


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱结合深度学习的桑椹采后TSS含量无损检测
[王子轩1  , 杨良
, 杨良2, 3, 4, * , 黄凌霞2 , 何勇4 , 赵丽华3 , 占鹏飞3 ]
, 杨良, 黄凌霞|
|


作者简介: 王子轩, 2002年生, 河海大学商学院本科生 e-mail: wangzixuan@hhu.edu.cn
桑椹起源于中国, 是我国最具历史的“药食同源”水果之一。 但桑椹采后快速变质和皮薄易腐败的特点制约了其产业化发展。 总可溶性固形物(TSS)是决定桑椹风味和品质的重要成分, 是其商业化的最基本品质特性之一。 借助于近红外高光谱成像技术和深度学习方法优化桑椹采后TSS含量的预测模型, 同时评估采后常见储运温度条件对定量模型的影响, 为桑椹采后品质快速评价提供依据。 选用具有一致商业成熟度的桑椹分别在常温(25 ℃)和低温(4 ℃)储藏, 然后在不同储藏阶段对样本进行光谱数据采集和TSS含量测定直至桑椹腐败不适宜食用。 基于校正后的高光谱图像提供的空间信息提取感兴趣区域以获得无背景的代表性光谱, 然后将标准正态变换(SNV)、 多元散射校正(MSC)、 Savizkg-Golag(SG)平滑用于光谱的预处理, 以提升光谱信噪比。 利用深度学习方法实现了桑椹采后TSS含量的预测。 对于常温和低温桑椹样本, 最优CNN模型剩余预测偏差(RPD)值分别达到5.828和5.449, 预测均方根误差(RMSEP)值分别为1.082和1.099 °Brix, 可见低温条件储藏降低了CNN模型的预测性能。 为进一步验证CNN模型的效果, 建立了基于传统经典机器学习方法偏最小二乘(PLS)和最小二乘支持向量机(LS-SVM)的TSS含量预测模型。 结果表明, 非线性模型LS-SVM更适合桑椹的TSS含量预测。 对于两个不同储藏温度, 最优LS-SVM模型RPD值分别为4.221和4.423, 表明CNN优于经典机器学习方法。 综上所述, 高光谱成像结合深度学习CNN的桑椹采后TSS预测具有较大潜力, 这为桑椹品质快速检测提供了技术支撑。
Originating in China, mulberry is one of the fruits of the homology of medicine and food and has a long history. However, the industrialization of mulberry fruit has been limited by its characteristics of short maturity period and the tendency for thin skin to decay. Total soluble solid (TSS) is an important component of determining the mulberry flavor and qualityandis one of the most basic quality characteristics for its postharvest-commercialization. This study aims to optimize a prediction model for monitoring the TSS content in postharvest mulberry fruits using near-infrared hyperspectral imaging and deep learning methods and to evaluate the impact of common postharvest storage temperature on the quantitative models, thus providing support for rapid quality assessment of mulberry fruits. Mulberry fruits with consistent commercial maturity were selected for storage at room temperature (25 ℃) and low temperature (4 ℃). Samples from different storage stages were selected for spectral data collection and TSS content determination until mulberry fruits became unfit for consumption. Based on the spatial information provided by the corrected hyperspectral images, regions of interest were extracted to obtain representative spectra without background accurately. Then, standard normal variate (SNV), multiplicative scatter correction (MSC), and Savizkg-Golag (SG) smoothing were used for spectra preprocessing to improve the spectral signal-to-noise ratio. Prediction models for TSS content measurement in postharvest mulberry fruits were established using deep learning. For mulberry samples stored at room temperature and low temperature, the optimal CNN models obtained the residual prediction deviation values of 5.828 and 5.429, with the root mean square error of prediction (RMSEP) values of 1.082 and 1.099°Brix, respectively, indicating that the prediction performance of the CNN model was degraded due to the low-temperature storage. The classical machine learning methods of partial least squares (PLS) and least square support vector machine (LS-SVM) were used to establish models for TSS prediction further to verify the effectiveness of the constructed CNN models. Results showed that the nonlinear LS-SVM model was more suitable for predicting TSS content in mulberry fruits than the linear PLS model. For mulberry fruits stored at two different temperatures, the optimal LS-SVM models achieved RPD values of 4.221 and 4.423 for TSS prediction, respectively, indicating that the CNN performed better than the classical machine learning methods. In conclusion, hyperspectral imaging combined with deep learning CNN has excellent potential in predicting TSS content inpostharvest mulberry fruits, which provides technical support for rapid assessment of mulberry quality.
