




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
铀矿区超富集植物可见及短波近红外光谱判别研究
[肖怀春1  , 刘阳
, 刘阳1 , 魏冰雪1 , 高家榕1 , 刘燕德2 , 肖慧1 ]
, 刘阳|
|


作者简介: 肖怀春, 1984年生,东华理工大学地球物理与测控技术学院讲师 e-mail: xiaohuaichun1985@163.com
随着各国对核能需求的剧增, 铀矿勘探成为核能供给中关键环节。 铀矿勘探方法主要有放射性物探测量、 地球化学测量等传统方法, 大都存在探测数据不准确、 效率低等的不足。 采用近红外光谱技术, 结合化学计量学, 探索铀超富集植物筛选及确定的可行性。 通过铀矿区植物生长情况及特性调查挑选超富集植物, 利用近红外光谱分析仪获取不同区域其叶片综合光谱, 比较分析光谱响应关系。 发现两种超富集植物的吸收峰位于650~700和950~1 050 nm两个波段内, 前一个波段为叶绿素的吸收峰主要由C—O与C—H键伸缩振动的组合频产生。 后一个波段是水的吸收峰主要由O—H键弯曲振动5级倍频导致。 通过PCA与SPA选择特征变量, 将两种样本分别按照3∶1的比例随机划分为训练与预测两部分, 结合PLS和LSSVM两种方法构建超富集植物铀富集检测模型, 并对比预测效果。 发现基于PLS的狗尾草铀富集检测模型效果最佳, 其判别正确率高达100%, RMSEP为0.115, R2为0.946。 两种建模方法中狗尾草检测模型均优于辣蓼, 可能是狗尾草富集系数高于辣蓼, 导致其铀矿区叶片铀含量浓度高于非铀矿区。 结果表明, 近红外光谱技术联合偏最小二乘法建立的超富集植物铀富集检测模型效果最好, 很好的对铀超富集植物进行无损识别, 从而筛选并确定之是可行的。 该方法为废铀矿区生态修复提供重要参考, 同时为利用特异性、 指示性植物寻找铀矿提供新思路。
With the increasing demand for nuclear energy, uranium exploration has become a key link in the supply of nuclear energy. Uranium exploration methods mainly include radioactive geophysical surveys, geochemical surveys, and other traditional methods, most of which have the shortcomings of inaccurate detection data and low efficiency.This study used near-infrared spectroscopy and stoichiometry to explore the feasibility of screening and identifying uranium super enriched plants. Through the investigation of the growth and characteristics of plants in the uranium mining area, the ultra-enriched plants were selected, the leaf comprehensive spectra in different regions were obtained by a near-infrared spectroscopy analyzer, and the spectral response relationship was compared and analyzed. It was found that the absorption peaks of the two hyper-enrichedplants were located in two bands: 650~700 and 950~1 050 nm. The absorption peak of chlorophyll in the former band was mainly generated by the combined frequency of C—O and C—H bond stretching vibration. In the latter band, the absorption peak of water is mainly caused by the 5-order frequency doubling of O—H bond bending vibration. The feature variables were selected by principal component analysis (PCA) and successive projections algorithm (SPA), and the two samples were randomly divided into training and prediction parts according to the ratio of 3∶1, respectively. The detection model of uranium enrichment in super-enriched plants was constructed by combining the two methods of partial least squares(PLS) and least square support vector machine (LSSVM), and the prediction effect was compared. Obtained the detection model of Setaria uranium enrichment based on PLS had the best effect, with a discrimination accuracy of up to 100%, RMSEP of 0.115, and R2 of 0.946. The Setaria detection model is superior to the coverage in the two modeling methods. It may be that the enrichment coefficient of setaria morifera is higher than that of ciderage.The results show that the detection model of uranium enrichment in super-enriched plants established by near-infrared spectroscopy combined with the partial least squares method has the best effect, and it is feasible to screen and identify uranium super-enriched plants. This method provides an important reference for the ecological restoration of the spent uranium ore area and a new idea for the use of specific and indicative plants to search for uranium ore.
