



{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于北方苍鹰优化核极限学习机的玉米品种鉴别研究
[倪金1  , 索丽敏
, 索丽敏1, * , 刘海龙1 , 赵蕊2 ]
, 索丽敏, 刘海龙|
|


作者简介: 倪 金, 1999年生, 黑龙江八一农垦大学信息与电气工程学院硕士研究生 e-mail: rubbit0@foxmail.com
玉米作为我国种植最为广泛的农作物, 其产量对于我国粮食安全具有重大意义, 由于不同品种具有不同的特性, 根据种植条件科学选种能够很大限度上提高产量并且降低生产成本, 但不同玉米种子外观极其相似, 导致科学选种工作产生了一定难度。 该研究基于近红外光谱技术结合核极限学习机(KELM)针对玉米品种分类问题构建鉴别模型, 利用甜糯黄玉米、 甜妃、 昌甜、 金色超人、 香甜5号五种玉米种子, 每种取(13±0.5) g作为一份样品, 共计126个样品作为研究对象, 对采集的近红外光谱数据进行标准正态变量变换(SNV)处理后采用竞争性自适应重加权采样法(CARS)对数据集进行降维。 按照5∶1的比例将样本随机分为训练集和测试集, 探讨北方苍鹰优化算法(NGO)对KELM模型性能的影响。 分别使用NGO算法、 粒子群算法(PSO)和灰狼算法(GWO)对KELM模型的两个重要参正则化参数 C和高斯核函数 γ进行寻优, 选择五折交叉验证识别准确率最高时对应的 C和 γ作为建模参数, 建立KELM分类模型。 将各算法寻优后建立的KELM模型性能进行对比。 实验发现, 通过NGO算法寻优后建立的KELM模型性能高于其他两种算法优化的KELM模型, 测试集识别准确率可达100%。 在CARS降维的基础上分别建立CARS-NGO-KELM、 CARS-PSO-KELM和CARS-GWO-KELM模型, 结果表明, 在面对降维后的数据时NGO算法仍能表现较好的性能, 其测试集准确率和 F1值均达到了100%。 为了验证样本数量对模型的影响, 使用各品种样品数量同步后的共计90个样品重新训练KELM模型。 结果表明, 在同步各类样品数量后, 各个模型在训练集和测试集上的表现均有提升。 该研究在近红外光谱的基础上引入多种优化算法构建核极限学习机模型并将识别准确率提升至100%, 实现了对玉米种子快速、 无损、 准确的品种鉴别, 研究结果为玉米品种快速鉴别提供了一种新方法, 同时也对监管部门具有一定的指导意义。
As one of the most widely planted crops in China, the yield of corn is of great significance to China's food security. Since different varieties have different characteristics, scientific seed selection according to planting conditions can significantly improve the yield and reduce the cost of production. Still, the appearance of different corn seeds is extremely similar, which leads to a certain degree of difficulty in scientific seed selection. In this study, based on near-infrared spectroscopy combined with the Kernel Extreme Learning Machine (KELM) to construct a discrimination model for the classification of corn varieties, the use of sweet glutinous yellow corn, sweet princess, Chang sweet, golden superman, sweet No.5 five kinds of maize seeds, each kind of 6 grains as a sample, a total of 126 samples as the object of the study, the near-infrared spectroscopy data collected by the standard normal variate transformation (SNV) treatment. Competitive Adaptive Re-weighted Sampling (CARS) was used to downscale the dataset. The samples were randomly divided into training and test sets according to the ratio of 5∶1 to explore the effect of the Northern Goshawk Optimization Algorithm (NGO) on the performance of the KELM model. The two important parametric regularization parameters C and Gaussian kernel function γ of the KELM model was optimized using the NGO algorithm, particle swarm algorithm (PSO), and gray wolf algorithm (GWO), respectively, and the C and γ corresponding to the highest accuracy rate of the 50-50 cross-validation recognition were selected as the modeling parameters to build the KELM classification model. The KELM model's performance is established after each algorithm's optimisation is compared. It is found that the performance of the KELM model established after optimization by the NGO algorithm is higher than that of the KELM model optimized by the other two algorithms, and the recognition accuracy of the test set can reach 100%. The CARS-NGO-KELM, CARS-PSO-KELM and CARS-GWO-KELM models are built based on CARS dimensionality reduction, and the results show that the NGO algorithm still performs better in the face of dimensionality reduction data, and its test set accuracy and F1 value both reach 100%. To verify the effect of sample size on the model, the KELM model was retrained using a total of 90 samples after synchronizing the sample size of each species. The results showed that after synchronizing the number of samples of each species, the performance of each model was improved on both the training and test sets. In this study, a variety of optimization algorithms are introduced to construct a machine learning model based on near-infrared spectroscopy and the recognition accuracy is increased to 100%, which realizes a fast, non-destructive, and accurate variety identification of maize seeds. The results of the study provide a new method for the rapid identification of maize varieties and also have certain significance as a guide for the supervisory authorities.