桑树原产于中国, 现已在世界范围内许多不同气候区种植[1]。 桑椹为桑树的成熟果实, 营养价值高, 含有丰富的蛋白质、 维生素、 矿物质, 以及多糖、 花青素、 类黄酮、 生物碱等生物活性物质[2, 3], 是我国最早确定并加以利用的“ 药食同源” 水果之一。 从入药到鲜食, 果桑逐渐发展为独立的产业, 丰富了我国水果食品行业。 然而, 桑椹一般在3月— 5月集中成熟, 采后桑椹由于呼吸跃变作用快速后熟, 加之其水分营养含量高, 极易受机械损伤和微生物侵蚀而失去食用价值。 因此, 借助于光谱技术对桑椹采后品质进行及时快速的无损检测, 对于规范桑椹品质分级, 避免其商品价值下降造成经济损失具有重要意义。
总可溶性固形物(total soluble solids, TSS)是评价桑椹采后品质和风味的重要指标[4], 也是其商业化质量的基本特性之一。 因此, 国内外学者在桑椹TSS含量检测上做了许多研究。 Huang等[5]首先使用可见-近红外光谱对有不平整表面的桑树果实内部TSS含量进行了预测, 最优模型决定系数为0.7。 颜辉等[4]使用手持式近红外光谱仪采集桑椹的光谱信息, 构建了TSS的竞争性自适应重加权抽样-偏最小二乘(competitive adaptive reweighted sampling-patrial least squares, CARS-PLS)模型, 验证集决定系数高达0.943。 Soltanikazemi等[6]基于可见-红外光谱和遗传算法检测了桑椹果汁的TSS含量, 遗传-偏最小二乘算法(genetic algorithm-patrial least squares, GA-PLS)模型相关系数达到0.96。 由于桑椹为聚花果, 呈现不规则圆柱形且表面不平整, 近红外光谱难以获取整颗果实的代表性光谱, 因而将成像和光谱相结合的高光谱技术被认为更适合桑椹的品质检测[7]。
高光谱成像技术近来备受关注, 被用于食品品质快速无损评价。 与近红外技术相比, 其最大的优势在于利用成像将空间信息耦合于光谱, 丰富了信息维度。 利用高光谱成像提供的空间信息, 可以精确的提取食品无背景的代表性光谱, 因此高光谱成像比近红外技术更适合小而非圆形的食品品质评估[8]。 但另一方面, 高光谱数据的高维度和冗余度增加了分析的复杂性, 选择合适的化学计量学方法对于模型构建至关重要。 卷积神经网络(convolutional neural network, CNN)是一种常用的深度学习方法, 具有权值共享、 特征提取等优点, 在农业、 医药等领域具有广泛的应用基础[9, 10], 为桑椹TSS含量预测提供了新思路。 此外, 桑椹采后常以室温和低温两种方式进行储运, 温度可能影响预测模型的性能[11, 12], 有必要构建基于不同储藏温度条件下的预测模型, 提升模型的实际应用潜力。
本工作使用高光谱成像技术与深度学习算法, 结合不同的光谱预处理, 进行了桑椹采后TSS含量的快速无损预测, 比较了采后不同储运温度对CNN模型效果的影响。 同时借助传统经典机器学习算法偏最小二乘(PLS)和最小二乘支持向量机(least square support vector machine, LS-SVM)构建预测模型, 通过与CNN模型对比, 验证了CNN模型对桑椹采后TSS含量预测的潜力, 为桑椹采后品质快速无损检测提供了新方法。