铀矿开采作为核能来源的主要环节之一, 其关键是铀矿勘探[1]。 随着各国对铀需求量不断的剧增以及铀冶矿业飞速发展, 铀矿勘探在矿业生产中扮演越来越重要的角色[2]。 据统计, 我国铀资源成矿地质条件优秀, 铀资源潜力巨大[3], 但要将铀资源潜力转化为可利用资源储量, 任重而道远, 所以铀矿探测迫在眉睫。 传统方法主要是放射性物探测量, 如航空γ测量、 地面γ测量等, 该方法或多或少存在缺点, 如航空γ测量受飞机性能限制以及有些区域无法保障低空飞行, 探测数据不够准确, 同时效率较低, 而地面γ测量受地表因素影响较大, 且无法确认放射性核素中具体的元素。 经多年的发展与积累, 逐步从传统的地面勘探转向深部隐伏勘探, 传统探测方法并不适用[4]。 故筛选铀超富集植物并确定对指导铀矿勘探具有重要参考价值。
金属元素铀通常以化合物形式存在, 采用化学方法检测不仅提取难度大、 周期长且具有破坏性[5]。 因其不具备光谱活性, 无法直接光谱检测; 但它通过积累、 迁移和扩散等方式被植物吸附, 为开展矿区铀富集植物检测研究奠定了基础[6]。 部分学者在该方面开展了相关研究工作。 Arsenov等研究了螯合剂(柠檬酸)对植物提取的酶活性影响和抗氧化防御的作用, 结果表明其促进了积累的Cd从根部向枝条和叶片的迁移, 还减少了Cd胁迫对光合作用的负面影响[7]。 Lombi等在不遭受生物毒害的情况下, 利用水培法测量得到超富集植物东南景天子叶对Cd的累积达到10 000 mg·kg-1, 展现出对Cd超高耐受性[8]。 赵雅曼等选取采矿区土壤及在此土壤中生长的7种植物为研究对象, 用化学方法测定植株体内富集的重金属元素(镉、 铅、 锌、 铜)含量, 结果发现芒萁对Cd、 Pb和Cu均具有较强的吸收能力, 且对这3种重金属的转运系数和富集系数均>1, 是潜在的多金属富集植物[9]。 吴攀等用电感耦合等离子体质谱仪(ICP-MS)测定铅锌废渣场周边不同土地上植物富集重金属情况, 结果显示玉米对Cu、 Zn、 Cd、 Pb等重金属较强的根部富集能力, 萝卜则相反。 林地植物中荚蒾对重金属有较好的富集能力[10]。
上述研究大都针对植物吸收或富集重金属含量展开化学方法检测。 光谱技术的发展及其独特优势, 使其被广泛应用于地质、 食品、 农业等领域。 如帅琴等获取了典型植物高光谱, 并测定其富集元素的含量, 建立了Co和W元素响应模型, 结果表明植物中提取的成矿元素富集信息可指示潜在的矿床位置[11]。 张大成等结合LIBS技术获取土豆干和百合干光谱, 分析对比了两种样品中Ca, Na, K, Fe, Al, Mg六种金属元素含量的情况[12]。 陈圣波等通过获取矿区典型植物高光谱, 测试分析了植物中14种金属元素和叶片生化参数, 结果表明不同植物选择性吸收富集的金属元素不同[13]。 