






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
苹果霉心病不同光谱检测方式对比研究
[张仲雄1, 2, 3  , 刘昊灵
, 刘昊灵1, 3 , 魏子朝1, 2 , 浦育歌1, 3 , 张佐经1, 2, 3 , 赵娟1, 2, 3, * , 胡瑾1, 2, 3, * ]
, 刘昊灵, 胡瑾]
|
|


作者简介: 张仲雄, 1994年生, 西北农林科技大学机械与电子工程学院博士研究生 e-mail: zzx9519@nwsuaf.edu.cn
苹果霉心病是一种对消费者健康产生威胁的水果内部病害, 在苹果进入消费市场前实现霉心病的快速无损检测有助于提升苹果品质和保障消费者安全。 近年来, 可见/近红外光谱技术凭借其快速无损、 操作简单、 成本低和批量在线检测等优势, 被广泛用于水果品质无损检测研究中, 而根据实际检测需求进行光谱检测方式选择是开展水果光谱无损检测的关键步骤, 为探寻苹果霉心病光谱无损检测中最佳的检测方式, 首先基于实验室自主搭建的苹果漫反射、 漫透射和透射光谱采集系统分别获取了243个苹果样本的三种光谱数据, 然后采用一阶导数(FD)、 归一化(NOR)、 S-G平滑(S-G)、 多元散射校正(MSC)和标准正态变量变化(SNV)五种方法对光谱数据进行预处理, 其次将局部线性嵌入(LLE)、 多尺度分析(MDS)、 分布邻域嵌入(SNE)和t分布邻域嵌入(t-SNE)四种流形学习方法用于光谱数据降维, 并与传统的主成分分析(PCA)降维方法比较, 最后基于降维后数据建立了最小二乘支持向量机(LS-SVM)算法的苹果霉心病分类模型。 结果表明: 在三种不同的光谱检测方式中, 透射检测方式优于漫透射检测方式, 漫透射检测优于漫反射检测方式。 在五种不同的光谱降维方法中, 基于SNE的降维方法在三种不同的光谱数据中都优于其他降维方法, 最终以透射检测方式结合SNE降维方法构建了最优的苹果霉心病判别模型, 其校正集和测试集的准确率分别为99.52%和97.14%。 该研究对苹果霉心病光谱无损检测研究中的实验平台搭建和检测装备研发提供了指导。
, LIU Hao-ling, HU Jin
Moldy apple core is a kind of internal fruit disease that threatens consumers' health. Rapid, nondestructive detection of moldy apple core is helpful to improve the quality of the apple and ensure the safety of consumers before entering the consumer market. In recent years, Vis/NIR spectroscopy has been widely used in the nondestructive detection of fruit quality by its advantages of rapid, nondestructive, simple operation, low cost and batch online detection. The selection of spectral detection mode according to the actual detection requirement is an important prerequisite for developing fruit spectral nondestructive detection. Three kinds of spectral data from 243 samples were obtained based on diffuse reflection, diffuse transmission and transmission spectrum acquisition systems built by the laboratory. Five spectral pretreatment methods, including S-G smoothing (S-G), multiplicative scatter correction (MSC), standard normal variation (SNV), first derivative (FD), and normalize (NOR), were used for spectral data preprocessing. Four manifold learning algorithms, including locally linear embedding (LLE), multidimensional scaling (MDS), distributed neighbor embedding (SNE) and t-distributed neighbor embedding (t-SNE), were systematically used for spectral data dimensionality reduction. These were compared with the traditional principal component analysis (PCA) dimensionality reduction method. Finally, the least squares-support vector machine (LS-SVM) classification model was established based on the dimensionality-reduced data. The results show that the transmission detection mode is better than the diffuse transmission detection mode, and the diffuse transmission detection mode is better than the diffuse reflection detection mode in three different detection modes. The distributed neighborhood embedding algorithm is better than other dimension reduction algorithms. The model constructed by transmission detection mode combined with the distributed neighborhood embedding dimension reduction algorithm performs best. The accuracy of the calibration set and test set is 99.52% and 97.14%, respectively. The research provide a reference for establishing a spectral nondestructive detection platform and developing detection equipment for moldy apple core.
