




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高光谱图像的鞍山式铁矿品位反演方法研究
[曹旺1  , 毛亚纯
, 毛亚纯1, * , 文杰1 , 丁瑞波1 , 徐梦圆1 , 付艳华2 ]
, 毛亚纯, 文杰|
|


作者简介: 曹 旺, 1996年生, 东北大学资源与土木工程学院博士研究生 e-mail: 2010418@stu.neu.edu.cn
铁矿品位是评价铁矿贫富程度和经济价值的重要指标, 铁矿品位的检定效率对铁矿开采效率具有重大影响。 鉴于高光谱图像在物质分类与含量反演等领域具有分析速度快、 准确性高、 无破坏性等优势, 分别在可见光-近红外(VIS-NIR)与短波红外(SWIR)两个波段范围内采集鞍山式铁矿的高光谱图像, 探讨基于高光谱图像实现鞍山式铁矿品位反演的可行性。 首先, 提取高光谱图像感兴趣区(ROI)中的平均光谱代表对应样本的光谱数据, 分别采用多元散射校正(MSC)与标准正态变量变换(SNV)对其进行光谱变换。 然后, 分别利用蒙特卡洛无信息变量消除(MCUVE)、 竞争性自适应重加权采样(CARS)和连续投影算法(SPA)提取变换前后光谱数据的特征波段。 最后, 利用径向基函数神经网络(RBFNN)和极限学习机(ELM)分别建立鞍山式铁矿品位的定量反演模型。 结果表明, 在VIS-NIR范围内的光谱数据, 经MSC变换后, 利用CARS提取的特征波段建立的ELM品位反演模型效果最优( R2=0.90, RPD=3.02, RMSE=3.27, MAE=2.77)。 将MSC-CARS-ELM模型应用于鞍山式铁矿样品的VIS-SWIR高光谱图像, 能够生成像素级的铁矿品位分布图。 该研究为快速、 有效地实现鞍山式铁矿品位反演及可视化提供了一种新方法, 在地质采矿领域具有重要的应用价值。
Iron ore grade is an important index used to evaluate the degree of wealth and economic value of iron ore, and the verification efficiency of iron ore grade greatly influences the efficiency of iron ore mining. Because of the advantages of hyperspectral images in the fields of substance classification and content inversion, such as fast analysis speed, high accuracy, and non-destructive, this study collected hyperspectral images of Anshan-type iron ore in the two bands of VIS-SWIR and NIR, respectively, and discussed the feasibility of realizing grade inversion of Anshan type iron ore based on hyperspectral images. First, the average spectral representation in the ROI of the hyperspectral image is extracted, and the spectral data of the corresponding samples are transformed by multivariate scattering correction (MSC) and Standard normal variate transformation (SNV), respectively. Then, Monte Carlo uninformative variable elimination (MCUVE), competitive adaptive reweighted sampling (CARS), and successive projections algorithm (SPA) were used to extract the characteristic bands of the spectral data before and after the transformation. Finally, the quantitative inversion model of Anshan type iron ore′s iron grade is established using radial basis function neural network (RBFNN) and extreme learning machine (ELM). The results show that after the MSC transformation of spectral data in the VIS-SWIR range, the ELM grade inversion model established by using the feature bands extracted by CARS has the best effect ( R2=0.90, RPD=3.02, RMSE=3.27, MAE=2.77). Applying the MSC-CARS-ELM model to the VIS-SWIR hyperspectral image of an Anshan-type iron ore sample can generate a pixel-level iron ore grade distribution map. This study provides a new method for realizing grade inversion and visualization of Anshan-type iron ore quickly and effectively, which has important application value in geology and mining.
