




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱技术在牛肉丸复合掺假类型鉴别中的应用
[孔丽琴1, 2  , 牛晓虎
, 牛晓虎1, 2 , 王程磊1, 2 , 冯耀泽1, 2, 3, * , 朱明1, 2 ]
, 牛晓虎, 朱明|
|


作者简介: 孔丽琴, 女, 1995年生, 华中农业大学工学院博士研究生 e-mail: kongliqin_hzau@163.com
肉制品加工过程的复杂性给肉制品掺假检测带来了巨大的挑战。 基于高光谱技术, 对不同比例的猪肉-鸡肉复合掺假牛肉丸进行了掺假类别判别分析, 尤其首次提出了对熟牛肉丸复合掺假的快速检测。 为建立模型, 分别在牛肉糜中加入不同比例(20%、 40%和80%) 的猪肉/鸡肉, 获得单一掺假样品。 并将猪肉和鸡肉按2∶8、 5∶5和8∶2的比例混合, 在20%、 40%和80%比例下进行复合掺假。 此外, 还制备了油炸掺假牛肉丸, 以检验分类模型的适用性。 对采集的掺假样本高光谱数据, 经五种方法预处理后建立基于极限学习机分类(ELMC)和支持向量分类(SVC)的掺假鉴别模型。 此外利用连续投影算法(SPA)、 竞争性自适应重加权算法(CARS)分别提取特征波长并建立相应简化模型。 研究表明: 基于全波长建立的生/熟牛肉丸掺假类别检测模型SVC性能均优于ELMC。 而基于特征波长建立的简化模型ELMC性能优于SVC。 对生牛肉丸分类判别, 利用SPA筛选出的44个特征波长建立的ELMC模型性能最优, 其校正集和预测集的分类准确率均为97.17%。 基于CARS筛选出的38个特征波长建立的ELMC模型对熟牛肉丸具有最高的分类性能, 其校正集和预测集的分类准确率分别为97.17%和96.23%。 因此高光谱技术可以对生肉和熟肉的复合掺假类型进行有效、 快速、 准确的鉴别, 为便携式检测设备的研制奠定了理论基础。
The complexity of the meat processing process presents significant challenges in detecting adulteration in meat products. This study uses hyperspectral technology to identify and analyze adulteration in beef meatballs. To establish the models, different proportions (20%, 40%, and 80%) of pork/chicken were added to mince beef to obtain single adulterated samples, respectively. Subsequently, pork and chicken were mixed in 2∶8, 5∶5, and 8∶2 ratios to prepare samples for composite adulteration under three different gradients (20%, 40%, and 80%). In addition, fried adulterated beef balls were also prepared to test the applicability of classification models. Hyperspectral data of the adulterated samples were collected and preprocessed using five different methods. Adulteration identification models were developed using the Extreme Learning Machine Classification (ELMC) and Support Vector Classification (SVC) algorithms. Feature wavelengths were extracted using the Successive Projections Algorithm (SPA) and Competitive Adaptive Reweighted Sampling (CARS), developing corresponding simplified models. The results showed that the performance of the raw/cooked beef ball classification model's SVC model based on full wavelength was better than that of ELMC. In contrast, the simplified model based on characteristic wavelength showed a contrary trend. For the classification of raw beef balls, the ELMC model (SPA-ELMC-Raw) established based on the 44 characteristic wavelengths selected by SPA yielded the best performance, with classification accuracies of 97.17% for both the calibration set and prediction set. For the classification of cooked beef balls, the ELMC model (CARS-ELMC-Cooked) established based on the 38 characteristic wavelengths selected by CARS showed the highest performance, with classification accuracies of 97.17% and 96.23% for the calibration set and prediction set, respectively. The results indicated that hyperspectral imaging technology proves to be an effective, rapid, and accurate method for discriminating between different types of adulteration in raw and cooked meat. This provides a strong theoretical basis for developing portable detection equipment.
