




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种融合叶绿素荧光技术与可见-近红外光谱的番茄幼苗热胁迫无损检测方法
[魏子朝1, 2  , 卢苗
, 卢苗1, 2 , 雷文晔1, 2 , 王浩宇1, 2 , 魏子渊1, 2 , 高攀1, 2 , 王东1, 2 , 陈煦1, 2, * , 胡瑾1, 2, * ]
, 卢苗, 胡瑾]
|
|


作者简介: 魏子朝, 1998年生, 西北农林科技大学机械与电子工程学院及农业农村部农业物联网重点实验室硕士研究生e-mail: weizichao98@nwafu.edu.cn
全球气温上升导致高温天气频发, 番茄作为温度敏感型植物更易发生热胁迫, 最终导致产量损失。 在植物热胁迫检测中, 温度通常被用作标定其受胁迫程度的依据, 但由于不同植株个体的耐热性和自身健康状态存在差异, 同一温度下的植株可能会产生不同程度热胁迫症状, 以温度来标定热胁迫状态可能会导致误判。 以番茄幼苗为研究对象, 提出了一种融合叶绿素荧光技术与可见-近红外光谱的番茄幼苗热迫胁程度快速分类方法, 以提高对番茄热胁迫程度评估的准确性。 采集了对照组植株和热胁迫植株的叶绿素荧光参数与可见-近红外光谱数据, 以叶绿素荧光参数为热胁迫评价指标, 结合k-means++聚类算法评估了番茄幼苗受热胁迫影响的严重程度, 通过对标定后样本的叶绿素荧光参数和植物逆境胁迫相关生理量进行分析, 验证了标定结果的合理性。 以聚类模型输出为依据对光谱数据进行标定, 采用3种预处理方法及其组合, 结合3种特征波长提取算法对光谱数据进行处理, 获得了6个与样本热胁迫程度相关的特征波段。 最后以6个特征波段为输入, 热胁迫程度为输出, 基于4种机器学习算法构建分类模型, 实现了对样本热胁迫程度的分类。 结果表明: 样本叶绿素荧光参数 Fv/ Fm, Fv/ Fo, NPQ, Y( NPQ)和 Y( NO)与其胁迫状态存在显著的中高度相关, 依据以上参数将所有样本标记为无胁迫, 轻度热胁迫和重度热胁迫三类。 三类样本的叶绿素荧光参数、 丙二醛(MDA)含量以及光合色素含量均表现出了组间显著差异, 聚类结果合理。 基于聚类结果对光谱数据进行标定, 根据标定结果提取光谱特征波长, 99%以上的冗余特征被消除, 进一步筛选获得了6个用建立分类模型的特征波长。 在建立的4个模型中, 线性判别分析(LDA)模型具有最优性能, 其测试集分类准确率为92.45%, F1分数为0.929 1, AUC为0.9780。 结果表明, 采用叶绿素荧光技术结合可见-近红外光谱技术检测热胁迫是可行的, 该研究为热胁迫的快速检测、 耐热性快速筛选以及高温灾害预警提供了一种有效方法。
, LU Miao, HU Jin
Heat stress can inhibit the growth of tomato seedlings and lead to yield loss. Temperature is often used as an indicator to evaluate the impact of plant heat stress. However, due to the difference between individual plant heat tolerance and their health status, plants under the same temperature may show different heat stress symptoms, which could lead to misclassification. Therefore, combined with chlorophyll fluorescence technology and visible near-infrared spectroscopy, this paper proposes a classification method for tomato seedlings' heat stress severity. The chlorophyll fluorescence parameters and visible