苹果口感酸甜营养价值高, 具有预防疾病和提高人体免疫力等多种益处[1], 成为消费者最受青睐的水果之一, 但苹果在生长和储藏过程中易发生病害, 其中霉心病是一种常见的苹果内部果实病害, 会导致苹果产前生长期落果和产后储藏期烂果, 给苹果种植者和管理者带来巨大的经济损失。 研究发现霉心病苹果中含有对人体有害的多种毒素物质[2], 会对消费者健康产生巨大威胁。 由于霉心病苹果通过外观难以识别, 存在一定的食品安全隐患, 迫切需要一种苹果内部病害无损检测技术以满足市场检测需求, 从而保障消费者吃到安全放心的苹果。
目前已有多种检测技术应用于苹果霉心病无损检测, 其中可见/近红外光谱技术相比于X射线[3]、 电子鼻[4]、 振动声学[5]等其他无损检测技术具有操作简单、 高效快速、 绿色环保和成本低等优势, 因此近红外光谱技术是诸多苹果霉心病无损检测中理论研究最多和实际应用最广泛的技术[6]。 检测方式的选择是开展光谱检测的关键, 在苹果霉心病光谱无损检测方面, 目前主要有漫反射、 漫透射和透射三种检测方式, 由于不同的研究中基于不同的检测方式与不同的实验样本所得到检测结果各不相同, 仅从检测结果直接比较, 不具有可比性, 而针对同一批样本, 不同检测方式的检测结果究竟如何, 目前还未有相关研究报道。
原始光谱数据往往是高维冗余的变量, 如果直接用于建模不仅会导致模型复杂过高还会影响模型的准确性和稳定性, 因此在光谱数据建模前需要采取必要的降维处理, 在去除冗余变量同时保证模型精度。 近年来, 随着机器学习的快速发展, 流形学习在数据降维方面受到高度重视, 越来越多的研究将非线性流行学习方法用于解决光谱数据降维问题, 其中Lorente等[7]采用三种不同的流行方法减少可见/近红外反射光谱维度, 并基于降维后的光谱数据检测由真菌引起的柑橘类水果早期腐烂问题。 Wang等[8]将近红外光谱与流形学习方法结合, 提高了汽油中辛烷值预测的准确性。 郭俊先等[9]采用近红外透射光谱与化学计量学方法结合非线性流形学习数据降维方法, 实现了新疆冰糖心红富士水心病的鉴别。 上述研究表明流行学习方法在光谱数据降维方面具有明显的优势。
本研究基于可见/近红外光谱技术, 搭建了苹果漫反射、 漫透射和透射光谱数据采集平台, 获取同一批苹果样本的漫反射、 漫透射和透射光谱, 利用流形学习算法对预处理后的光谱数据进行降维处理, 建立了基于LS-SVM算法的苹果霉心病分类模型, 比较了不同的流行学习降维方法对模型的影响, 分析了不同光谱检测方式的优势与不足, 最后选择了苹果霉心病光谱无损检测中最佳的检测方式与数据降维方法。
富士苹果样本于2020年10月从陕西省扶风县某果园采摘, 挑选大小均匀和表面无缺陷的243个苹果, 装箱后运至西北农林科技大学农业农村部农业物联网重点实验室。 将苹果表面擦干净后统一编号, 未避免环境温度对检测结果的影响, 在实验室条件(温度: 22~25 ℃)下放置12 h后开始实验。
