

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于波峰波谷特征提取技术的檀香紫檀光谱识别
[庄鹏燕1 , 牛佳顺1 , 程俊3 , 卢静宜1 , 孙建平1, *  , 何拓
, 何拓2, * ]
, 何拓]
|
|


作者简介: 庄鹏燕, 女, 2000年生, 广西大学资源环境与材料学院硕士研究生 e-mail: 1401510876@qq.com
伴随着经济水平的飞速增长, 人们对红木产品的需求日益增大, 而檀香紫檀作为一种珍贵红木因其在精神层面上符合人们的追捧且价格昂贵, 具有巨大的商业价值而被不法分子替代和假冒。 为维护木材市场的秩序和消费者的利益、 实现对檀香紫檀的快速无损检测以及鉴别, 有必要建立一种快速、 可靠的檀香紫檀木材智能识别方法。 采用近红外光谱(NIR)分析技术提取檀香紫檀及其相似血檀的光谱信息, 利用定性分析方法、 偏最小二乘判别分析(PLS-DA)和误差反向传播人工神经网络(BPNN)对光谱信息建立校正模型, 进而对檀香紫檀及其相似木材血檀进行识别; 通过分析比较这三种模型对这两类木材识别的优缺点和识别准确率, 验证该方法对檀香紫檀和血檀识别的可行性。 研究发现三种判别模型均能够快速识别木材光谱图像, 具有对檀香紫檀和血檀进行快速无损分类识别的能力, 在选取不同图像处理方法的情况下, 三种判别模型显示的结果各不相同, 识别结果也存在差异。 进一步分析表明, 在使用BPNN模型对光谱数据进行建模时, 通过预处理将原始光谱数据波长范围866~2 533 nm的波峰波谷特征值作为输入, 当输入层节点数为24个特征值, 隐含层13个神经元时, 模型的均方根误差最小, 准确率达到96.43%。 此外, 缩短光谱范围并不会提高模型的识别率, 而在三种模型中, 全波段范围的BPNN模型具有最高的识别率。 实验结果表明, 基于人工神经网络模型结合NIR特征提取技术识别檀香紫檀木材有着较高的识别准确率, 其效果相较于前人有一定的提升。 该研究有利于减少人工识别的主观性, 使用计算机更能够缩短识别时间, 较高的准确率可以帮助维护木材市场的秩序和消费者权益。 同时, 这也为实现檀香紫檀智能视觉识别提供了参考, 为红木产业的可持续发展提供技术支持。
With the rapid growth of the economic level, people′s demand for mahogany products is increasing day by day. As precious mahogany, criminals replace sandalwood and counterfeit it because of its spiritual pursuit and high price. To maintain the order of the timber market and the interests of consumers and realize the rapid non-destructive detection and identification of sandalwood, it is necessary to establish a fast and reliable intelligent identification method of sandalwood. This paper used near-infrared spectroscopy to extract the spectral information of Pterocarpus santalinus and its similar blood sandalwood. The qualitative analysis method, partial least squares discriminant analysis (PLS-DA), and error back propagation artificial neural network (BPNN) were used to establish the calibration model of spectral information. Then, Pterocarpus santalinus and its similar wood blood sandalwood were identified. By analyzing and comparing the advantages and disadvantages and recognition accuracy of these three models for these two kinds of wood recognition, the feasibility of this method in the recognition of sandalwood and sandalwood is verified. The experimental results show that the three discriminant models can quickly identify the wood spectral images, and can quickly and non-destructively classify and identify sandalwood and sandalwood. In the case of selecting different image processing methods, the results of the three discriminant models are different, and the recognition results are also different. Further analysis reveals that when the spectral data are modeled using the BPNN model, the peak and trough eigenvalues of the original spectral data within the wavelength range of 866~2 533 nm are utilized as input following preprocessing. It is observed that when the number of input layer nodes is Setto 24 eigenvalues and the hidden layer consists of 13 neurons, the model achieves the smallest root mean square error, with an accuracy rate of 96.43%. Additionally, shortening the spectral range does not result in an improvement in the model′s recognition rate. The BPNN model demonstrates the highest recognition rate across the full band range among the three models. The experimental results indicate that the combination of artificial neural network modeling and near-infrared spectral feature extraction technology yields a high recognition accuracy in identifying sandalwood wood, surpassing trevious methodologies. This study contributes to mitigating the subjectivity inherent in manual recognition processes. The utilization of computers can expedite the recognition process, while the enhanced accuracy aids in maintaining order within the wood market and safeguarding consumer rights. Simultaneously, it offers insights into realizing intelligent visual recognition of sandalwood and furnishes technical support for the sustainable development of the mahogany industry.