Dunagan等在不同浓度的Hg溶液培养条件下获取了菠菜光谱, 并提取其红边位置及植被指数作为响应参数, 结果表明不同生长期两种参数的响应效果异同[14]。 Smith等发现用725和702 nm处的一阶微分比可监测泄露气体胁迫下植物生长的状况[15]。 综上所述主要在植物中金属元素含量检测或重金属胁迫下植物生长状态监测方面开展研究, 关于植物铀富集光谱检测研究鲜有报道。 因此开展超富集植物铀富集近红外光谱无损检测研究将有助于铀超富集植物筛选与确定。
铀矿区植株含铀浓度高, 光合作用受影响, 导致叶片细胞结构、 叶绿素和水分等发生变化, 光谱异于非铀矿区植株。 有研究表明, 少量铀会促进植物生长发育, 表现为叶面积增大, 根系变长, 但随着铀浓度增大, 植物体内会发生代谢紊乱, 表现为叶片缺绿严重, 光合效率降低, 甚至植株可能死亡[16, 17]。 为此, 开展铀矿区植物生长调查, 结合植物特性筛选出优势植物, 综合植物特性与富集系数, 获取铀矿区及非铀矿区超富集植物叶片综合光谱, 比较分析光谱响应关系。 提取样本特征变量, 结合化学计量学, 构建超富集植物铀超富集检测模型, 对不同区域的铀超富集植物进行判别, 以期实现铀超富集植物的筛选及确定。
样品采集地位于江西某铀矿区, 以丘陵地貌为主, 如图1所示, 地势整体呈现四周低、 中心高; 属亚热带气候, 四季分明, 地下水资源丰富。 植被覆盖面大, 且不同植被生长周期和特点使其对铀富集程度呈现差异, 经调查狗尾草与辣蓼生长周期均为一年[18]。 当一种植物可从土壤中富集重金属元素并能将其转移到地上部分, 吸收量超过一般植物的100倍以上, 且不影响植物本身的正常生理活动, 则被称为超富集植物或超累积植物[19]。
 | 图1 矿区地貌Fig.1 Mine landform |
调查分析得知此矿区周边存在超富集植物有: 芒草、 狗尾草、 鬼针草、 野棉花、 辣蓼、 葎草、 商陆、 凤尾蕨和鸭跖草共九种[18]。
通过实地考察以及富集植物专家的指导, 发现由于气候、 土壤等因素, 并非所有优势植物个体数量都较多, 所以选择其中个体数量较多的狗尾草与辣蓼作为研究对象[18]。 对其生长区域采用随机抛圈法划分为4个区域, 于每块区域中分别采摘狗尾草与辣蓼各13株, 狗尾草与辣蓼分别为52株; 为对比分析, 在与铀矿区生长环境相似的非铀矿区用同样方法采摘狗尾草与辣蓼各52株。 用保鲜袋装好样株带回温度为22 ℃, 相对湿度为45%~53%的实验室, 并存放冰箱保鲜室。 存储期间, 非铀矿区3株狗尾草和3株辣蓼以及铀矿区1株狗尾草和2株辣蓼样品因损坏被去除, 最终狗尾草剩余100株, 辣蓼剩余99株。
