






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种生成对抗网络半监督回归的废纺样品中羊毛含量的预测方法
[胡锦泉1, 2  , 杨辉华
, 杨辉华1 , 赵国樑3 , 周瑞知4 , 李灵巧5 ]
, 杨辉华|
|


作者简介: 胡锦泉, 1978年生, 北京邮电大学人工智能学院博士研究生, 桂林电子科技大学电子工程与自动化学院高级实验师 e-mail: jxhjq@guet.edu.cn
针对废旧纺织品回收在线分拣的需求, 提出了一种基于生成对抗网络的半监督回归方法, 使用少量标记样本和大量未标记样本来训练半监督回归器。 半监督回归器由神经网络组成的生成器和由神经网络构成的判别器组成。 生成器用于生成尽可能接近实际标记和未标记训练数据集内容的混合样本。 鉴别器用于验证生成器生成的样本并预测这些样本的连续标记。 生成的网络通过特征匹配损失进行训练, 损失函数是鉴别器中间层真实样本的输出与生成样本之间的误差平均值。 判别式有两个输出, 一个用于预测序列标记, 另一个用于确定生成的样本是真样本还是假样本的概率。 通过使用传统的无监督生成对抗性网络损失函数和监督回归损失的组合来训练判别式。 生成的网络通过特征匹配损失进行训练, 损失函数是鉴别器中间层真实样本的输出与生成样本之间的误差平均值。 先后收集了400个不同羊毛含量的混纺样品和3 000个未知成分的混纺样品。 70%的标记和未标记的混合样本被随机选择作为训练集, 其余30%的标记样本被用作重复实验的测试集。 开展了多个实验进行验证。 第一个实验为混纺光谱生成实验, 用于验证生成对抗网络能够根据内在规律有效生成混合样本光谱。 第二个实验为半监督对抗网络定量分析性能对比实验, 对羊毛成分分析模型训练与测试, 并将本半监督对抗网络定量分析模型与其他定量模型进行性能对比。 第三个实验为现场高羊毛含量混纺细分模型预测对比实验, 用羊毛含量在80%到99%之间的混纺样品进行成分分析, 并将本文的半监督对抗网络定量分析模型与其他定量模型进行性能对比。 第四个实验为中高羊毛含量混纺细分综合模型现场预测实验, 用羊毛含量在40%到99%之间的混纺样品训练半监督对抗网络定量分析模型并部署在分拣系统, 由操作员进行现场测试数据进行准确率、 分析时间等测试。 实验结果表明, 基于生成对抗网络的半监督回归方法优于PCR、 PLSR、 SVR、 BPNN等模型, 该模型的预测 R2达到0.964。 经过现场反复测试, 该模型能快速提取出40%以上羊毛含量的混纺样品。
In this paper, a semi-supervised regression method based on a Generative adversarial network is proposed to meet the demand for online sorting for waste textile recycling, which uses some labeled samples and a large number of unlabeled samples to train the semi-supervised regression. The semi-supervised regression consists of a generator composed of neural networks and a discriminator composed of neural networks. The generator generates a mixed sample that is as close as possible to the actual labeled and unlabeled training dataset content. The discriminator is used to validate the samples generated by the generator and predict