实验室自主搭建的苹果漫反射、 漫透射和透射光谱采集系统如图1(a, b, c)所示。 光谱仪都采用Maya2000 Pro(美国, Ocean Optics公司), 光谱波长范围200~1 100 nm。 光谱仪一端与不同检测方式的光纤相连, 另一端通过数据线与计算机连接, 在SpectraSuite软件中设定采集参数和保存光谱数据。
 | 图1 三种不同的光谱采集系统示意图 (a): 漫反射; (b): 漫透射; (c): 透射Fig.1 Schematic of spectral acquisition system for three different detection modes (a): Diffuse reflection; (b): Diffuse transmission; (c): Transmission |
苹果漫反射光谱采集系统如图1(a)所示, 漫反射光纤采用二分叉光纤, 一端固定在苹果的果托下方, 另外两端分别连接光谱仪和漫反射光源。 漫反射光源使用HL-2000型卤钨灯(美国, Ocean Optics公司), 光源波长范围为360~2 400 nm, 在光谱采集软件中设置积分时间为10 ms, 平均扫描次数和滑动平均宽度都为5, 获取相应的光谱数据, 然后利用式(1)计算得到每个苹果样本的反射率R。
式(1)中, R为反射率, Rr为原始漫反射光谱, Rd为漫反射暗参考光谱, Rw为漫反射亮参考光谱。
苹果漫透射光谱采集系统如图1(b)所示, 采用两个MR16型卤素灯(德国, OSRAM公司), 单个功率50 W光源波长范围为250~3 000 nm, 位于苹果上方且安装方向与水平面成45° 。 图1(c)为苹果透射光谱采集系统, 采用一个MR16型卤素灯, 且安装在苹果的正上方。 透射和漫透射光纤一端连接苹果果托下方的准直镜, 另一端连接光谱仪, 在光谱采集软件中设置积分时间为100 ms, 平均扫描次数和滑动平均宽度都为5。
为避免外界杂散光对检测结果的影响, 所有的光谱数据采集过程均在暗室中进行。 为保证采集系统稳定而获得可靠的光谱数据, 采集数据前对系统预热30 min, 在每个苹果赤道方向均匀选择三个光谱采集点, 分别测量每个样本的漫反射、 漫透射和透射光谱数据, 将三个点的平均值作为该样本的光谱数据。
在获取每个苹果样本的三种光谱数据后, 用水果刀沿苹果茎轴处切开, 根据果核与果肉部分是否有病害物质, 将样本标签分为健康苹果和霉心病苹果。 实验中健康苹果与不同类型的霉心病苹果如图2(a-d)所示, 可以看出健康苹果果核与果肉正常, 而霉心病苹果内部果核有褐变、 发霉、 腐烂等症状, 发病严重的样本从果核逐渐腐烂至果肉部分, 但外观却与健康苹果并无明显差异, 只有将苹果切开后观察内部情况才能判断是否为健康苹果或霉心病苹果。 为了方便后续的建模分析, 采用数字标签“ 1” 表示健康苹果, 数字标签“ -1” 表示霉心病苹果。