实验选用有代表性的桑椹(Morus alba L.)品种, “ 大十” 和“ 桂花蜜” (如图1所示), 于浙江省湖州市的商业果桑园手工采摘, 并在低温条件下运输至实验室。 挑选成熟度一致、 大小均一、 无病虫害和缺陷的果实进行储藏。 桑椹被随机分为6组, 每组包含两个品种的各20个样本。 将其中3组样品常温储藏(25 ℃), 另外3组低温储藏(4 ℃)。 常温储藏样品每天取样采集数据, 低温储藏样品每两天取样采集数据。
 | 图1 桑椹样本大十(a)和桂花蜜(b)Fig.1 Mulberry fruit samples, Dashi (a) and Guihuami (b) |
使用近红外高光谱成像(near-infrared hyperspectral imaging, NIR HSI)系统(如图2所示)采集样品光谱数据, 系统详细数据参考文献[7]。 光谱仪被置于定制黑箱内, 采用双卤素灯提供可控光源, 采集光谱范围为900~1 700 nm, 包含256个波段。 高光谱图像采集过程中, 样品以20 mm· s-1匀速移动, 设置曝光时间为3 ms, 镜头距离样品30 cm, 采集方式为线扫描。 每次采集样品光谱数据的同时, 采集参考黑板和白板光谱, 用于图像校正。 光谱采集完之后, 使用便携式糖度计(ATAGOPAL-2, 日本)测定样品TSS含量。
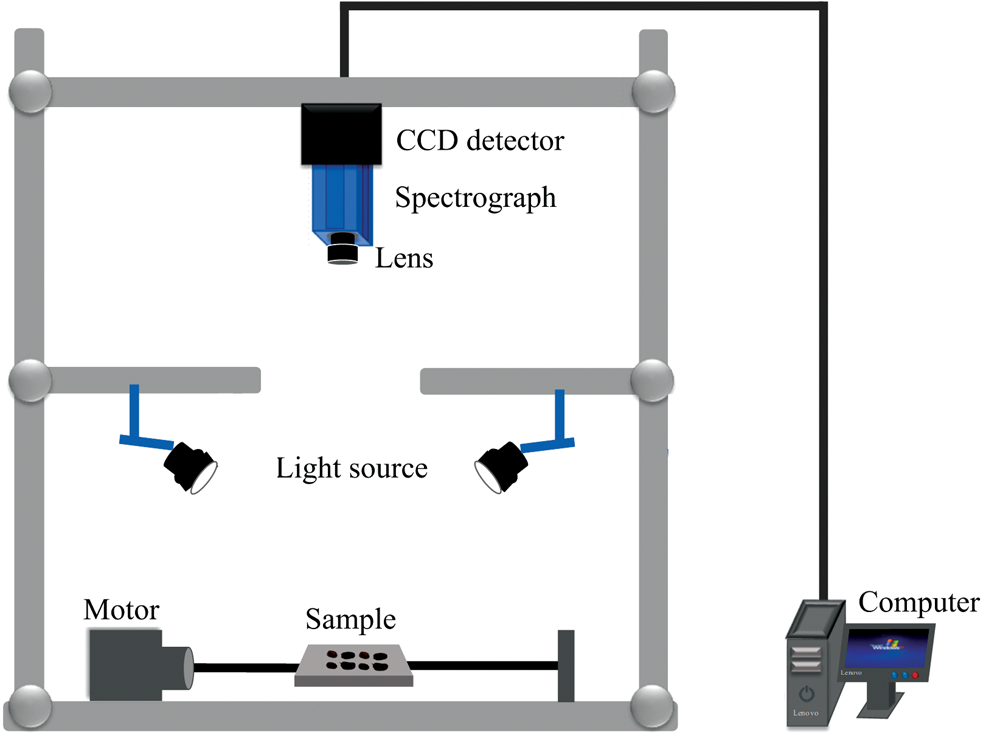 | 图2 高光谱成像系统示意图Fig.2 Diagram of hyperspectral imaging system |
1.3.1 图像校正与光谱提取
样品高光谱原始图像为强度信号, 必须使用同一条件下采集的参考白板和黑板进行校正, 图像校正公式为
其中, R为校正后的图像; IR为样品原始图像; ID为参考黑板图像, 是使用相机镜头盖子盖住镜头后获取的暗电流图像信息; IW为参考白板图像, 是反射率接近100%的聚四氟乙烯材料的图像。 后续所有数据处理分析均建立在图像校正的基础上。
校正后的图像还包含无用背景信息。 由于桑椹较小且表面不平整, 因此在没有背景信息的情况下客观准确地提取果实光谱对于建立定量预测模型非常重要。 软件ENVI 4.6(Research Systems Inc., Boulder, USA)被用于提取感兴趣区域(region of interest, ROI), 将ROIs数据平均处理后作为对应样本的代表性光谱。
1.3.2 光谱预处理
光谱数据的采集受到环境、 仪器等诸多因素影响, 为了消除基线漂移和背景干扰, 需要对光谱进行预处理。 分别采用了标准正态变换(standard normal variate, SNV)、 多元散射校正(multiplicative scatter correction, MSC)和Savitzky-Golay(SG)平滑三种光谱预处理方法, 对原始光谱进行单一的预处理校正。 SNV通过归一化来扣除光谱中的线性平移影响, MSC则对每条光谱的随机变异进行校正, SG平滑则可以消除光谱噪声。
