


{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱结合模糊非相关QR分析的生菜储藏时间辨别
[胡彩平1, *  , 傅兆民
, 傅兆民2, * , 许鸿嘉2 , 武斌3 , 孙俊4 ]
, 傅兆民, 许鸿嘉|
|


作者简介: 胡彩平, 1977年生, 金陵科技学院计算机工程学院副教授 e-mail: hucp@jit.edu.cn
生菜是人们经常食用的蔬菜之一, 生菜的储藏时间是影响生菜新鲜程度的重要因素。 所以研究一种简单、 快速、 非破坏性的生菜储藏时间的鉴别方法是非常必要的。 近红外光谱(NIR)分析能快速和准确的获取生菜的近红外光谱, 从而实现无损鉴别生菜储藏时间。 但是生菜的NIR数据中存在噪声信号和冗余信号, 为了消除光谱的噪声信号并提取特征信息, 提出了一种基于模糊非相关QR分析(FUQRA)的近红外光谱生菜储藏时间鉴别新方法。 首先, 需要降低原始NIR数据的维数, 通过使用主成分分析(PCA)将包含1 557个维度的光谱数据降至包含22个维度。 然后通过模糊非相关判别转换(FUDT)计算出特征向量, 利用特征向量建立鉴别向量矩阵, 并进行QR分解, 得到最终的鉴别向量矩阵。 最后以60个新鲜生菜样本为研究样本, 使用K近邻(KNN)方法进行分类, 用Antaris Ⅱ型NIR光谱仪对生菜样品进行近红外光谱检测和数据收集。 实验过程中每隔12小时对每个样本进行3次重复检测, 将这些数据取平均值作为实验数据。 随后利用多元散射校正(MSC)减少近红外光谱中的噪声信号。 为了验证所提出方法的有效性, 分别将主成分分析(PCA)结合KNN、 主成分分析和模糊线性判别分析(FLDA)结合KNN、 主成分分析和模糊非相关判别转换(FUDT)结合KNN以及主成分分析和模糊非相关QR分析(FUQRA)结合KNN四种算法分析结果进行比较。 将权重指数 m的不同取值产生的分类准确率进行比较, 选出最合适的权重指数和KNN的参数 K: m=2, K=3。 最终得到的分类准确率分别为43.33%、 96.67%、 96.67%和98.33%。 可以看出, 相比其他三个算法, 模糊非相关QR分析可以更好地实现对生菜储藏时间的鉴别。
Lettuce is one of the vegetables that people often eat, and the storage time of lettuce is an important factor affecting the freshness of lettuce. Therefore, it is necessary to develop a simple, fast, and non-destructive method to identify the storage time of lettuce. Near-infrared spectroscopy (NIR) can quickly and accurately detect the near-infrared spectrum of lettuce to realize the non-destructive identification of lettuce storage time. However, noise and redundant signals are in the NIR spectral data collected by the near-infrared spectrometer. To eliminate the noise information of the spectrum and extract the feature information, a novel method was proposed to identify the storage time of lettuce based on NIR spectroscopy and fuzzy uncorrelated QR analysis (FUQRA). Firstly, principal component analysis (PCA) was used to reduce the dimension of the original spectral data from 1557 dimensions to 22 dimensions. Secondly, after the feature vectors are obtained by fuzzy uncorrelated discriminant transformation (FUDT), the discriminant vector matrix is established by using the feature vectors, and the final discriminant vector matrix is obtained by QR decomposition. Finally, the k-nearest neighbor algorithm was utilized for classification. 60 fresh lettuce samples were selected as the research object. Firstly, the NIR spectral data of lettuce samples were collected by Antaris Ⅱ near-infrared spectrometer and detected once every 12 hours. Secondly, multivariate scatter correction (MSC) was used to reduce the noise signal in the NIR spectra. To verify the effectiveness of the proposed method, the experimental results were compared by four classification models: principal component analysis (PCA) combined with a K-nearest neighbor (KNN) algorithm, PCA and fuzzy linear discriminant analysis (FLDA) combined with KNN algorithm, PCA and fuzzy uncorrelated discriminant transformation (FUDT) combined with KNN algorithm and PCA and FUQRA combined with KNN algorithm. The classification accuracies produced by different values of the weight index m were studied, and the most appropriate parameters were selected: m=2, K=3. Under this condition, the classification accuracies of the four algorithms were 43.33%, 96.67%, 96.67%, and 98.33%, respectively. It can be seen that compared with the other three algorithms, FUQRA can better realize the identification of lettuce storage time.
