
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于鞍山式铁矿成像光谱的融合算法研究
[毛亚纯1  , 文杰
, 文杰1, * , 曹旺1 , 丁瑞波1 , 王世佳2 , 付艳华3 , 徐梦圆1 ]
, 文杰, 曹旺|
|


作者简介: 毛亚纯, 1966年生,东北大学资源与土木工程学院教授 e-mail: dbdxmyc@163.com
铁矿资源是我国经济发展和社会进步的物质基础。 在铁矿开采过程中, 快速精准地确定铁矿品位, 对矿山开采决策及经济效益具有重要影响。 高光谱成像技术具有影像覆盖范围广、 精度高等优势, 已广泛应用于矿石分类及成分反演等领域。 然而目前高光谱成像传感器的波段范围主要为可见短近红外(Vis-SWIR)和近红外(NIR)两类, 且两类数据多为独立获取, 缺乏连续性, 采用单一数据所建模型的精度往往偏低。 因此融合多传感器所获光谱数据, 可有效解决单一传感器波段范围小、 包含目标特征波段少等问题, 提高基于高光谱成像技术的铁矿品位反演精度。 使用Pika L与Pika NIR-320高光谱成像仪, 分别在Vis-SWIR与NIR两个波段范围内采集鞍山式铁矿的成像光谱数据, 提出了基于互信息(MI)的光谱串联融合方法, 该方法首先对两组光谱数据进行预处理, 然后对处理后的数据进行互信息计算以此对光谱数据进行串联融合。 最后分别以Vis-SWIR、 NIR以及基于不同波段串联融合的光谱数据为数据源, 建立RBF神经网络品位反演模型, 并以融合前后光谱数据所建模型的准确性与精度为融合算法有效性的判别指标。 结果表明, 光谱数据串联融合后所建模型的准确性与精度高于单独使用Vis-SWIR、 NIR光谱数据所建模型的准确性与精度。 与基于其余波段串联融合的光谱数据相比, 在基于互信息计算得出的959.89 nm处串联融合后光谱数据所建模型的准确性与精度最高, R2为0.88, RPD为2.97, RMSE为4.464, MAE为3.32。 该研究针对多传感器光谱融合提出了一种新思路, 对成像光谱技术应用于铁矿品位反演具有现实指导意义。
Iron ore resources are the foundation of our economic development and social progress. In the process of iron ore mining, the rapid and accurate determination of iron ore grade has an important influence on the mining decision and economic benefit. Hyperspectral imaging technology has the advantages of wide image coverage and high accuracy and has been widely used in ore classification and composition inversion. However, the band range of existing hyperspectral imaging sensors mainly includes visible and shortwave infrared (Vis-SWIR) and near-infrared (NIR). The two data types are mostly acquired independently, lacking continuity, and the accuracy of the model built with single data is often low. Therefore, the fusion of spectral data obtained by multiple sensors can effectively solve the problems of the small band range of a single sensor and few bands containing target characteristics and improve the accuracy of iron ore grade inversion based on hyperspectral imaging technology. In this study, Pika L and Pika NIR-320 hyperspectral imagers were used to collect imaging spectral data of Anshan iron ore in Vis-SWIR and NIR bands, respectively, and a spectral series fusion method based on mutual information (MI) was proposed. Firstly, the two groups of spectral data were preprocessed. Then, mutual information is calculated on the processed data to conduct a series fusion of spectral data. Finally, Vis-SWIR, NIR, and spectral data based on the series fusion of different bands were used as data sources to establish RBF neural network grade inversion models, and the accuracy and precision of the models based on spectral data before and after fusion were used as the discrimination index of the effectiveness of the fusion algorithm. The results show that the accuracy and precision of the model built after series fusion of spectral data is higher than that built using Vis-SWIR and NIR spectral data alone. Compared with the spectral data based on series fusion of other bands, the accuracy and precision of the model established based on the mutual information calculation of series fusion spectral data at 959.89 nm are the highest, R2 0.88, RPD 2.97, RMSE 4.464, MAE 3.32. This study proposes a new idea for multi-sensor spectral fusion, which has practical significance for the application of imaging spectrum technology in the inversion of iron ore grade.