玉米是我国主要的粮食作物, 因其具有自身耐旱、 抗病虫害能力强等特点, 使得在全国范围大面积种植, 其产量对我国粮食安全以及社会发展也具有重要意义。 不同的玉米品种有不同的特性, 科学选种可以大大提高产量同时也可以降低生产成本, 但不同玉米种子外观及其相似, 导致鉴别有一定的难度。 因此有必要开发一种快速检测手段对玉米种子品种进行鉴别。
随着计算机技术和仪器测量技术的发展, 光谱检测技术已广泛应用于农业[1, 2]、 烟草[3, 4]、 化工[5, 6]等领域。 近红外光谱技术因具有无损、 快速、 成本低等众多优点, 深受广大学者重视。 吕梦棋等[7]针对传统人工挑选玉米种子存在误差大、 效率低等问题, 提出一种基于残差神经网络(residual network, ResNet)的图像分类方法对玉米种子进行精确分类。 该方法首先建立图像采集平台对采集到的数据进行图像预处理, 然后构建ResNet网络模型并对整个网络进行优化, 输入图像数据反复进行训练得到权值最佳的模型。 结果表明, 该方法对于三种不同玉米种子识别准确率分别达到了96.4%、 93.5%、 和92.3%, 该方法虽准确率尚可, 但数据量较大, 模型繁琐。 冯瑞杰等[8]为了快速检测玉米品种类型, 基于支持向量机(support vector machines, SVM)和近红外光谱联合建立了玉米品种分类模型, 将预处理后的近红外光谱数据输入SVM模型中, 分别引入网格搜索(grid search, GS)、 遗传算法(genetic algorithm, GA)和贝叶斯优化算法(Bayesian optimization, BO)对其中的两个重要参数进行优化。 实验表明, 使用BO优化的SVM分类模型相比于其他两种优化算法得到的SVM模型性能具有显著优势。 这种方法虽结合了近红外光谱和机器学习, 但建立的模型及优化算法较陈旧。
机器学习中的分类模型有很多, 极限学习机(extreme learning machines, ELM)[9]因其具有训练简单和速度快等优点现已被广泛应用于医疗[10]、 烟草[11]、 设备故障诊断[12]等领域。 ELM的输入层权值矩阵和隐含阈值矩阵是随机选取的, 并且在训练时不需要改变参数, 仅需要提供隐含层神经元数量和激活函数就能获取全局最优目标值, 虽然ELM相比传统的神经网络具有一定优势, 但其输入权值的随机性会影响算法的稳定性, 人工调节隐含层数量会影响算法的计算速度且容易出现过拟合现象。 为解决上述问题Huang等[13]于 2012年提出核极限学习机(kernel extreme learning machines, KELM), 利用核函数代替ELM中的激励函数, 将数据从向量空间映射至高维特征空间, 同时添加正则化参数进一步提高了模型的稳定性和泛化能力。 在KELM中核函数和正则化参数对模型的性能具有决定性作用, 近年来, 群体智能优化算法如雨后春笋般涌现, 常见的优化算法如粒子群算法(particle swarm optimization, PSO)、 灰狼算法(grey wolf optimizer, GWO)等普遍存在收敛速度慢, 容易陷入局部最优等问题。 