 | 图2 健康苹果与不同类型的霉心病苹果病害表型 (a): 健康苹果; (b): 褐变型; (c): 霉心型; (d): 腐烂型Fig.2 Disease phenotypes of healthy apple and different types of moldy apple core (a): Healthy apple; (b): Browning; (c): Moldy core; (d): Core rot |
在光谱数据获取过程中, 由于实验样本、 采集环境、 仪器老化和人为操作等因素影响, 导致采集的原始光谱中除了包含被测样本的有效信息外, 还包含噪声等其他干扰信息, 采用一阶导数(first derivative, FD)、 归一化(normalize, NOR)、 S-G平滑(savitzky-golay, S-G)、 多元散射校正(multiplicative scattev correction, MSC)和标准正态变量变化(standard normal variate, SNV)进行光谱数据预处理, 从而达到降低噪声、 提高信噪比和减少其他干扰因素影响的目的[10]。
原始的光谱数据存在健康苹果和霉心病苹果样本分布不均衡问题, 使模型性能倾向样本数量较多的健康苹果, 导致模型对霉心病苹果检测性能较低, 根据前期研究[11]采用SMOTE方法对原始不平衡光谱数据进行均衡化处理, 采用KS算法按3:1分为校正集与测试集, 样本集具体分布情况如表1所示。
| 表1 样本集分布 Table 1 Sample set distribution |
由于原始的光谱数据维度较高, 且不同波段的冗余数据降低了模型的预测精度和鲁棒性, 因此, 在构建光谱分析模型前需要进行数据降维处理, 进一步去除冗余信息、 降低模型复杂度、 简化模型结构和提高模型性能。 主成分分析(principal component analysis, PCA)是目前光谱分析中最常用的数据降维方法之一, 其降维原理是根据方差最大理论对原始光谱数据的多个变量进行线性组合, 得到新的综合变量代替原始的高维数据, 从而实现高维光谱数据降维[12]。 流行学习是将原始高维数据中恢复低维流形结构, 计算出相应的嵌入映射, 从而实现数据的降维处理。 局部线性嵌入(locally linear embedding, LLE)算法可以学习数据间的局部流行结构, 具有计算复杂度低的优势[13]。 多尺度分析(multidimensional scaling, MDS)算法根据数据集的相似程度, 计算各数据点在K维空间中的位置, 高维数据转换为低维数据后样本点的相对位置关系不变。 分布邻域嵌入(stochastic neighbor embedding, SNE)算法将数据间的欧式距离转化为条件概率在低维空间中表示高维数据间的相似性。 t分布邻域嵌入(t-distributed stochastic neighbor embedding, t-SNE)算法是对SNE算法的改进, 采用t-分布概率代替条件概率, 可以使数据在低维空间中均匀分布。
