
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于改进的XGBoosting算法对婴幼儿奶粉中的脂肪含量的预测模型
[张文婧1, 2  , 薛河儒
, 薛河儒1, 2, * , 姜新华1, 2 , 刘江平1, 2 , 黄清1 ]
, 薛河儒, 姜新华|
|


作者简介: 张文婧, 女, 1986年生, 内蒙古农业大学计算机与信息工程学院及大数据研究与应用重点实验室博士研究生 e-mail: zhangwenjing@imau.edu.cn
婴儿奶粉成分配比中, 脂肪有着重要地位。 脂肪不仅是婴儿生长发育中的重要成分, 同时也为婴儿的生长提供必需的能量, 对于婴儿脑发育及神经髓鞘的形成具有重要意义。 化学的婴儿奶粉脂肪含量检测如乙醚提取法, 方法检测灵敏, 但存在破坏样本和检测周期较长的缺点, 因此寻求一种为婴儿奶粉成分的无损检测方法, 高光谱成像技术提供了一种可能的途径。 以内蒙古地区不同阶段的婴儿奶粉为研究对象, 采用多元散射校正(MSC)、 标准正态变换(SNV)、 平滑滤波算法(Savitzky-Golay)、 鲁斯特算法(Roust)等对高光谱数据进行预处理, 再利用竞争性自适应重加权算法(CARS)算法从125个特征波长中筛除光谱数据中冗余的波长保留有效波长66个。 对极值梯度提升算法(XGBoosting)算法进行了贝叶斯优化(BO), 最终构建了基于BO-XGBoosting对婴儿奶粉脂肪含量的预测模型。 结果显示, 该模型预测效果优于传统的偏最小二乘回归(PLSR)和支持向量回归(SVR)模型, 且优于集成算法中Bagging、 GrdientBoosting算法。 贝叶斯优化极值梯度提升算法BO-XGBoosting模型在测试集实验, 得到的决定系数(R2)和均方根误差(RMSEP)分别为0.953 7和0.577 3, 比XGBoosting算法的 R2和RMSEP分别提高2.91%和降低19.2%。 该研究为奶粉中脂肪含量的预测提供了基于BO-XGboosting集成算法的快速无损检测的算法支持和理论依据。
Fat plays an essential role in the composition of infant formula. Not only is fat a vital component of a baby's growth and development, but it also provides essential energy for growth. It is crucial for the development of the infant brain and the formation of nerve myelin. Chemical methods for determining the fat content of infant milk powder, such as ether extraction, are sensitive but have the disadvantage of destroying samples and having a long detection period. In this paper, the hyperspectral data undergoes preprocessing processes with standard normal transform (SNV), multiple scattering corrections (MSC), Savitzky-Golay smoothing, and Roust method using different stages of infant milk powder in Inner Mongolia, China. A competitive adaptive re-weighting algorithm, CARS, was used to sift out redundant wavelengths from the spectroscopic data at 125 feature wavelengths, leaving 66 valid wavelengths. The Bayesian optimization algorithm optimizes the XGBoosting prediction model, leading to a BO-XGBoosting model that predicts the fat content of infant formula better than the original model. The experimental results show that the model predicts better than the traditional partial least squares regression (PLSR) and support vector machine (SVR) regression model, outperforming the Bagging and GrdientBoosting algorithms in the integrated algorithm. In the BO-XGBoosting model in the test set experiments, the decision coefficient R2 and root mean square error of prediction (RMSEP) obtained are 0.953 7 and 0.577 3, which are 2.91% higher and 19.2% lower than the determination coefficient R2 and root mean squared error of prediction (RMSEP) of the XGBoosting model's R2 and RMSEP, respectively. This study provides algorithmic support and a theoretical foundation for BO-XGBooting based rapid, non-destructive detection of infant formula fat content.
