






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
LAMOST的“Unknown”光谱分类研究: ODS-YOLOv7模型
[王晓敏1  , 高军萍
, 高军萍1, * , 蒲源2, * , 邱波1, * , 张健楠3 , 闫静1 , 李荣1 ]
, 高军萍, 蒲源, 邱波, 张健楠|
|


作者简介: 王晓敏,女, 1999年生,河北工业大学硕士研究生 e-mail: 2655579859@qq.com
天体识别是天文新发现和深入研究天体的基础。 在LAMOST DR8 v1.0发布的低分辨率光谱数据中有约53万条因没有类别标签而被命名为“Unknown”的光谱, 其中有88.56%的光谱信噪比在0~10之间, 对这批光谱的研究分析将增加LAMOST的有效数据产出。 该研究为“Unknown”光谱的分类设计了一种ODS-YOLOv7模型。 它是一种端到端的类别预测模型, 通过添加一维卷积注意力模块以提高光谱识别能力。 在经过一批信噪比在0~10之间的已知类别光谱训练后, ODS-YOLOv7可以学习到低信噪比光谱的有效特征, 进而实现对“Unknown”光谱的类别预测。 实验表明, 该模型在已知类别标记的低信噪比恒星、 星系、 类星体的光谱识别中, F1-score分别为0.98、 0.95、 0.95; 同时在与传统算法KNN、 RF、 DT、 SVM和深度学习算法1D CNN、 1DSSCNN、 ResNet、 DenseNet、 VIT对比实验中取得相对最好的效果。 实验结果还给出了ODS-YOLOv7模型对DR8 v1.0中信噪比在0~10的“Unknown”光谱预测置信度分布, 在预测类别为恒星、 星系、 类星体任务中, 有92%的分类置信度在60%以上。 为保证模型输出质量, 本文只选取分类置信度大于99%的光谱类别作为输出结果。 以此为依据, 在DR8 v1.0和DR9 v0发布的全部“Unknown”光谱中分别有37.19%和47.03%被ODS-YOLOv7模型预测出类别。 此外, 还增加人工认证以检验该模型预测的正确性。 为提升模型的可解释性, 参照了二维图像特征可视化的Grad-CAM方法, 将其改进为适合于可视化一维光谱数据特征的算法。 其结果表明该模型可自动关注到不同的分类特征, 使得该模型非常适用于低信噪比“Unknown”光谱的类别预测。
Identifying celestial spectra is essential for making new astronomical discoveries and conducting detailed studies of celestial objects. The LAMOST DR8 v1.0 release of low-resolution spectral data contains approximately 530 000 spectra named “Unknown”. The reason is that they have no category labels. And 88.56% of these spectra have signal-to-noise ratios between 0 and 10. Therefore, the effective output of LAMOST will increase if we analyze these spectra. In this paper, we propose an ODS-YOLOv7 model to deal with the problem of the “Unknown”spectral classification. It is an end-to-end category prediction model and is suitable for one-dimensional spectra. We also add a one-dimensional convolutional attention module to improve the accuracy of spectra recognition. After training on a set of known category spectra with signal-to-noise ratios between 0 and 10, the ODS-YOLOv7 model can learn the effective features of the low signal-to-noise spectra. Thus, it can enable us to predict “Unknown”spectra. Experiments show that the model has an F1-score of 0.98, 0.95, and 0.95 for the spectral identification of low signal-to-noise stars, galaxies, and quasars spectra with known labels. In the meantime, ODS-YOLOv7 obtains the best results in comparison experiments with traditional algorithms KNN, RF, DT, SVM, and deep learning algorithms 1D CNN, 1DSSCNN, ResNet, DenseNet, and VIT. The experimental results also give confidence in the predictions of the ODS-YOLOv7 model for the “Unknown”spectra in DR8 v1.0, with 92% of the confidence levels above 60%. To ensure the quality of the model output, only spectral categories with a prediction confidence level greater than 99% are selected as output in this paper. Ultimately, 37.19% and 47.03% of the “Unknown”spectra released in DR8 v1.0 and DR9 v0, respectively, are predicted by this model.In addition, the paper tests the accuracy of the model’s predictions using manual authentication. To improve the interpretability of the model,the paper takes the Grad-CAM method for two-dimensional image visualisation. It improves it into an algorithm suitable for visualising one-dimensional spectral data to predict output features. Experiments show that the model focuses on different features in the visualisation of different classes of astronomical features and that the model is good at predicting low signal-to-noise “unknown”spectral classes.
