

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于光谱反射率的低照度图像增强方法研究
[麻祥才1, 2  , 曹前
, 曹前2 , 白春燕2 , 王晓红3 , 张大伟1, * ]
, 曹前]
|
|


作者简介: 麻祥才, 1991年生, 上海理工大学光电信息与计算机工程学院博士研究生 e-mail: Marcle_caizi@163.com
低照度图像增强技术是机器视觉研究热点之一, Retinex理论模型假设图像是反射分量与光照分量乘积, 通过去除或校正光照分量并结合物体的反射特性来恢复图像, 被广泛应用在传统算法和深度学习增强模型中。 光谱反射率是颜色的指纹, 多光谱图像比普通图像的信息量更为丰富。 色度学理论和Retinex理论都认为图像的颜色特性取决于反射系数, 但光谱反射率是基于仪器测量获得真实的数据, 而图像反射分量是基于图像分解假设的数据, 目前文献没有从光谱角度对低照度图像增强进行研究。 受Retinex理论启发结合深度学习非线性拟合能力, 用颜色的光谱反射率代替RetinexNet网络中的图像反射分量, 用CIE标准光源的光谱功率分布代替网络中的图像照明分量, 提出了一种基于光谱反射率的低照度图像增强方法。 首先对图像数据库中正常光照图像进行光谱重建, 构建低照度图像与正常光照的多光谱图像数据集。 然后训练将低照度图像转换成多光谱图像的深度学习网络模型。 任意低照度图像通过网络模型得到多光谱图像, 多光谱图像根据色度学理论得到CIEXYZ三刺激值, 再通过标准颜色空间转换到RGB颜色空间中显示。 该方法在公开LOL数据集上进行训练与测试, 结果表明在图像噪声抑制和颜色恢复方面都优于常用方法, 证明该方法对低照度图像增强的优越性和有效性。
Low illumination image enhancement technology is one of the research hotspots of computer vision. The theoretical algorithm of Retinex assumes that the image is the product of the reflection component and the illumination component. It restores the image by removing or correcting the illumination component and combining the reflection component of the object, which is widely used in traditional algorithms and deep learning enhancement models. Spectral reflectance is the fingerprint of color, and multispectral images have more information than RGB images. Colorimetric theory and Retinex theory agree that the color of an image depends on reflection data, but spectral reflectance is obtained based on instrument measurement, and the image reflection component is obtained based on image hypothesis decomposition. The literature has not studied the enhancement of low-light images from the perspective of spectral reflectance. Inspired by Retinex theory and combined with the strong nonlinear fitting ability of deep learning, a low illumination image enhancement method based on spectral reflectance is proposed. The spectral reflectance of color is used to replace the image reflection component in the RetinexNet network, and the spectral power distribution of the CIE standard light source is used to replace the image illumination component in the network. Firstly, the spectral reflectance of normal light images in the image database is reconstructed to build a multispectral image dataset of low illumination and normal light images. Then, the deep learning network model is trained to convert low-illumination images into the multispectral images. Any low illuminance image is obtained from the multispectral image through the network model, and the multispectral image is obtained from the CIEXYZ tristimulus according to the colorimetric theory and then converted to the RGB color space for display through the standard color space.The method is trained and tested on the public LOL dataset, and the results show that this method is superior to the standard methods in image noise suppression and color restoration, which proves the superiority and effectiveness of this method for low illumination image enhancement.