铁矿作为基础设施建设不可或缺的原材料, 深刻影响建筑业、 军工业、 机械制造业等行业的发展, 具有非常重要的战略地位。 鞍山式铁矿在世界范围内广泛分布, 占世界铁矿资源总储量的60%, 同时它也是是中国最重要的铁矿类型之一, 占中国铁矿资源总储量的55.2%, 具有重大研究价值[1]。
作为矿山资源潜力评价的重要指标与靶区优选的基础, 矿床的平均品位通常随着矿山的开采而不断下降, 因此与矿山开采初期相比, 矿山开采的中期以及后期必须处理更多的原矿才能生产相同单位的金属, 然而这将导致资源浪费和废石清除率以及开采能耗的增加[2, 3, 4]。 因此, 矿石品位的检定对矿山的开采效率以及开采成本具有重大影响[5]。
目前矿区主要利用化学分析法进行矿石品位检测, 该方法需要将采集的矿石样本粉碎后送到实验室进行化学分析, 尽管该方法检测精度较高, 但存在着化验周期长、 检测成本高、 无法原位测定品位等问题[6]。 高光谱定量反演作为一种快速、 无损、 非接触的物质分析技术, 其具有周期短和成本低等优点, 已被广泛应用于矿岩识别和矿石品位反演等研究[7, 8]。 Tusa等利用随机森林等机器学习方法预测黄铜矿等矿石中的铜品位, 并取得了较高的准确率[9], Gallie等基于VIS-NIR高光谱数据实现了来自安大略省萨德伯里盆地的矿山黄铜矿与石英、 花岗岩等岩石的分类[10]。
高光谱图像通常表示为一个立方体, 包含前两个维度的空间信息和第三个维度的光谱信息, 相较于点光谱仪测得的单反射光谱, 高光谱图像具有除光谱信息外的空间信息[11, 12]。 此外, 高光谱图像单像元尺寸较小, 提供了纯矿物的光谱, 可以量化样品表面各矿物的含量, 绘制不同组成成分的含量分布图[13, 14]。 例如, Krupnik等在综述中提出, 近距离高光谱图像在矿物勘探、 环境监测等方面具有广阔前景[15]; Dalm等基于室内NIR(950~2 550 nm)高光谱图像实现了黄铜矿、 绿泥石、 白云母等多种矿物的分类, 并且识别、 绘制的矿物图中可以明显观察到样品纹理[16]。 Agustin Lobo等基于室内VIS-NIR(450~950 nm)与SWIR(950~1 650 nm)的高光谱图像, 利用随机森林等机器学习方法, 实现了锡石、 黑钨矿、 黄铜矿等多种矿物的分类, 并且具有较高的整体准确率(98%)[17]; Dalm等分别利用浅成热液矿床钻孔岩芯样本的VIS-NIR(500~1 250 nm)和SWIR(1 250~2 500 nm)高光谱图像, 实现了叶蜡石和伊利石等废石识别[18]。
尽管学者们对基于点源高光谱数据的矿石品位反演与基于高光谱图像的矿石分类进行了较为深入的研究, 但针对基于高光谱图像实现矿石品位反演的研究较少。 因此本工作以中国辽宁省鞍山式铁矿为研究对象开展了如下研究: (1)利用鞍山式铁矿高光谱图像和化学分析数据建立铁矿品位预测模型; (2)通过比较不同预处理方法与建模方法组合后所建预测模型的精度与准确性, 寻找最优的品位预测模型; (3)开展铁矿品位可视化研究, 基于高光谱图像生成像素级的铁矿品位分布图。
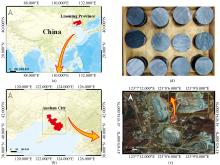
中国辽宁省鞍山—本溪地区探明铁矿储量超100亿吨, 工业储量超40亿吨, 居中国首位, 且易于开采, 具有极大的工业价值。 以辽宁省鞍山市鞍千矿露天采场为研究区, 在研究区内不同地点均匀采集鞍山式铁矿石, 对采集后的鞍山式铁矿石进行钻孔、 取芯以及切块处理, 制成185件块状铁矿样品, 如图1所示。 通过化学分析法对实验样本进行化学分析, 获取了实验样本的铁品位含量。 化验结果表明, 实验样本铁品位分布在11.4%~66.83%之间, 平均铁品位为29.85%。