near-infrared (Vis-NIR) spectrum data of the controlled and heat-stressed plants were collected. Using multiple chlorophyll fluorescence parameters as indicators, a clustering model based on the k-means++ algorithm was established to obtain the classification labels on the severity of heat stress. The reasonableness of the clustering result was verified by analyzing the difference between the chlorophyll fluorescence parameters and the biochemical indicators among the three samples. Then, the spectral data were labelled based on the output of the clustering model; six characteristic bands highly related to the sample's heat-stress severity were extracted using three preprocessing methods and their combinations, combined with three characteristic wavelength selection algorithms. With six characteristic bands as input and the heat-stress-severity as output, classification models are established based on four machine learning algorithms to classify the heat-stress-severity. The results showed that The chlorophyll fluorescence parameters Fv/ Fm, Fv/ Fo, NPQ, Y( NPQ) and Y( NO) showed significant moderate to high correlation with their heat stress status, and the samples were labelled as non-heat-stressed samples, mild heat-stressed samples and severe heat-stressed samples based on the five parameters. After feature extraction, more than 99% of redundant features are eliminated, and only six characteristic wavelengths remain. Characteristic wavelengths that can be used to establish classification models are obtained. The LDA model performs best among the four models, with a classification accuracy of 92.45%, an F1 score of 0.929 1, and an AUC of 0.978 0. The results indicate that using chlorophyll fluorescence technology combined with Vis-NIR technology to detect heat stress is feasible. This study provides an effective method for rapidly detecting heat stress, rapid screening of heat tolerance in plants and early warning of heat stress.