婴幼儿配方奶粉是奶粉市场中重要的组成部分。 从国家到地方、 企业都把婴幼儿配方乳粉品质安全作为食品安全的重中之重, 制定出台了一系列法律制度和政策措施, 目的是提升婴幼儿配方乳粉的品质, 维护婴幼儿配方乳粉的安全[1]。 亟需开发婴幼儿配方乳粉成分分析标准物质, 特别是最为基本的营养成分——脂肪。 脂肪不仅是婴儿主要热量及必需脂肪酸的供给来源, 而且帮助修复组织和生理调节, 也是适应婴幼儿胃肠道及渗透压的最佳选择[2]。
目前奶粉中脂肪成分的检测仍依赖化学方法, 检测方法有盖勃氏法、 索氏提取法等, 其方法的缺点则是成分检测时破坏样品、 耗时长、 操作复杂等, 无法满足现代质量控制的要求[3]。 如何快速检测奶粉中的脂肪成分成了一个亟待解决的问题。
高光谱成像(hyperspectral imaging, HSI)技术, 同时包含图像信息和光谱信息, 是融合了传统成像技术获取物体空间数据信息和光谱技术获取物质原子、 分子光谱特征的技术。 通过测量物体在不同波长下的反射率、 辐射率等光学参数, 可以对物体内部品质和外部特征进行全面扫描检测[4, 5]。 获取感兴趣区域像素点的特征, 并结合样本的空间信息可以为样本建立预测模型打下坚实的基础。
Woodcock等通过HSI法测定奶酪质量和真实性[6]。 Debora等应用NIR HSI和多元曲线校正方法(multiplicative scatter correction, MSC)对奶粉掺假进行检测, 并开发校对模型对掺假淀粉尿素乳清粉的奶粉进行模型评估[7]。 赵紫竹等应用图像处理技术对高光谱数据进行分析, 构建N-PLS模型, 精度高于偏最小二乘法(partial least-regression, PLSR)模型, 预测牛奶中脂肪质量浓度[8]。 Asma Khan等利用高光谱成像技术结合奶粉的颗粒度对不同工厂生产的不同质量和性质的奶粉进行分类鉴别[9]。 Munir等利用高光谱数据结合PLS构造一个预测模型, 来预测奶粉的奶源信息[10]。 Liu等通过基于改进麻雀搜索算法优化反向传播神经网络对牛奶中的蛋白含量进行了预测分析[11]。
采用内蒙古地区的五种婴儿奶粉作为试验样本, 经过多次采集高光谱数据, 结合脂肪含量数据, 建立竞争性自适应重加权算法(competitive adapative reweighted sampling, CARS)进行特征波长的选择, MSC算法对数据进行预处理, 再经过贝叶斯优化极值梯度提升算法(Bayesian algorithm optimizes the extreme gradient boosting algorithm, BO-XGBoosting)算法共同构建了预测模型, 该模型以常见的光谱预测模型PLSR和支持向量机回归(support vector machine regression, SVR)算法, 以及集成算法中的套袋法(Bagging)、 梯度提升(GrdientBoosting)与XGBoosting算法作为基准算法进行了比较, 找到预测效果最优算法来预测婴儿奶粉中的脂肪含量, 为奶粉成分的定量分析提供参考。
实验样本来源于内蒙古地区品牌的婴儿奶粉, 分别取样该品牌一段, 二段, 三段婴儿奶粉, 与同品牌不同系列的三段、 四段奶粉, 组成五种婴儿奶粉的实验样本, 所用的样品是从超市购买。 样品采集容器直径为90 mm、 高度为8 mm。 分别取不同批次的婴儿奶粉, 开罐后置于容器中, 用平尺压平, 使其均匀。 脂肪含量如表1所示。
| 表1 婴儿奶粉脂肪含量 Table 1 Fat content of infant formula |
高光谱成像采集系统由光谱成像仪由地面机载高光谱成像仪组成, 光源系统由可调节的高强度石英卤钨灯(100 W), 扫描平台由线性底座、 扫描架、 控制器和反射参考板组成光。 谱波长范围为400~1 000 nm、 分辨率为2.8 nm, 共有750个光谱通道, 其光谱图像的分辨率为777× 1 004像素。
采集环境: 室内温度: 22~25 ℃, 湿度: 28%~33%之间, 将样本置于黑色扫描平台, 调整镜头向下调整40° 角, 扫描探头距离样本15 cm, 光源垂直照射40 cm。
在高光谱数据采集软件中, 设置像元混合为6次, 分辨率为4.8 nm, 设置曝光时间10 ms, 测量暗电流得到黑校正光谱图像, 测量参比, 得到白校正光谱图像, 因高光谱存在着光强的变化和暗电流会产生高光谱图像噪音, 需要进行黑白校正, 其校正方法为[12]。
式(1)中, I为原始高光谱图像; B为用黑板校正后的图像; W为用白板校正后的图像; R为校正后的光谱图像。
实验采用软件ENVI5.3提取样本的光谱数据, 5种样本奶粉, 每种取样20份, 每个样本选择10个感兴趣区域(region of interesting, ROI), 并计算 ROI内所有像素点的平均值得到样本平均反射光谱。 每个样本提取10条反射率, 共计组成1 000条数据样本。