 | 图1 研究区域位置图 (a): 中国地图; (b): 鞍山市地图; (c): 研究区域地图; (d): 部分样本Fig.1 Location maps of the research area (a): Map of China; (b): Map of Anshan city; (c): Map of study area; (d): Some samples |
分别使用美国Resonon公司生产的Pika L和Pika NIR-320高光谱成像仪对样品进行光谱测试, 仪器的具体参数如表1所示。
| 表1 成像光谱仪参数 Table 1 Parameters imaging spectrograph |
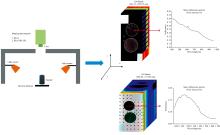
实验过程中, 将样品放置于移动平台上, 以4盏卤素灯为实验光源, 以标准白板为定标背景。 实验结束后使用与高光谱成像仪配套的Spectronon Pro软件将仪器采集的原始DN值转化为反射率数据。 因无法获取单独像元对应矿物的品位数据, 所以圈定每个样品在高光谱图像中所对应的全部像元为感兴趣区(region of interest, ROI), 提取ROI内的平均光谱代表该样品的光谱信息。 剔除传感器波段边缘噪声较大的数据后, VIS-NIR光谱数据保留的波段范围为404~959.89 nm, SWIR光谱数据保留的波段范围为964.48~1 667.87 nm。 高光谱图像采集与平均光谱提取流程如图2所示。
 | 图2 高光谱图像采集与平均光谱提取流程Fig.2 Process of hyperspectral image acquisition and average spectrum extraction |
分别以多元散射校正(multiplicative scatter correction, MSC)与标准正态变量变换(standard normal variate transformation, SNV)对原始光谱数据进行光谱变换, MSC可有效降低散射对光谱数据的影响, 修正光谱数据的基线平移和偏移现象; SNV可以消除固体颗粒间大小不均与表面散射引起的误差, 增强光谱数据中与品位相关的光谱信息。
此外, 高光谱数据包含大量的干扰和无信息变量, 现有研究通常对其进行特征提取后, 再利用机器学习的方法建立成分反演模型[16, 19]。 虽然如局部线性嵌入(locally linear embedding, LLE)、 等距特征映射(isometric feature mapping, ISOMAP)等经典流行降维算法在高光谱数据特征提取中具有较好的效果[19], 但其并不适用于高光谱图像[20]。 原因在于流行降维算法具有较高的计算复杂性, 尤其在百万级像素的高光谱影像降维应用中, ISOMAP算法中需要求解全局点间最短路径矩阵并对大型稀疏矩阵进行特征分解, LLE算法虽然是基于局部邻近点的线性重构, 但处理百万级像素高光谱图像时仍需要较大内存来存储光谱间的距离矩阵[21]。 因此本工作通过蒙特卡洛无信息变量消除(Monte Carlo uninformative variable elimination, MCUVE)、 竞争性自适应重加权采样(competitive adapative reweighted sampling, CARS)、 连续投影算法(successive projections algorithm, SPA)三种特征波段提取算法来减少高光谱图像的多重共线性和冗余, 以提高效率和可靠性。