最小二乘支持向量机(least squares-support vector machine, LS-SVM)算法在处理光谱的定性和定量问题方面具有明显的优势, 因此文中将LS-SVM算法用于建立苹果霉心病判别模型。 LS-SVM算法对支持向量机(support vector machine, SVM)算法的进一步改进, 将不等式约束变为等式约束, 通过求解线性方程组来解决复杂的凸二次优化问题, 弥补了SVM算法在少量的训练样本中存在训练时间长、 训练结果随机等不足, 适合解决小样本和高维数据问题[14], 具体模型用式(2)表示。
式(2)中, K(x, xi)是核函数, xi是输入向量, ai是拉格朗日乘子, b是偏差。 常用的核函数有多项式函数、 Sigmoid函数和径向基函数等, 其中径向基函数可以处理光谱与检测对象之间的线性和非线性关系, 因此将径向基函数作为核函数, 具体如式(3)所示。
式(3)中, σ 2是径向基核函数的宽度。
采用准确率评价模型性能, 准确率表示模型正确识别的样本与总样本的比值, 该值越接近100%说明模型性能越好。
三种不同检测方式的健康苹果和霉心病苹果的平均光谱如图3所示。 漫反射光谱选取400~1 000 nm作为有效波长, 光谱曲线如图3(a)所示, 在490 nm之前健康苹果光谱反射率高于霉心病苹果, 在490~623 nm之间健康苹果光谱反射率低于霉心病苹果, 在623 nm之后健康苹果和霉心病苹果光谱反射率比较接近。 漫透射和透射光谱选取550~950 nm作为有效波长, 光谱曲线分别如图3(b)和(c)所示, 其中, 健康苹果的光强普遍高于霉心病苹果, 漫透射的光强高于透射光强。 两种光谱分别在波长636、 705和808 nm附近有明显的波峰, 在波长680和748 nm附近有明显的波谷, 其中705 nm附近波峰最高, 可能是由C-H键和O-H键的拉伸振动产生波峰[15], 在波长680 nm附近有明显的吸收峰, 是由于叶绿素的吸收所导致[6]。 三种不同的光谱检测方式中, 健康苹果和霉心病苹果光谱在不同波段处都存在明显的差异, 这为基于光谱技术的苹果霉心病无损检测提供了理论依据。
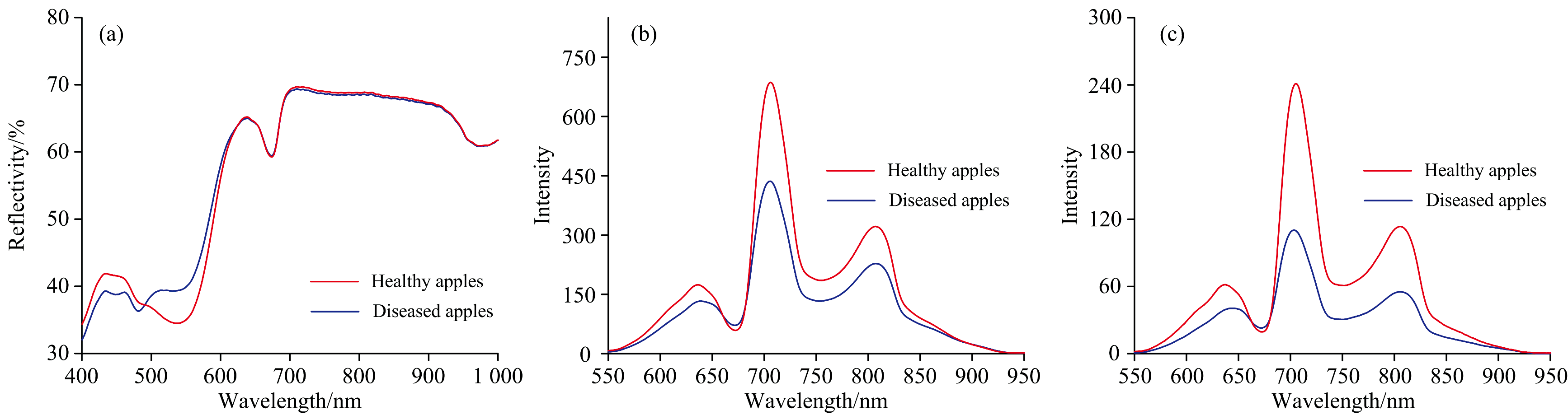 | 图3 三种不同检测方式的平均光谱 (a): 漫反射; (b): 漫透射; (c): 透射Fig.3 Average spectra of three different detection modes (a): Diffuse reflection; (b): Diffuse transmission; (c): Transmission |
对比了五种不同的光谱预处理方法对三种不同检测方式的光谱建模结果的影响, 每种检测方式中最佳的预处理方法如表2所示。 在漫反射检测方式中, 经过FD预处理后模型的性能最优, 在漫透射检测方式中, 经过SNV和FD预处理后模型的性能最优, 在透射检测方式中, 经过S-G平滑预处理后模型的性能最优。 结果表明由于不同预处理方法的原理不同, 对模型性能的影响也不同, 因此需要针对实际的光谱数据情况, 对比不同预处理方法, 选择最佳的预处理方法。
