




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于全透射可见-近红外光谱的西瓜糖度在线检测研究
[王贺功1, 2  , 黄文倩
, 黄文倩2 , 蔡仲磊2 , 严忠伟2 , 黎胜2 , 李江波2, * ]
, 黄文倩]
|
|


作者简介: 王贺功, 1998年生, 新疆农业大学机电工程学院硕士研究生 e-mail: whg202300@163.com
糖度是评价西瓜品质的重要指标之一, 影响着西瓜的受欢迎程度和销售价格。 但体积大、 皮厚的自然生物特征为西瓜糖度的快速、 无损评估带来了挑战。 为探索西瓜糖度快速无损检测, 选择230个西瓜作为试验样本, 使用自行研制的全透射可见-近红外光谱系统在线采集西瓜光谱数据, 在线检测过程中保持光谱连续检测点在西瓜的赤道部位, 并分别测量西瓜整果糖度和中心糖度作为理化糖度参考值。 首先对样本在线检测过程中产生的多条光谱数据进行均值化处理, 并选取波长范围690~1 100 nm的光谱数据, 使用蒙特卡洛方法剔除其中的异常样本, 使用多种预处理方法(SNV、 SG平滑等)对光谱数据优化, 并采用SPXY算法划分样本校正集和预测集以减小因西瓜内部糖度分布差异造成的影响; 基于优化的光谱数据构建了线性PLSR模型和非线性LS-SVM模型预测西瓜中心糖度和整果糖度。 结果表明, 基于SNV和SG组合法预处理光谱构建的LS-SVM模型预测西瓜整果糖度效果最好, 其校正集相关系数 RC=0.92, 建模均方根误差RMSEC=0.37°Brix; 预测集相关系数 RP=0.88, 预测均方根误差RMSEP=0.40°Brix。 进一步使用特征波段挑选算法(CARS、 UVE、 SPA等)对光谱数据优化, 结果显示构建的模型效果更好, 其中使用CARS和UVE组合算法选取的特征波长构建LS-SVM模型预测西瓜整果糖度时效果最好, 其校正集相关系数 RC=0.94, 校正均方根误差RMSEC=0.31°Brix; 预测集相关系数 RP=0.91, 预测均方根误差RMSEP=0.37°Brix, 且建模变量从1524个特征变量缩减到39个特征变量。 该研究为实际生产中西瓜糖度快速无损检测应用提供了参考。
Sugar content is a crucial parameter for assessing watermelon quality, influencing watermelon's marketability and commercial value. However, the natural biological characteristics of large volume and thick skin pose challenges for rapid and non-destructive evaluation of the sugar content of watermelon. In this study, 230 watermelons were selected for investigation. A custom-designed full-transmission visible-near-infrared detection system was developed. Spectral data of all samples were acquired online. Each sample spectral data comes from the equatorial part of the watermelon. The overall watermelon sugar content and the central sugar content were measured separately to provide reference values for the assessment of sugar content. In the data processing phase, the spectral data of each sample was averaged, and spectral data in the 690~1 100 nm was selected. The Monte Carlo method was implemented to remove abnormal samples, and preprocessing, such as Standard Normal Variate correction and Savitzky-Golay smoothing, was applied to optimize the spectral data. The SPXY algorithm was used to divide the calibration and prediction sets. Utilizing the optimized spectral data, linear Partial Least Squares Regression (PLSR) and non-linear Least Squares Support Vector Machine (LS-SVM) models were developed to forecast each sample's center sugar content and overall sugar content. The results revealed that, Combined with standard normal variate correction and Savitzky-golay smoothing, the LS-SVM model yielded the most favorable results in predicting the overall watermelon sugar content. The calibration correlation coefficient ( RC) of 0.92 and root mean square error of calibration (RMSEC) of 0.37°Brix were obtained for the calibration set. Correspondingly, the prediction correlation coefficient ( RP) of 0.88 and root mean square error of prediction (RMSEP) of 0.40°Brix were obtained for the prediction set. Furthermore, feature wavelength selection algorithms (e.g., Competitive Adaptive Reweighted Sampling, Uninformative Variable Elimination, Successive Projections Algorithm) were used for variable selection. Study found that the LS-SVM model combined with Competitive Adaptive Reweighted Sampling and Uninformative Variable Elimination methods has the optimal performance in predicting the overall watermelon sugar content with a calibration correlation coefficient ( RC) of 0.94 and a calibration root mean square error of 0.31°Brix. Correspondingly, the prediction correlation coefficient ( RP) and the root mean square error of prediction (RMSEP) were 0.91 and 0.37 °Brix, respectively. Additionally, the number of variables was significantly reduced from 1 524 to 39. This study provides a reference for the practical application of rapid and non-destructive testing of sugar content in watermelon.