径向基函数(radial basis function, RBF)神经网络是具有单隐含层的前向神经网络, 隐含层的变换函数是对中心点径向对称衰减的非负非线性函数。 一般采用高斯函数作为隐含层激活函数, 该函数是局部响应函数, 具有学习速度快、 避免出现局部极值等优点, 在解决非线性问题中有着广泛的应用[22]。
极限学习机(extreme learning machine, ELM)是具有单隐含层的前向神经网络, 它不仅对非线性数据具有较强的拟合能力, 且在训练过程中无需调整隐含层和输入层之间的连接权值, 只需设置隐含层神经元个数即可。 采用稳定性较强的Sigmoid函数作为隐含层激活函数, 并设置隐含层神经元个数为30[23]。
以决定系数(R2)、 相对分析误差(RPD)作为反演模型准确性的评价指标, 以平均绝对误差(MAE)、 均方根误差(RMSE)作为反演结果精度的评价指标。 R2和RPD越高, MAE与RMSE越小, 说明模型的拟合程度越好。
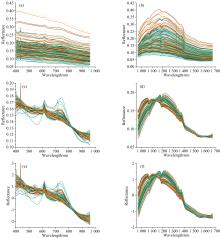
鞍山式铁矿样品的原始光谱反射率曲线与利用MSC和SNV对原始光谱数据变换后的曲线如图3所示。
 | 图3 鞍山式铁矿样品原始及变换后光谱曲线 (a): VIS-NIR; (b): SWIR; (c): VIS-NIR-MSC; (d): SWIR-MSC; (e): VIS-NIR-SNV; (f): SWIR-SNVFig.3 Original and transformed spectral curves of Anshan-type iron ore samples (a): VIS-NIR; (b): SWIR; (c): VIS-NIR-MSC; (d): SWIR-MSC; (e): VIS-NIR-SNV; (f): SWIR-SNV |
图3(a)与图3(b)为样本在VIS-NIR与SWIR范围内的光谱曲线, 在VIS-NIR范围内光谱曲线整体呈现缓慢降低的趋势, 在550与600 nm处存在两个较为明显的反射峰, 受Fe3+电子跃迁的影响, 样本光谱在700~750 nm区间存在一个微弱的宽缓吸收峰。 在SWIR范围内光谱曲线呈现先上升后下降的趋势, 在1 075与1 175 nm处存在两个较为明显的吸收谷。 由于大气中水汽的影响, 光谱在1 300~1 400 nm区间存在反射谷特征和波段震荡特征。 经MSC与SNV变换后的光谱曲线能有效突出上述光谱特征, 如图3(c)至图3(f)所示。
MCUVE将每个波段视为一个变量, 利用蒙特卡洛抽样法选取不同波段并建立偏最小二乘(partial least squares, PLS)模型, 可以求取每个波段所对应的稳定性, 并以PLS模型的交互验证均方根误差(RMSECV)为评价指标选择特征波段个数。 如图4所示, RMSECV随波段变量数量的增加整体呈现先降低后升高的趋势, 在所选变量数量分别等于18、 15、 17、 5、 18以及16次时, PLS模型达到最低的RMSECV, 即VIS-NIR、 VIS-NIR-MSC、 VIS-NIR-SNV、 SWIR、 SWIR-MSC、 SWIR-SNV六种光谱数据分别取稳定性绝对值最大的18、 15、 17、 5、 18和16个波段为该光谱数据的特征波段。
