
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度学习的梨树养分含量高光谱监测
[黄林峰1  , 蒋雪松
, 蒋雪松1, 2, * , 贾志成1 , 周宏平1, 2 , 周磊1 , 戎子凡1 ]
, 蒋雪松, 贾志成|
|


作者简介: 黄林峰, 1999年生, 南京林业大学机械电子工程学院研究生 e-mail: huanglf@njfu.edu.cn
为了实现梨树生长和结果时期对于梨树养分的精准和及时地监测, 进一步为梨树施肥管理及梨果品质提升提供保障和调整策略, 养分监测十分重要。 使用ASD FieldSpec3高光谱仪获取梨树果实膨大期和成熟期的叶片高光谱数据, 采集叶片氮磷钾含量信息。 对比分析原始反射率、 一阶导数变换(FD)、 卷积平滑算法(SG)、 标准正态变量变换法(SNV)等光谱预处理方法对于高光谱反射率监测模型拟合效果的影响。 利用主成分分析(PCA)、 竞争自适应重加权抽样(CARS)和连续投影算法(SPA)选择高光谱数据的特征波段。 之后, 使用偏最小二乘法回归(PLSR)、 支持向量回归(SVR)、 随机森林(RF)、 梯度提升树(GBDT)、 卷积神经网络(CNN)、 深度森林(DF)算法建立基于特征波段的监测模型, 筛选梨树氮磷钾3种营养元素的最优高光谱监测模型。 结果表明, 深度学习算法DF具备较好的处理高光谱数据的能力。 氮元素的最佳建模组合为SG-SNV预处理的PCA特征波段的DF回归模型( R2=0.928 3, RMSE=0.238 1 g·kg-1); 磷元素的最佳建模组合为SG-SNV预处理的SPA特征波段的GBDT回归模型( R2=0.936 7, RMSE=0.043 1 g·kg-1); 钾元素的最佳建模组合为SG-SNV预处理的PCA特征波段的DF回归模型( R2=0.954 4, RMSE=0.276 7 g·kg-1)。 基于高光谱特征波段的监测模型拟合效果良好( R2>0.9), 可以实现梨树果实膨大期和成熟期氮磷钾含量的准确监测。
To achieve wide-scale, accurate, and timely monitoring of pear nutrients during the growth and fruiting periods of pear trees and to further provide protection and adjustment strategies for pear fertilization management and pear fruit quality improvement, we used the ASD FieldSpec3 hyperspectral spectroscopy system to monitor the nutrient content of pear trees. The ASD FieldSpec3 hyperspectrometer was used to obtain leaf hyperspectral data during the fruit expansion and ripening periods of pear trees and to collect information on the leaf nitrogen, phosphorus, and potassium content. The effects of spectral preprocessing methods such as raw reflectance, first-order derivative transformation (FD), convolutional smoothing algorithm (SG), and standard normal variable transformation (SNV) on the fitting effect of the hyperspectral reflectance monitoring model were comparatively analyzed through the raw spectral curves. Principal component analysis (PCA), competitive adaptive reweighted sampling (CARS), and successive projection algorithm (SPA) are then used to select the characteristic bands of hyperspectral data. After that, partial least squares regression (PLSR), support vector regression (SVR), random forest (RF), gradient boosted tree (GBDT), convolutional neural network (CNN), and deep forest (DF) algorithms were used to establish monitoring models based on the edge bands to screen the optimal hyperspectral monitoring models for the three nutrient elements, nitrogen, phosphorus, and potassium, in pear trees. The optimal modeling combination of nitrogen was the DF regression model of PCA eigenbands pre-processed by SG-SNV (R2=0.928 3, RMSE=0.238 1 g·kg-1). The optimal modeling combination of phosphorus was the GBDT regression model of SPA eigenbands pre-processed by SG-SNV (R2=0.936 7, RMSE=0.043 1 g·kg-1). The best modeling combination for potassium was the DF regression model (R2=0.954 4, RMSE=0.276 7 g·kg-1) for the SG-SNV preprocessed PCA feature band. The monitoring model based on hyperspectral edge bands was well fitted (R2>0.9), which can realize the accurate monitoring of nitrogen, phosphorus, and potassium content in pear fruit during expansion and ripening.