番茄作为世界各地广泛种植的作物, 对温度变化十分敏感。 通常18.3~32.5 ℃被认为是番茄的最佳生长温度[1], 当环境温度高于该温度区间上限时会引发植物热胁迫现象。 热胁迫导致植物细胞结构受损、 膜系统功能紊乱、 引起植物体内氧化产物积累, 进而对植物的光系统Ⅰ (PSⅠ )和光系统Ⅱ (PSⅡ )造成光抑制, 最终导致产量损失[2]。 需要探索一种有效、 快速的方法来评估番茄热胁迫程度, 以实现对高温灾害的快速预警和补救。
可见-近红外光谱技术因其能够提供有关植物中色素和叶细胞结构的信息, 被认为是植物胁迫分析领域的一项重要技术, 应用此技术在植物胁迫检测时, 需要提供可靠的指标来标定环境胁迫的程度。 在热胁迫检测中, 高温环境的温度通常作为用于评估植物热胁迫程度的指标。 受热胁迫持续时间、 热胁迫强度以及植物个体对高温的耐受性差异等因素影响, 不同植物在相同高温环境下可能会产生不同的热胁迫症状[3], 将导致对植物热胁迫程度的错误标定。 除温度外, 还存在其他的用于评估植物热胁迫程度的指标: 热损伤指数[4]是一种常用的基于肉眼观察法评价植物热胁迫程度的指标, 此方法具有快速、 无损的特点, 但在面对受热胁迫后表型变化不明显的样品时, 便不再适用, 该指数的有效评估需要观测者具有丰富的专业知识积累。 另一类方法则是基于理化测试的方法, 如: 膜损伤指数[4]、 光合色素含量(主要为叶绿素与类胡萝卜素含量)以及丙二醛(malonaldehyde, MDA)含量[5]。 这些指标虽能定量描述植物的胁迫程度, 但其测量过程具有破坏性、 需要专业的人员和设备等特点限制了其在现场检测的效率。
叶绿素荧光技术被认为是植物健康状态的无损探针, 已被广泛用于各类植物胁迫检测领域[6]: Rollins等[7]证实了采用叶绿素荧光参数Fv/Fm和NPQ能够对表征热胁迫条件下的大麦叶片PSII状态; Dong等[8]使用6个叶绿素荧光参数结合机器学习技术对番茄冷害程度进行了分级。 以上研究表明, 叶绿素荧光参数可以有效地指示植物受胁迫的程度, 然而叶绿素荧光参数的测定过程相对光谱检测较长, 并且需要在测定前进行20 min以上的暗适应。 若能将在胁迫检测领域更具优势的叶绿素荧光技术与检测速度较快的光谱技术相结合, 使用叶绿素荧光参数代替温度作为标定热胁迫程度的指标, 再依据这种标定结果构建基于光谱技术的分类模型, 将两种技术的优势进行互补, 便有可能提高植物胁迫检测的效率, 同时能使得检测结果的生理意义更加明确。
本研究以番茄幼苗为对象, 结合叶绿素荧光技术与可见-近红外光谱技术, 提出了一种植物热胁迫程度检测方法, 主要工作包括: 首先采集样本的可见-近红外光谱数据和叶绿素荧光参数; 通过聚类方法标定植物热胁迫程度, 分析了各类样本组间的叶绿素荧光参数差异, 同时测定不同胁迫程度样本的MDA与光合色素含量, 以验证聚类结果; 最后提取与热胁迫程度相关的特征波长, 采用机器学习算法建立分类模型, 实现对番茄幼苗热胁迫的程度准确分类。
试验于西北农林科技大学农业农村部农业物联网重点实验室(北纬34° 07'39″, 东经107° 59'50″)开展, 选择在杨凌日光温室中生长的番茄苗“ 优柿3号” 作为试验对象。 于2022年4月将长势一致的幼苗移栽至尺寸为4.3 cm× 5.5 cm× 5.5 cm花盆中, 加入基质(Pindstrup Mosebrug A/S, 丹麦)培养于人工气候箱中(RGL-P500D-CO2, 达斯卡特, 中国)。 正常培养环境条件: 昼/夜空气温度为28 ℃/18 ℃, 空气相对湿度为60%, 空气二氧化碳浓度为400 μ mol· mol-1; 昼/夜光周期为14 h/10 h, 光量子通量密度为430 μ mol· m-2· s-1, 所有幼苗进行统一灌溉, 当幼苗生长至两叶期时开始试验。 试验组温度梯度设置为39, 41, 43, 45和47 ℃, 对照组温度为28 ℃, 其余环境参数与正常培养环境相同。 每次试验开始时, 选择长势一致的6株样本, 将其均分为对照组与试验组, 将试验组置于高温下2 h后取出开始测量。 各温度梯度样本分配为: 对照组100株幼苗, 41和43 ℃组各30株幼苗, 43 ℃组、 45 ℃组和47 ℃组各75株幼苗。 试验结束后, 共获得有效样本351个, 其中对照组样本100个, 热胁迫样本251个。 在建立聚类模型后, 重复试验以获得用于MDA和光合色素含量测量的样品。