| 表2 基于LS-SVM模型的三种检测方式分类结果 Table 2 Classification results of three detection modes based on LS-SVM model |
为比较不同降维方法对不同检测方式光谱数据的降维效果, 将上述研究选择的最佳预处理方法用于不同的降维方法中, 具体结果如表2所示。 可以发现三种不同的检测方式中, 除了漫透射检测方式中基于PCA、 MDS和SNE三种方法预测集准确率都为92.86%外, 其他两种检测方式中基于SNE降维方法的模型性能最优。 表明SNE降维方法适用于苹果霉心病的多种检测方式的光谱降维问题, 后续的建模分析均采用SNE降维方法。
基于SNE算法的不同检测方式的数据集前三维可视化如图4(a, b, c)所示。 漫反射光谱经过降维后, 健康苹果和霉心病苹果在空间中的分布较分散, 且有较多的重叠样本, 漫透射光谱经过降维后, 健康苹果和霉心病苹果在空间中的分布进一步聚集, 重叠样本相对减少, 而透射光谱经过降维后, 健康苹果和霉心病苹果在空间中的聚集明显, 重叠样本进一步减少。 前三维的信息不能将健康苹果和霉心病苹果有效分类, 需要更多维度的光谱信息结合机器学习方法来解决苹果霉心病光谱分类问题。
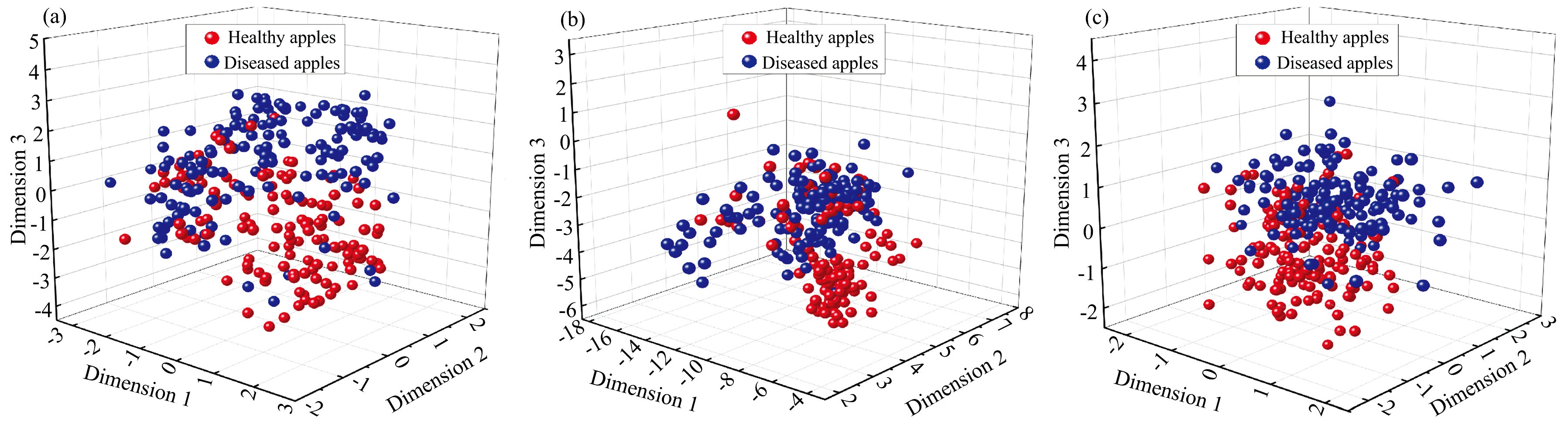 | 图4 基于SNE算法的不同数据集降维可视化图 (a): 漫反射; (b): 漫透射; (c): 透射Fig.4 Visualization of dimension reduction under different data levels based on SNE algorithm (a): Diffuse reflection; (b): Diffuse transmission; (c): Transmission |
惩罚系数γ 和核函数参数σ 2是LS-SVM模型的两个重要参数, 其中γ 表示对错分样本惩罚的程度, 实现错分样本比例与算法复杂度之间的平衡, σ 2表示径向基核函数的宽度, 影响数据在高维特征空间中分布的复杂性[16]。 建模前需要对模型的参数进行优化选择, 以确保模型的性能最优, 惩罚系数γ 和核函数参数σ 2通过两步网格搜索法确定, 其中γ 和σ 2的取值范围为[1× 10-5, 1× 105], 三种光谱数据集下LS-SVM算法参数优化结果如图5所示。 图中网格点“ · ” 和“ × ” 分别代表第一步和第二步网格搜索的范围与步长, 曲线代表轮廓误差。 三种检测方式光谱基于SNE降维方法的(γ , σ 2)最优参数值分别为(332 063.42, 4.25)、 (1.47, 0.43)、 (1.19, 3.76)。
 | 图5 LS-SVM算法参数优化结果 (a): 漫反射; (b): 漫透射; (c): 透射Fig.5 Parameter optimization results of LS-SVM algorithm (a): Diffuse reflection; (b): Diffuse transmission; (c): Transmission |
