{kind=link}
{kind=link}
{kind=link}
利用预训练模型提升光谱特征提取性能的有效性研究
[任菊香1  , 刘忠宝
, 刘忠宝2, * ]
, 刘忠宝]
|
|


作者简介: 任菊香, 女, 1971年生, 山西工程科技职业大学信息工程学院副教授 e-mail: 806214106@qq.com
观测技术的发展带来了海量的光谱数据。 如何对这些数据进行自动分类受到广大研究人员的关注, 其关键是光谱数据的特征提取。 鉴于人工处理方式的局限性, 主流研究大多采用机器学习算法进行光谱数据的特征提取。 然而, 这些机器学习算法由于时空复杂度过高无法处理海量光谱数据。 近年来涌现的预训练模型具有优良的特征提取能力, 但目前鲜有文献对该模型对光谱数据有效性问题进行探讨。 因此, 将恒星光谱数据作为研究对象, 分别引入BERT、 ALBERT、 GTP等预训练模型和卷积神经网络(CNN)来对恒星光谱数据进行特征提取和分类处理, 通过比较实验结果来检验这几类预训练模型在恒星光谱特征提取方面的有效性。 利用Python编程语言编写光谱分类程序。 在预训练模型特征提取的基础上, 利用TensorFlow1.14中的CNN模型进行光谱类型判定。 实验用到的数据集是SDSS DR10恒星光谱数据集, 包括K型、 F型、 G型。 利用网格搜索和5倍交叉验证法获得实验最优参数。 在相同训练数据集条件下, 与ALBERT、 GPT相比, BERT模型的分类正确率均最高。 从平均正确率看, 在K型、 F型、 G型恒星数据集上, BERT模型的平均正确率比ALBERT分别高0.025 1、 0.021 5和0.022 5, 比GPT分别高0.049 7、 0.042 4和0.043 2。 分析实验结果可以得出如下结论: (1)恒星光谱分类正确率随训练数据规模的增大而提高; (2)在训练数据规模占比相同的情况下, 同一模型在K型恒星数据集上的分类正确率最高, 其次是F型恒星数据集, G型恒星数据集最低; (3)与ALBERT、 GPT相比, BERT模型具有具有更优的特征提取能力。
The development of observation technology has led to massive spectral data. How to automatically classify these data has received attention from researchers, the most important of which is feature extraction. Given the limitations of manual processing, most of the research uses machine learning algorithms to extract feature-based spectral data. However, these machine learning algorithms cannot handle massive spectral data due to the high spatial and temporal complexities. The pre-trained models emerging in recent years have excellent feature extraction capabilities. Still, there is little research on the effectiveness of such a model in the feature extraction of spectral data. Therefore, this paper takes the stellar spectral data as the research object separately introduces the pre-training models such as BERT, ALBERT, GTP, and Convolutional Neural Networks (CNN) for feature extraction and classification of the stellar spectral data, and tries to verify the effectiveness of these pre-training models for feature extraction of stellar spectral data by comparing the experimental results. Python programming language is used to write the spectral classification program. Based on the feature extraction of the pre-trained models, the CNN model in TensorFlow 1.14 is utilized for spectral data classification. The dataset used for the experiment is the SDSS DR10 stellar spectral dataset, including K-type, F-type, and G-type. The grid search and 5-fold cross-validation are utilized to obtain the experimental optimal parameters. The BERT model has the highest classification accuracies compared to ALBERT and GPT with the same experimental conditions. In terms of the average classification accuracies, the average classification accuracies of the BERT model are 0.025 1, 0.021 5, and 0.022 5 higher than that of ALBERT, and 0.049 7, 0.042 4, and 0.043 2 higher than that of GPT, on the K-type, F-type, and G-type stellar datasets. It is easy to draw the following conclusions by analyzing the experimental results: Firstly, the classification accuracies improve with the scale increase of training data; Secondly, the same model has the highest classification accuracies on the same training dataset of K-type stellar, followed by the F-type and the G-type; Thirdly, the BERT model has the best ability of feature extraction compared with ALBERT and GPT.