牛肉因含有丰富、 优质的蛋白质和较少的脂肪而备受消费者青睐。 近年来牛肉消费量的稳步增长[1], 推动了牛肉制品的快速、 多元化发展, 在此背景下, 不法商贩由于利益驱使往往对牛肉制品进行掺假。 牛肉制品掺假不仅会给食品安全检测带来了巨大挑战, 严重危害消费者的权益和身体健康, 甚至会引发宗教问题[2]。 牛肉制品种类繁多且加工方式(蒸, 卤, 炸, 腌, 烤等)多样, 在制备过程中加入调料以及加工方式会掩盖甚至改变掺杂物(如猪肉, 鸭肉和鸡肉等)的气味、 颜色、 口感进而为掺假鉴别带来挑战。 因此开发牛肉制品掺假精准检测方法是十分必要的。
广泛应用的肉类掺假鉴别方法有蛋白质组学法, DNA法, 传感器法和光谱法[3]。 蛋白质组学分析法和DNA分析法检测精度高, 准确度高但均存在检测成本高, 重复性较低的缺点[3, 4]。 传感器法主要包括电子舌和电子鼻, 两种设备操作方便, 但价格昂贵, 重复性较差[3, 5], 且检测过程中需对样本进行一定的前处理[6]。 光谱技术由于其检测过程无需对样本进行前处理, 测量方便、 稳定等优势, 成为了食品掺假分析领域中重要的技术手段[7]。
近红外光谱技术可以对样本进行无损检测, 但是其只能实现对样品局部信息的采集, 如若进行多次扫描来扩充信息, 则耗时较长。 而结合了机器视觉与光谱技术的高光谱成像快速无损检测, 能够同时获得样本的图像和光谱信息, 实现对样本信息更好的表征, 近年来已被广泛应用于肉类掺假检测[8]。 Li等[9]利用高光谱成像结合卷积神经网络对三文鱼掺假实现准确检测。 而高光谱结合化学计量学方法在变质肉类掺假、 同源肉类掺假和低经济价值异源肉类掺假均表现出了良好的分析性能[7, 10]。 白亚斌等[11]利用高光谱技术建立一种牛肉-猪肉掺假的快速无损检测方法。 此外, 孙宗保等[12]利用高光谱成像技术成功实现了对牛肉丸中掺杂的猪肉和鸡肉含量的预测。 以上研究表明, 高光谱成像技术在肉类掺假检测中有良好的应用前景。 然而目前大部分研究仅关注肉类的单一掺假, 且很少充分重视不同肉类之间因色泽、 质地不同而造成的掺假样本随掺杂比例变化颜色差异较大的现象。 因此, 牛肉制品中香料和调味品、 多元掺假物的加入以及加工方式对基于高光谱技术的牛肉掺假检测性能的影响亟待深入研究。
为此, 利用高光谱技术结合化学计量学方法对生牛肉丸以及炸制的熟牛肉丸中的猪肉、 鸡肉、 猪肉-鸡肉混合掺假进行了分类判别分析。 同时比较了多种预处理方法对分类判别模型性能的影响。 此外为进一步简化模型, 提升模型运行速度, 应用竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)和连续投影算法(successive projections algorithm, SPA)选取特征波长建立和优化牛肉丸掺假类别识别模型, 为开发便携式光谱仪奠定理论基础。
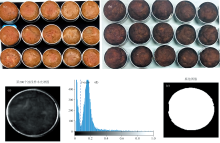