本研究采用北方苍鹰优化算法(northern goshawk optimization, NGO)对KELM模型中的正则化参数C和核函数γ 进行寻优, 利用五折交叉验证识别准确率最高时对应的C和γ 作为参数用于KELM模型建立。 在基于近红外光谱数据的基础上引入多种优化算法, 采用对比的方式分别构建核极限学习机模型, 并将识别准确率提升至100%, 实现了对玉米种子快速、 无损、 准确的品种鉴别, 研究结果为玉米品种快速鉴别提供了一种新方法, 同时对监管部门具有一定的指导意义。
研究对象为5种不同品种的玉米种子, 对其采集近红外光谱数据后分别使用多元散射校正(multiplicative scatter correction, MSC)、 标准正态变量变换(standard normal variate, SNV)、 平滑滤波(savitzky-golay, SG)、 归一化(normalization)四种方法进行光谱数据预处理, 并建立KELM模型, 找出效果最佳的预处理算法用于实验建模。 分别引入PSO、 GWO、 NGO三种群体智能优化算法对模型进行参数寻优, 并在此基础上加入竞争性自适应重加权采样法(competitive adaptive reweighted sampling, CARS)对建模数据降维, 从而探讨数据维度对模型性能的影响。 最终实现对不同品种玉米的准确鉴别。
1.1.1 相关原理
多元散射校正(multiplicative scatter correction, MSC)可以有效消除由于散射水平不同带来的光谱差异, 增强光谱与数据之间的相关性。 该方法通过理想光谱修正光谱数据的基线平移和偏移现象。 MSC步骤如下: (1)求得所有光谱数据的平均值作为理想光谱; (2)将每个样本的光谱与平均光谱进行一元线性回归, 求解最小二乘问题得到每个样本的基线平移量和偏移量; (3)对每个样本的光谱进行校正: 减去求得的基线平移量后除以偏移量, 得到校正后的光谱。
标准正态变量变换(standard normal variate, SNV)用于消除光谱数据中的系统性偏移和尺度缩放效应, 其原理是对每个光谱数据点进行均值中心化和标准差归一化。 SNV步骤如下: (1)对每个光谱数据点进行均值中心化, 即该光谱数据点减去平均值; (2)对每个光谱数据进行标准差归一化, 即该光谱数据点除标准差; (3)处理后的光谱重构成为一个新的光谱矩阵。
平滑滤波(Savitzky-Golay, SG)是一种数字滤波器, 可以应用于一组数据, 从而平滑数据。 其原理是通过卷积的过程实现在不改变信号趋势和宽度的情况下提高数据的精度。 即通过线性最小二乘法将相邻数据点的连续子集与一个低次多项式拟合。
归一化(normalization)是将数据映射到指定的范围内进行处理, 用于去除不同维度数据的量纲以及量纲单位。 经过归一化后, 将有量纲的数据集变成纯量, 可以达到简化计算的作用。
竞争性自适应重加权采样法(competitive adaptive reweighted sampling, CARS)是一种特征提取方法, 采用全部特征建立偏最小二乘回归模型并迭代, 筛选出回归系数绝对值大的波长点, 将权重小的波长点去除后, 利用交互验证选出RMSECV值最低的子集, 该方法可有效提取光谱数据中的特征波长点。