光谱经常被用于天体识别、 星体演化、 恒星大气参数估计等天文研究中[1]。 各种天文望远镜获得的海量光谱数据为机器学习提供了充足的样本[2]。 在此基础上, Weaver等[3]使用ANNs算法对A型恒星近红外光谱进行分类, Kaushal Sharma等[4]采用CNNs方法将恒星光谱分为O、 B、 A、 F、 G、 K、 M七个类型。 Wen等[5]比较了KNN、 DT、 RF和SVM四种算法对LAMOST DR5(Large Sky Area Multi-Object Fiber Spectroscopic Telescope Data Release 5)发布的光谱数据的分类效果。 何东远等[6]设计了1DSSCNN算法, 在F、 G、 K类型的分类任务中精度分别为90%、 93%、 97%。 王奇勋等[7]建立了DenseNet模型, 在恒星、 星系、 类星体的分类任务中F1分数分别达到0.998 7、 0.912 7和0.914 7。 这些研究大多选择已知类别的高信噪比光谱作为样本。
在实际发布的LAMOST DR8 v1.0数据中“Unknown”类型光谱有534 091条, 这个数量远高于DR8 v1.0发布的星系和类星体光谱数量的总和, 说明了使用传统的模版匹配方法对这些光谱进行正确分类难度较大[8]。 为此有大量研究者先后挑战“Unknown”类型的光谱识别。 如郑子鹏等[9]提出一种1D CNN结合GAN网络的半监督学习方式在“Unknown”类型中人工认证出200个O型星。 Guo等[10]使用ML-PIL二元非线性哈希算法从LAMOST DR5 v1的“Unknown”类型光谱数据中检测M型恒星。 上述两种方法仅对“Unknown”类型光谱中的恒星子类型进行识别, 未关注到星系和类星体的识别。 杨雨晴等[11]提取LAMOST DR5中的“Unknown”光谱的影响空间及数据场特征, 通过K-Means算法进行聚类, 得到5种聚类类型, 可以用于分析低信噪比光谱的形成原因, 为观测计划制定提供参考。
为了更好地实现“Unknown”光谱的类别预测, 本文设计了一种ODS-YOLOv7(One Dimensional Spectra-YOLOv7)模型。 该模型通过已知类别标记的低信噪比光谱进行训练, 然后用于DR8 v1.0 的“Unknown”光谱的类别预测。
实验数据采用LAMOST DR8 v1.0发布的低分辨率光谱数据。 不同类型的光谱数据量分布见表1, 其中星系和类星体的数据量远远低于“Unknown”的光谱数据量。 因此, 本文尝试对其中的“Unknown”光谱数据进行类别预测。 “Unknown”光谱不同信噪比下的数量分布如表2所示, 可知它们绝大多数分布在低信噪比0~10区间(88.56%)。 因此, 实验使用LAMOST DR8 v1.0发布的低分辨率光谱中信噪比在0~10之间的已知类别光谱去训练模型, 然后对DR8 v1.0所有的“Unknown”光谱进行分类。 此后, 为了检验模型的泛化性能, 对DR9 v0发布的27 686条“Unknown”光谱也进行了分类。
