{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于可见光谱特征波长提取和分类算法的柑橘黄龙病快检研究
[邱鸿霖1  , 刘天元
, 刘天元1, * , 孔丽丽1, 3 , 于新娜1 , 王贤达2, * , 黄梅珍1 ]
, 刘天元, 孔丽丽, 黄梅珍|
|


作者简介: 邱鸿霖, 1999年生, 上海交通大学电子信息与电气工程学院硕士研究生 e-mail: qhl123@sjtu.edu.cn; 1057962043@qq.com
柑橘黄龙病(HLB)是由亚洲韧皮杆菌引起的一种严重病害, 目前无法根治。 其防控具有重要意义和经济价值。 当前利用健康和患病叶片的光谱差异对其进行诊断显示了良好的应用前景。 因患病叶片在叶绿素反射区及O—H伸缩振动区的可见光谱与健康叶片存在显著差异, 而可见光谱检测在采集和数据处理方面具有成本低、 简便的优势, 研究可见光谱的黄龙病快速检测方法具有可行性和重要意义。 为了减少光谱数据冗余和计算量, 实现精准的黄龙病的早期鉴别以及降低黄龙病相似病症的误诊率, 采集了黄龙病患病地区共160个叶片样本。 经qPCR测定分别将其分类标定为健康、 轻度疾病、 重度疾病和缺镁症四类。 根据叶片样本在可见光波段450~800 nm的反射光谱特征, 通过S-G平滑以及降采样等预处理光谱数据后, 为了优选出尽可能囊括光谱特征信息的特征波长, 分别使用遗传算法(GA)、 连续投影算法(SPA)以及竞争自适应重加权采样法(CARS)对采集到的可见光谱数据进行特征波长提取和降维优选出特征波长, 进一步降低模型复杂度, 提高预测精度。 综合泛化能力及检测速度的考量, 在定性判别分析模型的选择中采用训练速度快, 分析准确率高的最小二乘支持向量机(LS-SVM)以及随机森林(RF)对两种变量筛选算法降维后的数据进行分类判别。 通过对不同的模型的验证优选, 筛选出最佳的快检方案。 对比发现, 在建立的模型中, SPA-RF模型与其他模型比较, 对于训练集和测试集的判别准确率分别达到了100%和97.5%。 结果表明, 连续投影算法以及随机森林的组合分类模型可以很好地实现黄龙病早期的病理鉴别, 同时也能够很好地识别出黄龙病病叶与其他相似病症的差异, 为柑橘黄龙病快速检测及防治提供了一种方法依据。
The Citrus Huanglongbing (HLB), caused by the Asian citrus psyllid, represents a severe disease with no current cure. Its control is of significant importance and economic value. Current diagnostic approaches utilizing the spectral differences between healthy and diseased leaves show promising applications. Diseased leaves exhibit notable differences from healthy ones in the chlorophyll reflection zone and the O—H stretching vibration region of the visible spectrum. With its low cost and simplicity in data collection and processing, the visible spectrum detection scheme presents a feasible and significant approach for the rapid detection of HLB. To reduce spectral data redundancy and computational load, achieving precise early identification of HLB and minimizing misdiagnosis of similar symptoms, this study collected 160 leaf samples from HLB-affected areas. These samples were classified into four categories—healthy, mild disease, severe disease, and magnesium deficiency-using qPCR determination. Reflecting on the characteristics of leaf samples in the visible light band (450~800 nm), the study involved preprocessing spectral data through S-G smoothing and down sampling. To select feature wavelengths that encapsulate maximum spectral information, Genetic Algorithm (GA), Successive Projections Algorithm (SPA), and Competitive Adaptive Reweighted Sampling (CARS) were employed for feature wavelength extraction and dimensionality reduction, further simplifying model complexity and enhancing prediction accuracy. Considering the generalization ability and detection speed, the study used the Least Squares Support Vector Machine (LS-SVM) and Random Forest (RF) to classify and discriminate the dimensionally-reduced data from the two variable selection algorithms. The best rapid detection scheme was selected by validating and optimising different models. -In comparison with others, the SPA-RF model achieved a discrimination accuracy of 100% and 97.5% for the training and test sets, respectively. The results demonstrate that the combination of SPA and RF in the classification model effectively accomplishes early pathological identification of HLB and distinguishes HLB-diseased leaves from similar symptoms, providing a basis for rapid detection and control of Citrus Huanglongbing.