我国西瓜产量全球最高, 据联合国粮食及农业组织(FAO)统计, 2019年我国西瓜产量为63 241万吨, 占全球西瓜总产量的60.61%。 随着西瓜产量的不断增加和人们生活水平的不断提高, 消费者在选购西瓜时对其内部品质的要求越来越严格。 因此, 高质量的产品和品牌是我国西瓜产业在国际竞争中的核心竞争力[1]。 糖度是决定西瓜内部品质的重要因素之一, 同时也可以表征西瓜的采收时间和成熟度[2]。 目前对西瓜内部糖度的评估大多采用有损伤的测定方法, 如蒽酮比色法或折光计测量法, 存在制样烦琐、 分析时间长、 检测成本高等问题, 无法实现快速规模化检测应用[3]。 水果内部品质无损检测的方法主要有光学[4, 5, 6]、 声学[7]和电学检测技术[8], 其中可见-近红外光谱光学检测技术具有成本低, 检测速度快等优点, 非常适合用于水果内部品质的在线检测[9]。 对于西瓜这类大尺寸厚皮水果, 由于光源穿透能力有限, 更多采用的光谱检测模式是漫反射或者漫透射[10, 11]。 这两种方式并不能非常有效地获取西瓜内部果肉信息, 尤其是深层果肉的糖度信息, 为此, 本研究开展了基于全透射可见-近红外光谱技术的西瓜糖度在线检测。
选取品种“ 京美2K” 西瓜为研究对象, 样本于2022年9月购自北京大兴区庞各庄镇。 此西瓜品种属于小型西瓜, 呈椭圆形, 赤道直径约90~110 mm。 共使用西瓜样本230个, 实验前, 剪掉瓜梗, 将西瓜表面用纱布擦拭干净, 然后将样本置于实验室环境下24 h, 以减少温度对光谱数据的影响。
样本如图1所示。
 | 图1 西瓜试验样本Fig.1 The watermelon samples |
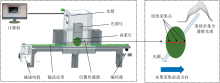
采用的可见-近红外全透射光谱在线采集系统如图2所示。 该系统主要包括减速电机、 输送皮带、 位置传感器、 编码器、 光谱仪(光谱范围562~1 110 nm, 光谱间隔0.3 nm)、 卤素灯(FUJI, JCR, 150 W, 15 V)、 光箱和计算机等组成。 数据采集时, 光谱仪积分时间设置为10 ms, 西瓜样本(果梗和花萼轴垂直于皮带)以0.5 m· s-1的恒定速度通过光箱并由软件采集和记录样本的光谱信息[12], 由于采用了短积分, 西瓜在通过光谱仪时, 系统可以测得单个样本赤道区域不同位点连续多条全透射光谱曲线, 多条曲线取均值作为最终所测样本的光谱曲线。
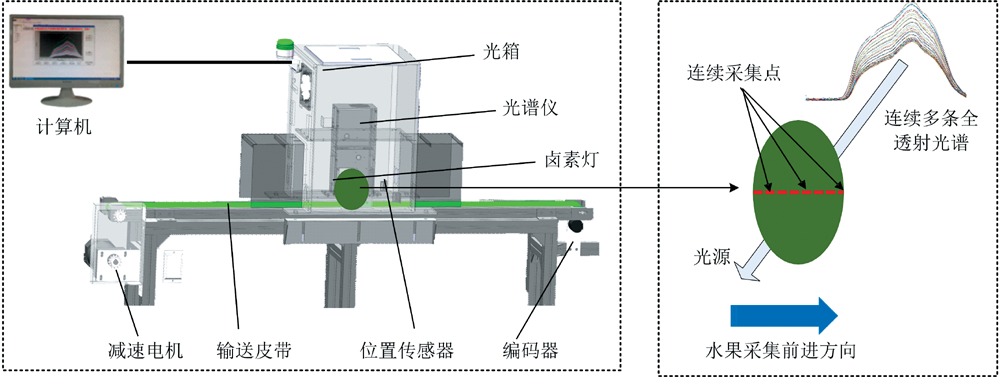 | 图2 西瓜光谱在线检测系统Fig.2 Online detection system used for collection of watermelon spectral data |
西瓜样本光谱数据采集后, 将西瓜沿纵向对称切开, 从中心位置取尺寸约为 20 mm× 20 mm× 20 mm的果肉块压汁, 然后取少许果汁滴在PR-101a数字折光仪(Atago Co., Tokyo, Japan)的测量窗口测量3次, 求平均值作为每个西瓜样品的中心糖度真值; 将所测样本剩余果肉用榨汁机榨汁, 混合均匀后取少许滴在数字折光仪上, 以同样的方法测量其糖度值作为西瓜整果糖度值。 为保证测量精度, 在每次测量后, 用清水清洗数字折光仪, 然后用纸巾将测试窗口擦拭干净。
相对其他水果, 西瓜尺寸体积大, 其糖度分布差异明显, 糖度理化值的测定易出现误差。 为提高糖度预测模型的精度, 借助蒙特卡洛算法剔除异常样本[13, 14]。 原始光谱数据存在散射和随机噪声, 标准正态变量变换(SNV)可以用来校正因散射而引起的光谱误差, 卷积平滑(SG)能够减弱光谱中的随机噪声[15], 因此, 采用SNV和SG平滑以及SNV与SG平滑组合的方法对原始光谱数据进行预处理以改善原始光谱质量。 为保证样本可以最大程度表征西瓜糖度分布, 增加样本的差异性和代表性, 采用SPXY(sample set partitioning based on joint xy distance)算法划分模型校正集和预测集[16]。
