





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱结合哈里斯鹰优化核极限学习机鉴别化橘红胎切片年份
[谢百亨1  , 马晋芳
, 马晋芳1 , 周泳欣1 , 韩雪勤1 , 陈嘉泽1 , 朱思祁1 , 杨懋勋2, 3, * , 黄富荣1, * ]
, 马晋芳, 黄富荣]
|
|


作者简介: 谢百亨, 1998年生, 暨南大学理工学院光电工程系硕士研究生 e-mail: xiebh2022@126.com
化橘红胎是药用历史悠久的广东省道地中药材, 由于其制品收藏年份越久远价格越高, 市面上常有以次充好的现象。 为此, 采用高光谱成像技术, 结合哈里斯鹰优化核极限学习机对四组不同年份的化橘红胎切片样品进行鉴别。 采集四个年份共193个化橘红胎切片样本400~1 000 nm的高光谱图像。 首先采用主成分分析法(PCA)分析化橘红胎切片的原始反射光谱, 然后分别采用Savitzky-Golay平滑(S-G平滑)、 多元散射校正(MSC)、 标准正态变量交换(SNV)对样本光谱进行预处理并建立核极限学习机(KELM)模型; 发现经SNV处理的样本光谱的判别准确率最高, 训练集达到99.24%, 测试集95.56%; 进一步用竞争性自适应重加权算法(CARS)、 蒙特卡洛无信息变量消除法(MCUVE)对样本光谱进行特征波长的选择; 最后, 采用KELM建立判别模型, 同时使用哈里斯鹰算法(HHO)优化KELM参数选择并比较建模效果。 结果表明: 基于HHO-KELM的判别效果相较KELM有0.76%~4.44%的提升, 通过 MCUVE 筛选所得特征波段信息冗余明显减少且精度提升, 训练集和测试集最佳准确率均可达100%, 故采用高光谱成像技术可以实现对不同年份的化橘红胎切片进行无损鉴别。
, MA Jin-fang, HUANG Fu-rong
Citri grandis fructus immaturus is a local Chinese medicinal material with a long history of medicinal use in Guangdong Province, because the higher the price of the product with the older the production year, the phenomenon of shoddy charging is often in the market. The study used hyperspectral imaging technology combined with the Harris Eagle optimized(HHO) kernel extreme learning machine(KELM) to identify four sets of different years of citri grandis fructus immaturus. In this study, 193 orange-red tire section samples were collected in four years, and hyperspectral images of 400~1 000 nm were collected. Firstly, the original reflection spectra of orange-red tire sections were analyzed by principal component analysis (PCA), and then Savitzky-Golay smoothing (S-G), multiple scattering correction (MSC),and standard normal variable exchange (SNV) were used to pretreat the sample spectra and establish KELM model, and found that the discrimination accuracy of the sample spectra treated by SNV was the highest, reaching 99.24% of the training set and 95.56% of the test set. Further, use of competitive adaptive weighting algorithm (CARS) and Monte Carlo Information-Free Variable Elimination (MCUVE) to select the characteristic wavelength of the sample spectrum; Finally, the discriminant model is established by KELM, and the HHO is used to optimize the KELM parameter selection and compare the modeling effect. The results show that the discrimination effect based on HHO-KELM is 0.76%~4.44% higher than that of KELM. The redundancy of feature band information obtained by MCUVE screening is significantly reduced, The accuracy is improved, and the optimal accuracy can reach 100% of the training set and 100% of the test set, so the use of hyperspectral imaging technology can realize the non-destructive identification of citri grandis fructus immaturus in different years.