梨树是中国原产果树之一, 栽培历史悠久、 分布地区广泛, 栽培面积和梨产量居世界首位, 是重要经济林种, 梨产业为中国第三大水果产业[1]。
梨的质量取决于梨树生长过程中的营养状况。 氮是蛋白质、 核酸、 氨基酸等生命物质的合成元素, 能促进光合作用, 提高梨品质, 提高产量[2, 3]。 磷(P)元素常以有机物形态参与糖、 蛋白质和脂肪的代谢过程[4], 促进早期植物根系的生长[5], 并能提高抗逆性、 提高作物产量。 钾(K)主要以无机盐的形式存在, 在光合作用, 碳水化合物的转运、 储存, 蛋白质的合成等过程中占重要作用[6, 7]。
非成像高光谱采集主要利用地面便携式光谱仪(如ASD FieldSpec3光谱仪)[8], 根据作物生理状态不同对光谱反射率的影响, 可以进行作物养分丰缺的定性或定量监测。 2021年, Wang等[9]使用可见光-近红外(VIS-NIR)光谱和机器学习自适应增强(Adaboost)算法估算梨树叶片氮元素含量, 具有很好的准确性(R2=0.96, RMSE=1.03 g· kg-1)。 对于磷元素含量的监测, 2022年, 许童羽等[10]采用竞争性自适应重加权采样法(CARS)筛选氮元素与磷元素共同特征波段, 使用优化极限学习机(RUN-ELM)构建水稻叶片的反演模型效果较好(R2> 0.6)。
高光谱数据由于光谱分辨率高, 容易出现信息冗余的问题; 同时易受到成像设备与外部环境等因素的影响, 产生误差和噪音。 有学者发现使用卷积平滑算法(SG)和一阶导数组合对原始光谱进行预处理, 适用于苹果树冠层氮元素特征波段的筛选[11]。 同时, 筛选和改进模型也能提高监测效果, Sajad Sabzi[12]等尝试结合人工网络和模拟退火算法(ANN_SA)对黄瓜叶片特征波段进行筛选, 提高监测效果。
本工作以梨树为研究对象, 分析冠层光谱反射率对于梨树养分丰缺的响应程度, 探索适用于梨树养分检测的光谱特征, 在小样本量条件下构建新的深度学习模型, 并与经典机器学习模型和深度神经网络模型进行比较, 创新性地使用并分析深度森林(DF)算法的应用以提高模型拟合效果, 为梨树氮磷钾含量检测提供了一种小样本量情况下适用的新算法, 用于建立梨树养分监测模型, 指导梨树果园的精细化管理。
试验场地位于江苏省南京市花山现代园艺有限公司梨园内, 选择代表性梨树林作为测试区域(东经31.259 831 57° , 北纬118.941 971 7° )。 植株样本采集是从成熟的树枝中间收集, 确认叶片是无虫害, 新鲜且未受损的。
基于中华人民共和国农业行业标准(NY/T 2017-2011), 利用微量凯氏定氮法, 钼锑抗比色法和火焰光度计法分别对梨树叶片的全氮, 全磷和全钾含量进行了鉴定, 以此确定梨树的营养水平[13]。
每年的6月—8月份是梨树果实的主要生长阶段, 经历了坐果、 膨大和成熟等阶段。 于2022年6月至8月我们检测了样本叶片中的氮、 磷、 钾元素的含量(图1)。
 | 图1 各元素含量箱型图Fig.1 The content of each element |
高光谱数据采集使用FieldSpec3便携式光谱仪(ASD Inc., Analytical Spectral Devices Boulder, Boulder, CO, USA)。 光谱采样区间在350~2 500 nm的VIS-NIR-SWIR波段, 使用25° FOV的光纤, 光谱采样间隔为1 nm。 每次采集前使用聚四氟乙烯标准白色参考面板(Labsphere, North Sutton, NH, USA)进行高光谱反射率的校正。
高光谱数据采集时, 易受到光强不均、 传输噪声等因素的干扰, 影响后续建模精度。 因此, 在使用高光谱数据进行建模前, 首先对数据进行预处理校正, 以提高信噪比。
(1)卷积平滑算法(Savitaky-Golay, SG)
光谱在导数光谱分析之前需要进行平滑处理, 以最小化计算光谱导数时的高频噪声。 使用了一种计算高效的均值滤波器平滑方法。 平均滤光片平滑将指定窗口内所有点的平均光谱反射率值作为同一窗口中点的新值。 该算法可以表示为
式(1)中, n(采样点数)是滤波器的大小, 并且l是中点的索引。
(2)导数法
一阶导数(FD)变换突出了目标的反射率, 同时消除或限制了部分线性或近线性背景的影响。 该算法可以表示为
式(2)中, λ k和λ l分别是对应于k和l点波长, S(λ k)、 S(λ l)是与波长λ k和λ l相对应的光谱反射率值。
(3)标准正态变量变换法(standard normal variate transform, SNV)