红木中以檀香紫檀最为珍贵, 它因具有深紫红色的心材和漂亮的纹理而受到追捧, 这一贵重木材不仅在视觉上具有吸引力, 并且由于其抽提物产生的天然檀香的香气而独具特色[1]。 现阶段, 由于檀香紫檀木材存在资源稀缺、 进出口贸易受限等问题, 市场上出现了大量仿冒和假冒产品。 一些制造商采用低成本的木材如血檀等, 通过染色、 贴面等手段伪装成檀香紫檀欺骗消费者。 这些产品不符合安全标准, 不仅威胁到消费者的权益和安全, 同时也会损害整个行业的健康发展[2]。 因此, 快速有效地分辨檀香紫檀木材质地、 鉴别其真伪[3]对于规范市场、 珍稀木材保护与利用等方面都具有重要意义[4]。
而对檀香紫檀的识别技术主要来源于传统的木材识别方法, 其中以形态学为基础的识别方法需要经验丰富的工匠通过长期的实践积累才能实现。 19世纪, 人们通过微观识别法观察木材的细胞结构和纤维形态, 这种方法需要对木材的组织结构进行破坏[5]。 20世纪初, 人们开始引入生物学标志物和放射性同位素对木材种类进行测定但需要严格的实验室条件限制。 这些传统方法主要从物理和解剖学的角度进行, 成本高、 速度慢、 通常只能精确到属[6]。 研究发现, 光学和化学分类方法在木材鉴定方面有很好的效果, 通过分析光谱特征可以区分极其相似的木材物种[7]。 其中近红外光谱(near-infrared spectroscopy, NIR)成像技术是一种简单、 绿色、 有效的光谱分析技术[8], 分析效率高、 操作方便, 已成功应用于石油化工[9]、 农业[10]、 食品[11]等行业, 近年来在林业科学领域中显示出巨大的潜力[12], 现阶段已有学者对多种红木结合主成分分析法(principle component analysis, PCA)进行研究, 识别准确率受环境影响较大。 在此基础之上有学者基于NIR技术结合机器学习, 建立的模型对煤矿中的煤和矸石样本光谱数据识别准确率可达到95%以上[13], 验证了光谱分析法在识别方面的可行性。 目前, NIR结合机器学习方法对木材的识别主要集中在木材表面, 有学者结合偏最小二乘判别分析和BP神经网络模型对木材表面缺陷进行判别[14], 识别准确率可达到95%以上, 但把两者结合用于红木识别研究的报道较少。 虽然NIR技术需要很强的专业判断能力, 但与机器学习算法[15]相结合具有更大的潜力[16]。
针对上述问题, 本研究提出基于NIR分析技术, 利用光谱信息结合定性分析方法、 偏最小二乘判别分析(PLS-DA)和误差反向传播人工神经网络(BPNN)[17]的三种方法建立校正模型, 探索光谱全波段、 光谱波峰波谷特征值对识别效果的影响, 对比分析三种模型在准确识别紫檀方面的优缺点和识别准确率, 研究快速、 准确识别檀香紫檀木材智能模型, 为红木智能识别提供新的思路。
根据现行红木标准GB/T 18107—2017准备两种血檀(Pterocarpus tinctorius, 刚果、 赞比亚)以及檀香紫檀(Pterocarpus santalinus L.f, 印度)木材样本各21块, 表面粗糙度一致、 含水率为12%。 其中檀香紫檀木块规格为100 mm× 50 mm× 10 mm, 两种血檀的规格为100 mm× 50 mm× 15 mm。 样本中14块(样本总数的2/3)用于模型训练, 7块(样品总数的1/3)作为未知样品对模型进行验证。
1.2.1 NIR采集
使用布鲁克公司TANGO小型化傅里叶变换近红外光谱仪对木材样品进行光谱采集, 每间隔10分钟测量一次背景单通道光谱以保证光谱的稳定性。 采谱时将样品放置在仪器的样品台上, 确保木块安放正确并与光学路径对齐, 打开光谱仪的控制软件并设置参数[环境温度: (20± 5) ℃, 湿度: 20%± 5%, 光谱扫描范围: 866~2 533 nm, 光谱采样间隔为: 4 cm-1]。 启动光谱扫描, 让仪器记录木材样品的NIR。
