




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
激光诱导击穿光谱技术对水稻产地识别研究
[宋少忠1  , 符少燕
, 符少燕2 , 刘园园2 , 齐春艳3 , 李景鹏4 , 高勋2, * ]
, 符少燕]
|
|


作者简介: 宋少忠, 1972年生, 吉林工程技术师范学院教授 e-mail: songsz@jlenu.edu.cn
水稻是中国主要粮食作物, 而水稻品质与其生长的外部环境如土壤特性、 气候、 日照时间和灌溉水等环境息息相关, 高品质水稻的产地区域面积有一定地域限制, 因此水稻可看成为是一个明显的地理标志物。 市场常出现一些假冒或者贴牌的知名优质水稻出售, 损害了水稻品牌, 降低了消费者的水稻品质保障, 并且扰乱了市场稳定性, 因此对于水稻产地快速识别技术的需求十分迫切。 利用LIBS结合机器学习算法, 对吉林省5个产地(大安、 公主岭、 前郭、 松原、 洮儿河)的水稻进行产地识别, 建立了主成分分析(PCA)算法分别结合Bagged Trees、 Weighted KNN、 Quadratic SVM和Coarse Gaussian SVM共四种机器学习算法的水稻产地识别模型。 实验选取了5个水稻产地共450组在200~900 nm的LIBS数据, 对水稻LIBS光谱数据采用卷积平滑(S-G平滑)进行降噪和特征谱线归一化预处理, 对水稻LIBS光谱数据进行主成分分析, 实现了水稻产地具有较好的聚类空间集群分布, 但部分水稻产地存在空间重叠。 采用5倍交叉验证, 采用PCA-Bagged Trees、 PCA-Weighted KNN、 PCA-Quadratic SVM和PCA-Coarse Gaussian SVM共四种机器学习模型, 水稻产地的识别精度均达到91.8%以上, 并且PCA-Quadratic SVM模型的识别精度高达97.3%。 结果表明结合LIBS技术和机器学习算法能够高精度和高效率实现水稻产地的识别。
Rice is the primary grain crop in China, and the quality of rice is closely related to the external environment, such as soil characteristics, climate, sunshine time, and irrigation water. The high-quality rice-origin area has certain regional limitations. Therefore,the rice can be seen as an apparent geographical marker. There are often some counterfeits or branded famous high-quality rice in the market, which can damage the rice brand, reduce the rice quality guarantee of consumers, and disturb the market stability, so rapid identification technology of rice origin is needed. The rice origin identification models of five sources in Jilin Province (Daan, Gongzhuling, Qianguo, Songyuan and Taoerhe) are done by laser-induced breakdown spectroscopy and machine learning algorithms. The principal component analysis (PCA) algorithm, combined with four machine learning algorithms, Bagged Trees, Weighted KNN, Quadratic SVM, and Coaster Gaussian SVM, has been established. A total of 450 groups of LIBS data are selected. The spectral data of rice LIBS are pretreated with Savitzky-Golay smoothing (S-G smoothing) for noise reduction and normalisation. The principal component analysis uses the rice LIBS data, which shows that the rice origins had an excellent cluster distribution of clustering spaces. Still, there is spatial overlap in some rice origins. Utilising5x cross-validation, the identification accuracy of rice origins can reachmore than 91.8% by adopting PCA-Bagged Trees, PCA-Weighted KNN, PCA-Quadratic SVM and PCA-Coarse Gaussian SVM, and the recognition accuracy of PCA-Quadratic SVM model is as high as 97.3%. The results show that the combination of LIBS technology and machine learning algorithms can identify rice origin with high precision and high efficiency.