化州柚是一种特产于广东省化州市的芸香科植物, 外表面黄绿色, 密布茸毛, 有皱纹及小油室; 内表面黄白色或淡黄棕色, 气芳香, 味苦、 微辛, 生食难以入口, 常以干品入药。 化橘红为芸香科植物化州柚(Citrus grandis ‘ Tomentosa’ )或柚(Citrus grandis (L.) Osbeck)的未成熟或近成熟干燥外层果皮。 前者习称“ 毛橘红” , 后者习称“ 光七爪” 、 “ 光五爪” 。 夏季果实未成熟时采收, 置沸水中略烫后, 将果皮割成5或7瓣, 除去果瓤和部分中果皮, 压制成形, 干燥。 化橘红胎(化橘红珠)为芸香科植物化州柚(Citrus grandis ‘ Tomentosa’ ) 的干燥幼果, 采收未成熟果实杀青并干燥, 压制成圆柱形或切片。 化橘红制作工艺复杂, 价格昂贵, 而化橘红胎不去除囊室, 制作省时省力, 价格合适, 且实用疗效与化橘红相仿, 备受当地市场认可。 据当地地方志、 《广东中药志》等记载, 化橘红和化橘红胎均有悠久的药用历史, 有理气宽中, 燥湿化痰之效, 用于咳嗽痰多, 食积伤酒, 呕恶痞闷。 但前者被录入历版《中国药典》, 在全国范围流通使用; 而后者因长时间无对应标准, 流通困难, 没有得到广泛认可和关注, 致使道地产区的柚农和加工化州柚制品的相关企业无法更广泛地对其进行市场推广。
依《本草纲目》记载: “ 橘红佳品, 其瓤内有红白之分, 利气、 化痰、 止咳功倍于它药……其功效愈陈愈良” 。 年份越久远的化橘红药效更好, 单价更高, 化橘红胎亦然。 市场上以次充好牟取暴利的现象时有发生, 因而有必要对不同年份的化橘红胎进行鉴别区分。 但肉眼通常难以分辨不同年份的化橘红胎; 当前研究中, 对化橘红或化橘红胎不同年份的鉴别, 主要采用薄层色谱法、 紫外可见分光光度法、 高效液相色谱法、 气质联用法等等。 上述方法操作复杂, 检测费时, 且所用试剂存在环境污染。 因此, 需要寻求更为快捷准确的测定方法, 对不同年份的化橘红胎切片进行快速判断。
近年来, 具有非接触测量特点的光谱技术愈来愈多地应用于中药材的检测分析, 如近红外光谱被应用于中药材产地鉴别、 中药成分含量测定; 高光谱成像被应用于中药成分含量分布[1]、 中药资源调查[2]、 中药制剂生产厂家的可视化判别[3]。 二者相比, 高光谱成像技术融合了传统的图谱技术和光谱技术, 能够检测样本的空间和光谱信息, 反映受检样品的形貌特征和化学特征, 分析过程无需化学手段, 对样本无破坏, 具有多维度、 数据丰富、 灵活等优点。 并且, 高光谱成像结合光谱预处理、 特征波长筛选算法[4]、 深度学习等诸多化学计量学方法, 可以减少数据的噪声和冗余, 更好的解析高光谱复杂的数据, 实现对样本快速准确的分析[5]。
