



{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于NSGA-Ⅱ算法选择光谱反射率重建样本的研究
[林鹭 , 王智峰
, 王智峰* , 李超]
, 王智峰, 李超]
|
|


作者简介: 林 鹭, 女, 1999年生, 辽宁科技大学计算机与软件工程学院硕士研究生 e-mail: 1090569368@qq.com
为解决光谱反射率重建过程中训练样本数目庞大导致工作量大, 重建精度不高等问题, 提出一种基于NSGA-Ⅱ算法的光谱反射率重建样本选择方法。 近日Liang等提出了一种从大量样本数据中选取具有代表性样本的新方法, 定义光谱重建误差为均方根误差与拟合优度系数的乘积, 以这一标准选择光谱重建误差最小的样本作为代表性样本进行光谱反射率重建。 受Liang等人工作的启发结合NSGA-Ⅱ算法选择代表性样本, 先对全体训练样本使用多项式回归算法和伪逆法进行光谱反射率重建, 再使用NSGA-Ⅱ算法, 设定两个目标函数, 一个是所需代表性样本个数的光谱均方根误差的和, 另一个是拟合优度系数倒数的和, 令两个目标函数值最小。 将经过NSGA-Ⅱ算法挑选出的Pareto等级为1的全部样本按照样本出现次数由高至低排序, 以此顺序从高到低依次选为代表性样本, 直至达到所需代表性样本个数。 若从Pareto等级为1的样本集合中挑选的代表性样本数不足所需要的个数则选择下一等级出现次数最多且没有被选择过的样本直至代表性样本数达到需求。 将1 269块无光泽Munsell标准色卡按照样本下标划分为偶数色卡、 奇数色卡, 第一组实验用Munsell奇数色卡为全体训练样本, 从Munsell偶数色卡中随机选择20个色块为测试样本。 第二组实验选用Munsell偶数色卡为全体训练样本, 从Munsell奇数色卡中随机选取20个色块为测试样本。 第三组实验训练样本与第一组相同, RC24色卡为测试样本。 将该方法与Mohammadi、 Cao、 Liang等提出的三种样本选择方法进行对比。 通过实验得到使用NSGA-Ⅱ算法结合多项式回归与伪逆法选择的代表性样本重建的光谱反射率在均方根误差和色差两个指标上均优于现有的样本选择方法, 并且该方法不限于特定系统, 具有通用性。
To solve the problems of heavy workload and low reconstruction accuracy caused by the large number of training samples in the process of spectral reflectance reconstruction, a sample selection method for spectral reflectance reconstruction based on the NSGA-Ⅱ algorithm was proposed. Recently, Liang et al. proposed a new method to select representative samples from many sample data. The spectral reconstruction error was defined as the product of the root mean square error and goodness-of-fit coefficient. Based on this standard, the sample with the smallest spectral reconstruction error was selected as the representative sample for spectral reflectance reconstruction. Inspired by the work of Liang et al., this method combined with the NSGA-Ⅱ algorithm to select representative samples. First, the polynomial regression algorithm and pseudo-inverse method were used to reconstruct spectral reflectance for all training samples. Then, the NSGA-Ⅱ algorithm was used to set two objective functions. One is the sum of the spectral root mean square error of the required number of representative samples; the other is the sum of the reciprocal of the goodness-of-fit coefficients, which minimizes the values of the two objective functions. All samples with Pareto level 1 selected by NSGA-Ⅱ algorithm are sorted according to the occurrence times of samples from high to low and selected as representative samples from high to low until the required number of representative samples is reached. Suppose the number of representative samples selected from the sample set with Pareto level 1 is less than the required number. In that case,the samples that appear most frequently in the next level and have not been selected are selected until the number of representative samples reaches the demand. The experiment divided 1 269 dull Munsell standard color cards into even color cards and odd color cards according to sample subscript. In the first group of experiments, Munsell odd color cards were used as the whole training samples, and 20 color blocks were randomly selected from Munsell even color cards as the test samples. In the second group of experiments, Munsell even color cards were selected as the whole training samples, and 20 color blocks were randomly selected from Munsell odd color cards as the test samples. The third group of experimental training samples is the same as the first group, and the RC24 color card is the test sample. The proposed method is compared with the three sample selection methods proposed by Mohammadi, Cao and Liang. The experimental results show that the NSGA-Ⅱ algorithm combined with polynomial regression and pseudo-inverse method to select representative samples for spectral reflectance reconstruction is superior to the existing sample selection methods in terms of root mean square error and color difference, and this method is not for a specific system has generality.