 | 图4 RMSECV随选定波段数量的变化(MCUVE) (a): VIS-NIR; (b): VIS-NIR-MSC; (c): VIS-NIR-SNV; (d): SWIR; (e): SWIR-MSC; (f): SWIR-SNVFig.4 RMSECV varies with the number of selected bands(MCUVE) (a): VIS-NIR; (b): VIS-NIR-MSC; (c): VIS-NIR-SNV; (d): SWIR; (e): SWIR-MSC; (f): SWIR-SNV |
CARS是一种逐步去除无关变量以保留关键变量的特征波段选择算法, 通过蒙特卡洛抽样方法选取N个波段子集, 然后利用这些波段建立PLSR模型, 以回归系数的绝对值作为每个波段的评价指标, 随着采样次数的增加, 保留波段的个数也随之减少, 在达到最低RRMSECV时仍保留的波段视为经算法选取的特征波段。 图5显示了CARS中RMSECV值随采样次数增加而变化的情况, 由图可知, RMSECV值随着采样次数的增加先呈现缓慢降低的趋势, 这是由于算法消除了大量冗余变量而对模型进行了优化, 而后RMSECV值呈现阶梯式升高的趋势, 是由于一些关键变量被消除而导致模型性能的恶化, 在采样次数分别为27、 26、 26、 26、 22和9次时模型达到最低的RMSECV值, 此时上述六种光谱数据仍保留的特征波段个数为20、 22、 22、 9、 10和52个特征波段。
 | 图5 RMSECV随采样次数增加而变化的情况(CARS) (a): VIS-NIR; (b): VIS-NIR-MSC; (c): VIS-NIR-SNV; (d): SWIR; (e): SWIR-MSC; (f): SWIR-SNVFig.5 Changes of RMSECV with the increase of sampling runs(CARS) (a): VIS-NIR; (b): VIS-NIR-MSC; (c): VIS-NIR-SNV; (d): SWIR; (e): SWIR-MSC; (f): SWIR-SNV |
SPA算法不以最小的RMSECV值为收敛条件, 而是以某点的RMSECV值与最小RMSECV值符合F检验(α =0.25)为截止程序, 在一定程度上避免了过拟合现象。 图6显示了SPA中RMSECV值随所选特征波段数量增加而变化的趋势, 在达到图中红点所示位置后, RMSECV曲线仍呈现下降的趋势, 但随着所选特征博段数量的进一步增加, 改善变得微乎其微, RMSECV曲线变得较为平稳, 且所选点与最低点RMSECV值满足F检验(α =0.25), 因此上述六种光谱数据保留的特征波段数量分别为26、 26、 28、 22、 12和17。
 | 图6 RMSECV随选定波段数量的变化(SPA) (a): VIS-NIR; (b): VIS-NIR-MSC; (c): VIS-NIR-SNV; (d): SWIR; (e): SWIR-MSC; (f): SWIR-SNVFig.6 RMSECV varies with the number of selected bands(SPA) (a): VIS-NIR; (b): VIS-NIR-MSC; (c): VIS-NIR-SNV; (d): SWIR; (e): SWIR-MSC; (f): SWIR-SNV |