| 表1 DR8 v1.0低分辨率光谱数据量分布 Table 1 Distribution of DR8 v1.0 low-resolution spectral data volumes |
| 表2 “Unknown”光谱数据量分布 Table 2 Distribution of “Unknown”spectral data volumes |
为保证输入数据的统一性, 对每条光谱369~867 nm波长范围内的流量值进行重采样。 LAMOST发布的一维光谱包含噪声、 连续谱和谱线。 谱线由发射线和吸收线组成, 一维光谱数据主要根据谱线特征进行天体识别。 因此, 本文的数据预处理包括去噪、 去连续谱、 提取谱线特征这三个步骤。 此外, 由于观测仪器灵敏度、 观测天体与地球的距离和天体本身亮度情况的差异, 光谱不同波段的流量值差异较大[12]。 因此, 为了让模型更加关注谱线特征而不是谱线强度变化, 并加快模型收敛速度, 本文对光谱数据进行了最值归一化, 将光谱的所有流量值映射到0~1范围内, 如式(1)所示
式(1)中, f是LAMOST发布的原始一维光谱的流量值, fmin是一维光谱中的最小流量值, fmax是最大流量值, fscale是对光谱归一化之后的流量值。
为获得“Unknown”光谱的有效特征, 实现高准确率类别预测, 本文提出一种端到端的类别预测模型ODS-YOLOv7(图1), 该模型参考了YOLOv7模型的设计方法, 采用已知类别的低信噪比光谱作为训练数据去获得模型的最佳特征提取权重。 它包括输入降维、 特征融合、 分支缩减、 输出类别4部分, 使用了9个子模块(a—i)。 该模型不同部分包含的子模块类型和数量是不同的。
 | 图1 ODS-YOLOv7模型Fig.1 The model of ODS-YOLOv7 |
输入降维部分由两个卷积核为1×3、 1×5的(a)CBR(Convolution_BatchNormalization_Relu)模块、 两个1×2池化窗口的(c)CBMR(Convolution_BatchNormalization_Maxpool_Relu)模块、 四个卷积核均为1×3, 步长分别是1、 2、 1、 2的(b)CBS(Convolution_BatchNormalization_Silu)模块组成。 1×3 700(单通道3 700维)输入数据经过输入降维部分后得到256×925和128×925的特征作为下一部分的输入。 相比于主成分分析降维得到的固定特征数据, 卷积降维可以根据模型的学习效果动态调整特征。 该部分的子模块介绍如下: (a)CBR包括卷积层、 批归一化层、 Relu激活函数; (b)CBS模块采用Silu激活函数, 其他组成同(a)模块; (c)CBMR模块在(a)模块的批归一化层和Relu激活函数之间添加一个最大池化层。
