
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于拉曼光谱结合CNN-LSTM深度学习方法的铁皮石斛总黄酮含量快速检测研究
[刘宗溢1, 2  , 张彩虹
, 张彩虹1, 2 , 蒋健康1, 2 , 沈斌国3 , 丁艳菲1, 2 , 张雷蕾1, 2, * , 朱诚1, 2, * ]
, 张彩虹, 朱诚]
|
|


作者简介: 刘宗溢, 1998年生, 中国计量大学生命科学学院硕士研究生 e-mail: lzyzgjldx@163.com
铁皮石斛具有很高的商业价值和营养价值, 将云南文山、 广西金秀、 安徽霍山、 浙江台州四个产地共130个样品作为研究样本, 在785 nm激光下利用便携式拉曼光谱仪获得了铁皮石斛拉曼光谱, 采用NaNO2-Al(NO3)3-NaOH比色法测定铁皮石斛总黄酮含量。 以每条经过归一化后的拉曼光谱数据作为输入, 利用Savitzky-Golay卷积平滑(SG平滑)、 标准正态变量变换(SNV)、 多元散射校正(MSC)等不同预处理方法对光谱数据进行处理, 以偏最小二乘(PLS)、 支持向量机(SVM)和卷积神经网络-长短期记忆神经网络(CNN-LSTM)模型作为比较, 竞争自适应重加权采样(CARS)作为波长选择方法, 对不同的机器学习模型进行比较研究。 采用以下预测质量指标: 校正集、 测试集相关系数( Rc、 Rp), 校正集、 测试集均方根误差(RMSEC、 RMSEP), 评价铁皮石斛总黄酮含量预测模型的性能。 结果表明: 光谱在经过SNV预处理之后, CNN-LSTM方法预测铁皮石斛总黄酮含量准确率最高, Rc、 Rp分别为0.983和0.964, RMSEC、 RMSEP分别为0.032和0.047 mg·g-1。 结合拉曼光谱建立的SNV-CNN-LSTM深度学习模型准确可靠, 具有很强的鲁棒性, 优于传统的机器学习模型(PLS、 SVM)。 利用拉曼光谱结合CNN-LSTM模型对铁皮石斛总黄酮含量进行预测, 克服了传统的理化鉴别法的缺陷, 具有快速无损的特点。 该方法能对铁皮石斛的品质进行区分, 并加快药食同源植物市场铁皮石斛产业化, 构建自主品牌并增加其影响力, 同时此项技术也可应用于消费者和市场监管部门。
, ZHANG Cai-hong, ZHU Cheng
Dendrobium officinale has high commercial value and nutritional value. In this study, 130 samples were taken as research samples from Wenshan in Yunnan, Jinxiu in Guangxi, Huoshan in Anhui and Taizhou in Zhejiang. The Raman spectrawere obtained by a portable Raman spectrometer under a 785 nm laser. Then, the total flavonoid content of Dendrobium officinale was determined by NaNO2-Al (NO3)3-NaOH colorimetry. With each normalized Raman spectral data as input, different preprocessing methods included SG, SNV and MSC are used to preprocess the spectral data. Partial least squares (PLS), support vector machine (SVM) and convolution neural network short and long-term memory neural network (CNN-LSTM) models are used as a comparison, and competitive adaptive reweighting sampling (CARS) is used as wavelength selection method to compare different machine learning models. In addition, the following prediction quality indicators were used: correction set and correlation coefficient of the test set ( Rc, Rp), root mean square error of correction set and root mean square error of prediction set (RMSEC, RMSEP) to evaluate the performance of the prediction model of total flavone content in Dendrobium officinale. The results showed that the prediction accuracy of the CNN-LSTM method was the highest, with Rc and Rp of 0.983 and 0.964, RMSEC and RMSEP of 0.032 and 0.047 mg·g-1, respectively. The SNV-CNN-LSTM deep learning model based on Raman spectroscopy is accurate, reliable, and robust, superior to traditional machine learning models (PLS, SVM). In this study, Raman spectroscopy combined with the CNN-LSTM model was used to predict the content of total flavonoids in Dendrobium officinale with the characteristics of fast and non-destructive, which overcame the shortcomings of traditional physical and chemical identification methods. This method can distinguish the quality of Dendrobium officinale, accelerate the industrialization of Dendrobium officinale in the market of medicinal and edible homologous plants, build its brand and increase its influence. At the same time, this technology can also be applied to consumers and market supervision departments, with broad prospects.