试验用的牛腩肉来自山东(西门塔尔牛)、 内蒙古(西门塔尔牛)、 安徽(黄牛)三个产地, 猪前胛肉(长白猪)和鸡大腿肉(三黄鸡)购于悦活里超市(武汉)。 使用无菌刀去除肉样表面的筋、 膜和脂肪, 将牛肉、 猪肉、 鸡肉分别放入破壁机搅碎。 参照美国《药典指南草案》要求加标样品的制备分为三个级别(浓度在风险阈值附近, 该浓度的一半和两倍)。 按照20%, 40%, 80%的比例将猪肉糜和鸡肉糜分别掺杂到牛肉糜中以制备单一掺假样本。 每个掺假肉样本总质量为30 g, 设置6个平行样本。 单次制备3个, 即取混合肉类共计90 g, 在其中加入生抽1.8 g, 蛋清10 g, 淀粉10 g, 胡椒粉0.25 g, 牛髓膏0.18 g, 乙基增香剂0.27 g, 牛肉精粉0.18 g。 将肉糜与调料充分混合均匀后, 分成三部分, 揉成大小基本相同的肉丸, 放置在不同编号的直径40 mm、 高25 mm的铝盒中。 复合掺假样本的比例同上述保持一致。 同时在每一掺假比例下猪肉和鸡肉分别以2∶ 8, 5∶ 5, 8∶ 2的质量比掺杂到牛肉中以制备复合掺假样本。 另将100%牛肉, 100%猪肉, 100%鸡肉样本作为对照, 共获得324个生肉丸样本。 将上述肉丸放入预热5 min的油锅中炸制3 min后捞出, 共制得324个熟肉丸样本。 制备的生/熟牛肉丸样本如图1(a)和(b)所示。 生/熟肉丸样本均按照分类标签分为6类, 其中第1类为纯牛肉丸样本(18个), 第2类为不同掺假比例下的猪肉单一掺假样本(54个), 第3类为猪肉-鸡肉复合掺假样本(162个), 第4类为不同掺假比例下的鸡肉单一掺假样本(54个), 第5类和第6类分别为纯猪肉丸和纯鸡肉丸样本(均为18个)。
 | 图1 掺假牛肉丸样本图及样本掩模图像获取 (a): 生掺假牛肉丸样本; (b): 熟掺假牛肉丸样本; (c): 样本原始光谱图像; (d): 样本灰度值分布; (e): 样本掩模图像Fig.1 Samples of adulterated beef balls and sample mask image acquisition (a): Samples of raw adulterated beef balls; (b): Samples of cooked adulterated beef balls; (c): Raw spectral image; (d): Gray value distribution; (e): Sample mask image |
高光谱图像采集装置主要由高光谱成像仪(SPECIM, V10E, Finland)、 高精度电控移动可升降平台(北京卓立汉光仪器有限公司, HSIA-TSA300-IMS, 中国)、 采集箱、 散热风扇、 卤素灯光源和计算机(联想, ThinkPad, 中国)等组成[13]。 光谱仪的波长范围为400~1 000 nm, 光谱分辨率为2.8 nm。 为减少基线漂移带来的影响[12], 样品的高光谱图像信息采集之前首先将高光谱图像采集系统预热30 min。 试验时系统参数设置为: 曝光时间0.1 s, 电控移动平台移动速度1.8 mm· s-1, 平台移动距离设置280 mm。
为避免发生镜面反射先用滤纸吸干样品表面水分和油脂, 然后有序放置在黑色背景板上进行扫描。 利用黑板(0%反射率)和白板(100%反射率)参考图像校正原始图像。 校正公式如式(1)所示。