基于LS-SVM模型的三种检测方式分类结果如表2所示。 三种光谱检测方式中, 透射检测方式最优, 其次是漫透射检测方式, 最低的是漫反射检测方式。 漫反射检测方式中最优模型的测试集将4个健康苹果和3个霉心病苹果误判, 模型准确率为90.00%; 漫透射检测方式中最优模型的测试集将3个健康苹果和2个霉心病苹果误判, 模型准确率为92.86%; 而透射检测方式中最优模型的测试集只将2个霉心病苹果误判, 没有误判的健康苹果, 模型准确率为97.14%。
为了清楚地表示不同检测光谱方式的误判样本, 深入探究不同检测光谱方式的优势, 用韦恩图表示误判的霉心病苹果和健康苹果的标签编号。 从图6(a)中可以看出, 对于误判的霉心病样本, 三种检测方式都将编号107样本误判, 透射检测方式将编号155样本误判, 但漫反射和漫透射检测方式没有将该样本误判。 同样, 漫透射检测方式将编号144样本误判, 但透射和漫反射检测方式没有将该样本误判。 漫反射检测方式将编号56和编号87样本误判, 但透射和漫透射检测方式没有将这两个样本误判。 对于误判的健康样本, 透射检测方式没有误判的样本, 其他两种检测方式都将编号12和编号110样本误判, 另外漫反射检测方式还将编号102和编号109样本误判, 而漫透射检测方式只将编号121样本误判。 结果表明不同的检测方式针对不同类型的霉心病样本具有各自的检测优势和不足, 后期可以考虑将不同的检测方式结合, 以实现不同检测方式之间的优势互补, 进一步提高苹果霉心病检测准确率。
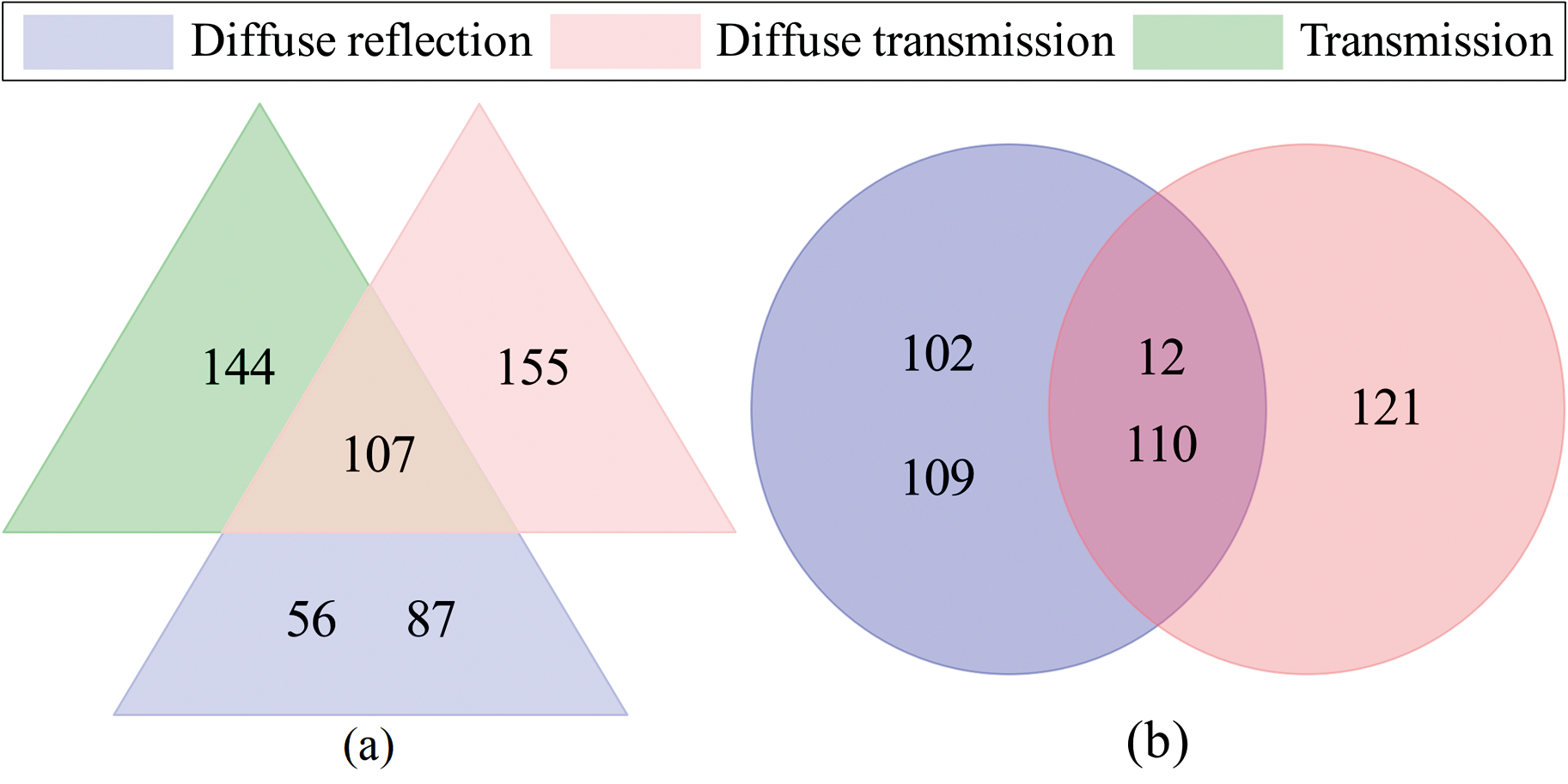 | 图6 不同光谱检测方式误判样本韦恩图 (a): 误判的霉心病苹果; (b): 误判的健康苹果Fig.6 Venn diagram of misclassified samples with different spectral detection modes (a): Moldy apples misclassified sample; (b): Healthy apples misclassified sample |
三种检测方式都将编号107样本发生误判, 从图7中可以发现, 该样本是一个发病程度较轻的霉心病样本, 由于病害程度较轻的霉心病样本与健康苹果果肉组织没有显著差异, 导致光谱信息差异较小, 所携带的霉心病分类信息相对较弱, 因此这种类型的样本无论哪种检测方式都不能正确识别, 需要借助其他的无损检测方式来解决这类问题。 除了漫反射检测方式误判编号56和编号87的样本发病程度较高外, 漫透射和透射误判编号155和编号144的样本发病程度相对较低, 说明漫反射检测方式会将病害程度高的霉心病样本误判, 而漫透射与透射检测方式会将发病程度较低的霉心病样本误判。
 | 图7 不同光谱检测方式误判的霉心病苹果表型图Fig.7 Phenotype of moldy apples core misclassified by different spectral detection modes |