用于实验的玉米为市购种植最为广泛的: 甜糯黄玉米、 甜妃、 昌甜、 金色超人、 香甜5号五个品种, 去除破损、 瘪粒、 矮小的玉米粒后, 每个品种选取(13± 0.5) g作为一个样品, 得到甜糯黄玉米36个、 甜妃18个、 昌甜18个、 金色超人18个、 香甜5号36个, 共计126个样品。 为了降低因湿度温度等原因对样本的影响, 将样本置于近红外光谱实验室静置20 h后进行扫描。
采样仪器为Bruker公司生产的TANGO近红外光谱仪, 测量波长为11 520~4 000 cm-1, 分辨率为8 cm-1。 将近红外光谱仪开机预热40 min后, 进行仪器分辨率校正, 将玉米样本置入仪器专用样品杯中, 保证样品杯底部均匀无漏光现象, 并将定制的标准白板盖在样品杯杯口, 避免因人为操作和外界环境引起的异常, 将样品杯放于仪器载物台上开始扫描样本透射率。 每个样品扫描32次后选取平均光谱作为研究样本。 将样品数据按照5: 1的比例随机分为训练集和测试集, 划分后训练集和测试集样本数据量分别为105个和21个。
1.3.1 核极限学习机
ELM是基于单隐含层前馈神经网络(single-hidden layer feedforward neural network, SLFN)提出的新学习策略, 此方法具有结构简单、 学习率高等特点, 在机器学习领域极具价值。 ELM在训练前可以随机产生输入权重和隐含层偏置, 只需要给定隐含层神经元的数量及激活函数便可获得最优解, 但输入层权值矩阵和隐含层阈值矩阵的随机性影响了模型的稳定性, 同时ELM隐含层冗余节点对数据特征共线无益, 还可能出现过拟合。 KELM是基于ELM引入核函数的改进算法, 能够在保留ELM优点的基础上通过引入核函数的方式将数据从向量空间映射至高维特征空间进行运算。 KELM计算每个样本与所有样本的相似度其不再受隐含层节点数的干扰, 提高了模型的稳定性和泛化能力。 正则化参数C和RBF核函数γ 对模型的性能起到决定性作用, C取值过大会导致模型出现过拟合; 反之会导致学习不足出现欠拟合现象。 γ 的形式和参数变化影响了输入空间到特征空间的映射, 也会对特征空间的性质产生影响。
1.3.2 北方苍鹰优化算法
KELM对正则化参数C和核函数γ 的取值十分敏感, 其性能与两个函数的关系无法用表达式描述, 只能通过多次尝试的方法来选取最优的C和γ 值。 NGO是2021年提出的一种模拟北方苍鹰捕猎过程的算法[14], 这种行为的模拟大幅提高了算法对空间的局部搜索能力。 北方苍鹰优化算法在给定初始种群数量后所有种群成员随机选取最优区域, 并确定种群成员的新值后更新各成员值。 算法进入下一次迭代并在随机选取的最优区域中不断搜索更新每次迭代得到的最佳值, 直到最后一次迭代结束后引入迭代过程中得到的最佳解作为给定优化问题的拟最优解。 虽然最优区域的确定相当于一次全局搜索, 但能有效缩小搜索范围使算法能够以极快的速度完成寻优。