SNV主要用来消除散射及光程变化对光谱的影响。 假设样本i的离散光谱为xi(1× m), 首先对该光谱的各个波段反射率取均值, 再将各个波段的原始光谱减去均值光谱, 最后再除以标准差。 该算法可以表示为
高光谱数据的特点是多波段、 相邻波段之间的强相关性和高冗余性。 选择合适的特征变量提取方法可以减少冗余, 降低模型复杂度, 提高模型稳定性。 主成分分析(principal component analysis, PCA)、 竞争自适应重加权抽样(competitive adaptive reweighted sampling, CARS)和连续投影算法(successive projections algorithm, SPA)被用于波长的选取。
主成分分析(PCA)是一种用于特征提取的线性转换方法[14]。 它能够将数据映射到新的坐标系, 使数据在新的坐标系中尽可能地分散, 从而提取出主要的特征信息。 PCA算法的特点是可以自动确定最佳投影方向, 将多维数据降为低维数据, 尽可能多地保留数据信息。
竞争性自适应重加权采样(CARS)[15]通过自适应更新采样对波长进行竞争选择, 得到一个与MCS采样次数相等的波长子集, 建立PLS模型并计算交叉验证均方根误差(RMSECV)。 最终, 选择对应于RMSECV最小值的波长作为光谱数据的特征波长[16]。
连续投影算法(SPA)[17]是通过谱变量的投影映射构造新的变量集, 并逐一选择与前一个变量共线性度最小的变量, 得到共线性度最小的变量集。 根据多元线性回归预测模型预测的最小均方根误差原则, 对各新变量组模型的预测效果进行评估, 筛选出最优变量数和起始变量数。
回归模型是通过建立数学模型来找出作物样本化学元素含量数值与光谱反射率数据之间对应关系。 选用的算法主要包括PLS、 SVR、 RF、 GBDT、 CNN和DF等算法。 将数据集按7:3的比例划分为训练集和测试集输入算法模型。
偏最小二乘法回归(partial least squares regression, PLSR)对矩阵X和矩阵Y的主成分进行分解, 以提取出相对于因变量最全面的变量, 并最大化主成分与浓度之间的相关性。 支持向量回归(support vector machines, SVR)是一种基于支持向量机(SVM)的机器学习算法, 其学习策略是将数据集中的样本数据映射到高维空间使得不同类样本之间的间隔最大化, 将分类监测问题转化为超平面的求解问题, 最终转化为一个凸二次规划问题的求解。 随机森林(random forest, RF)通过监督学习建立模型。 创建多棵决策树结构, 为每棵树随机分配输入变量, 出现频率最高的输出结果被确定为最终结果。 梯度提升树(gradient boosting decision tree, GBDT)通过反复迭代来最小化损失函数并提高模型预测能力, 计算过程包括梯度计算、 决策树构建和残差更新等步骤。
传统的回归算法, 对高光谱反射率数据表现不佳。 因为波长的数量通常大大超过样本量。 深度学习可以有效地深度提取特征, 并表现出优于传统技术的回归拟合能力。
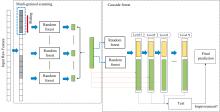
卷积神经网络(convolutional neural networks, CNN)是一种典型的深度神经网络算法, 它的核心思想是通过卷积和池化等操作提取出输入变量特征, 然后将这些特征输入到全连接层。 最终达到模型收敛状态且具备完成预测任务的能力。 深度森林算法(deep forest, DF)是一种基于随机森林集成学习的深度学习算法, 借鉴了CNN滑动卷积核的特征提取, 通过多粒度扫描(multi-grained scanning)方法, 滑动窗口扫描原始特征, 生成输入特征。 通过自动组合和选择多个随机森林中的特征来实现特征的高效学习, 计算过程包括数据随机分割、 特征随机选择和随机森林集成等步骤[18]。 流程如图2所示。
 | 图2 深度森林算法流程Fig.2 The process of deep forest algorithm |
决定系数R2, R2衡量的是监测模型整体的拟合度, 表达的是因变量与自变量之间的整体关系, 有确定的取值范围0~1[19]。 当决定系数越接近1时, 因变量在拟合线附近呈现均匀、 密集的分布状态, 表明模型的估测精度越高。 计算公式如式(4)
式(4)中: yi为冠层元素含量的实测值,
