
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于PLS-DA和LS-SVM的可见/短波近红外光谱鉴定港种四九、十月红和九月鲜菜心种子的可行性研究
[章海亮1  , 聂训
, 聂训1 , 廖少敏1 , 詹白勺1 , 罗微1 , 刘书玲3 , 刘雪梅2, * , 谢潮勇1, * ]
, 聂训, 谢潮勇]
|
|


作者简介: 章海亮, 1977年生, 华东交通大学电气与自动化工程学院教授 e-mail: hailiang.zhang@163.com
目前市面上菜心的品种复杂, 不同菜心种子的品质与发芽率不同, 但菜心种子单从外观上差别不大, 因此区分菜心种子的类别成为了一大难题。 为了实现菜心种子类别的快速区分, 探究了基于可见/短波近红外光谱分析菜心种子类别的可行性。 从南昌市种子交易场所购买了港种四九、 十月红和九月鲜三个品种的菜心种子, 从中挑选出品相较好且大小适中的子粒, 将每种菜心种子均匀分为30份, 按照2∶1划分为建模集和预测集, 所有样本共计90份。 通过近红外光谱仪获取采样间隔为1 nm的菜心种子的光谱反射率, 波长覆盖范围325~1 075 nm, 将原始光谱数据采用多元散射校正(MSC)、 卷积平滑(S-G)和标准正态变换(SNV)三种预处理方法进行预处理, 预处理后的光谱变量建立偏最小二乘回归(PLSR)模型, 确定了SNV是最佳预处理方法。 采用主成分分析(PCA)对菜心种子进行了聚类分析, 从前三个主成分因子(PCs)得分图可知三种菜心种子存在光谱特征差异。 将原始光谱变量、 前三个PCs(累计贡献97.15%)和基于随机蛙跳(RF)算法挑选的13个特征波长作为偏最小二乘判别(PLS-DA)和最小二乘支持向量机(LS-SVM)模型的输入变量, 从模型结果可知: 三种输入变量中, 采用RF筛选特征波长作为模型输入变量时, 模型预测效果最好, PCs建立的模型最差, 相比于PCA分析, 采用RF筛选出的特征波长更能够反映原始光谱信息。 比较不同模型预测效果, LS-SVM模型比PLS-DA模型得到的预测精度更好, 其中RF-LS-SVM模型是所有模型中最佳的预测模型, 建模集和预测集均为100%。 采用可见/短波近红外光谱研究菜心种子的类别可行, 并且能够获得很好地预测效果, 为菜心种子的快速区分提供了理论依据。
, NIE Xun, XIE Chao-yong
At present, the varieties of cabbage on the market are complex; the quality and germination rate of different cabbage seeds are different, but the appearance of cabbage seeds is not very different, so it has become a big problem to distinguish the types of cabbage seeds. This paper explores the feasibility of analyzing cabbage seed categories based on visible/short-wave near-infrared spectroscopy to achieve rapid differentiation of cabbage seed categories. The experiment purchased three varieties of cabbage seeds of Hong Kong species Sijiu, October red and September fresh from the Nanchang Seed Trading Place. The seeds with good appearance and moderate size were selected, and each kind of cabbage seed was evenly divided into three categories. 30 copies, divided into modeling and prediction sets according to 2∶1, totalling 90 copies of all samples. The near-infrared spectrometer was used to obtain the spectral reflectance of cabbage seeds with a sampling interval of 1 nm, and the wavelength coverage was 325~1 075 nm. The original spectral data were corrected by multivariate scattering (MSC), convolution smoothing (S-G) and standard normal transformation (SNV). )Three preprocessing methods were used for preprocessing. A partial least squares regression (PLSR) model was established for the spectral variables after preprocessing, and SNV was determined to be the best preprocessing method. In addition, principal component analysis (PCA) was used to conduct cluster analysis on cabbage seeds. The scores of the first three principal component factors (PCs) show that the three kinds of cabbage seeds have differences in spectral characteristics. Finally, the original spectral variables, the first three PCs (with a cumulative contribution of 97.15%) and 13 characteristic wavelengths selected based on the random frog (RF) algorithm were used as partial least squares discriminant (PLS-DA) and least squares support vector machines ( The input variables of the LS-SVM) model, from the model results, we can see that among the three input variables when the RF screening characteristic wavelength is used as the model input variable, the model prediction effect is the best, and the model established by PCs is the worst. The characteristic wavelengths screened by RF can better reflect the original spectral information. Judging from the prediction effects of different models, the LS-SVM model has better prediction accuracy than the PLS-DA model. The RF-LS-SVM model is the best prediction model among all models, and the modeling set and prediction set are both 100%. In conclusion, using visible/short-wave near-infrared spectroscopy to study the types of cabbage seeds is feasible. It can achieve a good prediction effect, which provides a theoretical basis for the rapid differentiation of cabbage seeds.