1.2.1 叶绿素荧光参数采集
使用叶绿素荧光成像系统Imaging-PAM(Heinz Walz, 德国)采集样本的叶绿素荧光参数。 仪器参数设置: 光化光辐射为81 μ mol· m-2· s-1, 测量光强度为2, 频率为1, 增益为6。 每个叶片上选取3个大小一致的感兴趣区域(area of interest, AOI), 以3个AOI中所包含像素的平均值作为该样本的测量结果。 所有样本在测量前均进行了30 min的暗适应以保证测量结果准确。
1.2.2 光谱数据采集
在叶绿素荧光采集结束后进行可见-近红外反射光谱数据的采集。 以带有积分球的手持式叶片夹(SpectroClip-TR, Ocean Optics, 美国)、 卤钨灯(HL-2000-HP, Ocean Optics, 美国)、 波长范围为350~925 nm, 光谱分辨率为1.2 nm FWHM的光谱仪(QEPRO-VIS-NIR, Ocean Optics, 美国)和计算机搭建光谱数据采集平台获取光谱数据。 在OceanView 2.0软件(Ocean Optics, 美国)中完成光谱仪参数的设置: 积分时间为350 μ s, 扫描次数为10, 窗平滑宽度为5。 每次从叶片上表面避开主叶脉采集光谱数据3次, 将其平均值作为该样本的测量结果。
1.2.3 MDA与光合素色含量测定
MDA是植物体内脂质发生过氧化后的产物, 视为衡量细胞膜损伤程度的有效指标, 其含量随着胁迫程度的加深而增加[9]; 叶绿素和类胡萝卜素含量与植物的光和能力和光保护能力直接相关, 在植物受到环境胁迫时, 其含量会发生改变。 两者含量的改变都能够从生理层面反映植物遭受到胁迫的严重程度。 本研究依照植物生理学实验指导[10]测量样本的MDA含量, 依照96%乙醇法[11]测量样本的叶绿素和类胡萝卜素含量, 每次测试进行3次生物学重复, 将其均值作为测量结果。
1.3.1 叶绿素荧光数据处理
建立叶绿素荧光参数聚类模型前, 需对输入特征进行优选以提高模型性能。 为选择合适的相关性分析方法, 需考察样本是否符合正态分布。 在本研究中, 因待检验样本的数量大于50个, 选择Kolmogorov-Smirnov方法对所有叶绿素荧光参数进行正态性检验, 结果表明所有叶绿素荧光参数均不符合正态分布。 基于以上原因, 本研究采用斯皮尔曼相关性分析法对叶绿素荧光参数进行优选, 综合考虑相关性系数大小和显著性选择关键叶绿素荧光参数[12]。 使用k-means++算法基于关键叶绿素荧光参数建立热胁迫程度聚类模型。 根据模型的误差平方和(sum-of-squared error, SSE)以及CH(Calinski-Harabasz)指数[13]随聚类簇数k的变化关系曲线, 基于手肘法确定最佳簇数。 采用轮廓系数[14]作为模型内部评价指标对聚类效果进行评估, 该系数用于衡量聚类簇的聚合度, 取值范围为[-1, 1], 其值越接近1表明簇聚合度越高, 聚类效果越好; 当该系数为0时, 表示存在重叠分配的样本; 当该系数小于1时, 表示存在被错误分配的样本。
1.3.2 光谱数据预处理
为消除由粗糙叶片表面引起的光谱散射效应和仪器噪声等因素对数据的干扰, 需要对光谱数据进行预处理。 本研究以SG卷积平滑(savitzky-golay smoothing)、 标准正态变量变换(standard normal variate, SNV)和多元散射校正(multiple scattering correction, MSC)方法为基础对光谱数据预处理。 SG平滑方法能够消除由仪器噪声引起的光谱尖峰, 减少外界因素对光谱数据的影响, 而SNV和MSC方法能够校正由光程变化和散射等因素引起的光谱变化, 组合使用多种方法能够提高光谱预处理的效果。
