

{kind=link}
{kind=link}
{kind=link}
基于近红外光谱法的精米品种判别优化研究
[杨森1  , 王振民
, 王振民1, * , 宋文龙1 , 邢键1 , 戴景民2 ]
, 王振民, 宋文龙|
|


作者简介: 杨 森, 1987年生,东北林业大学计算机与控制工程学院讲师 e-mail: yangsen@nefu.edu.cn
由于地理标志性大米巨大的市场价值, 导致掺假行为时有发生。 因此, 为保证地理标志性大米品牌效益和消费者权益, 实现准确的精米品种判别具有重要意义。 近红外光谱法是精米品种判别的常用方法, 通过提取不同品种近红外光谱中的差异性特征实现品种分类。 然而, 现有研究中存在特征波长选取性能不足和针对指定品种判别准确度不足的问题, 限制了基于近红外光谱法的精米品种判别准确度的提升。 针对上述问题, 面向东北地区五常、 响水、 越光、 银水四种大米, 从特征波长选取和品种判别策略两个方面, 研究基于近红外光谱法的精米品种判别优化。 首先, 为提高特征波长选取性能, 将排列熵和自适应滑动窗口分割相结合, 提出了基于自适应滑动排列熵的精米光谱特征波长选取方法, 并开展与传统特征波长选取算法的对比实验。 其次, 为提高面向不同指定品种的判别准确度, 提出基于判别目标的精米品种判别策略, 通过研究光谱预处理算法与分类建模算法匹配优化, 建立“指定品种-选定模型-选定算法的”的判别流程。 实验结果表明, 采用所提出的自适应滑动排列熵算法进行特征波长选取, 相比于传统算法精米品种判别误差至少可降低50%; 采用所提出的基于判别目标的精米品种判别策略, 相比于传统的基于固定模型的判别策略的判别准确度至少可提高2.5%。
Due to the enormous market value of geographically iconic, adulteration or fraud often occurs. Therefore, to ensure the brand benefits from geographically iconic rice and consumer rights, it is important to identify polished rice varieties accurately. Near-infrared spectroscopy is a common method to distinguish polished rice varieties. The varieties can be classified by extracting the different features of different types in near-infrared spectroscopy. However, there are some problems in the existing studies, such as insufficient characteristic wavelength selection performance and insufficient discrimination accuracy for specific varieties, which limit the improvement of the discrimination accuracy of polished rice varieties based on the near-infrared spectroscopy method. In response to the above problems, this paper studies the optimisation of milled rice variety identification based on near-infrared spectroscopy from the two aspects of characteristic wavelength selection and variety identification strategies for four types of rice, Wuchang, Xiangshui, Koshihikari, and Yinshui in Northeast China. First, permutation entropy (PE) and adaptive sliding window (ASW) were combined to improve the feature wavelength selection performance. An adaptive sliding permutation entropy (ASW-PE) based method for selecting the characteristic wavelength of polished rice spectrum was proposed and compared with the traditional algorithm. Secondly, a discriminant strategy based on the discriminant objective was proposed to improve the discriminant accuracy of different specified varieties. By studying the matching optimisation of the spectral preprocessing algorithm and classification modelling algorithm, a discriminant process of “specified cultivation-selected model-selected algorithm”was established. Experimental results show that using the adaptive sliding permutation entropy algorithm proposed in this article to select characteristic wavelengths can reduce the milled rice variety discrimination error by at least 50% compared with the traditional algorithm; using the milled rice variety judge strategy based on the discrimination target proposed in this article. Compared with the conventional judge strategy based on fixed models, the discrimination accuracy can be improved by at least 2.5%.