我国地大物博, 种植的蔬菜在品种与形态上各异。 目前市面上菜心的品种复杂, 不同菜心种子的品质与发芽率不同, 但菜心种子单从外观上差别不大, 因此区分菜心种子的类别成为一大难题。 仅依靠人为挑选难以保证正确分辨各种菜心种子, 而且分辨过程中存在区分时间长等缺点, 迫切需要一种快速、 高准确率的菜心种子鉴别方法。
近红外光谱作为一种快速、 无损、 便捷的检测方法, 在农作物掺假、 鉴别、 中药分析等方面得到了广泛的应用。 如茶籽油[1]、 大米[2]等掺假问题的研究, 以及西瓜[3]、 小麦粉[4]、 荞麦[5]、 茶叶[6]等分类研究和中药[7]的惨假问题研究。 目前已经有不少学者运用近红外光谱技术对玉米[8]种子、 番茄[9]种子等分类识别问题进行了一系列的研究, 并取得了较好结果, 但是对菜心种子的分类研究却几乎没有。
本工作采用可见/短波近红外光谱(325~1 075 nm)对菜心种子的类别进行研究分析, 获取了港种四九、 十月红和九月鲜三种品种的菜心种子, 共计90份。 采用偏最小二乘回归模型对多元散射校正(MSC)、 标准正态变换(SNV)和卷积平滑(S-G)的预处理效果进行了评估。 然后通过主成分分析(PCA)对样本数据进行聚类分析, 采用随机蛙跳算法(RF)进行特征波长筛选。 最后基于全波段、 PCA得到的主成分变量、 特征波长建立最小二乘支持向量机(LS-SVM)模型进行研究分析。
自江西省南昌市种子交易场所购买了港种四九、 十月红和九月鲜3个品种的菜心种子。 从购买的种子中挑选出品相较好且大小适中的子粒, 去除干瘪、 色泽度差和偏大或偏小的子粒。 将挑选好的种子采用3个大小、 容积相同的器皿盛放, 并依次放置光谱仪内进行光谱数据的采集, 每个品种挑选出30份, 共计90份。 光谱仪采用美国ASD公司的Hand Held2 (覆盖范围: 325~1 075 nm, 采样间隔: 1 nm, 探头视场角20° ), 采集时将每份样本置于探头视场角内, 均匀采集10次, 取平均值作为该组样本的光谱值。
为了尽可能获取光谱的有效信息, 提高数据信噪比, 去除基线漂移与冗余的数据干扰, 通常需要将采集到的光谱数据进行数据预处理。 标准正态变换(standard normal transformation, SNV)是一种对数(1/R)光谱的数学变换方法, 用于去除斜率变化和校正散射效应。 卷积平滑(Savitzky-Golay, S-G)算法一种通过移动窗口来对窗口内的数据采用一定程度的多项式进行拟合的时域低通滤波算法, 在过滤噪声的同时可以保持信号的形状和宽度不变化。 多元散射校正(multiplicative scatter correction, MSC)可以有效修正散射光和基线变化的倾角[10]。 本研究采用上述三种方法进行数据预处理。
主成分分析(principal component analysis, PCA)是一种无监督的数据描述与降维技术, 主要应用于光谱中的聚类分析。 通过PCA可以在一定维度空间中显示出可视化的数据趋势, 观察已知样本的聚类趋势[11]。
采用随机蛙跳算法(random frog, RF)算法进行特征波长筛选。 RF[12]借鉴了可逆跳跃马尔可夫链蒙特卡罗(RJMCMC)方法的框架, 通过计算模型中变量被选定的概率, 选取RMSECV最小时被选的波长个数作为最终挑选的特征波长。 对于所计算出的波长概率, 概率越大, 变量越重要。
在本研究中, 港种四九、 十月红和九月鲜菜心种子将通过偏最小二乘判别分析(partial least squares discriminant analysis, PLS-DA)和最小二乘支持向量机(least squares-support vector machine, LS-SVM)模型进行分类, 因此属于一个多分类问题。 PLS是光谱建模中最为常见的校正模型, 可以有效解决光谱与待测理化值之间的线性关系, PLS-DA是基于PLS的有监督的模式识别方法, 将光谱数据与分类变量进行线性回归[10]。 LS-SVM是回归计算与模式识别中一种强大的机器学习方法, 可以有效处理多元校准问题中的线性和非线性问题[13]。