the continuous labeling of these samples. The generated network is trained through feature matching loss, which is the average error between the output of the actual sample in the middle layer of the discriminator and the generated sample. The discriminant has two outputs, one for predicting sequence markers and the other for determining the probability of whether the generated sample is a true or false sample. Train discriminants by using a combination of traditional unsupervised generative adversarial network loss functions and supervised regression losses. The generated network is trained through feature matching loss, which is the average error between the output of the actual sample in the middle layer of the discriminator and the generated sample. We have collected 400 blended samples with different wool contents and 3 000 blended samples with unknown components. 70% of labeled and unlabeled mixed samples were randomly selected as the training set, while the remaining 30% of labeled samples were used as the test set for repeated experiments. This article has conducted multiple experiments for verification. The first experiment is a blended spectrum generation experiment, which is used to verify that the generative adversarial network can effectively generate mixed sample spectra based on intrinsic laws. The second experiment is a semi-supervised adversarial network quantitative analysis performance comparison experiment, which trains and tests the wool composition analysis model, and compares the performance of this semi-supervised adversarial network quantitative analysis model with other quantitative models. The third experiment is a prediction and comparison experiment of on-site high wool content blended yarn segmentation models. Composition analysis is conducted on blended yarn samples with wool content between 80% and 99%, and the performance of this semi-supervised adversarial network quantitative analysis model is compared with that of other quantitative models. The fourth is a field prediction experiment for the subdivision comprehensive model of medium to high wool content blended fabrics. A semi-supervised adversarial network quantitative analysis model is trained using blended fabric samples with wool content between 40% and 99% and deployed in the sorting system. The operator conducts on-site testing data for accuracy, analysis time, and other tests. The experimental results show that the semi-supervised regression method based on a Generative adversarial network is superior to PCR,PLSR, SVR, BPNN and other models, and the prediction R2 of this model reaches 0.94. After repeated on-site testing, the model can quickly extract blended samples with a wool content of over 40%.
在废旧纺织品回收的不同环节中, 需要采用不同的评价方法。 对于回收企业, 具有某种材质高含量的混合材质样品也具有一定的经济效益, 尽可能的识别出这些高含量混纺样品能提高收益率。 对于纺织企业, 需对不同来源的回收样品进行质量检控, 有效识别混杂在纯材质中的混纺样品以及开松后的纤维化样品的质量管理。 国内外众多研究者在研究合适的定量分析算法, 以适应不同环节不同要求下的定量分析, 保障企业的质量管控。 张国丽[1]等构建了简化模型对棉/涤混纺织物中棉含量进行了分析; 田玲玲[2]等提出用近红外光谱定标法对桑蚕丝/氨纶两组分含量进行检测; 杜文倩[3]等利用383个未参与建库的聚酯、 棉、 羊毛、 锦纶、 真丝、 粘胶、 腈纶、 聚酯/毛、 聚酯/锦纶、 真丝棉、 锦纶/氨纶、 聚酯/棉12类织物样品对所建谱库进行在线检索识别。 郑佳辉[4]等基于在线原始谱图, 探讨出最佳光谱预处理方法为S-G平滑+最大最小归一化(MMN)+S-G导数, 并利用偏最小二乘法建立了废旧聚酯/棉混纺织物的在线近红外定量分析模型。 时瑶[5]等利用偏最小二乘法(PLS)建立涤/棉混纺织物中涤含量的近红外(NIR)定量分析模型。
近年来深度学习方法大放异彩[6, 7, 8], 国内外众多学者结合深度学习和近红外光谱分析技术, 提出了很多新的分析方法。 Kim等[9]提出了一种基于堆叠收缩自动编码器(SCAE)的模型来处理近红外光谱图像。 Skotare等[10]提出了一种基于卷积神经网络和迁移学习的定量分析建模及模型传递方案, 以提高模型在单仪器和跨仪器上的预测性能。 李灵巧[11]等通过引入深度卷积生成对抗网络(DCGAN)提取拉曼光谱内部特征, 对抗生成新的拉曼光谱, 从而达到扩充数据集目的。 Zheng等[12]基于近红外光谱和变分自编码建模鉴别多类药物。