常见的群体智能优化算法有很多如PSO、 GWO, PSO的权重和偏差值更新方法容易陷入局部极值, 惯性因子值较大时, 全局寻优能力强, 局部寻优能力弱; 值较小时, 全局寻优能力弱, 局部寻优能力强。 对于GWO算法, 在一般问题的求解精度和收敛速度方面都有良好的性能, 但极容易出现早熟收敛的现象。
1.3.3 评价指标
本研究使用精确率(precision)和召回率(recall)计算F1值作为分类模型性能的评价指标, F1值是二者的综合值, F1值高则说明模型的性能强, 计算公式如式(1)所示
式(1)中, 精确率(precision)的高低代表了预测为正的样本中有多少是真正的正样本, 召回率(recall)针对总样本而言, 表示的是样本中的正例有多少被预测正确, 这二者都对F1值的高低起到决定性作用, 其计算公式如式(2)和式(3)所示, 其中TP表示将正类预测为正类的数量; FP表示将负类预测为正类的数量; FN则是将正类预测为负类的数量。
本研究采用分类准确度作为评价指标, 即模型预测正确样本的数量在全部预测样本中的占比。 并在前两项评价指标基础上绘制混淆矩阵对模型进行评价。
为了降低采样时由于颗粒分布不均匀等原因产生的散射对模型稳定性的影响, 在建模前分别采用MSC图1(a)、 SNV图1(b)、 SG图1(c), 以及NOR图1(d)对原始数据进行预处理。
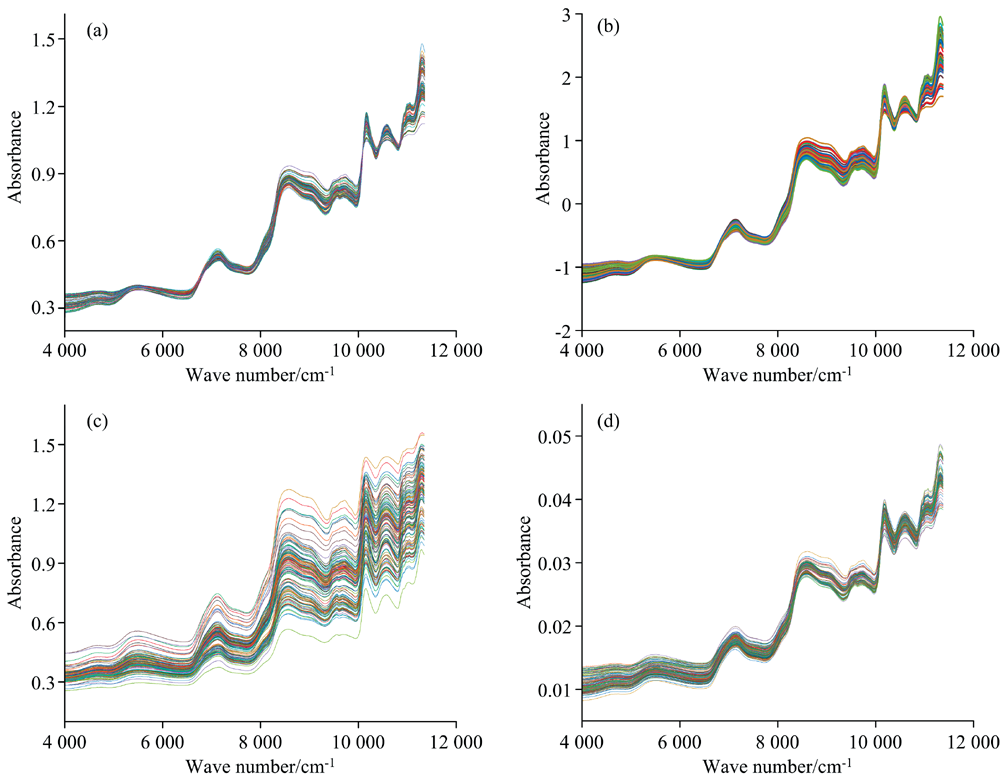 | 图1 预处理后的光谱 (a): MSC; (b): SNV; (c): SG; (d): NORFig.1 Near-infrared spectra after preprocessing (a): MSC; (b): SNV; (c): SG; (d): NOR |
为了选取最适合本研究的预处理方法, 将图1中的数据分别按照5: 1的比例分为训练集和测试集并建立正则化参数C和核函数γ 均为10的单一KELM模型, 根据不同预处理方法下构建模型的训练及测试集准确度来选择预处理方法, 由表1可知, 在数据经过SNV预处理后建立的KELM模型准确度较其他预处理方法准确率更高, 故本实验选择SNV对数据进行预处理。
| 表1 不同预处理方法下构建KELM模型的训练及测试集结果 Table 1 Training and test set results of constructing KELM model under different preprocessing methods |
对于SNV预处理后的数据, 选用五折交叉验证分别建立NGO-KELM, PSO-KELM和GWO-KELM模型, 三种优化算法的适应度曲线如图2所示, 模型参数和性能如表2所示。
 | 图2 适应度曲线Fig.2 Adaptation curve chart |
| 表2 不同优化算法寻优后建立KELM模型的性能 Table 2 Performance of KELM models after search by different optimization algorithms |