1.3.3 光谱数据特征波长提取
光谱数据携带了反映样本胁迫状态的关键信息, 而同时包含大量高度共线性的冗余数据[15], 需要对其进行特征提取来提高后续建模性能。 本研究使用竞争性自适应重加权算法[16](competitive adaptive reweighted sampling, CARS), 区间随机蛙跳算法[17](interval random frog, iRF)、 连续投影算法[18](successive projections algorithm, SPA)及其组合对光谱数据进行特征提取, 得到所有算法组合下提取的特征波长子集。 采用直方图法统计特征波长子集中的各波长的出现频率, 选择结果中出现频率较高的波长作为最终提取结果。
1.3.4 分类模型建立
为平衡正常样本与胁迫样本的数量, 使用分层采样算法按7∶ 3比例将数据集划分为训练集和测试集。 使用机器学习算法构建分类模型, 并对各模型的结果进行对比分析。 分别使用了偏最小二乘判别分析(partial least squares discriminant analysis, PLS-DA)、 线性判别分析(linear discriminant analysis, LDA)、 支持向量机算法(support vector machine, SVM)和反向传播神经网络(back propagation neural network, BPNN)4种机器学习算法构建分类模型。 使用分类准确率, F1分数和受试者特性曲线下方面积(area under curve, AUC)作为分类模型的评价指标。
各模型的参数设置如下: PLS-DA模型的主成分个数设置为5; LDA模型的主成分个数设置为2, 采用奇异值分解(SVD)算法作为模型的降维方法; 使用网格搜索法确定SVM模型的最优核函数为线型核函数, 惩罚因子C设置为10; BPNN模型设置激活函数为ReLU, 网络结构设置为6, 3, 3, 采用自适应学习率更新模型神经元权重。
1.3.5 数据分析工具
使用Python(版本3.7.10)语言和Scikit-learn(版本1.0.0)工具包实现对数据的相关性分析和分类模型的构建; 使用Matlab R2021a (MathWorks, 美国)软件实现对光谱数据的预处理与特征波长提取; 使用SPSS软件(SPSS, Inc., 美国)进行叶绿素荧光参数、 MDA及光合色素含量的统计学分析。 由于三类样本的叶绿素荧光参数不服从正态分布, 使用Kruskal-Wallis非参数检验法对三类样本的叶绿素荧光参数进行差异显著性分析(显著性水平设置为0.05); 采用单因素方法分析对MDA和光合色素含量进行统计学分析(显著性水平设置为0.05)。
将所有样本的8个叶绿素荧光参数与其胁迫状态分别进行了相关性分析(正常样本记为0, 胁迫样本记为1), 其结果如图1(a)所示。 所有叶绿素荧光参数均与其胁迫状态表现出显著相关关系(显著性水平为0.01, 标记为“ * * ” ), Fv/Fm, Fv/Fo, NPQ/4(记为NPQ), Y(NO)和Y(NPQ)共5个叶绿素荧光参数表现出了中高度相关性, 其相关系数均超过0.4。 Fv/Fm定义为植物PSII最大量子产率, Fv/Fo定义为植物PSII的潜在活性, 二者均为用于评估光抑制程度的最有效参数, 其值随着谐迫程度加深而降低; Y(NPQ)和Y(NO)用于描述植物PSII的能量去向, 与参数Y(II)组合能够反映植物PSII的生理状态; NPQ表征植物对于能量的耗散能力, 即光保护能力。 Fv/Fm和Fv/Fo与热胁迫状态表现出了高度相关, 而NPQ, Y(NO)及Y(NPQ)表现出了中等相关, 这些叶绿素荧光参数已被证明与植物在环境胁迫下的自我保护与调节机制密切相关[19], 上述分析表明叶绿素荧光参数的相关性分析结果符合植物生理规律。 除Fv/Fm和Fv/Fo外, 其余叶绿素荧光参数与植物的胁迫状态存在中度相关, 表明对于某些环境胁迫因子, 仅用参数Fv/Fm或Fv/Fo来评估其对植物的胁迫程度可能会丢失部分信息, 应辅以其他参数进行综合评价。