地理标志性大米因其营养、 品质和口感等优势而备受消费者青睐, 市场价值巨大[1]。 不良商家将普通大米掺进地理标志大米[2], 甚至错误的标识地理来源, 不仅极大损害地理标志性大米声誉, 也损害了种植户正当权益, 更降低了消费者的购买积极性和品质信赖[3, 4, 5]。 因此, 实现准确的地理标志性大米品种判别, 是消费者、 零售商、 生产者以及政府当局的迫切需要[6]。
国内外许多研究人员都开展了精米品种判别技术研究, 所用方法包括近红外光谱法[7, 8, 9, 10]、 拉曼光谱法[11]、 等离子体质检法[12]等。 其中, 近红外光谱法研究和应用较多。 宋雪健研究了基于近红外光谱法的五常和查哈阳的大米产地溯源[7]。 钱丽丽基于近红外光谱法分别研究了查哈阳大米[8]、 五常大米[9]、 建三江大米[10]的鉴别方法。 然而, 现有基于近红外光谱法的精米品种判别研究中, 由于一般采用某一种固定模型进行不同品种判别, 即基于固定模型的判别策略, 存在针对指定品种判别准确度不足的问题。
在基于近红外光谱法的精米品种判别中, 光谱特征波长选取是关键步骤, 提取出的特征波长能否最大化体现大米品种间差异化, 直接决定大米品种判别准确度。 目前常用的光谱特征波长选取算法为方差分析算法(analysis of variance, ANOVA)、 竞争性自适应重加权采样算法(competitive adapative reweighted sampling, CARS)法和连续投影算法(successive projections algorithm, SPA)。 宋雪健[7]和钱丽丽[10]基于光谱吸收峰和ANOVA算法确定特征光谱波段。 翁士壮[13]在大米无损鉴别研究中, 利用CARS算和SPA算法提取大米光谱特征波长并对比。 然而, 近红外光谱波长变量冗余且相邻波长间相关性较强, 在大米品种判别中采用上述方法存在特征波长选取性能不足的问题。
针对上述问题, 选用东北地区五常、 响水、 越光、 银水四种大米构建数据集, 以提高基于近红外光谱法的精米品种判别准确度为目标, 深入优化特征波长选取算法, 提出基于自适应滑动排列熵的精米光谱特征波长选取方法; 深入优化判别策略以满足不同测量需求, 提出基于判别目标的精米品种判别流程。
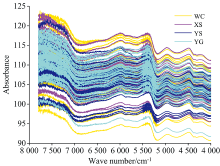
实验样品选用五常(WC)、 响水(XS)、 银水(YS)和越光(YG)四个大米品种, 研磨处理后获得米粉。 为降低温湿度影响, 将米粉分类置于磨口瓶中室温密封一周。 然后, 以10 g米粉为单位, 4个品种共获取4×80个共320个样本, 按1∶1比例划分为训练集和验证集。 采用iCAN9傅里叶变换红外光谱仪搭配PN044-60XX型漫反射附件进行光谱采集。 光谱测量范围4 000~7 800 cm-1, 扫描次数32次, 分辨率调节范围1~16 cm-1, 分辨率选用4 cm-1。 每个样本采集光谱三次并取平均值, 获取的原始光谱曲线如图1所示。
 | 图1 原始光谱曲线Fig.1 Raw spectral curves |
图1中每条光谱曲线包含1 972个数据点。 由于含氢基团与近红外光波谐振使得分子能级发生跃迁, 光谱曲线在不同波段呈现不同的吸收峰。 受仪器性能以及光谱散射等问题干扰, 光谱图中存在两处较明显噪声区。 此外, 原始光谱中存在大量冗余光谱信息, 因此需要进行光谱特征波长选取以保证精米品种判别准确度。
将排列熵(permutation entropy, PE)和自适应滑动窗口分割(adaptive sliding-window, ASW)相结合, 提出自适应滑动排列熵(ASW-PE)方法用于精米光谱特征波长选取。 新算法的原理如下:
滑动窗口模型为观测样本顺序排列的动态数据块矩阵, 第k个数据窗口表示为
式(1)中, L为窗口宽度, 由标准差矩阵Σ k、 均值mk和Gram矩阵Gk描述窗口的统计特征
式(2)和式(3)中, Xk为标准化后的数据块矩阵。 定义第k+1个新数据窗口的Gram矩阵为GH, 并建立新旧数据窗口的混和Gram矩阵
对GΩ进行特征值分解, 特征值对角阵和特征向量分别为Λ Ω和PΩ, 定义转换矩阵
通过转换矩阵
对G'k和G'H进行特征值分解得到
通过窗口滑动并设置遗忘个数l=μL对旧窗口数据进行自适应丢弃, 得到第k+1个数据窗口为
式(8)中, H为滑动步长, l为自适应丢弃样本的数量。 对自适应滑动窗口分割后的时间序列进行相空间重构, 获得新的时间序列为
式(9)中, m是嵌入维数, τ 是延迟时间。 将时间序列的重构分量按照升序排列可得
式(10)中, j1, j2, …, jm表示各元素的索引位置, 如果在重构分量中观测到相等的序列, 根据索引位置排序, 即x(1+(ja-1)τ )≤x(1+(jb-1)τ ), (a<b)。 m维向量的排列方式有m种, 通过计算时间序列出现的相对频率获得一个有序的模式概率分布P={pj, j=1, 2, …m!}, 以此估计香农熵
排列熵值的大小表示信号随机性和可预测性的高低。 将Hp用logm!归一化, 即