柑橘黄龙病(Huanglongbing, HLB)又称黄梢病或黄枯病, 是由亚洲韧皮杆菌侵染引起的、 发生在柑橘上的一种毁灭性病害, 造成柑橘树枯死, 被称为“ 柑橘的癌症” 。 目前尚无根治的方法, 危害性巨大, 2020年中国农业农村部将其列入《一类农作物病虫害名录》, 黄龙病发病地区分布范围广, 在亚洲、 非洲、 大洋洲、 北美以及南美洲的50多个国家和地区都有分布。 大量实验证明, 柑橘黄龙病不可治, 但病害流行早期可通过砍除病树的方式控制传播源从而有效进行防控, 另一方面, 如何有效地将黄龙病植株与其他相似病症植株区分开以防止误砍, 也是黄龙病防治的一大重点难题。 因此, 研究建立黄龙病的快速检测方法和技术, 具有重要的意义和巨大的经济效益。 实验室病理分析和田间人工诊断是目前柑桔黄龙病的主要诊断方法。 聚合酶链式反应(polymerase chain reaction, PCR)是柑桔黄龙病的主要实验室病理分析方法, 该方法准确, 但检测速度慢、 周期长、 价格昂贵, 难以适用于大面积果园检测需求[1, 2, 3, 4]。 并且黄龙病在潜伏期特征不明显, 因缺乏营养元素而引起的黄化特征跟黄龙病的特征相似, 田间人工诊断法虽然简单易行, 但存在主观性, 判别准确率低。 当前运用健康叶片和黄龙病叶片的光谱差异对黄龙病进行诊断的研究展示了良好的应用前景而备受关注。 马淏等采用可见-近红外光谱, 建立了黄龙病线性Fisher判别模型, 模型分类精度达到90%以上[5]。 梅慧兰等对310~1 000 nm波段的健康叶片和黄龙病叶片(包括三种病情严重程度)和缺锌情况叶片的高光谱图像, 运用偏最小二乘法判别模型进行分析, 实现了96.4%的判别准确率[6]。 刘燕德等通过高光谱技术对黄龙病的快速检测方法进行了探索, 研究了不同光谱处理技术对检测结果的影响, 获得了100%的准确率[7]。 Sankaran等使用中红外光谱技术对黄龙病柑橘树叶片进行检测, 采用最近邻神经网络模型, 实现了超过95%的分类准确度[8]。
上述研究大多采用高光谱图像或者采用近红外波段的光谱数据进行研究分析, 一方面, 高光谱相机和近红外光谱仪的价格较高, 另一方面, 高光谱图像含有丰富的信息量, 但其相邻波段相关度高, 冗余信息多。 采用多段光谱拼接的方式, 在波段较多的情况下处理数据的时间会大大增加, 尤其是不加选择的采用全谱进行分析的方式, 更增加了处理复杂度和处理时间。 由于患病叶片存在光合作用受阻现象以及含水量降低的特点, 其在可见光波段的叶绿素反射区及O— H伸缩振动区与健康叶片存在明显差异。 相比其他光谱检测手段比较而言, 可见光谱具有光源和仪器价格便宜, 光谱容易采集, 数据处理简单便捷的优势。 在可见光谱数据分析中, 特征波长的选择对于简化模型、 提高计算效率和确保检测精度至关重要。 特征波长选择的核心目标是从高维光谱数据中筛选出对分类或回归任务最有信息量的波段, 从而减少数据冗余和计算负担, 同时保持甚至提高模型的预测能力。 当前已有多种变量选择方法被提出和应用, 如遗传算法、 竞争自适应加重加权采样法[9]、 灰狼算法[10]等。 为了实现黄龙病的早期诊断以及其他相似病症的诊断, 探究一种无损, 经济, 快速, 准确的黄龙病检测方法, 以实现将黄龙病植株及时砍除同时避免误砍, 本文采集了黄龙病健康、 轻症、 重症、 缺镁四类叶片的可见波段光谱。 考虑到遗传算法的全局搜索能力、 连续投影算法的简单高效以及竞争自适应重加权采样法的自适应性, 采用此三种变量筛选算法进行数据降维, 优选出特征波长, 进一步降低模型复杂度, 提高预测精度。 再利用这些筛选出的特征波长作为变量, 结合最小二乘支持向量机以及随机森林建立多种快速分类模型, 通过对不同模型的验证优选, 筛选出能够有效鉴别出黄龙病早期病征以及黄龙病相似病症的最佳检测模型, 为黄龙病在可见光波段的快速无损检测提供方法依据。
