

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
灰霉病早期胁迫下花椰菜多酚氧化酶活性的高光谱研究
[王凯 , 薛建新
, 薛建新* , 李尧迪, 张明月]
, 薛建新, 李尧迪, 张明月]
|
|


作者简介: 王 凯, 1998年生, 山西农业大学农业工程学院硕士研究生 e-mail: wang13593517901@163.com
利用高光谱技术实现灰霉病早期胁迫下花椰菜多酚氧化酶(PPO)活性的快速无损检测。 为了使预测效果更好, 在900~1 700 nm光谱范围内采集253个健康花椰菜样本及257个染病花椰菜样本的光谱信息, 并使用分光光度计法对样本中多酚氧化酶活性进行测定。 对健康及染病花椰菜样本PPO活性均值进行分析, 发现健康花椰菜PPO活性均值(10.257 U·g-1)小于染病花椰菜PPO活性均值(12.324 U·g-1)。 利用光谱-理化值共生距离(SPXY)算法对样本进行校正集(健康样本193个, 染病样本197个)和预测集(健康样本60个, 染病样本60个)的划分, 对划分后的样本集进行六种单一预处理(卷积平滑算法SG、 去趋势算法DT、 中值滤波MF、 归一化处理NOR、 标准正态变量变换SNV、 基线校正Baseline)。 利用相关系数(R)和均方根误差(RMSE)作为模型评价指标, 发现预处理能够有效提高模型的精度和稳定性, 其中健康样本经NOR预处理后的预测集建模效果最好; 染病样本经DT预处理后的预测集建模效果最好。 采用连续投影算法(SPA)与回归系数法(RC)提取特征波长, 建立PPO活性值的偏最小二乘回归(PLSR)、 最小二乘支持向量机(LS-SVM)及BP神经网络三种预测模型, 探究不同特征波长提取方法对模型精度的影响, 比较不同建模方式对花椰菜PPO活性预测的准确度。 结果说明提取特征波长可以优化光谱信息, SPA和RC对两种样本提取的波长个数分别为9, 12, 7和11, 其中SPA优化后的光谱数据对健康样本PPO活性预测效果较好, RC优化后的光谱数据对染病样本PPO活性预测效果较好。 对比分析模型效果, 发现LS-SVM模型对两种样本和其对应的酶活性产生了很好的拟合效果。 最终发现, SPA-LS-SVM模型对于健康花椰菜PPO活性预测效果较好, 其预测相关系数( Rp)为0.832, 预测均方根误差(RMSEP)为1.676; RC-LS-SVM模型对于染病花椰菜PPO活性预测效果较好, 其 Rp为0.848, RMSEP为1.156。 研究结果表明高光谱技术可以实现灰霉病早期胁迫下花椰菜多酚氧化酶活性的测定, 为快速检测花椰菜多酚氧化酶活性及便携式仪器开发提供了科学依据。
Hyperspectral technique was applied to detect polyphenol oxidase (PPO) content in cauliflower with early botrytis stress. A total of 253 healthy cauliflower samples and 257 infected cauliflower samples were used to acquire hyperspectral within the range of 900~1 700 nm, and the corresponding PPO content in the cauliflowers were measured with the spectrophotometry method in order to make the prediction effect better. The mean value was applied to the analysis of the PPO with cauliflower samples, and results showed that the mean PPO content of healthy cauliflower (10.257 U·g-1) was less than that of infected cauliflower (12.324 U·g-1). The SPXY method divides the cauliflower sample set into a calibration set (193 healthy, and 197 infected samples) and a validation set (60 healthy and 60 infected samples). Six kinds of single pretreatment were performed on the divided sample set. The R (correlation coefficient) and RMSE (root mean square error) were used as the model evaluation index, and results showed that pretreatment can effectively improve the accuracy and stability of the mode. It was found that the predictive set modeling effect of healthy samples after NOR pretreatment is the best and that of infected samples after DT pretreatment is the best. Successive projection algorithm (SPA) and regression coefficient (RC) were used to select the characteristic wavelengths. Partial least squares regression, least squares support vector machines, and BP neural networks were built to explore the impact of different feature wavelength extraction methods on the accuracy of the model and compare the accuracy of different modeling methods on the prediction of PPO content of cauliflower. The results showed that extracting the characteristic wavelength can optimize the spectral information, and the number of wavelengths extracted by SPA and RC for the two samples were 9, 12, 7 and 11 respectively. It was found that the LS-SVM model has a good fitting effect on the two samples and their corresponding enzyme activities by comparing and analyzing the effect of the model. It was found that the LS-SVM model had a good fitting effect on the two samples and their corresponding enzyme activities. Finally, the results showed that the SPA-LS-SVM model had a good prediction effect on the PPO content of healthy cauliflower, with an Rp (correlation coefficient of prediction) value of 0.832 and an RMSEP (prediction root mean square error) value of 1.676; and RC-LS-SVM model had a good prediction effect on PPO content of infected cauliflower, with a Rpvalue of 0.848 and a RMSEP value of 1.156. This study showed that the hyperspectral technique can detect PPO content in cauliflower with botrytis stress and provide a theoretical basis for rapid detection of PPO contentin cauliflower and the development of portable instruments.