铁皮石斛(Dendrobium officinale)属于兰科石斛属, 《中国药典》2020版单独列出其干燥茎为珍稀名贵中药材。 铁皮石斛的主要活性成分包括多糖、 黄酮、 生物碱等, 其具有增强免疫力、 抗肿瘤、 降低血糖等功效[1]。 铁皮石斛因地理条件的不同会导致其品质差异, 而活性成分含量决定了铁皮石斛质量。 由于不同质量的铁皮石斛价格差异巨大, 在经济利益的驱使下, 存在部分不法商贩以次充好、 虚标来源等现象。 传统方法例如紫外分光光度法、 高效液相色谱法等可以准确测量铁皮石斛的质量属性[2, 3], 然而以上技术难以大规模检测单个样品的活性成分, 在单一样品水平上进行快速、 准确、 无损的品质属性测定, 可以为铁皮石斛的品质评价提供指导。
拉曼光谱检测技术(Raman)是一种分子振动光谱技术, 能够提供化学和生物分子结构的指纹信息, 成为药食同源植物有效成分识别重要的分析工具[4]。 Li等[5]利用薄层色谱结合表面增强拉曼光谱法(TLC-SERS), 同时对14种柑橘类黄酮进行分离和检测, 回收率较高(91.5%~121.7%), 相对标准差低于20.8%, 该方法快速灵敏准确。 Govindamm等[6]利用拉曼光谱对于黄酮类化合物桔皮素进行检测, 在1 609 cm-1处检测到羰基伸缩振动; Pompeu等[7]对酚酸和黄烷醇类黄酮化合物进行分析, 发现区分儿茶素最明显的拉曼谱带在1 700~1 600 cm-1, 归因于C=C拉伸振动。 对于铁皮石斛总黄酮含量, 利用红外光谱结合PLS模型成功对其进行了检测, Rc和Rp分别为0.979 0、 0.882 4, RMSEC和RMSEP分别为2.438 2和4.169 9。
近年来, 由于深度学习的特征学习能力, 拉曼光谱已经发展成为一种寻求提高分类和回归问题性能的替代方法[8, 9]。 Zhang等[10]使用近红外高光谱成像技术(NIR-HSI), 采用CNN提取特征, PLS进行建模分析的方法对黑果枸杞的总酚、 总黄酮和总花青素含量进行了预测, 校正集决定系数(
利用拉曼光谱结合CNN-LSTM深度学习模型快速检测了铁皮石斛总黄酮含量, 并比较了传统的机器学习模型(PLS、 SVM模型)在铁皮石斛总黄酮含量检测方面的能力, 为铁皮石斛质量管理研究提供稳定可靠的方法。 本研究所提出的评价模式可为不同的资源评价系统提供技术支持, 为同类药食同源植物的质量评价提供实际参考, 对药食同源植物产地溯源提供了技术支撑。