式(1)中, R为校正后图像, RS为采集的原始图像, RW为全白校正图像, RB为全黑校正图像。
高光谱图像采集系统单次采集的图像包含不同掺假比例下的多个样本信息。 首先对校正后图像进行分割得到单个样本的高光谱图像, 进一步对分割后所得的单个样本图像进行感兴趣区域(ROI)提取以消除背景光谱对样品光谱的干扰。 ROI的大小和形状都会对模型的精度有一定影响[14], 因此本研究采用阈值分割技术对ROI进行提取。 图1(d)为某个样本归一化后的灰度值频数分布图像。 图像为双峰结构, 通过设置灰度阈值(T=0.079)可将其划分为背景及噪声区及感兴趣区组成的二值图像。 此外, 二值图像进一步经过膨胀与腐蚀的形态学操作得到掩模以定位感兴趣区域, 最后取掩模定位区域图像平均光谱得到单个样本的光谱数据。 如图1(c)和(e)所示, 样本实际轮廓和掩模定位后的图像区域基本重合, 可较好反映样本信息从而用于建模分析。
采用卷积平滑(savitzky-golay, SG)、 矢量归一化(vector normalization, VN)、 一阶导数(first derivative, 1st De)、 多元散射校正(multiplicative scattering correction, MSC)、 标准正态变量变换(standard normalized variate, SNV)对光谱数据进行预处理以消除其所包含的无关信息和噪声。 其中, SG可以有效的减小随机误差, VN可以消除微小光程导致的光谱数据变动, 1st De可以有效消除基线漂移和背景的干扰, MSC用于消除或减小颗粒分布不均匀以及颗粒大小产生的散射影响[15]。
全波长光谱中包含大量的冗杂信息, 通过对光谱特征波长的选择, 可以提高建模效率, 减少建模变量[16, 17, 18]。 选用SPA[19]、 CARS[20]对生/熟肉丸分类鉴别全波长模型进行简化。
剔除6个异常样本后, 利用SPXY[21]算法将样本数据按照2∶ 1的比例划分为校正集和预测集。 分别采用极限学习机分类(extreme learning machine classification, ELMC)和支持向量分类(support vector classification, SVC)建立掺假样本的多分类模型。 其中纯牛肉丸样本分类标识为1, 混有20%, 40%, 80%猪肉/鸡肉的单一掺假样本分类标识分别为2和4, 猪肉-鸡肉复合掺假的样本分类标识为3, 纯猪肉和纯鸡肉样本分类标识分别为5和6。
ELMC采用任意分配输入权值与隐层偏差的训练方法, 相较于传统模型具有更高的学习率, 预测精度和泛化性能[22]。 在运算过程中, 需要设置的参数仅为隐含层神经元个数。 通过穷举法探究ELMC模型中隐含层神经元个数对预测结果的影响以及模型的预测性能, 设置隐含层神经元个数初值为2并以步长为2递增至校正集样数量。 为消除模型随机影响, 在每种神经元个数(N)下执行20次ELMC算法, 通过观察平均校正集和预测集准确率来确定最优隐含层神经元个数N。