蔬菜是人们日常生活中必不可少的食物, 生菜是人们经常食用的蔬菜之一, 生菜中富含有人体所需要的营养物质。 随着人们的生活工作繁忙, 也没有时间每天去购买新鲜的生菜, 如何为生菜保鲜就非常重要。 当前, 人们可以用冰箱来为生菜保鲜, 但生菜的储藏时间是影响生菜新鲜程度的重要因素。 随着储藏时间的延长, 生菜中亚硝酸盐含量就会不断增加而损害人体健康, 长期储藏会导致其中的大多数营养物质的含量下降, 所以研究一种简单、 快速、 非破坏性的生菜储藏时间的鉴别方法是非常必要的。
近红外光谱是一种无损、 绿色环保的检测技术, 在农产品和食品无损检测等领域已经得到广泛应用[1, 2, 3]。 使用近红外光谱仪采集的生菜近红外光谱数据, 能够用于准确鉴别生菜储藏时间, 但是可能存在噪声信号。 为了对含噪声信号的生菜的近红外光谱进行鉴别, 提出了一种基于模糊非相关QR分析(fuzzy uncorrelated QR analysis, FUQRA)的近红外光谱生菜储藏时间鉴别的新方法。
由于生菜初始近红外光谱数据维数高达1 557维, 包含许多冗余信息, 不利于后续分类器的准确分类, 因此需要使用主成分分析(principal component analysis, PCA)进行数据降维。 主成分分析算法是一种常用的数据降维技术, 用于从高维数据中提取出最具代表性的主要特征。 通过主成分分析, 可以实现数据的降维, 去除冗余信息, 保留了数据中最重要的特征[4, 5]。 这有助于减少数据集的维度, 简化数据分析和可视化, 并且有助于发现数据中的模式和关系[6]。
