


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱成像技术结合集成学习的金钗石斛氮素检测
[匡润1, 2, 3, 4  , 龙腾
, 龙腾1, 3, 4 , 刘海林2 , 吴继辉1, 3, 4 , 吕金胜1, 3, 4 , 谢自然1, 3, 4 , 刘文涛1, 3, 4 , 兰玉彬1, 3, 4 , 龙拥兵1, 3, 4 , 王再花2, * , 赵静1, 3, 4, * ]
, 龙腾, 刘海林, 赵静]
|
|

 , 龙腾, 刘海林, 赵静
, 龙腾, 刘海林, 赵静
作者简介: 匡 润,女, 1998年生,华南农业大学电子工程学院(人工智能学院)硕士研究生 e-mail: kuang1349060064@163.com;龙 腾, 1998年生,华南农业大学电子工程学院(人工智能学院)博士研究生 e-mail: longteng_868@qq.com;
匡 润,龙 腾:并列第一作者
金钗石斛叶片氮素含量是实现其精准施肥的重要决策依据之一。 传统的氮素含量检测方法耗时且有损样品, 如何高效检测金钗石斛叶片氮素含量是种植企业日益关心的问题。 为了快速、 无损获取金钗石斛叶片氮素含量, 以金钗石斛新鲜叶片为实验样品, 在获取其402.6~1 005.5 nm高光谱图像和氮素化学检测值后, 经感兴趣区域(ROI)分割、 光谱预处理, 利用偏最小二乘回归(PLSR)、 核岭回归(KRR)以及支持向量回归(SVR)等三种个体学习器算法, 以及随机森林(RF)、 Bagging和Adaboost等三种集成学习算法, 针对金钗石斛的氮素含量进行建模。 在此基础上构建基于金钗石斛新鲜叶片全波段光谱信息、 经过竞争自适应加权算法(CARS)特征提取的特征波段光谱信息的回归预测模型, 并进行预测精度对比。 结果表明, 在基于全波段光谱信息构建模型时, 经过多项式平滑算法(SG)预处理的光谱数据建立的RF模型最佳(
, LONG Teng, LIU Hai-lin, ZHAO Jing
KUANG Run and LONG Teng: joint first authors
Dendrobium nobile leaf blades’ nitrogen content is a decisive factor for precise fertilization. Traditional nitrogen content detection methods are time-consuming and can completely deplete samples. Efficiently detecting the nitrogen content of D.nobile leaf blades has become a growing concern for herbal medicine cultivation enterprises. To quickly and non-destructively obtain the nitrogen content of D.nobile leaf blades, this study used fresh D.nobile leaf blades as experimental samples. After obtaining their hyperspectral images in the range of 402.6~1 005.5 nm and nitrogen chemical detection values,the images underwent the extraction of regions of interest(ROI), followed by preprocessing of the spectral information within those regions’ learner algorithms including Partial Least-Squares Regression (PLSR), Kernel Ridge Regression (KRR), and Support Vector Regression (SVR), as well as ensemble