
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
SATS: 一种基于多重特征提取的恒星光谱分类算法
[屠良平1, 2  , 李双川
, 李双川2 , 涂东鑫1 , 李建喜1, * , 丁治超2 ]
, 李双川, 丁治超|
|


作者简介: 屠良平, 1977年生,辽宁科技大学理学院教授 e-mail: tlp_kd@163.com
对恒星光谱进行深入研究, 可以了解恒星的化学组成和物理特性。 恒星光谱分类是恒星光谱研究领域的一个重要方向, 随着海量恒星光谱数据的出现, 人工分类手段就无法满足科研的需要。 基于此, 搭建了SATS(SVD Analysis Transformer SoftMax)算法, 该算法实现了对F、 G、 K型恒星光谱的自动分类。 SATS算法, 首先以奇异值分解(SVD)的方式, 对归一化后的恒星光谱做去噪处理; 然后对恒星光谱进行特征提取, 特征提取层共有六个模块: 增量主成分分析(Incremental PCA)、 核主成分分析(Kernel PCA)、 稀疏主成分分析(Sparse PCA)、 因子分析(Factor Analysis)、 独立成分分析(Fast ICA)和Transformer(前五个模块统称为Analysis模块), 为保证方差贡献率在0.95以上, IPCA、 KPCA、 Sparse PCA、 Factor Analysis和Fast ICA将恒星光谱特征提取为300维; 最后, 将恒星光谱输入到SoftMax层进行自动分类。 SATS算法将多个Analysis模块结合使用, 进一步提高了使用单一Analysis模块的分类正确率。 Transformer模块和多个Analysis模块的结合使用, 再一次提高了分类正确率。 SATS算法最大的优势在于对恒星光谱进行了多重特征提取, 以不同的特征提取方式, 最大程度地保留了原始恒星光谱信息, 将信息损失做到最低。 SATS算法的最终分类正确率为0.93, 这一分类正确率也高于混合深度学习算法CNN(convolutional neural network)+Bayes、 CNN+KNN、 CNN+SVM、 CNN+Adaboost和CNN+Adaboost0.86、 0.88、 0.89、 0.87、 0.89的分类正确率。
An in-depth study of a stellar’s spectrum provides insight into its chemical composition and physical properties. Stellar spectrum classification is an important direction in stellar spectrum research. With the emergence of massive stellar spectrum data, artificial classification cannot meet scientific research needs. Based on this, this paper constructs the SATS algorithm, which realizes the automatic classification of F, G, and K-type stellar spectra. Firstly, the SATS algorithm uses singular value decomposition (SVD) to denoise the normalized stellar spectra. Then, the SATS algorithm performs feature extraction on the stellar spectrum. The feature extraction layer consists of six modules:Incremental principal component analysis (IPCA), nuclear principal component analysis (KPCA), sparse principal component analysis (SparsePCA), FactorAnalysis, independent component analysis (FastICA) and Transformer(the six modules are collectively referred to as Analysis module), to ensure that the variance contribution rate is above 0.95, IPCA, KPCA, SparsePCA, FactorAnalysis and FastICA extract the stellar spectral features into 300 dimensions. Finally, the stellar spectra are fed into the SoftMax layer for automatic classification. SATS algorithm combines multiple analysis modules to improve the accuracy of classification further using a single analysis module. Once again, the combination of Transformer modules and multiple Analysis modules improves classification accuracy. The most significant advantage of the SATS algorithm is that it performs multiple feature extraction on the stellar spectrum, which retains the stellar spectral information to the maximum extent and minimizes the information loss by different feature extraction methods. The final classification accuracy of the SATS algorithm is 0.93, which classification accuracy is also higher than that of the hybrid deep learning algorithms CNN+Bayes, CNN+Knn, CNN+SVM, CNN+Adaboost and CNN+Adaboost 0.86, 0.88, 0.89, 0.87, 0.89.
