





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
中红外光谱双重校验异常样本检测方法研究
[张朱珊莹1, 2, 3  , 张若静
, 张若静1, 2, 3 , 顾瀚文5 , 谢勤岚1, 2, 3, * , 张献文4, * , 撒继铭5 , 刘繄6, 3 ]
, 张若静, 张献文, 撒继铭|
|


作者简介: 张朱珊莹, 女, 1982年生, 中南民族大学生物医学工程学院讲师 e-mail: syzhu@mail.scuec.edu.cn
中红外吸收光谱法目前最有前途的无创血糖检测技术之一。 中红外吸收光谱的血糖浓度检测结果准确性与光谱信号的可靠性密切相关。 采集中红外光谱信号的过程易受环境或人为等因素的影响而产生包含大量干扰信息的异常光谱。 异常样本存在会降低预测模型的有效性和可靠性, 故异常样本的检测和剔除至关重要。 本研究提出双重校验异常样本检测法能够将异常样本准确筛选出来并剔除。 本算法分为两个阶段, 首先利用蒙特卡洛交叉验证异常样本检测, 初步筛选异常样本, 提高光谱样本集的稳定性; 其次以马氏距离平方近似服从卡方分布为理论基础, 自适应确定最优阈值, 对剩余数据集进行异常样本再识别。 以64份包含葡萄糖、 白蛋白、 尿素、 乳酸、 果糖、 胆固醇在内的葡萄糖混合仿体溶液样本为研究对象。 双重校验法首先利用预测误差平方和对异常样本敏感的特性对光谱数据集中的异常样本进行初步判定, 共检测出3个异常样本, 从光谱数据集中剔除检测出的异常样本后建立PLS校正模型, 该模型的相关系数为0.91, RMSECV为60.17 mg·dL-1。 其次, 双重校验法以马氏距离平方近似服从卡方分布为理论基础, 实现异常样本自适应识别。 共检测出了12个异常样本, 剔除全部异常样本后构建的PLS模型性能得到了提升, 相关系数达到0.99, RMSECV达到57.77 mg·dL-1。 通过与无异常样本剔除、 PCA-MD法、 蒙特卡洛法相比较双重校验法结果最优, 证明了本算法在异常样本检测上的优越性。 与未剔除异常样本时的PLS模型相比, 相关系数从0.86上升到了0.99, RMSECV从67.51 mg·dL-1降低至57.77 mg·dL-1, 分别提升了15.12%、 14.42%。 本研究针对异常样本检测方法中易受阈值影响而出现正常样本误检或异常样本漏检的问题给出了很好的解决策略, 该方法能够准确检测并剔除异常样本, 进而提高预测模型的精度和预测性能。 为中红外光谱数据集异常样本的准确剔除提供了一种思路。
, ZHANG Ruo-jing, ZHANG Xian-wen, SA Ji-mingMid-infrared absorption spectroscopy is one of the most promising non-invasive blood glucose measurement techniques. The accuracy of blood glucose concentration measurement results of the mid-infrared absorption spectrum is closely related to the reliability of spectral signals. However, collecting mid-infrared spectral signals is susceptible to environmental or human factors, and an anomaly spectrum containing a large amount of interference information will be generated. The existence of an anomaly spectrum will reduce the effectiveness and reliability of the prediction model, so the detection and removal of abnormal samples are crucial. This study proposes that the twin check abnormal sample detection method can accurately screen and eliminate abnormal samples. This algorithm is divided into two stages. Firstly, the Monte Carlo cross-validation abnormal sample detection method is used to preliminarily screen abnormal samples and improve the stability of the spectral sample set. Secondly, based on the theory that Mahalanobis distance square approximately obeys chi-square distribution, the optimal threshold is adaptively determined, and the remaining data sets are re-identified with abnormal samples. 64 samples of the glucose-mixed imitated solution containing glucose, albumin, urea, lactic acid, fructose and cholesterol were studied. The twin check method first uses the characteristic that the sum of squared prediction errors is sensitive to abnormal samples to make a preliminary judgment on the abnormal samples in the spectral data set, and a total of 3 abnormal samples are detected. The PLS correction model is established after removing the abnormal samples from the spectral data set. The correlation coefficient of this model is 0.91, and RMSECV is 60.17 mg·dL-1. Secondly, the twin check method is based on the theory of Mahalanobis distance square approximately conforming to chi-square distribution, which realizes the adaptive identification of abnormal samples. A total of 12 abnormal samples were detected. The performance of the PLS model constructed after removing all abnormal samples was improved, with the correlation coefficient reaching 0.99 and RMSECV reaching 57.77 mg·dL-1. By comparing the results of the twin check method with the non-abnormal sample removal, PCA-MD method and Monte Carlo method, the superiority of this algorithm in abnormal sample detection is proved. Compared with the PLS model without removing abnormal samples, the correlation coefficient increased from 0.86 to 0.99, and RMSECV decreased from 67.51 to 57.77 mg·dL-1, increasing by 15.12% and 14.42%, respectively. This study provides a good solution strategy for the problem of false detection of normal samples or missing detection of abnormal samples due to the easy influence of threshold of existing abnormal sample detection methods, which is conducive to the method's accurate detection and elimination of abnormal samples, thus improving the accuracy and prediction performance of the prediction model. This method provides a way to eliminate the abnormal samples of mid-infrared absorption spectrum accurately.