特征融合部分由最近邻插值上采样upsampling、 (b)CBS模块、 (d)ODSC(One Dimensional Spectral Feature Concatenation)模块、 (e)ODSFC(One Dimensional Spectral Feature Fully Concatenation)模块、 (i)SPPT(Spatial Pyramid Pooling Add Two Concatenation)模块组成。 输入降维部分处理得到的两种不同特征数据进行特征融合后得到256×925、 512×462和256×462三种不同的特征。 特征融合部分的子模块介绍如下: (b)CBS模块同输入降维部分; (d)ODSC模块可以让模型学习到更多的特征, 该模块有两个分支, 上分支由5个串行的卷积核为1×1、 1×1、 1×3、 1×3、 1×3的CBS模块构成, 用于提取不同感受野的特征。 下分支由卷积核为1×3的CBS提取特征, 两分支的输出特征拼接之后经过一维卷积注意力模块和卷积核为1×1的CBS模块得到输出特征; (e)ODSFC作用同ODSC模块, 该模块同样也是两个分支, 在上分支中, 输入数据依次经过卷积核为1×1、 1×3、 1×3、 1×3、 1×1的CBS提取特征, 在下分支中输入数据经过卷积核为1×1的CBS模块变换通道数。 上分支的所有输出特征与下分支特征进行拼接实现特征融合效果, 与ODSC不同的是ODSFC模块对两分支中所有CBS模块的输出特征都进行了特征拼接, 特征提取能力更强; (i)SPPT模块用于获得不同尺度的感受野, 在上分支, 输入数据经过三个串行的卷积核均为1×1、 1×3、 1×1的CBS后经过3个并行的最大池化层获得不同感受野的特征, 池化窗口为1×5、 1×9、 1×13。 在下分支, 输入数据经过卷积核为1×1的CBS改变通道数。 两个分支的特征进行特征融合后再通过卷积注意力机制, 最后经过CBS模块得到SPPT处理完成的特征。
分支缩减部分包括(b)CBS模块、 (g)CBA(Convolution_BatchNormalization_Add)模块、 (h)Repconv、 最近邻插值上采样模块。 特征融合得到的三个输出特征经过分支缩减部分得到一个768×924的特征。 分支缩减部分中的模块介绍如下: (g)CBA模块上下分支均由卷积层和批归一化层组成, 上分支和下分支中卷积层的卷积核大小分别选择1×3和1×1; (h)Repconv用于将多分支权重转换为单分支权重, 其是在(g)CBA的基础上增加了一个批归一化层。
模型最后的类别输出部分由展平层、 全连接层、 Softmax处理组成。 分支缩减后的特征经过输出类别部分得到网络对于输入数据在每一个类别上的预测得分。 在ODS-YOLOv7模型中多次使用残差连接加深网络的深度来缓解深层网络梯度消失问题, 使得网络可以学习到输入数据更深层的特征表示。 CBAM(Convolutional Block Attention Module)是一种关注特征空间和通道信息注意力模块[15], 通常用于提高二维数据处理模型性能。 本文将CBAM模型改进为适合于一维光谱数据的卷积注意力模型CBAM, 更好地关注一维光谱的有效分类特征。
ODS-YOLOv7模型采用Relu和Silu两种激活函数来缓解梯度消失问题, 以增加网络深度。 Relu函数来将一部分神经元的输出置为0, 减少参数之间的相互影响, 缓解过拟合问题。 Silu激活函数不是单调递增函数, 函数值变换平缓, 用来减少模型需要学习的权重数量。 Relu激活函数如式(2)所示, Silu激活函数如式(3)所示。
