

{kind=link}
{kind=link}
{kind=link}
噪声鉴别C均值聚类的滁菊花茶品质等级鉴别研究
[武斌1  , 谢晨傲
, 谢晨傲2 , 陈勇2 , 武小红2 , 贾红雯1 ]
, 谢晨傲|
|


作者简介: 武 斌, 1978年生, 滁州职业技术学院信息工程学院副教授 e-mail: wubind2003@163.com
近红外光谱检测技术可以通过探测近红外区域的光谱特征, 反映所测样品内部有机物化学成分和结构信息。 在分析物质成分时, 近红外光谱通常会涉及到大量的波长数据, 因此其维数往往比较高。 同时, 光谱会出现重叠和冗余等现象, 会影响模型的性能。 提出一种噪声鉴别C均值聚类(NDCM)算法。 NDCM将一种快速广义噪声聚类(FGNC)和模糊线性判别分析(FLDA)相结合, 可实现模糊聚类过程中进行数据鉴别信息的提取和数据空间维度的压缩, 以达到更高的聚类准确率。 对滁菊花茶近红外光谱数据进行模糊C均值聚类(FCM)得到的模糊隶属度和聚类中心作为噪声鉴别C均值聚类(NDCM)的初始模糊隶属度和初始聚类中心, 使NDCM具有聚类速度快, 准确率高等优点。 FCM算法对光谱噪声数据敏感, 而NDCM算法在处理含噪声的光谱数据时能够表现出较好的性能。 该研究选取特级滁菊、 一级滁菊、 二级滁菊三种品质等级的滁菊花茶作为实验样本, 共计240个样本。 实验使用便携式近红外光谱仪(NIR-M-F1-C)采集滁菊花茶的近红外光谱数据。 用Savitzky-Golay滤波和多元散射校正(MSC)对滁菊花茶近红外光谱进行预处理, 以减少光谱中掺杂的噪声和重叠信息。 通过主成分分析(PCA)对采集到的400维光谱数据进行维度压缩降至6维。 该研究使用线性判别分析(LDA)提取滁菊花茶光谱数据中的鉴别信息, 并将数据空间维度进一步转换为2维。 分别用FCM, FGNC和NDCM三种算法对处理后的数据进行聚类分析, 以实现对滁菊花茶的准确分类。 实验结果显示: 当权重指数 m=2.5时, FCM, FGNC, NDCM的聚类准确率分别为92.42%, 98.48%, 100%。 NDCM聚类时间略长于FGNC。 FCM算法需要进行27次迭代才能收敛, 而FGNC算法和NDCM算法分别只需要13次和10次迭代就能达到收敛。 采用近红外光谱技术结合MSC、 Savitzky-Golay滤波、 PCA、 LDA和NDCM算法, 建立了一种精准鉴别滁菊花茶品质等级的聚类模型。
Near-infrared (NIR) spectroscopy detection technology can reflect the measured sample's organic chemical composition and structural information by detecting the spectral features in the NIR region. During the material composition analysis, NIR spectroscopy often involves a significant amount of wavelength data, resulting in relatively high data dimensions. Furthermore, spectra are susceptible to phenomena such as overlap and redundancy, which impact the model's performance. Therefore, we proposed a noise discriminant C-means clustering (NDCM) algorithm that combined fast generalized noise clustering (FGNC) and fuzzy linear discrimination analysis (FLDA). NDCM can realize the extraction of data identification information and data space compression in the fuzzy clustering process, which can achieve higher clustering accuracy. The fuzzy membership degree and the cluster centers obtained by fuzzy C-means clustering (FCM) on the near-infrared spectral data of Chuzhou chrysanthemum tea are used as the initial fuzzy membership degree and initial clustering centers of NDCM, respectively, so that NDCM has the advantages of fast clustering speed and high accuracy. The FCM algorithm is sensitive to noisy data, while the NDCM algorithm can perform better when dealing with noisy data in spectra. In this study, 240 samples of Chuzhou chrysanthemum tea with three quality grades, namely special grade, first grade and second grade, were selected as experimental samples. A portable NIR spectrometer (NIR-M-F1-C) was used to collect the NIR spectra of Chuzhou chrysanthemum tea, and they are the 400-dimensional data. At first, the NIR spectra were pretreated with Savitzky-Golay filtering and multivariate scattering correction (MSC) to reduce spectral scattering and noise. Secondly, the dimensionality of the spectral data was reduced by principal component analysis (PCA), and the dimensionality of the data after PCA reduction was 6. Next, linear discriminant analysis (LDA) was applied to extract the discriminant information in the spectral data of Chuzhou Chrysanthemum tea and further transform the data space dimension into 2 dimensions. Finally, three algorithms, i.e. FCM, FGNC and NDCM, were utilized to perform cluster analysis on the processed data to accurately classify chrysanthemum tea. The experimental results exhibited that when the weight index m=2.5, the clustering accuracy rates of FCM, FGNC and NDCM were 92.42%, 98.48%, and 100%, respectively. The clustering time of NDCM was slightly longer compared to FGNC. FCM had 27 iterations to reach convergence, while FGNC and NDCM took 13 and 10 times, respectively. NIR spectroscopy combined with MSC, Savitzky-Golay filtering, PCA, LDA and NDCM can provide a clustering model to accurately identify Chuzhou chrysanthemum tea quality.