样品来自于福建农业科学院于漳州平和某果园种植基地, 2021年10月由基地专业农艺师采摘。 在园区采集间隔一定距离植株的相同冠层叶片, 将采集的叶片用封袋装好并标记, 寄到实验室后用清水冲洗干净并放置令其自然晾干后立即进行可见光谱的采集。
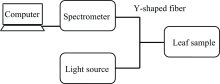
光谱数据采集系统主要由光谱仪, 光源, Y型光纤, 计算机等构成。 光源采用钨灯, 光谱仪采用美国海洋光学QE65000, 光谱范围为200~1 100 nm, 在计算机端利用其配套的软件Spectrasuite对接收到的叶片反射的可见光波段的光谱数据采集, 积分时间设置为50 ms, 扫描次数为15次, 平滑度选取为15。 光谱采集系统如图1所示。
 | 图1 光谱采集装置示意图Fig.1 Schematic diagram of spectrum acquisition device |
样品经过光谱采集以后, 由福建省农业科学院对黄龙病患病样品进行检测。 主要的方式为提取待检样品DNA, 用超微量分光光度计(NanoDrop)测定并稀释待检样品DNA浓度为50 ng· μ L-1, 置于-20 ℃冰箱保存备用。 利用上下游引物HLBas(5’ -TCGAGCGCGTATGCAATACG-3’ )、 HLBr(5’ -GCGTTATCCCGTAGAAAAAGGTAG-3’ )和TaqMan探针HLBp(5’ -AGACGGGTGAGTAACGCG-3’ , 荧光报告基团FAM、 猝灭基团BHQ1)[11]对稀释的DNA样品进行qPCR检测[12]。 qPCR反应体系为2× PrimerMix 12.5 μ L, 250 nmol· L-1的HLBas和HLBr各1 μ L, 150 nmol· L-1的HLBp 1 μ L, 待测DNA样品1 μ L, 无菌水补足至25 μ L; 扩增反应程序为94 ℃ 3 min, 94 ℃ 10 s, 58 ℃ 30 s , 同步采集荧光, 扩增42个循环, 扩增反应在Bio-rad CFX96TM PCR仪上进行, 每个反应体系设置3次重复。 样品经过检测后, 根据检测结果分为健康, 轻症, 重症三类叶片。
1.4.1 叶片光谱采集方案
利用所搭建的实验装置采集叶片的反射光谱。
根据文献报道, 处于患病初期的叶片, 其病理异常主要表现在叶脉基部。 随着病情加深, 部分叶肉褪绿, 叶脉基部和侧脉区域开始逐渐黄化, 叶片呈现不规则且大小不一的黄绿斑块[13]。 由于黄龙病的不均匀显示直接影响光谱信息, 从而影响诊断精度。 因此, 采样位置依据不同患病程度的叶片作了一定的设计。 具体方式为对于轻症叶片采集部位是叶脉根部周围区域, 而对于重症叶片采集部位是叶片的黄色部位。 每张叶片采集五个点, 求取平均值。 同时, 通过拉曼光谱方法对该采样方案进行了客观验证; 该采样方法能够尽可能收集更全面的黄龙病光谱信息, 为进一步的分析建模提供保障。 另外, 为了排除叶脉的影响, 尽可能地避开叶脉进行检测。
1.4.2 光谱处理过程
为了消除暗电流噪声等对光谱的影响, 采用如式(1)对采集的光谱数据进行计算, 获得反射率光谱。
式(1)中, R为反射率, Iλ 为叶片上所采集的光强谱, Dλ 为暗电流噪声谱, Wλ 为聚四氟乙烯白板标定的全白图像谱。
采集的过程中, 将叶片放置于表面平整的白板上, 并使叶片表面尽量平整。 将光源和光谱仪预热20分钟后, 用Y型光纤的一端连接光源, 光源发出的光通过光纤照射在叶片样品或白板上, 光被叶片或白板反射后由光纤的另一端传导到光谱仪后被检测。
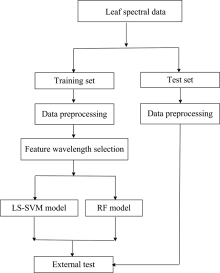
叶片光谱的处理方法如图2所示。 实验中一共筛选出160个样本, 分为健康, 轻症, 重症, 缺镁四类。 以3∶ 1的比例, 划分为训练集以及测试集。 其中, 训练集中正常, 轻症, 重症, 缺镁样本都为30个, 用于测试样本则是每种10个。 为了消除光谱中的噪声, 采用Savitzke-Golay平滑算法对光谱进行预处理, 窗口长度选择为17。 为了提取光谱数据中有关信息, 利用MATLAB中的resample函数对光谱进行降采样后采用特征波长选择的方案对其进行降维, 筛选出一组维数较小的变量。 然后分别采用最小二乘支持向量机以及随机森林算法建立判别模型, 对样品进行分类判别。