光照不足会影响图像成像质量, 造成不佳的人眼视觉感知和限制其在机器视觉领域中的应用。 研究者们提出了许多低照度图像处理技术, Retinex理论是图像增强方法中应用最广泛的方法之一, 最经典的算法包括单尺度Retinex(SSR)算法[1]、 多尺度Retinex(MSR)算法[2]以及具有色度保持的MSR方法(MSRCP)[3]。 为了更好抑制噪声和颜色恢复, 后来研究人员又提出基于变分优化的Retinex模型[4]和通过照明图估计的低亮度图像增强(LIME)[5]等算法, 这些算法可以较好再现图像颜色和阶调层次, 但参数复杂。
深度学习网络模拟人脑信息处理机制来提取数据特征, 采用复杂的非线性函数拟合输入到输出映射关系, 在许多计算机视觉领域应用中展现出优势。 Li等提出LightenNet[6], 利用卷积神经网络来估计低照度图像的光照图像, 然后利用引导滤波优化光照图像, 最后基于Retinex模型获得增强图像。 Lü 等设计了反射和照明分解网络[7], 为了在保持边缘信息的同时提高亮度, 增加注意力引导照明调整网络。 通过对抗学习网络融合图像, 以减少图像退化来提高图像自然度。 Zhang等建立了一个简单有效的KinD网络[8], 该网络将图像分解为反射分量和光照分量, 使用在不同曝光条件下拍摄的成对图像进行训练。 Zhang等提出了一种基于信息熵理论和Retinex模型的自监督(Self-supervised)图像增强方法[9]。 深度学习和Retinex理论相结合的方法在一定程度上取得不错效果, 但在颜色恢复和抑制噪声方面仍需提高。 光谱反射率是一种物理特性, 通常用于高保真彩色再现以解决同色异谱现象[10], 但基于光谱反射率的低照度图像增强研究较少。
鉴于此, 本研究提出了一种基于光谱反射率的低照度图像增强方法。 首先介绍基于光谱反射率的低照度图像增强的理论, 利用光谱重建技术构建图像库中正常RGB图像的多光谱数据集, 然后利用深度学习训练将低照度图像映射为多光谱图像的网络模型。 任意低照度图像通过网络模型得到多光谱图像, 多光谱图像根据色度学理论得到CIEXYZ三刺激值, 再通过标准颜色空间转换到RGB颜色空间中显示并利用主客观评价方法对多光谱图像的参照光源进行选择。 通过测试图像的增强效果, 比较现有方法与本文方法的优越性。
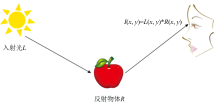
Retinex理论模型是用于低照度图像增强的经典算法之一, 该模型将图像看作反射分量与光照反射之积如图1所示, 认为物体的颜色的反射系数决定了图像的内在固有属性。
 | 图1 Retinex理论模型示意图Fig.1 The schematic diagram of Retinex theoretical model |
假设图像I由光照分量L与反射分量R组成如式(1)所示。
从低照度图像中只需要估计出光照分量L并去除或者校正光照分量L, 得到反射分量R即可达到图像增强目的。
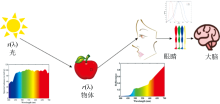
非发光体的颜色视觉感知形成过程是当光线照射在颜色物体上并与表面的颜料物质相互作用时, 一部分波长会被吸收, 而另一部分波长会被反射或透射, 并允许继续通过材料, 反射或透射的波长进入人眼并刺激视网膜中的感觉细胞, 最后刺激被传送到大脑形成视觉感知。 图2显示了反射物体颜色感知的形成过程。
 | 图2 反射物体视觉感知形成过程机理Fig.2 The formation mechanism of reflective object visual perception |
Retinex理论是基于图像分解角度进行出发, 但该理论与颜色视觉感知过程相类似, 图像的反射分量与色度学理论中光谱反射率, 图像中光照分量与颜色视觉感知中光照分量相等同, 可以为基于光谱重建的低照度图像增强提供理论依据。
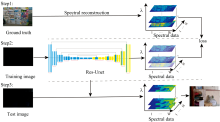
提出一种基于光谱反射率的低照度图像增强方法。 该方法的实施流程包括三个部分: 真实图像光谱反射率数据重建、 深度学习模型设计和深度学习模型应用, 如图3所示。
 | 图3 基于光谱反射率的低照度图像增强的实施过程Fig.3 Implementation process of low illumination image enhancement based on spectral reflectance |