恒星主要是由氢、 氦和微量较重元素这些发光等离子体构成的巨型球体。 晴朗的夜晚, 夜空中那数不清的“星星”, 除少数行星外, 绝大多数都是恒星。 生活中, 我们每个人持有不同的身份证号, 这个特殊的向量将不同省市区的人们进行了有效区分。 对恒星来说, 由于恒星间的光谱各不相同, 故将光谱看作是恒星的身份证号。 其中, F型光谱对应的恒星, 表面温度在7 600~6 000 K之间, 恒星颜色为黄白色, 其谱线特征为: 有大量的金属线出现, 电离出现的钙线加强增宽, 氢线强; G型光谱对应的恒星, 表面温度在6 000~5 000 K之间, 恒星颜色为黄色, 其谱线特征为: 电离的钙线极强极宽, 全部的金属线增强, 氢线开始变弱; K型光谱对应的恒星, 表面温度在5 000~3 600 K之间, 恒星颜色为橙色, 其谱线特征为: 金属线比G型恒星的金属线强很多, 但是氢线弱。 恒星光谱所蕴含的物理、 化学信息, 对人类了解恒星、 了解宇宙意义重大。
本文实验数据来自LAMOST-DR8数据集和SDSS(sloan digital sky survey)[1]恒星光谱模板库。 LAMOST[2](large area multi-target optical fiber spectroscopic astronomical telescope)为人类了解宇宙及银河系做出了巨大的贡献。 2022年6月, 基于LAMOST数据, 陈静等发现600多颗处于特殊演化阶段的S型恒星[3]; 2022年3月, 基于LAMOST数据, 天文学家向茂盛和Hans-Walter Rix揭示了银河系早期的形成和演化历史, 研究成果以封面期刊的形式发表于Nature期刊[4]; 2022年3月, 基于LAMOST数据, Martin等发现宇宙中金属含量最低的球状星团遗迹[5]; 2021年5月, 基于LAMOST数据, Li等证实银河系反银心子结构起源于银盘, 等等。
学者们已经搭建了很多恒星光谱自动分类算法。 如, 逯亚坤等提出了特征融合卷积神经网络(FFCNN)分类模型, 该模型用于二维恒星光谱的分类[6]。 Zhao等设计了六个卷积神经网络分类器, 以集成的方式对恒星光谱进行分类[7]。 Kyritsis等使用随机森林(RF)算法开发了一个工具, 根据恒星光谱的子类型对OB型恒星光谱进行自动分类[8]。 洪舒欣等提出基于卷积神经网络的恒星光谱型和光度型的分类模型[9]。 Liu等提出双超球模型的恒星光谱分类算法[10]。 杜利婷等提出利用胶囊网络对恒星光谱进行分类的方法[11]。 Brice等提出使用单个分类器来对恒星光谱进行Morgan-Keenan分类[12]。 Sharma等提出使用卷积神经网络对恒星光谱进行分类的方法[13]。 Liu等提出基于类内散度和类间散度的SVM恒星光谱分类算法[14]。 张静敏等利用短时傅里叶变换(STFT)将一维光谱数据转化为二维傅里叶光谱图像, 然后再使用深度卷积网络对二维傅里叶频谱图像进行分类, 以间接实现恒星光谱分类任务[15]。 以上恒星光谱分类算法均为“特征提取器+分类器”的模式, 但是这些算法均只有一个特征提取器, 或是一个特征提取器的多次使用, 本文提出的SATS算法, 其使用了六个特征提取器对恒星光谱进行特征提取, 六个不同的特征提取器以各自独有的计算方式提取到了恒星光谱的不同特征, 这样的设计使恒星光谱的分类特征更加明显, 分类任务的结果更优。
SATS算法性能优异, 表现良好, 但目前只应用在了F、 K、 G型恒星光谱分类任务中, 若在恒星、 星系、 类星体光谱分类任务中有良好的实验结果, 将进一步证实其优异的性能; 此外, 随着更多、 更好的Transformer算法的出现, SATS算法在将来一定会有更加完美的表现。
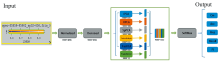
SATS是一个拥有输入层、 归一化层、 去噪层、 特征提取层和SoftMax输出层5层网络架构的算法。 SATS算法结构如图1所示。 结构图中的数字是该层输出数据的维度。
 | 图1 SATS算法结构图Fig.1 SATS algorithm structure diagram |
本文选用的实验数据如下: ①LAMOST-DR8数据集中r波段信噪比大于30的高质量F、 G、 K型恒星光谱, 其中F、 G、 K型恒星光谱各3000条; ②SDSS恒星光谱模板库中的F、 G、 K型恒星光谱, 其中F、 G型恒星光谱各10条, K型恒星光谱13条。 恒星光谱在不同波长位置处流量差异巨大, 在有吸收线的位置流量值往往较低。 对机器学习算法而言, 数据自身较大的差异会使算法学习到过多无用特征, 导致最终结果不佳。 对恒星光谱进行归一化处理, 使光谱流量处于同一数量级, 不仅消除了光谱自身一些较大的差异, 还使算法收敛的更快。 本文使用式(1)所示的线性归一化函数, 来对光谱做归一化处理。