近年来高光谱技术发展迅速, 因其具有效率高、 周期短、 可实现品位原位测定等优势, 已被广泛应用于矿岩识别[1, 2]和矿石品位分析[3, 4]等领域。 成像光谱具有空间可识别性, 可应用于大范围的分析研究, 然而目前高光谱成像传感器的波段范围主要为可见短近红外(Vis-SWIR)与近红外(NIR)两类, 单一传感器获得光谱数据的波段范围小, 包含目标特征波段少, 而光谱融合可利用光谱数据间互补性将多传感器所测数据融合, 使目标信息更加全面与准确。 数据级融合是一种较为常用的光谱融合策略, 该方法以矩阵的形式将多传感器测得光谱数据按一定方式连接, 尽可能多的保留了原始数据信息。
对此, 国内外诸多学者基于光谱数据级融合开展了大量研究。 Moros[5]等将光谱数据级融合分为数据串联融合、 累加融合、 外积融合以及外和融合四种不同的融合算法; 徐伟杰等[6]对火星表面矿物可见近红外(Vis-NIR)光谱与拉曼(Raman)光谱分别采用串联融合与累加融合的方法进行融合, 提高了相关矿物分类模型的预测准确度; Terra等[7]通过外积融合将土壤的可见近红外光谱与中红外(MIR)光谱进行融合, 提高了土壤有机碳(SOC)含量预测精度; Xu[8]等将激光诱导击穿光谱(LIBS)和衰减全反射傅里叶变换中红外光谱(FTIR-ATR)的数据通过外积融合法融合后, 建立了土壤有机质含量(SOM)高精度和准确性的预测模型; Xu[9]利用外积融合法将X荧光光谱(XRF)和可见近红外光谱融合后, 提高了土壤Cr含量预测模型的精度; 李志刚等[10]提出基于不同导数阶次的光谱融合策略, 提高了溶液中葡萄糖含量的预测能力。 上述研究表明, 融合多传感器可有效提高反演模型的准确性与精度, 但传统研究大多将边缘交叉波段去除以解决串联融合过程中出现的数据冗余问题[6, 11], 但若该波段区间存在目标特征信息则会降低反演模型准确性与精度。 本研究采集的两组光谱数据在886~1 025 nm间存在重合, 但受Fe3+影响, 鞍山式铁矿在880~1 000 nm附近存在显著的光谱特征[12, 13], 保留此区间光谱数据可有效提升反演模型的准确性与精度。