根据资源调查和文献综述, 为了扩大分布特性, 购买了四个代表性产地的铁皮石斛样品共130组, 分别来自云南文山(一年生, 文山市皓霖商贸有限公司)32组, 广西金秀(三年生, 金秀县瑶山绿农生态农业开发有限公司)32组, 安徽霍山(五年生, 霍山牙尖土特产有限公司)32组, 浙江台州(三年生, 浙江凤凰源生物科技股份有限公司)34组, 采集到的干燥茎样品放在带有标签的保存袋中进行下一步分析。
QE-Pro拉曼光谱仪(Ocean opticis公司, 光谱范围: 2 870~200 cm-1, 分辨率: 0.42 nm)。 RPB4拉曼探头(如海光电)。 785 nm激光器(如海光电)。 UV6100紫外-可见分光光度计(上海元析仪器)。 SMART-N纯水仪(Heal Force公司)。
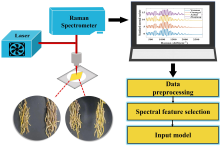
拉曼光谱采集系统: 激光器、 QE-Pro拉曼光谱仪、 光纤、 计算机系统等, 铁皮石斛光谱采集过程与数据前处理过程如图1所示。 实验参数设置: 积分时间2 000 ms(在不损伤样品的情况下信噪比最高), 平均次数2次, 激光功率为320 mW, 采样间距为1 mm。 采集前对铁皮石斛干条表面进行擦拭处理, 避免其他无关痕量物质干扰。 将每份铁皮石斛样品采集五次拉曼光谱, 取均值作为样品最终拉曼谱。 整个采集光谱过程均在暗室内操作以减少荧光干扰。 每组数据光谱范围为2 870~200 cm-1, 后续将光谱数据随机排列后输入建立的预测模型中, 80%的数据作为校正集, 20%的样品作为测试集。
 | 图1 铁皮石斛光谱采集与数据前处理流程示意Fig.1 The schematic diagram of spectrum acquisition and data preprocessing of Dendrobium officinale |
铁皮石斛总黄酮含量的测定参考2020年版《中国药典》总黄酮含量检测方法[11]。 对照品溶液的制备: 称取对照品芦丁20 mg溶解于80%乙醇溶液中, 转移至100 mL容量瓶定容。 取0、 0.4、 0.8、 1.2、 1.6、 2.0、 2.4 mL对照品溶液分别置于10 mL玻璃试管中, 分别加蒸馏水至2.4 mL, 加入5%NaNO2溶液0.4 mL, 混匀放置6 min; 加入10%Al(NO3)3溶液0.4 mL, 混匀放置6 min; 加入4%NaOH溶液4 mL, 混匀放置15 min; 于吸收波长510 nm处测定吸光度, 横坐标为芦丁含量、 纵坐标为吸光度得出回归曲线方程。 准确称取2.0 g过三号筛铁皮石斛粉末, 滤纸封住后置于索氏提取器, 加入120 mL 80%乙醇加热回流1.5 h。 适量活性碳脱色1 h, 过滤, 光照15 min, 取处理好的样品溶液12 mL用80%乙醇定容至25 mL。 精密量取供试品溶液2.4 mL, 自“ 加入5%NaNO2溶液0.4 mL” 起测定吸光度, 利用回归曲线方程计算出溶液中总黄酮含量。