花椰菜(Brassica oleracea var. botrytis)又名菜花、 花菜、 椰菜花, 属于十字花科芸薹属, 是一种具有独特风味的两年生蔬菜作物, 主要种植在我国沿海及高海拔地区[1, 2, 3]。 花椰菜包含硫代葡萄糖苷、 维生素和类胡萝卜素等高水平抗氧化物, 具有很高的营养价值, 对于慢性疾病的预防有不错的效果, 因此深受消费者的喜爱[4, 5]。 然而花椰菜在生长过程中容易受到病害的侵袭, 灰葡萄孢(Botrytis cinerea Pers)感染后产生的灰霉病, 属于花椰菜常见病害之一, 其会造成花椰菜产量的下降, 严重影响经济效益。
植物在自然界中会受到许多非生物和生物胁迫, 在这些压力下进化出了复杂的防御系统来保护自己[6]。 当植物受到病害侵袭时, 自身的形态及生理指标会有一系列的改变, 病害会诱导植物产生大量的活性氧(reactive oxygen species, ROS), 这些活性氧会调控植物自身的防御系统, 对抵抗病菌的入侵具有重要的意义, 而过多的活性氧则会危害自身[7]。 多酚氧化酶(polyphenol oxidase, PPO)是一种存在于植物体内的铜结合酶, 在植物受到侵袭时起到防止氧化损伤的作用, 因此可以用来评估植物对于环境的抗性[8]。 在分子氧的参与下, PPO会将花椰菜体内的单酚羟基化为o-双酚, 然后将o-双酚氧化为o-醌, 醌继续氧化形成黑色物质使得组织产生褐变, 产生褐变的花椰菜会降低其本身的营养价值[9]。 目前测定花椰菜PPO活性方法包括毛细管电泳、 分光光度法、 化学发光法和色谱法, 这些方法能够比较准确测量PPO活性, 但其过程繁琐且会对样本造成破坏[10]。 亟需寻找一种快速无损的检测方法, 能够实现花椰菜灰霉病早期胁迫下的PPO活性检测, 从而对花椰菜灰霉病进行早期诊断。
高光谱是一种快速无损的检测方法, 已有学者将其成功的应用在植物酶活性检测上。 Boshkovski等[11]利用高光谱对三种不同品种橄榄在干旱干扰下的抗氧化酶活性进行预测, 使用主成分回归和偏最小二乘回归, 确定高光谱光谱信息和抗氧化酶活性的相关性。 Shrestha等[12]采用7倍交叉验证法建立偏最小二乘回归模型对鲜切苹果片的多酚氧化酶活性进行预测, 利用正交回归对多酚氧化酶活性测量值与预测值分析, 其相关系数为0.800, 结果表明高光谱检测技术能够实现鲜切苹果片多酚氧化酶活性的检测。 程帆等[13]利用高光谱检测技术对角斑病胁迫下的黄瓜叶片中过氧化物酶活性进行检测, 建立了两种特征波长下的偏最小二乘回归预测模型, 发现采用RF-PLSR模型可以快速无损的检测出病害早期胁迫下黄瓜叶片中过氧化物酶活性。 Li等[14]基于全波段和连续投影法提取特征波长, 建立线性偏最小二乘和非线性支持向量机的四个预测模型, 结果发现SPA-SVM预测模型效果最好, 在其基础上建立了五阶动力学模型, 利用该模型能够实现马铃薯晚疫病叶片过氧化物酶活性预测。
以上学者均利用高光谱实现了酶活性的研究, 但是利用高光谱技术对灰霉病早期胁迫下花椰菜中PPO酶活性进行预测, 尚未有相关的研究。 本研究采用高光谱结合化学计量学算法对花椰菜中PPO酶活性建立预测模型, 为实现灰霉病早期胁迫下花椰菜多酚氧化酶活性检测提供理论参考。
为避免其他未知病害对实验结果造成影响, 故选择对染病样本进行人工接菌处理。 试验的花椰菜样本在试验当天采摘自太谷区田地, 运送至实验室后进行挑选, 选择表面无明显损伤的完整花椰菜进行后续处理。 灰霉菌孢子悬浮液由山西农业大学食品科学与工程学院提供。 将灰霉菌在马铃薯葡萄糖琼脂培养基(potato dextrose agar, PDA)上培养10 d, 之后洗下孢子, 用无菌水调整孢子浓度, 得到浓度为1× 106 个· mL-1的灰霉菌孢子悬浮液用于后续研究。