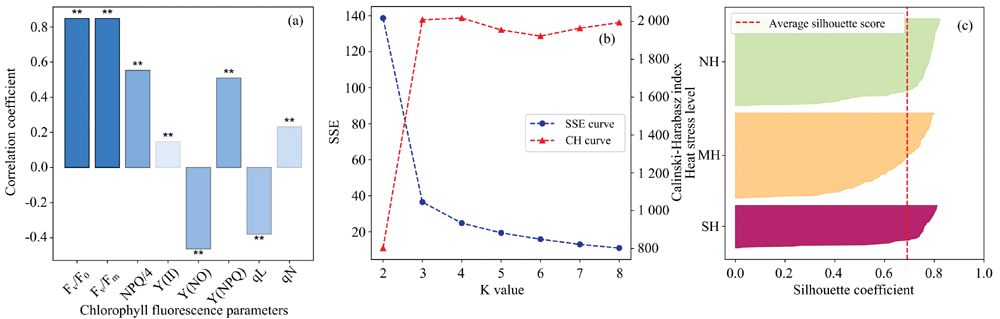 | 图1 叶绿素荧光参数聚类分析 (a): 叶绿素荧光参数相关分析; (b): 聚类模型性能与簇数变化; (c): 聚类模型轮廓系数Fig.1 Clustering model of the chlorophyll fluorescence parameters (a): Correlation analysis of chlorophyll fluorescence parameters; (b): Clustering model performance with variation in number of clusters; (c): Silhouette coefficient of the clustering model |
将上述5个叶绿素荧光参数为输入, 基于k-means++算法构建聚类模型。 如图1(b)所示, 根据手肘法可知, 当k=3时, 模型的SSE和CH指数产生突变, 当k=4时, 二者仅产生小幅变化, 再增加聚类簇数对模型聚类效果提升很小。 当k=3时模型具有最佳性能, 其CH指数和轮廓系数分别为2 008.72和0.69, 由图1(c)可知三个簇的轮廓图中所有值都大于0, 表明没有样本被错误或重叠分配。 根据聚类模型的输出, 将各个簇内的样本标记为3类, 即: 无胁迫样本(non-heat-stressed, NH), 轻度热胁迫样本(mild heat-stressed, MH)和重度热胁迫样本(severe heat-stressed, SH)。
对比分析了NH、 MH和SH三类样本的8个叶绿素荧光参数, 用于验证聚类结果的合理性, 同时解释三类样本差异产生的原因。 其结果如图2(a— f)所示。 NH、 MH和SH样本的Fv/Fm, Fv/Fo, NPQ和Y(NPQ)参数依次显著降低, Y(NO)依次显著升高, 表明聚类模型划分出的不同样本之间的关键叶绿素荧光参数存在显著差异。 MH和SH样本的Fv/Fm和Fv/Fo相比于NH样本降低, 表明热胁迫影响了样本的PSII最大光合效率和潜在光合能力, 这种影响随胁迫程度加深呈现阶段性加深。 相比于NH样本, MH和SH样本Y(NPQ)与NPQ的降低表明其抵抗逆境胁迫的能力遭到削弱, 导致多余的能量无法耗散。 轻度热胁迫(MH)虽然抑制了植物自身的调节能力, 而此时植株的正常光合能力尚未被破坏, 表现为其Y(II)和Y(NO)与无胁迫样本(NH)相比并未产生大幅变化; 而重度热胁迫样本(SH)表现出了极低的Y(II), Y(NPQ)和极高的Y(NO), 说明此时植株几乎无法有效利用光能进而导致大量光能过剩, 并且这些能量难以通过热或荧光的形式进行耗散[20], 说明植株的光合机构已经遭到了严重的不可逆损伤。 上述分析表明, 聚类模型划分出的三类样本其光合机构的状态之间存在显著差异, 并且这些差异具有生理可解释性, 证明了叶绿素荧光聚类模型结果的有效性。
 | 图2 各类样本组间叶绿素荧光参数对比 (a): Y(Ⅱ ); (b): Y(NPQ); (c): Y(NO); (d): NPQ; (e): qN; (f): qL; (g): Fv/Fm; (h): Fv/FoFig.2 The differences in ChlF parameters among the NH, MH, and SH samples (a): Y(Ⅱ ); (b): Y(NPQ); (c): Y(NO); (d): NPQ; (e): qN; (f): qL; (g): Fv/Fm; (h): Fv/Fo |
作为聚类模型的内部评价指标, CH指数和轮廓系数能仅反映模型本身的性能优劣, 却无法证明聚类结果的合理性, 通常需要借助其他外部评价指标来解释产生这种聚类结果的原因。 图3(a— f)为不同胁迫程度标记样本的MDA和光合色素含量测定结果, 由图3(a— e)可知, 与NH样本相比, MH样本和SH样本的MDA含量、 叶绿素和类胡萝卜素含量依次显著升高。 本研究中受胁迫样本(MH和SH)的MDA含量高于MH样本, 而SH样本又高于MH样本, 其变化规律与对胁迫等级的划分结果一致。 叶绿素和类胡萝卜素含量的增加表明, 在胁迫条件下, 植物启动了色素调节机制。 植物通过加速合成光合色素来提高光合速率, 导致叶绿素a和叶绿素b的浓度升高, 同时还提高了类胡萝卜素这一类光保护色素的合成, 用于减轻植物体内由单线态氧导致的光抑制, 以此降低高温环境对植物机体的损伤[21], 这种调节机制强度随着胁迫程度增加而增加。 上述结果表明, 聚类模型对胁迫程度的标记结果具有生理意义, 证明了聚类结果的合理性。