基于同一检测方式获取的光谱数据, 所采用的数据降维方法不同, 最终模型结果也存在一定的差异, 但在不同检测方式的光谱数据中基于SNE流行学习降维方法的降维效果普遍都优于其他降维方法, 表明该降维方法适合解决苹果霉心病光谱降维问题。 其次, 可以发现, 并不是所有的流行学习降维方法都优于传统的PCA降维方法, 比如在漫反射检测方式中, 基于MDS和t-SNE的流行学习方法的预测集准确率仅为85.71%, 而基于PCA降维方法的预测集准确率为88.57%, 此外其他两种检测方式中也存在该情况。 主成分分析作为一种线性降维方法, 对线性分布的数据具有较好的降维效果。 实际的苹果霉心病光谱无损检测问题中既包含简单的线性分类问题, 又存在复杂的非线性分类问题, 因此降维方法的选择需要结合实际的数据分布情况来选择最佳的降维方法。
针对同一批霉心病检测样本, 漫反射、 漫透射和透射三种光谱检测方式都可以实现苹果霉心病检测, 但从检测结果来看, 透射检测方式优于漫透射检测方式。 由于苹果霉心病是一种苹果内部病害, 病菌的侵染是从苹果果核向周围组织逐渐扩散, 病害组织对光的吸收能力强于健康组织[17]。 透射检测方式的检测光源位于苹果的正上方, 信号接收器位于苹果的正下方, 检测光源可以穿过苹果的果核及周围组织, 携带更多的苹果霉心病病害信息, 而漫透射检测方式的检测光源是从苹果45° 方向进入苹果内部, 尽管可以通过苹果果核位置, 但更多的是与苹果果肉之间的相互作用信息。 透射和漫透射检测方式优于漫反射检测方式, 主要是因为漫透射和透射检测方式的检测光源能量强, 且光源、 苹果和信号接收器的位置能使检测光源经过苹果内部, 携带了更多的霉心病病害信息。 而漫反射检测所采用的检测光源的功率较小, 穿透能力有限, 因此获取的光谱信息往往只是苹果表面和浅层信息。 大部分研究采用透射或漫透射检测方式[18, 19]开展苹果霉心病无损检测研究。 下一步可以借助蒙特卡洛模拟方法深入探究不同的光谱检测方式中光子在苹果组织间相互作用规律[20], 以便从理论上解释透射检测方式优于漫透射检测方式, 漫透射检测方式优于漫反射检测方式的结果。
比较了漫反射、 漫透射和透射三种不同的光谱检测方式和五种不同的降维方法分别对苹果霉心病检测精度的影响。 结果表明, 光谱检测方式对苹果霉心病检测结果影响较大, 在不同的光谱检测方式中, 最佳的光谱检测方式是透射, 其次是漫透射, 最低的是漫反射。 在不同的光谱数据降维方法中, 基于SNE的流行学习降维方法在三种光谱数据中都具有明显的优势, 说明该方法更适合解决苹果霉心病光谱数据降维问题。 最终基于透射检测方式和SNE降维方法构建了最优的苹果霉心病判别模型, 其中测试集的总体准确率为97.14%, 分别高于漫透射检测方式和漫反检测方式的4.28%和7.14%。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|