将每个样品分为A面和B面, 每一面划分为25 mm× 20 mm的十个采谱区, 代表10个样本, 每个木块样品可以分为20个采谱区, 得到20个样本, 如图1(a)所示。
 | 图1 (a)样品划分采谱区; (b)测量样品单通道光谱Fig.1 (a) Sample division sampling area; (b) Measurement of sample single channel spectrum |
每个采谱区由仪器扫描32次后形成一条光谱以减少数据运算, 每5条光谱平均为一条光谱后保存, 每个树种最终得到84条光谱样本用于实验研究。 测量样品单通道光谱如图1(b)所示。
光谱数据采集结束后, 当同一类样本的光谱出现异常时对该样本进行重新扫描以判断是否应更正光谱或选择剔除。 为消除仪器噪声、 样本背景和杂散光等影响, 对得到的数据进行预处理。
1.2.2 光谱数据预处理
仪器存在其他干扰信息, 光谱预处理在一定程度上可以有效消除其影响。 本研究中使用一阶导数和二阶导数、 矢量归一化(vector normalization, VN)、 多元散射校正(multiplicative scatter correction, MSC)和标准正态变量校正(standard normal variation, SNV)对光谱数据进行预处理, 使得数据更符合模型的假设条件, 提高模型性能。
(1) 导数校正[18](derivative correction)
导数校正作为一种常用的光谱预处理方法广泛应用于光谱分析中, 计算公式如式(1)和式(2)
对于光谱数据而言, 一阶导数可以减少光谱的基线漂移效应, 有效消除不同组分间的干扰, 提高分辨率和灵敏度, 二阶导数则可以增强光谱峰的特征, 提高数据的可解释性和模型的鲁棒性。 但导数矫正同时也存在引入噪声, 降低信噪比的问题。
(2) VN
将每个样本向量除以其模长, 使得每个样本向量都处于单位长度上, 从而消除样本的尺度差异, 提高模型对数据特征的提取能力。 本实验中求出光谱值与y平均值的差值, 得到的光谱的中值为零, 再计算所有y值的平方和, 用光谱除以该平方和的平方根, 结果光谱的矢量归一值是1。
(3) MSC和SNV
MSC用于消除NIR光谱中的线性散射影响, 进而提高模型的可靠性和预测性能。 SNV的目的与MSC相似, 主要用来消除样本表面固体颗粒大小、 表面散射以及光程变化对NIR漫反射光谱的影响[19], 使得数据在每个特征维度上都呈现出标准正态分布的形式。
1.2.3 特征提取
NIR光谱全波段有1 845个数据点, 过多的数据输入模型过于冗杂, 且某些波段范围内有效信息较少, 引入后会降低模型精度, 因此对光谱数据进行特征参数提取, 从而提高模型的识别效果。 本研究运用PCA法和波峰波谷特征数值提取对光谱特征参数进行提取。
(1) PCA[20]
通过线性变换达到降低数据维度的目的。 降维后的每个分量是原变量的线性组合, 最后保留下来累计贡献率达到所需阈值要求的主成分因子得分。 计算步骤: 对原始数据样本集合进行标准化处理—正交分解标准化后的数据矩阵的协方差矩阵, 得出主成分分量—计算各主成分的累计贡献率, 根据贡献率阈值选取主成分—建立主成分方程, 计算主成分值。
(2) 波峰波谷特征值提取[21]
木材中含有不同的含氢基团, 其NIR曲线具有起伏显著的波峰波谷, 因此吸收度的数值包含大量的样本信息, 提取光谱曲线的波峰波谷特征参数达到模型输入特征参数降维的目的。 实施步骤如下: 原始光谱数据小波去噪后再使用函数找出每一条光谱曲线的波峰波谷位置, 由于同种木材具有相似的光谱曲线, 因此可以提取到同一个波峰波谷的位置的不同光谱的吸光度值, 保留若干具有显著特征的波峰波谷, 使用它们的吸光度值作为模型的输入参数。
利用已知样本建立预测模型, 定性判别未知样品的类别。 本研究采用OPUS软件、 PLS-DA、 BPNN[22]定性分析。
1.3.1 OPUS定性分析