近年来, 随着观测技术的发展, 涌现并收集了海量的光谱数据。 光谱数据分类作为光谱数据处理的一个重要研究方向, 一直受到学术界的广泛关注。 光谱分类的关键是特征提取。 传统的人工处理方式无法满足实际需求, 机器学习算法由于时空复杂度过高亦很难有效利用。 近年来涌现出的预训练模型以其优良的特征提取能力得到大规模的推广应用。 该模型是否对光谱数据亦有成效?目前鲜有文献对此问题进行研究。 鉴于此, 本文将恒星光谱数据作为研究对象, 分别引入当前主流的几类预训练模型和卷积神经网络(convolutional neural networks, CNN)来对恒星光谱数据进行特征提取和分类处理, 通过比较实验结果来检验这几类预训练模型在恒星光谱特征提取方面的有效性。
主成分分析[1]、 线性判别分析[2]、 保局投影[3]等机器学习算法广泛应用于恒星光谱特征提取。 目前, 研究人员采用深度学习模型来对恒星光谱数据进行特征提取。 Liu等受卷积神经网络启发, 提出一维恒星光谱卷积神经网络(1D stellar spectra convolutional neural network, 1D SSCN), 他们利用该模型进行光谱特征提取和分类处理[4]; Jiang等针对卷积神经网络存在的过拟合问题, 提出增强型多尺度卷编码积神经网络(enhanced multi-scale coded convolutional neural network, EMCCNN), 该模型能够有效地对恒星光谱进行去噪处理以及特征提取[5]; Zhao等提出鲁棒的集成卷积神经网络(ensemble convolutional neural network, ECNN), 他们利用该模型对斯隆恒星光谱数据进行特征提取和分类处理[6]; 何东远等引入一维卷积神经网络对SDSS恒星光谱数据进行特征提取和自动分类, 实验结果表明该模型具有较高的特征提取能力[7]; Shi等提出基于卷积神经网络的恒星光谱分类网络, 用以识别O、 B、 A、 F、 G、 K、 M等类型光谱[8]。 目前, 对光谱特征提取方法比较研究的成果不多, 典型代表是: 姜斌等在探究恒星光谱数据特点的基础上, 着重研究了这些数据在高维空间的分布性状, 结合流形学习在特征提取方面的有效性, 对比分析了t-SNE和主成分分析两类特征提取方法的有效性[9]。 然而, 该对比研究针对传统机器学习算法展开, 尚未发现对预训练模型进行对比研究的文献。 因此, 本文研究具有一定的前瞻性和新颖性。
预训练模型是一种对大规模光谱数据进行特征提取的模型。 该模型需要输入光谱数据的离散化属性值。 通过学习这些光谱数据的结构, 预训练模型可以获取丰富的特征信息。 近年来, 预训练模型的兴起在深度学习领域引起了广泛关注, 并涌现了一系列模型, 典型代表有: BERT、 ALBERT、 GTP等。
2018年Google提出了第一个预训练模型——BERT[10]模型。 BERT模型采用双向Transformer编码器来处理光谱数据, 这使得BERT模型可以基于上下文信息对光谱数据进行编码, 从而更好地提取光谱数据的特征信息。