针对回收废纺在线分拣过程, 提出了一种基于生成对抗网络的半监督回归[13, 14, 15, 16]方法, 该方法使用一些标记样本和大量未标记样本来训练半监督回归器。 半监督回归器由神经网络组成的生成器和由神经网络构成的判别器组成。 生成器用于生成尽可能接近实际标记和未标记训练数据集内容的混合样本。 鉴别器用于验证生成器生成的样本并预测这些样本的连续标记。 生成的网络通过特征匹配损失进行训练, 损失函数是鉴别器中间层真实样本的输出与生成样本之间的误差平均值。 判别式有两个输出, 一个用于预测序列标记, 另一个用于确定生成的样本是真样本还是假样本的概率。 通过使用传统的无监督生成对抗性网络损失函数和监督回归损失的组合来训练判别式。
采用Pertern公司的非接触式漫反射近红外光谱仪DA7440作为光谱采集设备, 光谱范围为950~1 650 nm, 分辨率5 nm, 扫描次数100次, 生成光谱时间小于700 ms。 软件开发环境为windows10操作系统下anaconda3, 编程语言为Python。
所有样品、 采集设备、 实验场地均由上海季采环保科技有限公司提供。 样品的化学分析结果(标签)由北京服装学院提供。 样品集如表1所示。
| 表1 样品类型和数量 Table 1 Type and quantity of samples |
表1中含毛混纺是指纯羊毛和其他纯材质的两种或多种材质混纺, 每个样本均有各成分含量值。 现场测试集中包含纯腈纶3件、 纯棉48件、 纯涤纶47件、 纯毛41件和混纺86件, 其中86个混纺样品中有40个不同羊毛含量的混纺样品。 表1中纯材质样品和混纺样品根据不同比例, 分成训练集和测试集; 现场测试集用于模型的最终性能验证和评测, 训练集用于模型的训练。
回收的废旧纺织物通常都经过了几年的使用和闲置, 品种和颜色繁多, 加工工艺情况不明, 损坏程度不一, 厚薄程度不一, 光谱采集部位随机, 容易受到纽扣、 拉链等影响, 导致光谱发生不同程度的变化, 影响模型的分类性能。
图1所示为部分纺织物的原始近红外光谱图。 (a)为纯腈纶、 纯棉、 纯涤纶和纯毛样品光谱各2条, 可以看出不同种类的纯材质均有特有的特征且相互之间具有较大的差异, 区分不同的纯材质纺织物比较容易, 但如果采用纯材质样品分别作为训练模型的正负样本则很难获得较好的分类性能。 (b)为部分纯毛的原始光谱, 可以看出纯毛样品具有一些共同的特征, 但也有部分样品显示出明显的其他特征, 由于样品标签并不包含样品的颜色、 工艺等信息, 我们无法确定造成同种材质样品表现出不同特征的具体原因, 但模型必须能够准确将受到各种影响的纯材质样品提取出来。 (c)为部分纯毛和含毛混纺的样品光谱, 可以看出不同含量和不同材质混纺以及混纺工艺都会对样品光谱造成不同程度的影响, 高含量的混纺样品和部分特殊混纺样品(如粘纤)会严重影响模型的分类准确性, 这些样品作为训练模型的负样品效果会比较好。 但实际上混纺种类繁多, 获得更多的混纺样品需要付出较大的时间和经济成本。 (d)为部分不同颜色的纯棉样品光谱, 可以看出不同的颜色工艺会对样品光谱造成极大的影响。 当然这些样品除了颜色不同之外, 其他加工工艺是否相同并不确定, 因此造成的影响是否完全由染色引起也不能确定, 只是可以说明, 对于废旧纺织物来说, 很多因素会造成样品光谱的极大变化, 从而增加了模型的分类难度。 (e)为同一个样品在实验室环境下的五次采样光谱, 可以看出在实验室环境下, 每次采样会产生不同的漂移; 在现场环境下, 会产生更大的差异, 对定量分析结果造成较大的误差。
