Perilla Frutescens, hyperspectral imaging technology was employed, and the hyperspectral images of Perilla Frutescens were acquired from four distinct producing regions. Based on obtaining effective wavelength images of Perilla Frutescens, its texture features and energy values obtained by wavelet transform were fused with spectral values in various ways to create different characterization vectors. These vectors were then employed to construct corresponding rapid detection models for PAE content. The models' prediction capabilities were thoroughly compared and analyzed to determine the optimal prediction strategy for PAE content. The specific methods are as follows. (1) Four methods were employed to preprocess the raw spectral values. After evaluating the predictive performance of the constructed models, it was determined that Local Weighted Scatterplot Smoothing (LOWESS) emerged as the optimal preprocessing method. (2) The Competitive Adaptive Reweighted Sampling (CARS) and Successive Projections Algorithm (SPA) were employed to extract the characteristic wavelengths of the preprocessed spectral information, and the corresponding spectral values were then computed to facilitate their integration with other mentioned features in the paper. (3) Principal Component Analysis (PCA) was utilized to get effective wavelength images from the hyperspectral images. The grayscale co-occurrence matrix (GLCM) was then applied to the effective wavelength images to extract four texture features: Energy (ASM), Contrast (CON), Correlation (COR), and Entropy (ENT); simultaneously, the Daubechies wavelet was employed to conduct three-level decomposition of the effective wavelength image, and the energy of the low-frequency component derived from the decomposition was also considered as a characterization feature of the effective wavelength image. (4) The extracted features of wavelength spectral values, wavelet energy values, and texture features were utilized to construct feature input vectors in different ways, and based on the mentioned vectors, four detection models were then constructed: Partial Least Squares Regression (PLSR), Backpropagation Neural Network (BPNN), Random Forest (RF), and Extreme Gradient Boosting (XGBoost); and then these models were evaluated and compared according to their prediction capabilities to identify the optimal input vectors and prediction models. The research results indicate that the prediction capabilities of the four prediction models using single-class feature input vectors are all inferior to that of the input vectors fused with multi-class features; the optimal input vector is the feature fusion input vector, which incorporates the texture feature values and wavelet energy values from effective wavelength images as well as the spectral values corresponding to the feature wavelengths selected by CARS after LOWESS preprocessing. Among these models, the XGBoost model demonstrates the strongest prediction capabilities. The