植物不同部位铀富集系数不同, 顺序为根>叶>茎。 但因根直径较小, 影响数据可靠性, 故取叶片代表整株样品[18]。 每株样品取一片比较完整且面积较大叶片, 使用Thermo Scientific公司纯水仪制造的蒸馏水清洗叶片, 降低灰尘、 泥土等外界因素的影响, 烘干水分后压平, 防止光谱采集期间出现能量饱和。 将处理完的叶片用自封袋装好, 并标号备用。
采用纬创英图WY-NIRMagic-6100/H型多光谱成像与近红外光谱检测系统, 其整体外观如图2所示, 主要由往复式传送平台单元、 主控单元以及光谱和图像采集单元等几部分硬件构成。 配有分析软件及ChemoStudio化学计量学分析软件。
 | 图2 多光谱成像与近红外光谱检测系统Fig.2 Multispectral imaging and near-infrared spectroscopy detection system |
数据采集前仪器应预热30 min, 使其达到最佳使用状态。 同时进行相应参数设置, 主要有: 连续测量模式, 低速运行, 参比积分时间1 600 μs, 单次采集时间1 000 μs, 平均次数为10等。 软件参数界面具体如图3所示, 波长范围为600~1 050 nm, 数据采集期间样品应位于光源正下方, 放置位置如图4所示。
 | 图3 软件参数界面Fig.3 Software parameter interface |
 | 图4 样品放置示意图Fig.4 Schematic diagram of sample placement |
偏最小二乘(partial least squares, PLS)是一种基于不同样本特征的多元统计方法, 集成了典型相关分析、 线性回归分析的优点, 有效解决变量间的多重共线性问题, 且计算简单, 预测精度较高[20, 21], 其公式为式(1)
式(1)中, F预测为预测样品类别值, P预测为由光谱矩阵求出的预测样品得分矩阵, C为预测样品类别值的得分矩阵与光谱矩阵的得分矩阵进行线性回归得到的关联矩阵, Q为浓度矩阵的载荷矩阵。
最小二乘支持向量机(least squares support vector machine, LSSVM)是一种将支持向量机的凸二次规划问题转化为求解线性方程问题的方法, 用于分析数据和模式识别, 以及分类和回归分析[22, 23], 其预测公式为式(2)
式(2)中, 径向基K(xi, xj)为核函数, α为拉格朗日乘子, b为偏差。 LSSVM方法的两个可调参数(σ 2和γ)通过均方误差(MSE)的目标函数最小化得到[24]。
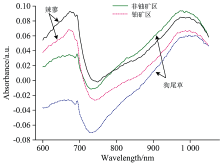