SVC能够通过核函数将输入空间的非线性可分训练样本集映射到特征空间中, 使训练样本在特征空间线性可分且能有效解决非线性分类问题[23]。 SVC中常用的核函数主要包括径向基核函数(RBF), 多项式核函数, Sigmoid核函数。 径向基核函数在解决不可分问题和处理小特征维度的情况具有很大的优势[24], 因此选用RBF作为SVC的核函数对复合掺假样本进行分类判别。 此外利用遗传算法(GA)优化算法寻核函数(g)、 惩罚因子(c)的最优组合。
建立掺假类别分析模型后, 通过分类准确率来评价模型性能。 分类准确率为正确分类样本数量在所有样本中所占百分比, 计算公式如式(2)所示。 分类准确率越高, 模型性能越好。 混淆矩阵用来分析掺假样本种类正确和错误识别的具体情况。 此外, ELMC模型中的最优隐含层神经元个数N越大, 模型越复杂。 核函数参数g是决定SVC模型空间复杂度的重要参数, g越大则模型空间复杂度越高。 惩罚参数c越小表示对经验误差的惩罚越小。 当分类准确率持平时, 比较分类模型参数进行模型评价。
式(2)中, Accuracy为分类准确率, NPC为正确分类的样本数量, NAS为总样本数量。
部分生/熟掺假肉丸样本的光谱范围和平均光谱如图2所示。 从图中可以看出, 虽然两者光谱曲线趋势大体一致, 但是熟肉丸样本光谱反射率整体上比生肉丸样本小。 此外, 大量样本光谱的重叠导致无法用肉眼对样本的种类进行区分, 因此需联合化学计量学方法进一步处理以实现对不同掺假样本的准确分类。
 | 图2 生/熟牛肉丸掺假样本光谱范围及平均光谱 (a), (b): 生牛肉丸样本; (c), (d), (e): 熟牛肉丸样本Fig.2 Spectral range and average spectrum ofadulterated raw/cooked beef ball samples (a), (b): Raw beef ball samples; (c), (d), (e): Cooked beef ball samples |
2.2.1 全波长模型
为建立生牛肉丸掺假类型识别模型, 比较了不同预处理方法下建立的ELMC和SVC模型性能, 结果如表1所示。 ELMC模型下的校正准确率和预测准确率的差值较小, 说明该模型的性能较为稳定。 除VN和1stDe外, 其他预处理方法下的ELMC模型相对原始光谱数据模型(None-ELMC-Raw)的校正准确率(96.23%)均有一定提升, 但只有MSC-ELMC-Raw模型的预测准确率高于None-ELMC-Raw模型的预测准确率(94.34%)。 故最优ELMC模型为MSC预处理下的模型(MSC-ELMC-Raw), 其校正准确率和预测准确率均为97.17%, 此时神经元个数N=56。 不同预处理条件下建立的支持向量机分类(SVC)模型识别准确率均达到了90%以上, 经过矢量归一化(VN)预处理的支持向量机分类模型(VN-SVC-Raw)的校正准确率和预测准确率分别为94.34%和91.51%。 SG-SVC-Raw和None-SVC-Raw的模型效果相当。 经过1stDe和SNV预处理的SWC模型校正集准确率达到了100%, 但1stDe-SVC-Raw模型预测集准确率仅为93.40%, 所以最优模型为SNV预处理的SVC模型(SNV-SVC-Raw), 其预测准确率为97.17%。