1.3.3 预测模型
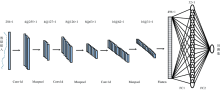
采用深度学习方法卷积神经网络(CNN)进行了桑椹TSS含量的快速无损检测。 与传统经典建模方法相比, CNN可以深度挖掘特征信息, 通过权值共享池化机制有效减少了参数量, 从而提升模型效果[13]。 CNN是一种前馈神经网络, 其基本结构包含卷积层、 池化层和全连接层。 CNN通过卷积层来提取特征, 之后在池化层对特征信息进行降维, 并通过全连接层整合分类。 优化的一维CNN预测模型结构如图3所示, 包含了3个卷积层、 3个池化层和2个全连接层。 卷积层采用2× 1且步长为1的卷积核, 池化层大小为2步、 长为2。 卷积层激活函数使用ReLU函数, 全连接层使用Sigmoid函数, Adam优化器; batch size设置为16, 学习率为0.000 1。
 | 图3 基于一维卷积神经网络(CNN)的TSS预测模型结构Fig.3 The framework of TSS prediction model based on 1D convolutional neural network (CNN) |
为验证CNN的预测性能, 建立了桑椹采后TSS含量的偏最小二乘(PLS)和最小二乘支持向量机(LS-SVM)预测模型进行比较。 PLS和LS-SVM是两种经典的机器学习方法, 可分别用于构建线性和非线性回归模型。 对于模型性能评价, 采用的参数主要包括决定系数(determination coefficient, R2)、 均方根误差(root mean square error, RMSE)、 剩余预测偏差(residual prediction deviation, RPD)和鲁棒性指标ABS(absolute difference between RMSEC and RMSEP)。
使用光谱平均处理以获取桑椹样本代表性光谱, 原始光谱和预处理后的不同类型样本光谱如图4所示。 近红外区域的吸收带通常反映不同化合物中分子键的振动, 这对于开发品质预测模型是相当重要的。 由图可见, 在970 nm处观察到吸收峰, 这是由水分子O— H第二伸缩泛音引起的[14]。 类似的化学键泛音可以在1 450 nm处观察到, 这可以归属于水分子O— H第一伸缩泛音。 但此处吸收较弱, 与其他物质吸收峰重叠。 桑椹水分含量高达85%以上, 被认为是多处水分子吸收峰的主要原因。 此外, 在1 190 nm处发现另一个吸收峰, 主要反映了碳水化合物C-H第二伸缩泛音[14]。 对于不同的桑椹品种和采后储藏温度条件, 可以观察到样本高度一致的光谱变化趋势, 仅通过谱线难以区分桑椹品种和储藏条件。
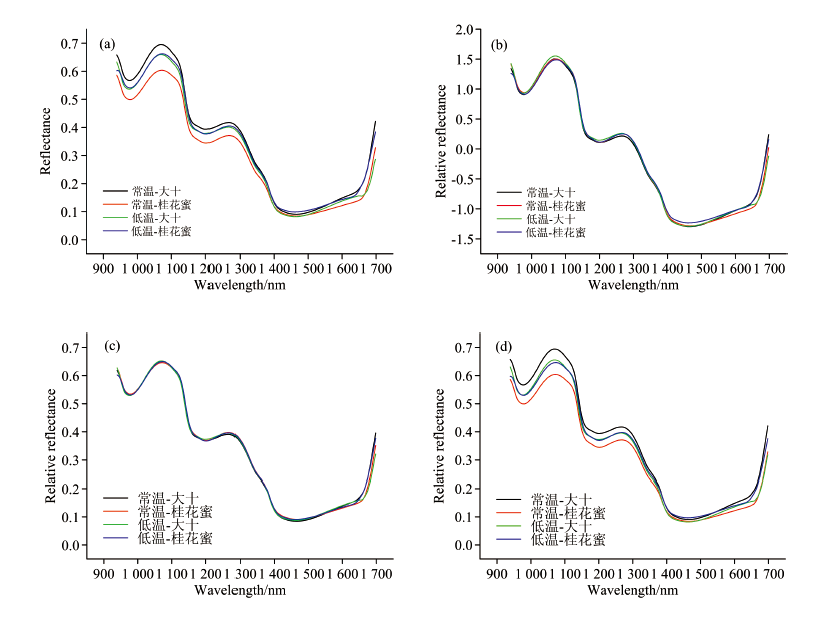 | 图4 不同预处理后桑椹样本的平均反射光谱 (a): 原始光谱; (b): SNV; (c): MSC; (d): SG平滑Fig.4 Mean reflectance spectra of the mulberry samples after different pre-processing (a): Raw; (b): SNV; (c): MSC; (d): SG smoothing |