采用投射与反射双模式, 获得的铀矿区和非铀矿区代表性样品综合光谱如图5所示, 图中非铀矿区植物光谱曲线为实线, 铀矿区植物光谱曲线为虚线。 从图5中可以看出不同植物非铀矿区吸光度整体高于铀矿区, 720~1 080 nm范围内表现的更为明显, 同时因狗尾草的富集系数高于辣蓼, 在铀矿区辣蓼吸光度高于狗尾草。 两种超富集植物的吸收峰位于650~700和950~1 050 nm两个波段内, 前一个波段辣蓼和狗尾草的吸收峰位置分别在670与690 nm附近, 为叶绿素的特征波长, 主要由C—O与C—H键伸缩振动的组合频产生。 后一个波段两种超富集植物的吸收峰分别在975和980 nm附近, 是水的特征波长, 吸收峰主要由O—H键弯曲振动5级倍频导致。 铀浓度高使得植物叶片光合作用受到阻碍, 破坏了叶绿体的结构和功能, 促进叶绿素的降解, 叶绿素含量的下降, 水分减少, 故铀矿区超富集植物的吸光度均低于非铀矿区, 且光谱出现“红移”现象[25, 26], 其中一个吸收峰位于680 nm处。 通过对比分析铀矿区与非铀矿区超富集植物叶片光谱, 可知铀含量与光谱存在响应关系, 因此, 结合变量筛选, 开展超富集植物铀富集检测模型研究。
 | 图5 狗尾草与辣蓼的原始近红外光谱Fig.5 Original near infrared spectra of Setaria and Polygonum spiculata |
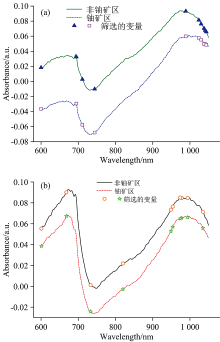
连续投影算法(successive projections algorithm, SPA)是一种前向迭代搜索变量的方法, 即从某一个波长开始, 在每次迭代中加入一个新变量, 直至所选变量数达到设定值, 其目的是筛选出冗余信息最少的波长来解决共线性的问题[27]。 设置迭代次数最小与最大值分别为10和100, 选择的变量个数均为10。 狗尾草与辣蓼两种超富集植物光谱被筛选出的变量对应波长(单位为nm)分别为: 600、 695、 711、 744、 989、 1 024、 1 030、 1 041、 1 038、 1 044和601、 668、 733、 820、 949、 954、 974、 978、 994、 1 035, 如图6所示。
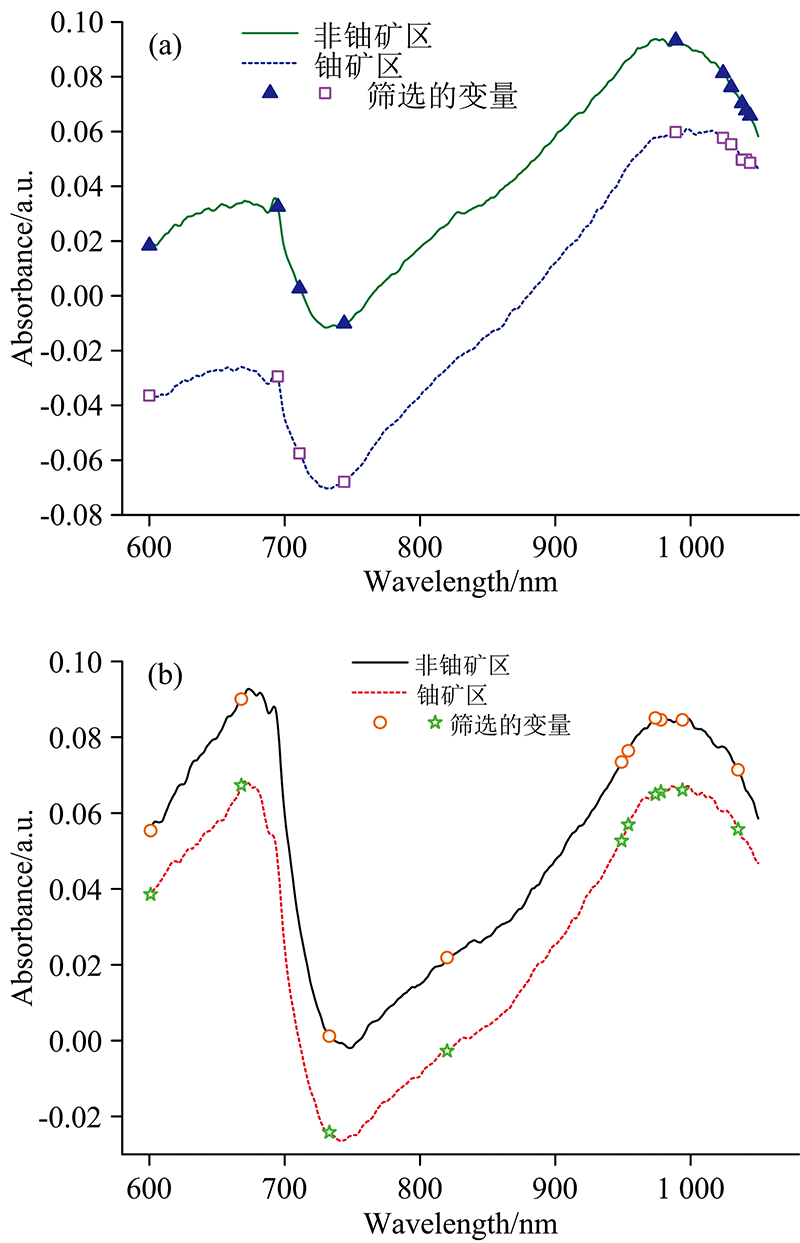 | 图6 超富集植物SPA筛选变量结果 (a): 狗尾草; (b): 辣蓼Fig.6 SPA screening variable results of super-enriched plants (a): Setaria; (b): Polygonum spiculata |
从图6中能看出变量大多分布于波峰处, 分别对应叶绿素和水分的吸收峰, 主要是因其涵盖了叶片的大部分信息。 将其作为输入, 后续建立模型进行分析。