随着数字图像技术的发展, 人们对彩色图像的复制与还原的要求越来越高, 光谱反射率重建是颜色复制的核心技术[1]。 但是在不同的应用领域例如印刷、 纺织、 文化遗产修复等均有大量的特定的数据库, 如果使用数据库内全部样本进行训练重建光谱反射率会加大工作量浪费资源, 而且以往的研究表明, 含有大量样本的数据库有显著的样本冗余。 所以从包含大量样本的数据库中选取具有代表性的样本重建光谱反射率在越来越多的领域里开始变得十分重要。
在以往的研究中Mohammadi等提出了基于层次聚类分析的样本选择方法[2], 使用层次聚类法将样本分为不同的簇, 计算每个簇中向量的夹角挑选平均夹角最小的样本作为当前簇的代表性样本, 该方法能减少用于训练的样本数量, 但在特定色调下才能体现该算法良好的性能, 对多个测试集平均均方根误差达到0.032以下。 Shen等提出了一种基于特征向量的方法和一种基于虚拟成像的样本选择方法[3], 前者是用特征向量模拟整个反射率集合, 后者是试图最小化训练集与测试集的均方根误差从而选择代表性样本, 重构CDC图表的光谱反射率平均均方根误差达到0.008 9。 Eckhard等提出了一种基于递归自上向下算法的印刷油墨光谱代表性样本选择方法[4], 重构CC140数据集平均均方根误差达到0.031。 Cao等提出以较小色差选择样本的方法[5]重建Munsell色卡平均均方根误差已达到0.017 7。 Liang等提出定义光谱重建误差TOTAL=RMSE× (1-GFC), 以此标准选择代表性样本[6], 重构壁画光谱反射率平均均方根误差达到0.032 5。 Zhang等提出Sine-SSA-Bp算法[7], 在小训练集上有较好的重建精度, 当训练集与测试集在2∶ 1的比例下重构RC24色卡平均均方误差达到0.012。
上述选择样本的研究方法大多只考虑了均方根误差或色差某个单一的指标, 不能高效地提升光谱反射率重建精度。 方法受Liang等的启发, 本工作提出结合RMSE(均方根误差)和GFC(拟合优度系数)两项指标使用NSGA-Ⅱ 算法进行多目标优化, 考虑RMSE、 GFC两个目标的因素来选择代表性样本进行训练。 实验结果表明使用本方法选择的代表性样本重建光谱反射率精度高于现有的样本选择方法, 同时本方法不针对于特定的系统, 具有通用性。
基于NSGA-Ⅱ 算法选择光谱反射率重建代表性样本的步骤如图1所示。
 | 图1 本文选择代表性样本的步骤Fig.1 Selection process of representative samples' |
步骤1: 获取相机RGB响应值重建样本数据库光谱反射率
假设照相机是理想的线性光电转换系统, 样本的一个色块的响应值可以由式(1)得到