本实验采用Intel Core I5处理器, Pytorch 1.7.0学习框架, Python 3.7.13编译器。 ODS-YOLOv7使用Adam(Adaptive Moment Estimation)优化器, 学习率设为0.000 1。 实验中训练ODS-YOLOv7模型的数据选取已知类别标记的信噪比在0~10之间的60 000条光谱, 其中恒星、 星系、 类星体各20 000条。 这样既可以充分学习光谱特征, 也完成了数据平衡。 为衡量模型对不同类别光谱的识别能力, 本文基于相同的实验数据把ODS-YOLOv7与传统算法KNN(K-Nearest Neighbor)、 SVM(Support Vector Machines)、 DT(Decision Tree)、 RF(Random Forest)[5]和深度学习算法1D CNN[9]、 1DSSCNN[6]、 DenseNet[7]、 ResNet[13]、 VIT[14]进行了比较。 在比较之后保留ODS-YOLOv7模型的最佳权重用于“Unknown”光谱类别预测。 预测时ODS-YOLOv7输入的数据是DR8 v1.0和DR9 v0中全部的“Unknown”光谱, 模型输出“Unknown”的预测类别及预测概率。
实验中使用精确率、 召回率、 F1-score、 准确率、 ROC(Receiver Operating Characteristic)曲线、 AUC(Area Under Curve)多项评价指标和混淆矩阵在低信噪比光谱数据上比较不同模型的性能。 采用改进的Grad-CAM算法[16]观察ODS-YOLOv7模型提取到的低信噪比光谱特征, 增加模型的可解释性。 实验中使用的精确率(precision)、 准确率(accuracy)、 召回率(recall)以及F1-score评估指标计算如式(4)—式(7)所示。
recall=TP/(TP+FN)(6)
其中, TP是将正例预测为正例的样本数, FN是将正例预测为反例的样本数, FP是将反例预测为正例的样本数。 T表示类别预测正确的个数, F是类别预测错误的样本数。
由于“Unknown”没有真实标签, 无法直接衡量模型的预测性能。 本文实验采用模型对低信噪比光谱识别的评价指标间接作为ODS-YOLOv7预测模型性能的评价。 不同模型对一维低信噪比光谱识别的性能表现如表3所示。 通过不同算法的评价指标对比发现本文提出的ODS-YOLOv7模型在低信噪比恒星、 星系、 类星体的识别实验中取得最好的效果。 本文模型对低信噪比恒星、 星系、 类星体的识别准确率是0.96, 高于其他模型, 说明该模型相比于其他模型能够更好地提取低信噪比光谱特征, 最适合于“Unknown”光谱类别预测。
| 表3 不同模型对低信噪比光谱的识别性能 Table 3 The recognition performance of different models for low signal-to-noise ratio spectra |