菊花茶是一种以菊花为原材料的花草茶, 用菊花制成的茶饮因其独特的味道和香气而备受人们的喜爱[1]。 菊花具有多种功效, 包括抗炎、 退热、 镇静和降压等。 研究表明, 菊花中含有多种类黄酮类化合物, 苯酸类化合物, 木脂素等。 其表现出多种不同的生物活性, 如抗氧化性, 抗肿瘤, 神经保护等[2]。 这些成分的性质和浓度决定了菊花的功能特性。 国内菊花茶品种繁多, 品质各不相同, 有普通花茶和优质花茶。 菊花茶的品质等级主要受气候、 土壤、 栽培管理和采摘时间等因素的影响[3]。 这些因素会直接影响菊花的生长环境和生长过程, 进而影响菊花茶的品质。 不同品质等级的菊花茶在营养成分、 香气和口感等方面有所差异[4]。 市场有些商家为了获取更高的利润, 会在优质菊花茶中掺杂劣质的菊花茶。 采用现代先进技术和仪器设计出一种方便快捷且识别准确率较高的菊花茶品质等级鉴定模型具有重要的研究价值[4, 5]。
国内外研究学者采用近红外光谱, 无损检测等先进技术对不同种类的茶叶进行定性与定量的研究与分析, 取得了许多显著成果[6, 7, 8]。 武斌等使用Antaris Ⅱ 型傅里叶近红外光谱仪采取茶叶傅里叶近红外光谱, 提出一种可能模糊鉴别C均值聚类(possibilistic fuzzy discriminant C-means clustering, PFDCM)算法, 并使用PFDCM进行茶叶聚类, 最终得到聚类的准确率为98.84%[9]。 Jia等在浙江绍兴购买三种不同价格的越州龙井茶, 根据价格将其分为三种不同的品质, 采用偏最小二乘回归、 支持向量回归和随机森林算法建立感官质量评分预测模型, 根据评分来判断越州龙井的品质[10]。 Wu等使用FTIR-7600红外光谱采集四川三种茶叶的FTIR的光谱信息, 并使用一种联合Gustafson-Kessel(AGK)算法进行茶叶聚类。 研究结果表明, 使用AGK算法进行聚类可以获得93.9%的准确率[11]。 不同品种的菊花茶具有不同的功效, 多糖和黄酮类化合物是菊花的主要活性成分, He等使用近红外高光谱成像技术获取三种不同品质菊花的光谱, 光谱范围为975~1 646 nm。 用偏最小二乘法和最小二乘法支持向量机建立预测建模, 从而测定菊花中的总多糖和总黄酮[12]。 为了快速鉴别菊花品种, Wu等采用高光谱成像结合深度卷积神经网络算法鉴别菊花品种。 采集了7个品种共11 038个样品的874~1 734 nm光谱范围内的高光谱图像, 采用二阶导数方法选择最佳波长。 在基于全波长的深度卷积神经网络在训练集和测试集上均获得了接近100%的准确率[13]。
噪声聚类(noise clustering, NC)可用于处理含有噪声的数据[14]。 NC聚类将噪声数据点视为一个独立的类别, 并在保持高准确性的同时有效地处理噪声数据点。 在NC的研究基础上, Davé 综合了模糊C均值聚类(fuzzy C-means, FCM)和可能C均值聚类(possibilistic C-means, PCM)的优点, 将噪声聚类扩展为广义噪声聚类(generalized noise clustering, GNC)[15]。 快速广义噪声聚类算法(fast generalized noise clustering, FGNC)解决了GNC算法依赖参数和在GNC算法运行前必须先运行FCM算法的缺陷[16]。 FGNC算法通过非参数化方法计算GNC所需的参数, 能够处理含噪声数据, 聚类准确率高, 聚类时间短。 