当前在中药研究中, 常用的化学计量学方法有PCA、 模糊数学与灰色系统理论法、 聚类分析法、 人工神经网络法、 支持向量机法等[6]。 其中, 误差反向传播(BP)神经网络在中药质量评价中具备良好的拟合效果, 得到广泛应用。 但传统的 BP 神经网络采用梯度下降法求解且迭代过程中需要持续更新参数, 容易陷入局部最优值, 训练速度有限。 而极限学习机(ELM)相比 BP 神经网络有更高的训练效率和更紧凑的网络结构[7]。 ELM是一种求解广义单隐层前馈神经网络的方法, 隐含层参数可随机产生, 在训练前只需要确定惩戒因子或神经元数目即可生成隐含层节点, 在对多个经典的机器学习问题的模拟测试中表现出优异性能, 具有训练速度快且泛化能力强的优点[8, 9]。 Huang等引入了最小二乘支持向量机中的核函数, 进一步形成核极限学习机, 相比原极限学习机减少了初始化参数, 提高了适应性和稳定性[10]。
本研究以化橘红胎切片为研究对象, 采用高光谱成像技术直接采集样品数据, 对比无预处理、 Savitzky-Golay平滑、 多元散射校正(MSC)、 标准正态变量交换(SNV)得到的反射光谱数据建立KELM模型的性能, 比较全波段、 竞争性自适应重加权算法(CARS)[11, 12, 13]和蒙特卡洛无信息变量消除法(MCUVE)[14]筛选特征波段的建模效果, 进一步建立哈里斯鹰优化的核极限学习机(HHO-KELM)模型以期提高KELM的判别精度, 为化橘红胎年份鉴别提供快速检测方法, 也为推动对地方药材——化橘红胎的市场应用提供相关研究资料。
化橘红胎切片购于广东省化州市某大药材公司。 各年份化橘红切片样本如图1所示, 可见切片色泽及大小与贮藏时间有一定联系, 但肉眼无法准确判断其年份。
 | 图1 各年份化橘红胎切片Fig.1 Slices of citri grandis fructus immaturus aged with different years |
利用实验室搭建的高光谱成像检测系统, 包括: 手持智能型高光谱相机SPECIM IQ, 高亮度光源, 白色标定板等。 高光谱相机可探测波段范围为400~1 000 nm, 输出高光谱图像大小为512× 512像素, 成像距离为150 mm至无穷远。 如图2所示, 在黑色载物板上均匀摆放化橘红胎切片, 使两侧光源对准载物板, 调节高光谱相机水平并对焦后, 触发相机快门开始扫描。
 | 图2 高光谱成像平台Fig.2 Hyperspectral imaging platform |
采集到的原始高光谱数据需经式(1)进行黑白校正, 本实验使用的高光谱成像仪内置黑白校正功能。
式(1)中, I为原始光谱图像, O为校正后光谱图像, H1为扫描白色标定板(反射率约为1)得到的标定图像, H0为关闭光源扫描黑色载物板(反射率约为0)得到的标定图像。
读取黑白校正后的高光谱图像并分割出切片图像, 获取整片切片截面为感兴趣区域(region of interest, ROI)。 提取每一份切片400.2~997.4 nm波段的平均反射光谱。 剔除各年份的化橘红切片平均反射光谱离群样本, 得到共176个样本的平均光谱反射曲线。 采用Kennard-Stone算法对每个年份的化橘红切片平均反射光谱以3∶ 1的比例提取训练集与测试集, 该算法基于变量间的欧几里得距离挑选样本进入训练集直到数量达到要求, 能涵盖数据集中大多数差异, 确保训练模型更能代表整个数据集。