ODS-YOLOv7模型在与传统机器学习方法对低信噪比光谱识别的对比实验中, 各项评价指标均优于后者。 ODS-YOLOv7的光谱识别准确率达到了0.96, 而KNN和SVM模型却不足0.50。 DT模型的识别准确率达到了0.61, 识别效果远不能满足光谱自动识别的要求。 RF模型识别准确率达到0.80, 是传统学习模型中效果最好的, 比浅层的1D CNN深度学习模型的识别效果好, 但是远低于本文提出的模型准确率。
ODS-YOLOv7模型在与其他主流深度学习模型的对比实验中, 各项评价指标也均优于后者。 在恒星识别中, ODS-YOLOv7模型的精确率是0.98, 高于其他模型; 召回率和F1-score都是0.97, 与DenseNet模型持平, 优于其他模型。 在星系识别中, ODS-YOLOv7模型的精确率, 召回率和F1-score均是0.95, 均高于其他模型。 在类星体识别中, ODS-YOLOv7模型的精确率和F1-score都是0.95, 与DenseNet模型相同, 且高于其他模型; 召回率是0.95, 优于其他模型。
传统算法识别效果普遍偏低可能是本文实验中使用的训练光谱数据不仅数量多而且噪声含量高导致的。 1D CNN和1DSSCNN模型可能是由于网络层数较浅, 提取特征能力受限导致在深度学习模型对比中识别效果较差。 ResNet和DenseNet模型的网络层数较深且添加了残差机制缓解梯度消失问题, 可以提取到光谱深层次的特征, 识别效果较好。 VIT模型的识别效果略低可能是由于在输入光谱数据时, 需要对数据进行切片, 在切片数据中噪声含量较多, 影响了光谱的识别效果。 ODS-YOLOv7对信噪比在0~10之间恒星、 星系、 类星体的光谱识别精确率、 召回率、 F1-score、 准确率指标中占绝对优势, 综合识别效果优于其他模型, 可以很好地对低信噪比光谱进行识别。
由表3中的各个模型评价指标值可知, 传统机器学习算法效果较差, 因此, 本文在混淆矩阵分析中未对传统机器学习算法的混淆矩阵进行分析。 实验中使用的低信噪比光谱在六种深度学习模型中的混淆矩阵如图2所示, 横坐标表示光谱数据的预测类别标签, 纵坐标表示光谱数据的真实标签, 对角线位置的数值为识别正确的光谱数量。 在六种深度学习模型的混淆矩阵中, 本文提出的ODS-YOLOv7模型对三种天体的识别均达到最好的效果, ODS-YOLOv7混淆矩阵对角线位置的值均大于其他模型对角线上的值; 1D CNN模型对恒星、 星系、 类星体的识别效果均为最差, 对角线位置的值均小于其他模型相应位置的值, 错误识别数量最多; VIT将星系错误识别为类星体光谱的数量最多, 有521条星系光谱被错误识别成类星体; 1DSSCNN各个类别识别错误的光谱数量均高于本文提出的模型; DenseNet比ResNet模型对三种低信噪比天体的识别正确数较多, 但是低于本文提出的ODS-YOLOv7模型识别效果。
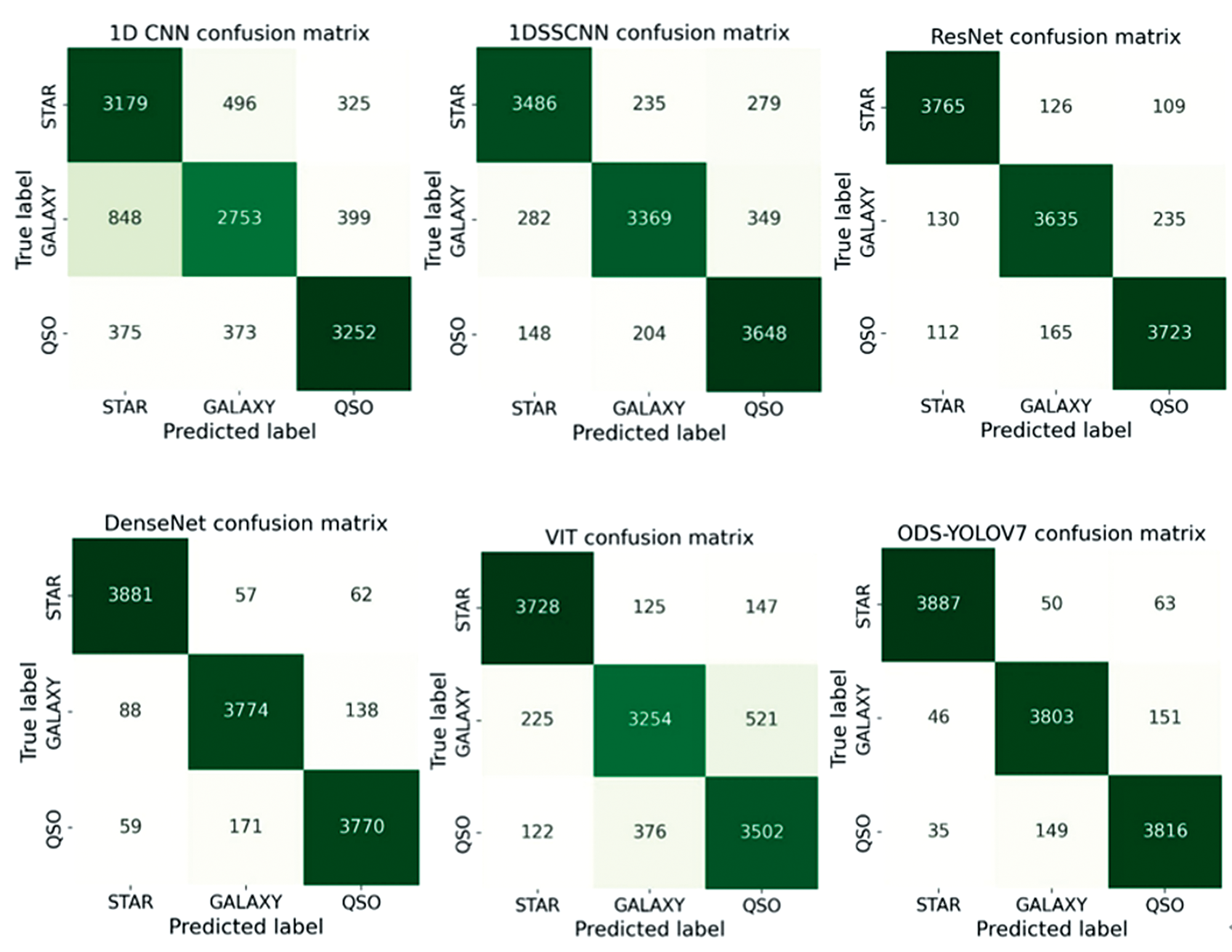 | 图2 测试样本分类结果混淆矩阵Fig.2 The confusion matrix of test sample classification results |