如何在光谱串联融合中解决数据冗余问题的同时保证数据信息的完整性, 有效实现光谱数据串联融合, 有重要的研究价值。 为此, 使用Pika L与Pika NIR-320高光谱成像仪分别采集192件块状鞍山式铁矿样品Vis-SWIR与NIR的成像光谱数据, 提出了基于互信息的光谱串联融合方法, 并以Vis-SWIR、 NIR以及基于不同波段串联融合的光谱数据建立RBF神经网络品位反演模型, 以此评价融合算法的有效性。
辽宁省鞍山-本溪地区探明铁矿储量超100亿吨, 工业储量超40亿吨, 居全国首位, 且易于开采, 具有极大的工业价值。 以辽宁省鞍山市鞍千矿露天采场为研究区, 为使后续光谱处理方法及所建模型具有普适性, 采集的样本应具有代表性, 在研究区内不同地点均匀采集鞍山式铁矿石, 采集后钻孔、 取芯以及切块处理, 制成192件块状铁矿样品, 如图1所示。
 | 图1 实验样品Fig.1 Experimental samples |
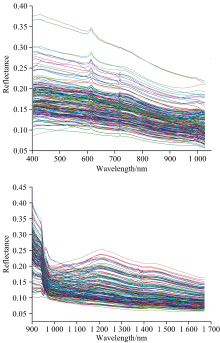
使用美国Resonon公司生产的Pika L与Pika NIR-320高光谱成像仪对样品进行光谱测试, 仪器具体参数如表1所示。 实验过程中, 将样品放置于移动平台上, 以4盏卤素灯为光源, 以标准白板为定标背景, 分别采集192件样品Vis-SWIR成像光谱数据与NIR成像光谱数据。 使用与高光谱成像仪配套的Spectronon Pro软件将采集的原始DN值数据转化为反射率数据。 通过ENVI圈定每个样品在成像光谱数据中所对应的全部像元为感兴趣区(ROI), 并提取ROI内的平均光谱为该样品的光谱信息。 剔除Pika L在可见光区域采集的噪声波段与Pika NIR-320在近红外长波区域采集的噪声波段, 保留404~1 025.35 nm范围内290个波段数据和886.49~1 667.87 nm范围内158个波段数据用于后续分析与计算, 鞍山式铁矿样品的Vis-SWIR与NIR光谱曲线如图2所示。