因光谱数据中存在着基线漂移、 高频噪音等问题, 原始的样本数据需要找到适合的预处理方法, 采用标准正态变换(standard normal transform, SNV)、 MSC和Savitzky-Golay平滑滤波以及鲁斯特算法Roust等四种预处理方法来对高光谱数据进行信息增强, 并建立预测模型, 对比几种预处理方法效果, 选出最优预处理方法。
由于高光谱数据具有波长数量较多, 维度高等特点, 特征波长的选择方法可以剔除噪音波长, 减少波段数量, 简化模型结构, 提高模型性能。 筛选婴儿奶粉的特征波长选用了CARS和无信息变量消除算法(uninformative variable elimination, UVE)。
1.4.1 竞争性自适应重加权算法
于霜等比较了常用的几种特征波长的选择方法如CARS、 连续投影算法、 UVE、 遗传算法等, 建立了CARS+PLSR模型预测精度最优[13]。 CARS算法不仅可以优选特征波长, 剔除多余波长, 较大程度上解决选择变量过程中需要考虑过多组合量的问题, 从而选出优化的变量子集, 有助于提高模型的预测能力。 CARS是结合蒙特卡洛采样与PLS模型回归系数的特征变量选择方法[14]。 为选取稳定的特征波长, 实验迭代运行CARS算法10次, 每次迭代产生的特征波长, 选取贡献率最多的波长。
算法过程如下:
(1) 蒙特卡罗模型采样
采样是指随机划分数据集进行建模分析, 划分比例为8∶ 2。 对于建模方法选择简单方便的PLS进行分析。
(2) 指数衰减波长选择
首次采用全部变量进行建模, N次迭代过程中确定的变量是逐次递减的, 第i次采样确定的变量个数比例根据式(2)确定
式(2)的约束条件为r1=P, rN=2/P, 可求得指数递减函数参数为
递减函数分布两部分, 式(3)中(i< n)为“ 快速选择” 阶段, 大量变量被快速剔除; 式(4)中(n< i< N)为“ 精选阶段” , 每次删除的变量较少, 即变量精准分析。
(3) 自适应重加权采样
根据(2)确定的迭代采样变量个数进行变量剔除, 即重采样。 权表示变量出现的频率, 建立基于筛选变量的分析预测模型, 并计算其RMSE, 此处为验证模型的有效性, 采用RMSECV。
(4) 循环迭代
根据设置的循环迭代次数进行循环计算, 根据最小的RMSECV确定最佳的变量集合, 即为所求特征变量。
1.4.2 无信息变量消除法UVE
UVE算法原理是利用噪声的无关变量信息统计去选择光谱自身的特征波长, 其中一个最重要是噪声的利用或者加入, UVE在添加噪声后, 根据光谱变量和噪声组成的自变量矩阵对目标矩阵回归系数统计分布进行变量判断, 其中回归系数的统计分布以均值和标准差的比值表示, 通过确定上下限并提出对应范围内的变量, 最终确定特征变量。
1.5.1 贝叶斯优化算法
贝叶斯优化(Bayesian optimization, BO)是一种全局优化算法。 机器能够根据概率框架预测未来数据, 并且根据预测数据给出决策。 这些问题的主要难点在于观测值具有不确定性, 而概率模型能够对不确定性进行建模, 有效地解决观测噪声问题[15]。 在已知有限样本的情况下, 通过构造黑箱函数输出的后验概率来寻找函数的最优值。 目前贝叶斯优化已经成为超参数估计领域的重要方法[16]。
BO通过基于目标函数的过去评估结果建立替代函数(概率模型), 来找到最小化目标函数的值。 它的框架主要包括两个核核心: 概率代理模型(probabilistic surrogate model, PM)和采集函数(acquisition function, AF), PM主要利用高斯过程(Gaussian process, GP)回归, 通过样本D1∶ t={D1∶ t-1, (Xt, yt)}, 对高斯过程进行估计和更新。 通过AF来指导新的采样。 贝叶斯优化算法见表2: 其中, D1∶ t={D1∶ t-1, (Xt, yt)}是表示训练集合t=1, 2, 3, …表示训练集合中的训练样本个数, D是数据集, μ 是x点的均值, σ 是x点的方差, β 是参数。
| 表2 贝叶斯优化算法表示 Table 2 Bayesian optimization algorithm process |
1.5.2 极值梯度提升算法
XGBoosting算法又被称为极值梯度提升树, 是一种有监督的集成学习算法。 该算法在2014年3月提出的, 并构建的梯度提升算法。 该算法思想就是不断地进行特征分裂来生长一棵树, 每次添加一棵树, 实际是学习一个新函数, 去拟合上次预测的残差[17]。
任何机器学习问题都可以从目标函数出发, 目标函数分为两部分: 损失函数和正则化项, 其中, 损失函数用于描述模型拟合数据的程度, 正则化用于控制模型的复杂度。 算法流程如下:
(1) 构造目标函数, 用来评估模型的好坏
式(5)中,
将模型
(2) 对目标函数经过泰勒二阶公式展开, 如式(8)
式(8)中, L(yi,
(3) 将式(9)中的目标函数参数和, 用树结构引入目标函数, fk(xi)和Ω (fk)进行参数优化, 在式(8)中为了防止过拟合添加了正则项。 用式(10)衡量模型的复杂度
式(10)中, T为叶子节点个数,
将式(10)代入到式(11)中, 得到新的目标函数式(12)
(4) 根据最终目标函数式(12), 构建最优树
针对于不同棵树的最优obj, 然后选取obj最小的一棵树, 但是树结构很复杂, 引出了贪心算法, 去构建一棵最优的树。 计算信息增益objnew-objold。 遍历特征计算信息增益, 构造一颗目标函数最小的树模型, 最终得到式(13)
XGBoosting算法是基于贪心算法的决策树的生产策略, 采用泰勒公式展开后接近拟合目标函数, 通过对奶粉中的脂肪含量和光谱中的特征波长构造的融合数据进行预测脂肪含量, 通过训练集的训练模型, 在预测集上应用得到拟合数据, 即脂肪的预测值。
1.5.3 基于贝叶斯优化的极值梯度提升模型
基于贝叶斯优化的极值梯度提升模型BO-XGBoosting, 通过BO算法对XGBoosting模型中的参数进行优化, 算法流程如图1所示, BO-XGBoosting模型的建立预测模型的基本步骤如下:
 | 图1 BO-XGBoosting算法流程图Fig.1 BO-XGBoosting algorithm flow |
(1) Start确定输入数据, 输入经过预处理和特征波长选择后的特征波长, End输出婴儿奶粉的脂肪含量, 并计算模型衡量指标R2和RMSE。
(2) 初始化XGBoosting的主要参数的权重, n_estimator: 参数限制最大生成树的数目, learning_rate: 每次迭代的梯度下降步长, booster中gbtree: 采用树的结构来运算数据, gamma: 训练集的正则化参数, max_depth: 最大树深度。
初始化参数: n_estimator=10; learning_rate=0.3; gamma=0; max_depth=10。
(3) Model initialization初始化贝叶斯优化的参数, 确定搜索空间参数, 参数范围如下: n_estimator=(10, 60), gamma=(le-9, 0.5, “ log-uniform” ), learning_rate=(0.01, 0.8, “ log-uniform” ), max_depth=(5, 100)。
(4) 计算最小mean_squared_error(MSE), Score=min(MSETraining set, Testing set)
(5) 贝叶斯优化经过GP过程对参数进行估计和更新, 和AF过程是指导新的采样过程, 反复交叉验证, 迭代次数为10。
(6) 经过BO选出最优参数传递给XGBoosting模型, BO-XGBoosting模型在训练集运行, 并在测试集上预测脂肪含量,
2.1.1 不同预处理方法建立模型比较效果
光谱数据全波长原始光谱为125个波长, 经过4种预处理方法, 分别与经典算法中的偏最小二乘回归(PLSR)和支持向量回归(SVR)等算法建立预测模型, 训练集和测试集划分为8∶ 2。 依次经过MSC, SNV, Rousu(通过中位数和四分位来缩放数据, 用于异常值比较敏感的数据)和Savitzky-Golay平滑滤波等预处理。 实验结果如表3所示, 表3中MSC+PLSR预测模型中的训练集的
| 表3 对比预处理方法与预测模型的成对组合的预测准确率 Table 3 The prediction accuracy of pairwise combination of pretreatment method and prediction model was compared |
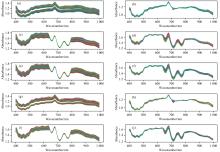
五种婴儿奶粉的光谱数据集, 经过MSC处理后的图像见图2所示, 在图2中(a)代表Zhenhu 1 segment婴儿奶粉原始光谱图像, (c)代表Zhenhu 2 segment婴儿奶粉原始光谱图像, (e)代表Zhenhu 3 segment婴儿奶粉原始光谱图像, (g)代表Seine Mouiller 4 segment婴儿奶粉原始光谱图像, (i)代表Litter lamb 3 segment婴儿奶粉光谱数据图像, (b), (d), (f), (g), (h), (j)分别代表的对应原始光谱图像经过MSC预处理后的平滑光谱图像。 平滑后的图像线条更为聚集, 能更好地拟合一种波形。