研究证明孟塞尔1 269个无光泽标准色块显示出好的光谱反射率重构结果[11], 因此选择它作为训练样本来求解设备响应值到光谱反射率的转换矩阵。 孟塞尔色块颜色的光谱反射率利用分光光度计测量得到, 由于光谱反射率重建技术是对照度正常的RGB图像进行重构, 这要求孟塞尔色块设备响应值为RGB空间。 光谱反射率通过使用CIE 1931颜色匹配函数和CIE D50光源转换为CIE XYZ三刺激值, 如式(2)所示
式(2)中, K为调整系数, 这个常数取决于照明光源的Y刺激值, 通过式(3)求出
式(3), r(λ )为颜色物体的光谱反射率, s(λ )为光源功率分布,
颜色CIE XYZ三刺激值借助sRGB标准颜色空间转换得到RGB空间即为设备响应值。 根据训练样本的RGB数值和光谱反射率利用文献[12]方式进行求解转换矩阵, 实验表明, 基于[1, rgb, r3, g3, b3, rg2, rb2, gr2, gb2, br2, bg2, rg, rb, gb, r2, g2, b2, r, g, b]的平均色差为0.24, 最大色差为2.04, 适合求解转换矩阵。
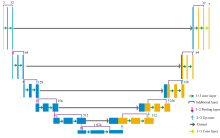
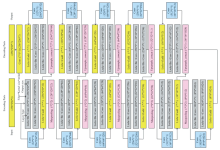
U-Net网络是一种形状类似U形的对称网络, 因其形状特殊性越来越多被应用到图像增强中, 分为编码过程和解码过程。 网络卷积层使网络具有更强的特征提取能力, 但随着网络卷积层的增加, 会导致网络的梯度消失问题。 He等提出的残差模块可以避免卷积层增加引起的梯度消失问题[13]。 因此, 在U-Net中引入残差模块形成Residual U-Net网络。 Residual U-Net结构示意图如图4所示, 参数如图5所示。
 | 图4 Residual U-Net结构示意图Fig.4 The schematic diagram of residential U-net structure |
 | 图5 Residual U-Net参数图Fig.5 The parameter diagram of Residual U-Net |
训练过程就是不断改变参数, 以获得较小的损失函数值。 该算法使用1-范数计算网络输出图像数据和正常光照多光谱图像之间的损失, 其表达式如式(4)
式(4)中, N表示训练样本的颜色数, ‖ · ‖ 1为1-范数, G表示相应的正常光照的多光谱图像, E是网络输出的预测值。
低照度图像输入到训练好Residual U-Net模型中输出得到增强后的多光谱图像, 根据色度学理论将多光谱图像转换CIEXYZ三刺激值图像后, 利用标准颜色空间到RGB空间的转换矩阵将CIEXYZ三刺激值图像转换RGB图像进行显示, 从而实现低照度图像的增强。
LOL图像数据集是一个真实场景提取的低照度/正常光照图像对的数据集[14]。 该数据集包含485对用于训练的图像和15对用于测试的图像, 分辨率为400× 600, 数据集包含场景较多, 适用于不同场景下的图像增强。
实验是在台式服务器上进行的, 显卡NVIDIA GeForce RTX3090, 编程语言Python 3.9.12, 深度学习框架TensorFlow 2.6, 在训练过程中, 输入图像随机裁剪长宽大小均为256个像素并对图像进行上下左右翻转操作来扩充图像数据库, 颜色值范围0到255除以255归一化为0到1, batchsize设置1, 共训练1 500次, Adam优化算法用于优化训练结果。
根据色度学理论, 网络输出的多光谱图像需要在光源照射下才能被人眼所感知。 人眼所感知的色彩受不同标准照明体的光谱功率能量分布影响。 不同标准照明体下多光谱图像CIE XYZ值由等式(2)计算得出, 再通过sRGB标准颜色空间将多光谱图像CIE XYZ值转换到RGB空间中显示, 不同标准照明体下同一幅图像的人眼感知的颜色如图6所示。
 | 图6 书柜图像不同照明体下颜色剐知 (a): A照明体; (b): B照明体; (c): C照明体; (d): D50照明体; (e): D65照明体; (f): F2照明体Fig.6 Color perception of bookcase image different illuminators (a): Illuminator A; (b): Illuminator B; (c): Illuminator C; (d): Illuminator D50; (E): Illuminator D65; (f): Illuminator F2 |