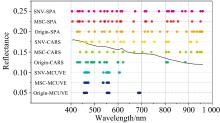
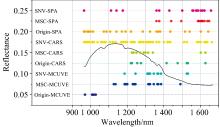
VIS-NIR与SWIR光谱数据经不同预处理组合算法提取的特征波段分别如图7与图8所示。
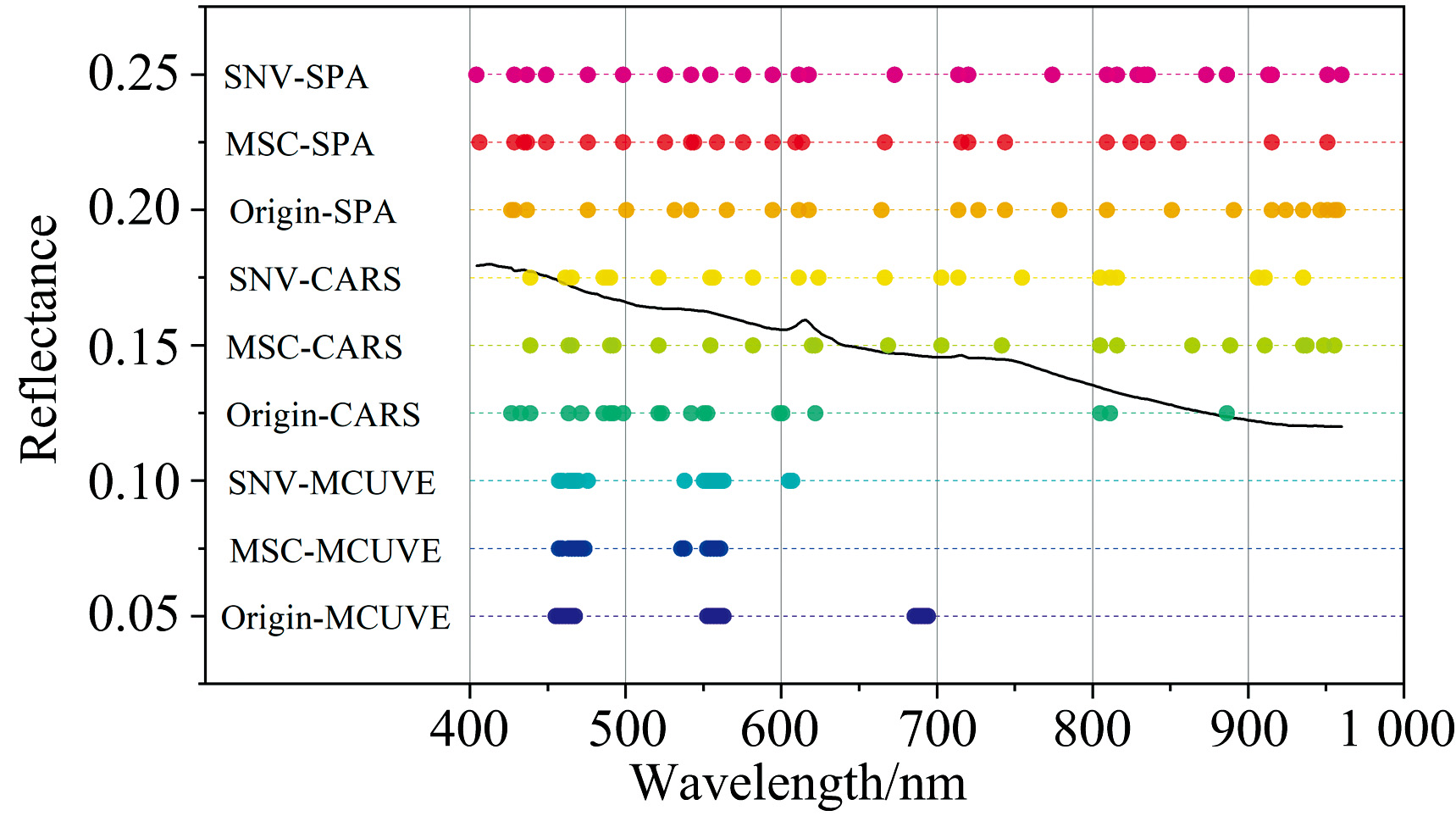 | 图7 VIS-NIR光谱数据基于不同预处理方法对选择的特征波段Fig.7 Characteristic bands selected for VIS-NIR spectral data based on different pretreatment methods |
 | 图8 SWIR光谱数据基于不同预处理方法选择的特征波段Fig.8 Characteristic bands selected for SWIR spectral data based on different pretreatment methods |
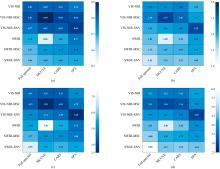
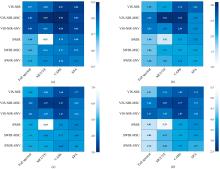
训练集与测试集按照3:1的比例进行均匀划分, 以139个鞍山式铁矿样本的数据作为模型的输入数据, 使用46个鞍山式铁矿样本的数据检验模型的准确性与精度。 本文以决定系数(R2)、 相对分析误差(RPD)作为反演模型准确性的评价指标, 以平均绝对误差(MAE)、 均方根误差(RMSE)作为反演结果精度的评价指标, 基于RBFNN和ELM建立铁矿品位反演模型准确性与精度的评价指标分别如图9与图10所示。
 | 图9 基于预处理前后光谱数据的RBFNN预测结果 (a): R2; (b): RPD; (c): RMSE; (d): MAEFig.9 Prediction results of RBFNN based on the spectral data before and after preprocessing (a): R2; (b): RPD; (c): RMSE; (d): MAE |
 | 图10 预处理前后光谱数据基于ELM的预测结果 (a): R2; (b): RPD; (c): RMSE; (d): MAEFig.10 Prediction results of ELM based on the spectral data before and after preprocessing (a): R2; (b): RPD; (c): RMSE; (d): MAE |
由图可知, 原始光谱数据反演精度较低, 因其可能受到实验环境、 矿石表面散射等的影响, 此外, 原始光谱数据含有较多的噪声和冗余信息, 光谱特征不明显。 MSC与SNV两种光谱变换方法可有效突出光谱特征信息, 消除表面散射的影响, 从而提升反演模型的准确性与精度。 MCUVE、 CARS以及SPA通过提取特征波段的方法实现光谱特征提取, 可在有效降低光谱数据冗余的同时较好的保留原始光谱数据特征, 提高光谱质量。 不同的预处理组合算法对反演模型的提升效果不同, 在VIS-NIR范围内MSC-CARS-ELM反演模型效果最优, R2=0.90, RPD=3.02, RMSE=3.27, MAE=2.77。 在SWIR范围内SPA-ELM反演模型效果最优, R2=0.80, RPD=2.23, RMSE=4.42, MAE=3.70。 基于RBFNN与ELM所建模型中皆为VIS-NIR-MSC-CARS组合算法精度最高, 相应的预测值与实测值差异图如图11(a)与图11(b)所示, 其中该组合算法利用RBFNN所建模型R2=0.90, RPD=2.75, RMSE=3.59, MAE=3.04, 模型准确性与ELM所建模型相近, 但反演精度低于ELM所建模型。