近红外光谱数据通常存在吸收峰的重叠, 不同成分的光谱特征峰可能出现在相似的波长范围内。 传统的线性判别分析(linear discriminant analysis, LDA)用于特征提取, 其目标是将样本投影到低维子空间, 以最大化类别间的差异并最小化类别内的差异[7]。 然而, LDA采用硬性分类方式, 无法有效处理模糊性, 也不能考虑样本在多个类别之间的隶属度。 与LDA不同, 模糊线性判别分析(fuzzy linear discriminant analysis, FLDA)专注于解决模糊性问题[7]。 FLDA在LDA基础上引入了模糊隶属度函数, 容许样本在不同类别之间具有模糊的隶属度, 从而更好地处理吸收峰重叠和模糊或不确定标签[8]。 因此, FLDA更适用于处理近红外光谱数据中的模糊性, 提供了更具弹性的分类方法, 使得在复杂的光谱数据中更容易进行分类和解释[9]。
FLDA虽然解决了LDA的硬性分类问题, 但是FLDA计算得到的特征具有相关性, 为了解决此问题, 在FLDA和非相关判别变换(uncorrelated discriminant transformation, UDT)的基础上形成了模糊非相关判别转换(fuzzy uncorrelated discriminant transformation, FUDT)[10]。 与LDA和FLDA不同, FUDT处理数据得到的特征是非相关的; 与UDT相比, 特别是在处理近红外光谱中的一些重叠数据点时[11], FUDT具有更好的分类准确率, 能够更好地处理近红外光谱数据中的模糊性。 FUDT处理得到的特征虽然是非相关的, 但是其特征向量不是正交的, 即FUDT存在特征向量非正交性问题。 目前该问题的研究还未见文献报道。