竞争性自适应重加权采样算法(competitive adapative reweighted sampling, CARS)、 连续投影算法(successive projections algorithm, SPA)和无信息变量消除(uninformative variables elimination, UVE)是挑选可见-近红外光谱特征波长常用的三种算法[17]。 CARS是一种蒙特卡洛采样与PLS模型回归系数结合的特征变量选择方法[18], UVE是一种基于分析PLS回归系数b以消除那些不提供有用信息的特征变量的算法[19], SPA是一种使矢量空间共线性最小化的前向变量选择算法。 本研究采用的光谱波长间隔为0.3 nm, 存在很多无信息变量和冗余变量, 这三种算法在去除光谱无信息变量和冗余变量, 简化光谱数据, 降低光谱维度, 消除噪声方面具有很好的效果。
基于光谱数据和西瓜两种糖度数据分别构建用于整果糖度和中心糖度预测的偏最小二乘回归(partial least squares regression, PLSR)模型[20]和最小二乘支持向量机(least squares support vector machine, LS-SVM)模型[21]。 PLSR是一种集主成分分析、 相关分析和多元线性回归优点的线性回归模型, 对西瓜光谱数据和糖度数据的共线性问题有较好的处理效果。 LS-SVM是一种非线性模型, 具有运算过程简单、 收敛速度快及计算精度高等优点, 选取常用的径向基函数(radial basis function, RBF)作为LS-SVM模型的核函数, 可以有效解决可见-近红外光谱数据与糖度理化值之间的线性和非线性问题。 模型评价指标使用校正相关系数(correlation coefficient of calibration, RC)和校正均方根误差(root mean squared error of calibration, RMSEC), 以及预测相关系数(correlation coefficient of prediction, RP)和预测均方根误差(root mean squared error of prediction, RMSEP)。 相关系数越接近1, 代表西瓜光谱数据对糖度的解释效果越好, 均方根误差越小, 代表模型预测西瓜糖度数据与真实值差距越小, 其构建的模型效果也就越好[22], RC和RP以及RMSEC和RMSEP越接近, 表示所构建的模型越稳定。 其评估参数计算如式(1)和式(2)
式(1)和式(2)中: ypi和ymi分别表示样本集中第i个样本的预测值和实测值, ymean表示样本集中实测值的平均值, n表示样本集中样本的个数。
采用蒙特卡洛算法剔除西瓜异常样本, 经过5 000次的循环随机采样计算后, 样本预测残差均值与标准差的分布如图3所示。 保证剔除所有异常样本的同时尽可能保留足够多的样本数, 因此设置均值和标准差参数平均值的3.7倍作为界限, 大于界限值的为异常样本。 图中阴影方框表示正常样本所在区间范围, 可以看出, 中心糖度编号为129、 63、 88和196的4个样本可作为异常样本被剔除。 整果糖度编号为129、 88、 63、 106和196的5个样本可作为异常样本被剔除。
 | 图3 预测残差的均值和标准差分布图 (a): 中心糖度; (b): 整果糖度Fig.3 Mean value and standard deviation (STD) of prediction residual (a): Sugar content in center; (b): Sugar content of whole fruit |