合理的数据预处理能有效的减少干扰并最大限度地挖掘出特征光谱信息。 采用的光谱数据预处理方法有基线校正、 归一化、 Savitzky-Golay卷积平滑(SG平滑)、 标准正态变量变换(SNV)、 多元散射校正(MSC)[12]。 以上方法可以减小仪器噪声、 光散射等影响。 特征波长选择从原始光谱中选择一些对研究对象贡献最大的波长。 选择特征波长降低变量的数量, 减少建模复杂度, 有助于获得更准确的性能。 本研究采用CARS来选择最优波长[13]。
预测模型的选取对于预测样品中的活性成分至关重要。 对比PLS、 SVM和CNN-LSTM模型来预测铁皮石斛中总黄酮含量。 传统的机器学习算法不具有自动提取特征并调节自身参数的能力, 而对于深度学习模型, CNN模型采用权值共享与局部连接的方式, 可直接自动提取光谱数据的局部特征[14]。 LSTM将提取出来的特征进行训练, 不断调整自身参数达到有效预测铁皮石斛总黄酮含量的目的[15]。
针对CNN-LSTM模型, 采用拉曼光谱数据数据作为预测模型的输入, 对应的铁皮石斛总黄酮含量数据作为输出。 通过反复的迭代实验发现, 只通过提高CNN-LSTM网络层数不能提高预测的准确度, 在提高网络的层数之后, 训练的参数在不断增加, 而需要预测的总黄酮含量信息简单, 在经过多次迭代之后, 网络的预测模型过度提取校正集特征, 从而造成了过拟合现象, 在训练期间, 采用Dropout方法来减少模型的过拟合现象[16]。 Dropout方法主要通过将CNN-LSTM网络中的神经元以P的概率随机丢弃, 从而使这些神经元不参与CNN-LSTM网络的训练过程, 使得模型能够合理提取校正集信息, 从而具有较强的抗过拟合性能。
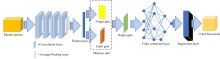
整个CNN-LSTM网络训练模型结构如图2所示。 输入数据通过CNN-LSTM网络的过程: 光谱数据在经过合适的预处理后, 经过卷积层和池化层的特征筛选和降维处理后进入LSTM网络, LSTM网络中的遗忘门、 输入门和输出门通过对CNN处理过的数据进行非线性变换等操作后不断迭代, 从而寻找合适的参数, 使得LSTM网络能够从CNN筛选过的特征数据中学习到铁皮石斛的产地信息, 最后将训练好的CNN-LSTM网络数据通过回归层输出预测值。 CNN-LSTM网络需要通过对校正集的铁皮石斛光谱数据和总黄酮含量信息进行训练确定模型的最优参数, 本文采用Adam算法进行参数优化。 将一维的拉曼光谱数据输入到CNN-LSTM网络中, 所构造的CNN-LSTM网络模型以及相关的参数为:
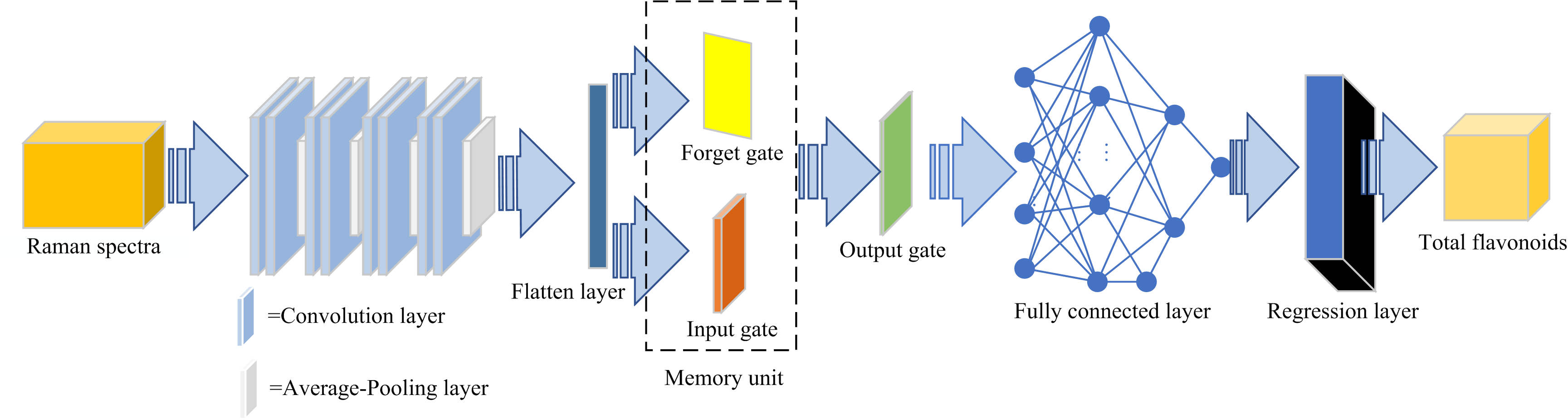 | 图2 CNN-LSTM结构Fig.2 The architecture diagram of CNN-LSTM |
(1)卷积神经网络层: 卷积层包括卷积核和池化核, 卷积核大小为1, 数量32, 大小设定维度向量, 对应拉曼光谱数据, 激活函数为ReLu。
(2)长短期记忆神经网络层: LSTM网络设置2层, 隐藏单元数目设置为128和32, 激活函数设置为为ReLu。
(3)Dropout层: 以25%的概率对神经元进行随机化清零。
(4)全连接层: 神经元个数设置为1, 对应总黄酮含量数据。
(5)回归输出层: 该层为输出层, 用于计算回归任务的均方根误差损失。
(6)训练参数: 最大迭代次数400, 批尺寸20, 学习率0.005。
光谱数据预处理和提取以及预测模型的建立均在MATLAB R2020b上进行。 通过校正集、 测试集相关系数(Rc、 Rp); 校正集、 测试集均方根误差(RMSEC、 RMSEP)评价模型的预测性能。 以Rc和Rp最高、 RMSEC和RMSEP最低的模型作为最优模型。
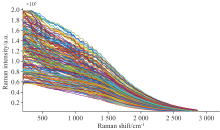
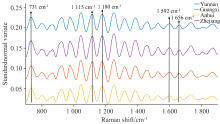
图3为样品的拉曼原始光谱。 由于光谱的头部和末端均存在噪声, 故只选取了2 806~900 cm-1范围内的光谱进行建模。 将四个产地拉曼光谱进行背景扣除后, 再进行标准正态变量变换, 如图4所示, 其中731、 1 115、 1 180、 1 592和1 656 cm-1处峰的形成是由于黄酮类物质的C—C—O等基团振动引起[17, 18, 19]。 但是铁皮石斛成分复杂, 拉曼光谱反映的是其多种生物活性物质叠加的整体效应。 由于化合物分子间的相互作用, 铁皮石斛拉曼特征峰和某个单独的活性成分拉曼峰相比会有所偏移。 所以这些波长不能简单地用于检测特定成分的含量, 后续采用数据分析方法探讨光谱与总黄酮含量的关系。
 | 图3 铁皮石斛原始拉曼光谱Fig.3 The raw spectra profile of Dendrobium officinale |