为了解决模糊非相关判别转换特征向量的非正交性问题, 本工作在FUDT基础上, 对FUDT的特征向量组成的矩阵进行QR分解以得到正交的特征向量, 该算法即为本文提出的模糊非相关QR分析。 当数据投影到该正交特征向量上形成新的数据, 然后再用分类器进行数据分类。 在获取生菜光谱数据后, 对数据进行光谱预处理和数据压缩, 然后用模糊非相关QR分析提取数据的鉴别信息, 最后用K近邻算法(K-nearest neighbors, KNN)[12, 13]进行分类, 取得了比模糊非相关分析更高的准确率。 所以, 模糊非相关QR分析是一种有效的光谱数据鉴别信息提取算法。
从当地超市采集生菜样本60个, 保证所有生菜样本为同一品种, 采摘时间、 大小、 菜叶颜色等差异很小, 可以减小误差。 将样本洗净并通风晾干, 放入冰箱冷藏, 仿真正常生活情景的存放环境。 每隔12 h取出样本, 并尽快进行近红外光谱采集。 使用美国ThermoAntarisⅡ 型近红外光谱分析仪采用反射积分球模式进行近红外光谱采集。 采集前, 将分析仪开机预热1 h。 采集时, 实验室温度保持在15 ℃, 相对湿度保持在70%左右。 对每个样品扫描32次并取均值, 得到生菜样品的漫反射光谱均值。 扫描波数范围: 10 000~4 000 cm-1, 扫描间隔为3.856 cm-1。 经过3次NIR检测, 获得了180个光谱数据, 每个数据的维数是1 557。
模糊非相关QR分析(FUQRA)原理是将模糊非相关判别转换(FUDT)得到的特征向量进行QR分解, 分别将样本数据投影到Q上, 从而得到新的样本数据。 新的样本数据可用于后续分类器的分类。 具体的步骤如下:
步骤一: 计算每类均值, 以每类均值作为聚类中心
式(1)中, 矩阵中的v1表示第一类训练样本的均值, v2为第二类训练样本的均值, v3为第三类训练样本的均值。
计算模糊隶属度
式(2)中, uik为第k个样本xk隶属于第i类的模糊隶属度; c为分类的类别数, vi为第i类的类中心值, m为权重指数, m∈ (1, +∞ ), n为样本数。
