{kind=link}
{kind=link}
近红外光谱技术对花生蛋白组分与亚基的高通量模型建立
[崔颢凡1  , 刘红芝
, 刘红芝1 , 郭芹1, * , 顾丰颖1 , 张雨2 , 王强1, * ]
, 刘红芝, 顾丰颖]
|
|


作者简介: 崔颢凡, 1999年生,中国农业科学院农产品加工所硕士研究生 e-mail: cuihaofan1999@163.com
花生是一种优质植物蛋白资源, 花生蛋白组分与亚基含量显著影响其功能特性, 决定了其在食品领域的应用范围, 花生蛋白主要包括花生球蛋白和伴花生球蛋白, 其中花生球蛋白包含4个亚基(40.5、 37.5、 35.5和23.5 kDa), 伴花生球蛋白Ⅰ包含3个亚基(15.5、 17和18 kDa), 伴花生球蛋白Ⅱ只含有1个61 kDa亚基。 为了实现花生蛋白主要组分及亚基的快速无损、 高通量、 高灵敏度检测, 以全国145份优质花生样品为研究对象, 首先采用便携式近红外花生品质速测仪, 在900~1 700 nm波长范围内对不同花生样品进行光谱采集, 再采用聚丙烯酰胺凝胶电泳法测定了花生蛋白组分与亚基含量, 花生球蛋白的亚基含量在44.3%~67.3%之间; 伴花生球蛋白亚基含量在35.2%~55.7%之间; 61 kDa亚基含量在13.5%~25.3%之间; 40.5 kDa亚基含量在6.8%~16.0%之间; 37.5 kDa亚基含量在6.9%~17.4%之间; 35.5 kDa亚基含量在5.7%~19.2%之间; 23.5 kDa亚基含量在18.7%~27.4%之间; 18 kDa亚基含量在5.9%~11.7%之间; 17 kDa亚基含量在6.9%~13.6%之间; 15.5 kDa亚基含量在4.5%~11.9%之间, 分别对比归一化(Normalize)、 一阶导数(FD)和二阶导数处理(SD)、 基线校准(Baseline)、 去趋势(Detrend)、 多元散射校正(MSC)和数据元素解析处理(Deresolve)这7种光谱预处理方法, 结合主成分分析(PCA)和偏最小二乘法(PLSR), 优化了2个蛋白组分和2个亚基(花生球蛋白、 伴花生球蛋白、 37.5和23.5 kDa)的近红外光谱模型, 构建了6个亚基(61、 40.5、 35.5、 18、 17和15.5 kDa)的近红外光谱模型, 实现了对上述10个指标的同步检测。 结果表明, 确定最优预处理方式后建立的模型校正集相关系数( Rcal)为0.90~0.96, 校正均方根误差(SEC)为0.25%~1.27%; 预测集相关系数( Rcp)为0.76~0.96, 预测均方根误差(SEP)为0.50%~1.81%, 具有很好的预测能力, 可用于花生品种蛋白组分与亚基含量的快速检测, 为花生蛋白品质的快速评价提供了新方法。
Peanut is a high-quality plant protein resource. The content of peanut protein components and subunits significantly affects its functional characteristics and determines its application range in the food field. Peanut proteins mainly include arachin and arachin. Among them, arachin contains four subunits (40.5, 37.5, 35.5, 23.5 kDa), arachin I contains three subunits (15.5, 17, 18 kDa), and arachin II contains only one 61 kDa subunit. To realize the rapid, non-destructive, high-throughput and high-sensitivity detection of peanut protein’s main components and subunits, 145 high-quality peanut samples in China were used as the research object. Firstly, the portable near-infrared peanut quality rapid tester was used to collect the spectra of