图4所示为挑选后所有样本的原始光谱曲线[图4(a)]和预处理后的光谱曲线[图4(b)]。 原始光谱曲线波长范围为562~1 110 nm。 从图4(a)中可以看出, 由于光谱探测器性能限制, 在690 nm波长之前和1 100 nm波长之后的光谱曲线透射强度值低, 不适合使用, 因此选取波长范围690~1 100 nm的光谱数据作为目标光谱数据, 选取的波长范围一共包含了1 524个波段。 其次, 从原始光谱曲线中也可以看出, 光谱存在严重散射和随机噪声, 因此原始光谱需要进行预处理。 图4(b)所示为经过SNV和SG平滑预处理后的光谱曲线。 可以看出, 各西瓜样本的光谱曲线趋势一致, 经预处理后的光谱数据散射特征得到了校正, 光谱曲线更平滑。
 | 图4 西瓜样本光谱曲线 (a): 原始光谱曲线; (b): 预处理后的光谱曲线Fig.4 Spectral curves of typical watermelon samples (a): Original spectral curves; (b): Preprocessed spectral curves |
西瓜内部含有许多由C— H, N— H和H— O等官能团组合成的化合物, 在光谱曲线中780~980 nm波段区域出现一些典型的波峰和波谷, 波长920 nm附近的波峰可能是因为H— O官能团伸缩振动三级倍频导致[23], 波长980 nm附近的波峰对应于水分有关的H— O伸缩振动的二级倍频。
使用SPXY算法以3∶ 1划分西瓜样本的校正集和预测集, 分布情况如表1。 对于中心糖度, 样本校正集包含169个样本, 测试集包含57个样本, 标准偏差均为1.0° Brix; 对于整果糖度, 样本划分为169个校正集和56个测试集, 标准偏差均为0.9° Brix。 从统计数据中可以看出, 无论是中心糖度还是整果糖度, 校正集糖度范围完全覆盖了预测集, 并且校正集和预测集的均值和标准偏差接近, 这些特征有助于构建一个稳健的预测模型。
| 表1 西瓜样本数据集划分 Table 1 Watermelon sugar data set division |
表2所示为全光谱PLSR和LS-SVM模型对西瓜整果糖度和中心糖度的预测结果。 其中, 选择PLSR模型校正均方根误差RMSEP最小值的主因子数作为最佳主因子数LVs, LS-SVM模型的正则化参数γ 影响模型的拟合精度和泛化能力, 核函数宽度值σ 直接决定了模型的计算量与执行效率[24]。 从表中可以看出, 无论对于整果糖度还是中心糖度, 基于不同光谱预处理数据所构建的PLSR模型和LS-SVM模型对西瓜糖度预测均存在较大的差异。 其中原始光谱所构建的模型预测性能最差, RC(0.99)和RP(0.80)以及RMSEC(0.15° Brix)和RMSEP(0.51° Brix)之间的差异较大, 表明模型存在过拟合且预测性能不稳定。 校正集在使用SNV预处理后, 模型依然过拟合, 但趋势减弱, 针对校正集和预测集, PLSR和LS-SVM模型相关系数和均方根误差的差值缩小。 进一步比较光谱经过SG平滑预处理后所建模型的预测结果, 两类模型各自的RC和RP值以及RMSEC和RMSEP之间的差异明显缩小, 表明模型稳定性较好, 过拟合情况消失。 这些结果表明, 原始光谱数据存在一定的光谱散射且光谱中随机噪声信号明显(注: 这些特征从原始光谱图中也可以获知)。 这些不利的特征可能是由于在线光谱采集系统在采集西瓜光谱数据时西瓜的快速运动或者系统存在一定的机械振动所引起的。 多种预处理方法中, SNV+SG平滑组合预处理方法获得了最好的建模预测结果。
| 表2 全光谱PLSR和LS-SVM模型对西瓜整果糖度和中心糖度预测结果 Table 2 Prediction results of whole fruit sugar content and sugar content in center of watermelon using full spectrum PLSR and LS-SVM models |