中红外吸收光谱因其具有葡萄糖指纹吸收区能够实现葡萄糖的定量分析而被认为是无创血糖检测领域最有前途的技术之一[1]。 由于背景干扰、 分子基团多样性导致的光谱谱峰重叠等因素, 使基于中红外光谱技术的血糖检测在临床应用上存在较大的误差与困难。 目前具有高准确度的中红外无创血糖检测仪器尚不存在。
基于中红外吸收光谱血糖检测结果的准确性与光谱信号的可靠性密切相关, 故甄别所测得的光谱信号, 剔除异常样本, 能够提高校正模型关联有效样本信息的能力, 从而构建稳健的校正模型[2], 并提高检测准确度。 目前异常样本检测已存在多种经典检测方法, 如马氏距离法、 杠杆值与学生化残差法以及光谱残差法等, 初步满足了剔除异常样本的需求[3, 4]。 为了更准确地识别异常样本, 许多学者采用稳健回归估计避免异常样本对校正模型稳定性的影响, 提高了多元校正模型的准确性[5]。 然而, 掩蔽效应可能会导致异常样本检测方法发生误检或漏检问题, 即异常样本的检测失败或者正常样本被错误识别为异常样本[6, 7]。 因此有研究借鉴了模型集成思想, 利用蒙特卡洛交叉验证建立一系列模型, 考虑异常样本在正常校正模型与异常校正模型中的不同分布, 提出了基于蒙特卡洛交叉验证的异常样本检测方法(Monte Carlo cross validation, MCCV), 降低了掩蔽效应的风险[7, 8]。 Jiang等利用多元校正模型对异常样本的敏感性这一特性, 结合蒙特卡洛采样方法建立大量模型, 利用预测误差平方和对异常样本的响应机制检测异常样本[9]。 研究结果表明, 预测误差平方和更大的校正模型中存在异常样本的概率更高, 相比于基于留一交叉验证的异常样本检测[10], 具有较好的检测异常样本的能力。
相比于经典异常样本检测与基于稳健回归估计的异常样本检测方法, 蒙特卡洛交叉验证异常样本检测法对异常样本的识别准确性更高, 是一种更为有效的异常样本检测方法。 然而, 该异常样本检测方法引入了随机性, 使得在迭代次数较低的时候难以保证异常样本检测结果的准确性与稳定性。 此外, 异常样本检测方法的关键在于判定阈值的合理设置, 通常选择大于阈值的样本作为异常样本。 虽然每种异常样本检测方法自身具有相应的阈值选择策略, 但不同光谱数据集的特性不同, 使得处于阈值附近的样本可能存在误检现象, 降低了异常样本检测方法的可靠性。
本研究提出了双重校验异常样本检测法, 首先采用蒙特卡洛交叉验证异常样本检测方法解决稳健性较低的问题, 然后针对主流异常样本检测方法的阈值易受人为因素影响, 通过采用卡方分布实现异常样本最优阈值自适应。 并与不同异常样本检测方法相比较, 证明了该方法在异常样本检测上的优越性。