从图6中可以看出, 同一幅多光谱图像的颜色在不同标准照明体下人眼感知存在显著差异, 在低色温标准照明体下图像整体趋于暖色调, 在高色温标准照明体下图像整体趋于冷色调。 相对于A和F2标准照明体, B、 C和D系列照明体下的人眼感知更符合正常光照下的人眼感知。 为了进一步选择出最佳的标准照明体, 三个经典指标: CIEDE2000[15]、 峰值信噪比(PSNR)[16]和结构相似性指数测度(SSIM)[17]来评价不同照明体下图像的客观数值, 具体数据见表1。
| 表1 不同标准照明体下的CIEDE2000、 PSNR和SSIM Table 1 CIEDE2000, PSNR and SSIM for different standard illuminants |
从表1中可以看出, 不同标准照明体下增强后图像与参考图像之间的CIEDE2000和PSNR存在差距, SSIM几乎相同, 这说明不同照明体对增强后图像颜色色相影响较大, 对增强后图像颜色亮度影响较小。 CIEDE2000数值越小, 说明增强后图像与参考图像色差越小。 PSNR和SSIM越大, 说明增强后图像越好。 D50标准照明体下增强后图像与参考图像的色差为9.36, 均小于其他标准照明体下的色差, PSNR为19.79均大于其他标准照明体下数值。 结合主观视觉感知, D50标准照明体的光谱功率分布选择为参考光源。
本文算法与NPE[18] LIME、 RRM[19]、 KinD、 Self-supervised、 RetinexNet进行比较验证对低照度图像的增强效果。 所有方法都在同一个数据集上测试, 该数据集包括来自LOL数据集的15个图像对, 不同方法的增强结果如图7所示。
 | 图7 不同算法对测试图像的增强结果 (a): 原图; (b): NPE; (c): LIME; (d): RRM; (e): KinD; (f): Self-supervised; (g): RetinexNet; (h): 所提方法; (i): 正常图像Fig.7 Results of test imageby different algorithms (a): Original image; (b): NPE; (c): LIME; (d): RRM; (e): KinD; (f): Self-supervised; (g): RetinexNet; (h): Proposed method; (I) Ground- truth image |
从图7中可以看出, 不同算法都显著提高了图像的质量。 从主观可以看出NPE算法尽管在图像颜色和亮度恢复效果较好但噪声严重, LIME算法对图像的亮度过度增强, RRM算法增强后的图像清晰度不够, KinD网络对图像亮度和抑制噪声表现好但在颜色恢复方面性能较差, Self-supervised网络对颜色和亮度恢复效果好但是噪声问题未很好的解决, RetinexNet网络同样存在噪声问题, 本文所提出算法可以很好地考虑图像的亮度和颜色。 客观评价方法借助于一些数学模型反映了人眼的主观感知。 为客观地评估增强结果, 采用三个经典指标: CIEDE2000、 峰值信噪比(PSNR)和结构相似性指数测度(SSIM), 评价结果如表2所示。
| 表2 不同算法的客观评价结果 Table 2 Objective evaluation results of different methods |
从表2中可以看出, 低照度图像采用不同方法增强后评价数值存在较大差距, 本文所提方法图像的客观评价优于比较算法的结果, 进一步证明所提方法的有效性。
旨在从光谱角度来提高低照度图像的质量。 该方法的优越性主要使用了图像颜色的光谱反射率, 与Retinex理论假设的图像反射分量相比, 图像颜色的反射率是颜色的物理属性。 Residual U-Net可以很好地实现低照度RGB图像到多光谱图像的转换。 实验表明, 该方法比现有方法具有好的图像质量, 可以为计算机视觉应用提供高质量的图像。 本研究将光谱重建应用到图像增强领域, 拓宽光谱重建的应用范围。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|