将新鲜采摘的完整花椰菜切成大小均匀一致的样本, 将其浸泡在1%的次氯酸钠溶液中消毒处理, 取出后用无菌水清洗, 放入超净工作台晾干。 用接种针在样本中上部且花球紧密的位置注入10孢子菌悬液, 之后放入灭菌处理的托盘中, 覆盖保鲜膜密封, 放入相对湿度为90%, 温度为21 ℃的恒温恒湿培养箱中培养。 24 h后获取健康及染病花椰菜样本的高光谱信息, 为了使结果更准确, 染病样本的光谱信息应选择接种位点附近。 图1(a)为健康样本, 花球紧密且表面无损伤; 图1(b)为染病样本, 接种位点附近出现轻微的变化, 无病斑。
 | 图1 健康及染病花椰菜样本图 (a): 健康; (b): 染病Fig.1 Images of cauliflower samples (a): Health; (b): Infected |
本试验的主要仪器有北京卓立汉光公司生产的GaiaSorter-NIR高光谱分选仪, 其工作光谱范围为900~1 700 nm; 上海智城分析仪器公司生产的ZHJH-C1112C型超净工作台, 工作区下降气流流速为0.35 m· s-1; 上海安亭科学仪器厂生产的TGL-16G型离心机; 上海佑科仪器仪表公司制造的T2600型紫外可见分光光度计; 北京科伟永兴仪器公司制造的HWS-150型恒温恒湿培养箱, 其控温范围为5~50 ℃, 控湿范围为50~90%RH; 青岛海尔生物医疗公司生产的DW-86L416G型低温保存箱, 箱内温度为-40~-80 ℃。
高光谱仪主要部件有光谱相机、 光源、 移动平台、 计算机、 暗箱, 该仪器的分辨率为5 nm, 采集系统全部位于暗箱中。 为了得到清晰的图像, 需要进行多次调整, 经过测试, 当镜头与菜花的距离为30 cm, 移动平台的速度为2.5 cm· s-1, 数据的采集效果最好, 得到的图像最清晰。 为消除暗电流的影响保证试验的精度, 需要进行黑白板的校正。 其校正的过程为:
首先放入标准白板, 采集标准白板(反射率99.9%)的图像为IW;
再将相机镜头遮盖住, 采集黑板(反射率0%)的图像为IB;
最后采集样本的原始光谱图像Io。
根据式(1)得到完成校正的图像I
式(1)中: IW为白板光谱图像; IB为黑板光谱图像; Io为原始光谱图像; I为校正后光谱图像。
Boshkovski[11], Shrestha[12], 程帆[13], Li[14]等学者均使用光谱信息完成了酶活性的研究, 且经过预试验发现图像信息对于PPO酶活性预测效果不太理想, 因此本次试验利用高光谱光谱信息进行PPO酶活性的检测研究。
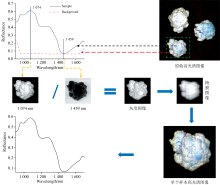
光谱信息提取利用ENVI 5.3软件实现, 为保证光谱信息的准确性, 对单个样本进行背景去除。 首先将样本反射率极大值(1 074 nm)下图像与反射率极小值(1 459 nm)下图像相除, 得到灰度图像[15]。 将灰度阈值设置为1.3, 图像中大于1.3的像素被置为1, 小于1.3的像素被置为0, 得到转化后的掩膜图像。 在原始光谱图像中去除掩膜图像, 得到去除背景的光谱图像, 在图像花球紧密的位置选择5× 5的矩形感兴趣区域, 计算所有像素点的平均反射率作为单个样本的光谱信息。 图2为单个样本提取光谱信息的过程。
 | 图2 单个样本光谱信息提取流程图Fig.2 Flow chart of single sample spectral extraction |
为防止PPO失活, 用液氮将采集完高光谱信息之后的菜花样本冷冻处理, 放入编号的密封袋中, 立即移入-80 ℃低温保存箱中进行保存。 PPO活性测定采用邻苯二酚法, 其原理为PPO催化邻苯二酚形成醌, 在分光光度计420 nm处使测量的OD值产生变化, 以每分钟变化0.1为1个酶活力单位[16]。
具体试验方法是根据吴咏等[17]方法作了一些改动。 (1)酶液的制备: 取花椰菜5 g冰浴研磨, 加入10 mL pH为6.4的磷酸缓冲液, 浸提5 h后在4 ℃离心10 min(13 000 r· min-1), 取上清液即酶液。 (2)酶活的测定: 取0.2 mL的酶液, 加入2.0 mL的磷酸缓冲液, 在35 ℃下水浴5 min, 取出后加入2 mL 1%的邻苯二酚, 摇匀, 立即计时并记录测定OD值, 之后每30 s记录一次, 记录总时长为3 min。 按式(2)计算PPO活性