主成分分析法是一种常用的特征提取方法, 它利用正交变换把由线性相关变量表示的观察数据转换为少数几个由线性无关变量表示的数据。 其中PC1解释了数据集中最大方差及方向, PC2以一种与PC1不相关的方式保留了大部分剩余的变量, 以此类推, 这样有助于确定每个变量的贡献, 优点是降低数据集维数, 尽量减少信息的丢失[28, 29]。 在此设置最大主成分数为20, 其得分权重如图7所示。
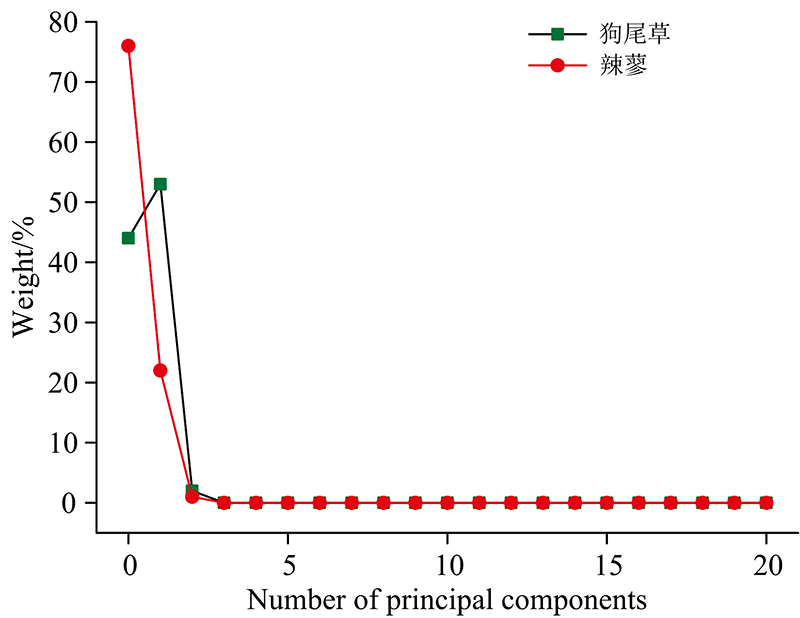 | 图7 主成分得分权重Fig.7 Principal component score weights |
图7中能发现不管是狗尾草还是辣蓼, 其前三个主成分的权重之和均为97%以上, 包含了叶片基本的原始信息。 将其作为模型输入, 建立超富集植物铀富集检测模型。
将100个狗尾草和99个辣蓼叶片随机按照3∶1的比例, 分为训练集和预测集, 同时设置铀矿区样品真值为1, 非铀矿区为0, 类别阈值为0.5。 结合PLS和LSSVM两种分析方法分别建模。 前者主要评价指标为判别正确率、 预测均方根误差(RMSEP)和相关系数(R2)等。 后者中采用RBF核函数, 模型主要评价参数为核参数σ 2和正则化参数γ, 使用十折交叉验证法选出最优值。 值越小, 模型性能越好[24]。 狗尾草与辣蓼的铀富集检测模型结果如表1所示。
| 表1 两种超富集植物判别模型结果 Table 1 Discriminative modeling results for two super-enriched plants |
从表1中能看出, 两种超富集植物的光谱数据经PCA特征变量压缩后, 不管是PLS模型还是LSSVM模型, 其判别效果都提高且模型较简单。 主要原因是PCA选择的20个线性无关的变量代表了叶片光谱的大部分主要信息, 一些线性相关的冗余变量被剔除。 SPA选择的变量数虽少, 但有可能剔除了包含样品部分信息的变量, 导致模型效果不佳, 但相比于全谱, 模型效果有所改善, 同时模型复杂度也得到了简化。
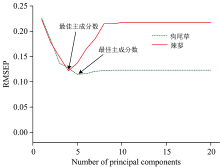
LSSVM与PLS模型效果对比, 在铀富集检测模型判别正确率相同条件下, 前者最终要回归线性层面, 故后者模型效果要略优于前者。 同时检测模型的一个主要因素是主成分数, 采用留一法交互验证确定, 两种超富集植物的主成分数决定图如图8所示。
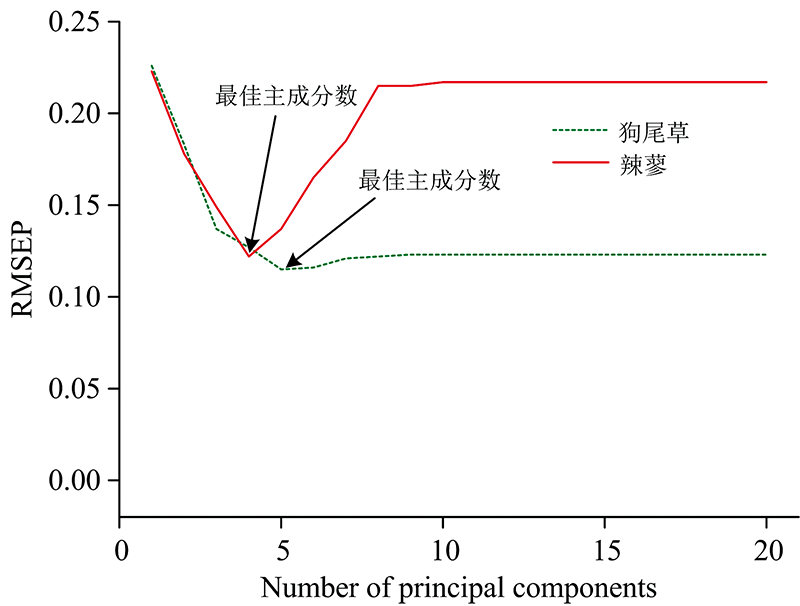 | 图8 主成分分析Fig.8 Principal component analysis |
从图8中可以看出, 随着PC数的增加, 预测集均方根误差逐渐下降。 狗尾草铀富集最佳PLS检测模型在PC数为5时REMSP达到最低, 而辣蓼铀富集最佳PLS检测模型在PC数为4时REMSP达到最低, 之后随着PC数的增加, 狗尾草的均方根误差基本保持不变, 而辣蓼的均方根误差逐渐升高。