针对FGNC目标函数中的度量距离进行了修改, 进一步优化噪声数据的聚类效果, 有研究提出了一种新的广义噪声聚类(novel generalized noise clustering, NGNC)算法。 NGNC更准确地处理噪声数据, 提高聚类结果的准确性和稳定性。 本研究从另一个角度出发, 将模糊线性判别分析(fuzzy linear discriminant analysis, FLDA)引入到FGNC聚类中, 提出一种新的噪声鉴别C均值聚类(noise discriminant C-means clustering, NDCM)算法。 NDCM采用FLDA算法中的模糊隶属度更进一步提高样本聚类的多样性, 同时还可以从含噪声的数据中提取更多有效的鉴别信息, 以提高聚类模型的性能。 使用近红外光谱结合NDCM聚类算法对滁菊花茶品质等级进行鉴别分析具有可行性。
在安徽滁州当地选取三种不同品质的滁菊花茶, 分别为: 特级滁菊, 一级滁菊, 二级滁菊。 每种滁菊有80个样本, 总共样本数为240。 选择每类样本中的58个样本进行训练, 其余的每类样本中的22个样本进行测试。 实验使用近红外光谱仪NIR-M-F1-C(由中国深圳市普研互联科技有限公司制造)采集滁菊花茶的近红外光谱数据。 该光谱仪的波长范围为900~1 700 nm, 可获取滁菊花茶样本在近红外区域的光谱信息, 为后续的数据分析和处理奠定基础。 首先组装光谱仪套件, 将反射探头与外置电源以及光谱仪连接起来, 测量端置于测量支架上, 连接显示装置, 打开外置电源。 实验人员在实验时确保所测量样本表面无破损, 大小形状相似。 将整个滁菊花茶样本放置在光路中央进行测量, 可以尽可能减少因样品不均匀或放置位置不当等因素引起的光谱信号差异。 实验采用非接触式反射测量, 实验期间的室内温度保持在18 ℃, 湿度保持在70%。 为减少误差, 每个样本的测量部位基本保持一致, 测量段与样本的距离保持一致。 使用软件DLP NIRscan Nano GUI v2.1.0记录采集的数据, 每次采集时间为3.641 s。 为了提高数据的准确性, 本实验对每个样本进行3次光谱测量, 并在数据处理过程中去除了一些异常光谱数据, 最终得到的平均值作为本次实验测量的光谱数据。 经过处理, 最终得到的样本光谱数据维度为400维, 可以用于后续的数据分析和处理。
FGNC聚类算法克服了GNC需要依赖FCM来计算参数的缺陷, 进一步提高了处理噪声数据的能力。 同时, 通过优化聚类中心, 使聚类速度更快, 聚类准确率更高。 本研究将FLDA算法引入到FGNC聚类中, 提出NDCM算法。 NDCM将噪声数据聚类到独立的类别中, 可以更好地处理噪声数据; 同时在聚类过程中能提取有效的鉴别信息, 从而使模型获得更高的聚类准确率。
噪声鉴别C均值聚类算法是一种迭代算法, 其主要步骤如下:
(1) 初始化: 设置权重m(m> 1), 样本数为n, 类别数为c(n> c> 1); 设置迭代次数初始值r和最大迭代次数rmax, 误差参数为ε 。
(2) 计算样本的协方差
${{\sigma }^{2}}=\frac{1}{n}\overset{n}{\mathop{\underset{k=1}{\mathop \sum }\,}}\,\|{{x}_{k}}- {\bar{x}}{{\|}^{2}}, {\bar{x}}=\frac{1}{n}\overset{n}{\mathop{\underset{j=1}{\mathop \sum }\,}}\,{{x}_{j}}$(1)