 | 图1 几种样品的原始光谱 (a): 纯材质; (b): 纯羊毛; (c): 部分纯毛和含毛混纺样品; (d): 不同颜色纯棉; (e): 同一样品的多次采样Fig.1 Several original spectrograms (a): Spectrum of several pure materials; (b): Several pure wool spectra; (c): Sample spectra of partial pure wool and wool blended fabrics; (d): Spectra of pure cotton with several different colors; (e): Multiple sampling spectra of the same sample |
总体来说, 废旧纺织物的近红外光谱具有明显的种类特征, 但也受到诸多因素影响, 造成分类错误的样品主要是一些高含量混纺和某些特殊工艺混纺样品, 收集更多的数据集是提高模型准确性的最佳途径, 但这需要付出极大的时间和经济成本, 工业上很难在获得完备的数据集之后再开展工作, 我们必须尽量从算法上处理这些问题。
考虑到已获取的训练样本集的数量, 用深度神经网络对100个混纺样品进行定量分析, 会产生较大的过拟合。 深度神经网络的复杂度和优越性必须要有足够多的样本集支撑。
为此, 采样各种纯材质样本和部分混合样本共同训练模型, 其中生成网络通过将两种或三种纯材质样本进行混合形成混纺样本, 以此获得足够多的具有不同比例成分的混合材质训练样本。
1.4.1 半监督生成式对抗网络
在所获得的数据集中有少量标记数据和大量未标记数据, 比较适合采用半监督学习方法。 对给定的K个标记样本的训练集SK={(xi, yi )|1≤ i≤ K}和M个无标记样本的训练集SM={xi |1≤ i≤ M}, 其中样本输入表示为xi∈ x(1≤ i≤ M+K), 样本标签表示为yi∈ y(1≤ i≤ K), 且满足K≪M。 学习的任务是构建合适的算法从SK和SM中学习分类器f: x→ y。
半监督生成式对抗网络架构如图2所示。
 | 图2 半监督生成式对抗网络结构图Fig.2 Structure of semi supervised generative countermeasure network |
由于判别器既有标记数据又有无标记数据, 需要利用有监督训练结果来改善无监督算法性能。 对无标签数据进行聚类, 并将与生成器的输出光谱最相近的类簇中的训练样本作为模型的条件变量, 进行无监督的非对称条件生成式对抗训练。 判别器采用非参数贝叶斯回归方法y=ω x+ε , 根据贝叶斯推断可知
对于未知的样本x* 的预测分布可通过似然估计得到
以输入x为条件变量, 根据条件生成式对抗网络, 得到对抗损失函数
式(3)中, y'∈ Y* 。 Y* 是真实标签和生成光谱聚类得到的标签合集。
1.4.2 模型评估
模型的评估采用预测均方误差RMSE和确定系数R2两个指标, 计算公式分别为
这里yi和
为了测试算法的有效性, 开展了多个实验验证。 第一个实验为混纺光谱生成实验, 用于验证生成对抗网络能够根据内在规律有效生成混合样本光谱。 第二个实验为半监督对抗网络定量分析性能对比实验, 对羊毛成分分析模型训练与测试, 并将本半监督对抗网络定量分析模型与其他定量模型进行性能对比。 第三个实验为现场高羊毛含量混纺细分模型预测对比实验, 用羊毛含量在80%~99%之间的混纺样品进行成分分析, 并将本半监督对抗网络定量分析模型与其他定量模型进行性能对比。 第四个实验为中高羊毛含量混纺细分综合模型现场预测说验, 用羊毛含量在40%~99%之间的混纺样品训练半监督对抗网络定量分析模型并部署在分拣系统, 由操作员进行现场测试数据进行准确率、 分析时间等测试。
待生成对抗网络训练结束后, 取生成网络的输出若干个, 记录混合参数并绘制光谱, 如图3所示。
 | 图3 生成光谱和实际光谱 (a): 生成光谱和实际光谱; (b): 两种成分相近的样品的生成光谱和实际光谱Fig.3 Spectra of the generated sample and actual sample (a): Several spectra of the generated sample and actual sample; (b): Spectra of the geoerated sample and actual sample with similar compositions |