对比PLSR和LS-SVM两类模型, 无论采用哪种光谱预处理方法建模, 所构建的整果糖度预测模型和中心糖度预测模型效果比较, LS-SVM模型均略优于PLSR模型, 这表明西瓜透射光谱数据与糖度之间可能存在稍许非线性因素, 但这种因素非常不明显, 甚至可以忽略。 在对整果糖度预测中, SNV+SG-PLSR模型的RP和RMSEP分别为0.84和0.45° Brix, SNV+SG-LS-SVM模型的RP和RMSEP分别为0.88和0.40° Brix; 对于中心糖度, SNV+SG-PLSR模型的RP和RMSEP分别为0.85和0.52° Brix, SNV+SG-LS-SVM模型的RP和RMSEP分别为0.89和0.46° Brix。 PLSR和LS-SVM两类模型对整果糖度的预测精度均略高于中心糖度, 这主要是因为西瓜尺寸大, 各个部位的糖度分布不均匀, 越靠近西瓜中心的糖度越高, 而分布在瓜皮边缘的西瓜果肉糖度偏低。 本研究基于全透射光谱模式在线采集西瓜信息, 不仅可以采集到西瓜最深处的果肉信息, 也可以采集到靠近果皮处的果肉信息, 所获取的光谱数据会更好的反映西瓜整体内部品质信息, 因此构建模型预测整果糖度比预测中心糖度的效果更好。 但不管是整果糖度的预测还是中心糖度的预测, 两类模型均获得了较高的精度, 鲁棒性也较好。
基于表2可知, SNV+SG-PLSR和SNV+SG-LS-SVM模型在评估整果糖度和中心糖度中具有最好的性能。 因此, SNV+SG预处理后的光谱数据作为输入采用CARS、 SPA、 UVE以及他们的组合即CARS+SPA、 CARS+UVE、 UVE+SPA进行变量选择, 提取的特征变量用来构建糖度预测模型。 表3所示为所有特征变量模型对西瓜整果糖度和中心糖度定量预测结果。
| 表3 特征变量模型对整果糖度和中心糖度定量预测结果 Table 3 Quantitative prediction results of whole fruit sugar content and sugar content in center using characteristic variable models |
从表3中可以看出, 对于整果糖度, 所有模型的RMSEP值范围为0.37~0.43° Brix; 对于中心糖度, 所有模型的RMSEP值范围为0.41~0.55° Brix, 具有较高的在线预测精度, 表明优选的变量使模型具有了良好的定量评估性能, 所有特征变量模型都可以实现西瓜整果糖度和中心糖度的有效预测。 但从该结果看, 构建的模型更能准确地评估整果糖度, 这一点与表2中显示的全光谱模型预测结果一致。 对比表2和表3也可以看出, 所有特征变量模型预测精度优于同类型全波长模型, 这也说明变量选择在模型优化中的重要意义。 对比所有变量选择方法, 对于整果糖度预测, 亦或是对于中心糖度预测, 所有模型RMSEP值并没有存在显著的差异, 但参与模型构建的变量数差异较大, 这与变量选择方法本身有关。 在所有的单变量选择方法中, UVE优选的变量数最多, SPA优选的变量数最少, 这是因为UVE方法主要用于剔除在原始变量中无信息的变量, 对那些有信息的共线性变量会保留; 而SPA方法是对共线性的冗余变量进行压缩, 在变量选择的过程中剔除了几乎所有的共线性变量以选择极少数的变量; CARS算法提取的变量数据介于两者之间。 组合变量选择方法在不影响预测精度的情况下, 对参与建模的变量数有一定的压缩作用(整果糖度预测CARS+UVE除外)。 在同时考虑预测精度和参与建模变量数的情况下, CARS+UVE组合变量选择方法被确定为最优的变量选择方法。 对于整果糖度, 39个特征变量被选择, 对于中心糖度, 15个特征变量被选择。 