紫苏是我国首批药食同源的植物, 市售紫苏不同产地和不同品种间营养成分和药用品质良莠不齐, 且紫苏醛(perillaldehyde, PAE)含量变幅较大。 根据紫苏挥发油中主成分差异可将紫苏挥发油分为紫苏醛型(PA)和紫苏酮型(PK)等, PA型的PAE含量一般比PK型高, 且《中国药典》2020年版[1]将PAE作为薄层色谱法鉴别紫苏叶片的对照成分。 紫苏中PAE含量测定方法一般是采用先提取紫苏的挥发油, 再用高效液相色谱(HPLC)等仪器测定挥发油中的PAE含量。 由于PAE具有挥发性, 测定过程中损耗难以避免, 严重影响PAE含量测定结果的准确性。 因此找出一个快速检测紫苏PAE含量的方法是需要的, 以期可对紫苏品质快速鉴定提供技术支撑。
高光谱成像技术具有快速检测、 对待测物品破坏性小等优点, 在食品[2]、 农业[3]等领域应用广泛。 高光谱光谱值融合纹理特征、 颜色特征等特征的检测方法研究目前已有较多报道, 如: Wan[4]等将优选的光谱值与滩羊肉高光谱第一主成分图像的纹理特征融合, 为滩羊肉中肌红蛋白含量快速预测提供依据; 杨东等[5]选取玉米籽粒7个特征波长对应的图像, 并提取图像纹理特征和颜色特征, 与特征波段对应的光谱值融合, 为玉米籽粒霉变等级快速判别提供依据。 这些研究对紫苏中PAE含量快速检测有借鉴价值, 但仍不满足PAE含量高光谱检测的要求, 有或多或少的局限性。 因此, 在已有成果的基础上, 尝试在确定高光谱图像的有效波长图像基础上, 对其进行小波变换, 把变换得到的小波能量值作为图像的一种表征特征, 然后融合有效波长图像的纹理特征等光谱表征信息作为PAE含量检测模型的输入向量, 以便构建稳健的检测模型, 提高检测结果的准确度和可靠性。
3种紫苏样本取自广西南宁市, 湖北省咸宁市和浙江省衢州市, 3地样本均为叶面绿色、 叶底紫色; 第4种样本取自辽宁省铁岭市, 为全绿紫苏。 每个产地共取样100片, 4个产地共得400个紫苏样本。 通过设定不同的随机种子值将数据集进行多次划分, 确保在多个情况下训练和评估各个模型, 以降低预测结果的偶然性。 每次划分训练集和测试集的比例为3∶ 1, 训练集样本共300个, 测试集样本共100个。
高光谱采集装置主要由光谱仪、 4只卤素灯、 传送带以及计算机构成, 设备结构及具体参数详见文献[6]。
进行紫苏高光谱数据采集时, 相机的物距为202 mm, 样本的传送速度为1.30 mm· s-1。 每次采样时, 将紫苏样本的正面朝上平放于传送平台上, 并使用 SICap-STVR软件将采集的图像大小设置为: Width为1032、 Height为850。
为确保紫苏高光谱数据具有代表性, 避开光谱图像的褶皱及斑点区域, 利用ENVI 5.31软件选取每幅图像包含叶片主轴中点的50像素× 50像素范围作为感兴趣区域(region of interest, ROI), 并将各波长图像ROI中的灰度平均值作为一个紫苏样本对应该波长的光谱值。