learning algorithms including Random Forest (RF), Bagging, and Adaboost, were utilized to model the nitrogen content of D.nobile. Regression prediction models were constructed based on the full-band spectral information of fresh D. nobile leaf blades and feature bands of spectral information extracted through CARS, and the prediction accuracy was compared. The results showed that when constructing the monitoring model based on the full-band spectral information, the RF model built with spectral data preprocessed by the Savitzky-Golay filtering (SG) method had the best prediction result (
金钗石斛[1](Dendrobium nobile, D. nobile)又名金石斛、 扁黄草等, 为兰科石斛属植物, 是我国传统名贵中药材之一; 其茎中富含活性生物碱, 是医疗、 保健食品以及化妆品等领域的热门研究对象。 相关的研究还表明金钗石斛叶和花含多种成分和功能活性, 使其在食品领域具有重要的开发潜力和市场应用前景[2, 3]。 除此之外, 金钗石斛花色艳丽, 形态优美, 并具有沁人心脾的香味, 在国际花卉市场上占有重要的位置。
随着市场对金钗石斛的需求量不断增大[4], 如何提高其产量和品质成了种植企业迫切关心的问题, 合理施肥是提高金钗石斛产量和品质的有效手段, 而氮素是植物生长发育的必需和主要营养元素之一[5], 其供应不足或过量都会导致植物体内营养失衡, 进而影响品质和产量[6]。 因此, 在金钗石斛的生长过程中, 检测其氮素含量尤为重要。 目前, 主要采用凯氏定氮法对氮素含量进行定量分析, 该方法测量准确, 但是存在操作复杂、 耗时、 具有破坏性等缺点。 为实现对金钗石斛叶片氮素含量的快速无损检测, 提出了一种基于高光谱成像技术预测金钗石斛叶片氮素含量的方法。
高光谱成像技术是一种将传统成像和光谱学相结合的技术, 可以获取目标物体的二维几何空间及一维光谱信息[7]。 高光谱数据中包含了大量化学和物理信息, 结合机器学习算法可以快速实现作物营养元素含量的测定, 一些学者已将该方法运用到作物氮素含量的快速无损检测。 于丰华等[8]采用氮素特征转移思路构建氮素特征转移指数, 运用线性回归的方式建立水稻氮素含量反演模型, 其效果优于传统植被指数建立的氮素含量模型, 为水稻叶片氮素含量反演提供了技术支持; Abderrahim等[9]对采用不同回归和光谱预处理方法的18个模型进行综合分析, 结果表明将一阶或者二阶多项式平滑算法(savitzky-golay filtering, SG)导数方法与多元散射校正(MSC)相结合是最佳的光谱数据预处理方法, 并且结合波长选择技术可以提高模型的预测精度, 为整合机器学习、 化学计量学和近红外光谱在实现番茄叶片中氮含量的快速无损测量方面的有效性提供了令人信服的证据; Jin等[10]通过使用遗传算法(genetic algorithm, GA)提取相对全面的联合数据集的高光谱图像的有效信息, 提高了PLSR模型预测叶片氮含量的精度, 为使用高光谱遥感数据构建预测氮含量鲁棒性高的PLSR模型提供了有价值的见解。 但这些研究多使用个体机器学习器建立回归预测模型, 其结果具有随机性, 并且模型的参数是不确定的, 改变数据集就需要重新训练模型, 耗时长且过程繁琐。 因此, 有必要使用稳定性更高且泛化能力更好的集成学习方法。