 | 图2 叶片光谱数据处理流程Fig.2 Processing flow of leaf spectral data |
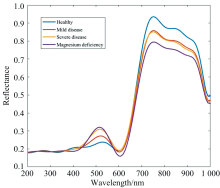
归一化后得到四类叶片的反射光谱如图3所示。
 | 图3 四类叶片的光谱特征Fig.3 Spectral characteristics of four types of leaves |
由图3可见, 四类叶片光谱的总体趋势是大致相同的。 与健康叶片相比, 患黄龙病的叶片以及缺镁叶片在波长为500~700 nm的波段之间反射率更高。 此波段恰为叶绿素的强吸收带, 由于叶绿素的缺失, 患黄龙病叶片以及缺镁叶片的光合作用受到阻碍, 故在该光谱范围内患病叶片的反射峰强于健康叶片[15]。 从680 nm开始, 为叶片的高反射率区域。 比较几类叶片的光谱数据, 最明显的差异是在720 nm附近波段, 该波段主要对应于O— H键四级倍频伸缩振动频率, 而患黄龙病的叶片的含水量降低, 故反射峰低于健康叶片, 并且随着病情程度的加重, 重度黄龙病叶片的反射峰比轻度黄龙病的反射峰更低。
1.6.1 遗传算法
遗传算法(genetic algorithm, GA)以生物进化论为基础[14], 是一种通过建立模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型, 从而模拟自然进化过程选择最优解自适应概率全局搜索方法。 该算法的主要步骤包括: 个体初始化、 适应度计算、 选择、 交叉和变异, 其中, 后四步根据初始时设定的标准交替进行, 直至最后筛选出的种群满足设定的终止标准。 选取偏最小二乘的交叉验证均方差(RMSECV)为适应度函数, RMSECV的计算公式为
式(2)中, yi为第i个样品的实际值,
1.6.2 连续投影算法
连续投影算法(successive projections algorithm, SPA)作为一种前向变量选择算法, 其目的是使矢量空间共线性最小化。 它可用于提取光谱全波段的几个特征波长, 消除原始光谱中的冗余信息, 使提取出的光谱的特征波段之间共线性最小, 能够在更少的变量数的情况下保证囊括全面的光谱特征信息。 该算法的主要做法是先选取一个波长, 作前向循环, 计算该波长对于所有未选择的波长的投影向量, 提取出具有最大投影向量的光谱波长, 如此直至循环结束。
1.6.3 竞争自适应重加权采样
竞争自适应重加权采样法(competitive adaptive reweighted sampling, CARS)是基于达尔文“ 适者生存” 提出的基于迭代统计信息的变量选择算法。 通过蒙特卡洛采样划分数据样本进行PLS建模分析, 将各波段反射率的绝对值作为权重, 通过指数递减函数对波段进行筛选, 保留回归系数绝对值权重较大的变量点作为新的子集, 同时剔除权值较小的变量点, 经过多次计算, 选出交互验证均方根误差最小的子集中的波长作为筛选波长。
1.6.4 最小二乘支持向量机
最小二乘支持向量机(least squares support vector machine, LS-SVM)[15, 16]是一种基于统计理论的支持向量机, 与传统方法相比速度更快, 并具有一定的泛化能力。 它通过非线性映射将输入变量映射到高维特征空间, 将原模型的解优化问题变为等式约束条件。 其算法的过程本质上是一个求解线性方程组的过程。 LS-SVM的函数模型由拉格朗日法求解最优化问题得到
式(3)中, α i为拉格朗日乘子, K(x, xi)为模型的核函数, b为偏差量。 采用的核函数为径向基核函数(radial basis function, RBF), 其表达式为
式(4)中, σ 为核函数的扩展常数, ‖ x-xi‖ 为样本点x与xi的距离。
1.6.5 随机森林