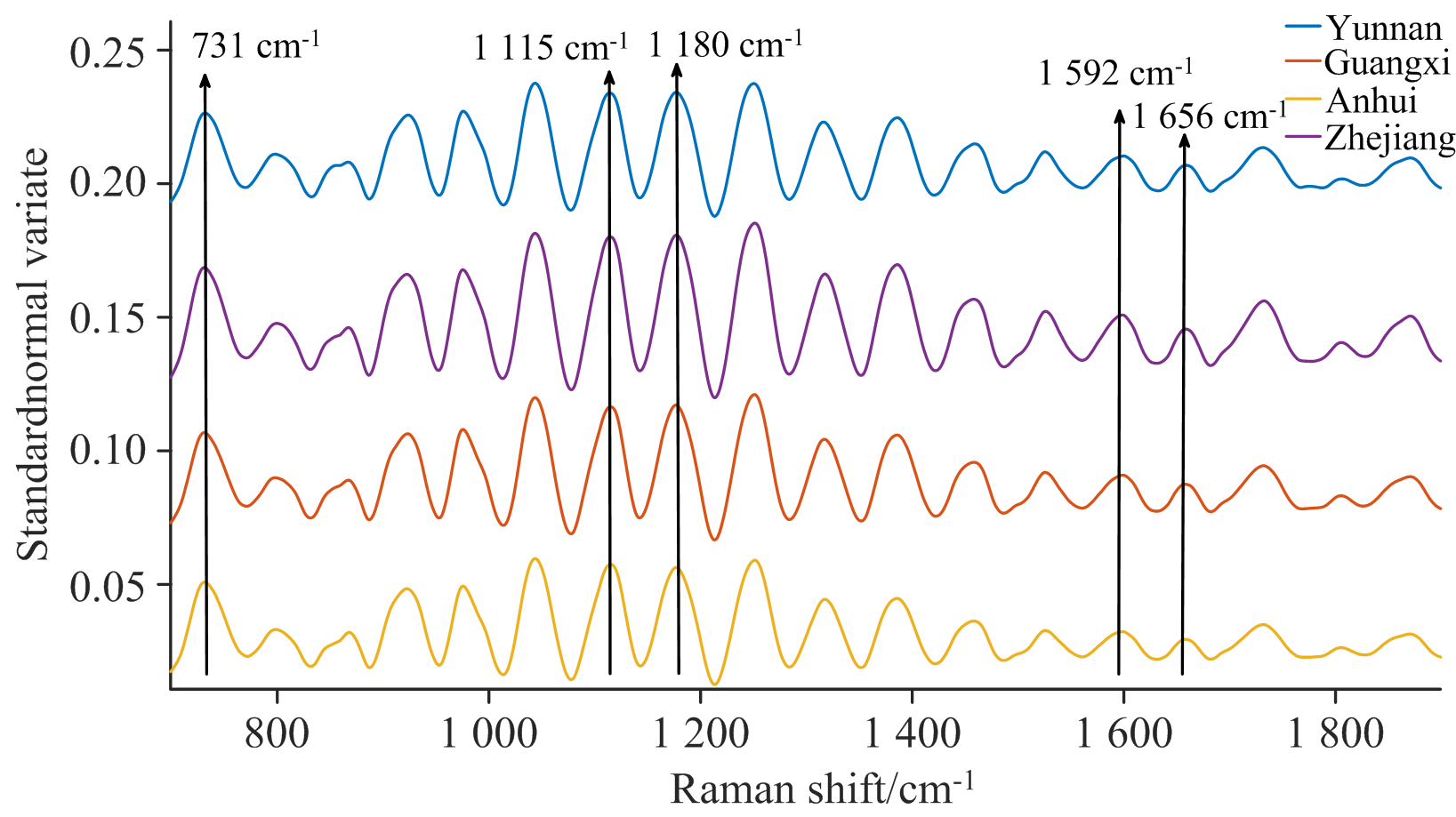 | 图4 光谱特征Fig.4 Spectral characteristics |
芦丁对照品吸光度与含量回归方程为y=0.537x+0.016, R2=0.999, 表示芦丁在0.08~0.48 mg含量范围内与吸光度线性关系良好。 测定四个产地的铁皮石斛总黄酮含量如表1所示, 校正集铁皮石斛总黄酮含量覆盖了预测集的范围, 使模型更加稳定。
| 表1 铁皮石斛总黄酮含量 Table 1 Total flavonoid content of Dendrobium officinale |
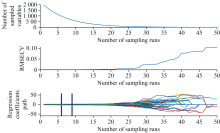
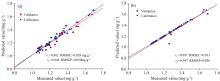
建立了铁皮石斛中总类黄酮预测校准模型的传统方法(PLS和SVM模型)。 将铁皮石斛归一化光谱数据作为模型输入, 比较不同的预处理方法, 使用CARS筛选波长或全波长, 铁皮石斛总黄酮含量数据作为模型预测输出。 通过使用全光谱和波长筛选, 两个模型的输入变量数量有所不同, 预测结果如表2所示。 从图5可以看出, 采样运行次数为9时, 交叉验证均方根误差(RMSECV)最低, 此时筛选的变量数量为639个, 经MSC预处理, 设置主因子数为6后, PLS模型具有较高的预测准确度, Rc、 Rp分别为0.982和0.948, RMSEC、 RMSEP分别为0.028和0.050 mg· g-1, 预测结果图如图7(a)所示。 而对于SVM模型, 基于网格搜索法对参数C和γ 进行筛选, 从图6可以看出, 最佳C和γ 分别为32和0.041, 此时Rc、 Rp分别为0.997和0.943, RMSEC、 RMSEP分别为0.013和0.056 mg· g-1, 准确率较高。 SVM模型预测结果如图7 (b)所示。
| 表2 PLS和SVM模型预测总黄酮含量结果 Table 2 The prediction results of total flavonoids by PLS and SVM models |
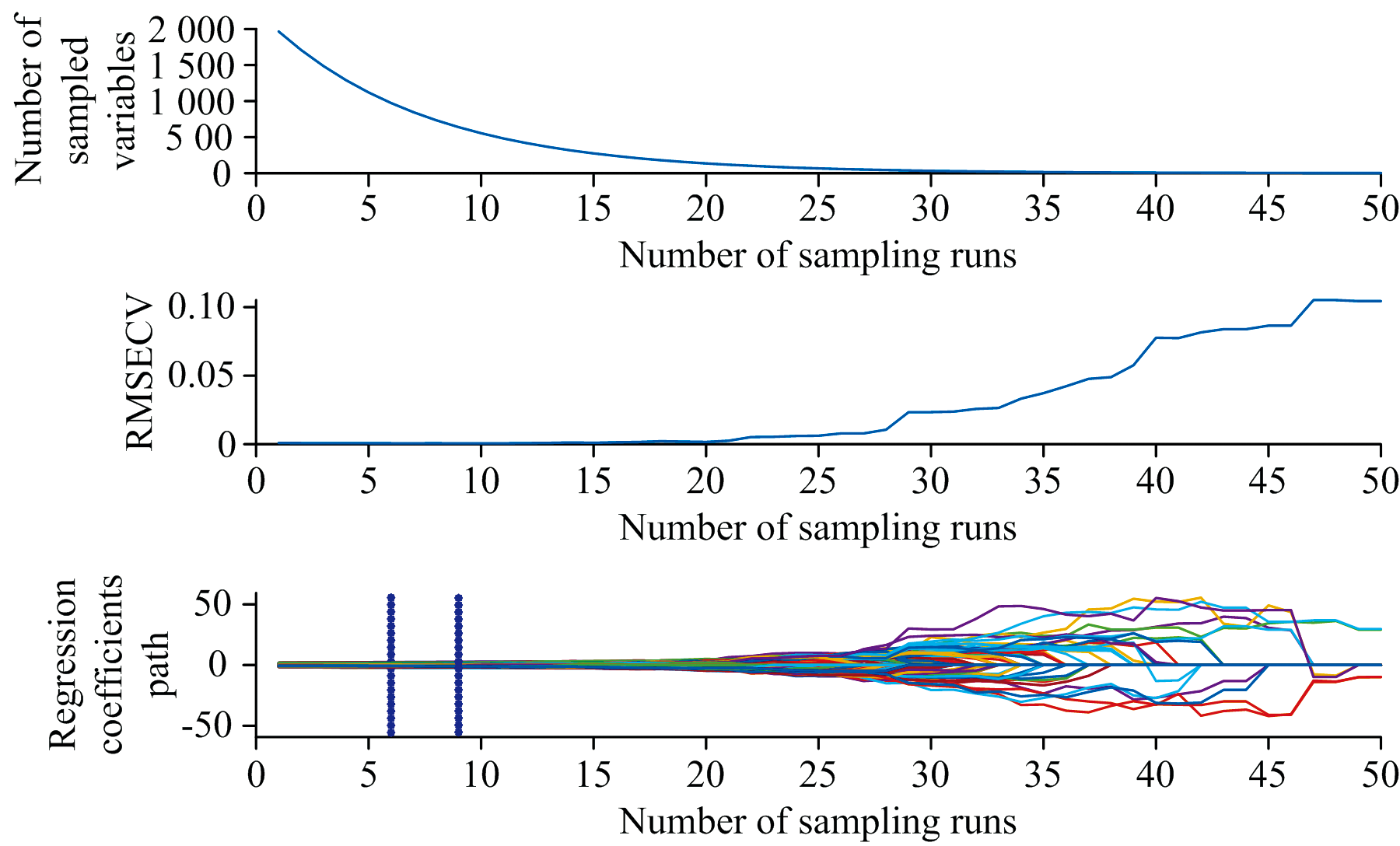 | 图5 CARS特征波长筛选过程Fig.5 The sifting process of characteristic wavelength by CARS |