式(1)中, flux为原始光谱流量, fluxmax和fluxmin分别为原始流量的最大值和最小值, Fluxn表示归一化后的流量。
SVD算法有较好的零相移特性和稳定性, 可以很好地抑制窄带噪声。 本文舍弃了光谱去噪领域较为流行的小波变换去噪算法, 转而使用SVD算法来对光谱做去噪处理。 详见第2.1节。 SVD去噪分三个步骤进行。 首先将恒星光谱构造为一个Henkle矩阵, 如式(2)
式(2)中, N为光谱数据个数, L为窗长度。 然后对H矩阵进行奇异值分解, 如式(3)
式(3)中, S为HHT的左奇异矩阵; D为HHT的右奇异矩阵; V是奇异值的对角矩阵。 最后, 对奇异值进行处理并重构信号。 将对应奇异值处理后, 可以得到新对角矩阵V', 设重构后的Henkle矩阵为H', 则有式(4)
对重构矩阵H'做反对角平均处理, 以实现抑制窄带噪声。
包含六个模块的特征提取层是SATS算法的核心控制层。 传统的PCA模块将全部数据一次性放入内存进行计算, 对海量高维数据来说, 这显然会降低硬件的运行效率并缩短硬件的使用寿命。 IPCA模块将海量数据分为若干小块, 每次只对其中的一块数据进行计算。 这样不仅可以用来处理更大规模的数据集, 同时也方便了在线处理。 为了更好地提取数据的“非线性”特征, 使用非线性映射将原始光谱数据投射到高维特征空间, 然后在这个高维特征空间中使用PCA, 这就是KPCA。 众所周知, 传统的PCA模块可解释性较差, SparsePCA模块即是为了解决此问题而产生的算法。 SparsePCA将主成分系数变得稀疏, 换言之, 即把部分系数变为0, 以这样一种方式将主成分的主要部分凸显出来, 这样主成分就会变得容易解释。 FastICA是近几年出现的算法, 其原理基于递推算法, 它最大的优势就是适用于各种各样的数据。 FastICA在每一次迭代中均有大量数据参与运算, 即它以批处理的形式对数据进行处理。 从并行处理的角度看, FastICA可以看作是神经网络算法, 这也就让它具有众多神经网络算法的优点: 并行的、 分布的、 计算简单、 占用内存少。 Factor Analysis是PCA的延伸和拓展应用, 其定义如式(5)
式(5)中, X为光谱数据, f为潜在变量, A为因子载荷, ε 是误差项。 A为X和f之间的相似性, 因子变量值越大, X和相应因子间的相似性就越高。 使用多种Analysis模块对恒星光谱进行特征提取, 自然就包含了多种计算方式下的光谱特征, 从而使原始光谱特征损失更少。
Transformer特征提取模块包含四个小模块, 连续谱拟合模块、 连续谱归一化模块、 谱线积分模块和Transformer特征学习模块。 谱线特征是LAMOST产出光谱最有效的特征, 为了获取谱线信息, 需要拟合光谱的连续谱, 本文使用7阶多项式来拟合连续谱。 连续谱归一化是剔除连续谱特征获得谱线信息的有效手段。 设拟合连续谱流量为F″, 去噪后的光谱流量为F', 则归一化后的光谱F可表示为式(6)
本文将整个波长区间进行10等分, 使用梯形积分法对光谱谱线信息进行数值积分。 最后每条光谱对应产生10个积分值, 这10个积分值即为恒星光谱的新特征。 最后, 使用Transformer实践应用算法BERT对10个积分值进行特征学习。 Transformer模型的计算核心是Attention函数, 其计算过程如式(7)所示
其中, headi=Attention(Q
实验过程, 即为SATS算法的搭建过程。
大气湍流等自然因素以及观测设备自身的一些漏洞, 导致LAMOST产出光谱掺杂了一定的噪声。 为了避免噪声对科研任务的影响, 需要对光谱做去噪处理。 小波变换是恒星光谱去噪领域最常用的方法, 但是通过本文的实验, 我们发现SVD算法更适合应用于恒星光谱的去噪任务。 因为LAMOST没有较精准的模板光谱, 所以使用SDSS恒星光谱模板库中的恒星光谱作为实验数据。 假定模板光谱不含有任何噪声, 人工为其添加高斯白噪声、 均匀白噪声和泊松噪声后, 使用小波变换和SVD算法对添加噪声后的光谱分别做去噪处理, 以去噪前后光谱的信噪比衡量去噪算法的性能。 其中, 高斯白噪声的信噪比为3 dB, 均匀白噪声的均值和方差分别为: 0, 0.1, 泊松噪声的常系数为0.1。 信噪比的计算, 如式(8)—式(10)。 在本节中, 信噪比作为一种指标, 只为衡量两种去噪算法的去噪能力, 1.2节所述信噪比来自LAMOST, 其经过了复杂的计算, 对天体光谱来说, 更科学、 更符合天体的物理化学性质, 和本节信噪比没有联系。 恒星光谱掺杂的噪声多以随机噪声的形式存在, 故本实验主要考察两种算法剔除随机噪声的能力。 实验结果如表1, 表2所示。 需要说明的是, 我们虽然指定了噪声的生成参数, 但噪声产生的随机性, 还是让恒星光谱的信噪比不尽相同。