建立参考谱图库, 将预测光谱同参考谱库进行比较计算匹配值。 定性分析有两种基本算法: 标准算法和因子法, 在分析过程中, 将测试光谱与参考谱图进行对比, 比较结果是匹配值, 也对应为谱图距离D。 两张谱图越匹配, 距离则越短, 完全相同的谱图匹配值为零。
(1) 标准算法
光谱距离D与光谱曲线之间的面积成比例, 使用欧式距离公式。
式(3)中, a(k)和b(k)是谱图a和b的纵坐标的值, 和是从所选全部数据点k得到的。
(2) 因子法
将谱图表示为所谓因子谱(荷载)的线性组合
式(4)中, 矢量a表示谱图a, 因子谱表示为f1, f2, f3等。 T表示重建原始谱a的必要因子(得分); 因子法计算光谱距离时使用因子T, 要对给定数量的因子求和, 这些因子T也称为得分。
定性分析判定预测光谱与库中参考谱的差别, 通过定义一个阈值来判定光谱是否与参考光谱相似或相同。 阈值为平均报告所列的最大距离加上标准偏差(SDev)与任何因子乘积的总和。
1.3.2 PLS-DA
此方法基于偏最小二乘回归法将光谱数据与分类变量进行线性回归, 用于建立输入特征与类别标签之间的关系。 采用MATLAB建模, 在所采集光谱的样本中随机选取占总量2/3的样本作为校正集建立模型, 剩余1/3的样本作为验证集。 以校正均方根误差(RMSEC)、 验证均方根误差(RMSEV)、 判别正确率(Accuracy)作为模型判别能力的评价指标。
建立模型时, 要将目标变量(Y)转换为虚拟变量(0或1)表示类别。 当需要对新样本进行分类时, 可以利用模型中的系数矩阵C来对新的特征数据进行投影, 根据投影后的结果进行分类。 即为在包含np个样本的验证集中, 每个样本有p个特征。 将这些特征数据表示为Xval, 其维度为np× p。 利用模型中的权重矩阵Wc将验证集的特征数据进行投影, 得到投影后的得分矩阵Tval, 则
使用已经计算得到的系数矩阵C, 将投影后的得分矩阵Tval进行加权求和, 得到每个验证样本的分类变量Yp,
式(7)中, Yp的维度为np× m, m是类别数量。 当Yp(验证集分类变量)> 0.5, 且偏差(Deviation)< 0.5时, 判别样本属于该类; 当Yp< 0.5, 偏差< 0.5时, 判别样本不属于该类; 当Yp的偏差> 0.5时, 无法判定样本类别。 需要注意的是, 当使用偏最小二乘判别分析进行分类时, 对于验证集的分类变量Yp的计算实际上是通过将验证集的特征数据投影到模型空间, 并利用模型的参数对投影后的结果进行解释, 从而得到每个样本对应的分类变量。
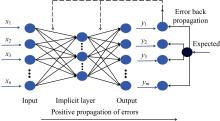
1.3.3 BPNN模型
BP神经网络作为有监督学习算法属于最基础的神经网络的一种, 其输出结果采用前向传播, 误差采用反向(back propagation)传播方式进行, 模型结构如图2所示。
其中, x1, x2, …, xn为输入变量, y为输出变量。 前一层神经元连接到下一层神经元, 收集到传递来的信息时经过“ 激活” 把值传递给下一层, 激活函数为sigmod函数, 映射关系为
式(8)中, x为输入变量, y的结果在0到1之间, 因此可以将任意实数映射到一个概率值(0到1之间)。
训练过程中随机初始化权重和偏置, 根据负梯度方向寻找误差的最小值, 从而确定最小的误差参数, 计算公式如式(9)所示
式(9)中。 target指实际值(目标值), out指神经网络的输出值。 本研究将光谱数据作为BP模型的输入矩阵。 网络的输入层节点数分别为主成分数和波峰波谷特征参数, 随机赋予初始权值和阈值, 训练过程中采用TRAINGDX和TRAINBR两种函数对模型梯度进行调整, 输出节点数为样本的类别数。 BPNN神经网络训练的最大迭代次数为5 000, 学习速率为0.1, 目标误差为0.001, 误差使用均方根误差(RMSEP)。 期望输出使用单位矩阵编码, 当对应样本的网络输出值大于0.5, 而其余位置小于0.5时结果为正确判别, 否则为判别错误; 采用RMSEP和识别正确率作为模型预测效果的评价指标, 识别率越高, RMSEP越小, 模型精度越高。