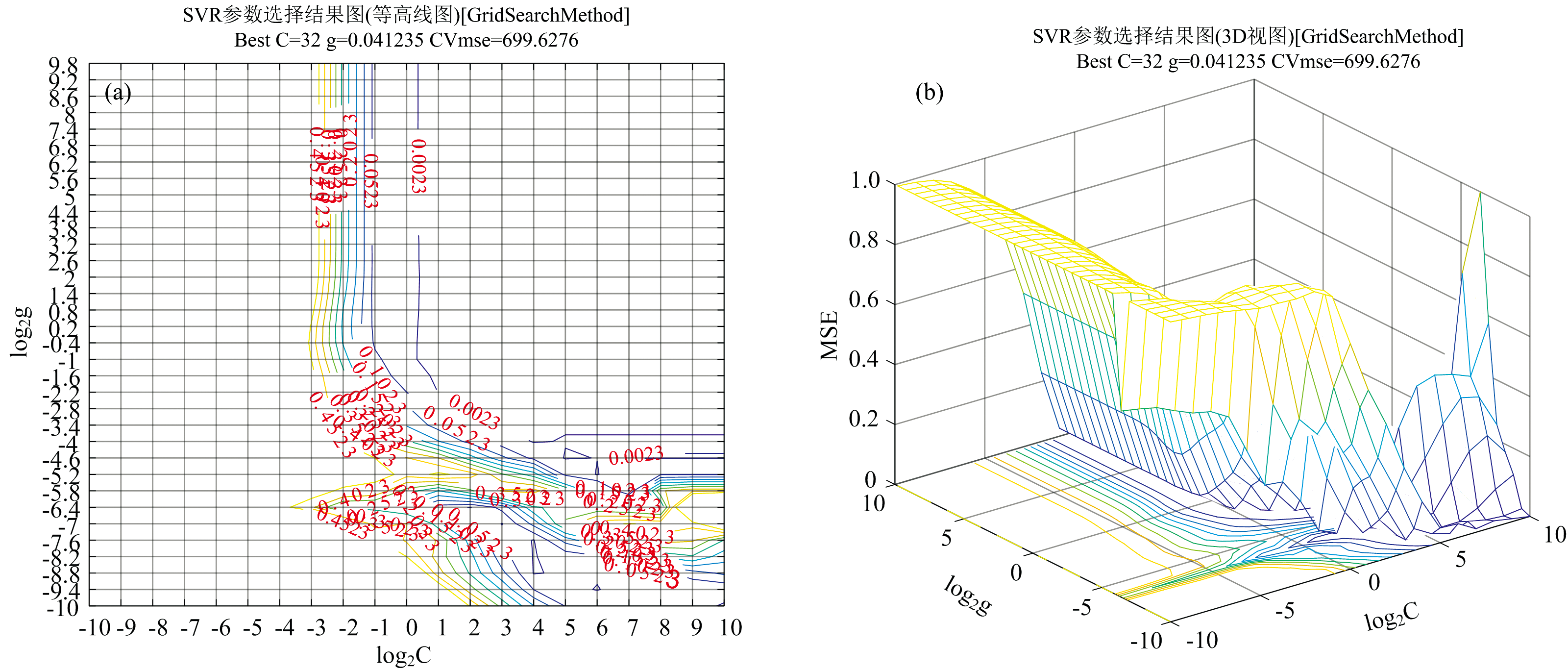 | 图6 网格搜索法寻优过程 (a): SVR参数选择结果(等高线); (b): SVR参数选择结果(3D视图)Fig.6 The optimization process of grid search method (a): Parameter selection results of SVR (contour map); (b): Parameter selection results of SVR (3D view) |
 | 图7 模型预测结果 (a): PLS模型; (b): SVM模型Fig.7 Themodel prediction results (a): PLS model; (b): SVM model |
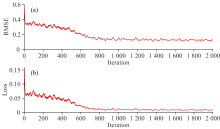
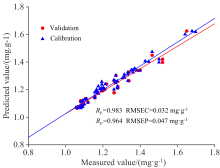
使用CNN-LSTM作为建模方法, 铁皮石斛光谱数据处理方式同2.3节。 训练过程过程如图8(a, b)所示。 表3显示了CNN-LSTM的预测精度。 在使用SNV预处理后选择全光谱, CNN-LSTM模型的Rc、 Rp分别为0.983和0.964, RMSEC、 RMSEP分别为0.032和0.047 mg· g-1, 该模型预测铁皮石斛总黄酮含量精度最高, CNN-LSTM对铁皮石斛总黄酮含量预测效果如图9所示。 研究发现CNN-LSTM模型只需要通过CNN对特征进行提取并结合LSTM对冗余长序列数据进行有效去除并调节自身参数的能力, 便可以有效地对铁皮石斛总黄酮含量进行预测。
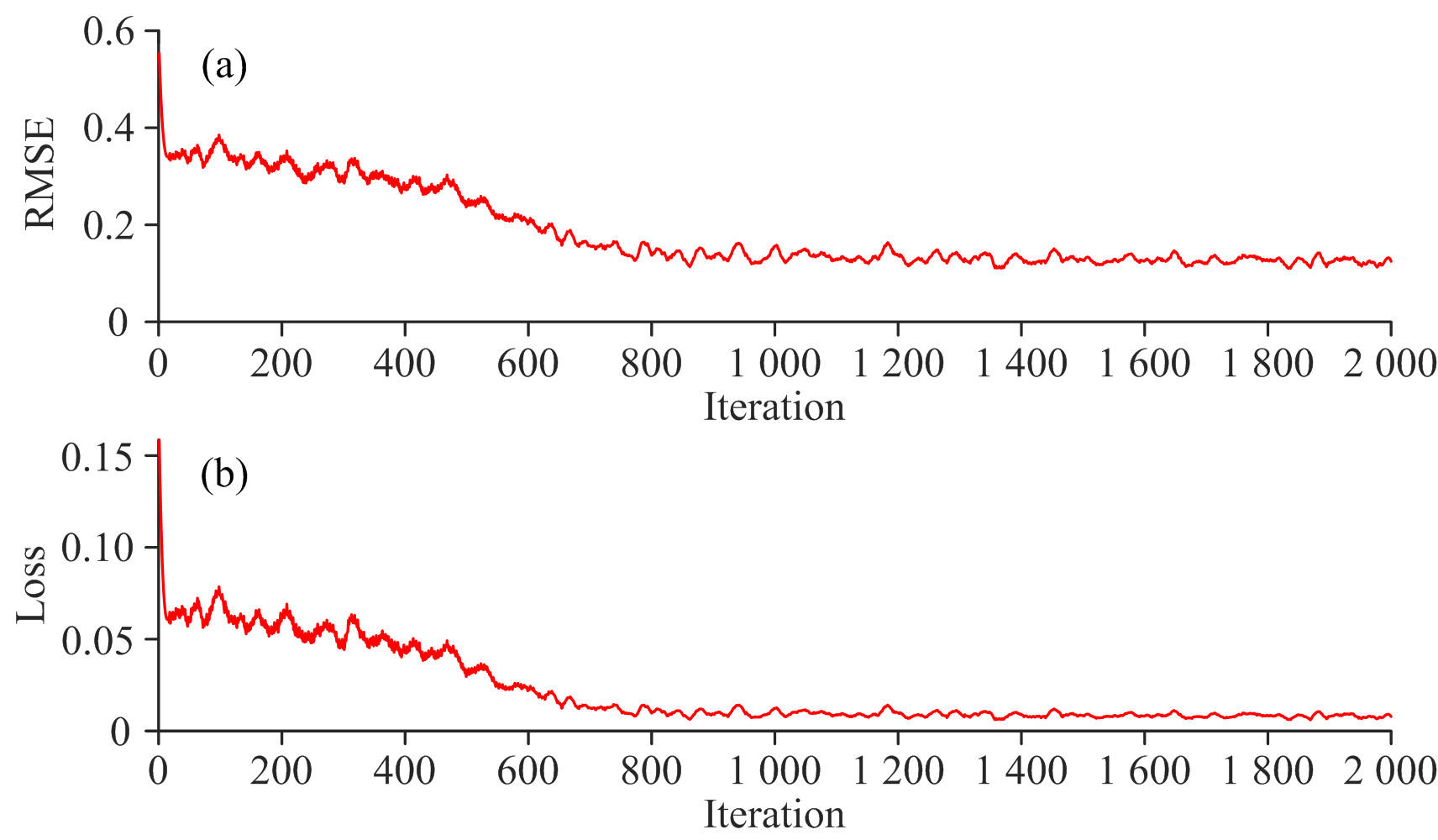 | 图8 CNN-LSTM模型训练过程 (a): 训练过程中均方根误差变化趋势; (b): 训练过程中损失函数变化趋势Fig.8 The training process of CNN-LSTM model (a): Variation trend of root mean square error in the training process; (b) Variation trend of the loss function in the training process |
| 表3 CNN-LSTM模型预测总黄酮含量结果 Table 3 The prediction results of total flavonoids by CNN-LSTM model |