集成学习方法是将几种机器学习技术组合成一个预测模型的算法, 可通过集成策略减小方差(Bagging)、 偏差(Boosting), 以提升预测精度。 Zhang[11]等以PLSR为基线模型, 应用集成学习策略(Bagging、 Boosting以及Stacking)组装多个个体学习器, 将上述两类算法构建六种浓度施肥条件下的烟草叶片氮素含量无人机高光谱预测模型, 结果表明与PLSR模型相比, 所有的集成学习方法的预测精度更高且模型稳定性也有所提升。 刘媛媛等[12]以KNN、 LS-SVM和随机森林(random forest, RF)为基学习器, 以LS-SVM为元学习器, 构建了黑斑病病害程度的Stacking集成学习预测模型, 与单一分类器建模结果相比, 集成学习的判别准确率上升5.18%, 表明Stacking集成学习方法可以与高光谱相结合实现库尔勒香梨黑斑病潜育期的识别。 张杰等[13]采用PLSR、 KNN、 BRR、 SVR四种个体学习器和Bagging、 RF和Adaboost三种集成学习方法进行了水稻氮素营养和籽粒蛋白含量监测的模型精度对比, 其结果表明集成算法具备良好的处理多重共线性的能力, 适合用于高光谱数据的分析和处理, 且模型精度较个体学习器精度高。
本工作采集了金钗石斛叶片的高光谱图像, 进行预处理和特征降维, 分别基于个体学习器算法[偏最小二乘回归(partial least-squares regression, PLSR)、 核岭回归(kernel ridge regression, KRR)、 支持向量回归(support vector regression, SVR)]和集成学习算法(RF、 Bagging、 Adaboost)建立金钗石斛氮素含量估测模型, 旨在探索金钗石斛叶片氮素含量快速准确检测的技术方法, 为大面积的金钗石斛无损营养诊断和设施园艺生产管理提供科学依据。
实验用270个金钗石斛样品均采集于广东省农业科学院环境园艺研究所白云区钟落潭基地(北纬23.371 93°, 东经113.394 83°)。 样品培育过程中每两周施加一次康朴平衡肥, N∶P2O5∶K2O=20∶20∶20, 施肥浓度为500 mg·L-1。 待金钗石斛成熟后, 选取高度、 叶片大小相近的90株金钗石斛作为实验样品运往实验室, 以每株金钗石斛上中下三个位置的较平整且大小均匀的叶片作为样品, 编号并进行高光谱图像的采集。
1.2.1 高光谱成像系统和图像采集
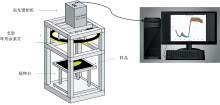
如图1所示, 采用可见-近红外高光谱成像系统(江苏, 双利合谱, Gaiafield Pro-V10)采集金钗石斛的高光谱图像数据, 该系统由光谱相机、 光源、 计算机及控制软件、 暗箱及校正白板等组成。 光谱相机波长范围为402.6~1 005.5 nm, 光谱分辨率为2.8 nm@500 nm, 光源采用卤素灯(光谱范围是350~2 500 nm)。
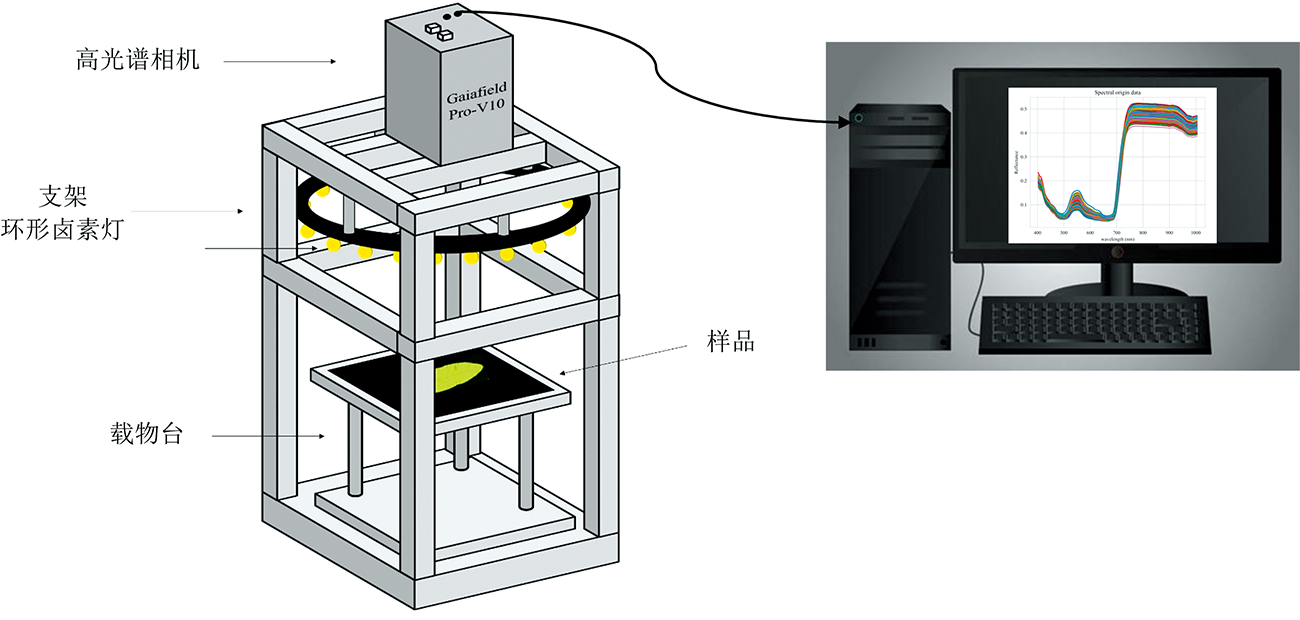 | 图1 高光谱采集系统Fig.1 Hyperspectral acquisition system |
高光谱相机、 光源和样品全位于暗箱中。 采集之前, 调整环形卤素灯与水平面平行, 确保拍摄区域照明均匀, 光功率分布差异小于10%。 实验开始, 先将相机预热15 min, 以减少光谱相机不稳定带来的随机误差。 高光谱相机镜头与样品之间的距离为24.51 cm, 焦距为23.00 cm。 采集参数设置为空间分辨率960×991, 曝光时间5 ms, 增益为1。 采集标准白板高光谱图像, 关闭卤素灯, 盖上相机盖, 采集背景高光谱图像。 高光谱图像数据, 即光谱立方体, 是一个包含x、 y轴方向的空间图像信息和z轴方向的光谱信息的三维数据立方体。 每个金钗石斛样本对应一个光谱数据立方体, 每个立方体包含176个波段。
1.2.2 氮素的化学测定
光谱图像采集完成后, 立即在烘箱里进行杀青60 min(温度为120 ℃), 之后在70 ℃的烘干箱中烘干48 h, 研磨过80目筛, 将磨好的粉末采用凯氏定氮法检测金钗石斛叶片中的全氮含量(见表1)。
| 表1 金钗石斛样品氮素含量 Table 1 Nitrogen content of D.nobile samples |
1.3.1 光谱校正
为消除相机暗噪声和光源强度不均匀的影响, 需要对原始光谱图像进行反射率校正, 校正公式如式(1)