2.1.1 原始光谱图分析
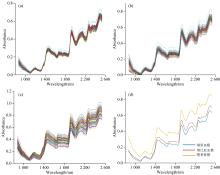
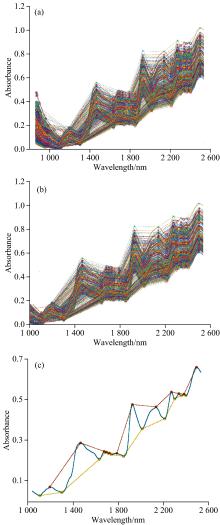
将采集到的光谱每五条平均为一条减少运算, 所得结果如图3所示。 从图谱中看出, 两种血檀的光谱位值相近且线条存在重叠现象, 赞比亚血檀和檀香紫檀的光谱也存在少量重叠; 三种木材光谱曲线形状相近, 紫檀的光谱范围整体大于血檀, 这是因为不同树种之间主要化学组分的含量不同造成吸收强度的高低不等。 三类样品的原始光谱图如图3(d)所示。
 | 图3 原始光谱图 (a): 刚果血檀原始光谱图; (b): 赞比亚血檀原始光谱图; (c): 檀香紫檀原始光谱图; (d): 三个树种样本的光谱图Fig.3 Original spectrogram (a): The original spectra of Helosanthes congo; (b): The original spectra of Helosanthes zambia; (c): The original spectra of Pterocarpus santalinus; (d): The spectra of three tree species samples |
2.1.2 预处理谱图分析
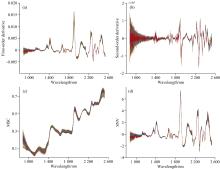
对原始光谱进行一阶导数、 二阶导数、 多元散射校正(MSC)和标准正态变量校正(SNV)预处理, 处理结果如图4所示。 由图可以看出, 导数处理后的光谱吸收峰能够更清晰的反映木材中的化学基团在近红外区域的振动吸收如图4(a)和(b)所示; MSC和SNV预处理后的光谱消除了散射和光程的影响, 增强了光谱的有效信息如图4(c)和(d)所示。
 | 图4 原始光谱的预处理光谱图 (a): 一阶导数处理光谱; (b): 二阶导数处理光谱; (c): MSC处理光谱; (d): SNV处理光谱Fig.4 Preprocessed spectra of the original spectrum (a): First derivative treatment spectrum; (b): Second derivative treatment spectrum; (c): MSC treatment spectrum; (d): SNV treatment spectrum |
2.1.3 光谱特征提取
(1)主成分分析
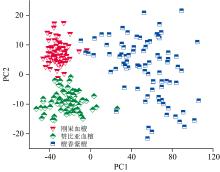
对NIR全波段信息的1 845个数据点进行主成分分析, 提取解释总分类99%以上的主成分得分取代数据点, 作为模型的输入参数。 结果如表1所示, 将特征值按大小顺序进行排列, 前两个特征值的累计贡献率达99.112%, 经总方差分解, 只采用前两个主成分即可解释NIR的主要信息, 两个主成分的得分分布如图5所示。 三种木材样本具有相对明显的样本分布, 只有少量混淆, 表明主成分分析结果显著, 它们在光谱数据上存在差异。
| 表1 NIR主成分分析结果 Table 1 Principal component analysis results of NIR spectroscopy |
 | 图5 主成分得分图Fig.5 Principal component score plot |
(2) 波峰波谷特征值提取
对全波段光谱进行波峰波谷提取, “ * ” 表示波峰数据点, “ o” 表示波谷数据点, 提取结果如图6所示。 综合图像提取结果, 舍去866~2 533 nm范围内的光谱; 再对1 000~2 533 nm范围内的光谱进行提取, 其中提取结果如图6(b)所示, 在提取相同数目的波峰和波谷特征值的前提下, 发现最多可以同时提取到12个波峰和12个波谷, 即共获取24个特征值如图6(c)所示。