式(2)中: U为每分钟吸光度变化0.1为1个单位; A为样品克数(g); B为样品提取液的总毫升数(mL); b为测定时用的样品液毫升数(mL)。
利用光谱-理化值共生距离(sample set partitioning based on joint x-y distances, SPXY)算法对样本集进行划分, 校正集的PPO活性值范围覆盖预测集PPO活性值有利于提高模型精度。 此次试验所作预处理为: 卷积平滑算法(savitzky-golay smoothing, SG), 多次取光谱平均值完成数据的加权平均来提高信噪比; 去趋势算法(de-trending, DT), 将光谱吸光度与波长拟合出的趋势线去除使光谱特征更加明显; 中值滤波(median filtering, MF), 利用邻域窗口的中值代替原始数据来减少边缘模糊; 归一化处理(normalize, OOR), 在光谱反射率有一定分布规律时, 对其中一组光谱数据进行标准化处理来消除固体颗粒对光谱的影响; 标准正态变量变换(standard normal variate transformation, SNV), 对单条光谱数据进行处理来消除表面散射带来的影响; 基线校正(baseline), 对被仪器背景等因素所影响的光谱曲线完成修正, 提高模型的稳定性。
为了缩短建模时间, 采用两种方式提取有效波长: 连续投影算法(successive projection algorithm, SPA)与回归系数法(regression coefficient, RC)。 利用偏最小二乘回归(partial least squares regression, PLSR)、 偏最小二乘支持向量机(least squares support vector machines, LS-SVM)和BP神经网络三种方式建模。 模型的质量通过相关系数(correlation coefficient, R)与均方根误差(root mean square error, RMSE)来评估, R越接近1说明模型的精度越高, RMSE越接近0说明模型越稳定[18]。
利用ENVI 5.3(Exelis Visual Information Solutions, USA)提取光谱信息; The Unscrambler X(CAMO, Process, AS, Norway)对光谱信息进行预处理并建立PLSR模型; MATLAB 2016 b(The MathWorks, USA)实现特征波长的提取及模型的建立; Origin 2018(OriginLab, USA)进行图形的绘制。
在建模前需要进行校正预测集的划分, 以便于更好的评估建立的模型。 利用SPXY算法进行校正预测集的划分, 其原理为利用光谱和理化值对样本间的距离进行计算。 其中健康样本中校正集划分193个, 预测集划分60个; 染病样本中校正集划分197个, 预测集同样划分60个, 具体划分的结果如表1所示。
| 表1 SPXY算法划分结果 Table 1 Division results by SPXY |
由表1可知, 花椰菜PPO活性的均值与类型存在一定的关系: 染病花椰菜PPO活性均值(12.324 U· g-1)大于健康花椰菜PPO活性均值(10.257 U· g-1), 对两种不同类型花椰菜的PPO活性进行独立样本t检验, 结果如表2所示, 其酶活性存在极显著性差异(p< 0.01)。 表明PPO作为花椰菜防御系统的一部分, 在其感染灰霉病后开始发挥作用, 增强抗病性来保护自身。
| 表2 独立样本检验分析结果 Table 2 The result of independent sample t-test |
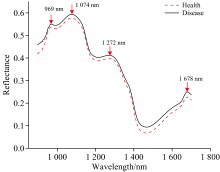