 | 图3 各类样本组间MDA与光合色素含量对比 (a): MAD含量; (b): 叶绿素a含量; (c): 叶绿素b含量; (d): 类胡萝卜素含量; (e): 叶绿素(a+b)含量; (f): 类胡萝卜素与叶绿素a比值Fig.3 The MDA and photosynthetic-pigment content of each of the three classes of samples (a): MAD content; (b): Chl a content; (c): Chl b content; (d): Car content; (e): Chl a+b content; (f): Car/Chl a |
图4为不同胁迫程度样本在不同温度处理下的分布。 其中28 ℃处理下的样本全部被聚类模型标记为了无胁迫; 39和41 ℃的样本大部分被标记为无胁迫, 43和45 ℃的样本大部分被标记为中度热胁迫, 47 ℃样本大部分被标记为重度热胁迫。 分析认为, 随着温度的升高, 样本被标记为更严重胁迫程度的概率同步增加。 然而不同温度处理之间的样本在胁迫程度标记上存在重叠, 表明仅使用温度梯度作为样本胁迫程度的划分依据会导致误分类情况的发生。 由于不同样本个体的生理状态(Fv/Fm值)和耐热性均存在差异, 导致相同温度的热胁迫环境对其生理状态的影响不同。 分析认为, 由于叶绿素荧光参数能够直接表征植株个体的光合机构的反应能量去向及光合作用状态, 其相较于温度更适用对样本热胁迫程度的定性描述。
 | 图4 不同胁迫程度样本在不同温度处理下的分布2.5 光谱数据预处理与特征波长提取Fig.4 The distribution of the labels on the severity of heat stress on samples subjected to different heat-treatment temperatures |
基于2.1节中聚类模型的输出结果, 将所有样本的原始光谱数据标记为NH, MH和SH三类, 由于光原始谱数据首尾存在严重的噪声干扰, 选择400~920 nm波长区间进行分析, 共包含686个有效波段, 三类样本的均光谱曲线如图5(a)所示。 样本的光谱曲线符合通常的植物光谱曲线形状, 随着胁迫程度的加深, 其光谱曲线整体形状虽无明显变化, 但是其“ 绿峰” 附近的光谱反射率随着胁迫程度的增加呈现下降趋势。 510~550 nm波段范围反射率的下降已被证明与植物的叶黄素脱环氧化作用有关, 而叶黄素循环过程是植物的非光化学猝灭(NPQ)功能的基础, 该功能与植物的光保护能力密切相关。 高温抑制了植物的非光化学猝灭效率, 导致过剩的光能抑制了PSI和PSII之间的电子传递效率, 表现为植物光合速率的下降[22]。 已有研究表明, 635 nm附近波段与植物组织的叶绿素含量存在显著相关性[23], 以上样本光谱曲线表现出的差异为建立热胁迫程度分类模型提供了依据。
 | 图5 平均光谱曲线与特征波长分布 (a): NH, MH和SH样品的平均光谱; (b): 特征光谱出现频数及其分布; (c): 特征光谱在光谱曲线上的分布Fig.5 Average spectral curve and characteristic wavelength distribution (a): Avarage spectral curves of NH, MH and SH samples; (b): Frequency and distribution of characteristic spectra; (c): Distribution of the characteristic spectrum on the spectral curve |