1.1.1 样本制备
在文献[11, 12]的基础上, 采用母液配制法制备了64份包含葡萄糖、 白蛋白、 尿素、 乳酸、 果糖、 胆固醇在内的葡萄糖混合仿体溶液样本, 各组分的浓度范围及浓度梯度如表1所示。 为确保仿体溶液样本的代表性以及小样本实验的鲁棒性, 所有仿体溶液样本中各分析物的浓度大小利用Minitab依据因子设计进行随机分配。 制备的葡萄糖仿体溶液样本共包含13个葡萄糖浓度, 每个浓度之间相差20 mg· dL-1, 其他成分的浓度范围如表1所示。
| 表1 各组分浓度范围及浓度梯度 Table 1 Concentration range of each component and concentration gradient |
1.1.2 光谱测量
采用Bruker公司的INVENIO-R光谱仪对不同葡萄糖浓度的仿体溶液样本进行中红外光谱数据采集, 测量方式为衰减全反射。 光谱采集范围为4 500~400 cm-1, 扫描16次后取平均值, 分辨率为2 cm-1。
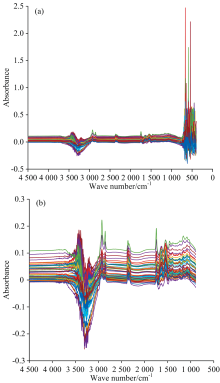
64个葡萄糖仿体溶液样本中红外吸收光谱图如图1(a)所示。 从图1(a)中能够看出, 890~400 cm-1之间存在大量的光谱噪声和仪器噪声。 将该光谱区间从原始光谱信号中去除, 采用4 500~890 cm-1范围内的光谱信号进行分析与研究, 如图1(b)所示。
 | 图1 (a) 全波段吸收光谱图; (b) 4 500~890 cm-1吸收光谱图1.2 算法原理1.2.1 主成分分析-马氏距离异常样本检测Fig.1 (a) Full-band absorption spectra; (b) 4 500~890 cm-1absorption spectra |
马氏距离法(Mahalanobis distance, MD)是较为常用的异常样本检测方法[13], 衡量了样品光谱与平均光谱之间的相似度, 相似度较低的样本被识别为异常样本。 通常利用主成分分析(principal component analysis, PCA)压缩光谱矩阵, 将高维光谱信号映射至低维正交子空间中, 降低光谱信号维数, 构建有效的协方差矩阵。 因此将PCA与马氏距离法相结合可以提高马氏距离的稳定性, 降低误检或漏检发生的概率。
1.2.2 蒙特卡洛交叉验证异常样本检测