参考陈家宝等[7]的紫苏PAE提取及含量测定方法, 将正己烷提取的PAE样本经气相色谱-质谱联用仪(赛默飞世尔科技公司, 型号为TSQ9000, 美国)进样完毕后, 使用设备自带谱库检索峰型, 并对比质谱图库中的标准谱图, 最终确定保留时间11.87 min的峰型为PAE, 并保存该处峰面积。 采用外标法制作PAE含量标准曲线, 用正己烷将PAE标准品(CAS18031-40-8 HPLC≥ 98%)配制成多个等梯度浓度样本, 在与提取的PAE样本相同进样参数情况下进样, 将各标准品样本保留时间在11.87 min的峰面积与相应的PAE标准品浓度做标准曲线, 依据标准曲线计算出各样本中PAE含量。 每个产地测量3个紫苏样本, 并将三个样本PAE含量平均值作为该产地紫苏PAE含量。
为消除采样时环境、 设备等对原始光谱的影响, 采用多项式平滑算法(savitzky-golay smoothing, SG)、 多元散射校正(multiple scattering correction, MSC)、 标准正态化变换(standard normal variate, SNV)和局部加权回归散点平滑(locally weighted scatterplot smoothing, LOWESS)4种方法对原始光谱进行预处理, 试用预处理后的光谱值构建不同的预测模型, 根据预测能力确定最佳预处理方法。 MSC、 SNV用来校正样品间因散射而引起的光谱误差。 LOWESS是将每个光谱值替换为它附近的加权平均值, SG是使用多项式函数将拟合值作为光谱值, 二者都充分利用光谱数据中的局部信息, 保留光谱原有的特征。
由于光谱波段范围大, 相邻波长间相似性高, 可能存在较多与PAE含量无关的冗余波长, 这会影响表征PAE含量的波长在预测模型中所占的比重, 进而掩盖PAE信息, 影响预测模型精度。 因此, 为找出能表征PAE成分的波长光谱值, 拟采用连续投影算法(successie projection algorithm, SPA)和竞争自适应重加权采样法(competitive adaptive reweighted sampling, CARS)对波长进行筛选[8]。
SPA是通过多次投影将原始数据空间投影到一个低维的子空间, 并在每次投影后选择投影方向上具有最大方差的特征作为保留特征, 最终得到一组最具代表性的特征波长。
CARS算法结合蒙特卡洛采样, 根据PLS模型中回归系数绝对值对波长进行保留与剔除, 以寻出最佳变量组合, 并将保留的波长使用交叉验证, 从而确定对理化值表达最重要的波长。
目前, 对光谱图像特征的研究多是基于主成分(principal components, PC)图像开展的[9, 10]。 计算发现, 提取PC图像的特征较为复杂、 费时, 但是提取某个波长下的图像特征, 可大大缩减高光谱图像特征提取的复杂性。 由于主成分分析(principal component analysis, PCA)处理高光谱图像时, 各PC图像是由相应的PC权重系数与波长图像相乘所得, 其中, PC的权重系数表示每个波长图像在主成分中的贡献程度, 绝对值最大的PC权重系数对应的波长图像承载了该PC最大的方差, 对该PC图像贡献率最大, 对原始图像特征的保留程度也最大。 因此, 依据累计贡献率大于99%的准则选择主成分个数, 分别将其各波长权重系数绝对值最大值所对应的波长图像定义为有效波长图像[11]。 后续提取的图像特征均是对有效波长图像提取的。
1.7.1 纹理特征