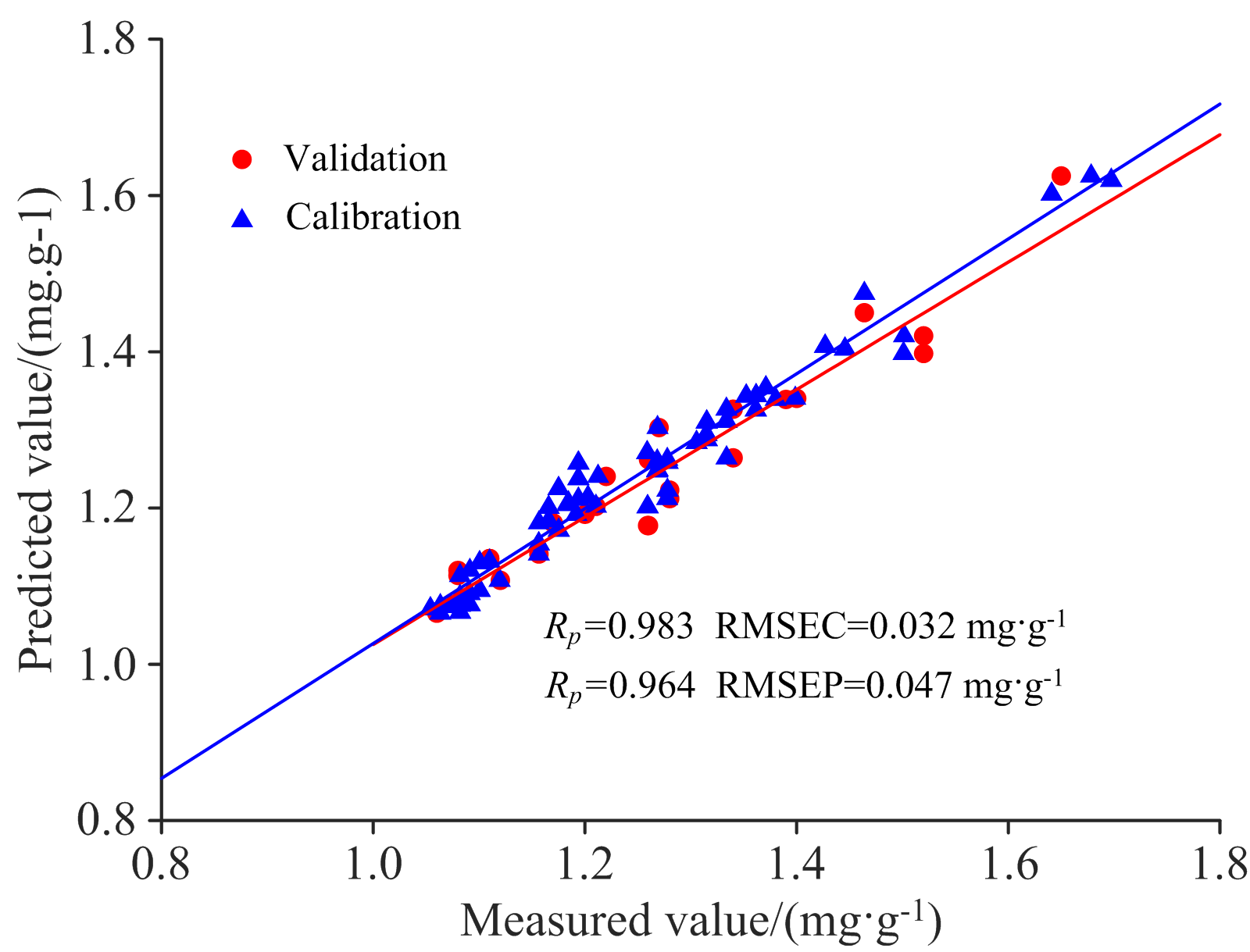 | 图9 CNN-LSTM模型预测结果Fig.9 The prediction results of CNN-LSTM model |
比较传统机器学习模型(PLS和SVM)和CNN-LSTM深度学习模型对铁皮石斛总黄酮含量预测性能结果, CNN-LSTM深度学习模型预测准确性有了提高。 与PLS模型相比, CNN-LSTM模型的Rc、 Rp分别增加了0.001、 0.016, 而且PLS需要采用CARS算法对拉曼光谱数据波长进行筛选才能达到最优效果, 面对不同的数据, 主因子数也需要不断地调整; 而与SVM模型相比, CNN-LSTM模型的Rp增加了0.021, Rc反而降低0.014, 这主要是因为SVM模型训练校正集数据时由于通过网格搜索法调参, 存在搜索到局部最优解的情况, 可能产生过拟合, 因此在面对不同的数据的情况下, 寻优算法存在着一定缺陷; 而对于CNN-LSTM模型, 采用Dropout方法便可以减少自身训练时的过拟合情况, 且CNN-LSTM深度学习模型融合了CNN(自动提取光谱数据局部特征属性)和LSTM(负责推导光谱特征数据携带的化学物质含量属性)的优点, 对铁皮石斛总黄酮含量预测具有一定的优势, 而且随着数据量的增加, CNN-LSTM模型能自动学习新特征进行性能的提升。 另外SVM和CNN-LSTM模型均为全波段光谱数据建模结果最优, 主要因为CARS是一种基于PLS模型回归系数的波长选择方法, 在使用以上两个模型进行训练时, 存在着非线性光谱信息丢失的可能。
将拉曼光谱与CNN-LSTM模型相结合, 作为评估铁皮石斛质量的工具之一, 具有巨大的应用潜力。 研究了SG、 SNV、 MSC等不同预处理方法以及特征波长筛选方法CARS对不同模型预测能力的影响, 结果表明SNV与深度学习算法(CNN-LSTM)相结合, 对铁皮石斛总黄酮含量预测效果最好, 相关系数均大于0.95, 均方根误差均小于0.05 mg· g-1, 对比传统的机器学习方法, CNN-LSTM深度学习模型适合大数据时代, 传统的模型方法无法高效处理海量数据, 而且对于新的数据无法进行有效学习, 需要人工对参数和特征进行调整, 本研究将为智能化检测提供一种新的思路。 本研究不仅为消费者提供了一种简单、 快速的药食同源植物质量检测方法, 并且为相关检测机构的质量安全管理提供了技术支持。 在未来的研究中将扩大代表性数据集以及活性成分指标, 多层次多角度对铁皮石斛进行评价, 以提供更加可靠和准确的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|