 | 图6 波峰波谷特征值提取结果 (a): 866~2 533 nm范围结果; (b): 1 000~2 533 nm范围内结果; (c): 波峰波谷24个特征值效果Fig.6 Peak and trough eigenvalue extraction results (a): 866~2 533 nm range results; (b): 1 000~2 533 nm range results; (c): Peak and trough 24 eigenvalue effect |
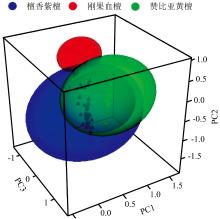
主成分分析因子化得分结果如图7所示, 由图知大部分样本具有明显的分布区域, 其中刚果血檀和赞比亚血檀样本较为集中, 且前者没有出现与其他样本混淆的情况; 檀香紫檀的分布区域较为宽泛, 有少量出现涵盖其他类别的样本。
 | 图7 因子化3D得分图Fig.7 Factorized 3D score plot |
OPUS定性分析中, 分别使用0.10和0.25(缺省值)作为阈值计算的x因子(计算光谱距离时的阈值), 定性分析结果如表2所示。 在本试验中, x的值从0.25开始, 每减小0.01预测一次结果, 在x=0.10时识别正确率开始出现变化, x减小到0.01期间, 结果再无明显变化, 则认为值无再继续减小的必要, 最终x取0.25和0.10的两个结果进行对比。 由表知, x=0.10时识别率更高。 由于x值越小阈值越小, 降低阈值在一定程度可以提高识别率, 但也缩小了样本范围。 阈值减小的情况下模型的容错性降低, 当样本种类达到一定数量时可能会出现无法识别或错误识别的情况。
| 表2 OPUS定性分析结果 Table 2 Qualitative analysis results by OPUS |
通过不同的预处理方式和算法组合, 最终得到的识别效果最显著的参数为采用一阶导数和矢量归一化对图像进行预处理, 使用因子化法计算未知光谱与参考谱图的距离, x因子的值为0.10, 置信水平为99.99%, 识别率为97.62%。
2.2.1 PLS-DA模型判别结果与分析
依据判别步骤, 首先建立三个树种样本的分类变量如表3所示, 对校正集样本数据和分类变量进行PLS分析, 再建立两者之间的回归模型, 最后计算验证集样本的分类变量的值。
| 表3 三个树种样本的分类变量 Table 3 Classification variables of three tree species samples |
(1) 无特征参数提取的PLS-DA模型判别结果
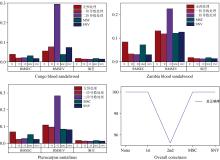
基于不同的预处理方式对全波段的NIR建立PLS-DA模型的判别结果如图8所示, 结果表明, 除二阶导数预处理时的识别正确率为95.24%外, 无预处理和其他预处理的模型识别率均达到100%, 此现象是由于二阶导数预处理使得光谱过度消噪而造成数据失真; 采用预处理的偏差值较无预处理时有所降低, 模型精度稍有提高, 所有模型的拒绝率都达到100%, 说明表示模型在接收到所有输入时都拒绝产生输出, 模型达到过拟合状态。
 | 图8 无特征提取的PLS-DA模型判别结果Fig.8 Discriminant results of PLS-DA model without feature extraction |
(2) 基于波峰波谷特征值的PLS-DA模型判别结果
由前文得最多可以提取24个NIR曲线的波峰波谷特征值, 适当减少数量, 依次选择20、 22、 24个特征值作为输入, 结果如图9所示, 改变特征值数目对识别效果无影响, 拒绝率和正确率均为100%; 特征值数目增多时, 偏差略有减小, RMSEC和RMSEV无明显差别, 说明适当改变特征值数目对PLS-DA模型识别效果基本无影响。