BERT模型的输入包含Token Embedding、 Position Embedding和Segment Embedding三部分, 这三种编码之和构成了BERT模型的输入数据。 其中, Token Embedding的作用是将输入数据转换成固定维度的向量; Segment Embedding的作用是区分多条输入数据; Position Embedding的作用是标注输入数据的先后顺序。 BERT模型的输入结构如图1所示。 图1中的输入数据由两条光谱数据组成, 以“ [CLS]” 为起始字符, “ [SEP]” 为光谱数据的分割字符, 最后再加一个“ [SEP]” 作为结尾。 其中, “ [CLS]” 是特殊类别标识, 表示输入光谱数据的特征信息; “ [SEP]” 是特殊分割标识, 用于分割多条光谱数据。
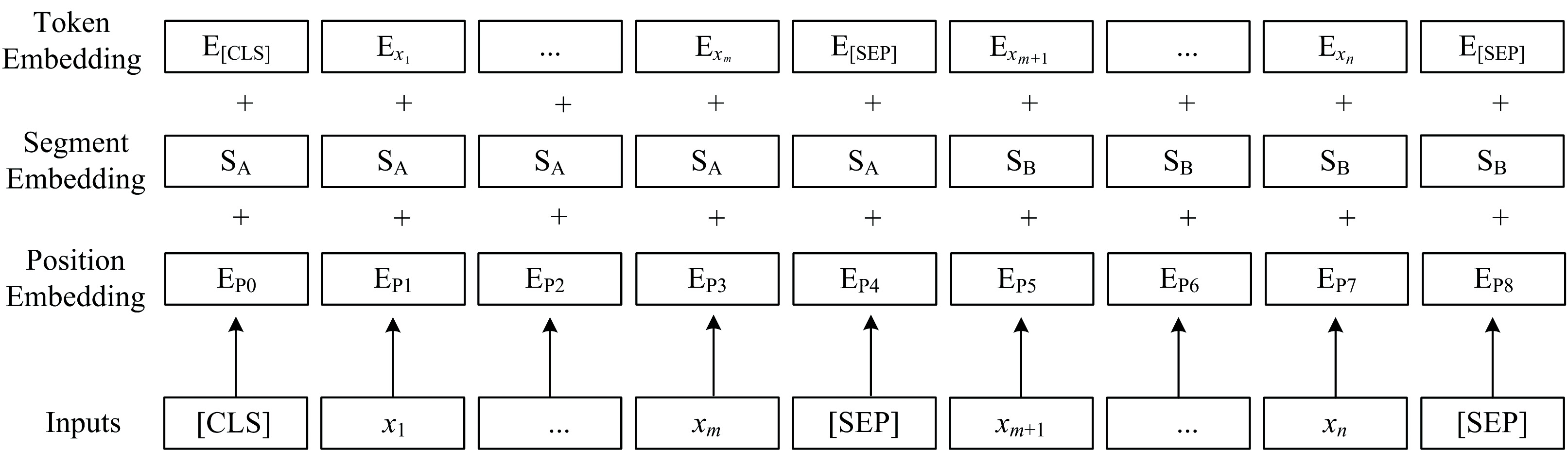 | 图1 BERT模型输入结构示意图Fig.1 The input structure of BERT model |
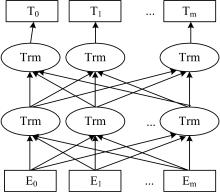
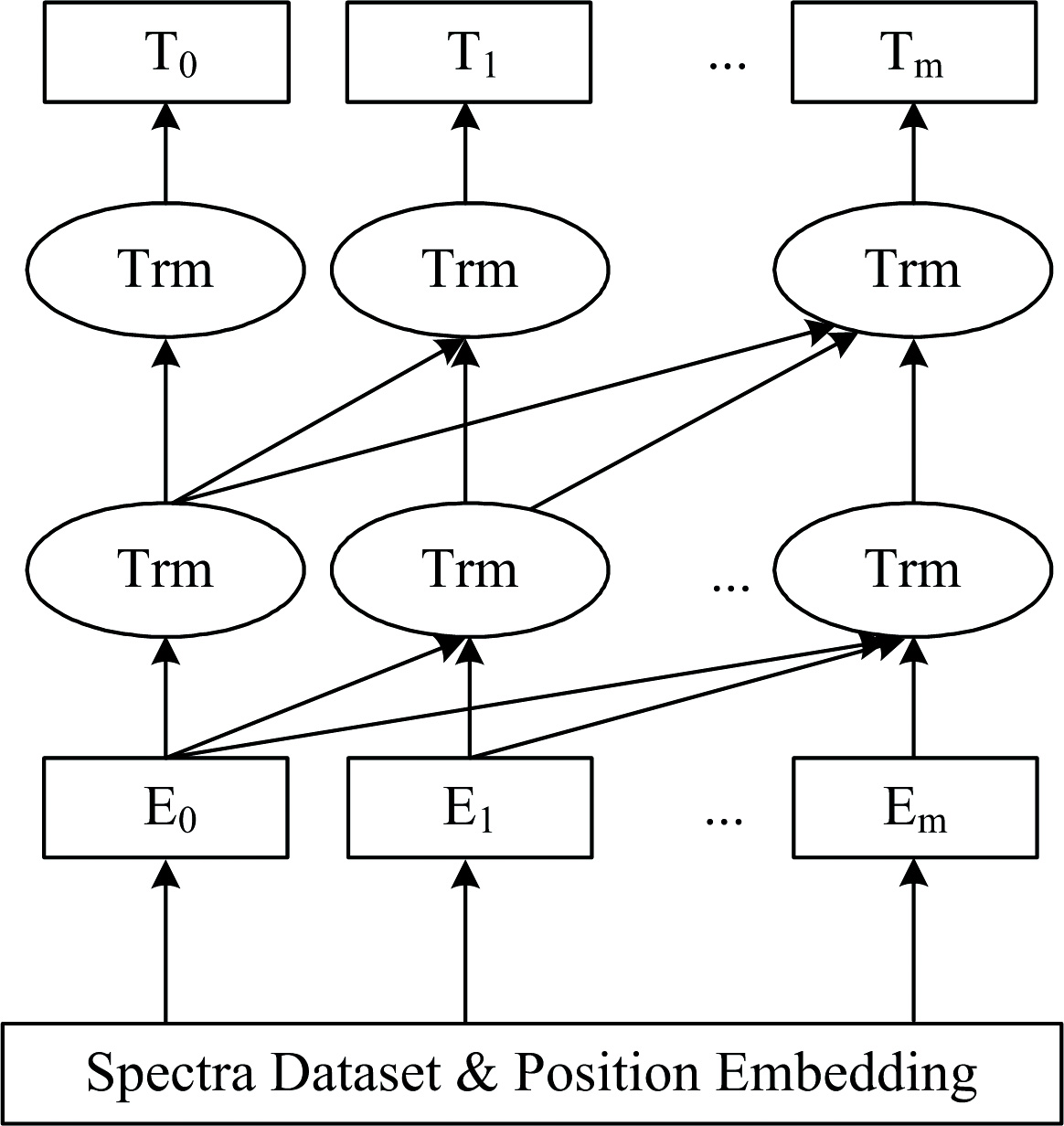
BERT模型的工作流程如图2所示。 其中, 输入数据由Token Embedding、 Position Embedding和Segment Embedding三种编码组合而成的输入数据E={E1, E2, …, Em}, 通过Trm(双向Transformer编码器)进行特征提取, 从而得到光谱数据的特征向量T={T1, T2, …, Tm}。 BERT模型采用MLM(masked language model)和NSP(next sentence prediction)进行训练。 MLM模型通过对输入光谱数据进行多层双向Transformer编码, 得到输入数据的特征表示。 然后, 经全连接层, 利用softmax函数对被掩盖的属性值进行预测。 NSP捕捉属性值之间的逻辑关系, 即给定两个属性值A和B, 预测A和B的先后顺序和内在联系。
 | 图2 BERT模型工作流程图Fig.2 The workflow of BERT model |
为了解决BERT模型参数量庞大的问题, Lan等提出一个轻量级的BERT模型——ALBERT[11]。 ALBERT模型的整体结构和BERT模型的整体结构相似, 但相较于BERT模型主要在以下几个方面进行优化:
(1)对嵌入层(embedding layer)向量进行因式分解。 BERT模型直接将嵌入层向量直接映射到隐藏层, 其中嵌入层维度E和隐藏层维度H相等。 当H提升时, E也随之增大。 假设属性值的规模为V, BERT模型的参数规模为O(V× H)。 而ALBERT通过在嵌入层后加入一个隐藏层, 将嵌入层向量先映射到一个低维向量空间, 然后再映射到隐藏层, 使得当E小于H时, 参数规模从O(V× H)降低至O(V× E+E× H), 从而提高模型的训练效率。
(2)使用参数共享优化技术。 在BERT模型中, 每一层都有独立的参数集合, 而在ALBERT模型中, 所有的隐藏层共享同一组参数, 因此, ALBERT模型的参数量大幅减少, 从而提高了模型的训练效率。
(3)引入SOP(sentence order prediction)任务来替代BERT模型中的NSP任务。 SOP任务专注于构建光谱数据离散化属性值之间的内在联系。 通过SOP任务, ALBERT模型可以更好地学习这些属性值之间的相关性和连续性, 从而提高ALBERT模型的光谱数据特征提取能力。