式(1)中, ${\bar{x}}$为样本的均值, xj为第j个样本值。
(3) 构造模糊类间散布矩阵SfB
${{S}_{\text{fB}}}=\overset{c}{\mathop{\underset{i=1}{\mathop \sum }\,}}\,\overset{n}{\mathop{\underset{k=1}{\mathop \sum }\,}}\,{{[u_{ik}^{\left( r \right)}]}^{m}}\left( v_{i}^{\left( r \right)}-{\bar{x}} \right){{(v_{i}^{\left( r \right)}-{\bar{x}})}^{\text{T}}}$(2)
式(2)中,
(4) 构造模糊总体散布矩阵SfT
${{S}_{\text{fT}}}=\overset{c}{\mathop{\underset{i=1}{\mathop \sum }\,}}\,\overset{n}{\mathop{\underset{k=1}{\mathop \sum }\,}}\,{{[u_{ik}^{\left( r \right)}]}^{m}}\left( {{x}_{k}}- {\bar{x}} \right){{({{x}_{k}}- {\bar{x}})}^{\text{T}}}$(3)
式(3)中, xk是第k个样本值。
(5) 特征值和特征向量的计算
式(4)中, 特征值λ 和其对应的特征向量Ψ 。
(6) 样本xk∈ Rq投影到特征空间(由Ψ 1, Ψ 2, …, Ψ p组成)
式(5)中, p和q表示维数, Ψ p是特征向量组中的第p个向量。
(7) 同样将
式(6)中,
(8) 计算参数
$u_{i k, \mathrm{FCM}}=\left[\sum_{j=1}^c\left(\frac{\left\|y_k-v_i^{\prime}(r)\right\|}{\left\|y_k-v_j^{\prime}(r)\right\|}\right)^{\frac{2}{m-1}}\right]^1, \forall i, k$(7)
式(7)中, yk为特征空间里第k个样本;
(9) 在特征空间中计算模糊隶属度函数值
$u_{i k}^{\prime(r+1)}=\frac{\left(\ \ \delta^{\prime 2}\ \ \left\|\ \ y_k-v_{i k}^{\prime(r)}\ \ \right\|^{-2}\ \ \right)^{\frac{1}{m-1}}}{\sum_{i=1}^c\left(\ \ \delta_{i k}^{\prime 2}\ \ \left\|\ \ y_k-v_i^{\prime(r)}\ \ \right\|^{-2}\ \ \right)^{\frac{1}{m-1}}+1}, \forall i, k$(8)
式(8)中,
(10) 在特征空间中计算第i类的类中心矢量
$v_i^{\prime(r+1)}=\frac{\sum\ _{k=1}^n\ \ \left[\ \ u_{i k}^{\prime(r+1)\ }\ \ \ \right]^m \ y_k}{\sum\ _{k=1}^n\ \ \left[\ \ u_{i k}^{\prime(r+1)\ }\ \ \ \right]^m}, \forall i, k$(9)
迭代次数r值增加, 即r=r+1; 直到满足条件:
(11) 迭代终止后, 根据模糊隶属度值对样本进行分类。
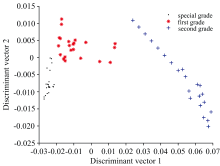
近红外光谱是一种分子振动光谱, 包含了丰富的含氢基团(N— H, C— H, O— H)的信息。 这些信息可以涵盖绝大多数有机分子的组成和结构成分, 为滁菊花茶品质等级分类提供了必要的分析依据。 由于滁菊花茶样品的颗粒度以及密度大小不同, 在光谱扫描时会出现散射, 从而影响模型的最终结果。 为此需要采用多元散射校正(MSC)对光谱数据进行预处理, 来减少散射影响和提高模型的准确性。 同时需要采用Savitzky-Golay滤波使光谱数据流平滑除噪, 滤除噪声的同时还可以确保光谱数据的形状, 宽度不变[17]。 经过预处理后的菊花茶光谱数据的维度仍为400维的高维数据, 为了减少计算复杂度并提高模型聚类准确率, 需要对数据进行降维处理。 使用主成分分析法(PCA)对光谱数据进行降维。 PCA的前6个主成分的累计贡献率高达99.96%, 选取PCA中的前6个主成分来代替之前的高维数据, 不仅可以减少数据信息的损失还可以进行数据维度的压缩。 将原400维的滁菊花茶近红外光谱数据投影到PCA的前6个主成分上可以获得6维的压缩数据。 从三种不同品质的滁菊花茶样本中各抽取58个样本作为训练集, 共174个, 其余的66个样本作为测试集。 采用线性判别分析法(LDA)对测试样本再次进行维度转换, 计算出训练集的鉴别向量和特征值。 计算得到的两个特征值分别为: λ 1=20.387 8, λ 2=6.112 9。 测试集样本经LDA特征空间转换后形成二维数据。 图1为线性判别分析的得分图。 如图1所示, 图中“ · ” , “ * ” , “ +” 分别表示特级滁菊, 一级滁菊, 二级滁菊的样本分布情况。 由图1, 二级滁菊样本的分布较为松散, 其他两种样本分布较紧密, 三种不同品质的滁菊花茶样本数据分布, 有利于之后的分类运算。
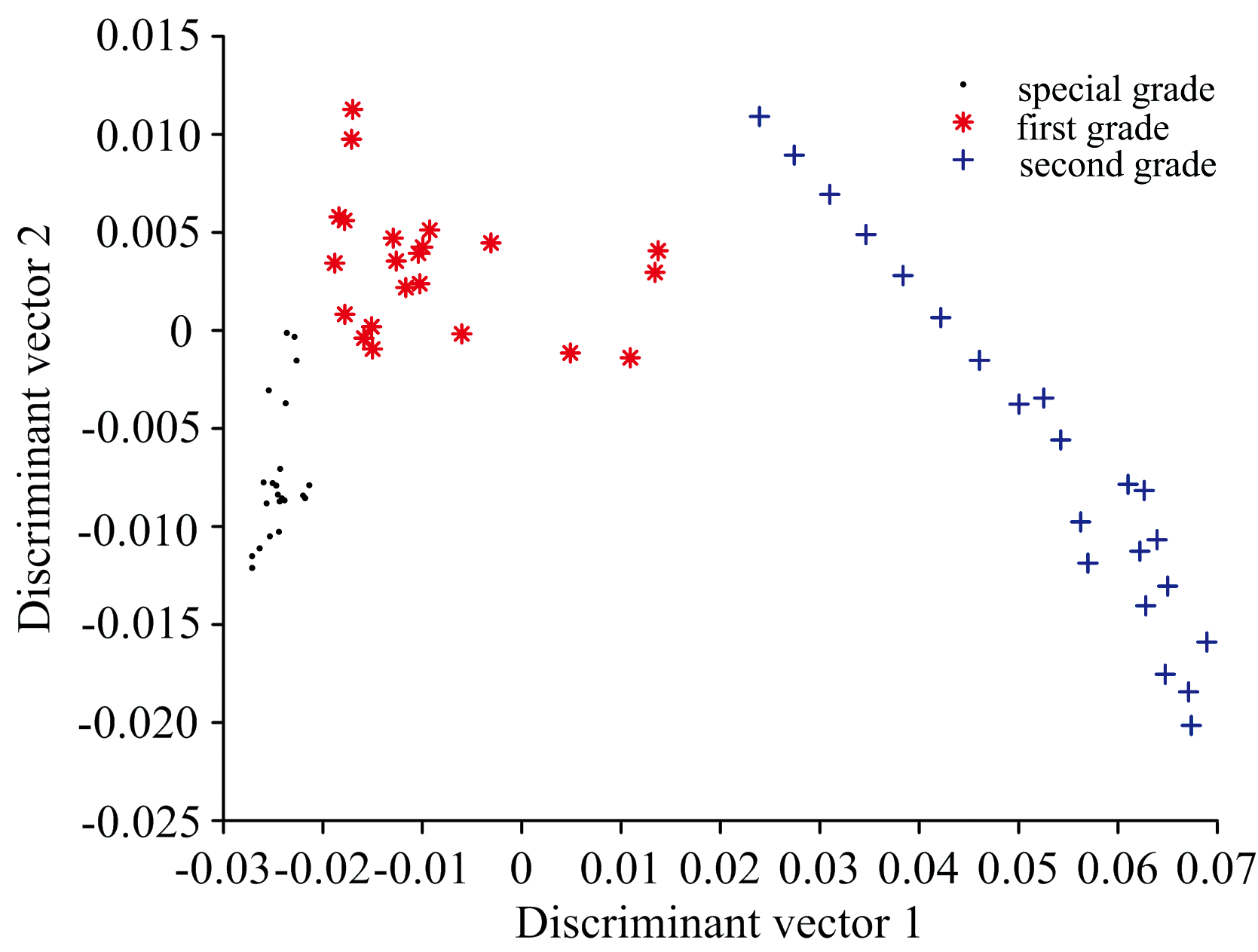 | 图1 线性判别分析得分图Fig.1 Scores plot of linear discriminant analysis |
偏最小二乘判别分析(partial least squares-discriminant analysis, PLSDA)是广泛应用于分类和预测建模的监督学习方法[18], 结合了偏最小二乘回归和判别分析的思想, 能够处理高维数据和多个预测变量。 本研究使用PLS-DA对预处理后的滁菊花茶数据进行分类。 如图2所示, 当选择不同的主成分数量时, PLS-DA模型的分类性能会相应地发生变化。 结果表明, 当所保留的主成分数量为3或5时, PLS-DA模型的分类准确率达到了66.67%。
 | 图2 不同主成分个数时PLS-DA模型的分类准确率Fig.2 Classification accuracies of PLS-DA model with different numbers of principal components |
2.3.1 模糊聚类的初始化参数设置
在运行FCM, FGNC, NDCM聚类算法之前, 需要进行初始化设置。 设置权重指数m=2.5, 待聚类样本数为66, 样本类别数c=3; 设置迭代次数初始值r=1和最大迭代次数rmax=100; 迭代最大误差参数ε =0.000 01。 设置FCM的初始聚类中心
2.3.2 三种模糊聚类算法的迭代次数和聚类时间