实验还通过ROC曲线和AUC值来比较不同算法的性能。 在如图3的ROC曲线里, 本文提出的ODS-YOLOv7模型的ROC曲线最接近左上角, 表明其性能优于其他模型。 1D CNN、 1DSSCNN、 ResNet、 DenseNet、 VIT、 ODS-YOLOv7模型的AUC值如图4所示, AUC值依次是0.82、 0.91、 0.94、 0.96、 0.90、 0.97。 通过AUC折线图可知ODS-YOLOv7模型的AUC值大于其他模型, 识别效果最优。
 | 图3 六种模型的ROC曲线Fig.3 The ROC curve of six algorithms |
 | 图4 六种模型的AUC值Fig.4 The AUC value of six algorithms |
为在视觉上观察和解释ODS-YOLOv7网络学习到的一维低信噪比光谱特征, 对Grad-CAM算法[16]进行改进以获得相关热力图。 此热力图的大小与输入的原始一维光谱数据一致, 颜色越深对结果影响越大。
实验中选择将ODS-YOLOv7模型最后一层卷积层的输出特征进行可视化。 本文模型最后一层卷积层输出特征是128×58(128通道58维)的数据, 在类别预测时不同通道的特征对于输出结果的贡献权重是不一样的, 这就需要获得不同通道对于预测结果的权重值。 为获得特征权重, 首先求取到最后一层卷积层输出特征图的梯度; 然后对每个特征图的梯度图进行全局平均池化获得每个通道的特征对结果贡献的权重; 对128通道的特征进行加权求和得到单通道的58维特征, 采用三阶B样条函数将加权求和后的特征插值到原输入数据大小得到热力图。 将热力图与原光谱数据绘制在一起得到恒星、 星系、 类星体的特征可视化分别如图5、 图6和图7所示。
 | 图5 恒星关注区域热力图Fig.5 Heatmap of the interesting region of star |
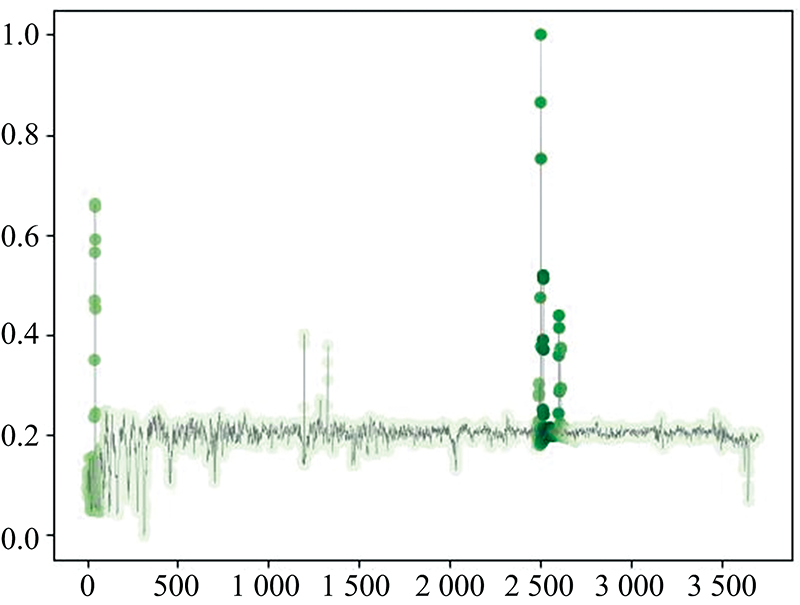 | 图6 星系关注区域热力图Fig.6 Heatmap of the interesting region of galaxy |
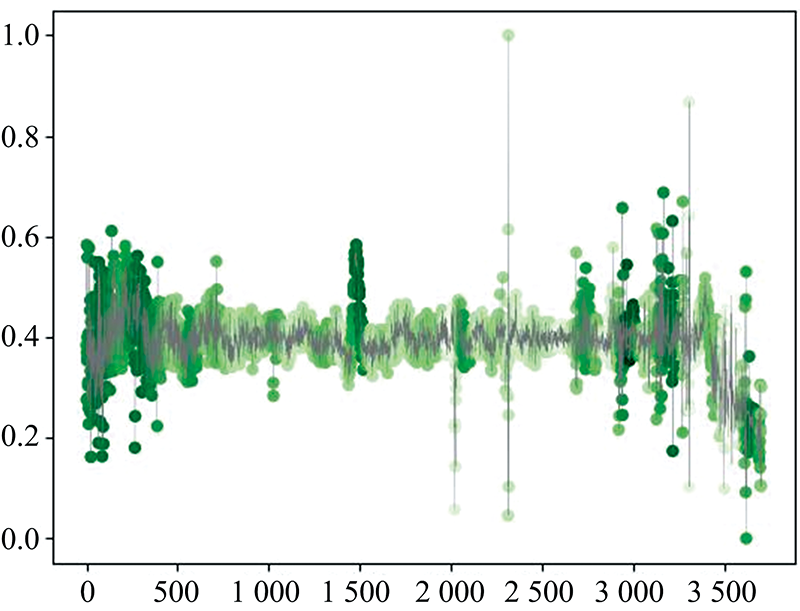 | 图7 类星体关注区域热力图Fig.7 Heatmap of the interesting region of quasar |
在图5的恒星光谱中, 吸收线的颜色深度要比发射线的颜色深, 尤其是光谱前端的吸收线最为明显, 说明模型此时更加关注吸收线。 在图6中的星系光谱中, 发射线处颜色普遍较深, 尤其是光谱后端的发射线较明显, 说明模型此时更加关注发射线。 在图7中的类星体光谱中, 颜色较深的部分通常是较宽的区域而不是单一的谱线, 说明模型此时更加关注区域特征。
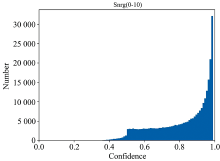
实验中为验证预测结果的有效性, 分别统计了所有信噪比在0~10之间的DR8 v1.0和DR9 v0中“Unknown”类型光谱的预测类别置信度分布, 结果如图8和图9所示: 横坐标是置信度分数, 纵坐标是置信度得分对应的光谱数量。 从两种发布数据的置信度直方图可以分析出“Unknown”类型光谱中的大多数光谱使用ODS-YOLOv7模型都可以被预测出类别, 且可信度较高。 在DR8v1.0中有472 971条信噪比在0~10之间的“Unknown”光谱, 其中类别预测置信度大于60%有435 899条, 占类别预测总数的92%。 在DR9 v0中25 398条预测结果中类别预测置信度大于60%的有23 592条。