首先, 对原数据集进行PCA聚类分析, 探究PCA聚类直接区分化橘红切片的可行性。 另外, 对数据集分别采用SG平滑、 MSC、 SNV三种预处理方法, 观察平均反射光谱曲线变化, 分别建立KELM分类判别模型并对比准确率, 选择判别准确率最高的预处理方法。 最后, 将选得的数据集分别经CARS算法和MCUVE算法筛选特征波长, 进行KELM和HHO-KELM建模, 比较分类效果。 数据处理和建模的大致流程, 如图3所示。
 | 图3 数据分析步骤Fig.3 Data analysis steps |
1.4.1 核极限学习机
假设有n个样本, 以xi表示每个样本的特征向量; yi表示每个样本期望的响应, 对分类器而言yi是样本类别标签; 有L个隐藏节点; G(x)表示激励函数。 那么, 单隐层前馈网络的输出可以表示为
式(2)中, ω i为连接输入层节点到第i个隐藏节点的权重; β i为连接第i个隐藏节点到输出节点的权重; bi为第i个隐藏节点的阈值; fout(x)为第j个输入特征向量由网路求得的输出值。 以H表示隐藏层输出, β 表示隐藏层到输出层的输出权重, T表示目标输出。
标准的ELM在训练前随机设定且在训练过程中不更新W和B的参数值, 训练目标为输出结果与期望响应差值最小
解出输出层权重β 即完成训练, β 取最小二乘解
式(7)中, C为惩戒系数; I为单位矩阵; H为隐藏层矩阵; H+为H的广义逆矩阵。 经过训练标准ELM模型的输出为
为避免使用随机参数的不稳定隐患, 引入核矩阵Ω ELM和核函数k(xi, xj)。 采用径向基函数作核函数, 使模型更稳定并提高数据区分度。 式中, σ 为径向基函数的宽度系数。
基于径向基函数的核极限学习机的输出函数可表示为
对于KELM, 调节惩戒系数C和核函数参数σ 即影响模型训练效果。
1.4.2 哈里斯鹰算法优化参数选择
HHO是由Heidari等在2019年提出的一种模拟哈里斯鹰捕食行为实现的优化算法, 具有全局搜索范围广, 收敛速度快等优点。 HHO算法以猎物位置描述待寻优参数, 以猎物逃逸能量描述优化目标函数, 算法寻优过程模仿哈里斯鹰捕食行为, 分为追踪、 围攻、 捕捉等几个阶段进行迭代, 逐步包围猎物, 使目标函数逐步减小。 当迭代次数达到要求时, 哈里斯鹰种群将猎物逼迫在包围圈中, 目标函数达到迭代过程的最小值[15]。
KELM分类模型的分类效果受惩戒域子C、 核函数宽度系数σ 影响, 因而可采用HHO算法对C、 σ 进行优化。 直接以KELM的分类错误率作为优化的目标函数容易陷入局部最优或出现过拟合现象, 笔者对KELM训练过程加入K-Fold交叉验证, 并以交叉验证得到的均方根值为优化目标函数(适应度值)。 K-Fold交叉验证是常用的模型评估技术, 它将数据集分成K个相等的子集, 然后进行K次模型训练和测试, 每次使用不同的子集作为测试集, 其余的子集作为训练集。 该技术可以减少模型的方差, 提高模型的泛化能力, 因此可以被用于优化算法的参数选择[16]。 采用K值为10进行交叉验证。
HHO-KELM算法步骤如下:
step1: 初始化HHO种群大小、 迭代次数;
step2: 训练集作输入, 交叉验证训练并测试KELM, 得到均方根值;
step3: 未达到迭代次数, 则采用HHO对C、 σ 进行寻优, 更新KELM;