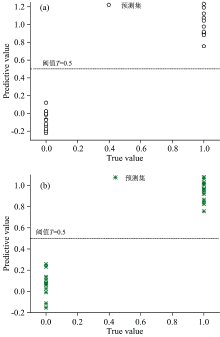
图9分别为狗尾草和辣蓼两种超富集植物最佳PLS检测模型预测值与分类变量相关图, 取设定真值的中间值T=0.5为阈值, 从图9中可以看出不管是狗尾草还是辣蓼, 均能较好地将铀矿区与非铀矿区的样本分开, 没有误判, 且判别正确率都为100%。
 | 图9 两种超富集植物PLS判别模型分类变量与预测值散点图 (a): 狗尾草; (b): 辣蓼Fig.9 Scatter plots of categorical variables and predicted values of the PLS discriminative model for the two hyperenriched plants (a): Setaria; (b): Polygonum spiculata |
通过PCA选择的20个变量, 对比PLS和LSSVM两种方法构建的超富集植物铀富集检测模型的预测效果, 如表2所示。 狗尾草要优于辣蓼, 主要原因可能是狗尾草的富集系数高于辣蓼, 导致其铀矿区叶片铀含量浓度明显高于非铀矿区。 在PLS检测模型中, 虽二者判别正确率均为100%, 且狗尾草检测模型的PCS高于辣蓼, 但狗尾草检测模型的RMSEP为0.115, 低于辣蓼模型的0.122, 而R2为0.946高于辣蓼的0.943; 在LSSVM模型中, 虽二者的判别正确率也相同, 均为100%, 但狗尾草模型的核参数σ 2和正则化参数γ分别为1.05和1.02, 小于辣蓼的1.35和1.12, 且狗尾草模型的运算时间t为0.04 s, 较短。
| 表2 狗尾草与辣蓼模型对比 Table 2 Comparison of modeling results for Setaria and Polygonum latifolia |
基于近红外光谱数据, 采用PLS和LSSVM两种方法, 在不同输入变量的基础上, 成功的建立了不同区域狗尾草和辣蓼两种超富集植物铀富集检测模型。 将两种样本分别按照3∶1的比例随机划分为训练集与预测集, 通过预测集对检测模型能力进行评价, 并对比分析判别结果, 得出基于PLS的狗尾草铀富集检测模型效果最佳, 其判别正确率高达100%, 能将两个不同区域超富集植物进行分离。 结果表明, 近红外光谱技术结合偏最小二乘法建立的超富集植物铀富集检测模型效果最好, 能对铀超富集植物无损识别, 从而筛选并确定是可行的。 基于近红外光谱的铀矿区超富集植物检测方法应用于铀矿区植物修复具有重要的现实意义, 为其他矿区生态修复提供重要参考, 并为通过特异性、 指示性植物寻找铀矿提供新思路。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|