其中, S为原始恒星光谱的功率, N为噪声功率, flux为光谱流量。
| 表1 SVD去噪前后模板光谱的信噪比 Table 1 Signal to noise ratio of SVD template spectrum before and after denoising |
| 表2 小波变换去噪前后模板光谱的信噪比 Table 2 Signal to noise ratio of template spectrum before and after wavelet transform denoising |
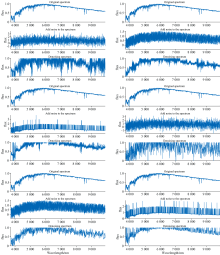
添加不同类型的噪声后, 模板光谱的信噪比出现了不同程度的变化。 由表1、 表2可以看出, SVD算法去噪后的光谱, 其信噪比更高。 对于添加高斯白噪声的光谱, 小波变换为其去噪后, 光谱的信噪比不到10, 而SVD超过10; 对于添加均匀白噪声的光谱, 小波变换为其去噪后, 光谱的信噪比不到17, 而SVD超过17; 对于添加泊松白噪声的光谱, 小波变换为其去噪后, 光谱的信噪比不到14, 而SVD超过14。 图2为一条光谱去噪前后的展示图, 上方3图使用的是SVD算法, 下方3图使用的是Wavelet算法。 其中, 左侧图处理的是高斯噪声、 中间图处理的是均匀噪声、 右侧图处理的是泊松噪声。
 | 图2 SVD和小波变换去噪前后的模板光谱图Fig.2 SVD and wavelet transform before and after denoising template spectra |
从图2左侧图可以看出, SVD算法剔除高斯噪声后, 保留了恒星光谱的吸收线、 发射线结构, 而Wavelet算法将全谱范围内的谱线拉长、 “变稀”; 从图2可以看出, SVD算法虽然改变了谱线的宽度, 但是很好地凸显出了主要谱线特征, 反观Wavelet算法, 其将谱线处理的过于稀疏, 让恒星光谱在全谱范围内保持了某种波动规律; 从图2右侧图可以看出, 由于添加噪声的扰动过大, 导致光谱蓝端出现了较大误差, 但是从全谱范围内来看, SVD算法很好地保留了光谱的发射线、 吸收线结构, 而Wavelet算法除保留了部分蓝端谱线外, 基本丢失掉了恒星光谱的吸收线和发射线结构。 基于以上论述, 我们认为SVD算法更适合用于剔除光谱的随机噪声。 由于对恒星光谱做了归一化处理, 因此, 本节仅关注[0, 1]区间内的数据, 可以肯定, 超出此区间范围的数据一定是噪声。
在上面的论述中, 我们比较了SVD、 Wavelet两种算法剔除光谱随机噪声的能力。 但是, 上面的论述只使用了一条恒星光谱进行实验, 实验结果或许有一定的随机性。 在接下来的论述中, 我们从SDSS恒星光谱模板库挑选了F、 G、 K型恒星光谱各10条进行实验。
恒星光谱去噪前后的‘ 差异性’ , 是衡量一个去噪算法性能的重要参考标准, 本次实验, 为添加噪声的恒星光谱做去噪处理后, 我们将其同原始恒星光谱进行了比较, 计算了整个波长区间内流量的绝对误差, 计算公式如式(11)。 实验结果如表3。
式(11)中, Flux为去噪后的光谱流量, flux为原始光谱流量。
| 表3 SVD、 Wavelet去噪前后光谱流量的绝对误差 Table 3 Absolute error of spectral flux before and after SVD and Wavelet denoising |
在表3中, 1—10行是SVD算法去噪后的光谱流量同原始光谱流量的绝对误差; 13—22行是Wavelet算法去噪后的光谱流量同原始光谱流量的绝对误差。 从表3可以看出, F型恒星光谱经SVD算法处理后, 产生了10个绝对误差数据, 这10个数据的均值和方差是87.389 56和10.379 27; F型恒星光谱经Wavelet算法处理后, 产生了10个绝对误差数据, 这10个数据的均值和方差是110.06和14.607 73, 这说明, Wavelet算法处理后的恒星光谱同原始恒星光谱相比‘ 差距’ 更大, 而且稳定性不如SVD算法, 对于G、 K型恒星光谱可以得出相同的结论。 F、 G、 K型恒星光谱经SVD算法处理后, 产生了30个绝对误差数据, 这30个数据的均值和方差是299.108 1、 59.448 03, F、 G、 K型恒星光谱经Wavelet算法处理后, 产生了30个绝对误差数据, 这30个数据的均值和方差是345.015 8、 69.251 49, 这说明SVD算法去噪后的恒星光谱同原始恒星光谱相比, 差异性更小, 稳定性更高。 因此, 我们认为SVD算法更适合用于剔除光谱的随机噪声。