step4: 达到迭代次数退出HHO, 输出最终适应值和寻优参数, 更新KELM;
step5: 测试集输入得到的HHO* KELM测试训练效果。
采集波长范围为397~1 003 nm的204个可见近红外光谱数据, 因首尾部噪声明显, 截取400.2~997.4 nm的201个波长的光谱数据。 所得全样本原始光谱曲线和按年份分组平均光谱曲线如图4所示。
 | 图4 化橘红胎切片原始光谱图(a)及平均光谱图(b)Fig.4 Original reflection spectra (a) and mean spectra (b) of samples |
由图4可知, 贮藏时间越长的化橘红胎切片可见近红外波段反射率越小, 各组化橘红胎切片的反射光谱曲线线性相近, 有所区别。 但观察图4(a), 除2021年化橘红胎切片的光谱曲线有较为明显的区分外, 其他三个年份化橘红胎切片得到的反射光谱曲线在整个波段范围内都有不同程度的交叠。 因此, 无法直接由反射光谱数据鉴别化橘红胎切片的生产年份。
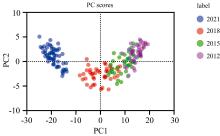
对化橘红胎切片原始反射光谱进行PCA聚类分析, 所得主成分贡献率信息如表1所示, PC1和PC2累计贡献率达到98.25%, 足以描述化橘红胎切片原始光谱特征。 采用PC1和PC2作得分图, 由图5可以看出, 各年份样本点有明显聚类, 2021年产化橘红胎切片区别明显, 而2018年、 2015年、 2012年产化橘红胎切片样品点有重合, 难以区分。 根据对样品外表观察, 推测原因是2021年产化橘红胎切片未完全脱水, 含水量偏高, 表面未有挥发油类物质析出, 而另外三组化橘红胎切片干制较完全且化学成分变化不明显。 所以, 无法通过主成分分析结果区分生产年份三年以上的化橘红胎切片样本, 仍需要进一步研究。
| 表1 PCA主成分分析 Table 1 Principal component analysis |
 | 图5 PCA主成分得分分布Fig.5 Principal component score distribution |
依次采用S-G平滑、 MSC、 SNV方法对化橘红胎切片原始反射光谱曲线进行预处理, 处理后反射光谱曲线如图6所示。 分别将无预处理和预处理得到的共四份高光谱数据训练KELM并分别验证训练集与测试集的预测准确率, 得到结果如表2所示。 经比较, 选取建立KELM模型效果相对最好的化橘红胎切片 SNV 处理反射光谱数据作进一步的分析和处理。
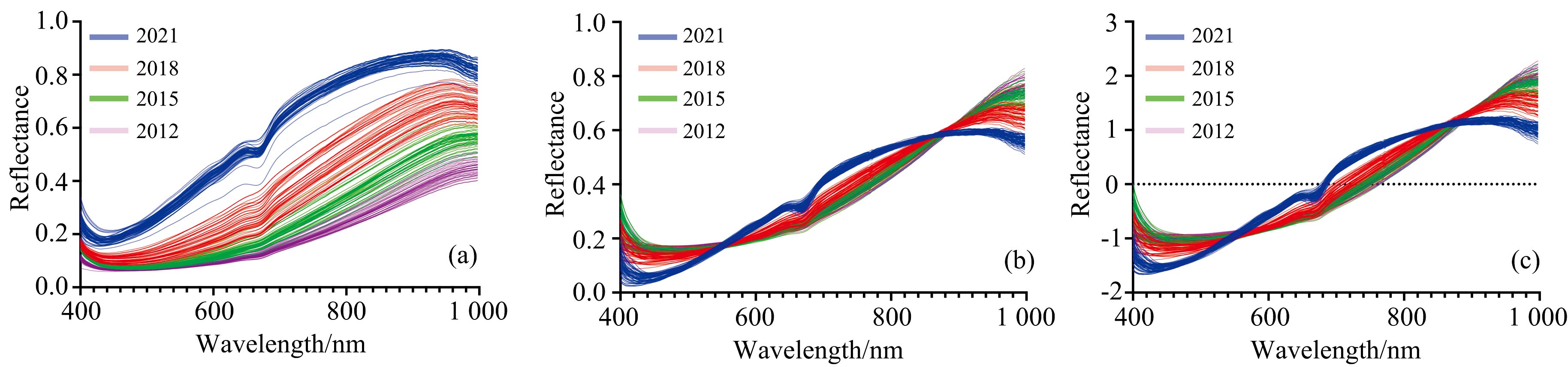 | 图6 不同预处理方法化橘红胎切片光谱图 (a): S-G平滑; (b): MSC; (c): SNVFig.6 Pretreated spectra of samples (a): S-G smoothing; (b): MSC; (c): SNV |
| 表2 不同预处理方法KELM 判别模型效果 Table 2 Accuracies of KELM discriminant models with different preprocessing methods |