感染灰霉病后, 花椰菜的形态及生理指标都会发生变化, 反射率也会产生一系列的变化。 为直观了解这种变化, 计算健康及染病花椰菜样本的平均光谱并绘制曲线图, 图3为健康及染病花椰菜的平均光谱曲线。
 | 图3 健康及染病花椰菜的平均光谱曲线Fig.3 Average spectra of cauliflower samples |
由图3可知, 在900~1 700 nm范围内, 反射曲线趋势大致相同, 染病花椰菜样本的反射率整体大于健康花椰菜样本的反射率, 且不同样本的吸收峰强度不同。 从图3中可以看出, 两种花椰菜光谱曲线均在969、 1 074、 1 272和1 678 nm处出现了吸收峰。 其中969 nm为游离OH二级倍频吸收峰, 1 074 nm处为C=C基团三级倍频吸收峰, 1 272 nm与O— H伸缩振动有关, 1 678 nm为CH3一级倍频吸收峰。
由于获得的高光谱数据可能包含探测器的噪音及固体样品的光散射等无关的信息, 预处理可以有效地剔除这些信息, 增加模型的稳定性[19]。 采用SG, DT, MF, NOR, SNV及Baseline六种不同方式对光谱数据进行单一预处理, 将预处理后的光谱数据与PPO值构建PLSR模型。 以模型评价参数R与RMSE的值作为具体的评判标准, 选择最优预处理作后续研究。 表3为光谱不同预处理后的建模结果。
| 表3 不同预处理结果 Table 3 Different pretreatment results |
由表3可知, 对于健康样本, NOR预处理后的模型精度较原始光谱有所上升, 模型的稳定性也较好, 其预测相关系数(correlation coefficient of prediction, Rp)为0.854, 预测均方根误差(root mean square error of prediction, RMSEP)为1.558, 其余模型的预测精度相比较原始光谱均有所下降; 对于染病样本, 经SG和DT预处理模型的预测精度相比较原始光谱均有所上升, 经DT预处理后的模型精度和稳定性最好, 其Rp为0.851, RMSEP为1.144, 经NOR和SNV预处理效果较差, 可能是预处理后剔除掉了关键信息。 健康样本经DT预处理后建模效果最差, 染病样本经过DT预处理建模效果最好, 可能是样本染病后光谱的基线漂移现象较严重, 而经过DT预处理可以消除这种现象, 表明健康与染病样本分别建模进行预测PPO活性是有必要的。 因此健康样本选择经过NOR预处理后的光谱进行后续研究; 染病样本选择经过DT预处理后的光谱进行后续研究。
预处理后的光谱数据剔除了其中无关的信息, 但其全波段光谱数据依旧复杂, 进行特征波长的筛选可以减少模型变量数, 提升建模速度, 因此采用变量筛选方式挑出与PPO活性值相关的波长。 采用SPA和RC两种方法对经过预处理后的光谱数据进行特征波长的选择。
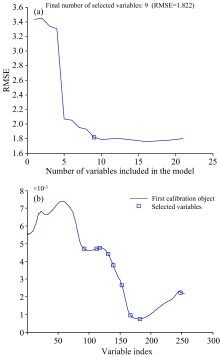
SPA是一种前向算法, 它划分一个波长个数范围, 从第一个波长开始, 计算每个波段在剩余波段下的投影, 按照投影值从大到小排列, 选择冗余度最小的变量组合[20]。 以健康样本为例: 图4为SPA算法提取特征波长的过程, 其中图4(a)横轴表示模型包含的变量个数, 纵轴表示均方根误差的变化, 当变量的个数为9个时, RMSE值为1.822; 图4(b)表示提取到的9个波长所在位置。
 | 图4 SPA提取的特征波长Fig.4 Characteristic wavelength extracted by SPA |
RC提取特征波长是在建立偏最小二乘回归模型之后, 在生成的回归系数选取极值点, 极值点所对应的波长则为特征波长。 以健康样本为例: 图5为通过RC法提取到的特征波长, 分别为915、 953、 994、 1 144、 1 189、 1 249、 1 338、 1 380、 1 434、 1 602、 1 631和1 656 nm。