该异常样本检测方法会对所测得的光谱数据集进行多次随机划分, 构建大量互不相同的多元校正模型, 利用异常样本与正常样本在校正模型性能表达上的差异性检测异常样本。 当校正集包含异常样本时, 降低了多元校正模型的预测性能, 使测试集样本的误差平方和整体较大; 当异常样本出现在测试集上时, 多元校正模型具有正常的预测性能, 测试集中只有异常样本的误差平方和较大。 预测误差的敏感性能够在一定程度上降低掩蔽效应的危害, 使得基于蒙特卡洛交叉验证的异常样本具有较优的异常样本检测能力。 该异常检测方法的原理[14]:
(1)在全部光谱数据集上建立偏最小二乘模型, 依据交叉验证均方根误差(root mean square error of cross validation, RMSECV)确定PLS模型的最佳主成分ncomp。 RMSECV的具体计算方式为
式(1)中, y为校正集样本葡萄糖浓度的参比值,
(2)从全部光谱数据集中使用蒙特卡洛采样每次随机选择一定比例的样本作为校正集, 其余的样本作为测试集。
(3)使用校正集建立PLS模型, 主成分数设置为ncomp。
(4)使用步骤(3)建立的多元校正模型计算测试集样品的误差。
(5)重复步骤(2)至步骤(4)K次, 确保每个样本在测试集中出现多次, 使得所有样本均存在一组误差向量residual。
(6)依据式(2)和式(3)计算每个样本预测误差向量的统计特征。
式(2)和式(3)中, μ i为第i个样本误差向量的均值, σ i为第i个样本误差向量的方差, Ji为第i个样本出现在测试集中的次数。
(7)按照式(4)和式(5)计算异常样品的阈值。
(8)选择样本误差均值大于Tμ , 同时样本误差方差大于Tσ 的样本作为异常样本。
1.2.3 双重校验异常样本检测法
该异常样本检测方法包含两个阶段: 第一阶段利用MCCV法剔除远离阈值的样本, 完成对异常样本的初步筛选, 提升光谱数据集的总体稳定性; 在第二阶段, 以卡方分布为理论基础, 自适应确定最优阈值, 对剩余数据集进行异常样本再识别。 文献[15]指出马氏距离的平方近似服从卡方分布。 为了降低阈值选择的不确定性, 提高异常样本判别的准确性, 对阈值的选择策略进行改进, 借助卡方分布确定最优阈值的综合推导, 避免人为设定阈值导致误检或漏检, 实现光谱数据集中异常样本的自适应检测。 双重校验算法的原理框图如图2所示, 每个阶段的主要步骤如下:
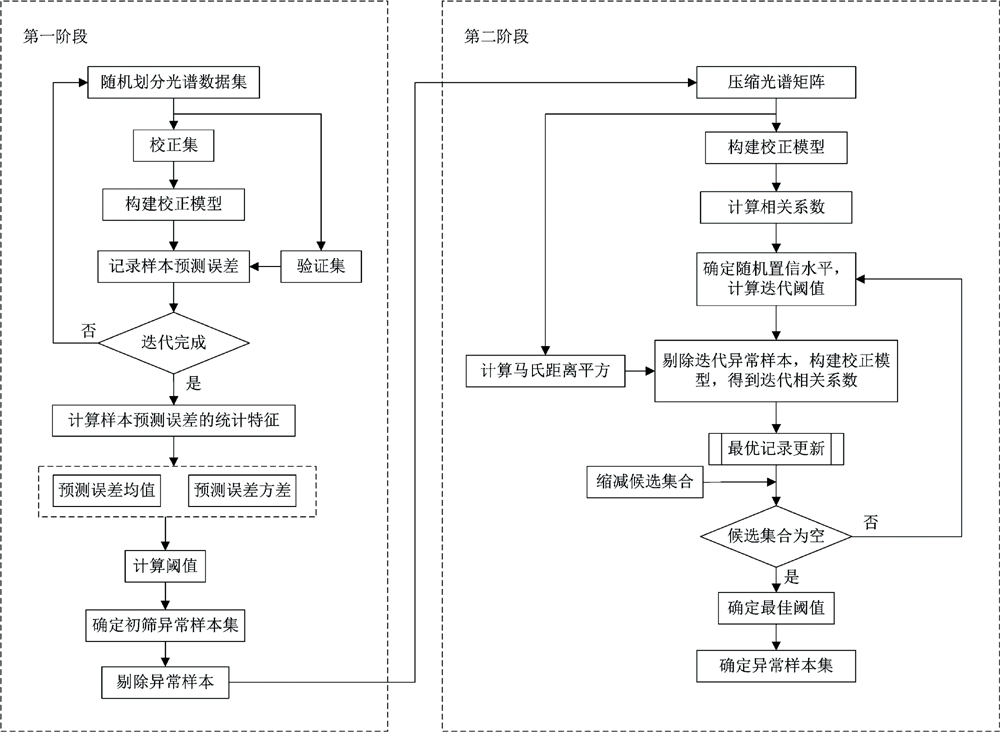 | 图2 双重校验异常样本检测法原理框图Fig.2 Principle block diagram of twin check abnormal sample detection method |
(1)第一阶段
①利用蒙特卡洛异常样本检测方法识别原始数据集中的异常样本。
②从原始数据集中剔除步骤①中识别出的异常样本, 得到新的数据集Qs。
(2)第二阶段
①在数据集Qs上构建PLS校正模型, 计算相关系数(记为R), 计算公式为
式(6)中, y为校正集或者测试集样本葡萄糖浓度的参比值,
②采用PCA对样本集Qs进行降维, 得到压缩后的样本集
③计算数据集
④搜索最优置信水平α opt。
⑤通过α opt确定阈值, 正常样本的识别区间通过椭圆区域确定, 表示为
式(7)中,
⑥将马氏距离的平方大于阈值的样本判别为异常样本。
其中, 在第二阶段中搜索最优置信水平α opt的步骤如下:
(1)从置信水平候选集Vα 中随机选择一个置信水平α * 。
(2)剔除α * 对应阈值下识别出的异常样本后建立校正模型, 记为PLSα 。
(3)比较PLSα 与最优模型的性能以判断是否更新最优记录。
为了高效地实现最优记录的准确更新, 通过以下三种策略更新置信水平候选集、 搜索最优置信水平, 从而确定最优阈值。
(1)策略一
若Rα > Ropt, 则引入高低水位置信水平以避免发生正常样本的误检。 低水位置信水平与高水位置信水平分别表示为α low与α up, 且满足式(9)
从样本集
①若
②若
(2)策略二
若Rα =Ropt, 则令式(11)成立
(3)策略三
若Rα < Ropt, 则最优置信水平以概率p更新, 则式(12)和式(13)成立
其中, 式(12)与式(13)中的概率的定义如式(14)
式(14)中, Ni为第i次迭代次数, N为总迭代次数。
图3为策略一的原理示意图, 蓝色圆点代表正常样本, 粉色矩形点代表异常样本, 红色虚线代表阈值线, 位于阈值线上方的点代表双重校验法识别出的异常样本。 策略一中搜索到更优的置信水平后, 通过该阈值所识别的异常样本中依然存在包含正常样本的可能性, 导致正常样本被错误识别为异常样本, 如图3中低阈值对应的情况。 因而剔除高低水位置信水平对应阈值之间的样本, 构建PLS模型, 对识别出的异常样本进行双重校验。 若存在误检样本, 则双重校验过程得到的 PLS 模型的性能较原 PLS 模型性能较差, 从置信水平候选集中移除小于低水位置信水平的值, 缩减解空间, 避免无效置信水平的搜索, 减少迭代次数, 提高最优置信水平搜索过程的收敛速度。