不同品种紫苏的理化成分及含量不同, 体现在叶片表面的皱褶、 纹路等有所不同, 会使得叶片纹理特征不同。 因此, 通过提取紫苏纹理特征, 尝试与其他表征特征融合, 以寻找能全面、 有效表达紫苏中PAE含量的表征向量。 在纹理特征提取中, 从像素灰度值共生的角度出发, 可通过分析像素之间的空间关系和灰度值分布情况, 捕捉图像的全局纹理特征[4]。 因此, 拟选用灰度共生矩阵(GLCM)提取紫苏有效波长图像的能量(ASM)、 对比度(CON)、 相关性(COR)和熵(ENT)作为纹理特征。
1.7.2 小波变换低频分量特征
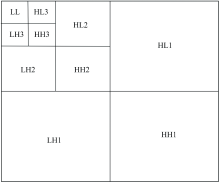
小波变换(wavelet transform)从频域分析的角度出发, 使用小波基函数将图像分解成不同的尺度和频率成分。 其中低频部分是变换后的平滑部分, 包含图像的总体信息, 高频部分一般含有噪声信息。 选用Daubechies小波将紫苏样本图像进行三层分解, 每次分解得到如图1中LL(低频分量)、 LH(垂直分量)、 HL(水平分量)和HH(对角分量), 其中LH、 HL和HH三者属于高频分量[12]。 由于小波变换后的高频分量含有噪声且能量远低于低频能量, 因此, 选用有效波长图像三层小波变换得到低频分量的能量作为小波能量, 并将其作为图像的一个表征特征。 小波变换低频分量的能量计算公式为
式(1)中, EL为经小波变换后的低频分量的能量值; fLL(X, Y)为小波变换后的低频分量; X和Y为有效波长图像像素矩阵的行和列。
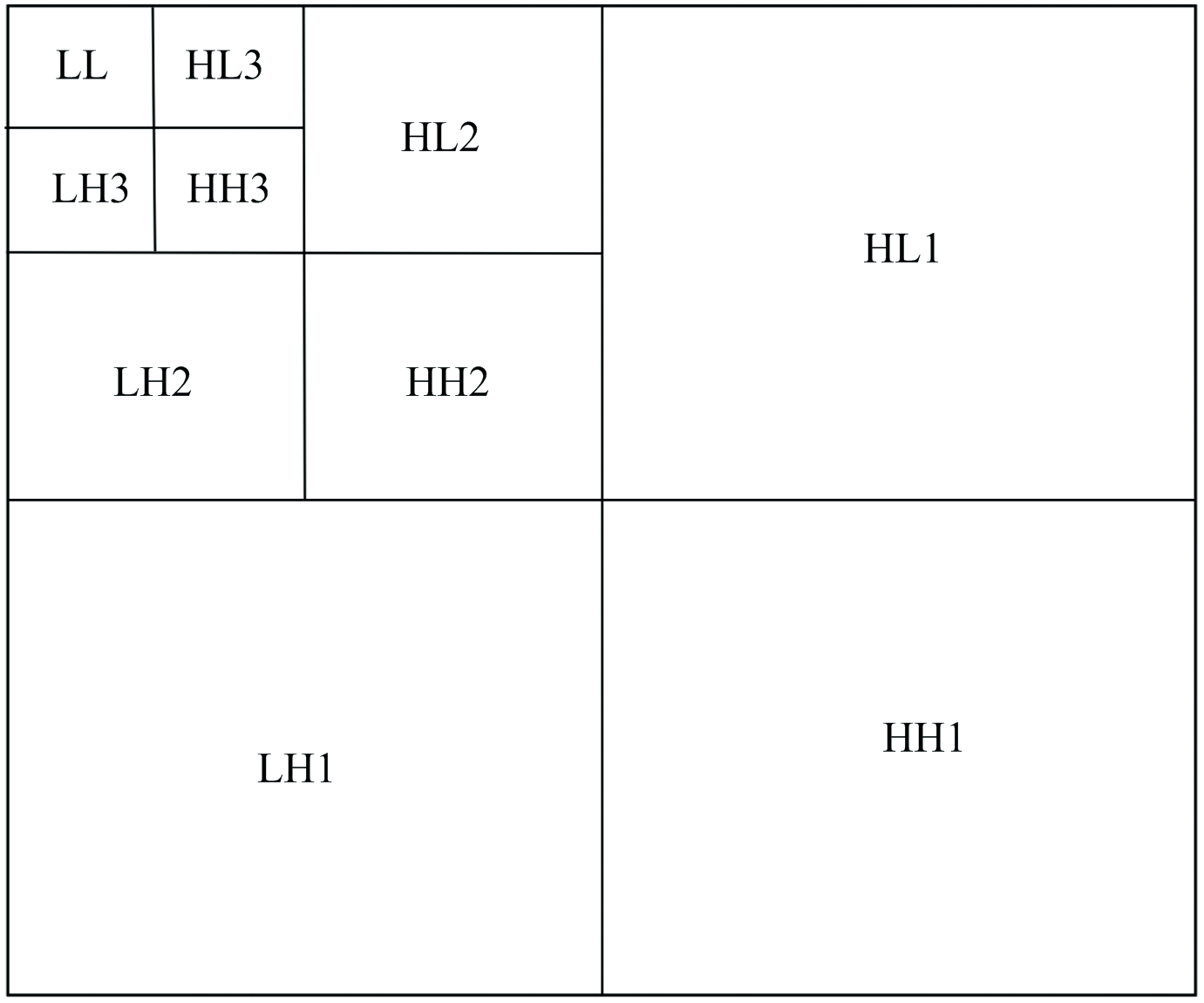 | 图1 小波三层分解示意图Fig.1 Schematic diagram of three-level wavelet decomposition |
1.8.1 输入向量构造
(1) 单类特征输入向量构造
将提取的特征波长的光谱值、 纹理特征值和小波能量值3类特征分别作为预测PAE模型的输入向量, 分析它们的预测能力以确定是否可以表征PAE含量。
(2) 多类特征融合输入向量构造
拟采用特征波长光谱值+纹理特征值、 特征光谱值+小波能量值、 特征光谱值+纹理特征值+小波能量值3种组合方式进行特征融合, 以构造预测模型的输入向量。
由于特征光谱值、 纹理特征值、 小波能量值三类表征值的单位和量级不同, 不经处理直接进行融合可能会导致特征中某个极端值对结果的贡献过大, 而其他特征则被淹没。 因此需对3类特征进行标准化处理, 以减少量纲和极端值等影响。
选用PCA进行多特征融合。 具体融合方法为: 将标准化处理后的特征光谱值、 纹理特征值、 小波能量值按照上述3种组合方式拼接成3个新的组合特征矩阵, 分别对新矩阵进行PCA处理, 最后将累积贡献率大于99%的PC构造为预测模型的输入向量。
1.8.2 预测模型的建立
选用偏最小二乘回归(partial least square regression, PLSR)、 BP神经网络、 随机森林(random forests, RF)、 极限梯度提升树(extreme gradient boosting, XGBoost)四种模型构建方法, 并将1.8.1构造的两类输入向量分别作为它们的输入向量, 对比各模型的预测能力, 以获得PAE含量的最佳表征向量和最优预测模型。
PLSR主要用于处理自变量(X)和因变量(Y)之间高度相关的情况, 将1.8.1中构建的两类输入向量分别作为自变量(X), 紫苏PAE含量作为因变量(Y), 把X和Y分别投影到新的综合变量上, 寻找它们之间的最大协方差方向, 从而建立起回归模型[13]。