GPT(generative pre-trained transformer)模型[12]采用Transformer解码器结构处理光谱数据, 以自回归的方式生成预设长度的光谱特征。 GPT模型的训练主要由两个阶段构成: 第一阶段是在大规模光谱数据上利用无监督方式对模型进行训练; 第二阶段是根据光谱分类任务进行有监督的微调(supervised fine-tuning)。
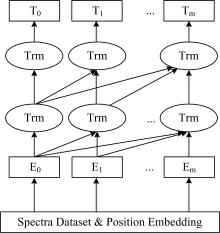
在第一阶段中, GPT模型的工作流程如图3所示。 其中, GPT模型的输入包括光谱数据和Position Embedding两部分。 Position Embedding用于表示光谱数据离散属性值的位置信息, 其目的是让模型了解这些属性值在输入光谱数据中的位置。 然后将光谱数据E={E1, E2, …, Em}输入到GPT模型, 通过Trm(Transformer解码器)得到每个属性值在当前位置的概率分布T={T1, T2, …, Tm}。
 | 图3 GPT模型工作流程图Fig.3 The workflow of GPT model |
GPT模型的第二阶段是微调。 针对光谱分类任务, 将光谱数据x={x1, …, xm}输入到第一阶段得到的模型, 取该模型最后一个隐藏层的输出, 并将其输入到全连接层, 利用softmax函数转化为概率分布, 如式(1)所示:
式(1)中, h为模型中最后一个隐藏层的输出, W为线性层权重, softmax(· )用于得到概率分布。
利用Python编程语言编写光谱分类程序。 在预训练模型特征提取的基础上, 利用TensorFlow1.14中的CNN模型进行光谱类型判定。 实验用到的数据集是SDSS DR10恒星光谱数据集, 包括K型、 F型、 G型。 实验选取K型光谱的K1、 K3、 K5次型, 信噪比区间均为(60, 65); F型光谱的F2、 F5、 F9次型, 信噪比区间依次为(55, 65)、 (70, 75)、 (80, 85); G型光谱的G0、 G2、 G5次型, 信噪比区间依次为(60, 75), (65, 70), (40, 75)。 实验数据如表1—表3所示。 鉴于预训练模型对输入数据有一定要求, 故将恒星光谱数据做如下处理: 选取间隔为20的200个波长作为条件属性; 根据每个波长处的流量、 峰宽和形状, 离散化为十三个数值之一; 恒星类别作为判定属性。
| 表1 K型恒星光谱数据集 Table 1 The dataset of K stars |
| 表2 F型恒星光谱数据集 Table 2 The dataset of F stars |
| 表3 G型恒星光谱数据集 Table 3 The dataset of G stars |
预训练模型和CNN模型的特征提取和光谱分类性能与参数密切相关, 选用网格搜索方式获取模型最优参数。 batch_size表示训练一次模型所用的数据规模, learning_rate表示模型的学习率, 它们均在网格{1× 10-3, 5× 10-3, 1× 10-4, 5× 10-4, 1× 10-5, 5× 10-5}中搜索选取; hidden_units是隐藏层包含的神经元数, 在网格{64, 128, 256, 512}中搜索选取; dropout表示丢失率, 在网格{0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}中搜索选取。 利用5倍交叉验证法获得实验最优参数。