其中(a)为部分生成光谱和部分实际光谱, 他们之间并无任何联系, 但可以看出他们均体现出了主要成分的峰值特征。 (b)为选出的两种混合比例比较接近的光谱, 其中第一、 三条光谱是生成光谱, 第二、 四条光谱是实际光谱。 可以看出生成光谱既体现出了主要成分的峰值特征, 也体现出了多样性, 能够丰富混纺材质光谱样本, 从而提高定量分析性能。
实验数据集采用表1中75个纯腈纶、 226个纯棉、 240个纯涤纶、 473个纯羊毛、 100个混纺和3 000个无标签样本构成, 按照7∶ 3的比例随机抽取构成训练集和测试集。 光谱预处理方法均使用SG一阶求导和SNV。 训练完成后获得的判决器的比例输出可作为最终的定量分析模型。 对比实验采用的分析模型有主成分分析PCR、 偏最小二乘法PLSR、 支持向量机回归法SVR和反向传播神经网络BP-ANN。 各模型均进行了一定的优化, PCR和PLSR的主因子数分别为15和12, 累计解释度能达到99.5%; SVR采用网格优化的高斯核; BP-ANN为单隐含层, 隐含层使用传输函数为对数函数, 输出层使用反正切函数, 网络误差为均方根误差, 误差搜索使用可变尺度共轭梯度(scaled conjugate gradient, SCG)算法。 各模型预测结果如表2所示。
| 表2 羊毛含量预测结果 Table 2 Wool content prediction results |
从表2中可以看出, 各种模型总体预测效果均不理想, 但本文提出的CGANR仍然表现出稍好的性能。 预测的数据分布如图4所示。
 | 图4 不同模型预测值分布 (a): PCR; (b): PLSR; (c): SVR; (d): BP-ANN; (e): CGANRFig.4 Plots of predicted values of each model (a): PCR; (b): PLSR; (c): SVR; (d): BP-ANN; (e): CGANR |
通过预测数据分析可知, 造成整体预测效果不理想的主要原因是模型对低含量羊毛混纺的预测结果比较差。 各种纯材质样本具有明显的波长特征, 但是在低含量的混纺中, 该特征往往会被主含量和噪声淹没, 难以成功发掘。 而不同种材质混纺和不同比例的混纺形成的差异是非常大的, 这也是造成预测不理想的原因。
根据市场经济需求, 只有40%以上羊毛含量的混纺才具有经济效益。 由此可按照羊毛含量进行区间细分, 从而提高预测效果。
实验数据集采用表1中75个纯腈纶、 226个纯棉、 240个纯涤纶、 473个纯羊毛、 100个混纺和3 000个无标签样本构成。 光谱预处理方法均使用SG一阶求导和SNV。 训练集由各纯材质样本和部分羊毛含量80%以上的混纺样本构成。 训练完成后获得的判决器的比例输出可作为最终的定量分析模型。 测试集由生成器产生若干个80%以上羊毛含量的生成样本和剩余羊毛含量80%以上的混纺样本构成。 对比实验采用的分析模型有主成分分析PCR、 偏最小二乘法PLS、 支持向量机回归法SVR和反向传播神经网络BP-ANN。 各模型预测结果如表3所示。
| 表3 羊毛含量预测结果 Table 3 Wool content prediction results |
从表3中可以看出, 各种模型总体预测效果具有明显提升, CGANR仍然表现出更好的性能。 预测的数据分布如图5所示。 通过预测数据分析可知, 对于80%以上羊毛含量的混纺成分预测结果已经明显提升, 高含量的材质特征波长比较明显, 受干扰影响相对较小, 因此各种模型的预测能力都有大幅度提升。 然而实际应用时, 模型预测的对象并非只有高含量混纺, 还有更多含量低一些的如40%~80%之间的混纺。 这些样本也是具有一定经济效益的, 必须想办法提高这些样本的预测结果。