使用SNV、 MSC、 SG、 SG-SNV、 SG-MSC和MSC-SNV共6种预处理算法, 联合CARS、 iRF和SPA共3种变量选择算法对光谱数据进行特征波长提取, 共获得18个特征波长子集。 为进一步减少特征波长的数量, 使用直方图法对特征波长子集中各波长的出现频率进行统计并排序, 获得排名位于前10%的特征波长, 其结果如图5(b)所示。 通过合并相近波长, 最终确定了6个波长作为优选特征波长(529, 532, 545, 600, 615和815 nm), 这些波长在样本典型光谱曲线中的分布如图5(c)所示。 结果表明, 这些由高温导致的光谱信息变化与本研究中对叶绿素荧光参数、 MDA含量和光合色素含量的分析结果一致, 表明了特征波长提取的有效性。
为获得具有最优性能的分类器, 使用了PLS-DA、 LDA、 SVM和BPNN共4种机器学习算法, 以特征波长为输入, 胁迫等级(NH, MH和SH)为输出建立分类模型, 各模型运行50次计算其平均分类准确率, 其结果如表1所示。 由于全光谱数据包含过多冗余导致模型参数过多, 所有模型均在全光谱数据集上产生了过拟合。 经过特征选择后, 光谱变量的数量减少了99%以上, 各模型获得了较好的(80%以上)分类准确率, 且未出现过拟合现象, 表明特征提取有效提升了模型性能。
| 表1 各模型在不同数据集上的分类准确率 Table 1 The classification accuracies of each model on different datasets |
对于特征数据集, PLS-DA、 LDA和SVM模型的表现优于BPNN模型, 可能由于BPNN模型更适合学习数据的非线性关系。 所有模型中LDA模型综合性能最优, 其训练集和测试集准确率分别为93.88%和92.45%。 LDA算法和PLS-DA算法均对输入数据进行了降维, 而它们在分类策略上存在差异。 LDA算法依赖变换后数据的均值实现数据分类, 而PLS-DA则依赖方差进行区分; 由于LDA算法可以先验地推断出数据集中的类别分布, 这使得在本研究的分类任务中LDA算法表现优于PLS-DA算法。 表2中各模型的F1分数和AUC表明, 这些模型在具有较高的分类精度的同时兼具较好的泛化性能。
| 表2 各模型在特征光谱数据集上F1分数与AUC值 Table 2 The F1 score and the AUC of the classification models based on the feature spectra data set |
以两叶期番茄幼苗为研究对象, 结合叶绿素荧光技术与可见-近红外光谱技术实现了对其热胁迫程度的分类, 基于聚类算法标定样本受热胁迫影响的程度, 以此为标准提取了与热胁迫高度相关的特征波长, 并基于特征波长建立了植物热胁迫程度分类模型, 主要结论如下:
(1)筛选出Fv/Fm、 Fv/Fo、 NPQ、 Y(NO)和Y(NPQ)共5个与热胁迫相关的叶绿素荧光参数为聚类模型输入, 确定了最优的聚类簇数, 并根据模型输出结果将所有样本的受热胁迫影响的程度标记为无胁迫、 轻度热胁迫和重度热胁迫三类;
(2)三类样本的叶绿素荧光参数、 MDA与光合色素含量均表现出了组间显著差异, 证明聚类结果符合植物生理规律。 由胁迫标签在与温度的关系分析, 使用叶绿素荧光参数划分热胁迫程度能够避免由于植物个体差异引起的误分类现象, 为后续建立光谱分类模型提供了理论支撑;
(3)基于叶绿素荧光参数聚类结果对样本的标定, 对光谱数据进行了特征提取, 最终获得6个特征波长, 基于LDA算法构建了最优分类模型。 该模型在训练集上的分类准确率为93.88%, 在测试集上的分类准确率为92.45%, 且模型具有一定泛化能力。
采用机器学习技术和统计分析方法, 提出了一种用于划分番茄幼苗受热胁迫影响程度的有效方法, 与化学计量学方法相比, 本研究提出的方法具有快速、 无损及可解释性好的特点, 可用于番茄耐热性筛选或灾害预警, 将此方法推广至不同环境胁迫因子和不同种作物, 为植物非生物胁迫检测与分类提供技术支持。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|