BP神经网络是由输入层、 隐含层和输出层组成。 这里采用单隐层结构, 故BP神经网络为3层结构, 其中输入层神经元个数为输入向量的维数, 输出层神经元个数为1, 即表征PAE的神经元, 隐层神经元个数由试凑法确定, 且不同的叔入向量会导致隐层神经元个数不同。 另外, 输入层神经元起到信号传递作用, 没有进行信号变换; 隐层神经元的激活函数选为tansig; 输出层神经元的激活函数选为purelin。
RF是一种具有集成思想的算法, 通过使用自助采样法, 有放回的将原始数据集随机抽取并组合成不同的子集, 并对每个子集构建决策树, 决策树的每个节点随机选择特征子集的一个特征进行分裂[14], 最终通过每棵决策树的预测结果平均值来作为最终的PAE含量预测值。 RF模型决策树数目设为100, 最小叶子数设为5, 并使用TreeBagger函数进行训练。
XGBoost是一种基于梯度提升树的机器学习模型, 它迭代地训练多个弱分类器(即决策树), 每次训练都试图优化目标函数的梯度下降。 模型在每轮迭代中根据之前的预测结果和真实值之间的残差来学习新的分类器, 通过加权累加这些分类器的预测结果, 最终得到整个模型的预测结果[15]。 XGBoost模型构建选用线性函数, 迭代次数设为100, 学习率设为0.1, 树的最大深度设为5。
表1为由色谱法测量得到中各产地紫苏中PAE的含量值, 它们大都在1.3~2.3 mg· g-1, 由于辽宁所产紫苏的挥发油为PK型, 其余三产地紫苏挥发油为PA型, 因此表1中辽宁产地紫苏中PAE含量明显低于其余三个产地。
| 表1 四种产地紫苏样本的PAE含量分析(mg· g-1) Table 1 The analysis of PAE content in Perilla Frutescens samples from 4 producing regions (mg· g-1) |
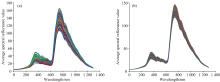
图2(a)为400个紫苏样本的原始光谱曲线, 由图2(a)可知, 不同产地紫苏平均光谱曲线形状基本一致, 光谱反射值大都处于0~180之间, 表明4地紫苏内部成分基本一致。 表2为预测模型构建中的
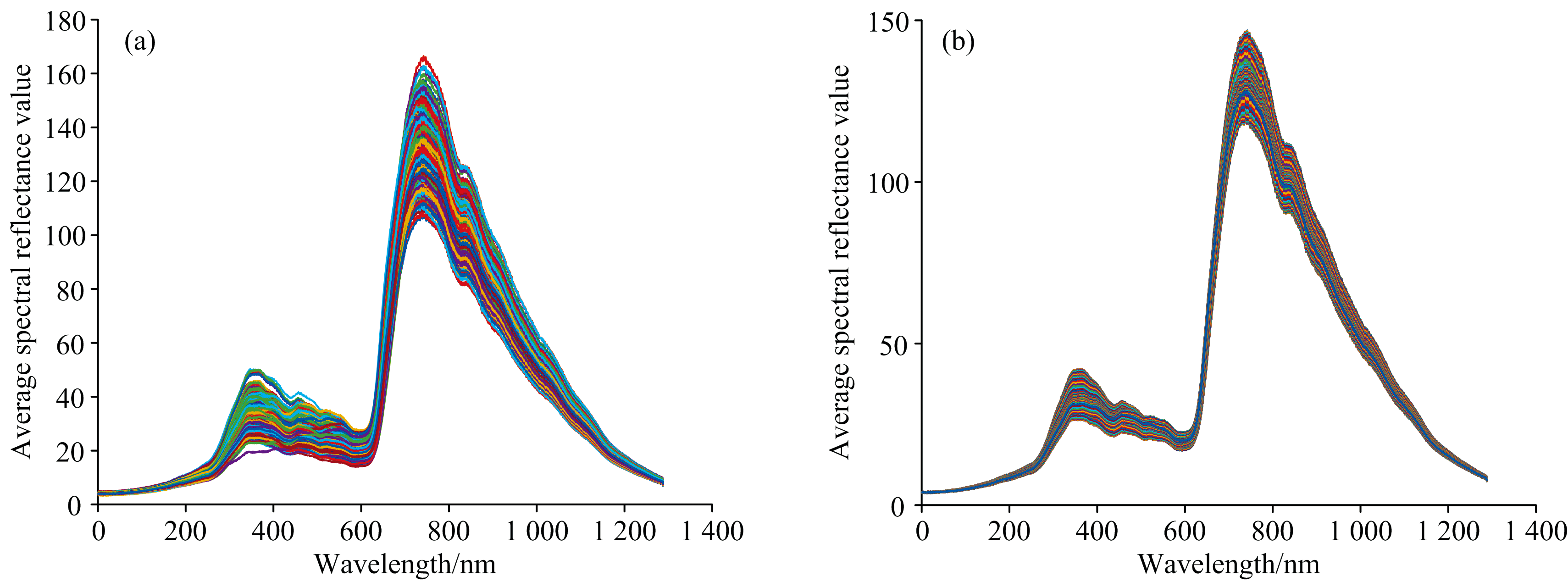 | 图2 LOWESS预处理前后光谱曲线图 (a): 紫苏原始光谱曲线图; (b): LOWESS预处理后的紫苏光谱曲线图Fig.2 Spectral curves before and after LOWESS preprocessing (a): The raw spectral curves of Perilla Frutescens samples; (b): The Perilla Frutescens spectral curves after LOWESS preprocessing |
| 表2 基于不同预处理后光谱值的预测模型对应的 |
2.3.1 CARS提取的特征波长
图3(a)为CARS提取的最优变量图, 竖直线位置表明采样运行58次时, 获得最佳变量子集且RMSECV值最小。 最终, CARS提取了44个波长, 占全波长的3.42%。 图3(b)为CARS提取的波长分布图。