结果表明, NGO收敛速度和对模型参数寻优表现高于PSO和GWO, 分析认为NGO可以充分利用解函数的特征, 尽可能找到并利用解空间中的最优参数, 提高了找到新的局部最优解的可能性, 增强算法在最优值处的收敛精度, 使算法在局部最优解附近搜索, 提高在局部最优解附近的收敛精度和对局部最优解的利用能力。 由于最优位置缓慢移动, 体现出整个群体的走向, 以“ 精英反向学习策略” 使苍鹰的位置逐渐收敛成一条“ 直线” , 有效提高了收敛速度和精度。 PSO算法以最优解对于其他解的更新指引性太强、 解的更新过程中的随机性太弱, 当解集向群体最优解汇聚的时候, 导致群体最优解所在的一定范围外的空间没有机会探索。 而GWO算法面对复杂问题时收敛精度不高, 随机生成初始种群的方式无法保证较好的种群多样性, α 狼也不一定是全局最优点, 在不断的迭代中, ω 不断逼近前3匹狼, 导致GWO算法陷入局部最优解, 这都会降低模型分类准确度。
为了验证三种算法对低维数据的寻优能力, 采用CARS对原有数据进行特征筛选如图3, RMSECV最小值为43即最优迭代次数为43, 此时所对应的波长变量子集特征波长数量为102个, 因此将原有的高维玉米光谱数据降至102维。
 | 图3 CARS对数据降维的参数Fig.3 Parametric plot of CARS for data dimensionality reduction |
在此基础上使用三种优化算法对KELM的正则化参数C和核函数γ 进行寻优, 使用五折交叉验证识别准确率最高时的参数作为建模参数, 分别建立CARS-NGO-KELM, CARS-PSO-KELM和CARS-GWO-KELM模型, 模型性能如表3所示。 结果表明使用GWO寻优得到的正则化参数C过大, 模型出现了过拟合现象。 PSO在面对降维后的数据上对比降维前表现略有提升, 分析是因为数据维度变小, 使PSO在全局空间中搜索到最优解的概率增大。 而NGO在面对低维数据寻优问题上表现仍高于其余两种优化算法, 这是因为其种群成员在面对求解问题中会在全局随机选取最优区域后在各自的最优区域中搜索最佳值, 在数据维度变小的情况下北方苍鹰选取最佳区域更容易覆盖到全局, 从而以更快的速度完成寻优。
| 表3 使用CARS降维后各模型的性能 Table 3 Performance of each model after dimensionality reduction using CARS |
根据四种模型在测试集上的混淆矩阵[图4(a— d)]可知NGO-KELM模型和CARS-NGO-KELM模型在测试集上能够正确识别各玉米样本种类, 而CARS-PSO-KELM和CARS-GWO-KELM两种模型的分类错误均与甜糯黄玉米和香甜5号有关, 可能是由于两类样本数量多于其他样本, 在训练时出现“ 学习过度” 导致模型出现了过拟合现象。
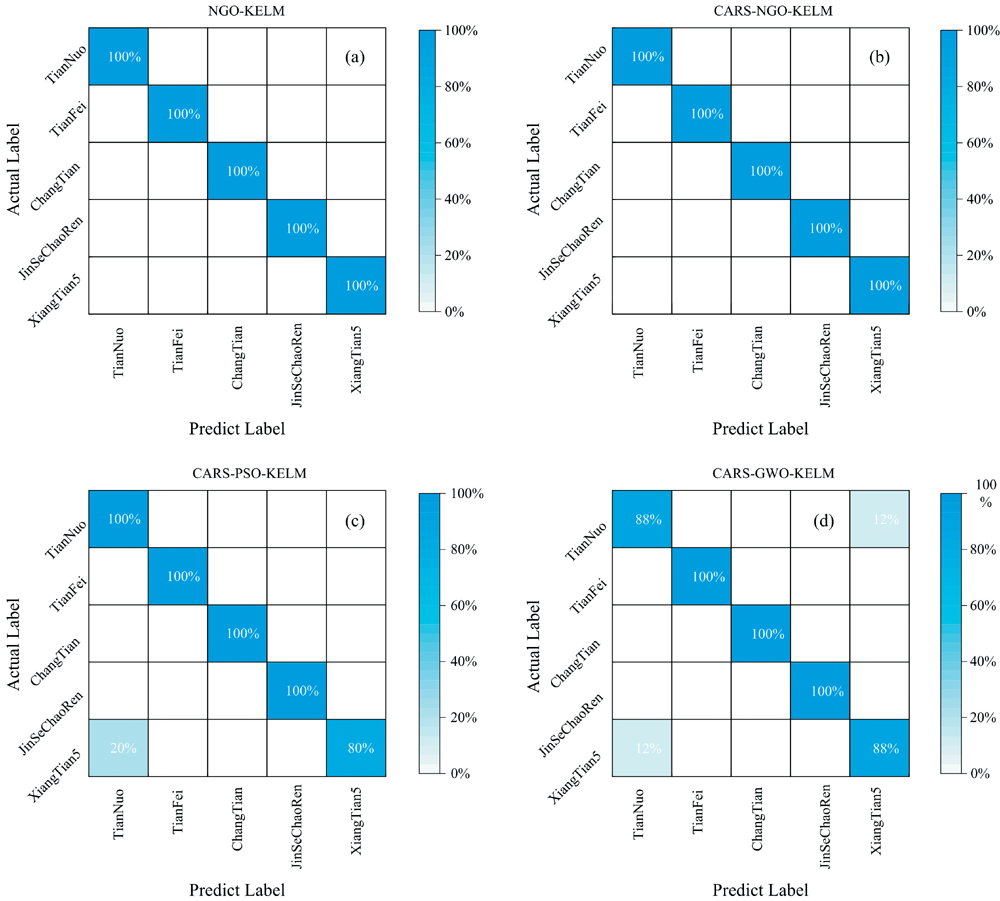 | 图4 四种模型在测试集上的混淆矩阵 (a): NGO-KELM; (b): CARS-NGO-KELM; (c): CARS-PSO-KELM; (d): CARS-GWO-KELMFig.4 Confusion matrix for the four model test sets (a): NGO-KELM; (b): CARS-NGO-KELM; (c): CARS-PSO-KELM; (d): CARS-GWO-KELM |