| 表1 不同预处理方法下建立的生牛肉丸全波长分类模型结果 Table 1 Performances of full-wavelength classification models of raw beef balls with different data preprocessing methods |
最优模型分类结果混淆矩阵如图3所示。 预测集中有1个猪肉掺假样本(分类标签为2)被预测为鸡肉单一掺假样本, 2个猪肉-鸡肉-牛肉复合掺假样本分别被预测为猪肉和鸡肉单一掺假样本。 其中2个被误判的复合掺假样本都是由内蒙古牛肉和80%(wt%)的混合肉(猪肉∶ 鸡肉=8∶ 2; 猪肉∶ 鸡肉=2∶ 8)组成。 经模型预测为单一猪肉(分类标签为2)和单一鸡肉(分类标签为4)掺假, 可能是由于样本中猪肉/鸡肉含量高及混合不均所导致。 图2(a)和(b)也验证了误判样本与其误判类别的光谱相似性。 其中被误判的生肉丸样本光谱曲线均坐落于3类掺假样本光谱的重叠区, 为其掺假类别的判定带来困难。 但97.17%的预测精度证明了高光谱技术应用于生肉丸掺假类型鉴别的高效性。
 | 图3 最优模型分类结果混淆矩阵 (a): 校正集; (b): 预测集Fig.3 Confusion matrices of optimal model classification results (a): The calibration set; (b): The prediction set |
2.2.2 简化模型
运用竞争性自适应重加权算法(CARS)和连续投影算法(SPA)分别对生牛肉丸掺假样本光谱数据优选出27个和44个特征波长。 表2为两种波长选择方法下建立的最优简化极限学习机(ELMC)和支持向量机分类模型(SVC)效果。 经过两种算法提取特征波长建立的简化模型运行时间均得到了一定程度的减小, 但性能均略低于全波长模型性能, 其中最优简化模型为SPA-ELMC-Raw, 校正准确率和预测准确率都为97.17%, 具有最优的分类正确率同时表现出较好的稳定性。
| 表2 不同波长选择方法下建立的简化模型性能 Table 2 Performances of simplified models using different wavelength selection methods |
SPA算法选中波长分布情况如图4(b)所示。 从图中可以看出, 筛选出的特征波长在400~450、 900~1 000 nm波段之间的分布较多, 且在750~900 nm分布较均匀。
 | 图4 CARS(a)和SPA(b)筛选出的特征波长分布Fig.4 Maps of characteristic wavelengths selected by CARS (a) and SPA (b) |
2.3.1 全波长模型
表3为不同预处理方法下建立的熟牛肉丸掺假样本的全波长掺假类别鉴别模型结果。 从表中可以看出选用不同预处理方法对ELMC模型的隐含层神经元个数的选取影响较大, 几种预处理方法对应的N值各不相同。 其中原始光谱建立的ELMC模型(None-ELMC-Cooked)和经SG预处理的ELMC模型(SG-ELMC-Cooked)性能明显优于其他模型, 虽None-ELMC-Cooked模型的校正准确率较高, 但其与预测准确率差值较大, 且相对于SG-ELMC-Cooked, 隐含层神经元个数较多, 模型更复杂, 故最优ELMC模型为SG-ELMC-Cooked, 其校正准确率为97.17%, 预测准确率为96.23%, 此时神经元个数N=70, 模型运行时间为13.09 s。