different peanut samples in the wavelength range of 900~1 700 nm. Then, the peanut protein components and subunits were determined by polyacrylamide gel electrophoresis. The subunit content of arachin was between 44.3% and 67.3%. The content of arachin subunits was between 35.2% and 55.7%. The 61 kDa subunit content ranged from 13.5% to 25.3%. The content of 40.5 kDa subunit was between 6.8% and 16.0%. The content of 37.5 kDa subunit was between 6.9% and 17.4%. The content of 35.5 kDa subunit was between 5.7% and 19.2%. The 23.5 kDa subunit content was between 18.7% and 27.4%. The content of the 18 kDa subunit was between 5.9% and 11.7%. The content of the 17 kDa subunit was between 6.9% and 13.6%. The content of the 15.5 kDa subunit was 4.5%~11.9%. The near-infrared spectral models of two protein components and two subunits (arachin, arachin, 37.5, 23.5 kDa) were optimized by comparing seven spectral pretreatment methods, including normalization, first derivative (FD) and second derivative (SD), baseline calibration, detrend, multiple scattering corrections (MSC) and data element resolution (Deresolve), combined with principal component analysis (PCA) and partial least squares (PLSR). The near-infrared spectroscopy models of six subunits (61, 40.5, 35.5, 18, 17, 15.5 kDa) were constructed, and the simultaneous detection of the above 10 indicators was realized. The results showed that the calibration set’s correlation coefficient ( Rcal) 0.90~0.96, and the corrected root mean square error (SEC) was 0.25%~1.27%. The prediction set’s correlation coefficient ( Rcp) was 0.76~0.96, and the root mean square error of prediction (SEP) was 0.50%~1.81%. It has good predictive ability and can be used for rapid detection of protein components and subunit content in peanut varieties, which provides a new method for fast evaluation of peanut protein quality.