| 表1 成像光谱仪参数 Table 1 Parameter of imaging spectrometer |
 | 图2 样品的Vis-SWIR和NIR光谱曲线Fig.2 Vis-SWIR and NIR spectral curves of samples |
成像光谱测试结束后, 以化学测试的方法确定各样品的铁品位, 鞍山式铁矿样品的平均品位为29.98%, 品位分布在11.4%~66.59%之间。
为扩大波段覆盖范围, 增加样品特征信息, 本研究采用数据串联融合对Vis-SWIR与NIR光谱数据进行融合处理, 数据串联融合方法是将同一样品的Vis-SWIR与NIR光谱数据首尾串联连接, 融合后光谱数据的波段数等于融合前两传感器波段之和, 如式(1)所示
式(1)中, VIS-NI
互信息(mutual information, MI)是信息论中的一个基本概念, 通常用于描述两个系统间的统计相关性, 或是一个系统内包含另一个系统内信息的多少, 与只关注线性相关性的相关系数相比, 互信息包含所有独立性(线性相关性与非线性相关性)。 互信息计算公式如式(2)
式(2)中, p(x, y)是X和Y的联合概率分布函数, p(x)和p(y)分别是X和Y的边缘概率分布函数, X和Y分别为Pika L与Pika NIR-320在886.49~1 025.35 nm采集的Vis-SWIR与NIR光谱数据。 基于互信息的融合波段选择方法如下:
(1)重采样
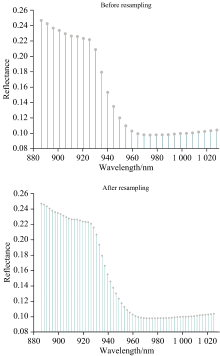
因Pika L与Pika NIR-320传感器间光谱分辨率存在差异, 为实现两传感器相同波段光谱数据特征的对比分析, 需对低分辨率NIR光谱数据进行重采样。 为此以Pika L采集的63个波段为基准, 使用三次样条插值方法对Pika NIR-320重合范围内采集的光谱数据重采样, 重采样后波段的范围为886.24~1 025.35 nm, 包含63个波段, 将两组光谱数据分别记为矩阵