式(1)中, d为色块的相机RGB响应值列向量; λ 为波长; S(λ )为光源光谱功率; R(λ )为物体表面的光谱反射率; o(λ )为CCD相机的灵敏度函数; c(λ )为相机滤色片的透射率; t为噪声, 通常忽略噪声。 式(1)写成矩阵向量形式的代数方程如式(2)
在式(2)中M为包含相机的光谱灵敏度的矩阵; r为物体表面光谱反射率列向量通常取400~700 nm, 10 nm间隔取点, 共31个分量。 光谱反射率重建即为式(2)的逆过程用式(3)表示。
式(3)中, r'为重建的光谱反射率, Q为相机响应到光谱反射率的转换关系矩阵, d为待测样本的相机响应值。
将相机响应值d通过3阶多项式回归模型预测样本的三刺激值[8], 如式(4)
式(4)中, U为3× h的矩阵表示h个样本的三刺激值的列向量矩阵, A为3× 20的多项式模型系数矩阵, V为20× h的矩阵是相机响应值d按3阶多项式模型展开的列向量矩阵。
本文使用伪逆法重建光谱反射率, ‘ +’ 为伪逆算子, 转换矩阵Q可表示为式(5)。
光谱反射率重建可表示为式(6)
步骤2: 计算重建的样本数据库光谱反射率的均方根误差和拟合优度系数
光谱均方根误差计算公式如式(7), n=31, 上标‘ T’ 代表转置运算。
拟合优度系数计算公式如式(8)
步骤3: 确定NSGA-Ⅱ 算法的决策变量与目标函数
NSGA-Ⅱ 算法是解决多目标优化问题的一种算法, 具有良好的可扩展性, 可以应用于大规模数据的样本选择问题。 多目标优化问题一般定义如式(9)
式(9)中, x为决策变量, F(x)为目标函数, j为目标函数个数, S为x的取值范围。
结合上文, 将训练样本数据库中的样本下标数设计为决策变量x, 训练样本个数为n, x的取值范围S即为[1, n]。 由于RMSE越小重建精度越高, GFC越大重建精度越高, 设计两个目标函数, 一个为所需代表性样本个数的RMSE的和, 另一个为
步骤4: 选择代表性样本
NSGA-Ⅱ 算法详细执行过程可参照参考文献[9, 10], 通过上文设计的NSGA-Ⅱ 算法我们可以得到多组样本集合, 这些样本集合的Pareto等级不同, 等级越低对应的目标函数效果越好, 反之等级越高效果越差, 即等级越低
步骤5: 重建测试样本光谱反射率
使用步骤1—步骤4选出的代表性样本, 通过式(4)—式(6)使用多项式回归模型和伪逆法完成对测试样本的光谱反射率重建。
实验使用尼康D610数码相机和Konica Minola分光光度计CM-2600d获取数据, 实验光源为CIE光源D65, A, D50。
为模拟含有大量训练样本的数据库, 将1 269块无光泽Munsell标准色卡按照样本下标划分为偶数色卡、 奇数色卡, 第一组实验用Munsell奇数色卡为全体训练样本, 从Munsell偶数色卡中随机选择20个色块为测试样本(Even_test20)。 第二组实验将训练集和测试集调换, 选用Munsell偶数色卡为全体训练样本, 从Munsell奇数色卡中随机选取20个色块为测试样本(Odd_test20)。 第三组实验, 使用Munsell奇数色卡为全体训练样本, RC24色卡为测试样本(RC24)。