 | 图11 预测值与实测值差异图 (a): VIS-NIR-MSC-MCUVE-RBF; (b): VIS-NIR-MSC-CARS-ELMFig.11 Scatterplots of predicated value vs measured value (a): VIS-NIR-MSC-MCUVE-RBF; (b): VIS-NIR-MSC-CARS-ELM |
将感兴趣区中所有像素对应的光谱数据经MSC变换后, 以CARS选择的26个波段(442.73、 467.35、 469.4、 494.15、 496.22、 525.25、 558.63、 585.9、 623.9、 626.02、 672.83、 707.14、 745.98、 809.12、 820.07、 868.52、 892.9、 915.15、 939.71、 941.95、 953.16和959.89 nm)作为输入数据输入至已经建立的ELM模型中, 预测每个像素点的品位数据。 由于样本内存在石英等不包含铁元素的矿物, 且矿石表面在取样切割过程中存在少量破损, 因此将预测值高于100%或低于0%的像素点用黑色表示。 图12为部分鞍山式铁矿样品的品位预测可视化结果, (a)、 (b)和(c)三个样本的品位预测平均值分别为22.34%、 24.79%和42.28%, 品位实测值分别为19.48%、 21.63%和38.59%。
 | 图12 MSC-CARS-ELM模型得到的鞍山式铁矿品位可视化预测图Fig.12 Visual grade prediction diagram of Anshan type iron ore obtained by MSC-CARS-ELM model |
与基于点源高光谱数据所建矿石品位反演模型不同[9, 24], 本工作以高光谱成像仪采集的室内高光谱图像为数据源, 探究了基于成像高光谱数据实现鞍山式铁矿品位反演的最优预处理组合算法。 通过CARS提取特征波段, 在简化模型输入变量, 降低计算复杂性和提升模型精度的同时, 也有助于开发基于特定波段的多光谱成像系统, 以满足快速在线检测鞍山式铁矿品位的需求。 此外, 成像光谱特征与基于无人机平台的矿区大面积高光谱成像特征更为相近, 本研究结论可以更好的支持矿山大面域成像高光谱数据的品位反演。 然而, 目前研究还处于室内高光谱图像并局限于单一样本的品位反演与可视化阶段, 下一步将基于机载高光谱图像实现矿区大范围的矿岩分类与矿石品位提取工作。
旨在探索应用高光谱图像实现鞍山式铁矿品位反演的能力, 并比较不同预处理组合算法和建模算法对反演模型的影响, 在VIS-NIR范围内MSC-CARS-ELM反演模型的准确性与精度最高(R2=0.90, RPD=3.02, RMSE=3.27, MAE=2.77), 可以实现快速无损检测鞍山式铁矿品位。 将MSC-CARS-ELM模型迁移至高光谱图像, 成功创建品位的二维分布图并实现伪彩色可视化, 品位变化对应的颜色变化也较为明显, 能够更直观的体现反演结果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|