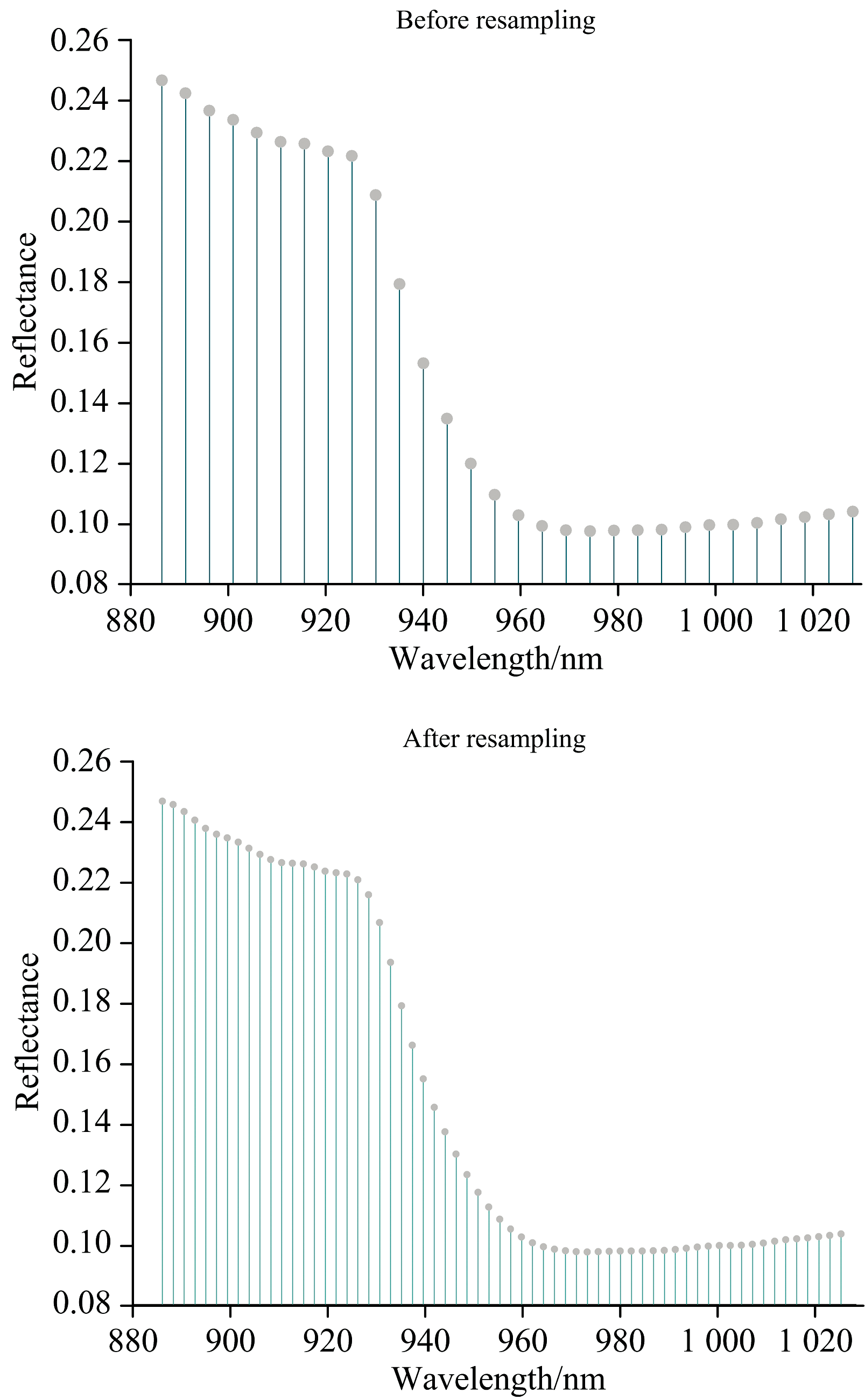 | 图3 部分样品重采样前后光谱波段数据对比Fig.3 Comparison of spectral data before and after resampling |
(2)一阶微分
受仪器自身条件限制与实验背景影响, 在相同波段处, Pika L采集的光谱数据与Pika NIR-320重采样的光谱反射率大小存在差异。 为消除传感器间差异与背景的干扰, 保留光谱数据的变化趋势, 分别对Pika L重合区间内采集的光谱数据与Pika NIR-320重合区间内重采样后的光谱数据做一阶微分处理, 得到
(3)互信息计算
为消除个别一阶微分数据间互信息不稳定的影响, 以五个相邻的微分数据为一组计算互信息, 即
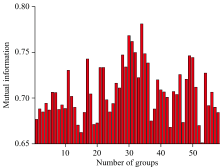
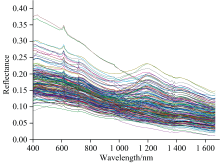
互信息计算结果如图4所示, 分布在0.65~0.78之间, 在第34组取得最大值0.78, 对应的中间波段为959.89 nm, 因此在该波段处对所有光谱数据进行串联融合。 因不同传感器的光谱响应特征和测试背景存在一定差异, 相同波段处测得的光谱反射率大小不同, 光谱数据串联融合后出现阶跃现象, 因此以959.89 nm处Pika L采集的光谱数据与Pika NIR-320重采样后光谱数据的差值对NIR光谱数据进行校正, 校正后数据NIRc=NIR+
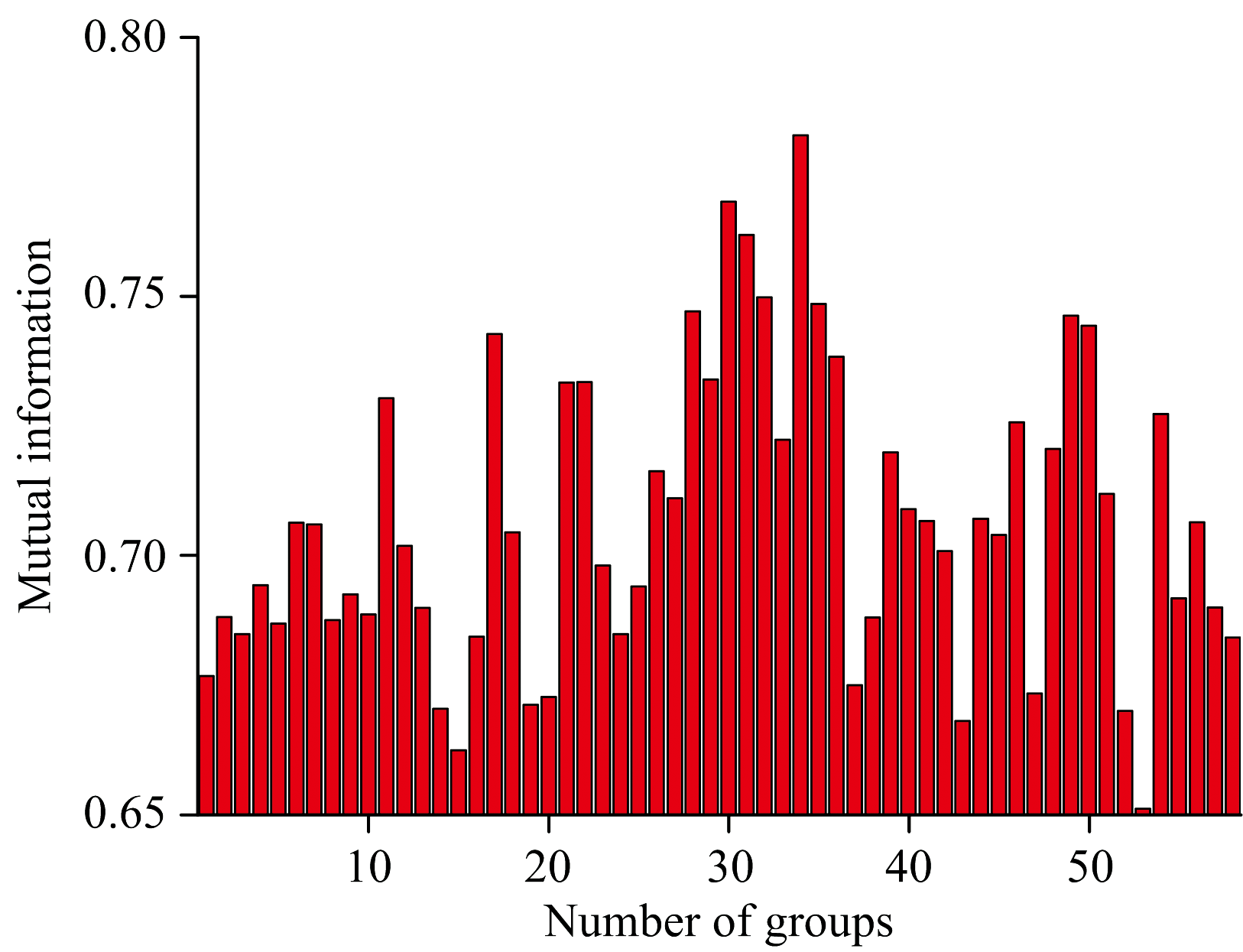 | 图4 互信息分布图Fig.4 Mutual information distribution |