| 表4 实验参数表 Table 4 The experimental parameters |
利用分类正确率对实验结果进行评价。 依次选取30%~70%的实验数据集用作模型训练, 剩余数据集作为测试数据集。 在三类恒星光谱数据集上的实验结果如表5—表7所示。
| 表5 K型恒星数据集的实验结果 Table 5 The experimental results on the K-type dataset |
| 表6 F型恒星数据集上的实验结果 Table 6 The experimental results on the F-type dataset |
| 表7 G型恒星数据集上的实验结果 Table 7 The experimental results on the G-type dataset |
由表5—表7可以看出: 恒星光谱分类正确率随训练数据规模的增大而提高。 此外, 在训练数据规模占比相同的情况下, 同一模型在K型恒星数据集上的分类正确率最高, 其次是F型恒星数据集, G型恒星数据集最低。 具体而言, 在表5中, 当训练数据占比70%时, BERT、 ALBERT、 GPT三类模型的分类正确率均最高, 均达到0.93以上, 但BERT模型的分类正确率最高, 分别比ALBERT、 GPT高0.025 6、 0.045 2。 在表6中, 当训练数据占比70%时, BERT、 ALBERT、 GPT三类模型的分类正确率均最高, BERT模型分别比ALBERT、 GPT高0.021 9、 0.044 8。 在表7中, 当训练数据占比70%时, BERT、 ALBERT、 GPT三类模型的分类正确率均最高, BERT模型分别比ALBERT、 GPT高0.027 6、 0.046 0。 从平均正确率看, 在K型、 F型、 G型恒星数据集上, BERT模型的平均正确率比ALBERT分别高0.025 1、 0.021 5、 0.022 5, 比GPT分别高0.049 7、 0.042 4、 0.043 2。 由上述实验结果可以看出: 与ALBERT、 GPT相比, BERT模型具有更优的恒星光谱特征提取能力。
预训练模型具有优良的特征提取能力, 该模型在众多领域取得了较好的实践效果。 目前, 一些研究试图将预训练模型应用到光谱数据特征提取, 尽管取得了一定进展, 但应用的广度和深度还有待加强。 特别是缺乏预训练模型的对比研究, 导致研究人员无法明确这些模型的性能表现, 不利于这些模型的推广应用。 为此, 本文将恒星光谱数据作为研究对象, 在引入BERT、 ALBERT、 GPT等典型预训练模型进行特征提取的基础上, 利用CNN模型进行恒星光谱数据分类, 通过分类结果来判断预训练模型特征提取性能。 对实验结果分析可得出如下结论: (1)随着训练数据规模的增加, 各预训练模型的分类正确率呈上升趋势; (2)K型恒星数据集上的分类结果较之F型、 G型更优; (3)BERT模型的分类正确率最优, 其次是ALBERT和GPT, 这表明BERT模型具有最优的恒星光谱特征提取能力。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|