| 表3 不同预处理方法下建立的熟牛肉丸全波长分类模型结果 Table 3 Performances of full-wavelength classification models of cooked beef balls with different data preprocessing methods |
不同预处理方法下建立的SVC模型性能均优于原始光谱建立的模型(None-SVC-Cooked), 1stDe、 MSC、 SNV预处理下的SVC模型的校正准确率均较None-SVC-Cooked有所提高, 但MSC-SVC-Cooked和SNV-SVC-Cooked模型的校正准确率和预测准确率差值较大, 不利于模型的稳定性, 1stDe-SVC-Cooked模型性能明显优于VN-SVC-Cooked, 且模型运行时间较短, 所以最优SVC模型为1stDe-SVC-Cooked, 其校正准确率为99.53%, 预测准确率为96.23%, 最优惩罚因子c=10.454 8, 最优核函数g=0.062 18。
全波长熟牛肉丸掺假鉴别模型中最优SVC模型的校正准确率高于最优ELMC模型。 因此, 1stDe-SVC-Cooked为最优熟牛肉丸掺假分类模型, 其分类结果混淆矩阵如图5所示。 该模型校正集中被误判的1个样本由内蒙古牛肉和20%(wt%)的鸡肉制备而成的鸡肉单一掺假样本, 其被误判为猪肉掺假。 预测集中被误判的4个样本的肉类组成分别为: 内蒙古牛肉-40%(wt%)猪肉; 内蒙古牛肉-40%(wt%)猪肉; 安徽牛肉-20%(wt%)猪肉; 山东牛肉-20%(wt%)猪肉。 经SVC模型预测后分别被判别为: 鸡肉单一掺假; 鸡肉单一掺假; 复合掺假; 纯牛肉。 同生肉丸一致, 熟牛肉丸中被误判的5个样本的光谱曲线均落在几类掺假样本光谱范围的重叠区域。 此外, 生牛肉丸模型的分类准确率比熟牛肉丸样本高, 可能是由于炸制过程中的水分流失和油脂吸收使不同掺假比例的样本光谱信息差异减小, 从而造成模型精确度降低。
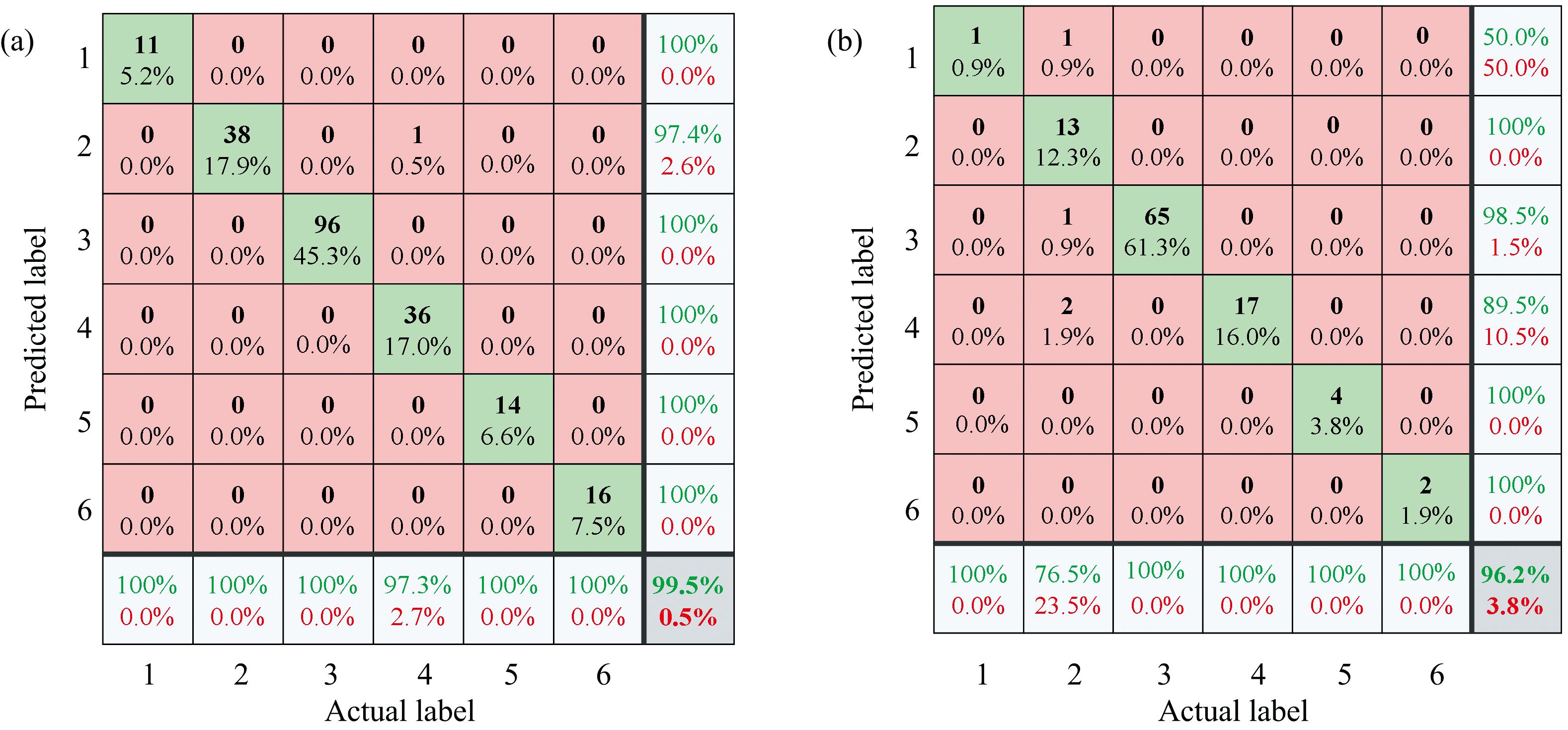 | 图5 最优模型分类结果混淆矩阵 (a): 校正集; (b): 预测集Fig.5 Confusion matrices of optimal model classification results (a): The calibration set; (b): The prediction set |
2.3.2 简化模型
运用CARS和SPA分别筛选出38和20个特征波长, 其分布情况如图6所示。 从图中可以看出, CARS/SPA筛选出的特征波段在450~550和700~800 nm分布均较少, 但在900~1 000 nm处均有较多特征变量分布。