 | 图5 融合后光谱曲线Fig.5 Spectral curves after spectral fusion |
为探讨基于互信息的光谱串联融合方法对鞍山式铁矿成像光谱数据融合的有效性, 利用RBF神经网络模型, 对未融合和在不同波段处串联融合后的光谱数据建立品位反演模型, 以模型的决定系数R2、 相对分析误差RPD、 平均绝对误差MAE、 均方根误差RMSE作为反演模型准确性与精度的评价指标, 同时作为光谱融合有效性的评价准则。
RBF神经网络是具有单隐含层的前向神经网络, 隐含层的变换函数是对中心点径向对称衰减的非负非线性函数。 一般采用高斯函数作为隐含层激活函数, 该函数是局部响应函数, 具有学习速度快、 避免出现局部极值等优点, 在解决非线性问题中有着广泛的应用[14]。 选择162个样品为训练样本, 30个样品为测试样本, 以RBF神经网络对剔除噪声后的Vis-SWIR光谱数据(886.49~959.89 nm)与NIR光谱数据(959.89~1 667.87 nm)分别建立品位反演模型, 反演模型的准确性与精度如表2所示, 对基于不同波段串联融合的光谱数据分别建立品位反演模型, 反演模型的准确性与精度如表3所示。
| 表2 Vis-SWIR及NIR数据的反演结果 Table 2 Inversion results of Vis-SWIR and NIR data |
| 表3 不同融合波段的反演结果对比 Table 3 Comparison of inversion results of different fusion bands |
综合分析表2与表3结果可知, 光谱数据串联融合后所建模型的准确性与精度高于单独使用Vis-SWIR, NIR光谱数据所建模型的准确性与精度。 可见, 光谱数据串联融合可有效扩大波段覆盖范围, 完善样品特征信息, 从而提高鞍山式铁矿品位反演模型的准确性与精度, 有利于鞍山式铁矿品位的准确快速反演。
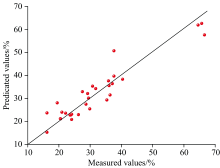