对于整果糖度预测, 尽管UVE+SPA组合算法和单独SPA变量选择算法提取了非常少的变量数(分别为6个变量和5个变量), 并且基于所提取变量数构建的模型其RMSEP值与基于CARS+UVE提取的39个变量构建模型的RMSEP值类似, 但应该注意到, 基于UVE+SPA和SPA提取的变量所构建的模型其RMSEC和RMSEP值在某些模型中相差较大, 这样的模型在实际工作中可能存在稳定性不足的缺陷。 校正集经过CARS+UVE变量最优算法选取的预测整果糖和中心糖的39个变量和15个变量在全光谱曲线中的分布如图5所示。
 | 图5 CARS+UVE算法选择的特征波长Fig.5 Characteristic wavelengths selected by CARS+UVE algorithm |
图5显示, 针对两种糖度, 所选择的特征波长在全波长范围内都有分布且主要集中在780 nm之后, 表明近红外区域的光谱数据对西瓜糖度预测更加有效。 图6所示为基于CARS+UVE算法选择的特征变量构建的PLSR模型和LS-SVM模型对两种糖度预测的散点图。 它以良好的线性相关性清楚地显示了预测值和测量值的分布。 与一些典型研究比较, 基于反射模式, Elena Tamburini等[25]对西瓜总可溶性固形物(total soluble solid, TSS)含量预测建模结果为RMSEP=1.4° Brix; 基于漫透射模式, Qi等[26]对西瓜可溶性固形物(soluble solids content, SSC)含量预测建模结果为RMSEP=0.7° Brix。 本研究采用的全透射光谱检测模式明显优于这两种模式获得的检测结果。
 | 图6 CARS+UVE-PLSR和CARS+UVE-LS-SVM模型对整果糖和中心糖预测散点图 (a): LS-SVM-整果糖; (b): LS-SVM-中心糖; (c): PLSR-整果糖; (d): PLSR-中心糖Fig.6 Scatter plots for predicting whole fructose and sugar content in center usingCARS+UVE-PLSR and CARS+UVE-LS-SVM models (a): LS-SVM sugar content of whole fruit; (b): LS-SVM sugar content in fruit; (c): PLSR sugar content of whole fruit; (d): PLSR sugar content in center |
实现了基于全透射可见-近红外光谱对西瓜糖度的准确在线预测, 构建并优化了用于西瓜整果糖度和中心糖度预测的PLSR模型和LS-SVM模型。 研究表明, SNV+SG光谱预处理方法能够有效改善光谱质量以降低模型的过拟合; CARS+UVE组合算法是一种有效的西瓜糖度预测透射光谱优化工具, 针对整果糖度和中心糖度, 分别提取了39个和15个特征波长, 基于全光谱2.6%和1.0%的信息构建的PLSR和LS-SVM模型对整果糖度和中心糖度预测的RMSEP值均低于0.5° Brix, 展现出良好的预测性能。 与对中心糖度预测相比, 两类模型对整果糖度的预测精度更高, 且无论对于哪一类糖度预测, 非线性LS-SVM模型具有略优的性能。 研究表明, 可见-近红外全透射光谱技术结合合适的光谱预处理和变量优化算法以及建模理论可以实现西瓜整果糖度和中心糖度的快速无损检测, 这为实现西瓜产后快速分级处理提供了理论支撑。 为降低西瓜内部品质检测成本, 可以尝试开发基于全透射的可见-近红外光谱检测技术, 但必须研制灵敏度更高的光谱获取传感系统以实时获取高性噪比的全透射光谱数据, 且需加强对西瓜各个品种适用范围更广的模型的研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|