 | 图9 基于波峰波谷特征值提取方式的PLS-DA模型判别结果Fig.9 Discriminant results of PLS-DA model based on peak-valley eigenvalue extraction method |
2.2.2 BP神经网络模型判别结果与分析
(1) 基于主成分分析的BP神经网络模型
对原始数据中的1845个数据点进行主成分分析, 选取贡献率高达99%的因子作为BP神经网络的输入参数, 在不使用任何光谱预处理方法时, 2个主成分即可解释大部分的光谱信息, 因此将2个主成分的得分矩阵作为模型的输入向量。 神经网络隐含层由经验公式
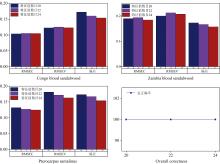
对神经元数为10~16的7种不同神经元数下BP神经网络的模型训练, 每个模型预测十次, 最终结果为十次预测的平均值, 7个模型的识别率均达96%以上。 调整神经元数目可以提高模型拟合度, 在一定范围内能够提升判别效果, 但较多的神经元数目会出现过拟合现象, 降低识别正确率, 同时也影响运算速度。 当隐含层神经元数为13时, RMSEP和识别正确率同时达到所有模型中的最佳值(97.62%), 拟合较好。 对上述得到的模型进行优化, 依次对NIR短波段(866~1 100 nm)、 NIR长波段(1 100~2 533 nm)和NIR全波段(866~2 533 nm)三个范围内的光谱建立BP神经网络模型, 结果表明全波段光谱范围内的模型识别效果最好, 缩短光谱范围不能有效提高模型识别率, 这是因为全波段光谱涵盖了更多的树种信息, 缩减光谱范围造成信息缺失, 从而降低树种识别率。
此外, 采用不同预处理方式对全波段光谱的BP神经网络模型进行优化, 隐含层神经元数为13。 采用MSC能明显提高模型识别率(100%), 降低RMSEP; 采用导数矫正和SNV预处理时, 模型识别率明显下降, 这是因为在这三种方式下进行主成分分析提取到的主成分数目均大于180, 主成分数目过多会降低数据的关联性, 预处理在消除噪音的同时也导致数据失真。
(2) 基于波峰波谷特征值提取的BP神经网络模型
木材的关键信息通常体现在光谱吸收峰和吸收谷的位置、 强度和形状上, 它们可以提供关于木材化学成分和结构的信息, 不同的化学成分对光的吸收和散射影响不同, 从而可区分木材种类。 本实验中, 提取NIR曲线的20、 22、 24个波峰波谷特征参数作为BPNN的输入, 设置隐含层神经元数为13, 训练结果如表4所示。 结果表明特征值的数量对模型识别的正确率无影响, 均为96.43%; 随着特征值数目的增多, 檀香紫檀的RMSEP由0.30减小为0.28, 刚果血檀与赞比亚血檀的RMSEP在特征值为22时达到稳定。 光谱信息相近的两类血檀树种的判别效果也有所提高, 说明特征值数目越多, 特征值包含的数据信息越多, 模型拟合度也越好。
| 表4 不同特征值数目下的BP网络模型 Table 4 BP network model with different number of eigenvalues |
基于NIR分析技术结合主成分分析法和波峰波谷特征值提取方式对檀香紫檀和两种血檀进行识别, 结果表明定性分析模型、 PLS-DA、 BPNN三种判别模型均具有对紫檀和血檀进行快速无损分类识别的能力, 在使用波峰波谷特征值提取方式对原始光谱数据进行处理, 24个特征值作为BP神经网络模型的输入层节点数时, 模型的RMSEP达到最小, 此时模型性能最好, 识别准确率达到96.43%, 本研究提供了一种可靠的红木识别方法, 相较于前人识别时间缩短。 此方法不仅有利于减少人工识别的主观性, 维护木材市场的秩序和消费, 同时也为智能识别红木提供了参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|