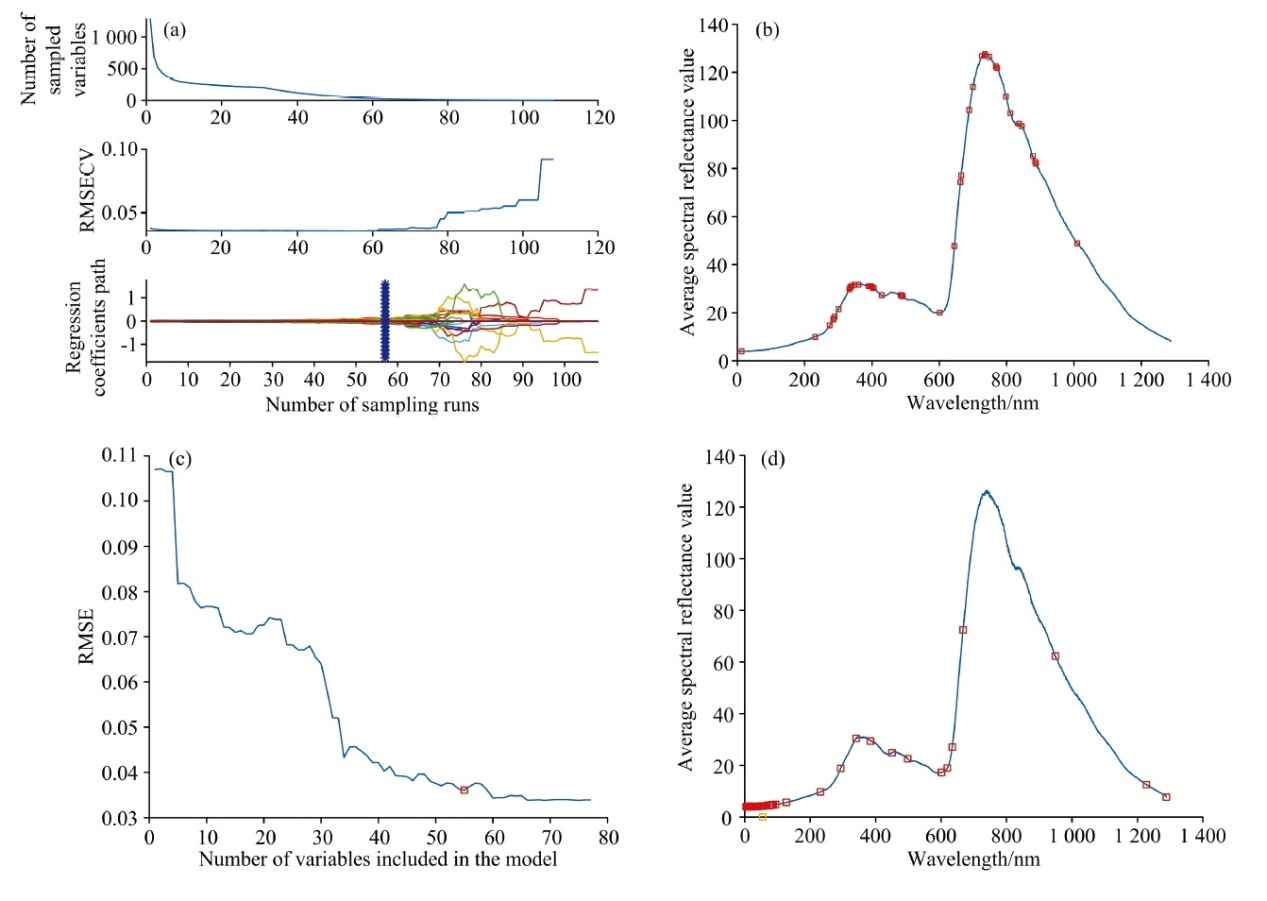 | 图3 特征波长的选择 (a): CARS提取特征波长过程的最优变量图; (b): CARS提取的特征波长分布图; (c): SPA提取选特征波长时RMSE变化趋势图; (d): SPA提取特征波长分布图Fig.3 The selection of the feature wavelengths (a): Optimal variable plot for feature wavelength extraction in CARS process; (b): Distribution map of feature wavelengths extracted by CARS; (c): Trend plot of RMSE variation with number of selected feature wavelengths using SPA; (d): Distribution map of feature wavelengths extracted by SPA |
2.3.2 SPA提取的特征波长
图3(c)为SPA进行特征波长筛选时RMSE随波长个数变化趋势图, 由图3(c)可知, 随着波长个数增加, RMSE值不断波动, 当波长个数为56时, RMSE值基本不变。 SPA从1 288个波长中提取了56个特征波长, 占全波长4.35%。 图3(d)为SPA提取的波长分布图。
2.3.3 特征波长的确定
对比图3(b)和图3(d)可知, CARS和SPA两种方法提取的特征波长个数相近, 尽管分布范围不同, 但都极大程度上降低了原始波长的维度。 为获取最优表征PAE含量的光谱值, 将两种方法提取的特征波长对应的光谱值分别输入到PLSR、 BP神经网络、 RF、 XGBoost4种预测模型。 表3为由特征波长构建的4个模型时
| 表3 基于2种特征波长提取方法的光谱值模型的 |
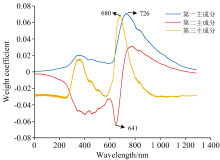
对紫苏高光谱图像进行PCA分析, 可知前3个主成分图累积贡献率高于99%。 图4为紫苏高光谱图像PCA分析后所得的PC1、 PC2和PC3图, 图中前3个PC图紫苏脉络清晰, 而其余PC图像噪声较大图像不清晰, 故舍弃, 因此可利用前3个PC确定有效波长图像。 图5为各波长在前3个PC中的权重系数图, 分别选择权重系数绝对值最大值对应的波长(即为641、 680和726 nm)图像为有效波长图像。
 | 图4 紫苏PC1、 PC2和PC3图Fig.4 The figures of Perilla Frutescens corresponding to PC1, PC2, and PC3 |
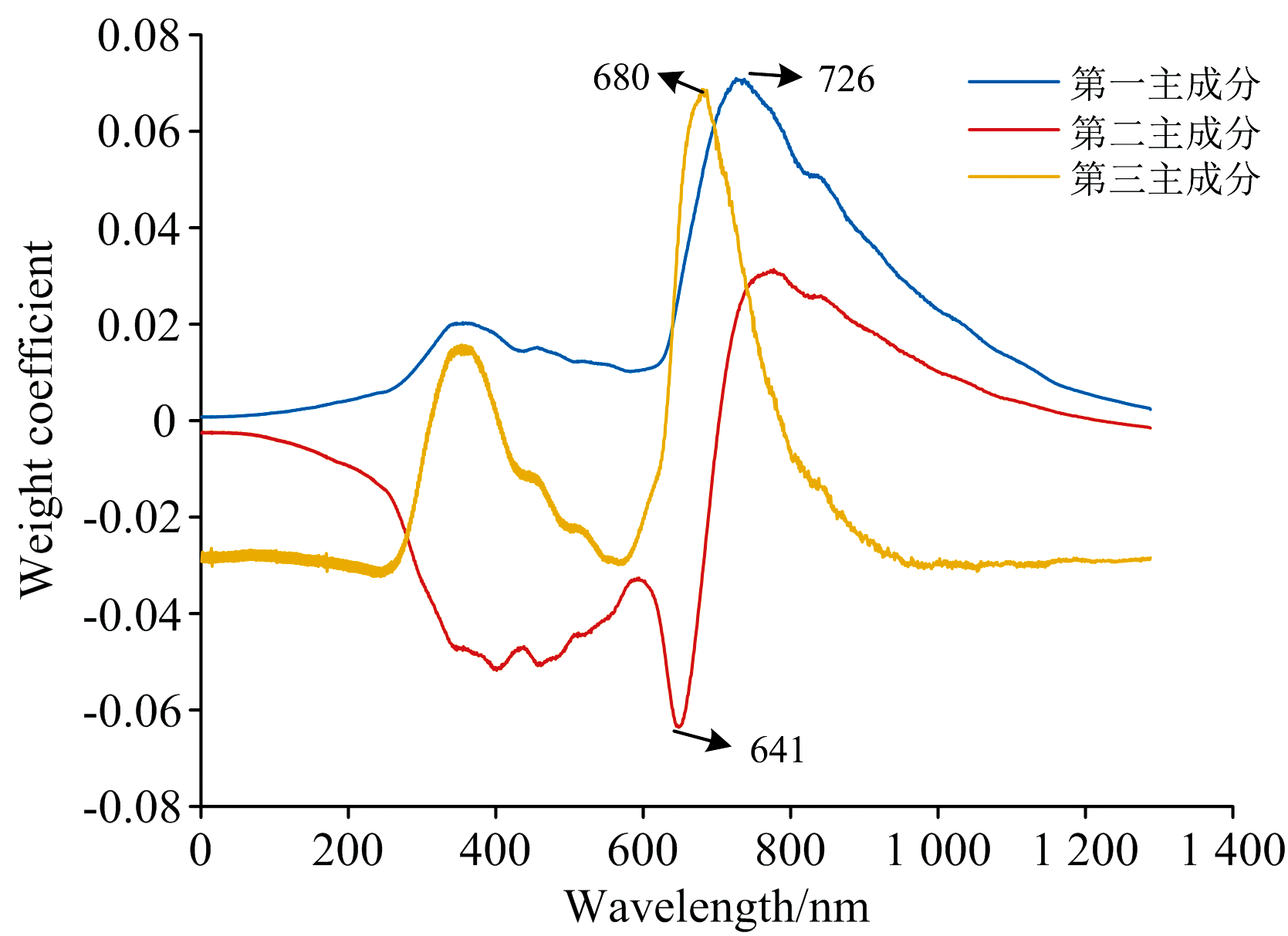 | 图5 各波长在三个主成分中的权重系数图Fig.5 Weight coefficient map of each wavelength in the three principal components |
图6为641 nm紫苏图像三层小波分解图, 图像低频和高频部分随分解层数升高被进一步分解, 使图像整体结构更加细致化。 每幅有效波长图像经小波变换可得1个低频能量值, 将每个紫苏样本的三幅有效波长图像分别进行小波变换, 最终400个样本计算得到小波能量值可构造为400× 3的矩阵。