水稻含碳水化合物75%, 蛋白质7%~8%, 脂肪1.3%~1.8%, 并含有铁、 锌等多种矿物质元素, 具有丰富的营养价值, 被称誉为“ 五谷之首” , 是中国的主要粮食作物。 水稻品质与其生长的外部环境如土壤特性、 气候、 日照时间和灌溉水等环境息息相关, 对同一水稻品种, 在不同地理区域生长出来的水稻品质存在一定的差异[1]。 高品质的水稻产地覆盖的区域面积有一定限制, 因此水稻可看成为是一个明显的地理标志物。 目前市场常出现一些假冒或者贴牌的水稻出售, 不仅损害水稻品牌, 且降低了消费者的水稻品质保障[2], 因此, 水稻产地识别对于提高水稻品牌保护, 维护消费者的品质需求, 同时对水稻市场稳定发展具有重要意义。
传统水稻产地识别一般观看水稻外观形状或咀嚼品赏判断, 易受鉴别者的人为因素影响。 通过脂肪萃取化学方法来识别水稻产地, 工作量大且耗时, 需要具备专业萃取技术的研究人员进行操作[3]。 因此, 亟需一种通过对水稻中矿物元素进行定性和定量分析, 从而实现水稻产地快速识别的现代分析技术。 高彤[4]等基于NIR和PLS-DA方法对东北大米产地进行溯源研究, 训练集准确率可达93.33%, 测试集准确率为86.67%; 有研究采用高光谱, 结合图像特征及模式识别技术, 并联合多个模型构成模型集群, 对东北/非东北大米产地进行了精准识别。 王靖会[5]等采用随机森林方法, 用原子吸收光谱技术对相邻区域地理标志大米产地进行确认, 实现了96%的准确率。
激光诱导击穿光谱(laser-inducted breakdown spectroscopy, LIBS)技术具有多成分同时探测分析、 快速、 在线定性分析及定量检测等特点, 已广泛用于生物组织识别[6]、 食品检测安全[7]、 土壤养分检测[8]、 生命医学分析[9]等领域。 在水稻产地溯源研究方面, 在前期农作物产地溯源研究基础[10, 11]上, 采用LIBS技术结合机器学习算法, 对同一品种水稻的不同水稻产地进行快速识别研究。 采用PCA对LIBS光谱数据进行数据降维并提取光谱特征量, 获得水稻产地聚类分析, 分别采用PCA-Bagged Trees、 PCA-Weighted KNN、 PCA-Quadratic SVM和PCA-Coarse Gaussian SVM四种机器学习算法, 对吉林省5个水稻产地(大安、 公主岭、 前郭、 松原、 洮儿河)进行识别。 结果表明结合LIBS技术和机器学习算法能够高精度、 高效率实现水稻产地的识别, 研究结果对水稻产地快速识别的产业化推进具有一定指导意义。
用于水稻产地识别的LIBS光谱实验装置如图1所示。 实验中激发光源为输出波长为1 064 nm的Nd∶ YAG激光器(Continuum, Power8000), 脉宽为10 ns, 重频为10 Hz, 光束直径为8 mm, 最大输出能量为1.1 J。 激光光束经能量调节系统(由半波片和格兰棱镜组成)后, 由熔石英玻璃透镜L1(焦距为120 mm)聚焦在水稻样品表面。 实验中, 激光脉冲能量为120 mJ, 样品表面处的激光光束半径为40 μ m。 水稻LIBS光谱由与激光入射方向45° 的熔石英透镜L2(焦距为75 mm)收集, 耦合经光纤传输到配有ICCD探测器(1 024× 1 024 pixel, DH334)的中阶梯光栅光谱仪(Andor, Me5000)进行LIBS光谱检测。 通过数字脉冲延时发生器(DG645, 美国Standford)同步控制YAG激光器和ICCD探测器工作, 设置ICCD探测器的探测延时和探测时间门宽分别为0.5和7 μ s, 在相同实验条件下, 获得五个产地的水稻LIBS光谱信号。 实验过程中, 为了防止水稻样品表面过度激光烧蚀, 将压制成片的水稻样品固定在三维平移台上“ 弓” 状匀速运动, 使每发激光脉冲作用在新的位置。 为了降低激光脉冲能量抖动对水稻LIBS光谱稳定性的影响, 采用100个脉冲进行LIBS光谱平均。 实验工作是在标准大气压、 室内温度为25 ℃、 空气相对湿度为35%的环境下开展。