花生是一种优质植物蛋白资源, 种质资源达8957份[1], 其蛋白含量达24%~36%[2], 花生蛋白包括花生球蛋白、 伴花生球蛋白Ⅰ和伴花生球蛋白Ⅱ, 其中花生球蛋白包含4个亚基(40.5、 37.5、 35.5、 23.5 kDa), 伴花生球蛋白Ⅰ包含3个亚基(15.5、 17、 18 kDa), 伴花生球蛋白Ⅱ只含有1个61 kDa亚基[3]。 不同品种的花生蛋白组成与亚基含量差异较大, 决定了其不同的功能特性, 其含量越高, 功能特性受影响就越大。 研究表明: 花生球蛋白的溶解性优于伴花生球蛋白[4], 伴花生球蛋白的乳化活性优于花生球蛋白[5], 且伴花生球蛋白、 花生球蛋白、 40.5、 23.5、 15.5 kDa亚基对花生蛋白凝胶性影响较大[6]。 因此, 构建花生蛋白组分与亚基含量高通量、 高灵敏度检测方法为花生蛋白品质评价提供低成本、 快速检测方法意义重大。
目前, 花生蛋白组分与亚基的检测方法大都停留在聚丙烯酰胺凝胶电泳法(SDS-PAGE)上[7], 该方法存在前处理复杂(脱壳、 脱红衣、 粉碎、 脱脂、 提取蛋白)、 操作过程繁琐、 实验周期长, 检测成本高、 有机溶剂消耗量大等问题, 并且有机试剂还会危害人体健康, 造成环境污染。 随着检测方法向快速无损方向发展, 台式近红外设备被用于花生球蛋白、 伴花生球蛋白的检测[8]、 便携式近红外速测仪被用于花生球蛋白、 伴球蛋白、 37.5、 23.5 kDa亚基的检测[9], 但台式近红外设备检测速度较慢、 数据处理复杂、 用时长, 且现有台式和便携式近红外已建相关模型检测指标较少, 尚不能全面评价花生蛋白品质, 亟需建立一种低成本、 高通量、 高灵敏度的花生蛋白组分与亚基含量的快速无损检测方法。
王强团队前期自主研发了便携式花生品质速测仪, 花生样品的扫描后即可一步得到检测结果, 无需再进行复杂数据处理计算[10], 并建立了花生球蛋白、 伴花生球蛋白、 37.5和23.5 kDa 4个蛋白组分和亚基模型[9], 但这4个指标还存在校正集相关系数较低, 校正均方根误差较高的问题。 本研究在此基础上, 采用搜集的全国145份优质花生品种, 结合主成分分析(PCA)和偏最小二乘法(PLSR), 进一步优化了花生球蛋白、 伴花生球蛋白、 37.5和23.5 kDa亚基这4个近红外模型, 并同步构建61、 40.5、 35.5、 18、 17及15.5 kDa 6个亚基新模型, 完善了花生蛋白组分与亚基评价指标(2个蛋白组分和8个亚基含量)的快速无损、 高通量、 高灵敏度检测, 不仅可为花生蛋白品质评价提供新方法, 也可为育种专家快速挑选亚基含量高、 功能特性好的花生品种及企业收购特定功能特性的花生蛋白原料提供设备和技术方法。
花生样品来源于不同地区, 包括不同果型、 不同种皮颜色的全国的优质花生种质资源, 花生去壳后得到带皮的花生籽粒, 每个品种即为1份样品, 共145份花生样品, 将花生籽粒干燥除杂后放置种子瓶中, 置于4 ℃冰箱保存, 花生品种编号见表1。
| 表1 花生品种及编号 Table 1 Peanut varieties and number |
1.2.1 花生样品近红外光谱采集
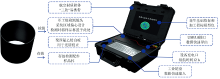
采用王强团队自主研发的基于Micro NIR 1700(VIAVI Solutions, 美国)的便携式花生品质速测仪, 近红外扫描光谱范围为900~1 700 nm, 漫反射光谱分辨率为7 nm, 波长准确性为2 nm, 该仪器内采用128像元非制冷铟镓砷探测器, 可在-20~+50 ℃温度范围内进行工作, 扫描一次仅需2.4 s。
参考赵思梦[9]等的方法, 得到花生样品的光谱信息。 便携式速测仪开机后, 预热30 min, 进行暗电流和白板矫正消除环境对检测结果的干扰。 检测前将花生样品从种子瓶中取出并常温放置至室温[(25± 1)℃] 24 h以上, 确保操作环境与样品环境一致。 检测时保证样品杯的清洁, 去除红衣破损的花生籽仁, 剔除杂物以及霉变粒等坏种粒, 取每种样品30~50 g, 将花生籽仁置于样品杯3/4处并混匀, 每种样品扫描5次, 每扫描一次旋转样品杯确保样品均匀扫描, 重复操作3次取平均值, 并且第二次和第三次扫描时要将花生样品重新装入样品杯中, 以得到同一种样品的多个近红外扫描光谱信息, 克服样品的不均匀性。
 | 图1 便携式花生品质速测仪及样品杯Fig.1 Portable peanut quality spectrometer and sample cup |
1.3.1 脱脂花生粉制备
将晾晒干燥后的花生样品剥壳, 取200 g花生仁用清水浸泡20 min, 手工脱红衣, 在烘箱中摊平烘干(水分质量分数约为7%)后采用万能粉碎机粉碎; 取粉碎后的花生蛋白粉样品添加正己烷脱脂, 所得的脱脂花生粉在通风橱摊平烘干后置于4 ℃冷藏备用[3]。