随机森林(random forest, RF)是由Leo Breiman(2001)提出的一种基于继承学习的组合分类器算法, 它通过自助法(bootstrap)取样技术, 从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树, 然后按以上步骤生成m棵决策树组成随机森林, 新数据的分类结果按分类树投票多少形成的分数而定。 从算法的实质上看, 它可以被视作是对决策树算法的一种改进, 通过将多个决策树合并在一起, 每棵树的建立依赖于独立抽取的样本。 由于每棵决策树所选取的特征是随机的, 这使得随机森林算法不易出现过拟合, 因此具有一定的抗噪声能力。 其通过对数据的反复训练学习, 具有分类准确率高, 分类类别没有限制的优点[17]。 除此之外, 随机森林模型所要调节的超参数少, 含义直观, 模型训练分析速度快。
由前面对四类叶片光谱特征的分析可知, 四类叶片光谱的差异主要呈现在550 nm附近以及720 nm附近, 因此, 选取可见光谱区450~800 nm为光谱分析的特征区间。
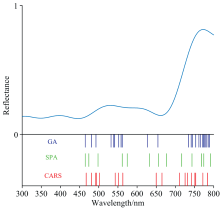
采用遗传算法对450~800 nm波段作特征波长提取, 将待筛选波长变量编码为染色体, 每个基因对应一个波长, 编码为1表示被选中, 0表示未被选中。 初代种群的规模为30, 迭代次数为100, 交叉概率为0.5, 变异概率为0.01, 以最小二乘拟合交叉验证均方根误差的倒数作为适应度函数。 在100次以后, 结果趋于稳定, 选取交叉验证均方根误差最小时对应的变量筛选出24个特征波长。 采用连续投影算法作为并行的特征波长选取方案, 运行算法时, 最大变量数选取为40, 最小变量数选取为10, 筛选出共13个特征波长变量。 并将以此几个变量作为后续判别模型输入变量。 利用CARS筛选出的18个特征波长作为后续的输入变量。 三种波长筛选算法所筛选出的特征波长如图4所示。
 | 图4 波长筛选算法筛选结果Fig.4 Wavelength screening results by different algorithms |
2.2.1 LS-SVM判别模型
最小二乘支持向量机的核函数采用径向基核函数, 径向基核函数需要优化两个参数: 正则化参数γ 以及核参数σ 2。 对此, 分别对三种变量选择算法筛选出的特征波长作为数据集, 利用LS-SVM建立判别模型。 为了降低误差, 增强模型的泛化能力, 使用PSO算法对正则化参数γ 以及最佳核参数σ 2进行优化。 表1列出了在选取相对应的最佳正则化参数以及最佳核参数下三种判别模型的误判率。 图5展示了三种模型对于40个测试集的判别结果。
| 表1 LS-SVM模型预测结果 Table 1 Prediction results of LS-SVM model |
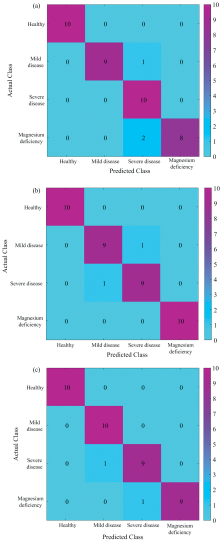
 | 图5 三类模型对测试集的判别结果 (a): GA-LS-SVM模型; (b): SPA-LS-SVM模型; (c): CARS-LS-SVM模型可以看出, GA-LS-SVM判别模型中, 有一个轻症被误判为重症, 同时有两个缺镁被误判定为重症, 对测试集的准确率达到92.5%, SPA-LS-SVM模型中, 有一个轻症被误判为重症, 另一个重症被判为轻症, 准确率达到95%。 而CARS-LS-SVM模型中, 有一个缺镁被误判为重症, 另一个重症被判为轻症, 准确率达到95%。Fig.5 Discrimination results of (a) GA-LS-SVM model; (b) SPA-LS-SVM model; (c) CARS-LS-SVM model for test sets |
2.2.2 RF判别模型