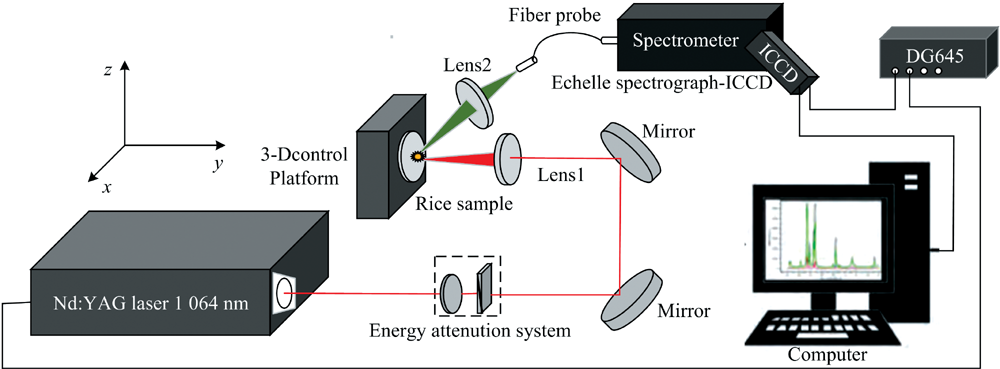 | 图1 激光诱导击穿水稻光谱实验装置Fig.1 Schematic diagram of the experimental setup of laser induced breakdown rice spectroscopy |
水稻样品分别来自吉林省大安(DA)、 公主岭(GZL)、 前郭(QG)、 松原(SY)、 洮儿河(TEH)等五个产地2021年生产的新稻, 水稻品种为吉林农科院研制的吉农816稻种。 水稻样品制备流程如图2所示, 将水稻去皮并用蒸馏水洗净后放进烘干机烘干, 使用振动研磨机(PrepM-01)将去皮后的水稻研磨至粉末, 由100目的筛子过筛, 使用压片机(FW-40)在25 MPa压力下压制25 min, 制成ϕ 30 mm× 2.5 mm的圆形水稻样品, 用于水稻产地识别的实验研究。 最终得到5个产地水稻的450组样本数据(DA、 GZL、 QG、 SY、 TEH各为90组)。
 | 图2 水稻样品制备流程图Fig.2 Rice sample preparation flowchart |
基于LIBS光谱技术结合机器学习算法实现水稻产地识别, 需要考虑水稻LIBS光谱整体数据。 由于水稻LIBS光谱的整体光谱数据维数高且结构复杂, 并存在大量的噪声等冗杂信息, 进而加大机器学习算法的运行时间和空间复杂度, 导致算法性能大幅度下降, 因此挑选特征谱线代替水稻LIBS全光谱数据显得至关重要[12]。 水稻LIBS光谱由线状光谱叠加在连续光谱上构成, 采用卷积(Savitzky-Golay, S-G)滤波器来进行卷积平滑滤波, 降低背景连续光谱, 提高水稻LIBS光谱的信背比。 在进行S-G卷积平滑滤波过程中, 平滑多项式级数为2, 经过S-G卷积平滑滤波处理后的5个产地水稻LIBS光谱如图3所示。 水稻内的元素含量与产地土壤特性、 日照条件以及灌溉水质有关, 水稻LIBS光谱强度的差异性, 可反映出水稻的产地属性, 因此选取多条元素LIBS特征光谱信息可对水稻产地进行识别。 基于美国NIST数据库对水稻LIBS光谱的特征谱线进行元素标记, 选择满足光谱线重叠少、 峰值分立、 谱线强度大等条件的特征光谱线, 最终选择C、 Mg、 P、 Cu、 Ca、 Fe、 Na、 H、 N、 K、 O共11个元素16条特征谱线进行水稻产地识别, 选择的LIBS特征谱线如表1所示。
 | 图3 水稻LIBS光谱(产地依次为大安、 公主岭、 前郭、 松原、 洮儿河)Fig.3 LIBS spectra of rice (the rice originsare DA, GZL, QG, SY, TEH) |
| 表1 水稻LIBS特征谱线 Table 1 Characteristic spectral lines of rice LIBS |
在实验过程中, 受到激光脉冲能量抖动、 空气流动和样品压制不均匀等因素影响, 导致水稻LIBS光谱谱线强度间绝对值存在一定的差异, 从而削弱谱线强度相对低的元素作用。 为实现不同元素特征谱线间的对比, 对水稻LIBS光谱中选择11个元素16条特征谱线进行归一化处理, 运用公式xscale=