由表3可知, 基于不同波段对光谱数据进行串联融合会影响所建模型的准确性与精度, 且随着互信息降低, 光谱数据基于不同波段串联融合后所建模型的准确性与精度整体呈现降低趋势, 当互信息最大值为0.78时, 对应959.89 nm处串联融合的光谱数据所建模型准确性与精度最高, 反演模型的铁品位预测值与真实值拟合图如图6所示, R2为0.88, 拟合效果较佳。 该结果表明, 基于互信息计算的959.89 nm波段融合后的数据建立的品位反演模型精度最高, 证明了基于互信息的光谱波段融合算法能够有效提高反演模型的准确性, 且959.89 nm能够作为鞍山式铁矿可见短红外和近红外串联融合的最佳波段。
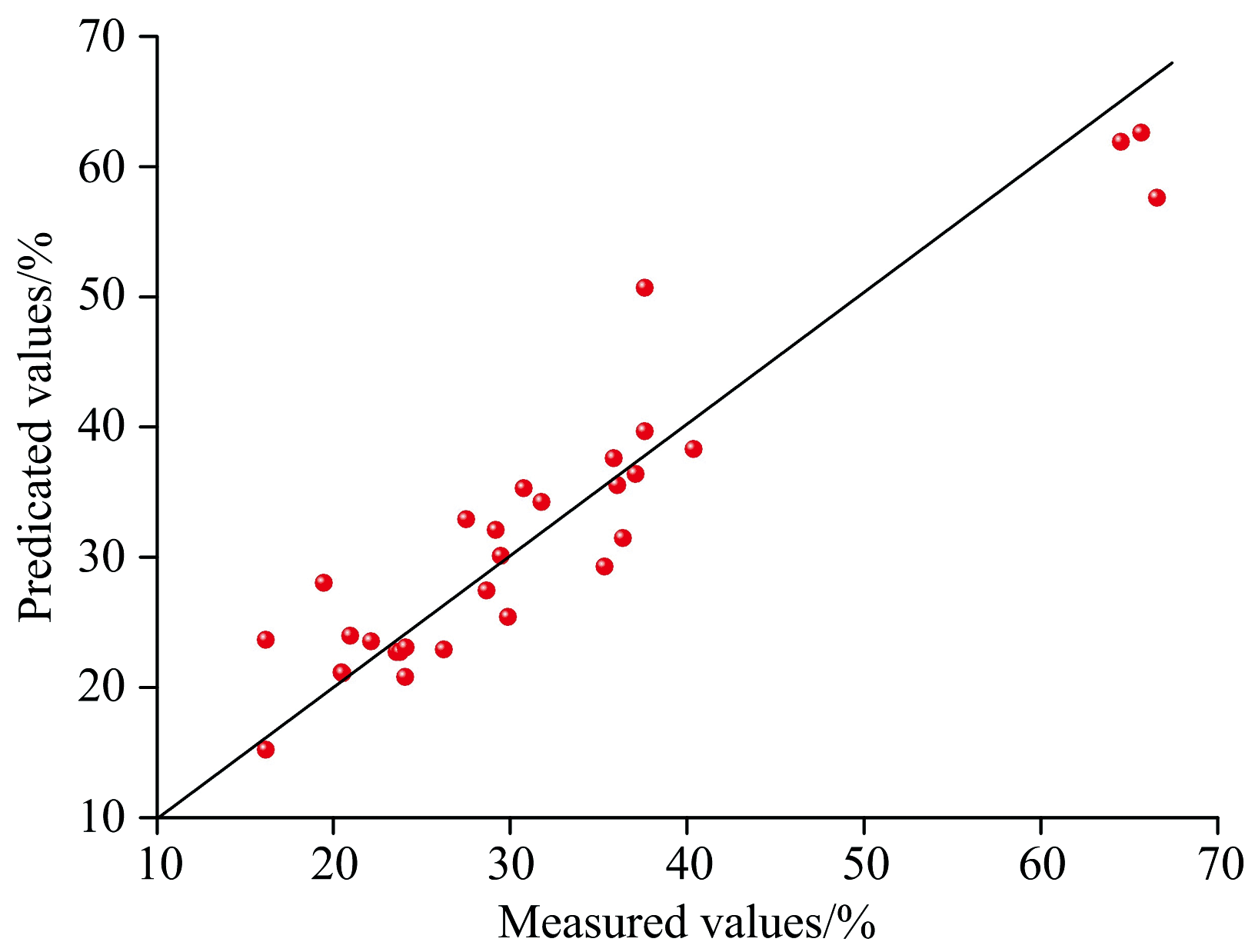 | 图6 预测值与真实值差异图Fig.6 The difference between the predicated value and the true value |
以192件鞍山式铁矿为实验样品, 使用Pika L与Pika NIR-320高光谱成像仪分别采集Vis-SWIR与NIR光谱数据, 提出了基于互信息的光谱串联融合方法, 对Vis-SWIR、 NIR以及基于不同波段串联融合的光谱数据, 利用RBF神经网络建立品位反演模型, 结论如下:
(1)与单独使用Vis-SWIR, NIR光谱数据相比, 光谱数据串联融合后所建鞍山式铁矿品位反演模型的准确性与精度更高;
(2)基于不同波段对光谱数据进行串联融合会影响所建模型的准确性与精度, 基于互信息的光谱串联融合方法可有效计算出鞍山式铁矿可见短近红外和近红外波段的最佳融合波段, 与在其余波段串联融合后光谱数据相比, 在互信息计算的959.89 nm处串联融合后所建模型的准确性与精度最高, R2为0.88, RPD为2.97, RMSE为4.464, MAE为3.32。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|