式(1)中, I(i, j)是经修正后某一波长下图像中的(i, j)像素点的反射率, Rraw(i, j)是对应(i, j)的原始灰度值; Rblack(i, j)是对应(i, j)的暗噪声的灰度值; Rwhite(i, j)是(i, j)对应的标准板的灰度值。
1.3.2 ROI区域选择
样品包括有正常叶片、 少数黄斑、 黄斑数量较多, 黄斑和褐斑以及灰斑叶片五种情况, 其RGB图像如图2(A)所示。 黄斑是由细菌导致的炭疽病; 褐斑是由于太阳光照强, 叶片水分蒸发, 水含量小导致叶片干枯形成的; 金钗石斛叶片残留氮肥导致了灰斑的形成。 上述灰斑和褐斑叶片部分会影响氮素含量预测, 所以需要将这两部分区域去除, 剩余的叶片部分将作为感兴趣区域提取光谱数据建立氮素含量相关模型。 金钗石斛叶片的表面留有农药残余, 在采集高光谱数据之前需要用纸巾擦拭叶片。
 | 图2 样品RGB图像和ROI区域的选择 (A): 样品RGB图像, (a): 正常; (b): 少数黄斑; (c): 黄斑数量较多; (d): 黄斑、 褐斑; (e): 灰斑(B): ROI区域的选择过程, (a): 750 nm光谱图; (b): 背景反相; (c): 全局直方图均衡化; (d): 聚类分割; (e): 绿色主体和黄斑; (f): ROI区域Fig.2 Selections of RGB images and ROI regions for samples (A): Selection of sample RGB images, (a): Normal; (b): With a few yellow spots; (c): With many yellow spots; (d): With yellow and brown spots; (e): With gray spots(B): Selection of ROI regions, (a): 750 nm spectrogram; (b): Background inversion; (c): Global Histogram equalization; (d): Clustering segmentation; (e): Green subject and macula; (f): ROI regions |
采用阈值分割法去除背景、 含有褐斑和灰斑的图像部分。 选取高光谱图像立方体中750 nm波段的灰度图[图2(B-a)]进行反相处理[图2(B-b)], 去除背景噪声。 首先进行全局直方图均衡化处理, 提高金钗石斛样品和背景的对比度, 使用聚类分割算法将金钗石斛叶片分为背景、 黄斑、 绿色主体以及介于黄斑和绿色主体两者之间的四类。 对绿色主体和黄斑分别设置阈值, 分别得到绿色主体和黄斑两个部分, 如图2(B-e)所示, 去除其他三类图像部分则得到两种感兴趣区域[图2(B-f)]。 将两种感兴趣区域(region of interest, ROI)进行与运算, 得到最终的ROI区域。 对ROI区域进行掩膜运算, 取金钗石斛叶片的感兴趣区域的轮廓, 再将轮廓映射到其他波段, 计算轮廓内所有像素灰度值的平均值, 即可得到去除背景、 褐斑以及灰斑干扰的ROI区域的光谱数据。
1.4.1 光谱预处理
采用SG算法, 分离重叠样本和突出光谱特征。 其核心思想是在窗口中加权滤波数据, 并通过给定高阶多项式的最小二乘拟合获得权重值。 SG的优点是在平滑时能更有效地保留信号的信息, 其流程如下:
将窗口的宽度设置为n=2m+1, 多项式的阶数设置为k, k-1阶多项式拟合窗口中的每个点x=(-m, …, 0, …, m), 如式(2)。 式(3)是式(4)的矩阵表示。
找到A的最小二乘解, 并且根据式(4)得到平滑结果。 n不宜过大, 并且k一般都小于4。 本实验中, 平滑时采用n=5且k=3。
1.4.2 特征选择