 | 图5 不同模型预测值分布 (a): PCR; (b): PLSR; (c): SVR; (d): BP-ANN; (e): CGANRFig.5 Plots of predicted values of various models (a): PCR; (b): PLSR; (c): SVR; (d): BP-ANN; (e): CGANR |
分拣系统由一台台式计算机为主控器, CPU为Intel酷睿I7, 内存16GB, 无GPU。 计算机通过网络接口连接Pertern公司近红外光谱仪DA7440, 采集一次光谱耗时0.9秒并生成csv文件。 本算法部署在WINDOWS应用程序中, 通过读取csv文件中的数据, 使用以训练好的模型完成分类。
在分拣设备上部署实验五的模型。 现场提供了40件含羊毛混纺样本, 其中羊毛含量超过80%的样本14件, 羊毛含量在40%~80%之间的混纺样本16件, 羊毛含量低于40%的混纺样本10件。 取若干件各种纯材质样本, 包括纯毛、 纯棉、 纯锦纶、 纯涤纶、 纯氨纶等。 上述这些样本均已知成分且装有吊牌标签, 便于实验数据统计。 另取大量未知成分的装有空吊牌的废旧衣服样本, 一起构成1000件现场测试数据。 由操作员一件件的放置在分拣线上, 分拣线上有称重传感器, 作为启动一次分拣的起始阀门, 分拣线实物图如图6所示。
 | 图6 现场测试图Fig.6 Photo of field test |
当称重传感器检测到纺织物后, 延迟200 ms启动光谱仪采集光谱, 然后经过光谱预处理和分类器判决, 控制转盘系统将该纺织物投入对应的箱子中。 由于各部分是并行工作的, 平均每件纺织品的处理时间小于1.2 s, 符合每小时2 000件的分拣要求。 当1 000件测试样品完成分拣后, 由操作员手工根据每件样品的分拣结果和其上的吊牌统计分拣结果并记录。 重复实验三次, 根据不同要求统计测试结果。
首先统计每次混纺样本成分预测值和实际值对比情况, 如图7所示。
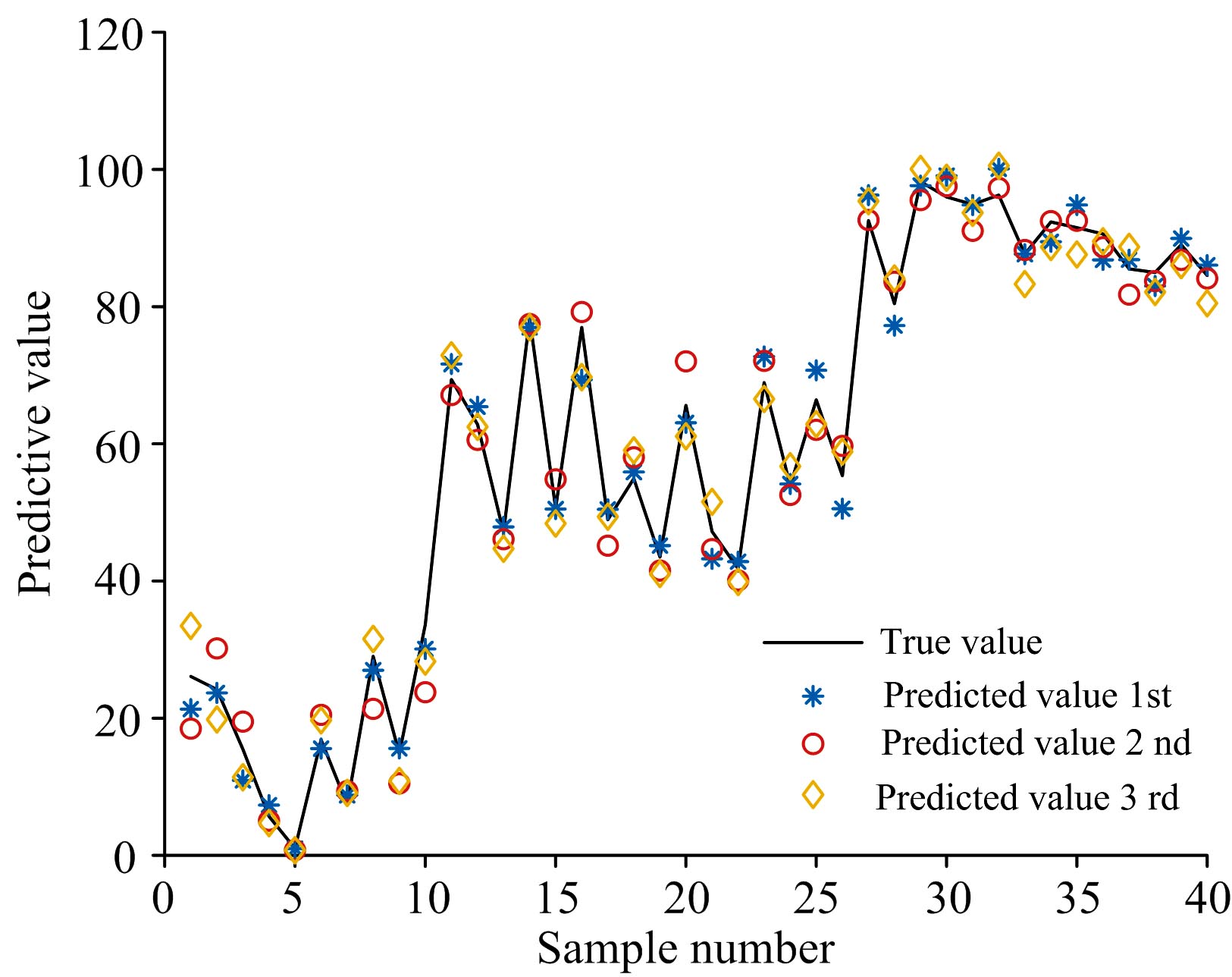 | 图7 预测值和实际值对比图Fig.7 Comparison of predicted value and actual value |
由图7可以看出, 模型对各含量混纺的成分预测具有一定的误差, 但基本上比较接近真实值, 高含量的预测误差在10%左右, 低含量的预测误差相对大些, 这和之前的实验数据基本相符。
根据实际废旧回收纺织品的分拣过程, 通常会将成分按等级区分, 如纯羊毛、 高含量羊毛(80%以上)和中等含量羊毛(40%以上)等。 由此形成第二种统计测试结果, 如表4所示。 表中P表示纯羊毛, H表示高含量混纺, M表示中含量混纺, L表示低含量混纺。 TP表示正确预测的正等级, 即需要提取出的高价值等级, 应该尽可能接近实际数量。 FP表示错误预测的正等级, 即将混纺样本判决为纯材质样本, 属于误判, 会降低产品的纯度。 FN表示错误预测的正等级, 即将纯材质样本判决为混纺样本, 属于漏判, 会降低产品的效益。 精准率根据TP/(TP+FP)计算, 召回率根据TP/(TP+FN)计算。 上表中的精准率和召回率基本符合工业化生产的效益要求。
| 表4 现场成分预测等级测试准确率 Table 4 Test results of accuracy rate of on-site component prediction grade |
构建了一种半监督回归方法, 利用部分标记样本和大量的未标记样本进行模型训练。 模型能够在大量未标记样本中获取近红外光谱相关特征, 结合标记样本进行伪标记样本生成, 从而充实训练集规模并改善训练集正负样本分布不平衡状态。 半监督回归模型包括生成模型和判别模型两个部分, 可以根据需求产生逼真的伪标记模型, 用于扩充数据集; 也可以对未知样本进行准确的成分分析。 实验结果表明, 该方法能够通过少量标记样本集进行训练, 并快速有效的提取出较高羊毛含量(40%以上)的混纺样品, 误差性能超过PCR、 PLSR、 SVR、 BPNN等模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|