1.3.2 花生球蛋白和伴花生球蛋白制备
采用封小龙[11]等的方法, 将脱脂花生粉用磷酸缓冲溶液溶解后离心, 去除沉淀后冷沉离心, 沉淀干燥后得花生球蛋白, 上清干燥得伴花生球蛋白。
1.3.3 SDS-PAGE电泳和亚基含量分析
称取样品加入样品缓冲溶液, 振荡后煮沸, 然后离心取上清液进行电泳, 电泳结束后将凝胶用考马斯亮蓝蛋白胶极速染色液进行染色, 置于摇床上过夜, 染色后无需脱色。 61、 40.5、 37.5、 35.5、 23.5、 18、 17和15.5 kDa亚基相对含量采用Image J 软件进行光密度分析[12], 各个亚基的含量为其光密度占该条带总光密度的百分比。
利用The Unscrambler X 10.4软件(CAMO公司, 挪威)建立模型。 采集到的花生样品光谱为X值, 各花生样品化学值指标为Y值, 采用偏最小二乘法(PLSR)对数据进行拟合, 建立数学模型。 PLSR是一种多因变量Y对自变量X的回归建模方法, 该算法在建立回归的过程中, 既考虑了尽量提取X、 Y中的主成分, 又考虑了使分别从X和Y提取出的主成分之间相关性最大化, 集主成分分析、 典型相关性分析、 多元线性回归分析三种分析方法的优点于一身, 能够实现模型构建的准确性[13]。
1.4.1 光谱预处理
在建立模型时, 需要尽可能地消除样本集对近红外光谱的影响, 减少自然光等干扰因素, 使模型更稳定, 数据更精确, 因为样品分布不均或者外界环境等原因可能会造成样本集光谱曲线产生重复、 基线漂移、 分散等现象, 故采用归一化(Normalize)、 一阶导数(first derivative, FD)和二阶导数处理(second derivative, SD)、 基线校准(Baseline)、 去趋势(Detrend)、 多元散射校正(multiplicative scatter correction, MSC)和数据元素解析处理(Deresolve)这7种预处理方法对原始光谱数据进行预处理消除误差[14]。 对比分析校正集相关系数(correlation coefficient in calibration, Rcal)、 校正均方根误差(standard error in calibration, SEC)、 和内部验证集相关系数(correlation coefficient in validation, Rcv)、 内部验证均方根误差(standard error in validation, SECV)来评价模型的预测性能。 Rcal和Rcv分别表示校正模型和内部验证模型的拟合程度, 越接近1, 模型拟合效果越好, SEC和SECV分别表示校正模型与验证模型中参考值与预测值之间的均方根误差, 数值越小, 模型预测性能越高。
1.4.2 模型的建立与验证
利用The Unscrambler X 10.4软件, 选择最佳的光谱预处理方法与最佳主成分数, 用偏最小二乘法(PLSR)进行模型的建立, 建模时为使数据拟合反复进行内部交叉验证剔除异常值, 通过比较模型的Rcal、 SEC、 Rcv、 SECV确定最优模型, 并采用外部验证模型评价模型的预测准确性与稳健性, 外部验证集不参与模型的构建, 扫描外部验证集的花生样品光谱并代入到已构建的近红外光谱模型, 并用化学方法测定各蛋白组分与亚基组成的含量, 用外部预测集相关系数(correlation coefficient in prediction, Rcp)和预测均方根误差(standard error in prediction, SEP)来筛选最佳模型。
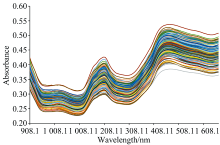
145份花生样品用便携式花生品质速测仪采集的近红外原始光谱如图2所示, 吸收趋势与各波段吸收峰相同, 可用于近红外光谱定量模型的构建。
 | 图2 花生种子的原始近红外光谱图Fig.2 Original near infrared spectra of peanut seeds |