经过不同的预处理后, 桑椹光谱保持了原有的趋势变化。 其中, SG[图4(d)]仅对光谱进行平滑处理, 可能消除了局部光谱噪声, 因而保留了不同处理带来的光谱上的微弱反射率差异。 而采用SNV[ 图4(b)]或MSC[图4(c)]的标准化处理之后, 不同类型样本的光谱差异被进一步缩小, 光谱谱线高度重合。
桑椹样本按照4∶ 1的比例被随机划分为校准集和预测集, 测定的样本集的TSS含量参考值如表1所示。 对于两个不同的储藏温度条件, 校准集样本均具有更广范围的TSS含量值, 大于预测集样本的TSS含量范围, 这对于建立准确稳健的预测模型是必不可少的。 同时各样本集TSS含量均值和标准差相近, 说明样本分集较为均匀, 有利于预测模型性能的提升。
| 表1 桑椹TSS含量参考值(单位: ° Brix) Table 1 Reference values of TSS content in mulberry fruits (unit: ° Brix) |
将不同预处理后的光谱数据以一维向量的形式输入CNN, 通过卷积和池化, 将提取的特征输入全连接神经网络进行学习, 最后输出实现回归预测, 分别得到桑椹采后常温和低温储藏的TSS含量预测模型, 结果见表2和表3。 由结果可以看出, 优化的CNN模型对桑椹采后TSS含量预测取得了优异的效果。
| 表2 基于CNN的常温储藏桑椹TSS含量预测结果 Table 2 Prediction results of TSS content in mulberry fruits stored at room temperature based on CNN |
| 表3 基于CNN的低温储藏桑椹TSS含量预测结果 Table 3 Prediction results of TSS content in mulberry fruits stored at low temperature based on CNN |
对于常温储藏样本, 利用原始光谱建立的CNN模型, 预测集决定系数
对于低温储藏样本的TSS含量预测, CNN模型同样获得了优异的结果。 仅使用原始光谱构建模型, 预测集RPD值达到3.682。 与对常温样本的预测类似, 经过对光谱进行预处理后, 模型效果均有不同程度的提升(SG-CNN模型精度略有下降), 而不同的预处理方法表现出模型性能提升度的差异。 最优模型为MSC-CNN, 预测决定系数
由于温度对化学成分光谱的影响, 根据不同的样品储存温度, 预测TSS含量的光谱模型得到的结果可能会有所不同。 总体来看, CNN模型对常温储藏样本的TSS含量预测效果更佳。 四个常温样本的CNN模型平均RPD值为4.987, 比四个低温样本的CNN模型平均RPD值(4.370)高14.12%; 最优模型对比, 常温样本预测RPD值比低温样本预测RPD值高6.96%。 温度会显著影响分子间和分子内的相互作用, 例如氢键, 从而导致光谱的温度变化敏感[12]。 此外, 桑椹表皮薄, 在经过低温储藏后易出现表皮破损, 外溢的营养物质可能带来额外的光谱噪声, 从而影响预测模型的精度[8]。