均方根误差RMSE, RMSE衡量观测值与真实值之间的偏差, 常用来作为机器学习模型预测结果衡量的标准[20]。 RMSE越小, 代表预测值和实测值之间的偏差越小, 表明模型的估测精度越高: 反之, RMSE越大, 表明模型的估测精度越低。
式(5)中: yi为冠层元素含量的实测值,
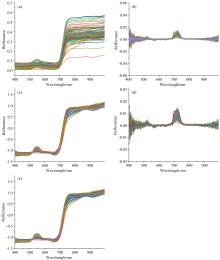
采用SG、 SNV、 FD、 SG-SNV、 SG-FD五种预处理方法对原始数据进行处理。 预处理后的样品的光谱曲线如图3所示。
 | 图3 经不同方法预处理后的样品光谱 (a): SG预处理; (b): FD预处理; (c): SNV预处理; (d): SG-FD预处理; (e): SG-SNV预处理Fig.3 The spectra of the sample preprocessed by different methods (a): SG; (b): FD; (c): SNV; (d): SG-FD; (e): SG-SNV |
为了更直观地比较预处理方法对模型拟合结果的影响, 在对光谱数据进行预处理后, 建立了全光谱波段(400~1 000 nm)训练的回归模型。 表1列出了不同预处理方法后PLS、 SVR、 GBDT、 RF、 CNN和DF算法的磷元素模型评价指标值(氮和钾元素的效果类似, 不再赘述)。
| 表1 经过不同预处理方法后的模型拟合结果 Table 1 The model fitting results with different pretreatment methods |
SG处理后, PLS和SVR模型的拟合效果降低。 其他预处理模型比未预处理的模型具有更好的拟合性能和更高的估算精度。 FD处理后, 除SVR模型的拟合效果有所降低以外, 其余5种模型拟合效果均有提升, 其中GBDT提升效果最为明显, R2提升接近50%。 SNV处理后, 所有6种模型均获得更好的拟合效果, GBDT、 RF、 CNN和DF模型的R2在0.75以上。
由表1中数据可知, 将SG与FD和SNV结合, 使用2种算法组合对光谱数据进行预处理, 模型的拟合效果将好于单种算法的预处理模型。 其中SG-FD仅对CNN和RF模型的表现好于SG-SNV, 在其余4种算法的表现上等于或逊于SG-SNV。 综上所述对于所有六种模型, 选取SG-SNV和SG-FD方法进一步研究。
使用CARS、 PCA、 SPA分别对SG-SNV和SG-FD方法预处理后的光谱数据进行特征波段筛选。
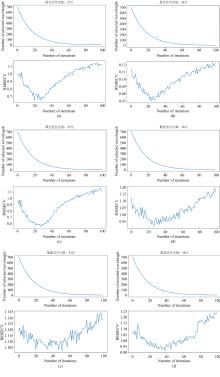
使用CARS算法的特征提取SG-FD预处理的光谱数据, 结果如图4所示。 将最大主成分数设置为20, 将MC采样时间设置为50, 并进行10倍CV。 随着MC样本数量的增加, 特征数量呈指数级下降。 RMSECV方差先减小后增大, 主要是由于去除了波长变量中的有效信息, 使RMSECV值增大, 进而模型性能下降。 CARS算法在SG-FD预处理光谱中分别筛选了119个氮元素的光谱特征波段, 144个磷元素的光谱特征波段和127个钾元素的光谱特征波段。 CARS算法在SG-SNV预处理光谱中分别筛选了138个氮元素的光谱特征波段, 34个磷元素的光谱特征波段和70个钾元素的光谱特征波段。 CARS算法很难筛选出几个特定的波长来表示梨树的养分丰缺(大于34个特征波段), 使用CARS进行特征波段的筛选难度较大。
 | 图4 CARS算法的特征波段筛选结果 (a): SG-FD氮元素; (b)SG-FD磷元素; (c): SG-FD钾元素; (d): SG-SNV氮元素; (e): SG-SNV磷元素; (f): SG-SNV钾元素Fig.4 The results of feature band screening of CARS algorithm (a): SG-FD for N; (b)SG-FD for P; (c): SG-FD for K; (d): SG-SNV for N; (e): SG-SNV for P; (f): SG-SNV for K |
使用PCA算法的特征提取SG-SNV和SG-FD预处理的光谱数据。 设置固定的阈值T(即累积贡献率)≥ 99.9%, 对筛选出来前n个特征变量进行分析。 当保留32个主成分时, SG-FD预处理数据特征累计贡献率> 99.9%, 仅占总变量数的5.33%。 当保留19个主成分时, SG-SNV预处理数据特征累计贡献率> 99.9%, 仅占总变量数的3.16%。
使用SPA算法, 对SG-FD和SG-SNV处理后光谱进行迭代选择, 结果如表2所示。