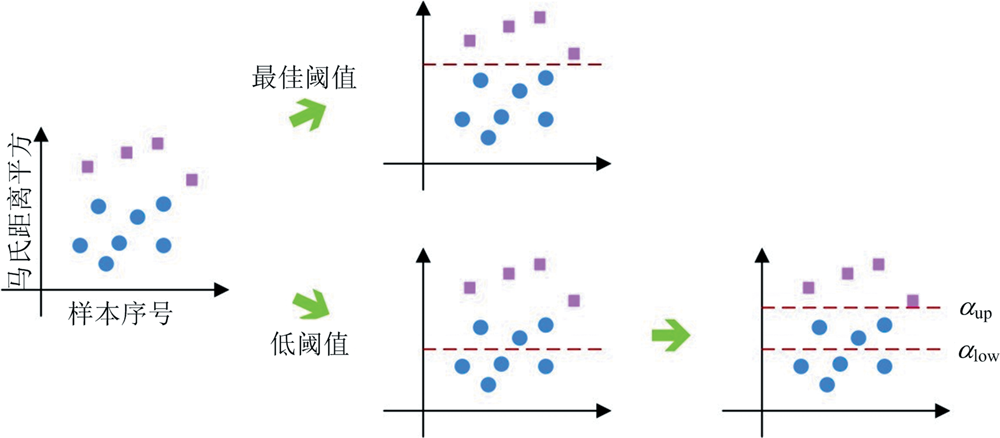 | 图3 策略一示意图Fig.3 The diagram of strategy one |
观察式(9)— 式(13)可知, 在最优置信水平搜索过程的起始阶段, 较大的解空间以及随机性的引入有较大的概率发生低阈值现象如图3所示, 使得正常样本被错误识别为异常样本, 因此通过策略一避免低阈值现象的发生。 同时, 在双重校验法的起始阶段对搜索过程中产生的较差置信水平采取一定的容忍度, 增强解空间的搜索范围, 避免陷入局部最优。 随着迭代过程的推进, 异常样本检测结果趋于稳定, 其包含正常样本的概率逐渐降低, 最优阈值被更新为较差阈值的概率亦随之降低, 确保异常样本检测结果的准确性。
本方法利用快速选择思想控制候选集的收缩, 实现最优置信水平的更新。 在随机选择α * 后, 下一步是确定α * 是否能够被接受以更新α opt。 分别构建α * 与α opt置信水平下的PLS模型, 计算其相关系数, 记为Rα 与Ropt。 若Rα 更大, 则通过策略一进行双重校验避免正常样本的误检; 若Ropt更大, 则以概率p控制最优记录的更新; 若两者相同, α opt被更新为更高的置信水平, 以降低被识别为异常样本的数量。 直至候选集为空集, α opt的搜索过程结束。
实验使用SIMPLS算法构建PLS校正模型, 并采用留一交叉验证估计矫正模型的RMSECV。 所有代码和计算均在Matlab R2019b中完成, CPU为Intel Core i5-10400F, RAM大小为16 GB。
双重校验法的第一阶段是对光谱数据集中的异常样本进行初步判定。 第一阶段存在两个参数, 分别为采样比例和采样次数, 因此对该方法进行参数初始化: 采样比例设置为80%, 采样次数设置为1 000。 以预测误差均值为横坐标、 预测误差标准差为纵坐标画出各样本预测误差统计量的均值-方差图, 如图4所示。 图4中虚线代表阈值线, 红点代表该阶段检测出的异常样本。 从图4中能够看出, 33号、 49号、 62号样本的预测误差均值偏离阈值程度较为明显, 未发现预测误差标准差大于阈值的样本。 由此可得, 双重校验法第一阶段共检测出的3个异常样本, 分别为33号、 49号、 62号样本。 从光谱数据集中剔除第一阶段检测出的异常样本后建立PLS校正模型, 该模型的相关系数为0.91, RMSECV为60.17 mg· dL-1。