在进行水稻产地聚类分析过程中, 由于LIBS特征光谱谱线数据变量之间具有强相关性, 导致LIBS特征信息重叠从而降低水稻产地聚类分析精度。 主成分分析(principal component analysis, PCA)是将相关的变量综合为一个或少数几个主成分的非监督学习算法[13], 因此采用PCA对水稻LIBS的选择16条元素特征谱线进行降维, 除去水稻LIBS光谱中相关性较强的多余特征信息[14], 从而实现水稻产地聚类分析, 为水稻产地的识别奠定基础。 首先基于PCA方法对5个水稻产地的水稻LIBS光谱中选择的11种元素的16条特征谱线进行降维, 获得PC1、 PC1、 PC2、 PC3、 …、 PC16等16个主成分参量, 前12个主成分的贡献率和累积贡献率如图4(a)所示, 前3个主成分PC1、 PC2和PC3的累积贡献率之和为77%, 前8个主成分的累积贡献率之和为94.1%。 由PC1, PC2和PC3组成的水稻产地聚类分析散点如图4(b)所示, 其中每种颜色的散点代表一个水稻产地。 由图4(b)可知, 同产地水稻样品的LIBS光谱特征谱线经PCA降维后集中在一定范围的空间区域, 具有较好的聚类集群分布。 结果表明大安(DA)、 公主岭(GZL)和松原(SY)等水稻产地的聚类性较好, 而前郭(QG)和洮儿河(TEH)水稻产地有些分散。 其中QG和DA聚类空间有所重叠, 而TEH与GZL以及SY聚类空间有所重叠。 这说明由PCA降维得到的主成分数据能够表征水稻产地信息, 并且能对水稻产地进行有效识别。
 | 图4 PCA主成分贡献率及水稻产地聚类分析 (a): PCA主成分贡献率; (b): 水稻产地聚类分析图Fig.4 Contribution rate of the PCA components and rice origin cluster analysis (a): Contribution rate of the PCA components; (b): Rice originclusteranalysis |
水稻LIBS光谱数据经PCA降维后, 由水稻产地聚类分析结果表明, 部分产地聚类有一定的空间重叠, 不能有效分开, 因此需要结合机器学习算法来对水稻产地进行精确快速识别。 用PCA对5个产地的水稻LIBS光谱(每个产地水稻LIBS光谱为90组, 共有450组)进行光谱数据降维处理, 得到前三个主成分PC1、 PC2和PC3的累积贡献率之和达到77%, 同时由PC1、 PC2和PC3组成的散点图能够说明五个产地的水稻有较好的聚类集群分布。 利用PC1、 PC2、 PC3、 …、 PC8代替水稻LIBS特征谱线, 从而构建得到不同产地水稻LIBS光谱的特征向量。 5个水稻产地构建共有450× 8数据矩阵分别作为Bagged Trees、 Weighted KNN、 Quadratic SVM、 Coarse Gaussian SVM等四种机器学习算法的水稻LIBS光谱特征输入量, 水稻LIBS光谱训练集和测试集的划分比例为8∶ 2随机分配, 采用5倍交叉验证[15]的方式对水稻产地识别模型进行参数优化和评估, 最后给出混淆矩阵表示水稻产地识别结果, 结果分别如图5(a— d)所示。