Mohammadi等提出的基于层次聚类分析的样本选择方法, 选择24个代表性样本进行训练重建光谱反射率, 光谱均方根误差低于其他训练样本数目得到的结果; Cao等提出以较小色差选择样本的方法, 选择3个训练样本并使用平方反加权方式重建光谱反射率效果最佳; Liang等使用新定义的光谱重建误差选取60个代表性样本重建光谱反射率效果趋于稳定。 本工作使用以上三种方法的最优结果进行对比。
使用本方法对三组实验的全体训练数据以10为间隔挑选30~100个代表性样本进行验证, 选取不同的代表性样本数进行反射率重建得到的评价指标结果如图2所示, 由图可知当选取60个样本为代表性样本时三组实验平均均方根误差最小、 平均拟合优度系数最大, 可达到最佳精度, 重建效果趋于稳定。
 | 图2 不同代表性样本数的重建光谱均方根误差(a)和平均拟合优度系数(b)Fig.2 Mean spectral RMSE (a) and mean spectral GFC(b) of reconstructed spectrum under different representative sample numbers |
NSGA-Ⅱ 算法中设置60个输入参数即代表性样本个数, 2个目标函数, 初始化种群设置为100, 最大迭代次数设为200, 交叉概率设为0.8, 变异概率设为0.05。 实验采用光谱指标RMSE和CIED65、 CIEA、 CIED50三种光源下计算的CIELAB平均色差Δ Eab如式(11)来比较本方法与Mohammadi、 Cao、 Liang等提出的三种方法光谱恢复精度。
由于Liang的方法优于当前现有样本选择方法, 故使用本方法选出的代表性样本与Liang的方法选出的代表性样本进行对比。 图3(a)给出了第一组实验测试样本为(Even_test20), 两种方法选出的代表性样本的RGB分布情况。 图3(b)给出了第二组实验测试样本为(Odd_test20), 两种方法选出的代表性样本RGB分布情况。 由图3(a)可知多数测试样本分布于R、 G、 B三个分量较小的区域, 本方法选出的代表性样本覆盖精度更高, Liang的方法选出的代表性样本多分布于三维空间的上方, 距离测试样本较远相似度较低。 由图3(b)可知在三维空间的底部使用本方法选择的代表性样本与测试样本分布更紧密且数目远远多于Liang的方法选出代表性样本, 反之Liang的方法选出的代表性样本多分布于三维空间中部, 但此区域内测试样本较少。 已知训练样本与测试样本尽可能相似时, 光谱反射率重建的性能更好, 因此由图3可知使用两种不同方法选择的代表性样本进行重建光谱反射率, 本方法的光谱反射率重建精度好于Liang的方法。