聚类初始化参数设置同2.2.1节。 分别运行FCM, FGNC和NDCM三种聚类算法, 对它们的最终迭代次数以及收敛情况进行分析。 实验所用计算机配置为: CPU Intel Core i5-8300H 2.30GHz(8 CPUs), RAM 16384MB, Windows11。 实验所用软件为: MATLAB R2016a。 三种聚类算法达到收敛时的最终迭代次数: FCM 27次, FGNC 13次, NDCM 10次。 FCM, FGNC和NDCM的聚类所需时间分别为0.093 8 s, 0.046 9和0.073 6 s。 FGNC运行前使用FCM最终迭代后的聚类中心作为初始聚类中心, 因此运行速度最快。 由于NDCM中需运行FLDA算法, 因此运行时间稍长于FGNC。
2.3.3 聚类准确性
设置聚类初始化参数同2.2.1节。 本实验首先使用FCM、 FGNC和NDCM聚类算法对数据进行聚类, 且在聚类前未进行任何数据预处理或特征提取操作。 聚类结果如表1所示。 可以明显看出, 由于没有进行数据预处理和降维, 聚类时间大幅增加, 而且聚类准确率也未能达到较好的结果。 通过将SG和MSC方法相结合, 可以有效消除样本中部分的噪声和散射效应, 从而提高光谱数据的准确性、 可靠性。 先使用SG+MSC对滁菊花茶的原始光谱数据进行预处理, 再利用PCA+LDA对数据进行降维和特征提取后, 在测试集中运行FCM, FGNC, NDCM算法。 FCM, FGNC, NDCM算法的运行结果如表2所示。 相比于表1, 表2中三种聚类算法的聚类准确率得到了显著提高, 同时聚类时间也大幅缩短。 其中FCM的聚类准确率为92.42%, 相比于其他两种算法较低。 而FGNC的聚类准确率达到了98.48%。 值得注意的是, 在NDCM聚类算法中, 由于结合了FLDA算法, 可以实现在模糊聚类过程中提取滁菊花茶光谱数据中的鉴别信息, 提高了聚类准确率。 在本实验中, 通过调整模糊权重指数m的值, 使得NDCM的聚类准确率高达100%。 NDCM的模糊隶属度如图3所示。 表明NDCM在提高聚类准确率方面具有显著效果, 进一步验证了其在滁菊花茶光谱数据上的聚类有效性。
| 表1 FCM, FGNC, NDCM的聚类结果 Table 1 The clustering results of FCM, FGNC and NDCM |
| 表2 在SG+MSC, PCA和LDA下FCM, FGNC, NDCM的聚类结果 Table 2 The clustering results of FCM, FGNC and NDCM under SG+MSC, PCA and LDA |
 | 图3 NDCM的模糊隶属度值Fig.3 Fuzzy membership values of NDCM |
在一种快速广义噪声聚类(FGNC)算法的基础上结合模糊线性判别分析(FLDA)提出一种新的噪声鉴别C均值聚类(NDCM)。 NDCM算法不仅可以降低噪声数据对聚类的影响, 还可以从数据中提取更多有效的判别信息, 从而提高聚类的准确率。 通过对三种品质滁菊花茶的近红外光谱进行FCM, FGNC和NDCM聚类算法分析得到的实验结果表明: 当权重指数m=2.5时, NDCM的聚类准确率可以高达100%。 相比于FCM和FGNC聚类算法, NDCM算法可以更加精准、 高效地对不同品质等级的滁菊花茶进行分类, 聚类准确率也得到了明显的提升。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|