| 表2 SPA特征波段筛选结果 Table 2 Characteristic bands selection by SPA |
采用SPA算法, CARS算法和PCA算法提取特征波段, 对比分析不同建模算法。
表3显示的是基于SG-FD和SG-SNV两种预处理方法的氮元素监测模型拟合效果, 其中PLS和SVR算法在三种特征提取方法中效果较差, 结合表3中数据, 说明PLS与SVR算法不适合用于建立梨树氮元素的高光谱回归模型。 SG-FD和SG-SNV两种预处理方式优劣性区分较小, 基于CARS、 SPA和PCA三种特征提取方法的RF、 GBDT、 CNN和DF均能建立良好效果的回归模型(R2> 0.84, RMSE< 0.35 g· kg-1)。 基于PCA提取特征波段的回归模型略好于CARS和SPA, 其中使用SG-SNV预处理方法的PCA特征波段的DF回归模型效果最好(R2=0.928 3, RMSE=0.238 1 g· kg-1)。
| 表3 氮元素模型拟合情况 Table 3 Model fitting results for N element |
表4显示的是基于SG-FD和SG-SNV两种预处理方法的磷元素监测模型拟合效果, 其中SVR算法在三种特征提取方法中效果与氮元素回归模型类似, PLS算法仅在SG-FD预处理下的PCA建模效果良好, 不适合用于高光谱回归模型的建立。 使用SG-SNV预处理光谱数据的模型拟合效果略好于SG-FD, 基于三种特征提取方法的RF、 GBDT、 CNN和DF均能建立拟合良好效果的回归模型(R2> 0.86, RMSE< 0.04 g· kg-1), 其中SPA提取特征波段的回归模型略好于CARS和PCA。 使用SG-SNV预处理方法的SPA特征波段的GBDT回归模型效果最好(R2=0.936 7, RMSE=0.043 1 g· kg-1)。
| 表4 磷元素模型拟合情况 Table 4 Model fitting results for P element |
表5显示的是基于SG-FD和SG-SNV两种预处理方法的钾元素监测模型拟合效果, 其中SVR算法仅在SG-SNV预处理下的PCA建模效果良好, PLS算法仅在SG-FD预处理下的PCA建模效果良好。 使用SG-SNV预处理光谱数据的模型拟合效果好于SG-FD, 基于三种特征提取方法的RF、 GBDT、 CNN和DF均能建立良好效果的回归模型(R2> 0.9, RMSE< 0.37 g· kg-1), 其中PCA提取特征波段的回归模型好于CARS和SPA。 使用SG-SNV预处理方法的PCA特征波段的DF回归模型效果最好(R2=0.954 4, RMSE=0.276 7 g· kg-1)。
| 表5 钾元素模型拟合情况 Table 5 Model fitting results for K element |
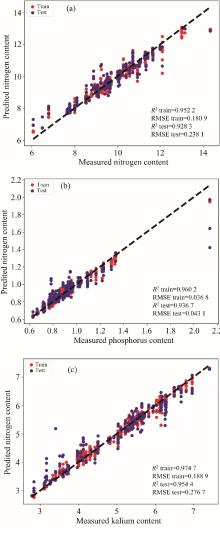
图5给出了基于最优监测模型的梨树氮磷钾含量预测值与实测值的散点图。 可以看到预测值和真实值在1:1线两侧离散点较少, 模型拟合结果较为良好。
 | 图5 模型预测值与实测值的散点图 (a): 最优氮元素监测模型; (b): 最优磷元素监测模型; (c)最优钾元素监测模型Fig.5 Scatter plot of model predicted value and measured value (a): Optimal N model; (b): Optimal P model; (c): Optimal K model |
以果实膨大期和成熟期梨树为研究对象, 利用实验室高光谱仪对梨树的氮磷钾营养元素含量进行监测, 结果表明:
将叶片原始光谱曲线经过SG-FD和SG-SNV处理后, 对应监测模型的拟合效果均有所提升, 合适的预处理方法可以有效提高模型拟合精度。 通过特征波段筛选, 可以降低高光谱监测模型的复杂度, 有效减少模型过拟合现象, 提高拟合精度, 使用PCA和SPA特征波段的建模拟合效果好于CARS特征波段的建模拟合效果。 氮磷钾三种元素的最佳建模组合拟合效果良好(R2均大于0.92)。 PLSR方法是一种线性回归方法, 不能有效地构建光谱反射率与叶片养分含量之间的回归模型, 说明梨树叶片养分含量与高光谱之间具有较强的非线性关系。 可以观察到, 基于深度学习的DF算法具备良好的处理非线性数据的能力(R2> 0.92), 鲁棒性好, 易于获得最佳建模结果, 可以为梨园的养分精准管理提供准确监测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|