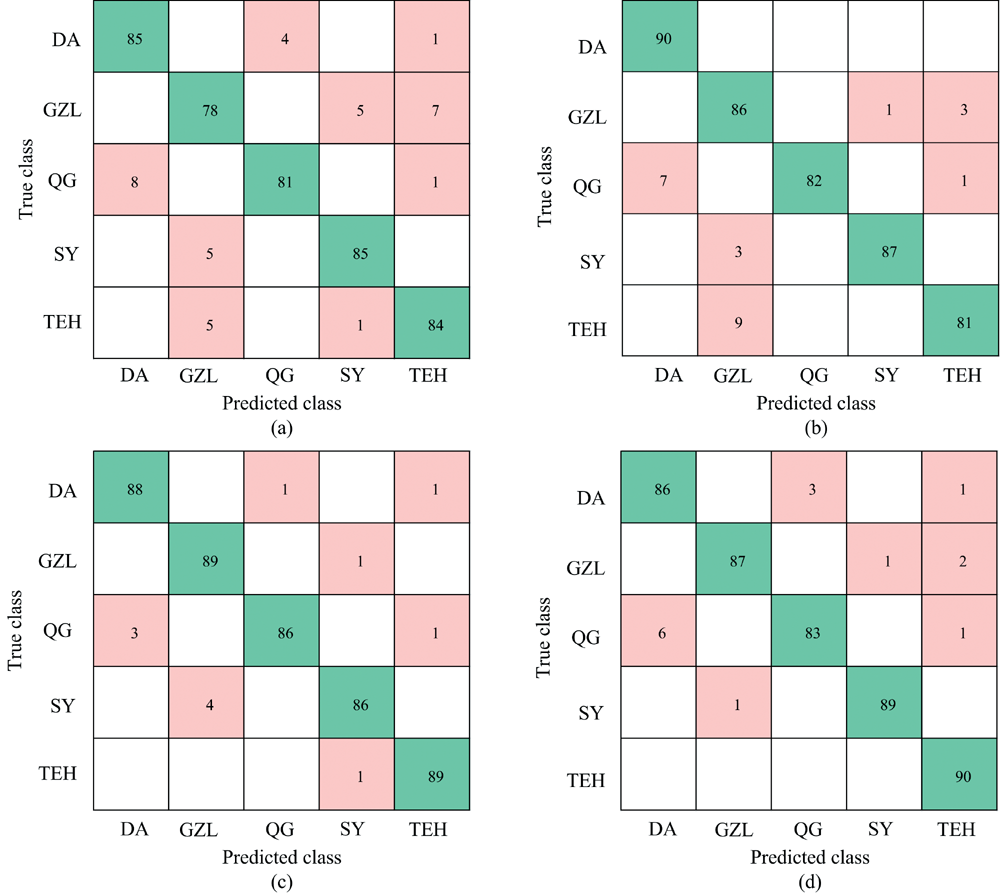 | 图5 结合LIBS和机器学习的水稻产地识别混淆矩阵 (a): PCA-Bagged Trees; (b): PCA-Weighted KNN; (c): PCA-Quadratic SVM; (d): PCA-Coarse Gaussian SVMFig.5 Rice origin identification confusion matrix combining LIBS and machine learning (a): PCA-Bagged Trees; (b): PCA-Weighted KNN; (c): PCA-Quadratic SVM; (d): PCA-Coarse Gaussian SVM |
基于PCA-Bagged Trees、 PCA-Weighted KNN、 PCA-Quadratic SVM和PCA-Coarse Gaussian SVM等四种机器学习算法对五个产地的水稻产地进行识别, 水稻产地的识别精度和机器学习训练时间结果如表2所示。 由图5可知, PCA-Bagged Trees、 PCA-Weighted KNN、 PCA-Quadratic SVM和PCA-Coarse Gaussian SVM这四种水稻产地识别模型对水稻产地的识别均存在误判现象, 其中QG被误判识别为DA, SY被误判识别为GZL, 与水稻产地聚类分析结果相符。 由表2可知, PCA-Bagged Trees、 PCA-Weighted KNN、 PCA-Quadratic SVM和PCA-Coarse Gaussian SVM这四种水稻产地识别模型精度均超过91.8%, 并且PCA-Quadratic SVM模型的识别精度高达97.3%, 结果表明结合LIBS技术和机器学习算法能够高精度和高效率实现水稻产地的识别。
| 表2 水稻产地识别机器学习算法模型结果对比 Table 2 Rice origin identification results comparison of machine learning algorithm models |
经过PCA降维结合Quadratic SVM和Coarse Gaussian SVM算法相比PCA结合Bagged Trees和Weighted KNN算法在水稻产地的识别精度和训练时间方面更优, 分析认为SVM机器学习算法能够将水稻LIBS光谱数据映射到高维的特征空间, 使反映水稻产地的样本数据在特征空间内线性可分, 从而达到高精度的水稻产地识别[16]。
结合LIBS光谱技术和PCA-Bagged Trees、 PCA-Weighted KNN、 PCA-Quadratic SVM和PCA-Coarse Gaussian SVM四种机器学习算法对同一水稻品种的五个水稻产地进行了识别研究。 基于主成分分析对水稻LIBS光谱进行降维, 获得水稻产地聚类分析散点图, 发现具有较好的空间聚类效果, 而QG与DA水稻产地、 TEH与GZL以及SY水稻聚类空间有小部分重叠。 在水稻LIBS光谱的PCA数据处理基础上, 运用PCA-Bagged Trees、 PCA-Weighted KNN、 PCA-Quadratic SVM和PCA-Coarse Gaussian SVM四种水稻产地识别模型对5个产地共450组水稻LIBS光谱数据进行了水稻产地识别, 精度都超过91.8%, PCA-Quadratic SVM模型的识别精度高达97.3%, 结果表明结合LIBS技术和机器学习算法能够高精度和高效率实现水稻产地的识别。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|