将三种变量选择算法所筛选出的特征波长变量利用随机森林算法对降维样本进行分类。 采用sklearn库中的随机森林分类树类(random forest classifier类), 同样以前文所建立模型所采用的120个样本作为训练集数据以及40个样本作为测试集数据。 单个决策树可使用的最大特征数量即选取为所得的特征变量数。 分类树属性分裂的标准采用CART算法, 所建立的随机森林的个数选取为50。 由于随机森林的抽样方法为有放回的bootstrap采样法, 因此并不能保证将所有的训练集样本全部囊括, 因此在最后的评估中, 也给出了模型对于训练集的评估能力。 图6— 图8展示了三种RF模型对于实验数据的判别结果。
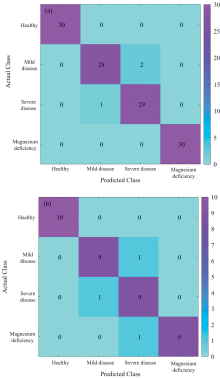
 | 图6 GA-RF模型判别结果 (a): 训练集; (b): 测试集Fig.6 Discrimination results of GA-RF model (a): Training set; (b): Test set |
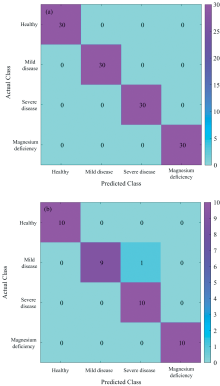
 | 图7 SPA-RF模型判别结果 (a): 训练集; (b): 测试集Fig.7 Discrimination results of SPA-RF model (a): Training set; (b): Test set |
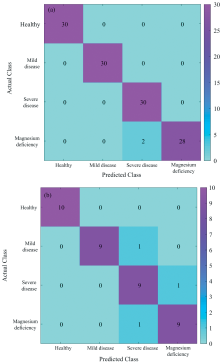
 | 图8 CARS-RF模型判别结果 (a): 训练集; (b): 测试集Fig.8 Discrimination results of CARS-RF model (a): Training set; (b): Test set |
可以看出, GA-RF模型中, 训练集中有2个轻症被判为重症, 一个重症被判为轻症, 准确率为97.5%, 测试集中有一个重症被判为轻症, 一个轻症被判为重症, 一个缺镁被判为重症, 准确率为92.5%。 SPA-RF模型中, 对于训练集的判别准确率达到了100%, 而对测试集的判别中, 仅有一个轻症被判为重症。 分类准确度达到了97.5%。 而在CARS-RF模型中, 训练集有两个缺镁被判为重症, 准确率为98.3%, 测试集中一个轻症被判为重症, 一个重症被判为缺镁, 一个缺镁被判为重症, 准确率为92.5%。 可以看出, 相比于GA-RF模型, SPA-RF模型对于轻重症的判别准确度更高, 而相比于CARS-RF模型, SPA-RF模型对于重症和缺镁的判别准确度更高。
利用柑橘黄龙病的病因分布特征, 对柑橘叶片的病理部位进行可见光波段的光谱采集。 利用SG平滑对光谱进行去噪, 同时采用遗传算法, 连续投影算法以及竞争自适应重加权采样法三种特征波长选择算法筛选出特征波长, 并依据这些特征波长使用最小二乘支持向量机以及随机森林建立判别模型。 在三种基于最小二乘支持向量机的叶片判别模型中, 对于测试集中健康、 轻度疾病、 重度疾病和缺镁症四类叶片的分类判别准确率分别达到92.5%, 95%, 95%。 在三种基于随机森林的叶片判别模型中, 对于测试集中健康、 轻度疾病、 重度疾病和缺镁症四类叶片的分类判别准确率分别达到92.5%, 97.5%, 92.5%。 所建立的叶片判别模型在测试集的检测结果中均表现出对于健康叶片及非健康叶片的高精度分割, 证明了所有模型均对黄龙病的病理鉴别有着很高的准确度。 在所有分类模型中, 连续投影算法以及随机森林的组合分类模型相比于其他模型, 对于黄龙病轻重症以及缺镁干扰样本有着更高的判别精度。 并且随机森林作为决策树算法延伸, 相比于最小二乘支持向量机, 在检测精度更高的同时其需要优化的模型参数更少, 更加简化了处理流程, 加快了处理效率。 该方法使用设备简单, 处理速度快, 检测精度高, 能够实现对不同阶段的黄龙病诊断, 能够实现极高的早期诊断率的同时降低对相似病症的误诊率。 因此, 本研究可以为黄龙病病理早期鉴别提供依据, 防止误诊。 对于柑橘黄龙病的无损诊断具有良好的应用前景。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|