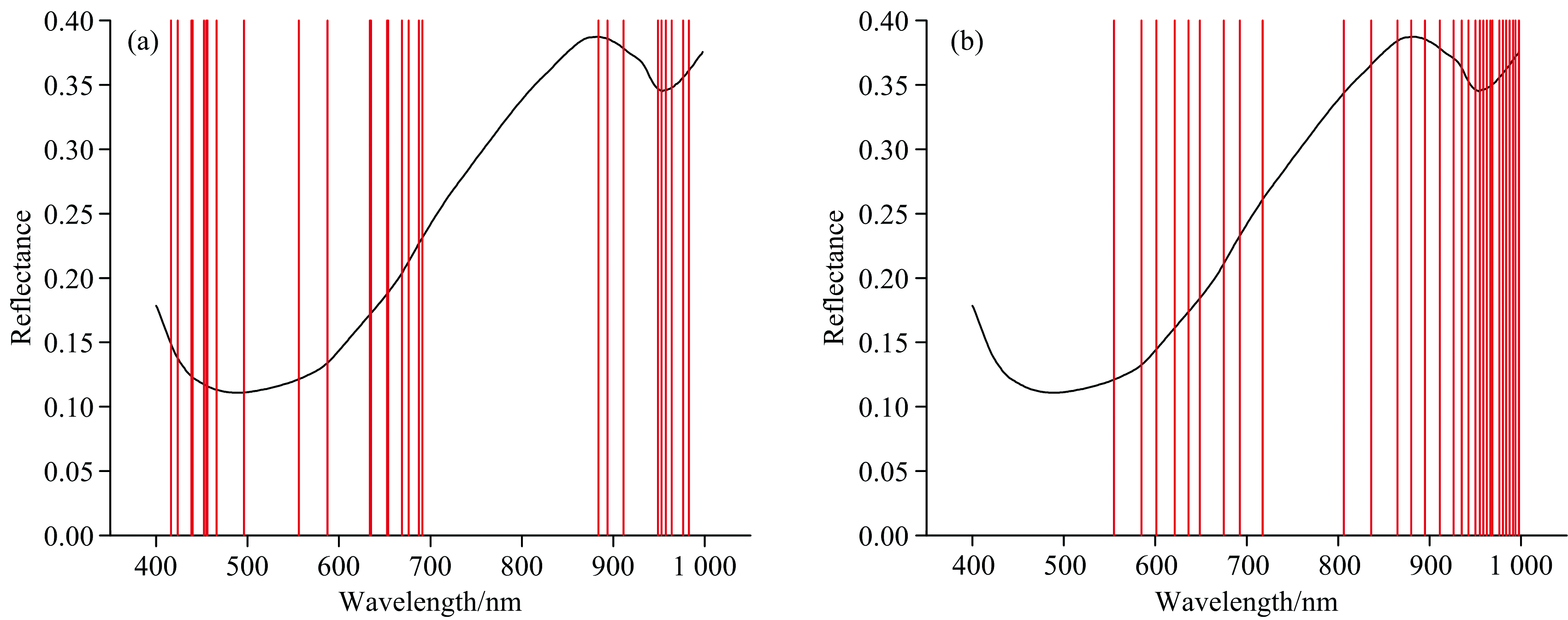 | 图6 CARS(a)和SPA(b)筛选的熟牛肉丸掺假样本特征波长分布Fig.6 Characteristic wavelengths screened by CARS (a) and SPA (b) for cooked adulterated beef ball samples |
如表4所示基于CARS建立的简化ELMC模型(CARS-ELMC-Cooked)性能明显优于SPA-ELMC-Cooked模型。 模型SPA-ELMC-Cooked的校正准确率比CARS-ELMC-Cooked的校正准确率高, 但其预测准确率较低, 因此最优简化ELMC模型为CARS-ELMC-Cooked, 其校正准确率和预测分类准确率分别是97.17%和96.23%。
| 表4 不同波长选择方法下建立的简化模型性能 Table 4 Performances of simplified models established using different wavelength selection methods |
对比不同波长选择方法下建立的简化支持向量机分类模型(SVC)效果, 经过CARS提取特征波长后建立的简化模型CARS-SVC-Cooked与基于SPA算法提取特征波长后建立的简化模型SPA-SVC-Cooked的校正准确率, 均低于全波长最优模型1stDe-SVC-Cooked。 CARS-SVC-Cooked的校正准确率和预测准确率高于模型SPA-SVC-Cooked, 因此最优简化SVC模型为CARS-SVC-Cooked, 其校正准确率和预测准确率均为91.51%。 虽然CARS-SVC-Cooked模型的校正集准确率高于CARS-ELMC-Cooked。 但是CARS-ELMC-Cooked具有更高的识别稳定性, 且模型运行时间较短, 因此熟肉丸掺假类别最优简化判别模型为CARS-ELMC-Cooked。
针对高光谱掺假检测中掺假类型单一、 缺乏熟肉制品检测、 样本制备未考虑颜色和调料影响等问题, 通过采集不同掺假物、 不同掺假比例的生/熟牛肉丸掺假样本光谱, 结合不同的光谱预处理方法, 分析比较了不同分类判别模型及其特征变量筛选后建立的简化模型的性能, 结果表明: (1)不同预处理方法(SG, VN, 1stDe, MSC, SNV)对模型性能的影响不同, 最优全波长生肉丸分类模型为经过SNV预处理后建立的SVC模型, 而最优全波长熟肉丸分类模型为经过1stDe预处理后建立的SVC模型。 (2)对原始生肉丸光谱数据进行特征波长筛选, 利用CARS得到27个特征波长, 利用SPA得到44个特征波长。 基于特征变量所建立最优简化模型为SPA-ELMC, 校正准确率和预测准确率均达到97.17%。 (3)对原始熟肉丸光谱数据进行特征波长筛选, 利用CARS得到38个特征波长, 利用SPA得到20个特征波长。 基于特征变量所建立的最优简化模型为CARS-ELMC, 校正准确率和预测准确率分别为97.17%和96.23%。 研究表明高光谱成像技术结合化学计量学方法可以有效识别牛肉丸中猪肉/鸡肉以及猪肉-鸡肉的复合掺假, 为开发相应便携式光谱仪器奠定了理论基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|