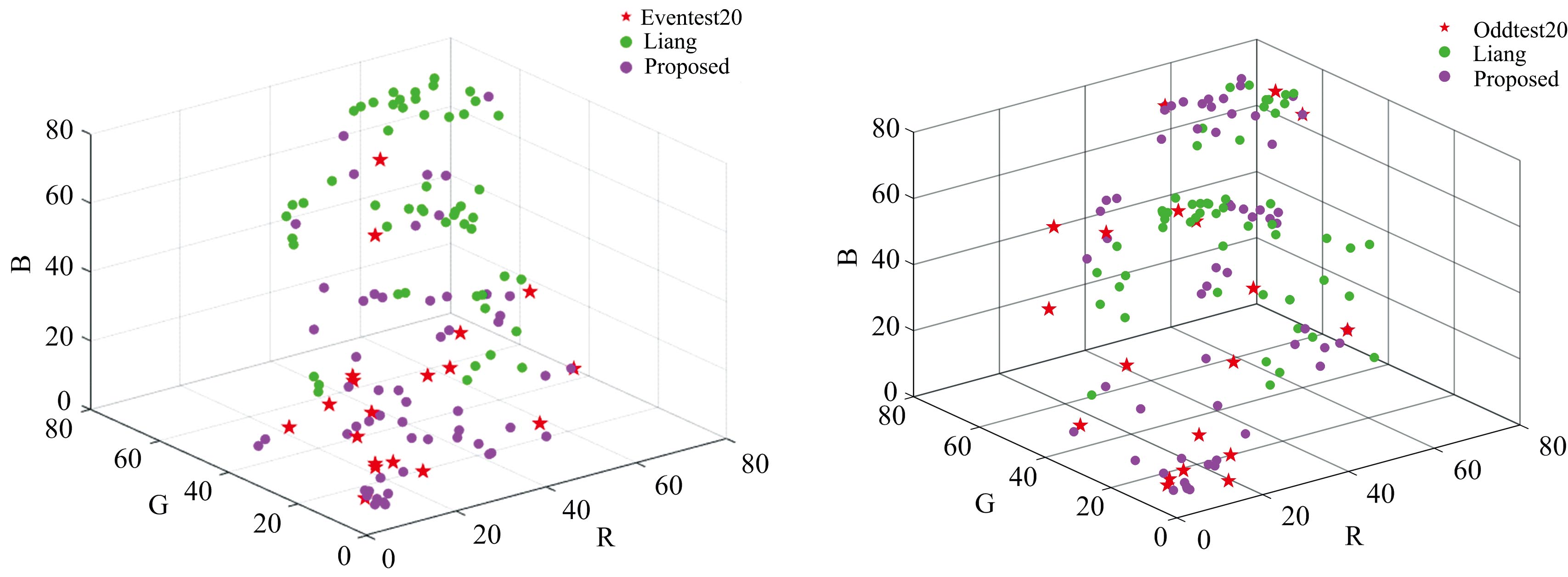 | 图3 不同测试样本的代表性训练样本RGB分布情况 (a): 测试样本为Even_test20; (b): 测试样本为Odd_test20Fig.3 RGB distribution of representative training samples for different test samples (a): Even_test20; (b): Odd_test20 |
图4演示了三组实验中随机两个测试色块的反射率重建曲线。 由图4可知使用本方法选择的代表性样本重建的光谱反射率与实际光谱反射率曲线基本拟合, 与使用Mohammadi、 Cao、 Liang等分别提出的三种代表性样本选择方法相比耦合度更高, 重构效果更好。
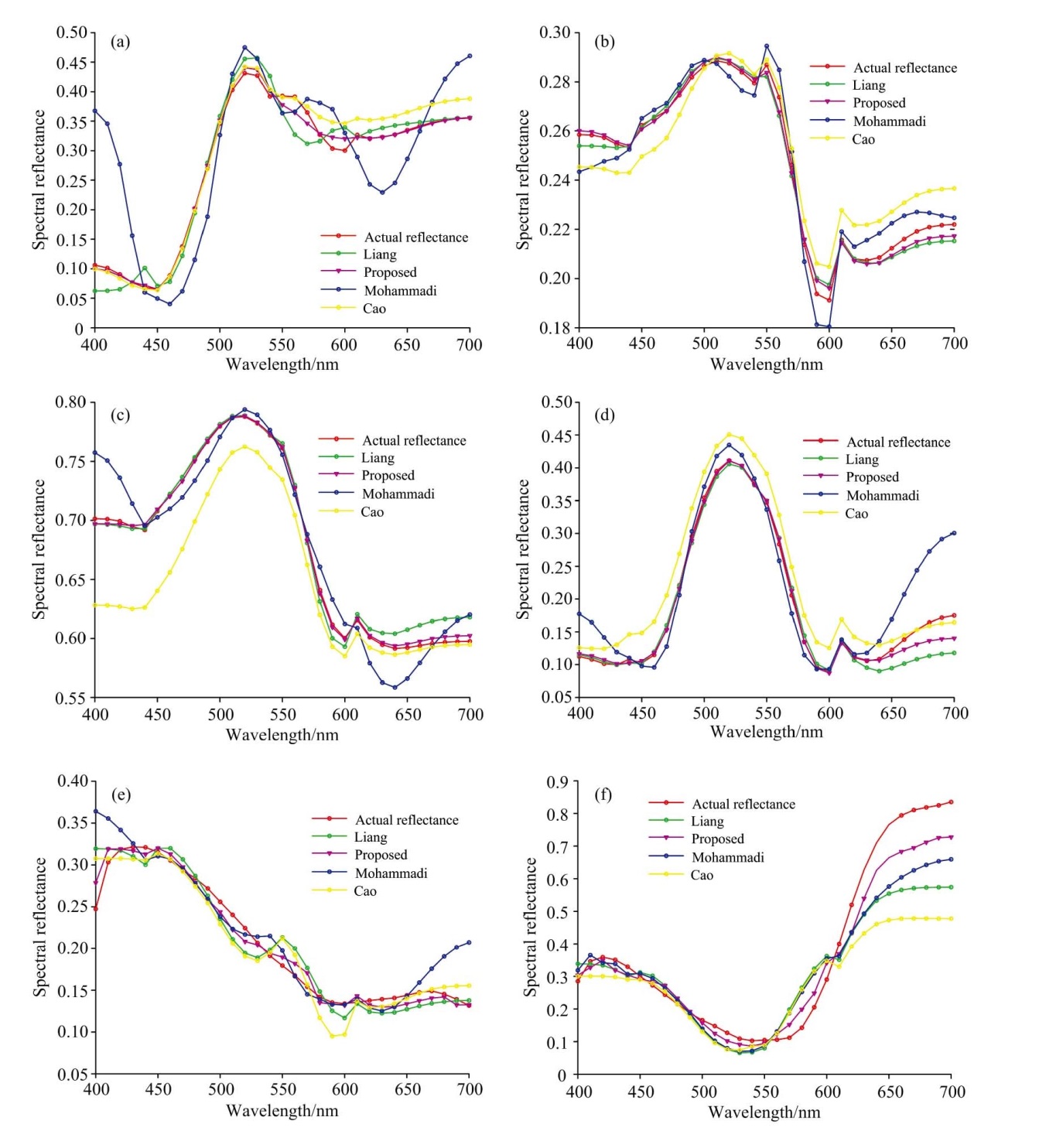 | 图4 四种方法重构的光谱反射率曲线 (a): Even_test20 #1; (b): Even_test20 #14; (c): Odd_test20 #10; (d): Odd_test20 #20; (e): RC24 #3; (f): RC24 #17Fig.4 Reflectance spectra reconstructed by four methods (a): Even_test20 #1; (b): Even_test20 #14; (c): Odd_test20 #10; (d): Odd_test20 #20; (e): RC24 #3; (f): RC24 #17 |
表1是四种不同方法选择的代表性样本作为训练样本重建测试样本光谱反射率的精度数据, 分别按照光谱均方根误差和色差的平均值、 最大值、 最小值来比较重建结果, 本文方法除第一组实验中均方根误差的最小值不是最优, 另外五个指标均优于其余三种样本选择方法。 第二组实验和第三组实验各项指标均优于其他样本选择方法。 说明本文提出的基于NSGA-Ⅱ 算法选择代表性样本用于重建光谱反射率, 可有效提高光谱反射率重建精度。
| 表1 四种方法的重构精度对比 Table 1 Comparison of reconstruction accuracies of the four methods |
代表性样本的选择对光谱反射率重建的精度有相当大的影响。 提出了基于NSGA-Ⅱ 算法选择光谱反射率重建样本。 首先重建训练样本数据库的光谱反射率, 计算出重建的样本数据库光谱反射率的均方根误差和拟合优度系数, 使用NSGA-Ⅱ 算法, 以RMSE的和与
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|