为了进一步提高预测模型的性能和建立模型的效率, 除了对光谱数据进行预处理之外, 还需要对预处理的结果进行特征提取, 降低数据的维度。 采用了竞争自适应加权算法(competitive adaptive reweighted sampling, CARS)来降低光谱数据的维度。 该方法是一种结合MSC采样和PLSR模型回归系数的特征向量选择算法[14]。 首先随机划分校正集, 利用MSC随机选取样品集的70%建立PLSR模型, 求得模型中回归系数向量的绝对值, 计算每个波长的回归系数绝对值权重。 通过自适应重加权技术筛选出PLSR模型回归系数绝对值权重大的变量, 去掉权重值小的变量, 基于权重值大的变量构成的新子集重复上述循环。 设定循环迭代次数是50, 完成迭代次数之后, 将会得到含有50个变量的变量子集和对应的50个RMSECV值。 最小的RMSECV值对应的变量子集即为最佳特征变量组合。
1.4.3 集成学习回归模型
机器学习算法根据训练时使用的学习器数量和结构, 可以分为集成学习和个体学习器。 个体学习器是单个的、 独立的学习器, 只根据训练数据学习; 而集成学习则是通过组合多个个体学习器, 利用集成策略使它们协作学习, 从而得到一个更好的模型。 选择了三种基于不同理论的个体机器学习算法和三种基于不同构建思想的集成学习算法, 研究两类算法在金钗石斛氮素营养监测上的优缺点。
个体机器学习算法包括PLSR, SVR和KRR, 其中PLSR是一种基于多元线性回归模型的变形, 其核心思想是通过寻找自变量与因变量之间的潜在关系来构建回归模型。 在这个过程中, PLSR算法通过对自变量和因变量的协方差进行分解, 将原始自变量的维数降低成为新的综合变量, 然后再使用这些综合变量进行回归建模和预测; SVR的主要思想是将特征空间映射到一个更高维的空间中, 然后在该空间中找到一个超平面, 使得所有样本点到该超平面的距离最小化, 并且在超平面上方和下方分别有限制线, 使得超平面与这些限制线之间的间隔最大化, 从而得到一个可行的回归预测模型; KRR是一种非参数回归方法, 它通过将特征空间映射到高维空间, 利用核函数来计算样本之间的相似度, 从而在高维空间中进行线性回归。
集成学习算法包括Bagging、 随机森林、 Adaboost, 其中Bagging的核心思想是通过对训练数据进行有放回的随机采样, 构造多个数据集来训练多个模型, 最终将这些模型的预测结果进行投票或平均获得最终的预测结果[15]。 随机森林通过建立多棵决策树, 每一棵都被训练在不同的样本和特征上得到一个回归结果, 随机森林就会把这些结果的均值当作最终的结果[16]。 Adaboost基于一系列弱学习器来构建一个强学习器模型, 其每一次弱学习都是关注前一次学习分类错误的样本, 然后加大这些分类错误样本的权值, 使下一次的弱学习器模型对这些分类错误的样本分类更为准确。 如此反复不断学习对分类错误的样本进行纠正, 最终得到一个具有较高准确性的强学习器模型[17]。
利用个体机器学习算法和集成学习算法构建金钗石斛氮素含量预测模型时, 采用五折交叉验证和网格搜索算法来搜索最优的变量组合。 所有模型均使用决定系数(
从图2(A)可以看出, 五种金钗石斛叶片的外观不同, 并且根据图3(a)所示, 氮素含量分布在0.51~2.85 mg·g-1之间, 所有样品氮素含量服从正态分布。 通过研究所有样品的原始反射光谱, 分析发现光谱曲线呈现相似的变化趋势, 如图3(b)左侧坐标所示。 可见光波段(430~760 nm)与氮素含量的相关性均大于0.65, 在该波段中有一个在550 nm左右的反射峰, 出现这一特征的原因是叶绿素对绿光的反射作用较强, 根据图3(b)右侧坐标可以看出在该波段氮素含量越高光谱反射率越高; 在450和670 nm左右有两个吸收谷, 450 nm的“蓝谷”是叶片吸收太阳光中的蓝光形成的, 在400~480 nm波段相关系数逐渐变大, 在“蓝谷”处相关系数达到局部最大0.93; 670 nm左右的“红谷”是叶片吸收红光形成的, 此处的波段和氮素含量的相关系数达到了全局最大0.95。
 | 图3 金钗石斛样品说明 (a): 金钗石斛样品直方图和正态分布曲线; (b): 金钗石斛光谱曲线与氮素含量的相关性分析; (c): SG处理的光谱反射曲线Fig.3 Descriptions of D.nobile samples (a): Histogram and normal distribution curve of D.nobile samples; (b): Correlation analysis between spectral curve of D.nobile and nitrogen content; (c): SG processed spectra |