为比较CARS与MCUVE筛选特征波长后的创建判别模型的效果, 由CARS筛选得到19个特征波长, 对应地选用MCUVE得到的重要性系数最高的前19个波长作为特征波长。 经CARS和MCUVE所得特征波长信息如表3所示。 由图7, CARS所选特征波长集中于两端, MCUVE所选特征波长分布相对均匀。 两种方法得到的特征波长在500~800 nm波段范围有明显差别, 具体效果需要建立分类判别模型进行实际对比。
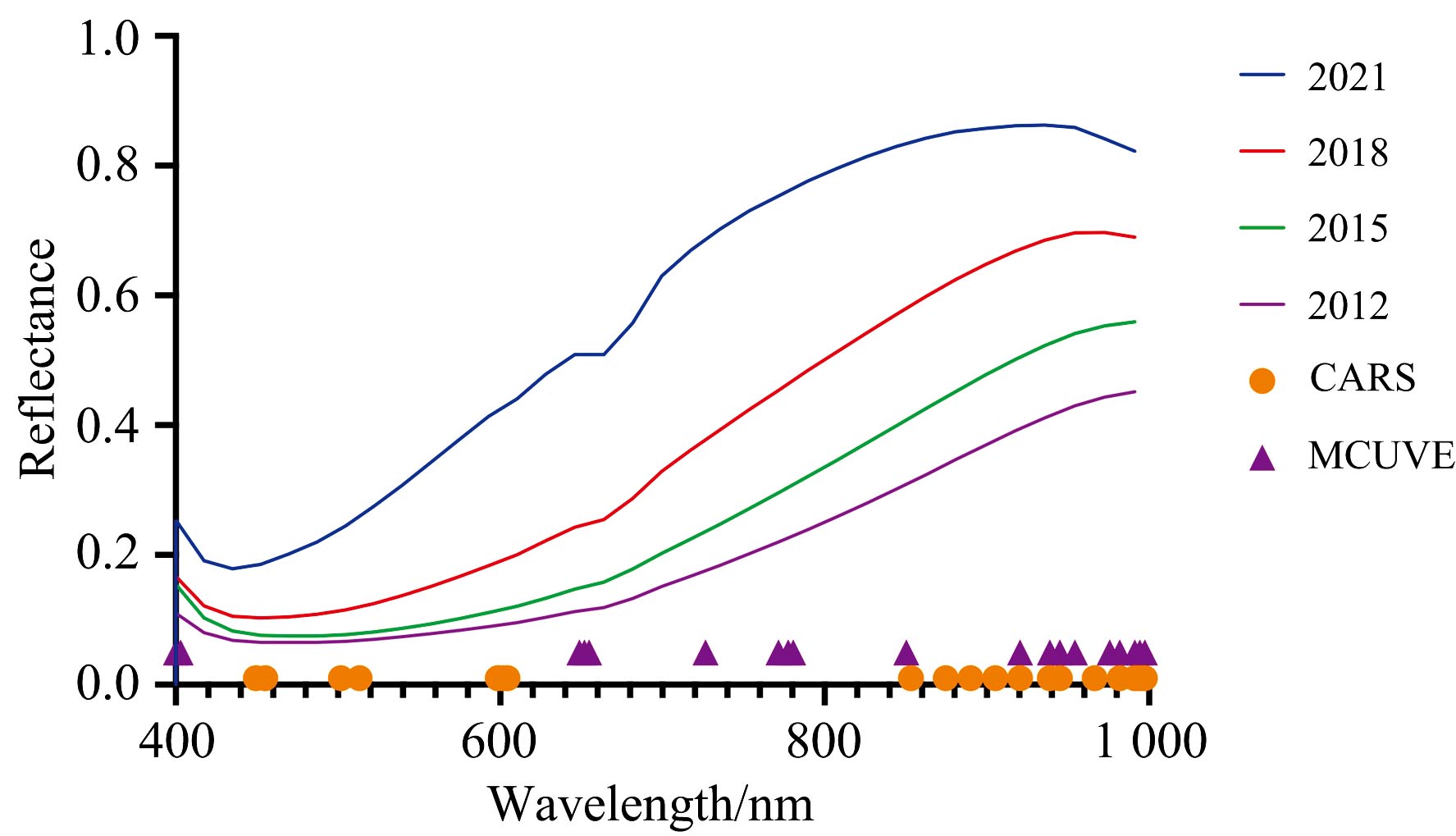 | 图7 特征波长分布Fig.7 Characteristic wavelength distribution |
| 表3 特征波长信息 Table 3 Feature wavelength information |
以全波段、 CARS和MCUVE方法筛选特征波长得到的数据集创建KELM模型, 分别检验训练集和测试集分类判别效果。 初始化HHO算法参数, 种群数量为30, 迭代次数500, 对KELM的惩戒系数C和核函数参数σ 寻优。 待HHO寻优结束后, 采用更新的C和σ 重新训练KELM并测试判别效果。 得到不同波段范围创建KELM和HHO-KELM分类判别模型的测试结果如表4所示。
| 表4 分类判别模型结果 Table 4 Classification discriminant modeling results |
全波段信息最为充足, 但信息的冗余会带来很大的运算压力, 使训练时间变长, 且可能使判别模型劣化。 通过波段筛选可以有效减少信息冗余, 加快训练速度, 可能提升判别效果。 对化橘红胎切片样品高光谱采用波段筛选后, 训练速度和判别效果有所提升。 并且, 在保留特征波长数量相同的前提下, MCUVE比CARS效果更好, 无论优化与否都能达到最高的判别准确率, 认为MCUVE筛选的19个特征波长可以描述原光谱数据的全部信息。 可以看出, 采用哈里斯鹰算法优化参数的核极限学习机对训练集检验的准确率有明显的提高, 且优化效果在测试集中也有所体现。 无论是在数据集包含全波段还是少数特征波长的情况下, HHO-KELM都能很好的通过高光谱数据实现化橘红胎切片的年份鉴别。
以鉴别不同年份的化橘红胎切片为中心课题, 以我国广东省化州市的地方药材化橘红胎为研究对象, 采用高光谱成像技术, 结合光谱预处理、 特征波段筛选、 机器学习及参数寻优算法, 比较了不同数据处理方法的建模和判别效果, 实现完整化橘红胎切片的实时快速鉴别, 为化橘红胎的市场推广和使用提供了技术参考。 根据实际比较, SNV预处理所得化橘红胎切片反射光谱建模效果最优, 并且经过MCUVE筛选特征波长得到的19个特征波长可以实现最好的建模判别效果, 认为所得19个特征波长可完全描述化橘红胎切片反射光谱信息。 此外, 经过HHO寻优训练的KELM相比原KELM性能有明显提升, 参数寻优效果良好。 研究表明, 采用高光谱成像技术可以实现对不同年份的化橘红胎切片进行无损鉴别, 并可通过MCUVE筛选所得特征波段减少信息冗余和提升精度, HHO能提高机器学习模型性能和稳定性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|