 | 图6 641 nm紫苏图像三层小波分解图Fig.6 Three-level wavelet decomposition of the Perilla Frutescens image at 641 nm wavelength |
2.6.1 单类特征输入向量预测模型构建
表4为纹理特征值、 小波能量值作为输入向量的模型构建评定结果。 对比表3和表4可知, 经LOWESS预处理CARS提取的特征波长光谱值作为输入向量, 预测模型构建能力好于仅纹理特征值和仅小波能量值, 表明光谱值、 纹理特征值、 小波能量值都包含部分与PAE相关的信息, 但是特征波长光谱值包含的PAE信息量要高于纹理特征值和小波能量值, 其中CARS提取的特征波长对应的光谱值建立的XGBoost预测能力最佳, 训练集
| 表4 基于图像特征输入向量预测模型产生的 |
2.6.2 多类特征融合输入向量预测模型构建
依据1.8.1, 特征波长光谱值+纹理特征、 特征波长光谱值+小波能量值、 特征波长光谱值+纹理特征+小波能量值三种组合构建的多特征融合输入向量经PCA融合后, 累计贡献率大于99%的PC个数分别为2、 3、 3, 即为输入向量的维数。 表5为特征融合输入向量预测模型构建的评定结果, 将表5与表3、 表4对比可知, 不同输入向量在PLSR、 BP神经网络、 RF、 XGBoost4种预测模型中预测能力不同, 多特征融合输入向量较单特征输入向量的
| 表5 基于特征融合输入向量预测模型的 |
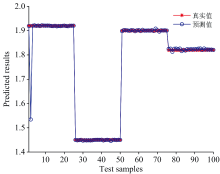
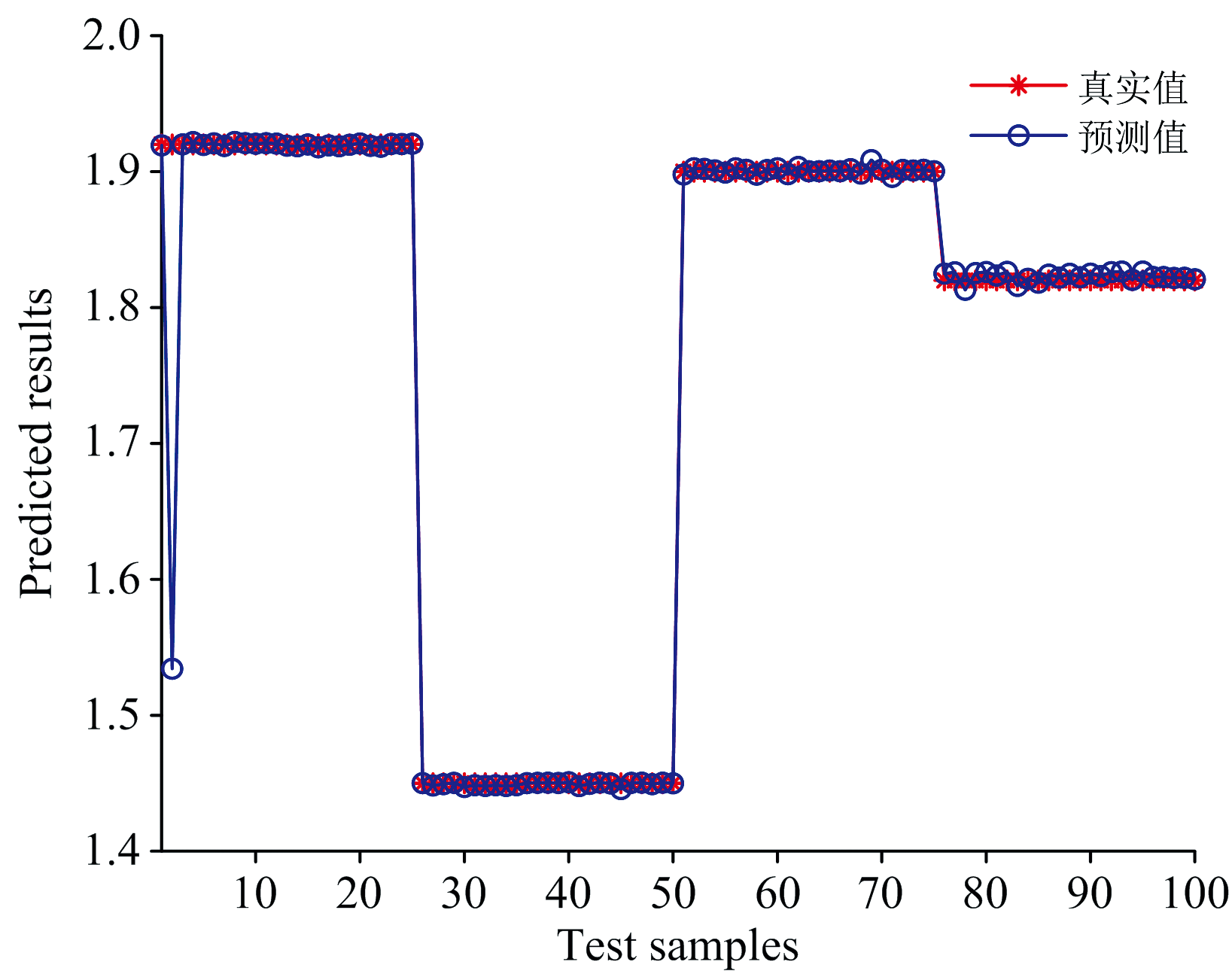 | 图7 测试集最优预测结果Fig.7 The optimal prediction results of test set |
选用4地出产的紫苏为研究对象, 采集紫苏高光谱信息并提取有效波长图像的纹理特征值和小波能量值, 将光谱值经预处理和特征波长提取后, 与纹理特征值和小波能量值构建单类特征输入向量和多类特征融合的输入向量, 对比预测模型的构建效果, 得到了紫苏中PAE含量的最优表征向量和最优预测模型, 主要结果与结论如下。
(1) 原始光谱数据经SG、 SNV、 MSC和LOWESS四种方法进行预处理, 对处理后的光谱值构建不同预测模型, 经对比分析预测效果, 最佳预处理方法是LOWESS。
(2) 对比CARS和SPA两种提取特征波长方法, 由特征波长对应的光谱值建立的预测模型可知, CARS提取的44个特征波长对应的光谱值表征PAE的能力最好。
(3) 对比单类特征输入向量预测模型构建效果可知, CARS提取的特征光谱值建立的模型构建效果比两种图像特征的构建效果好。
(4) 将特征波长光谱值+纹理特征、 特征波长光谱值+小波能量值、 特征波长光谱值+纹理特征+小波能量值三种组合方式构建为多类特征融合输入向量, 与单类特征输入向量模型构建效果对比可知, 特征波长光谱值+纹理特征值+小波能量值组合融合所得的前3个PC作为输入向量时模型构建效果最好, 并且最佳预测模型为XGBoost。
研究表明, 采用高光谱特征波长光谱值融合有效波长图像的纹理特征值和小波能量值构建的XGBoost模型对紫苏中PAE含量的预测最为准确。 该研究成果为PAE提取和开发提供了一种有效方法, 同时也可为紫苏品质和品种鉴别提供一种判据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|