在680~750 nm形成显著区别于其他植物的“红边”, 多数的红边参数与氮素含量有较强的联系, 如图3(b)也可以看出红边波段与氮素含量的相关性系数较高。 之后形成一个平台, 这主要归因于叶片中水的O—H键。 经过SG处理后的光谱反射率曲线如图3(c)所示, 光谱曲线更加平滑, 并且样本之间的差异也变得更小, 从图3(c)可以看出所有样本的曲线更加紧密。
利用RF、 Bagging、 Adaboost、 PLSR、 KRR和SVR六种不同算法, 根据金钗石斛全光谱数据与氮素含量, 构建金钗石斛氮素含量预测模型(表2)。 R2、 RMSE的下标C、 P和CV分别表示训练集、 测试集和交叉验证集, RAW表示未经预处理。 为了更好的将回归结果可视化, 图4和图6只展示了测试集的预测结果, 训练集的预测结果如表2和表3所示。 由于交叉验证的结果比训练集和测试集的结果更能反映机器学习算法的泛化能力, 因此我们优先考虑
| 表2 基于全光谱数据的模型预测结果 Table 2 Model prediction results based on raw data |
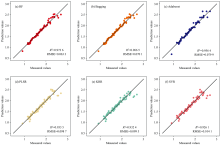
 | 图4 基于SG处理以全波段信息为输入的六种算法测试集的R2和RMSEFig.4 R2 and RMSE of test sets by using six algorithms based on SG processing with full band information as input |
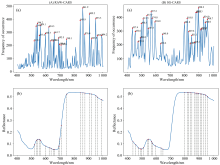
 | 图5 原始光谱数据(A)和SG处理数据(B)用CARS算法提取的特征波段 (a): 特征波段的统计频次; (b): 特征波段的分布Fig.5 Characteristic bands extracted by CARS algorithm from raw data (A, RAW-CARS) and SG processed data (B, SG-CARS) (a): Band statistical frequency; (b): Distribution of characteristic bands |
 | 图6 基于RAW-CARS光谱数据建立六种算法测试集的R2和RMSEFig.6 Establishing R2 and RMSE for six algorithm test sets based on RAW-CARS spectral data |
| 表3 基于特征波段数据的模型预测结果 Table 3 Model prediction results based on feature band data |
六种模型与MSC和SNV预处理结合存在过拟合现象, 但是与SG预处理结合在金钗石斛氮素含量的回归预测中表现优异, 因此, 后续的数据处理是基于SG处理。 原始光谱数据经过SG处理后建立的六种模型精度对比结果如图4和表2所示, 三种集成算法在相同输入参数下获取更高精度, PLSR、 KRR和SVR算法预测实测值散点图围绕y=x线仍然存在一定离散点。 SG预处理方法可以进一步提高RF、 Bagging、 Adaboost以及PLSR模型的预测精度, KRR模型的预测精度没有变化, 但SVR模型的预测精度反而降低。 另一方面, 在比较六种模型的预测性能时, 集成学习算法中的RF的预测性能最佳(
尽管利用全光谱信息建立的金钗石斛氮素回归预测模型精度较高, 但是全光谱数据中存在大量冗余特征, 导致预测的效率较低, 限制了机器学习模型在实时检测金钗石斛氮素含量积累的可行性。 采用CARS算法选取特征波长, 分别运行RAW-CARS、 SG-CARS算法程序各500次, 统计各个波长出现的次数, 图5(A-a)和图5(B-a)的纵坐标表示对应波段出现的频率, 出现次数越多则说明该波段对金钗石斛氮素含量预测贡献越大, 最后在原光谱中标出特征波长的位置如图5(A-b)和(B-b)所示, 如图5(A-b)和图5(B-b)所示挑选出现200次以上的波段建立回归模型。 