步骤二: 计算训练样本的模糊类间离散度矩阵SfB和模糊总体离散度矩阵SfT
式(3)和式(4)中,
步骤三: 计算特征值和特征向量
将最大特征值γ 1所对应的特征向量Ψ 1作为第一个特征向量。
步骤四: 转换特征空间。 根据PSfBΨ r+1=λ SfTΨ r+1, P=I-SfTΨ T(Ψ SfTΨ T)-1Ψ 计算第r+1个特征向量Ψ r+1。 则可得到c-1个特征向量组成的向量矩阵M=[Ψ 1, Ψ 2, Ψ 3, …, Ψ c-1]T。
步骤五: 对步骤四中的矩阵M进行QR分解, M=QR, 其中, Q∈ Rm× p, R∈ Rp× c, p=rank(M), 从而得到的新的鉴别向量矩阵Q。
步骤六: 根据新的鉴别向量矩阵Q, 将测试样本集投影到Q中, 对数据实现转换。 把第k(1≤ k≤ N2)个测试样本yk投影到Q上, 可得到zk
原始的光谱数据存在噪声信号与冗余信息。 使用主成分分析(PCA)对数据进行预处理, 消除上述影响。 首先采用多元散射校正技术(MSC)对原始光谱数据进行预处理, 消除光谱的散射效应。
预处理后的光谱数据存在着大量的冗余信息, 增加了数据分析与计算的复杂度, 且此时样本维度数远远大于样本数量, 直接进行后续的相关分析, 会导致小样本问题[14]。 因此, 可以利用PCA方法对光谱数据进行降维, 以提取主要的特征信息。 图1显示了前1~22个主成分在近红外光谱数据中的累计贡献率。 通过图1可以了解到, 前22个主成分的累计方差贡献率为99.99%。 所以, 选取前22个主成分, 既能保留近红外光谱的数据特征信息, 又能剔除掉冗余信息。