现有花生蛋白组分与亚基含量的相关研究表明花生球蛋白平均含量为56.00%, 伴花生球蛋白平均含量为43.98%, 亚基含量中最高的为23.5 kDa亚基, 平均含量为21.97%, 其次是61 kDa亚基, 平均含量为18.82%, 其余亚基平均含量在6.90%~13.99%左右[15], 本研究选取的145个花生样品来自全国各地花生品种符合蛋白组分与亚基含量所在范围, 能够代表大部分的花生品种。 部分花生品种如仲恺花4号、 粤油52号、 双红2号、 青兰8号等缺少35.5 kDa亚基, 所以在模型建立及分析35.5 kDa亚基含量时已剔除缺失35.5 kDa亚基的花生品种。 数据表明, 花生样品花生蛋白与亚基的变异系数范围为7.27%~19.16%, 变异系数较大, 分布范围较广, 具有较好的代表性, 能够利用近红外光谱方法进行化学值的预测, 满足建模的条件。
| 表2 花生样品蛋白组分与亚基组成含量 Table 2 Protein composition and subunit composition of peanut samples |
2.3.1 光谱预处理方法的确定
采用PCA剔除光谱中的异常值, 通过对比模型的相关系数和误差, 分别得到花生球蛋白、 伴花生球蛋白以及61、 40.5、 37.5、 35.5、 23.5、 18、 17和15.5 kDa亚基模型对应的最佳预处理方法, 见表3。
| 表3 不同光谱预处理对花生蛋白亚基模型的影响 Table 3 The best spectral pretreatment method for each model |
2.3.2 花生蛋白组分与亚基模型的构建与验证
剔除异常值后剩余花生样品140份, 按3∶1的比例划分为校正集和外部预测集, 随机选取用于建模的样品105个, 用于外部验证的样品35个, 对花生品种的各蛋白亚基含量的化学值与近红外光谱值进行拟合, 构建的最优模型参数如表4所示。 PLSR模型构建的过程中, 主成分数是评估模型性能的关键参数, 最佳主成分数由交叉验证的结果决定; 使用过少的主成分会降低模型的预测能力, 而使用过多的主成分数会导致模型过度拟合。 因此, 本研究中所采用的主成分数与之前类似研究保持一致[16, 17]。
| 表4 模型的构建与验证 Table 4 Construction and validation of model |
关于花生蛋白组分此前团队前期建立的台式机花生球蛋白与伴花生球蛋白Rcal分别为0.64和0.61, 便携式花生品质速测仪的花生球蛋白与伴花生球蛋白Rcal分别为0.92和0.85, 本研究中建立的花生球蛋白模型的Rcal比台式机花生球蛋白模型提升了44%, 伴花生球蛋白模型Rcal比台式机伴花生球蛋白模型提升了54%, 比前期建立的便携式花生品质速测仪模型提升了11%, 关于花生蛋白亚基组成, 23.5和37.5 kDa模型Rcal均为0.91, 本研究中建立的23.5和37.5 kDa亚基模型Rcal分别为0.93和0.96, 分别提升了2%和5%。 本研究中构建的便携式花生品质速测仪模型性能略优于前人构建的模型, 可能由于选择建模的花生样品品种、 数量、 产地、 收获年份不同, 导致建模样本和之前相比具有较大的差异, 而模型性能显著优于台式机模型可能是由于近红外光谱仪的不同导致了花生样本的光谱信息不同, 同时, 对光谱信息进行了不同的预处理也是造成模型差异较大的原因。 在新建立的模型中, 18和15.5 kDa亚基相关系数较低可能是由于18和15.5 kDa亚基在花生蛋白中含量较低造成的, 关于61、 40.5、 35.5、 18、 17和15.5 kDa亚基近红外模型未见相关报道。
对花生蛋白亚基组成近红外模型进行外部验证, 结果见表4。 用Rcp和SEP来筛选最佳模型, 相关系数高同时误差低的模型准确度高, 稳定性好, 建立的模型Rcp范围为0.76~0.96, SEP为0.50%~1.81%。 本研究中建立的花生球蛋白模型的Rcp比台式机花生球蛋白模型提升了44%, 比前期建立的便携式花生品质速测仪模型提升了9%, 伴花生球蛋白模型的Rcp比台式机伴花生球蛋白模型提升了40%, 关于花生蛋白亚基组成, 本研究中建立37.5 kDa亚基模型SEP比前期建立的便携式花生品质速测仪模型降低了32%。
采用团队自主研发的便携式花生品质速测仪优化了花生球蛋白、 伴花生球蛋白、 23.5和37.5 kDa 4个模型, 同步构建了6个新亚基(61、 40.5、 35.5、 18、 17和15.5 kDa)模型, 其校正集相关系数可达0.90~0.96, 外部验证集相关系数可达0.76~0.96, 模型SEP范围为0.50%~1.81%, 具有较好的检测稳定性, 可满足花生蛋白组分与亚基检测要求, 并为其检测提供了一种低成本、 快速无损、 高通量、 高灵敏度的新检测方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|