 | 图5 RC提取的特征波长Fig.5 Characteristic wavelength extracted by RC |
由于SPA提取的数据为变量所在位置, 并不是实际的波长, 因此SPA与RC提取的两种类型的特征波长结果如表4所示。 健康样本采用SPA与RC方法提取的特征波长个数分别为9和12, 比全波段变量数少了96.46%和95.28%; 染病样本采用SPA与RC方法提取特征波长个数分别为7和11, 比全波段变量数少了97.24%和95.67%, 能够有效的提升建模速度。
| 表4 健康与染病样本的特征波长 Table 4 Characteristic wavelength of healthy and infected samples |
为了探究不同特征波长提取方法对模型精度的影响, 比较不同建模方式对花椰菜PPO活性预测的准确度, 将SPA与RC法提取到的特征波段的光谱值作为模型的输入值, 采用PLSR, LS-SVM和BP神经网络与PPO活性建立预测模型, 三种模型结果如表5所示。
| 表5 三种模型预测结果 Table 5 Prediction results of three models |
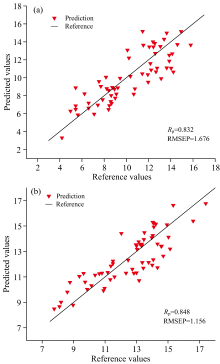
由表5可知, 健康样本的光谱数据经SPA优化后与PPO活性所建立的PLSR及LS-SVM模型效果优于经RC优化后所建立的两种模型, 表明SPA算法既提高了建模速度也提高模型的精度。 染病样本经RC方法提取后的光谱数据与PPO活性所建立的三种模型效果均优于经SPA法优化后建立的三种模型, 可能是由于SPA提取特征使得关键信息丢失, 造成其模型精度的下降。 对于两种样本而言, LS-SVM模型均能够有很好的预测效果, 证明LS-SVM模型能够使光谱数据与PPO活性产生很好的拟合效果; 而两种方法提取波长后建立的BP模型精度差距很小, 可能是神经网络的训练结果陷入了局部最优解。 结果表明SPA-LS-SVM模型对健康样本PPO活性预测效果最好, 其Rp为0.832, RMSEP为1.676; RC-LS-SVM模型对染病样本PPO活性效果预测最好, 其Rp为0.848, RMSEP为1.156, 可以实现花椰菜PPO活性的无损检测。 模型预测散点图如图6所示, 其中图6(a)为健康花椰菜最优模型预测散点图; 图6(b)为染病花椰菜最优模型预测散点图。
 | 图6 最优模型预测散点图 (a): SPA-LS-SVM; (b): RC-LS-SVMFig.6 Scatter diagram of optimal model prediction (a): SPA-LS-SVM; (b): RC-LS-SVM |
以花椰菜为研究对象, 分别建立了健康和感染灰霉病花椰菜PPO活性预测模型, 得到如下结论:
(1)染病花椰菜PPO活性相比健康花椰菜PPO活性有所增加, 表明PPO作为花椰菜防御系统的一环, 在花椰菜感染灰霉病后被激活, 以增强其抗病性保护自身;
(2)两种样本采用同一种预处理, 其PLSR模型精度结果截然相反: 健康样本经NOR预处理后预测精度最高, 而染病样本经NOR处理后预测精度最低, 表明花椰菜染病后其光谱信息基线漂移现象变严重;
(3)对比分析三种模型的预测结果, 发现LS-SVM模型能够使光谱数据与PPO活性产生很好的拟合效果, 其中SPA-LS-SVM模型对于健康花椰菜PPO活性预测效果较好, 其Rp为0.832, RMSEP为1.676; RC-LS-SVM模型对于染病花椰菜PPO活性预测效果较好, 其Rp为0.848, RMSEP为1.156。
研究表明高光谱检测技术可以有效实现灰霉病早期胁迫下花椰菜PPO活性检测, 然而花椰菜防御系统不只有单一的多酚氧化酶, 之后的研究将立足于酶活性的联系, 通过光谱实现花椰菜酶活性的快速检测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|