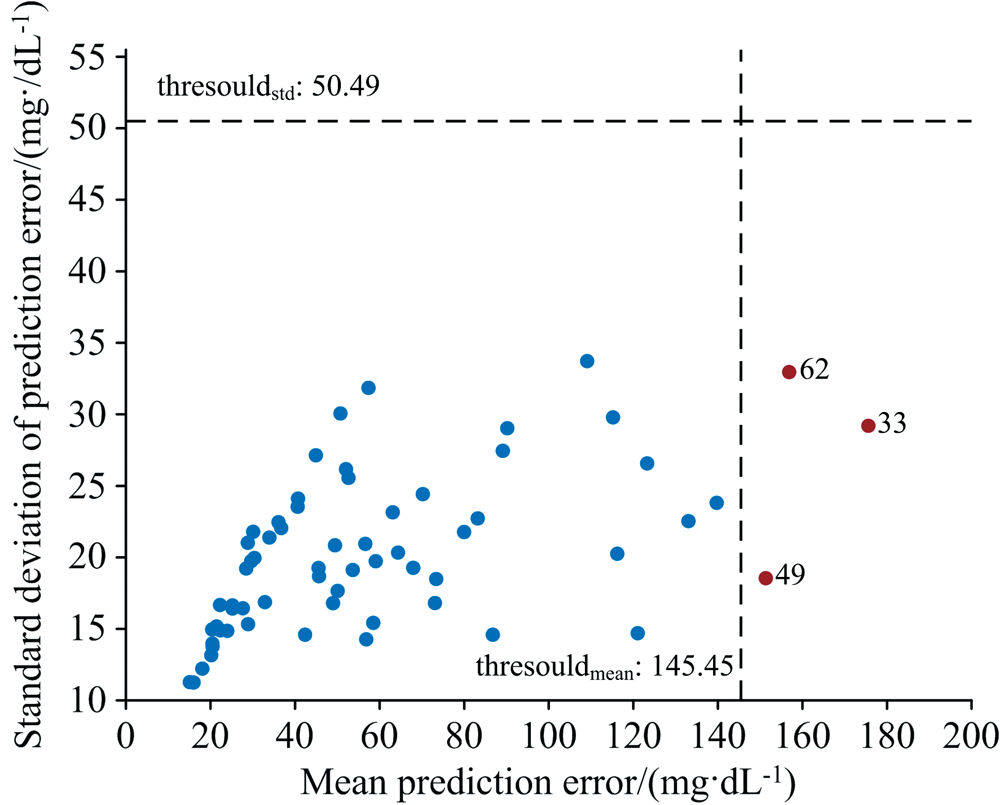 | 图4 样本预测误差均值-方差图Fig.4 Mean-variance plot of sample prediction error |
对剔除33号、 49号、 62号样本后的光谱数据集进行 PCA 降维, 以确定适合的主成分数量, 提取其映射数据后计算各光谱信号的马氏距离的平方。 图5为各主成分方差贡献率Pareto图。 从图5中能够看出, 第一主成分的方差贡献率为78.54%, 占有原光谱信息矩阵的绝大部分信息量, 其与第二、 第三主成分累计方差贡献率共达到了99.31%, 表明前三个主成分占有原光谱信号的大部分信息量, 将其映射数据作为计算马氏距离平方的光谱数据。
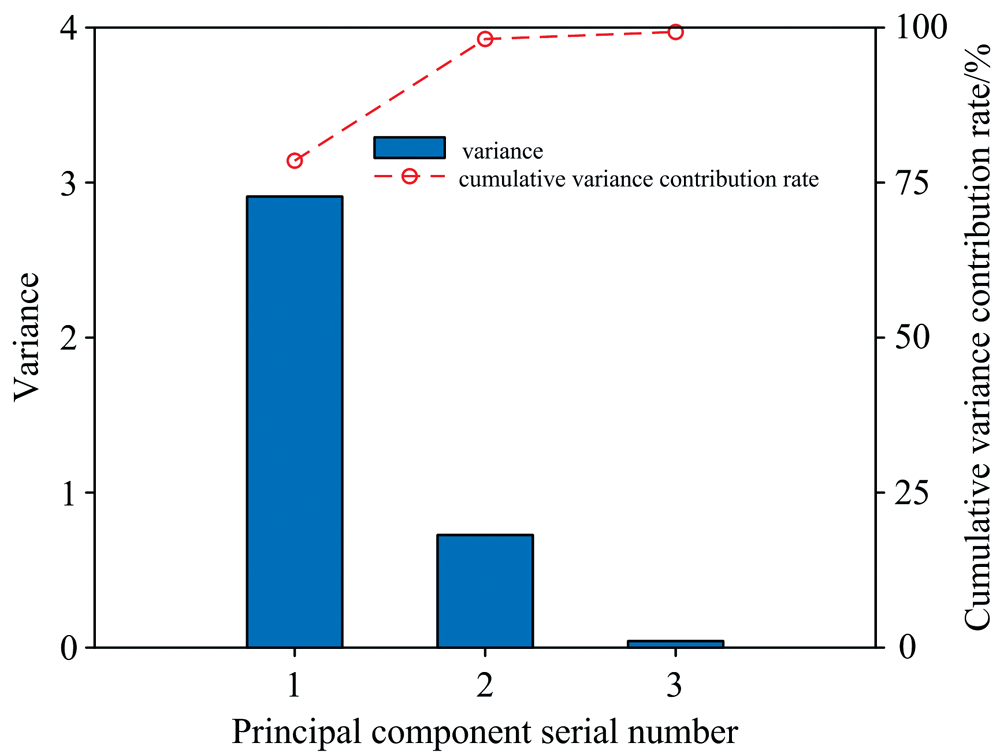 | 图5 主成分方差贡献率Pareto图Fig.5 Principal component variance contribution rate Pareto plot |
为了确定第二阶段异常样本判定的最优阈值, 最优置信水平的候选集的范围被设置为[68.3%∶ 0.1%∶ 99%]。 图6与图7共同展示了该异常样本检测算法在迭代过程中候选集合随迭代次数变化而变化的情况。 若在迭代过程中置信水平存在于候选集合, 则在图6中用圆点标记。 图7的散点图代表候选集合的大小, 散点的拟合曲线用红色虚线表示。
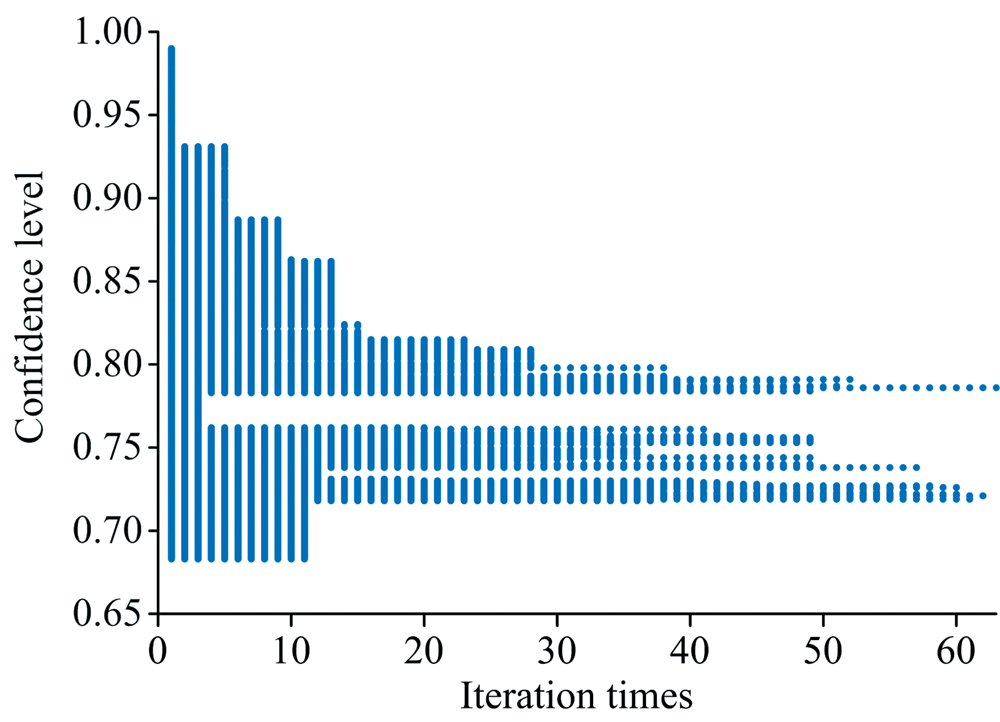 | 图6 置信水平候选集元素随迭代次数变化曲线Fig.6 Confidence level candidate set elements curve withiteration times |
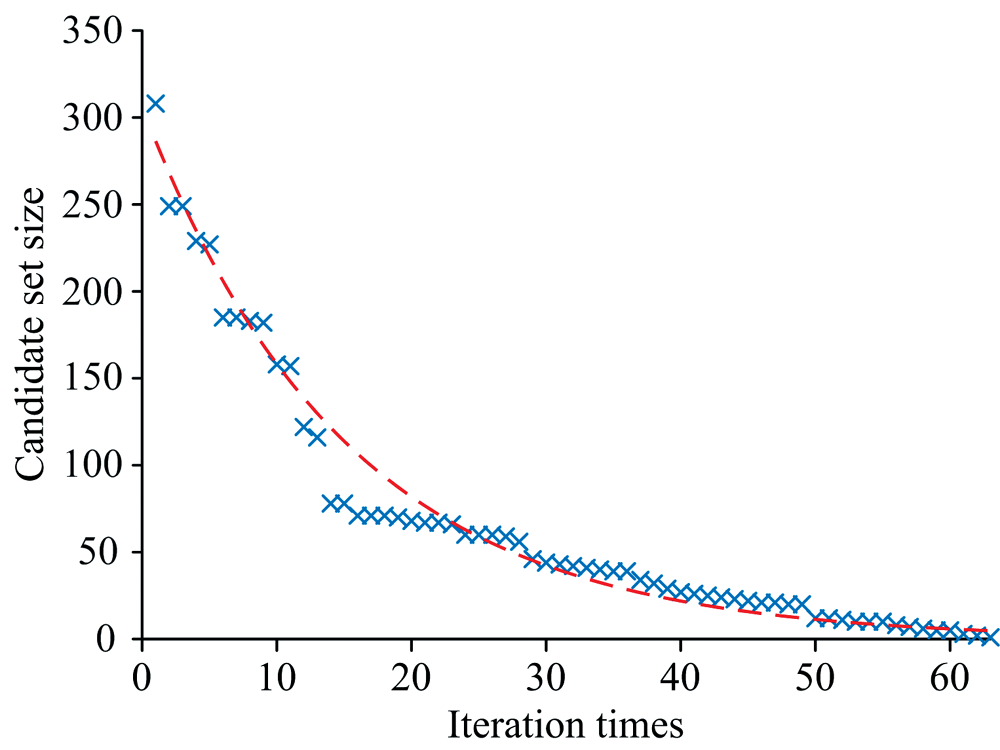 | 图7 置信水平候选集大小随迭代次数变化曲线Fig.7 Confidence level candidate set size curve with iteration times |
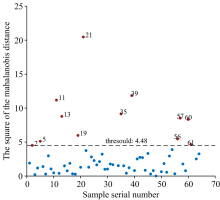
由图6图7知, 在迭代起始阶段, 最优置信水平的解空间较大, 策略一在保证最优阈值搜索准确性的同时快速剔除了置信水平候选集中的无效置信水平, 提高了双重校验法的收敛速度。 随着迭代过程的推进, 无效置信水平的占比逐渐趋于零, 最优置信水平的搜索速度变缓, 确定的最优置信水平为78.6%, 得到双重校验法第二阶段的最优阈值为4.48, 得到异常检测结果如图8示, 其中虚线为阈值线, 异常样本被标识为红色。