为了验证这一猜想, 分别将原有数据集中的甜糯黄玉米(36个样本)和香甜5号(36个样本)减少至18个, 使用剩余的90个样本数据按照5∶ 1的比例随机划分为训练集和测试集重新训练NGO-KELM、 CARS-NGO-KELM、 CARS-PSO-KELM、 CARS-GWO-KELM四种模型, 同步5种样本数量后的模型性能如表4所示。
| 表4 同步样本数量后模型性能对比 Table 4 Comparison of model performance after synchronizing the number of samples |
在同步样品数量后四种模型在测试集上的识别准确率均能达到100%。 说明在每种样品数量不均衡的情况下训练模型会对模型性能产生一定的影响, 对于样本量较多的种类可能会出现过拟合现象[15]。
利用近红外光谱技术结合机器学习模型提出了一种快速无损的玉米品种鉴别方法, 采用近红外光谱仪实现对玉米种子数据的获取; 使用SNV算法对原数据进行预处理, 并分别构建PSO、 GWO以及NGO优化KELM分类预测模型即PSO-KELM、 GWO-KELM以及NGO-KELM。 同时在此基础上加入CARS探讨数据维度对模型的影响, 获得结论主要包括:
(1) 使用不同优化算法对模型的正则化参数C和核函数γ 进行优化表现出了不同的结果, NGO算法优化的KELM模型相比于PSO算法和GWO算法优化的KELM模型有着更好的预测性能表现即模型参数更优。 NGO寻得的正则化参数C和核函数γ 为668.1、 59.33, 而PSO和GWO得到的参数分别为10、 4和1 000、 52.2。 结果表明, 相比于PSO算法和GWO算法, NGO通过随机选取最优区域缩小搜索空间后迅速收敛, 能达到快速准确寻找模型全局最优参数的目的, 可以有效提高KELM模型的性能。
(2) 采用CARS算法将数据由原有的1 845维降至102维后再次构建三种模型, 实验发现: 面对降维后的数据, PSO优化的KELM模型测试集准确度和F1值有所提升, 分别由原来的85.71%和83.33%提升至95.23%和88.88%, 而其他两种模型仅C与γ 值有所改变, 准确率和F1值均没有变化。 说明数据的维度对NGO算法和GWO算法影响并不大, 二者在面对高维数据和低维数据时同样适用, 但由于NGO算法探索能力强, 局部搜索和利用能力强的特点, 搭配模型使用能够给出更加准确的预测值。
(3) 分别将原有数据集中的各品种样品数量同步后, 重新构建的NGO-KELM、 CARS-NGO-KELM、 CARS-PSO-KELM、 CARS-GWO-KELM四种模型, 其测试集准确率和F1值均能达到100%。 由此可知, 样本数量不均衡会对KELM分类精度产生一定的影响, 导致模型性能下降。
本研究针对不同品种玉米种子鉴别难这一问题, 使用近红外光谱技术结合多种算法构建了分类预测模型, 可实现对不同品种玉米的准确识别。 研究结果为快速鉴别玉米品种提供了一种新方法, 同时也对监管部门具有一定的指导意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|