在2.1节中, 我们证实了SVD算法可以很好地应用于恒星光谱去噪任务, 然而对恒星光谱做去噪处理真的会提高分类正确率吗? 本节实验用来回答这个问题, 我们使用SVD去噪算法进行本次实验。 采用对比实验的形式进行本次实验: (1)将归一化处理后的F、 G、 K型恒星光谱直接输入至SoftMax层进行分类; (2)将归一化后的光谱做去噪处理后, 再输入至SoftMax层进行分类。 通过前后两次实验结果的比较, 来考察对光谱做去噪处理是否真的会提高分类正确率。 在本文中, SoftMax层的损失函数是数据集损失和正则项损失的加和。 实验结果如表4所示, 其中Ⅰ代表第一次实验, Ⅱ代表第二次实验。
| 表4 去噪效果评估的实验结果 Table 4 The experimental results of denoising effect evaluation |
可以看出, 使用去噪的恒星光谱进行实验, 其实验结果的绝大数指标是更优的。 此外, 测试集分类准确率也由0.76提高至0.8。 因此得出结论: 对恒星光谱做去噪处理是必要的。
PCA作为经典的特征降维算法, 在恒星光谱降维领域已广泛应用。 IPCA、 KPCA、 SparsePCA、 FactorAnalysis和FastICA作为独立的模块, 同样可以对恒星光谱做特征降维处理。 本节实验旨在考察: 使用不同的Analysis模块对恒星光谱分类任务的影响。 本节实验的工作机制如下: IPCA、 KPCA、 SparsePCA、 FactorAnalysis和FastICA五个特征降维模块, 对SVD算法去噪后的恒星光谱分别做特征降维后, 输入到SoftMax层进行自动分类。 实验结果如表5所示。
| 表5 使用单一特征提取模块进行分类的实验结果 Table 5 Experimental results of classification using a single feature extraction module |
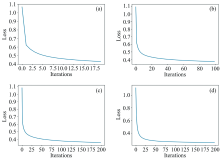
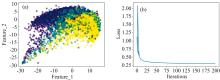
由表5可以看出, 使用FactorAnalysis模块对恒星光谱做特征提取是最有效的, 该次实验的大部分分类指标均优于其他实验。 其次是SparsePCA模块, 使用该模块对恒星光谱做特征提取后再分类, 分类正确率达到了0.86。 使用IPCA模块、 KPCA模块、 SparsePCA模块和FactorAnalysis模块进行的分类实验, 其所对应的收敛曲线如图3所示, 其中图3(a)为使用IPCA模块进行的实验, 图3(b)为使用KPCA模块进行的实验, 图3(c)为使用SparsePCA模块进行的实验, 图3(d)为使用FactorAnalysis模块进行的实验。 将特征降维后的前两个‘ 特征数据’ 作为横坐标、 纵坐标的数据分布图, 如图4所示, 其中图4(a)为使用IPCA进行实验的数据分布图, 图4(b)为使用KPCA进行实验的数据分布图, 图4(c)为使用SparsePCA进行实验的数据分布图, 图4(d)为使用FactorAnalysis进行实验的数据分布图。 图中3种颜色代表F、 K、 G三种光谱, 即用特征向量的两个特征值代表一条光谱。
 | 图3 使用IPCA、 KPCA、 SparsePCA、 FactorAnalysis特征提取模块进行实验的收敛曲线图Fig.3 Use IPCA, KPCA, SparsePCA, FactorAnalysis feature extraction modules to carry out the convergence diagram of the experiment |
 | 图4 ‘ 特征’ 数据分布图Fig.4 ‘ Feature’ data distribution map |
从2.3节可以看出, 使用单一Analysis模块, 对恒星光谱做特征降维后再分类, 其测试数据集的分类正确率已经在0.8以上。 如果将各Analysis模块结合使用, 会不会有更优的实验效果? 本节实验旨在说明这个问题。