 | 图8 样本马氏距离平方散点图Fig.8 Sample Mahalanobis distance squared scatter plot |
由图8知, 双重校验法在第二阶段共检测出了12个异常样本。 结合该异常样本检测方法的两个阶段, 该异常样本检测算法共检测出15个异常样本。 剔除全部的异常样本, 建立PLS校正模型以验证双重校验法的有效性, 得到校正模型的相关系数、 RMSECV值。 并与无异常样本剔除、 PCA-MD法、 蒙特卡洛法相比较, 如表2所示。
| 表2 剔除不同异常样本检测方法的识别结果后PLS模型性能指标 Table 2 The performance index of PLS model after eliminating the recognition results of different abnormal sample detection methods |
表2可以得出, 双重校验法剔除全部异常样本后构建的PLS模型性能最优, 相关系数达到0.99, RMSECV达到57.77 mg· dL-1。 与未剔除异常样本时的PLS模型相比, 相关系数从0.86上升到了0.99, RMSECV从67.51 mg· dL-1 降低至57.77 mg· dL-1, 分别提升了15.12%、 14.42%。
提出了异常样本双重校验法用来检测和剔除异常的光谱数据。 利用该方法对64个葡萄糖混合仿体溶液进行异常样本的检测。 首先, 利用蒙特卡洛交叉验证异常样本检测法, 初步筛选出3个异常样本。 其次以马氏距离平方近似服从卡方分布为理论基础, 自适应确定最优阈值, 对剩余数据集进行异常样本再识别, 共检测出了12个异常样本, 完成异常样本的精细筛选。 从原始光谱中剔除全部异常样本后构建 PLS 校正模型以验证双重校验法的有效性, 得到校正模型的相关系数为0.99、 RMSECV为57.77 mg· dL-1。 并与无异常样本剔除、 PCA-MD法、 蒙特卡洛法相比较。 研究结果表明, 双重检验异常样本检测法的有效性以及准确性更高, 剔除该方法识别出的异常样本后构建的校正模型性能最优。 本研究为中红外光谱数据处理时异常样本的检测提供一种方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|