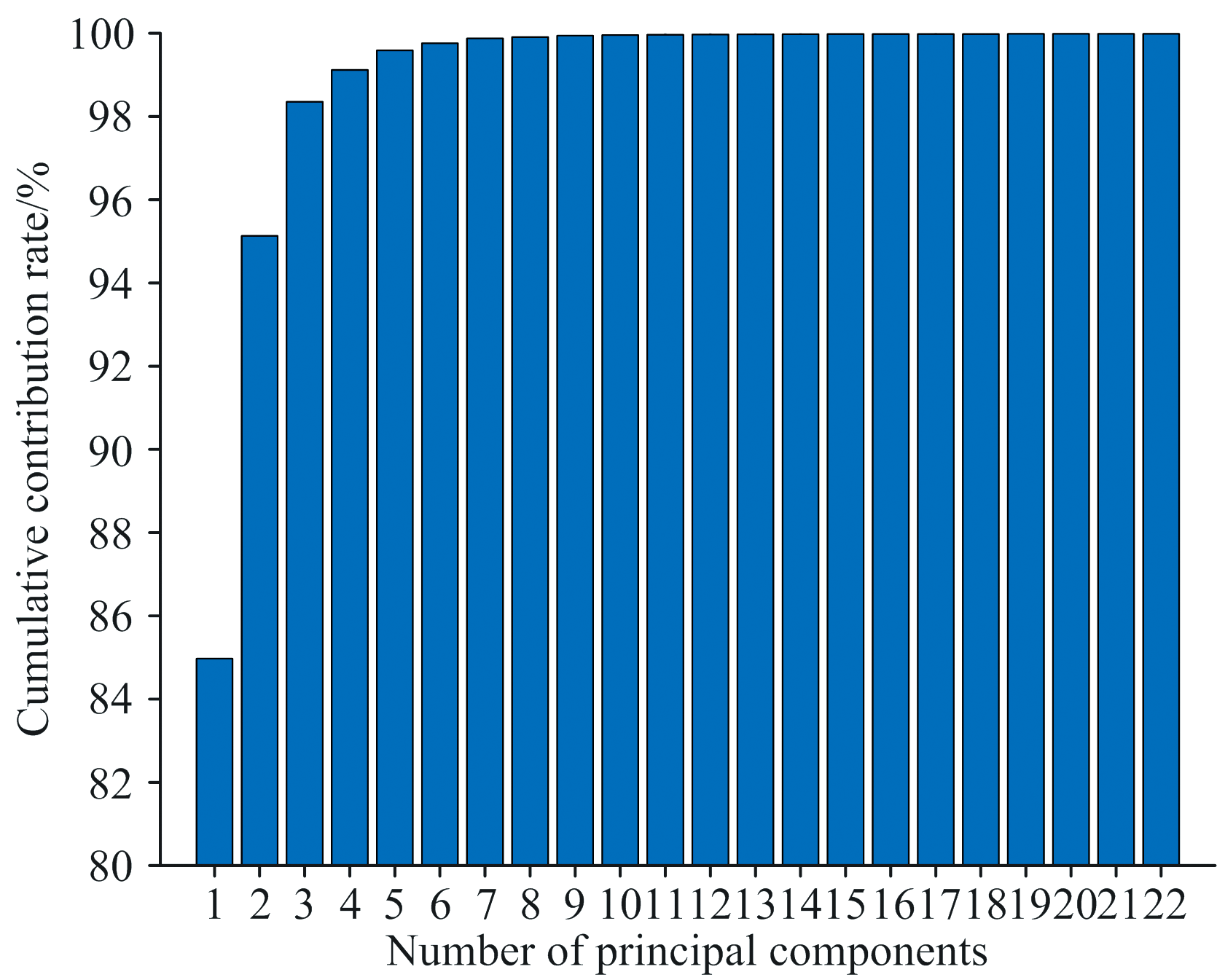 | 图1 前22个主成分的累计方差贡献率Fig.1 Cumulative variance contribution rate of the first 1— 22 principal components |
将间隔12 h测得的3组光谱数据设为3个不同的类, 类别数c=3, 每类共60个样本, 总共180个样本, 即样本数n=180。 对180个样本进行PCA后, 将每类的60个样本按检测顺序编号。 将样本划分为训练集和测试集, 即: 120个训练样本, 60个测试样本。 随后, 提供与训练集、 测试集相对应的标签, 为进行KNN做准备。 接下来, 取K=3, 直接使用PCA降维后的60个测试样本进行KNN鉴别, 并使用测试样本确定分类准确率为43.33%。
2.3.1 确定聚类中心及其他参数
对PCA处理后的样本数据进行模糊化处理。 确定类别数为3, 每个类别的训练样本为40个。 通过计算每类的均值, 以每类训练样本的均值作为初始类中心, 计算模糊隶属度和类中心。
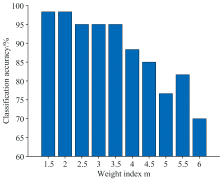
m的取值是影响分类结果的重要因素, 因此分别计算m取1.5、 2、 2.5、 3、 3.5、 4、 4.5、 5、 5.5、 6时FUQRA的分类准确率, 结果如图2所示。 可以看到m=2时PCA+FUQRA+KNN的分类准确率最高, 因此m取2。 调整KNN的参数K值并观察分类准确率变化情况, 最终确定m=2, K=3。
 | 图2 m取值不同时FUQRA分类准确率Fig.2 Classification accuracies of FUQRA with different values of m |
2.3.2 四种分类算法比较