式(10)中, Smax是从一个等概率顺序模式中获得的值, Hp的取值范围为0≤Hp≤1, Hp的变化反映并放大了时间序列的细微细节, 其值越小代表时间序列越规则, 反之, 则越随机。
基于ASW-PE算法进行特征选取流程如下:
(1)对滑动窗口参数初始化, 然后基于窗口遗忘指标对时间序列自适应滑动分割得到子序列;
(2)对子序列进行相空间重构, 并对重构的分量进行升序排列;
(3)计算各分量下标顺序出现的相对频率m!作为该分量的概率;
(4)对子序列所有分量的信息熵求和, 即被测样品的排列熵值, 根据排列熵值差异度(PE比值大于1.5)选择最优窗口并定位特征波段。
传统的基于固定模型的精米品种判别策略仅采用固定模型进行不同品种判别, 存在针对指定品种判别准确度不足的问题。 为此, 提出基于判别目标的精米品种判别策略, 示意图如图2所示。
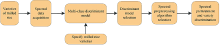 | 图2 基于判别目标的精米品种判别策略Fig.2 Discriminative strategy of polished rice varieties based on discriminative target |
采用基于判别目标的精米品种判别策略时, 建立基于多种分类算法的判别模型库, 然后获取不同指定精米品种对应的最优判别模型。 此外, 不同的判别模型所对应的最优光谱预处理算法也是不同的。 因此, 基于不同精米品种对应的最优判别模型和最优光谱预处理算法, 在测量过程中按照“指定品种-选定模型-选定算法的”的流程展开。
本节将本文提出的ASW-PE算法与传统的ANOVA、 SPA和CARS算法进行对比实验。 在ASW-PE算法中, 滑动窗口参数初始化设置为W=130和s=1, PE算法参数设置为m=4和τ =1。 同时, 借助PE比值来分析序列间的差异性, PE值差异越大其比值波峰越明显。 根据四种大米光谱PE比值峰值大于1.5选取了3个窗口序列, 特征波长区间为4 967~5 179、 4 755~4 948和4 495~4 688 cm-1, 共300个特征波长点。
采用四种特征波长选取算法得到精米品种判别RMSE值如图3所示。 其中本文所提出的ASW-PE算法获取的判别误差最小, 相比其他算法RMSE值至少降低50%, 证明了ASW-PE算法在精米品种判别中的优越性。
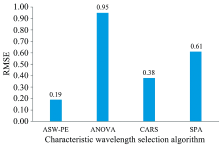 | 图3 四种特征波长选取算法得到的精米品种判别准确度Fig.3 Rice varieties classification accuracies based on four characteristic wavelength selection algorithms |
本节将本文提出的基于判别目标的精米品种判别策略与传统的基于固定模型的精米品种判别策略进行对比实验。 针对PLS模型, WC、 XS、 YS和YG分别赋值1、 2、 3和4。 针对PSO-SVM模型, PSO算法中学习因子c1=1.6、 c2=1.5, 惯性因子ω =1, 种群规模sizepop=30, 最大迭代次数为200, 粒子最大速度vmax=6。 不同精米判别策略所获取的判别准确度如表1所示。 其中, 在基于判别目标的精米品种判别策略中, PLS模型对应的最优光谱预处理算法为标准化预处理, PSO-SVM模型对应的最优光谱预处理算法为SNV预处理。
| 表1 不同精米判别策略所获取的判别准确度 Table 1 The discriminant accuracies obtained by different discriminant strategies for polished rice |
由表1可知, 当采用基于PLS的固定模型时, YG品种判别准确度只有25%, 是导致该模型准确度较低的主要原因。 当采用基于PSO-SVM的固定模型时, YG品种判别准确度的提高使得该模型准确度提高, 但是WC和XS品种判别准确度略低于基于PLS的固定模型, 也就是说模型准确度提高的同时针对指定品种判别准确度降低了。 综合分析结果可知, 采用本文提出的基于判别目标的精米品种判别策略, 相比于传统的基于固定模型的判别策略准确度至少可提高2.5%。 当判别目标为WC和XS时选取PLS模型和标准化预处理, 当被测目标为YG和YS时选取PSO-SVM模型和SNV预处理。
以东北地区五常、 响水、 越光、 银水四种大米为判别目标, 针对采用近红外光谱法的波长选取和判别策略进行优化研究。 研究结果表明, 针对特征波长选取优化, 采用自适应滑动排列熵算法, 相比于传统算法判别误差RMSE至少可降低50%; 采用基于判别目标的精米品种判别策略, 相比于传统判别策略判别准确度至少可提高2.5%。 此外, 由基于判别目标的精米品种判别研究可知, PLS判别模型与标准化光谱预处理组合最优, PSO-SVM判别模型与SNV光谱预处理组合最优, WC和XS判别与PLS模型组合最优, YG和YS判别与PSO-SVM模型组合最优。 本研究成果优化了基于近红外光谱法的精米品种判别, 为工程应用提供了有效参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|