首先将各Analysis模块进行横向组合。 即对一条4 096维的恒星光谱来说, 将使用一个1500维的新“光谱”代替。 实验结果如表6所示。
| 表6 特征提取模块组合使用的实验结果 Table 6 Experimental results of the combination of feature extraction modules |
然后将各Analysis模块进行纵向组合。 即对一条4 096维的恒星光谱来说, 将使用一个300维的新“光谱”代替。 需要说明的是, 此300维的新“光谱”是各Analysis模块产出数据的加和。 实验结果如表6所示。
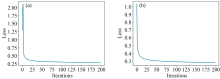
由表6可以看出, 将Analysis模块结合使用, 对恒星光谱分类任务是有益的。 Analysis模块横向组合、 纵向组合后, 其测试集分类正确率均高于只使用单一Analysis模块的分类正确率。 FactorAnalysis作为最优的Analysis模块, 其测试集分类正确率为0.87; 而将Analysis模块横向组合、 纵向组合后, 测试集准确率达到了0.91、 0.89。 两次实验的收敛曲线如图5所示, 其中图5(a)为Analysis模块横向组合的收敛曲线图, 图5(b)为Analysis模块纵向组合的收敛曲线图。
 | 图5 Analysis模块结合使用的收敛曲线图Fig.5 Convergence graphs used in combination with analysis modules |
将Analysis模块结合使用, 可以优化恒星光谱分类任务的实验效果。 本次实验, 将NLP领域大放光彩的Transformer实践应用算法‘ BERT’ 作为特征提取模块, 同Analysis模块结合使用, 来进一步优化恒星光谱分类任务的实验效果。 由2.4节可以看出, 将Analysis模块横向组合可以有更好的实验结果, 因此, 本节将Transformer模块同Analysis模块继续横向组合。 本次实验结果如表6所示。
本次实验, 我们进一步提高了测试集的分类正确率, 测试集分类正确率由0.91提高至0.93, 其他实验指标也有不同程度的优化。 SATS算法由此产生。 本次实验的数据分布图和收敛曲线图如图6所示, 图中3种颜色代表F、 K、 G三种光谱, 也即用特征向量的两个特征值代表一条光谱。
 | 图6 Transformer、 Analysis模块结合使用的 收敛曲线图和数据分布图Fig.6 Convergent graphs and data distribution diagrams used in combination with Transformer and Analysis modules |
本节实验的工作机制如下: SVD算法对归一化恒星光谱做去噪处理后, 输入至卷积神经神经网络(CNN)[16]中进行特征提取, 再输入至贝叶斯算法(Bayes)、 K近邻算法(KNN)、 支持向量机算法(SVM)、 Adaboost算法和随机森林算法(RF)中进行分类。 最后, 将混合深度学习算法的分类正确率, 同SATS算法的实验结果进行比较, 以此来考察SATS算法的分类性能。 实验结果如表7所示。
| 表7 对比算法的分类正确率 Table 7 Classification accuracy of comparison algorithm |
由表7可以看出, 混合深度学习算法的分类正确率最高为0.89, 低于SATS算法0.93的分类正确率。 由此也证明了SATS算法可以胜任恒星光谱分类任务, 它是有效的、 是优异的。
对恒星光谱进行准确分类、 高效识别, 在天文学研究中意义重大。 本文搭建了SATS算法, 该算法实现了对恒星光谱的自动分类。 SATS算法的诞生, 为海量恒星光谱分类任务又提供了一个好的方法。 SATS算法有着较高的分类准确率, 在F、 G、 K型恒星光谱分类任务中, 其分类正确率达到了0.93。 SATS算法最大的优势在于对恒星光谱进行了多重特征提取, 以不同的特征提取方式, 最大程度地保留了恒星光谱信息, 将信息损失做到了最低。 此外, 本文成功将深度学习模型Transformer应用在了恒星光谱分类任务, 毋庸置疑, 这是将深度学习模型应用在天文学研究领域, 又一次有益且成功的尝试。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|