为进一步验证CNN模型的性能, 使用经典的传统机器学习方法PLS和LS-SVM构建了桑椹采后TSS含量的检测模型, 结果见表4。 由结果可以看出, PLS和LS-SVM模型对桑椹采后TSS含量的预测取得了良好的结果。 使用原始光谱建模, 4个模型的平均RPD值达到3.616, 预测误差RMSEP值为1.7 ° Brix。 全部16个预测模型, RPD值最低为2.655, 最高为4.423, 可以基本满足对TSS含量的快速检测。
| 表4 桑椹采后TSS含量的PLS和LS-SVM预测模型 Table 4 PLS and LS-SVM prediction models for TSS content in postharvest mulberry fruits |
与CNN模型相似, 不同的光谱预处理之后模型效果之间显示出差异。 但另一方面, SG平滑处理后, PLS和LS-SVM模型性能减弱, 其原因可能在于SG平滑将部分特征信息识别为噪声进行了过滤。 整体来看, PLS和LS-SVM对桑椹采后TSS预测效果有较大差异, LS-SVM模型优于PLS模型, 这与Zhao等[18]的研究结论一致, 其原因可能在于LS-SVM是非线性回归方法, 它可以将原始数据映射到高维空间以做出最优线性解。 对于不同的储藏温度, 常温样本预测模型平均RPD值为3.494, 略低于低温样本预测模型RPD值(3.515); RMSEP值为1.896 ° Brix, 则略高于低温样本预测模型RMSEP值(1.653 ° Brix), 可见温度对于PLS和LS-SVM模型精度没有显著影响。
通过对比分析, 常温储藏样本TSS预测最优模型为RAW-LS-SVM, 预测集决定系数
 | 图5 常温(a)和低温(b)储藏桑椹的TSS含量拟合结果Fig.5 Fitting results of TSS content in mulberry fruits stored at room temperature (a) and low temperature (b) |
利用高光谱成像技术对桑椹采后TSS含量进行了分析, 探究了近红外高光谱与桑椹TSS之间的相关性。 借助于校正后的高光谱图像提供的空间信息, 提取了桑椹的代表性光谱, 并经过SNV、 MSC和SG平滑预处理后用于优化CNN模型, 结果表明预处理在一定程度上可以提升模型效果。 对于常温和低温桑椹的TSS含量预测最优模型分别为SNV-CNN和MSC-CNN, RPD值分别达到5.828和5.449, 可见低温储藏降低了CNN模型的预测效果。 为验证CNN模型的性能, 进一步使用PLS和LS-SVM构建了预测模型, 结果显示非线性算法LS-SVM性能优于线性算法PLS。 此外, CNN模型在精度和稳定性上均优于LS-SVM模型, 结果表明高光谱成像结合深度学习可以实现桑椹采后不同储藏温度条件的TSS含量预测, 这为桑椹采后品质快速评价提供了依据和支撑。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|