为了获得更好的模型性能, 采用两步网格法优化了LS-SVM中一些参数。 这些参数包括: (1)正则化参数c, 它决定了最小化训练误差和最小化模型复杂性之间的权衡。 (2)核函数的参数σ , 它隐式地定义了从输入空间到某些高维特征空间的非线性映射(本文采用径向基核函数: RBF核函数)。 常用的核函数包括线性核函数、 多项式核函数、 径向基核函数等, LS-SVM采用的是径向基核函数, 表达式为
式(1)中: x、 xk为某个输入空间的特征向量、 σ 为一个自由参数。
模型的评价指标包括决定系数(coefficient of determination, R2)、 均方根误差(root mean square error, RMSE)和准确度(accuracy)。 R2和RMSE用来评价预处理的结果, 通常RMSE越小, R2越接近真值1, 模型性能越好、 精度越高。 R2和RMSE按照建模集和预测集可划分为建模决定系数(coefficient of determination of calibration,
将波长作为横坐标, 每个波长点对应的反射率作为纵坐标, 建立菜心种子的光谱反射曲线如图1(a)所示。 整体上反射率曲线呈现上升趋势, 所有样本的曲线均较为相似, 单从光谱特征中无法区分不同类别菜心种子的差异。 将每个品种菜心种子的光谱数据计算其平均值, 建立平均光谱坐标轴如图1(b)所示。 不同品种的菜心种子的光谱曲线相互可分, 说明不同类型的品种其光谱反射率存在一定差异, 但仅从光谱曲线进行区分不具有说服力, 还需要建立定量分析模型对菜心种子的品种进行分析。
 | 图1 菜心种子 (a): 原始光谱; (b): 平均光谱; (c): SNV预处理光谱Fig.1 Cabbage seeds (a): Raw spectra; (b): Average spectra; (c): Pretreatment spectraby SNV |
原始光谱曲线的首端存在较大噪声干扰, 因此去除325~349 nm的噪声波段, 采用350~1 075 nm波段用于研究分析。 图1(c)是SNV预处理后的光谱图像。 将样本按照2∶ 1(60∶ 30)划分为建模集(Calibration)和预测集(Prediction)作为PLS模型的输入矩阵, 三种预处理方法的建模结果如表1所示。 经过预处理后的光谱数据建模决定系数有所提高, 其中SNV预处理得到了最佳的模型预测效果。
| 表1 不同预处理方法PLSR建模结果 Table 1 The Prediction results by PLSR models for different pretreatment methods |
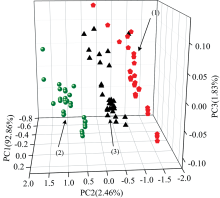
PCA产生的主成分因子(principal components, PCs)可以极大程度地解析原始变量中的重要信息, 由于新产生的变量维度小, 将PCs作为模型输入变量可以大大缩短模型运行时间, 优化模型效率。 PCs的得分图还可以对原始样本的信息进行聚类分析。 表2是菜心种子进行PCA得到的前三个PCs的贡献度。 由表2可以看出, 前三个PCs累计贡献97.15%, 其中PC1: 92.86%、 PC2: 2.46%、 PC3: 1.83%。 前三个PCs可以较大程度解析原始光谱信息。
| 表2 前三个主成分累计贡献度 Table 2 The cumulative contribution of the first three PCs |
通过前三个PCs的得分图分析菜心种子的类别, 将PC1和PC2作为X轴和Y轴, PC3作为Z轴, 建立如图2所示的得分图。 图中“ 1” , “ 2” , “ 3” 分别表示港种四九、 十月红和九月鲜品种的菜心种子。 由图2可以看出: 三种菜心种子清晰可分且存在聚类情况, 十月红位于最左侧, 九月鲜和港种四九分别位于中间和最右侧, 其中十月红相对九月鲜和港种四九的聚合度最优。 由得分图可以分析出三种菜心种子所采集的光谱存在一定的差异。
 | 图2 前三个主成分得分图Fig.2 Scoreplot of the first three PCs |
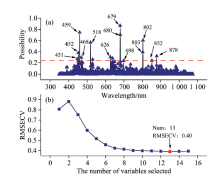