为了提高分类准确率, 在已有的FUDT算法的基础上结合QR分解, 提出了模糊非相关QR分析(FUQRA)。 为了确定分类效果, 将FUQRA与FLDA、 FUDT进行对比。 其中, FLDA和FUQRA处理光谱数据后的图分别如图3和图4所示, 从图中可看出储藏时间1和储藏时间2两个数据集靠近, 这给分类带来一定的难度; 而储藏时间3与另外两个储藏时间数据集距离较远, 所以, 储藏时间3容易与另外两个储藏时间区分开来。 四种分类算法的分类准确率如表1所示。
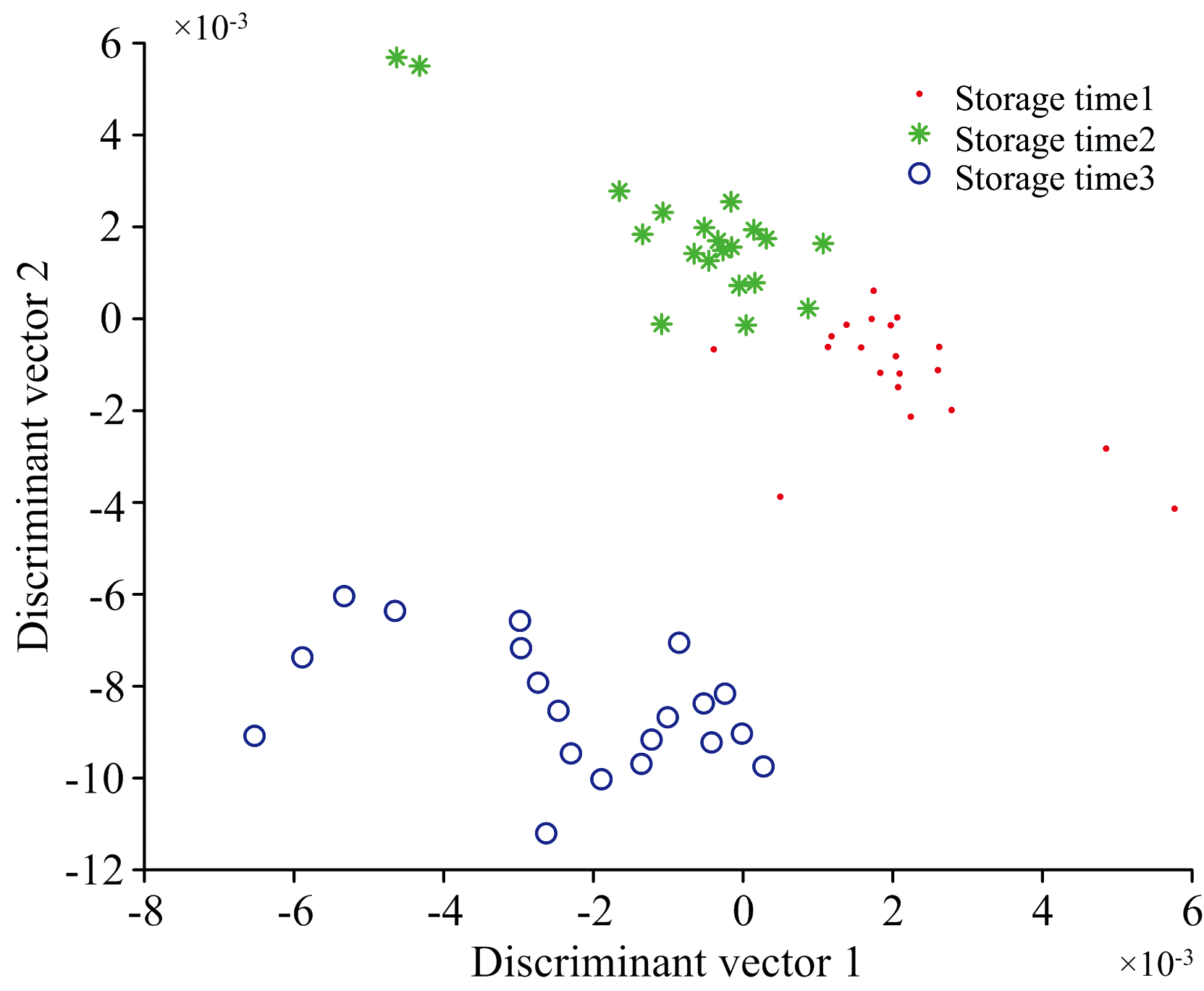 | 图3 FLDA处理后的图Fig.3 Processed by FLDA |
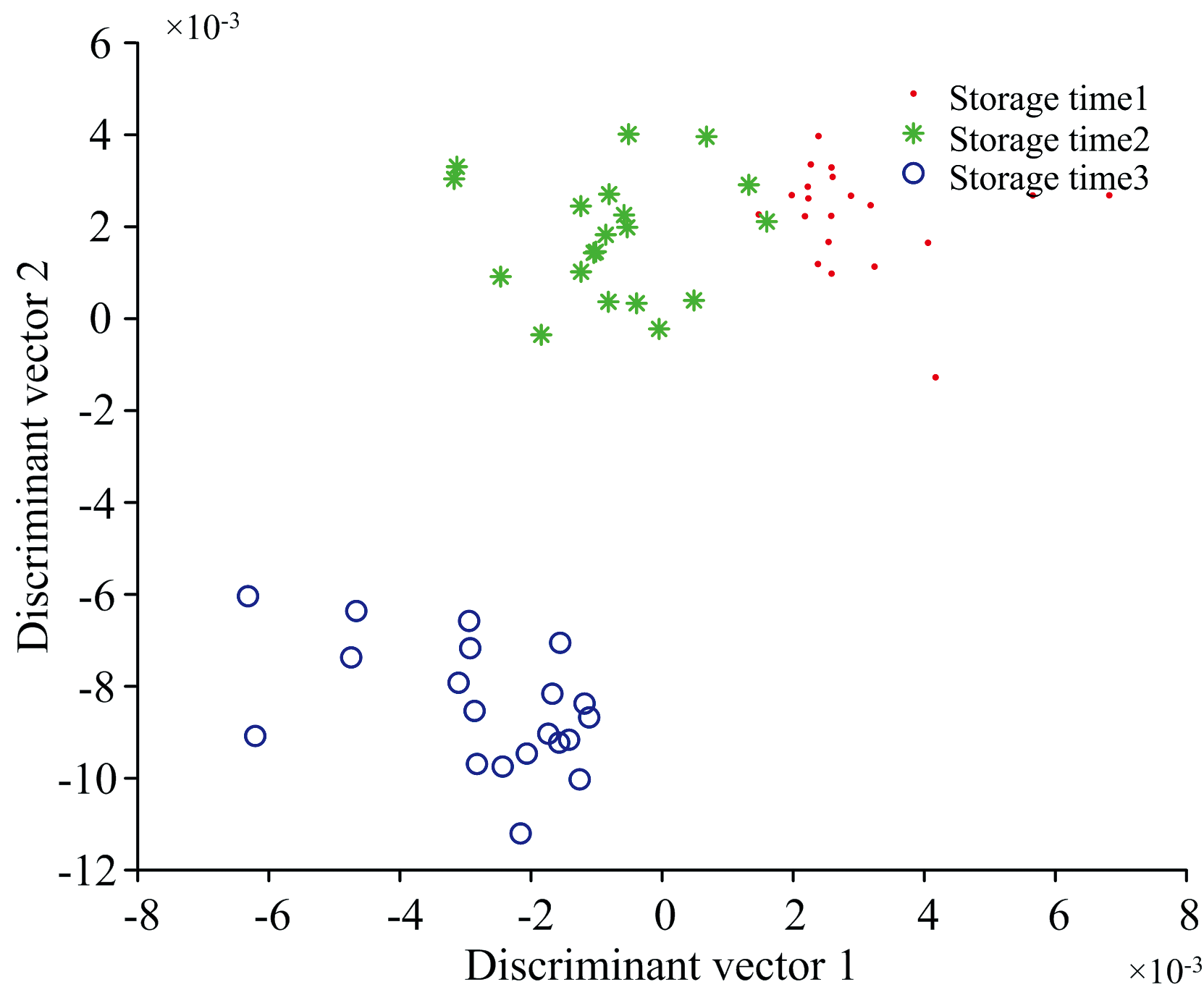 | 图4 FUQRA处理后的图Fig.4 Processed by FUQRA |
| 表1 四种分类方法的最高准确率 Table 1 The highest accuracy of four classification methods |
为了更有效的鉴别生菜储藏时间, 提出一种新的鉴别分析方法, 将QR分解法与模糊非相关判别转换(FUDT)相结合, 即模糊非相关QR分析(FUQRA)。 并在相同实验环境下与PCA+KNN、 PCA+FLDA+KNN、 PCA+FUDT+KNN相比较, 通过测试集可视化图和准确率, 可以发现FUQRA具有准确率更高(达到98.33%), 聚类效果更为显著的优点。 实验表明: PCA结合FUQRA和KNN, 能够更加快速、 高效而准确地实现生菜储藏时间的鉴别, 同时可以利用此方法尝试对其他蔬果的储藏时间进行定性判定。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|