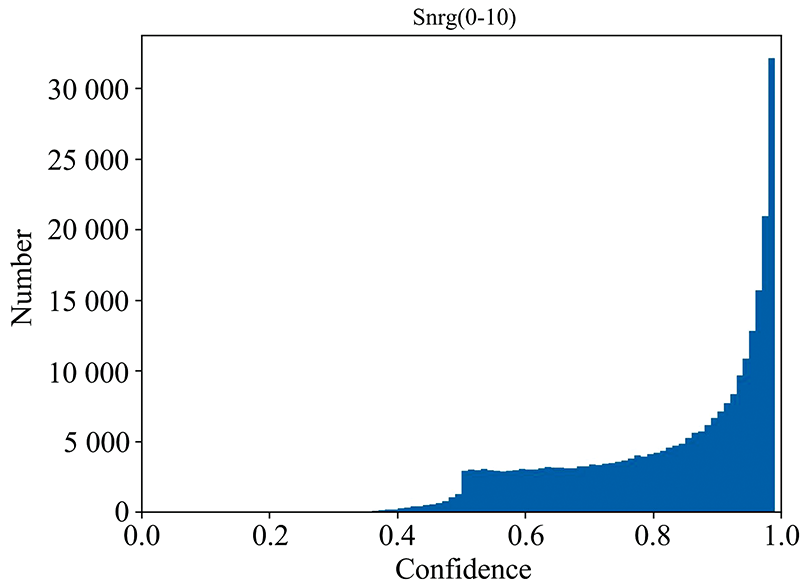 | 图8 DR8 v1.0 中的光谱预测置信度Fig.8 Spectral prediction confidence in DR8 v1.0 |
 | 图9 DR9 v0中的光谱预测置信度Fig.9 Spectral prediction confidence in DR9 v0 |
此外, 本实验对DR8 v1.0和DR9 v0发布的全部“Unknown”类型光谱数据进行类别预测, DR8 v1.0和DR9 v0中分别有198 631和13 022条“Unknown”类型光谱被预测出具体的星体类别且预测概率大于99%, 各类别数量如表4所示。
| 表4 “Unknown”类型光谱预测结果 Table 4 “Unknown”spectral prediction results |
本文在低信噪比光谱高准确率识别的基础上尝试将“Unknown”中的光谱类别预测为恒星、 星系、 类星体三大类。 在LAMOST发布的光谱数据中恒星数量最多, 星系和类星体数量较少。 为增加LAMOST发布数据中的星系和类星体数量, 减少人工认证时间和认证成本, 本文仅随机选取部分预测类别为星系和类星体的光谱进行人工认证。 虽然“Unknown”光谱中噪声含量多, 但是经过严格的人工认证, 在DR8 v1.0预测出类别的“Unknown”光谱中随机选取2 000条低信噪比星系、 类星体光谱, 两类光谱各1 000条的认证中, 确认了469条星系光谱, 120条类星体光谱。 在DR9 v0中随机选取相同数量的数据, 确认了星系光谱93条, 类星体光谱20条。
提出一种新的模型ODS-YOLOv7对LAMOST发布的“Unknown”光谱进行类别预测。 ODS-YOLOv7模型对低信噪比光谱识别的准确率达到0.96, 其识别准确率优于主流网络模型对低信噪比光谱的识别效果, 可以很好地学习到低信噪比光谱特征, 用于“Unknown”光谱的类别预测。 在ODS-YOLOv7模型将DR8 v1.0中“Unknown”类型光谱预测为恒星、 星系、 类星体的实验中, 预测出类别概率大于99%的恒星光谱55 010条、 星系光谱74 517条、 类星体光谱69 104条。 通过人工认证增加ODS-YOLOv7模型对“Unknown”类别预测的可信度, ODS-YOLOv7网络可以对“Unknown”类型进一步识别。 本文还对ODS-YOLOv7模型学习到的最后一层卷积层输出特征进行可视化, 可以直观地观察和分析模型在天体光谱识别过程中关注的区域。 本文提出的方法为低信噪比“Unknown”类型光谱信息的利用提供了一种新的思路, 增加LAMOST的有效产出。 未来计划在“Unknown”光谱预测为恒星、 星系、 类星体的基础上探究恒星子类型的预测和发现更多稀有天体, 增加LAMOST的有效数据产出。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|