氮素的特征波长多集中在叶绿素、 红边和水峰处, RAW-CARS程序从原来的176个波段中提取出22个特征波段, 占全光谱波段12.5%, 分别为521.3、 534.4、 544.2、 557.4、 564.1(叶绿素的绿峰)、 600.7、 624.3、 637.8、 654.8、 661.7(叶绿素b的吸收峰)、 692.5、 699.4(红谷)、 709.8、 748.1(红边)、 843.9、 861.9、 876.4、 909.2、 923.9、 953.3、 964.5、 994.2(水峰); SG-CARS提取出27个特征波段, 这些特征波段占全光谱波段的15.3%, 分别为437.4、 456.6、 475.8(蓝谷)、 492.0、 498.5、 511.5、 537.7、 547.5、 567.4、 574.0(叶绿素的绿峰)、 537.7、 594.0、 634.4、 648.0(叶绿素b的吸收峰)、 801.0、 818.8、 829.6、 840.3、 851.1、 869.2、 880.1、 887.3、 898.2、 912.9、 920.2、 934.9、 946.0、 960.7(水峰)。 这是由于氮素是构成叶绿素的重要元素, 因此与叶绿素a、 b相关的波长的反射率会随着植株体内氮素含量的变化而变化。
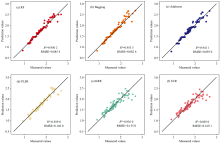
利用RF、 Bagging、 Adaboost、 PLSR、 KRR和SVR六种不同算法, 经RAW-CARS、 SG-CARS预处理后, 构建金钗石斛氮素监测模型(表3)。 图6和图7是基于上述两种数据分别画出的测试集散点图, KRR和SVR算法的y=x直线两边的离散点明显变多, 并且与用全光谱所建立的模型对比, 集成学习算法和个体学习器算法的监测精度均有所降低。 基于RAW-CARS、 SG-CARS数据建立的三种集成学习模型的预测性能均比三种个体学习器算法的预测性能高, 利用RAW-CARS数据进行预测时, Bagging模型的预测效果最佳(
 | 图7 基于SG-CARS光谱数据建立六种算法测试集的R2和RMSEFig.7 Establishing R2 and RMSE for six algorithm test sets based on SG-CARS spectral data |
随着金钗石斛的种植面积和需求量不断增加, 使用快速、 无损的方法检测植株的营养元素显得尤为重要。 获取金钗石斛叶片光谱数据和其氮素含量, 采用多种机器学习算法进行金钗石斛氮素营养检测。 研究表明:
(1)基于金钗石斛叶片的全波长信息建立六种回归预测模型结果表明: 无论是否进行预处理, 集成学习算法对金钗石斛氮素含量的预测精度均比个体学习器高, 并且测试集和交叉验证集的R2值都达到了0.95以上, 表明全光谱信息中与金钗石斛氮素含量相关的信息被充分利用。 其中经过SG预处理的数据构建的RF模型预测效果最好(
(2)基于CARS算法提取的特征波段建立回归预测模型结果表明: 将CARS算法提取的特征波段用于构建金钗石斛氮素含量预测模型, 各个模型的预测精度相比于使用全光谱数据建立的模型都有所降低。 经特征降维后, 基于SG-CARS数据建立的Bagging模型预测精度最高(
实验结果表明, 全光谱携带的信息能够更好的对金钗石斛氮素含量进行监测, 六种方法中, 仅输入全光谱的时候, 无论是否经过SG预处理, RF模型均最优, 经过CARS算法特征提取后, Bagging算法表现最优, Adaboost也取得了较好的监测结果。 利用所有光谱信息进行回归建模, 较大程度的保留了与金钗石斛氮素含量相关的信息, 模型的预测精度较高, 但是模型构建的效率比较低。 相反, 对光谱数据进行降维, 利用特征波段建立回归预测模型, 模型精度有所降低, 但是建模的效率大大提高。 因此, 在优化回归模型的特征参数时, 必须始终考虑精度和效率之间的平衡。 本实验只对金钗石斛氮素含量进行了预测, 在金钗石斛生长过程中还有其他影响其品质和产量的元素, 这些元素含量是否与金钗石斛光谱信息存在最优映射关系有待下一步的研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|