 | 图2 原始高光谱数据经过MSC处理后的吸收率图像Fig.2 Spectral image of the original hyperspectral map after MSC processing |
2.1.2 特征波长选择
光谱中存在的部分无效干扰信息降低了定量模型预测精度, 同时数据量较多也增加了模型复杂度和运算时间, 通过特征选择方法能够有效获取光谱特征波长, 提升模型检测效率。 本研究利用CARS算法和UVE算法对数据集中的光谱数据进行波长优选, 如表4所示。
| 表4 通过算法CARS和UVE筛选出的特征波长 Table 4 Selected characteristic wavelengths screened by CARS and UVE |
杨泽等在特征性峰位法结合化学计量学构建奶粉脂肪含量定量模型中确定的奶粉脂肪含量特征性峰位有2 925、 2 855、 1 745和1 456 cm-1、 , 其中1 745 cm-1是C=O伸缩振动和1 456 cm-1是CH2/CH3弯曲振动, 主要来源于奶粉中的脂肪[18]。 波长573.307 1 nm与1 745 cm-1相对应, 波长688.544 nm与1 456 cm-1相对应, 进一步验证了CARS算法在特征选择上的有效性。
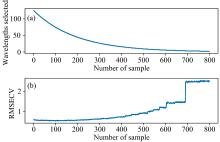
实验结果如图3所示, 其中蒙特卡洛采样次数设置为50, 最佳迭代次数为56次, 交叉验证次数10次, 最终筛选出的特征波长为66个波长。 在图3(a)中, 随着样本数据的增加, 选择特征波长数量也在减少; 图3(b)中随着样本数量增加, RMSECV值也在增加, 最终选取样本数量为100时的选出的特征波长, 与SVR建立预测模型时RMSEP=0.750 8, 是预测效果最好的。
 | 图3 经过CARS算法选取特征波长Fig.3 CARS algorithm for feature wavelength selection |
表5中CARS算法和UVE算法与PLSR和SVR进行组合建立预测模型, 实验结果显示CARS+SVR算法建立的模型是预测模型中效果最好的一组。 同时CARS+PLSR的预测集中
| 表5 CARS和UVE分别和PLSR、 SVR模型相结合建立预测模型 Table 5 CARS and UVE were combined with PLSR and SVR models to build prediction models |
光谱数据样本通过MSC预处理和CARS特征波长选择后分别建立PLSR、 SVR等baseline预测模型以及集成算法中的Bagging、 GrdientBoosting、 XGBoosting与BO-XGBoosting预测模型进行对比。
通过表6可以得出结果如下:
| 表6 不同预测模型的精度对比 Table 6 Precision comparison of different models |
(1) 虽然CARS+MSC+Bagging模型和CARS+MSC+XGBoosting算法在训练集上都是
(2) CARS+MSC+SVR预测模型相结合, 其预测效果明显优于表2中的MSC+SVR模型。 通过CARS算法, 剔除无用波长, 有助于提高预测模型的精准度。 而SVR模型适用于非线性相关数据, 因此通过CARS算法减少特征波长后, 可以提高运行效率和预测稳定性。
(3) 预测模型PLSR、 SVR、 与集成算法整体相对比, 集成算法在训练集上的
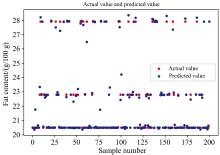
无论是在训练集还是测试集上, CARS+MSC+BO-XGBoosting模型的预测效果是所有模型中最好的。 预测集合上婴儿奶粉中脂肪含量测试值和预测值的图形效果见图4所示。
 | 图4 CARS+MSC+BO-XGBoosting模型处理后测试值和预测值对比结果Fig.4 The test value was compared with the predicted value with CARS+MSC+BO-XGBoosting prediction model |
运用了高光谱技术对五种婴幼儿奶粉进行光谱数据采集, 经过实验对比, 选择MSC算法对原始光谱数据进行预处理。 运用了CARS和UVE算法对高光谱数据进行的特征波长的筛选, 作为奶粉脂肪含量的自变量, 建立了PLSR、 SVR、 Bagging、 GrdientBoosting、 XGBoosting和BO-XGBoosting等六种预测模型, 通过比较模型的性价指标(R2和RMSE)来选取预测模型。 CARS+MSC+BO-XGBoosting的训练集中的
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|