采用RF对原始波段进行特征波长筛选, RF筛选结果如图3所示。 图3(a)和(b)分别是对应波长点被选择的概率和RMSECV的值随变量个数增加的情况。 根据图3(b), 当变量为13个时, RMSECV取得最小值0.40。 图3(a)中红线以上表示被选概率大于0.225时则被挑选中, 在图中标记处相应波长点分别为451、 452、 459、 468、 518、 626、 679、 680、 698、 802、 803、 852和878 nm, 即RF共挑选出了13个特征波长点。
 | 图3 RF筛选结果 (a): 波长点选择概率; (b): RMSECV变化Fig.3 RF filters the results (a): Probabity of wavelenth point being selected; (b): Value of RMSECV |
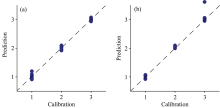
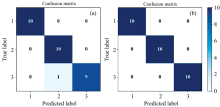
将PCA得到的前三个主成分因子和RF得到的13个特征波长变量作为PLS-DA和LS-SVM模型的输入变量, 得到的模型结果如表3所示。 由表3可知: LS-SVM模型整体预测效果比PLS-DA好, 分析认为由于LS-SVM模型不仅可以处理光谱数据与待测值之间的线性关系, 还可以有效解决两者之间的非线性关系, 这是PLS-DA模型无法处理的问题。 原光谱变量PLS-DA的建模集和预测集准确率为93.3%和90%, LS-SVM模型的建模集和预测集准确率均为100%, 但PCs-PLS-DA和PCs-LS-SVM模型的建模集和预测集准确率均有不同程度的下降, PLS-DA的建模集和预测集准确率为90%和86.7%, LS-SVM模型的建模集和预测集准确率为96.7%和93.3%。 RF挑选的特征波长作为输入时其模型效果更好, PLS-DA的建模集和预测集准确率增加到100%和96.7%, LS-SVM模型的建模集和预测集准确率均增加到100%。 RF不仅优化了模型运行时间, 还使得模型预测效果更为准确, 图4(a, b)分别是RF-PLS-DA与RF-LS-SVM模型的预测效果, 图5(a, b)分别是RF-PLS-DA与RF-LS-SVM模型的混淆矩阵图, 从图中也可以观察到, 采用RF-LS-SVM模型能够对30个样品全部分类正确, 准确率能达到100%, 而采用RF-PLS-DA模型对于第三种(九月鲜菜心种子)有一个未能识别正确, 其准确率为96.7%, 故RF-LS-SVM具有更好的模型预测结果。 采用RF-LS-SVM模型对菜心种子进行类别分析是可行的, 且能达到较好的预测效果。
| 表3 模型预测结果 Table 3 Model predictions |
 | 图4 (a)RF-PLS-DA和(b)RF-LS-SVM预测结果Fig.4 The predictions of (a) RF-PLS-DA and (b) RF-LS-SVM models |
 | 图5 (a)RF-PLS-DA和(b)RF-LS-SVM混淆矩阵Fig.5 (a) RF-PLS-DA and (b) RF-LS-SVM confusion matrix |
采用了SNV、 S-G和MSC三种预处理方法对菜心的原始光谱进行处理, 通过PLSR模型确定了SNV为最佳预处理方法。 通过PCA得到的得分图表明不同菜心种子存在聚类效果, 并将原始变量、 主成分因子(PCs)和RF筛选的特征波长作为PLS-DA和LS-SVM模型的输入变量, 分析可见/短波近红外光谱对港种四九、 十月红和九月鲜三种菜心种子进行鉴定的可行性。 从模型输入角度, RF筛选特征波长后, 模型预测效果最好, 在进行 RF特征波长筛选后, 筛选掉了一些光谱中无用信息, 降低了光谱数据的冗余度, 故模型预测结果变好。 而PCs建立的模型比原始变量所建立的模型预测结果更差, 分析认为PCs虽然降低了数据冗余度, 但也筛选掉了光谱数据中有用的信息, 故模型的预测结果变差。 整体可表示为: RF> Raw> PCs。 从不同模型预测效果比较, LS-SVM模型效果更好, RF-LS-SVM是所有模型中最佳的预测模型, 其建模集和预测集均为100%。 采用可见/短波近红外光谱研究菜心种子的类别可行, 并能达到很好地预测效果, 为菜心种子的快速区分提供了理论依据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|